基于PSOGA-BP的混合动力汽车非稳态工况声品质评价
2022-06-18廖连莹潘继郭赵景波左言言廖旭晖孟浩东
廖连莹,潘继郭,赵景波,左言言,廖旭晖,孟浩东
(1.常州工学院 汽车工程学院, 江苏 常州 213032;2.江苏大学 振动噪声研究所, 江苏 镇江 212013)
0 引言
混合动力汽车(hybrid electric vehicle,HEV)较传统内燃机汽车,其车内噪声总体水平有所下降,但乘客对HEV车内声品质的感受并没有明显改善[1]。在某些非稳态工况下,HEV所产生的振动和噪声,甚至会让乘客感到更不舒服。因此分析HEV非稳态工况下的车内声品质特点,找出影响HEV车内声品质的关键因素,并采取相应的改进措施,从而提升HEV的乘坐舒适性显得尤其重要。对于车内声品质的研究,大量学者从主观评价方法、客观评价模型和应用上进行了探究。如Gauthier等[2]分别利用最小绝对收缩和选择算子(LASSO),弹性网络和逐步回归3种算法构建了声品质预测模型。通过比较,得到LASSO算法因具备有效控制评价参数数量,具有最准确的预测结果和便于构建评价模型等优点,在3种算法中成为最适合建立声品质预测模型的一种算法。Duvigneau等[3]利用虚拟仿真的方法,建立了发动机声品质评价模型。高印寒针对汽车稳态和非稳态工况下,利用GA-BP神经网络和RBF神经网络等方法建立内燃机汽车车内声品质评价模型,取得了较好的评价效果[4-5]。徐中明等[6-7]利用粒子群-向量机同样对内燃机汽车加速工况声品质进行了研究,利用小波熵对汽车关门非稳态声品质进行了分析,验证了小波熵更能准确表征非稳态声信号的时频特性。朱仝等[8]利用遗传算法优化的支持向量回归方法对车内稳态噪声进行了声品质预测,提高了声品质模型的预测精度。黄海波等[9-11]用Adaboost算法,利用深度信念神经网络和GA-小波神经网络,建立了车内声品质评价模型,对内燃机汽车匀速工况车内声品质进行了预测,提升了车内声品质预测精度。赵向阳等[12]利用FELMS算法,对内燃机汽车匀速工况进行了声品质研究,提高了车辆稳态工况声品质预测精度。左言言等[13-15]对车辆声品质进行主客观综合评价,依据心理声学参数对声品质的影响程度,利用LSSVM和神经网络方法建立声品质评价模型,选择稳态工况对HEV车内声品质进行了预测,取得较好的评价效果。
从以上分析可以看出,既往对声品质的研究主要关注传统内燃机汽车或者新能源汽车的稳态工况下的声品质评价,针对HEV非稳态工况这种特殊工况的车内声品质评价研究较少,所建立的评价模型是否适用于HEV非稳态工况声品质评价还有待验证。本文针对混合动力汽车原地热机、缓加速、急加速、紧急制动、缓减速、滑行和变工况等非稳态工况,利用参考语义细分法进行主观评价试验。计算非稳态工况声品质客观参数,并进行相关分析。建立利用粒子群算法(PSO)和遗传算法(GA)优化的BP神经网络声品质客观评价模型。通过误差对比,证明PSOGA-BP模型更适合进行HEV非稳态工况车内声品质评价。
1 HEV车内噪声样本采集与处理
1.1 试验设备
本次试验选择某汽车公司的混联式HEV车辆作为试验用车。选用SQuadriga I便携式声音分析仪,用于采集车内噪声,为车内噪声特性分析及车内声品质分析提供必要数据。选用汽车检测仪AllScanner,通过与OBD-Ⅱ接口连接工作后,采集反映车辆运行状态的各参数数据,如发动机转速、油门踏板深度、MG1转速及扭矩、MG2转速及扭矩、SOC值等。
1.2 传感器及安装位置
试验所用传感器主要有Head Acoustics双耳麦克风、PCB麦克风、转速传感器等。
麦克风分别安装在驾驶员、副驾驶及后排座椅乘员头部附近,分别选取如图1(a)的正驾驶右耳,如图1(b)的副驾驶右耳和如图1(c)的左后排乘客右耳3个位置为噪声采样点。

图1 麦克风车内布置图
1.3 试验工况
本次试验测试工况包括了HEV原地热机、缓加速、急加速、急减速、缓减速、滑行和变工况等大部分非稳态工况:
1) 原地热机。分发动机低怠速和高怠速。
2) 缓加速。控制油门踏板开度小于50%,从车辆静止加速到120 km/h。
3) 急加速。完全踩下油门踏板,从车辆静止加速到120 km/h。
4) 急减速。完全踩下制动踏板,速度从120 km/h减到车辆完全停止。
5) 缓减速。轻踩制动踏板,速度从120 km/h减速到60 km/h。
6) 滑行。既不踩油门踏板,又不踩制动踏板,车辆利用惯性进行滑行,从速度120 km/h减速到40 km/h。
7) 变工况。在20~60 km/h速度区间,短时间内,进行加速、减速、滑行等各工况的迅速转换。
1.4 数据采集
试验参照ECE R51和GB/T 18697—2002进行,采样频率为44.1 kHz,噪声样本信号长度为30 s。试验路段选择郊区开阔地,周边30 m内无声音反射物。分别采集试验车辆在不同工况时噪声样本,每个工况测试2组数据。通过筛选,选择测试效果较好的20组噪声样本作为后续分析样本,并对20个样本进行5 s长度的截取,组成新噪声样本,总共28组,最终共得到84个噪声样本。
2 声品质主观评价
2.1 评价试验实施
声品质主观评价方法有排序法、等级打分法、成对比较法、语义细分法、参考语义细分法等[16]。这些评价方法各有优缺点,其中参考语义细分法是在语义细分法的基础上优化而来,其优点之一就是适合样本数较多的主观评价试验,本次HEV非稳态工况声品质主观评价试验即采用此方法进行。试验选取15号样本,即从65 km/h加速到100 km/h行驶工况下左后排乘客右耳处噪声作为参考声样本。采用5级语义细分评价法,当评价噪声样本与参考声样本一样好时赋值为3分,比较好时赋值4分,好得多时赋值5分,较差时赋值2分,差得多时赋值1分。
本次主观评价试验人员选择,在考虑统计学和听音经验的基础上,以及考虑HEV使用群体主要为年轻人的特点,选择了20~40岁之间具有驾驶经验和一定声学基础的人员共计24名,男女比例3∶1。
通过24位评价者,利用参考语义细分法分别对84个噪声样本进行评分,从评价结果来看,所有评价者评分都使用了满刻度评分,即最低分打1分,最高分打5分。因评价者采用的刻度范围一致,因此可以对评价结果直接进行统计分析。利用几何平均法对评价结果进行处理后,得到84个噪声样本的主观评价值如表1所示。
2.2 试验数据可靠性分析
根据参考语义细分法评价结果的特征,正确可信度高的评价者的评价结果间存在较大的相关性。为检验声品质主观评价结果的有效性,计算了所有评价者评价结果几何平均与各评价者评价结果的相关系数,如表2所示。

表1 所有评价者主观评价结果

表2 主观评价结果相关系数
为使评价结果一致性相对较高,相关系数应达到0.7~0.8以上。从表2可以看出,TP3、TP12、TP14和TP21 4位评价者的相关系数小于0.7,给以剔除,剔除后剩余20位评价者。对20位评价者的主观评价结果再次进行几何平均计算,得到84个噪声样本的最终主观评价值。
2.3 评价结果分析
为便于对声品质进行评价,使用式(1)对以上声品质主观评测结果进行归一化:
(1)
式中:X*为归一化后的各声音样本分值;Xi为各声音样本主观评价分值;Xmin为所有声音样本主观评价最小分值;Xmax为所有声音样本主观评价最大分值。各声音样本主观评价分值如表3所示。

表3 声音样本主观评价得分
3 客观参数计算及相关性分析
3.1 客观参数计算
声品质客观参数是声品质客观评价的基础,本试验选择响度、音调度、AI指数、波动度、粗糙度、尖锐度、A声压级和声压级8个客观参数,对84个噪声样本根据各客观参数计算模型进行计算,得到表4所示的客观参数值。
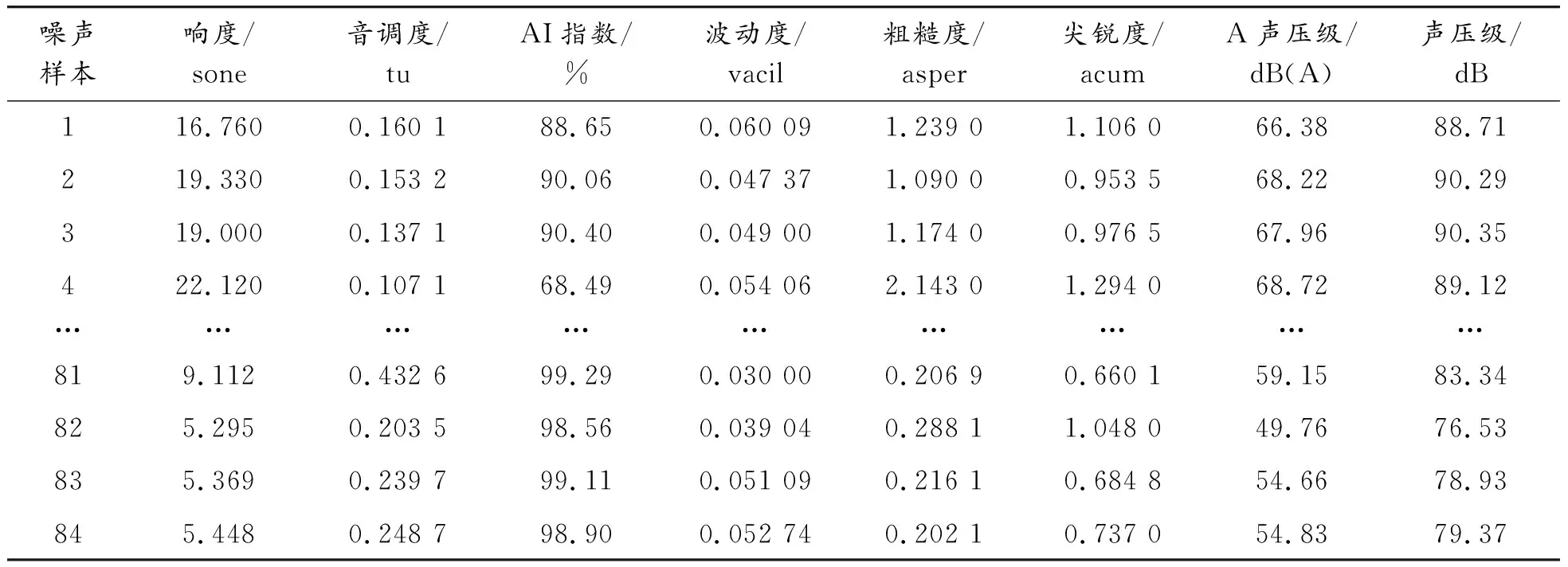
表4 声品质客观参数值
3.2 相关分析
为确定客观参数与主观评价结果之间的关系,利用Matlab软件对两者之间进行相关分析。同时对不同工况下主观评价结果与客观参数相关性也进行了计算分析,分析结果显示急减速工况是个特殊的工况,其主观评价结果与响度、AI指数、粗糙度、A声压级和声压级的相关性与其他工况的相关性呈相反状态。在实际驾驶车辆时,急减速工况出现的概率较低,仅在紧急情况下才会发生,因此在研究HEV声品质评价时,剔除急减速工况声样本。对剩余的78个声样本重新进行相关性分析,得到表5所示的结果。

表5 主观评价值与客观参数的相关系数
从表5可以看出,整个非稳态工况主观评价结果与客观参数的相关性都不高,但除了音调度外,其他客观参数在0.01水平上显著相关。考虑到声压级的相关性较低,因此在后续客观评价模型建立时,只选择响度、AI指数、波动度、粗糙度、尖锐度和A声压级6种客观参数进行建模。
4 PSOGA-BP预测模型建立
4.1 粒子群算法
通过评价者对混合动力汽车车内声品质进行评价,过程非常复杂,费时费力,评价结果受多种因素影响,因此建立一种声品质评价模型对声品质进行评价是一种不错的选择。考虑人耳对声音感受,以及HEV非稳态工况声品质均呈非线性,因此本文采用神经网络对声品质进行预测。为使HEV声品质预测模型精度进一步提高,同时避免遗传算法(GA)算法收敛速度慢的缺点,在GA-BP模型的基础上,引入收敛速度快的粒子群算法(PSO),组成PSOGA混合算法,可以克服单种算法的局限性,实现优势互补。PSOGA算法具有更好的全局搜索最优解的能力,在适应度、收敛速度和预测精度上体现较大优势,从而提高了算法的综合性能。
PSO属于全局随机搜索算法,通过一群粒子在空间里不断调整自身位置Xi和速度Vi来搜寻最优解。在这过程中,每个粒子可以寻得到一个最优解,这个解叫作个体极值,用Pbest表示。将Pbest与其他粒子共享,把整个粒子群中最优的Pbest作为全局最优解,称为全局极值,用Gbest表示。粒子群中的个体粒子再根据Pbest和Gbest调整Xi和Vi来得到全局最优解[17-18]。
其中Xi和Vi的调整公式为
Xi+1=Xi+Vi+1
(2)
Vi+1=wVi+c1r1(Pbest-Xi)+c2r2(Gbest-Xi)
(3)
式中:w表示惯性权重因子;c1和c2表示学习因子,取值[0,2];r1和r2表示随机数,取值[0,1]。
PSO算法全过程为:粒子群初始化,粒子适应度计算,寻找Pbest,寻找Gbest,更新粒子的Xi和Vi,输出最终全局最优解。
4.2 PSOGA-BP网络建立
建立的PSOGA-BP网络流程步骤如下:
1) 首先确定BP网络结构。为了便于把预测结果与BP和GA-BP神经网络模型进行比较,此预测模型的BP网络结构选择与它们一致,确定为6-6-1结构。即把响度、AI指数、波动度、粗糙度、尖锐度、A声压级6个参数作为输入层的6个节点,隐含层选择6个节点,输出层为声品质预测结果1个节点,如图2所示。

图2 BP神经网络声品质预测模型结构示意图
2) 初始化网络及初始化粒子群,确定各参数值:染色体长度为49;种群规模为40;最大进化代数为200;交叉概率为0.8;变异概率为0.07;最大惯性权重因子为0.9;最小惯性权值因子为0.4;学习因子为2。
3) 通过计算适应度函数,搜索Pbest和Gbest,按规则对粒子群的Xi和Vi进行更新。
4) 进行粒子群的交叉操作。
选择适应度值较好的粒子,按照设定的概率,利用式(4)和式(5)位置交叉算子和速度交叉算子对第i个粒子速度和位置与第j个粒子速度和位置进行交叉,对适应度较优的粒子重新放回粒子群进行下一步操作。

(4)

(5)
式中:α和β表示[0,1]之间的随机数。
5) 进行粒子群的变异操作。
按照设定的概率选择适应度值较差的粒子,分别根据式(6)和(7)的位置变异和速度变异算子,对粒子的位置和速度进行变异操作,将变异后的粒子重新放回粒子群。

(6)
(7)
式中:f(g)=r3(1-ei/emax),ei为当前迭代次数,emax为最大迭代次数,r1,r2,r3均为[0,1]之间随机数。
6) 更新Pbest和Gbest。
7) 判断PSOGA迭代运算是否满足结束条件,满足则输出最优权值和阈值,否则返回继续对种群进行初始化。
8) BP神经网络权值阈值更新。
9) 判断BP神经网络训练是否达到结束条件,如果不满足,返回重新进行权值阈值调整,并进行训练;如果满足,则训练结束。
PSOGA-BP算法流程如图3表示。

图3 PSOGA-BP算法流程框图
4.3 声品质评价
利用图3所示的PSOGA-BP算法,进行混合动力汽车声品质客观评价。选取归一化处理的78个噪声样本中的70个噪声样本,实现对网络的训练,训练结果如表6所示。
将剩余8个声样本的6种客观参量,导入建立的PSOGA-BP神经网络评价模型中,计算得到此8个声样本的声品质客观评价值及误差,如表7所示。
从表7可以看出,PSOGA-BP声品质预测模型的预测结果与主观测试结果较为吻合,误差较小,说明PSOGA-BP预测模型可较精确地对HEV车内声品质进行预测。
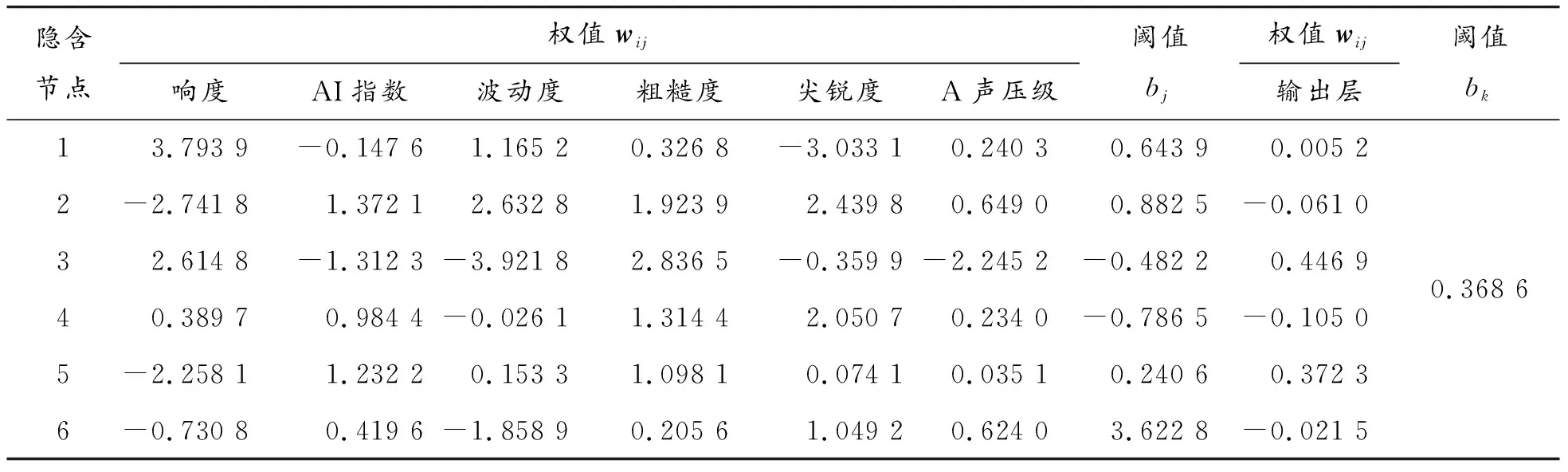
表6 PSOGA-BP神经网络声品质预测模型权值与阈值
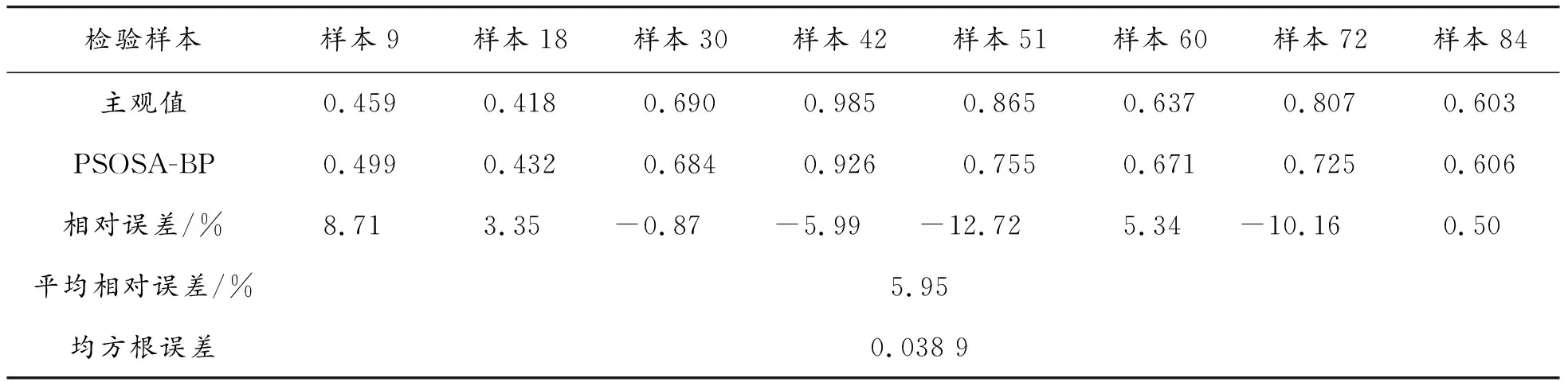
表7 PSOGA-BP声品质预测模型预测结果
5 声品质预测结果精度对比分析
为了验证PSOGA-BP声品质预测模型的效果,把预测的8个声样本的声品质结果与BP神经网络模型、GA-BP神经网络模型进行比较,利用折线图对预测结果进行显示,如图4所示。
由图4可以看出,3种声品质预测模型的8个噪声样本的预测结果均较接近于主观评价值,其中PSOGA-BP声品质客观评价模型,除样本51外,其他样本的预测值更加接近主观评价值。为进一步验证PSOGA-BP声品质预测模型的精确度,把模型预测误差分别与GA-BP和BP模型进行对比,如图5所示。

图4 声品质预测模型预测值曲线
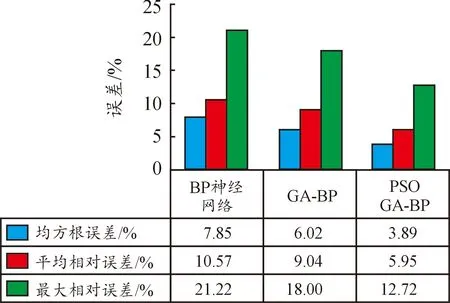
图5 不同声品质评价模型预测误差直方图
从图5可以看出,利用普通BP神经网络对HEV车内声品质的预测误差较大,最大达到21.22%。使用遗传算法和粒子群算法优化遗传算法的GA-BP和PSOGA-BP模型进行HEV声品质预测后,无论均方根误差、平均相对误差还是最大相对误差都有所下降。特别是PSOGA-BP模型的均方根误差仅有3.89%,最大误差也只有12.72%。对BP神经网络进行优化后的PSOGA-BP模型结合了粒子群优化和遗传算法优点,能显著提高预测结果的精度,说明该模型适合运用于HEV车内声品质预测。
6 结论
1) 选择原地热机、缓加速、急加速、紧急制动、缓减速、滑行和变工况等涵盖HEV大部分非稳态工况,进行了车内噪声测试。采用参考语义细分法,较全面地评价了非稳态工况HEV车内声品质。评价结果表明HEV车内声品质与车辆运行工况紧密相关。
2) 结合遗传算法和粒子群算法,建立了PSOGA-BP神经网络声品质预测模型,预测结果显示,均方根误差仅为3.89%,平均相对误差降到5.95%,最大误差只有12.72%,优于对比模型。说明PSOGA-BP神经网络声品质预测模型较适合用于非稳态工况下的HEV车内声品质预测。
