联合RF-BP-LR的电力客户电费拖欠混合风险预警算法
2022-06-18谢禄江皮羽茜
谢禄江,蒋 荣,皮羽茜,何 轶,廖 勇
(1.国网重庆市电力公司信息通信分公司, 重庆 401120;2.重庆大学 微电子与通信工程学院, 重庆 400044)
0 引言
我国对于电力能源的需求随着经济的发展在不断提高,电力行业已经成为我国经济发展的重要组成部分。据统计,2020年我国的总用电量达到75 110亿千瓦时,同比增长了3.1%,用电水平已经接近中等发达国家水平。全社会用电群体不断壮大,促进了全国总用电量的提高,同时加速了电力企业的发展,但也给供电企业带来了许多问题和隐患。目前,我国绝大多数电力公司采用的是“客户先用电,再向电力公司缴费”的经营模式[1],由于不能准确获取用电客户的信用水平,造成了部分诚信水平低的客户长期拖欠电费,严重影响了电费的顺利回收。若拖欠电费用户的总用电量占比较高,会破坏电力市场的正常交易秩序并给电力公司带来巨大损失[2-3]。故而对用户进行电费欠缴或拖缴风险分析和预警对于供电企业来说是一个亟需解决的问题。
针对上述问题,相关研究人员在对影响用户信用等级的特征提取、电费回收预警以及信用评估上已经展开了大量研究。De等[4]利用直觉模糊集理论的特点,在不确定的环境下,提出了基于直觉模糊层次分析法的信用风险评估模型。Wu等[5]提出了一种基于梯度学习决策树-随机森林-自适应逻辑回归的集成学习方法,构建了电费回收风险预测模型。为了有效评估信用,Chen等[6]构建了个人信用评估模型,使用反向传播(back propagation,BP)神经网络进行权重调整,准确性和收敛速度上具有明显的优势。为了评估异常用电和逾期收费的风险,Hu等[7]提出了一种基于多属性群决策的考虑付费和异常用电的用户欠费风险评估方法,首先确定包括用户付费和异常用电的评估指标体系,采用熵权法确定指标权重,然后根据最差指标对评价结果进行排序,并提供用户的风险等级。
为进一步提高电力行业欠费风险管理能力,有效辅助电力企业制定用电和电费预警策略,提出了RBL混合风险预警算法,提高了预测精度,对欠费风险用电客户达到预警目的,主要贡献如下:
1) 针对大量的电力客户数据集,有价值的信息很少的问题,首先利用随机森林(random forest,RF)算法对电力客户多维用户信息进行特征提取;其次,利用BP神经网络对客户信用进行初次风险预测并得出相关的信用得分值;最后,利用逻辑回归(logistic regression,LR)模型进行第二次预测,以此来提高整个预警模型的预测精度。
2) 根据欠费用户风险预测结果,本文特别地为电力企业建立了用电客户信用等级评价制度,对不同信用等级的用电客户制定了不同的预警策略、提供了针对不同信用等级用电客户可采取的相应措施,可用于电费回收管理人员进行提前催缴,确保电费回收的及时性。
1 特征提取以及数据预处理
1.1 问题描述及说明
对电力客户电费拖欠风险进行预警分析是一个多层次、全方位的问题。首先需要根据用电客户已有的数据提取出电费拖欠的主要影响因素,并对其进行标准化处理。用电客户的数据集中包含大量数据,如客户身份地址信息、历史用电情况及信用情况等,为了降低模型的识别难度,首先使用RF算法筛选出用户电费拖缴的主要影响指标。同时,针对多源数据结构不同且可能存在缺失或错漏的现象,还需要对数据进行预处理,得到可供模型输入的正常数据。
1.2 特征提取
RF是一种基于Bagging的集成分类器[8],在数据挖掘、分类筛选和预测等领域取得了突破性成果。RF分类器由多个树分类器组成,其中每个分类器使用由输入向量中独立取样的随机向量生成,每棵树对分类预测结果进行投票,以对输入向量进行分类。其中,RF分类器由N棵树组成,其中N是待生长的树的数量,可以是用户定义的任何值。为了对新数据集进行分类,数据集的每一种情况都被传递到N棵树中,在这种情况下,森林选择N个拥有投票数最多的类。在训练过程中,大约三分之二的样本(称为袋内样本)被用于训练决策树,剩下的三分之一(称为袋外样本)用于内部交叉验证,以估计最终得到的RF模型的整体性能[9],这个误差估计被称为袋外误差。RF分类器使用Gini指数作为属性选择度量,该值常用于度量数据在该类的纯度。对于给定的训练集T,随机选取一个属性,称其属于某类Ci,其Gini指数可表示为式(1)。
(1)
其中,f(Ci,T)/|T|表示选择的属性属于该类Ci的概率值。每次在新的训练数据上使用特征组合将树生长到最大深度,这些成熟的树没有修剪。这是RF分类器相对于其他决策树方法的主要优势之一。随着树的数量增加,即使不修剪树,泛化误差也总是收敛的,每个节点用来生成RF分类器所需的2个参数,即树的特征数和要生长的树的数量,它们由用户自定义。在每个节点上,只有选定的特征才会被搜索到最佳分割。为了对新数据集进行分类,数据集的每一种情况都被传递到N棵树中,在这种情况下,森林选择N个投票中拥有投票最多的类。给定样本的数据集合D,产生nTree棵决策树组合形成RF,RF形成过程[10]如图l所示。

图1 RF形成过程示意图
综合以上优点,利用RF算法对原始用户数据信息开展影响电费拖欠风险行为特征提取,从众多用电客户电费拖欠的影响指标中筛选出主要影响指标,提取过程如图2所示。

图2 特征提取过程框图
1.3 数据预处理
前期数据的处理与否会直接影响到模型训练的准确性。在用户数据记录过程中,由于人为因素、设备因素等影响,可能会造成供电企业对用户记录的数据不完整、错误的情况,因此在对数据进行提取之前需要对数据进行筛选并进行相应的处理,常见处理过程主要包括去掉冗余数据、对异常值的处理、合并数据等。
数据处理主要针对的是对原始数据中的缺失值进行填写、去除噪声数据等问题,例如:某些用户若干特征值缺失,如为空值时,对于缺失值采用全部填充0的方法;出现明显异常,如用电量为负数时,直接删除包含异常值的记录。对初始数据进行异常或噪声去除处理后,才能得到可供算法输入的有意义的干净的数据,保证整个算法的准确性。
由于各个指标的取值范围不一、区别太大,同时指标之间又存在不同的数量级,如果不加处理,那么在BP神经网络训练的时候,会导致网络训练时间过长,而且大量级数据会覆盖小量级数据提供的信息,从而会导致网络训练失败。因此应对用户的样本数据进行预处理,本文采用的数据处理方法为归一化数据处理。数据归一化方法为:
(2)
其中,s表示原始数据值;s*表示处理后的数据;μ表示训练数据的均值;σ表示训练数据的标准差。使得归一化处理后的用户数据服从均值为0、标准差为1的标准正态分布。
2 RBL电费拖欠混合风险预测模型
为准确预测用户电费拖欠风险,提出一种联合RF-BP-LR的混合预测算法,简称RBL。BP神经网络首先将RF筛选出的主要特征作为输入,通过网络训练得出该用户的电费缴纳信用得分值,然后将信用得分值和主要影响因素作为LR的解释变量建立一个LR的线性模型,以此对该用户的电费拖欠风险进行全方面预测。
2.1 用电客户信用评分网络模型
用户电费缴纳信用评分模型采用输入层、隐含层和输出层三层结构的BP神经网络。由RF筛选出的影响因素的数量可以确定神经网络的输入神经元个数。模型输出结果是用户的用电行为信用等级得分,因此可以确定输出神经元的个数为1。在模型训练过程中根据预测结果的好坏来对隐含层个数进行调整,经过验证,最终得到整个神经网络的结构示意图如图3所示。
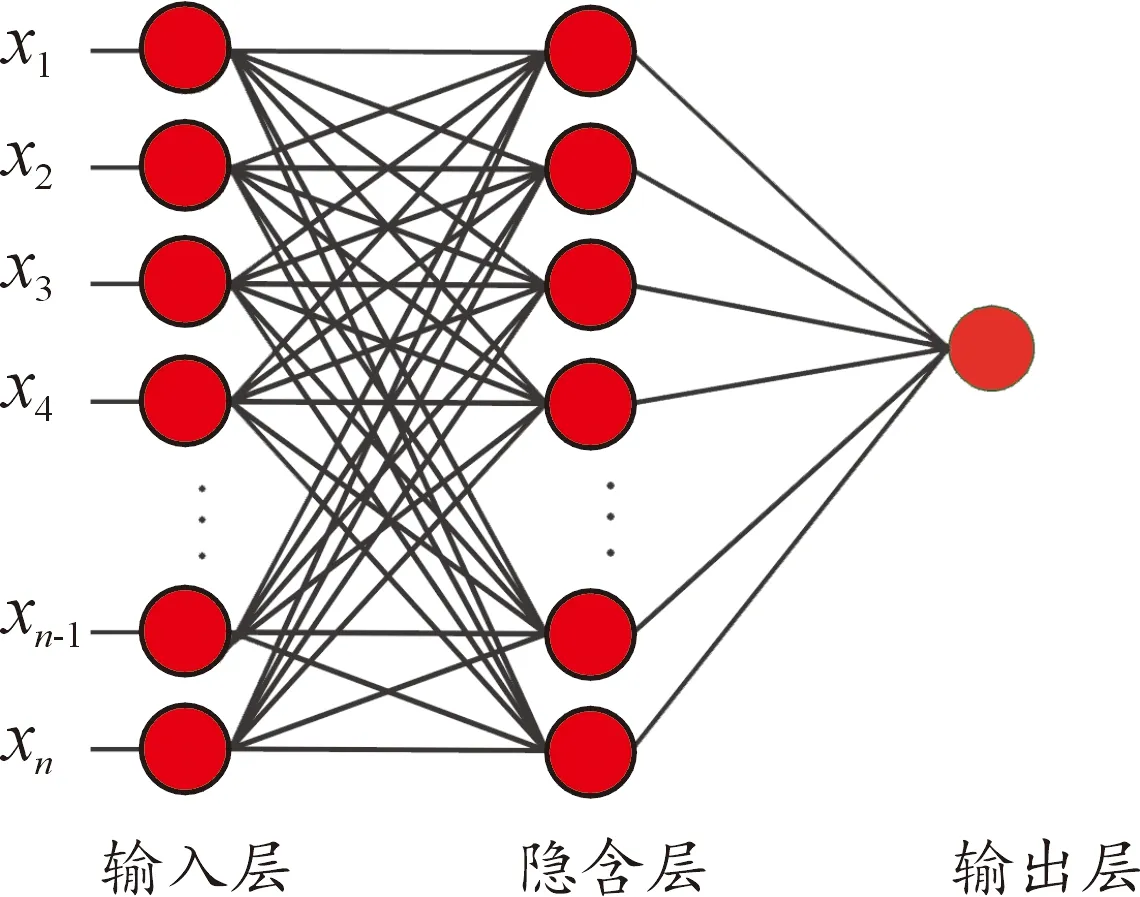
图3 用户电费缴纳信用评分的神经网络模型
BP神经网络的实现流程如下:
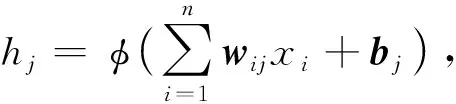

步骤3BP神经网络使用反向传播法来更新网络的权重,而反向传播法主要依赖于梯度下降法。其一般计算流程如下:
1) 输出层的更新
权重梯度可以表示为
(3)
(4)
更新:
wjk←wjk-η*hj(1-hj)ek
bk←bk-η*ek
(5)
2) 隐含层的梯度
隐含层梯度计算需要根据链式法则,由于激活函数为sigmoid函数,有
(6)
于是更新权值:
(7)
重复步骤3,直到损失值小于阈值t为止。
对用电客户进行风险预测是一个全方位的复杂的问题,通过以上推导可知,BP神经网络对输入无严格限制,并且能处理输入输出之间的非线性关系,同时误差经过不断的反向传播,参数会不断更新,使BP神经网络能推断数据之间的隐藏关系,从而使模型能准确预测未知数据,因此本文利用BP神经网络对用户电费缴纳行为进行第一阶段的信用得分预测。
8) 电力客户风险评价LR模型
LR是一种非线性的多元统计分析概率模型,该模型能解决多变量控制的结果为二分类的问题,被广泛地运用于风险预测建模分析[11]。从用电客户特征属性分析可知,影响电力客户欠费行为有多种因素,并同时影响了电力客户的信用等级。在此问题中,本文将各种影响因素作为自变量,将用户的信用等级作为因变量,从而使用LR模型对其信用等级进行预测。LR模型的表达式如下:
(8)
其中,P(Y=1|X=x)表示用户电费欠缴的概率;X∈Rn代表输入向量,其中特征数为n;w∈Rn为权重向量参数;b为偏置参数。
一般采用最大似然法计算LR的参数,计算过程中记P(Y=1|X=x)=π(x)为用户电费拖欠概率,由此计算出电费不拖欠概率为P(Y=0|X=x)=1-π(x),则相应的似然函数和对数似然函数分别为:
(9)
(10)

2.3 混合风险预警模型
根据上文对用户电费缴纳信用评分BP神经网络模型和LR模型的描述,二者均可用于数据预测领域,但仅仅使用其中一种模型进行预测,其得到的预测结果达不到预期效果[13]。因此为了更好的对用户电费缴纳信用进行评价,提高风险预测的精确度,本文使用RF进行初次特征提取后,建立基于RF的BP-LR混合预测模型,以此来对用户的电费拖欠风险进行预测,整个模型的结构如图4所示。
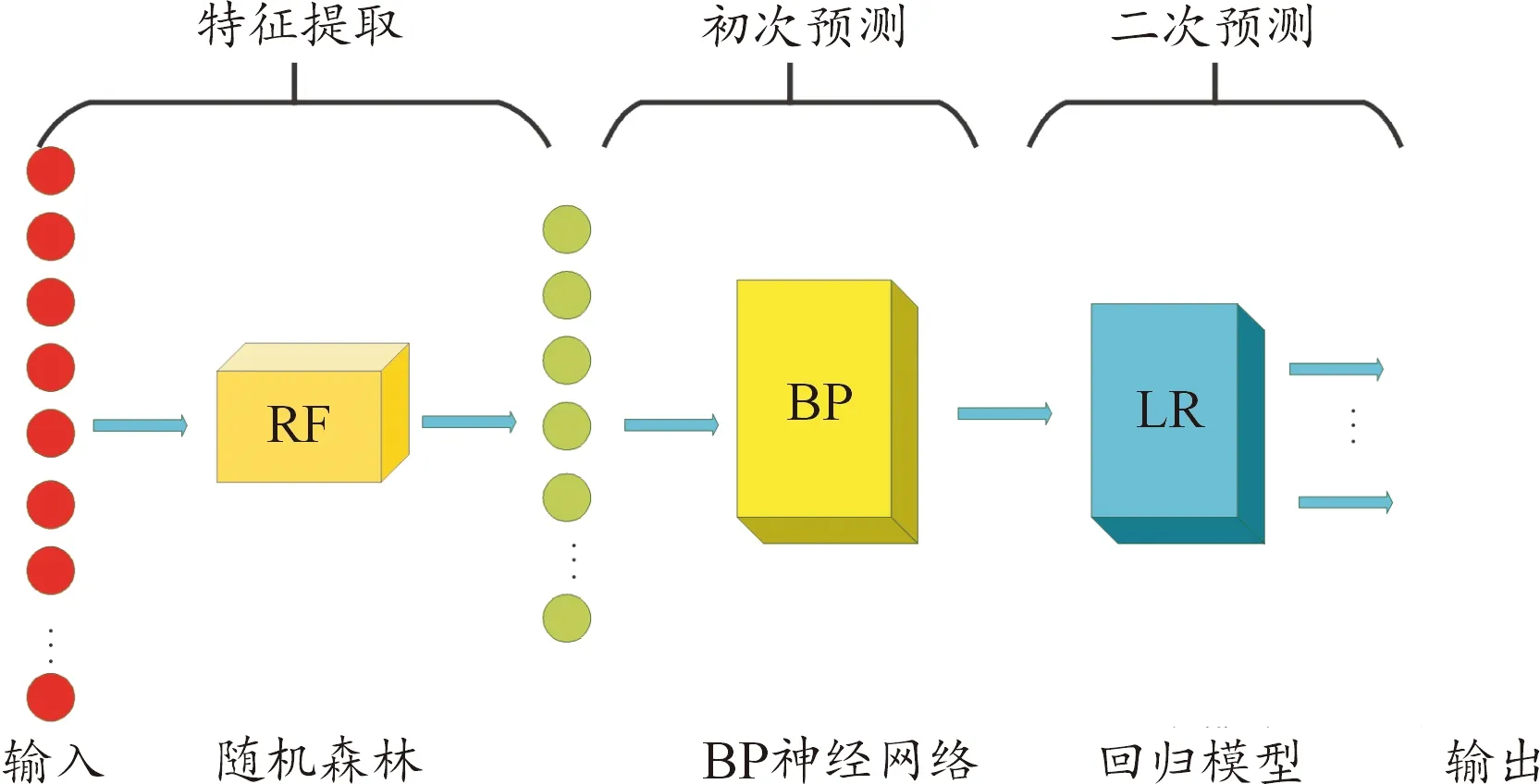
图4 基于RBL的电力用户欠费风险混合预测模型示意图
图4所示的混合预测模型,由RF特征提取模块、BP神经网络模块和LR模块组成,该网络模型包含特征提取、初次预测和二次预测三部分。使用RF对用户电费拖欠的众多影响指标中进行特征提取,筛选出主要影响指标后,将数据输入BP神经网络中训练,得到用户信用评分,最终通过LR模型预测出用户电费拖欠风险等级。
(11)
P(y|x;θ)=(hθ(x))y(1-hθ(x))1-y
(12)
似然函数表示为:
其中,y(i)表示第i个样本的类别;x(j)表示第j个样本;c为每个用户的数据样本总数。通常对式(13)进行对数变换可以得到:
(1-y(i))log(1-h(x(i)))
(14)
对l(θ)求偏导可以得到:
(15)
因此,LR模型的参数迭代公式为:
(16)
在取定了学习率α,并用迭代算法迭代收敛之后,可以得到LR模型的参数值θT,由此可以得到用电客户欠费风险的LR预测模型。
3 实验分析
用户电费欠缴风险预警主要是利用用户用电的基本情况以及历史缴费欠费行为充当数据集,基于此类信息来构建电力用户的欠费风险预警模型并进行训练,最终对各用户的欠费行为进行评估分类,得到高风险欠费用户信息,并针对此类用户采取响应措施以降低其电费欠缴或拖缴的风险。
3.1 数据集及模型训练
以某地区电力公司全部用户为样本集,基于2020年1月至2020年12月数据作为基础数据,2021年1月至3月是否拖欠电费为目标数据,进行模型训练。用户行为主要数据特征包括以下:
1) 基本信息:用户序号、行业分类、供电单位、电费计算方式、定价策略、开户时间、供电状态、合同信息、抄表周期、用户所在地址等;
2) 用电行为:用户违约次数、用户用电趋势、电费欠缴或拖缴次数和具体金额、欠费间隔、用电的类别、电费所处分类、催缴电费通知方式等;
3) 缴费行为:近1年缴费时间、缴费方式、缴费方式变更次数、缴费金额等。
对原始用户样本属性数据进行预处理后,使用RF法进行初次特征提取,计算特征提取后的用户属性特征与目标类别(是否欠缴或拖缴电费)的信息值,并进行降序排序,信息值(IV)用来衡量属性I和目标类别属性J(J为二元属性)之间相关性的指标,如表1所示,信息值的计算方式如下:
(17)
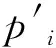
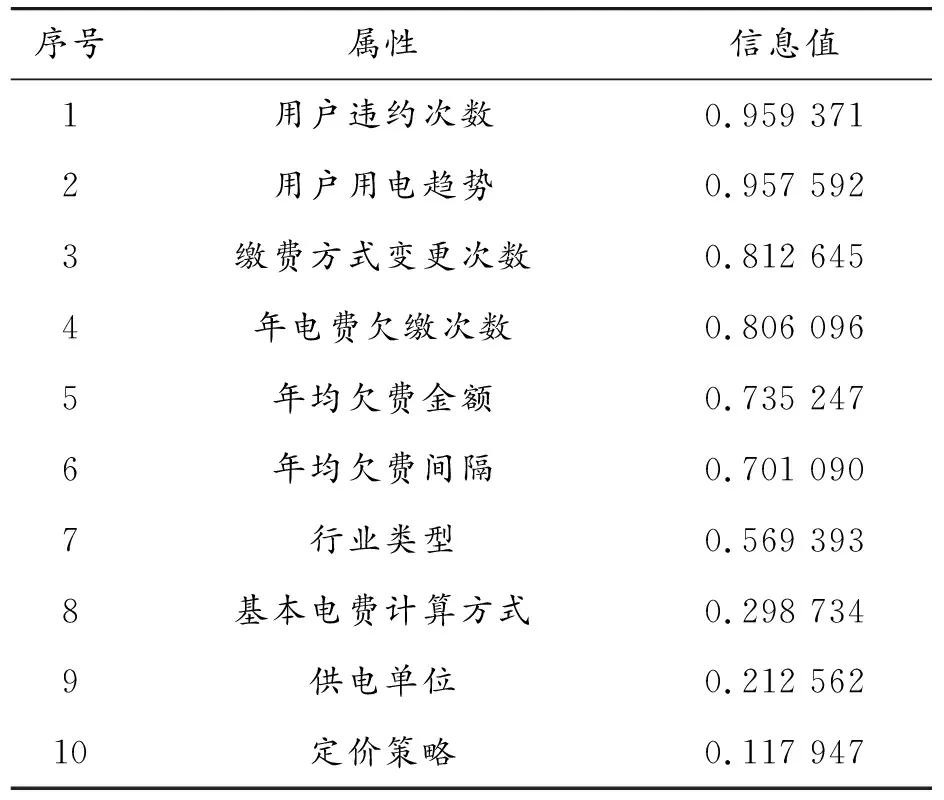
表1 特征选择中每个属性变量的信息值
一般当IV≥0.3时,说明该特征属性具有良好的预测能力,故将用户违约次数、用户用电趋势等属性选入模型中,将供电单位、定价策略等相关性不明显的属性剔除。
将经过特征提取后的数据集按照随机方式分成训练集和验证集,训练集和验证集比例为7∶3,BP神经网络参数设置[14]见表2。

表2 BP神经网络参数设置
LR模型的参数设置如表3所示。
对模型进行初始化后,开始训练模型。此次实验所使用的硬件设备为图灵(turing)架构的GeForce RTX 2080TI GPU;Intel Xeon E5-2630 V4 CPU;64GB RAM;使用Windows 10操作系统,在Python平台上的Pytorch深度学习框架完成整个训练过程。

表3 LR模型的参数设置
3.2 实验结果与分析
本文将预测精度作为各对比算法的评估指标[15],预测精度是指预测为风险用户中真正的风险用户的比例。训练过程中,本文所建立模型的预测精度以及损失值的变化曲线如图5、6所示。

图5 不同模型迭代次数与预测精确度变化曲线
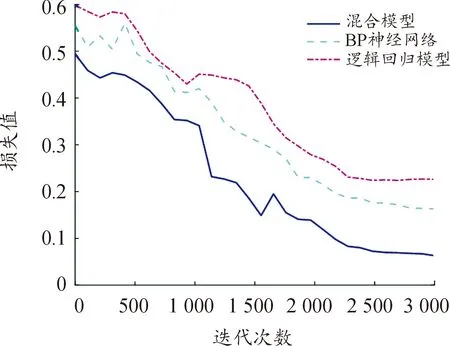
图6 不同模型迭代次数与损失值变化曲线
从图5、6中可以看出,当模型的迭代次数增加的同时,模型的预测精度在不断提高,并且损失值在不断降低。在迭代次数达到2 000次左右时,本文所建立的混合模型的预测精度和损失值在逐渐趋于平稳,而BP神经网络和LR模型在迭代次数为2 500次后才开始达到平稳,这是因为本文所提的混合预测模型,在数据输入BP神经网络模型前使用了RF进行了初次特征提取,使得模型更快收敛。在预测精度上与单个模型的结果进行了对比,从图5和图6可以看出相比于单一的BP神经网络和LR模型,本文所提的混合预测模型的预测精度更高,损失值更低。同时对比了使用决策树模型和深度信念网络的预测精度,不同模型的预测精度如表4所示。
从表4中可以看出,本文所提混合模型的预测精度可以达到92.83%,由于混合模型首先使用RF进行了一次特征提取,使用BP神经网络和LR模型进行初次和二次预测,预测精度相比单独使用BP神经网络或LR模型分别提高了2.73%和7.7%,相比决策树模型提高了6.56%,同时还对比了深度信念网络的预测精度,相比下本文混合模型具有2.34%的精度提升。总体上来看,使用本文所提的混合模型对用电客户电费拖欠风险的预测精度更高,收敛速度更快。
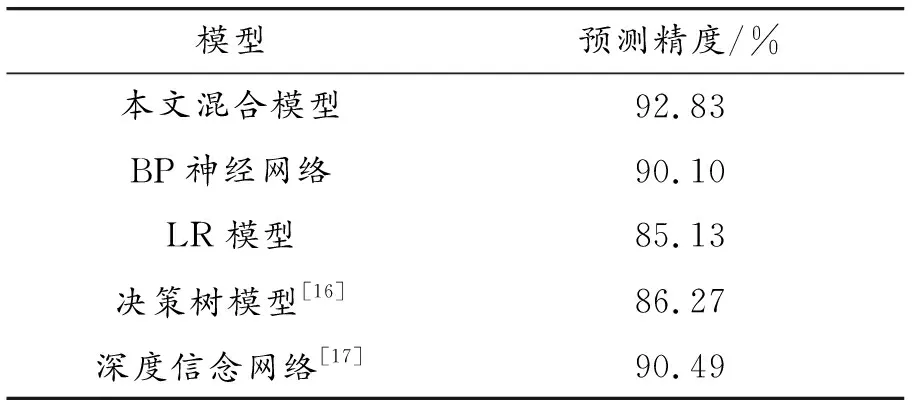
表4 不同模型的预测精度
基于所提的电力客户欠费混合风险预警算法风险预测混淆矩阵元素如表5所示。混淆矩阵的横坐标为原用电欠费风险客户,纵坐标为预测出来的用电欠费风险客户,可以看出大部分电费欠缴或拖缴风险客户被预测出来了。同时在矩阵的上三角位置上不为0的数值为被偏小预测的电费欠缴或拖缴风险客户,需要对这部分客户加大审查力度,确定是否有电费欠缴或拖缴行为,用以电费欠缴或拖缴风险预警。

表5 混合模型性能评价混淆矩阵元素
根据预测结果,可以建立用电客户信用等级评价制度,对不同信用等级的用电客户及时预警,同时采取不同的措施:
1) 对于高风险用户,应当优化电卡表系统以及多应用一些远程集抄控制设备,争取做到优先抄表,同时必须严格核实用户的基本信息,最好做到将先用电后缴费模式转变成先缴费后用电的模式,严格实现交多少费用多少度电。
2) 对于中风险用户,丰富电费欠费的通知途径,比如除了派送电量电费通知单,还尽量做到直接当面通知用户,多和此类用户交流,一旦发现有欠费行为能做到及时提醒。
3) 对于低风险用户,此类用户信誉较高,因此平时只要维护好电费管控系统,建立科学完善的内部信息系统,必要时候可以通过电话等方式通知用户缴费,并丰富用电客户的缴费方式,方便客户缴费,大幅度减少这类客户的欠费行为。
4 结论
在对用电客户电费拖欠风险的预测研究中,对电力企业对用户电费管理模式进行了分析,阐述了建立电费拖欠风险预警模型的重要性,同时分析了现有研究成果存在的问题和不足。为了更好地建立风险预警模型,首先使用RF算法提取关键影响因素,建立基于BP神经网络的用户电费欠缴或拖缴信用得分模型进行初次预测,为了提高用户电费欠缴或拖缴风险的预测精度,采用LR模型进行二次预测,从而对电力用户电费拖欠行为进行有效预警。实验结果表明,本文所提的基于RBL电力客户电费拖欠风险混合预测模型预测精度可以达到92.83%,损失值在0.1左右,相比单独使用BP神经网络或LR模型分别提高了2.73%和7.7%,同时对比决策树模型和深度信念网络,预测精度分别有6.56%和2.34%的提升。本文所提算法可对用户电费拖欠风险进行有效预警,帮助供电企业快速关注高风险用户,减少经济损失,从而提高面向企业用电客户缴费风险管理能力。
