基于CEEMD和GWO-SVR的铣削振动信号前瞻预测
2022-06-17张轩瑞刘献礼
吴 石, 张轩瑞, 刘献礼
(哈尔滨理工大学 先进制造智能化技术教育部重点实验室,哈尔滨 150080)
汽车车身构件日益复杂,相应淬硬钢模具存在大量的凸凹、沟槽等结构,为克服模具加工制造和装配中存在的这种结构性困难,多采用镶块式拼接模件。在模具整体铣削加工过程中,由于在拼接处存在硬度差,铣削振动变化大,产生的冲击振动会在短期内导致刀具磨损加剧,模具表面加工质量下降等。如果能准确地预测模具拼接区的铣削振动趋势,通过快速改变铣削参数进行前瞻控制,有利于在拼接处减小铣削力的瞬时突变,减少冲击振动对模具加工精度和产品质量的影响[1]。
在拼接模具整体铣削加工过程中,由于加工工况和切削环境复杂,测得的铣削振动信号中存在干扰信息和较强的非平稳特征[2],这些干扰信息的存在会严重影响铣削振动信号预测的精准度,因此需要对振动数据进行预处理以提高振动信号前瞻预测的准确性。
目前时频分析方法是分析非平稳和非线性信号的最常用的方法,如小波分析法、Hilbert-Huang变换等[3]。小波变换应用过程具有局限性,其基函数和分解层数的选取缺乏自适应性[4]。经验模态分解(empirial mode decomposition,EMD)方法是一种瞬时信号处理方法,避免了选取小波基函数的弊端,能够实现非平稳信号的分解并滤除噪声干扰,EMD方法以Hilbert变换为基础,将瞬时频域具有物理意义的信号定义为固有模态函数(intrinsic mode function, IMF),在非平稳信号处理领域得到应用[5-6]。由于EMD分解方法存在模态混叠现象,因此Wu和Huang提出了集合经验模态分方法(emsemble empirial mode decomposition, EEMD),有效地抑制了信号分解过程中局部极值在短时间内的频繁跳动[7]。
铣削振动信号预测常采用线性时间序列的预测方法[8-11],但在实际切削环境中,机床、刀具和工件使铣削呈现典型的非线性特征,因此铣削振动信号的非线性时间序列预测方法得到了迅速发展[12]。对于非线性时间序列预测,人工神经网络(artificial neuron network, ANN)的特殊性在于其本身处理数据时具有自学习能力,而且对于非线性数据的预测能力强,然而ANN算法在操作中会出现一些问题[13],如收敛速度慢、难以确定网络结构和局部最优等。支持向量机[14]是一种基于统计学习理论的学习算法,它的优势主要是在小样本、少信息、非线性及高维空间模式识别中,克服了人工神经网络极易陷于局部极小和过度拟合的问题[15],而且对于小样本数据分析来说,支持向量机拥有良好的学习能力和推广能力,被广泛应用于铣削颤振识别[16-17]、粗糙度预测[18]和铣削力预测[19]中,已经成为研究者用于解决非线性时间序列预测的一种重要工具。
本文提出了一种基于互补式集成经验模态分解方法和支持向量机回归结合灰狼群算法的振动信号预测模型(CEEMD-GWO-SVR模型),一方面通过加入正负白噪声的方式减少模态混叠对于振动信号EMD分解的影响,提高模态分量的平稳性;另一方面基于修正的GWO算法寻找支持向量回归机参数的最优解,总体上提高拼接处铣削振动信号预测的精准度。
1 模具拼接缝铣削振动信号的CEEMD分解
1.1 模具拼接区铣削试验
若要进行拼接区铣削信号的CEEMD分解和前瞻预测试验,需采集真实的铣削振动信号进行后续的试验。
铣削试验布置如图1所示,试验用的机床为 VDL-1000E型三轴立式加工中心,刀具为戴杰二刃整体硬质合金球头立铣刀(DV-OCSB2100-L140);工件材料为淬硬状态下模具钢(Cr12MoV),工件尺寸为200 mm×200 mm×60 mm,分成3个镶块,硬度分别通过不同的热处理工艺调至45HRC、50HRC、45HRC,通过2根长度为200 mm的不锈钢高强度铰制孔用螺栓连接为一个整体,拼接缝隙为0.2 mm。曲面淬硬钢模具铣削采用小切深,小行距和小进给的切削参数,加工参数如表1所示。

表1 试验用刀具参数及切削用量Tab.1 Test tool parameters and cutting parameters
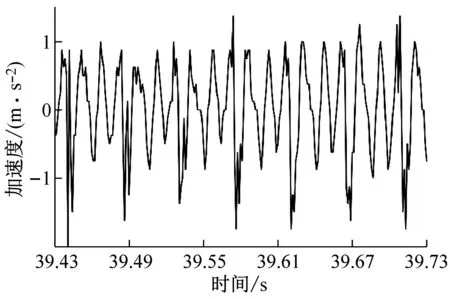
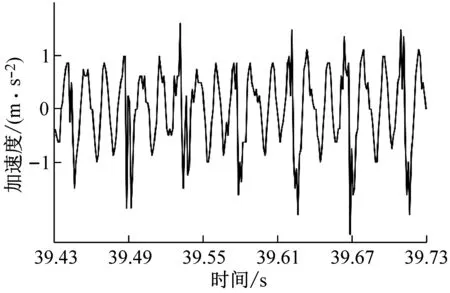
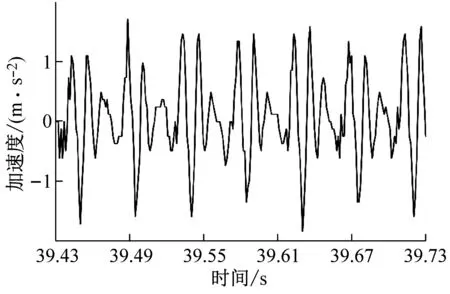
铣削试验时,从硬度为45 HRC的镶块向硬度为50 HRC的镶块进行铣削加工,铣削采用顺铣切削,共计完成9组试验。每组试验时均通过加速度传感器、数据采集系统测试工件的X、Y、Z三个分量上的振动加速度信号,采集到的铣削振动信号为动态铣削力和过缝冲击力共同激励后产生;由于Z向系统刚度较大,铣削振动信号幅值较小;X、Y两个方向的铣削振动信号幅值较大,进给方向(机床Y方向)最大,因此本文分析铣削振动信号波形时只提取X、Y两个方向的试验数据对其进行分析,过试验模具拼接缝后的铣削振动信号如图2所示。如图2所示的铣削振动信号为主轴转速n=4 000 r/min、每齿进给量fz=0.15 mm/z、径向切深分别为ae=0.1 mm、ae=0.2 mm、ae=0.3 mm和ae=0.4 mm时的四组铣削振动加速度试验数据,数据时序为铣削试验过程中的39.43~39.73 s。
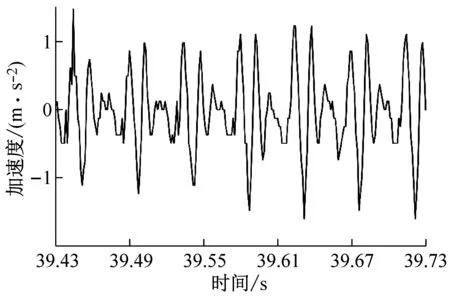
(a) ae=0.1 mm时工件X、Y两个方向加速度信号试验数据

(b) ae=0.2 mm时工件X、Y两个方向加速度信号试验数据
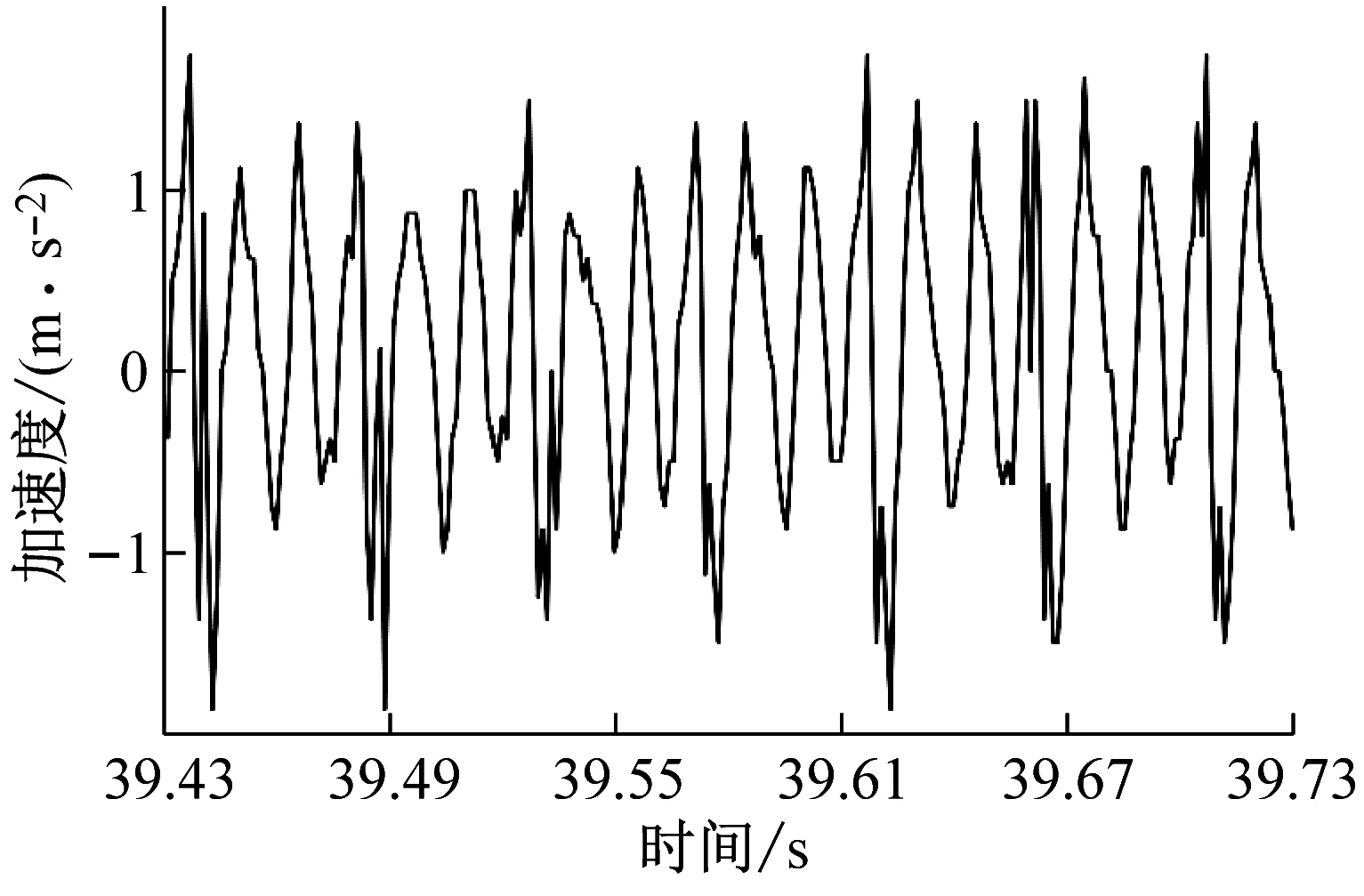
(c) ae=0.3 mm时工件X、Y两个方向加速度信号试验数据

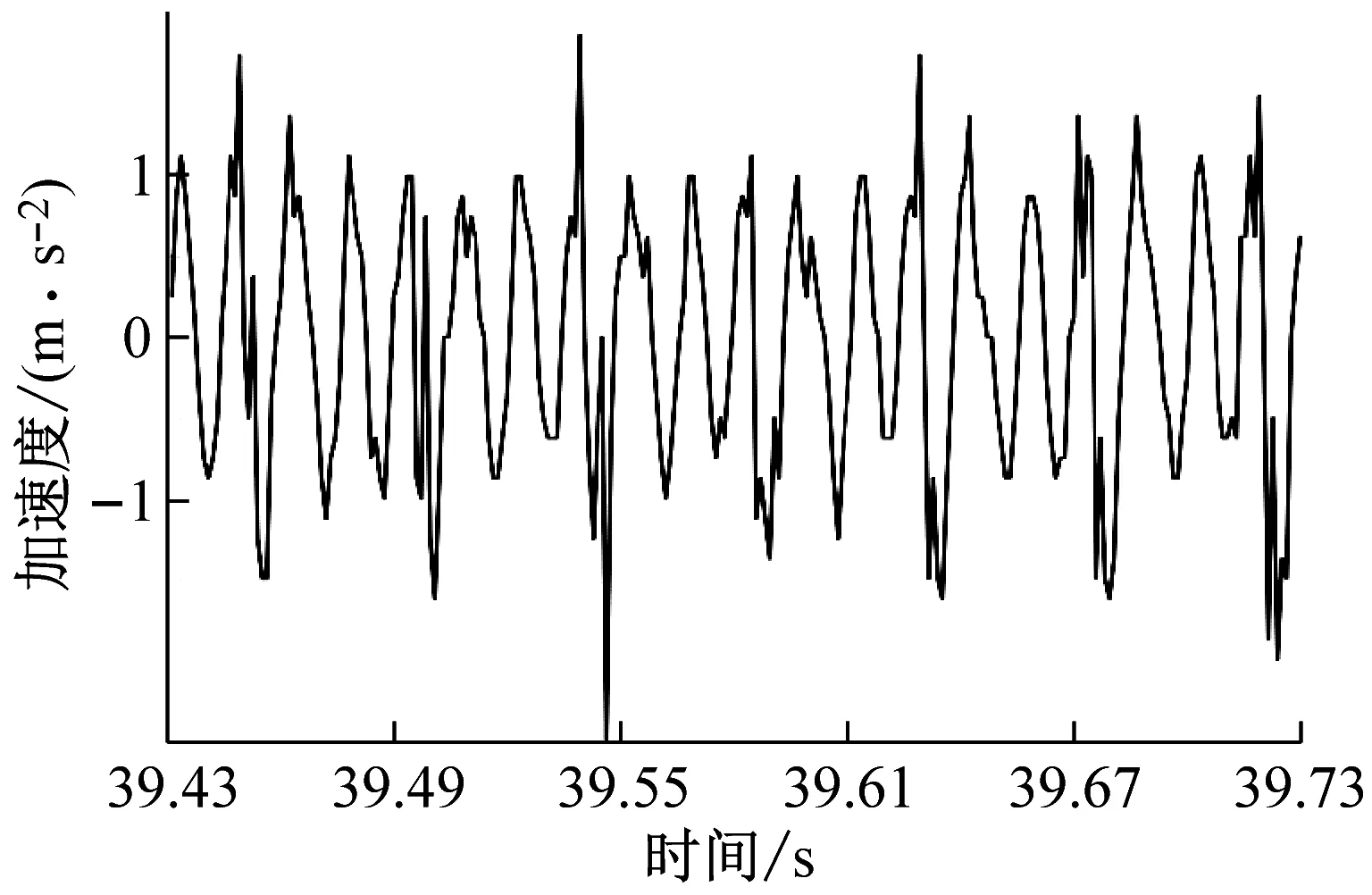
(d) ae=0.4 mm时工件X、Y两个方向加速度信号试验数据图2 不同变切深下的振动加速度信号图Fig.2 Vibration acceleration signal diagram under different variable depths of cut
1.2 基于CEEMD的铣削振动信号分解
过拼接缝后的铣削振动信号中存在有干扰信息,同时在铣削加工过程中的振动信号具有较强的非平稳特征,这些干扰信息对准确预测拼接缝振动信号会产生较大影响,所以需要对数据进行预处理。
EMD算法是一种自适应式时频域信号分解方法,相对于传统信号分解模型,EMD展现出了适应强的特性,EMD将一组信号分解成了若干个固有模态分量和一个残余项,公式如下
(1)
式中:x(t)是原始信号;m是IMF个数;ci(t)是第i个IMF分量;rm(t)是残余项。
但是EMD算法存在模态混叠问题,针对模态混叠问题,出现了EEMD算法来解决模态混叠问题,EEMD算法是在EMD分解的每一步骤中分别加入等幅的白噪声,但加入的白噪声会产生信息干扰,Yeh等[20]提出了CEEMD算法,CEEMD算法在信号中加入了N对相反噪声,然后分解加入噪声的新信号,最后得到不同的IMF分量,从而进行分解,如图3所示。CEEMD算法具体步骤如下
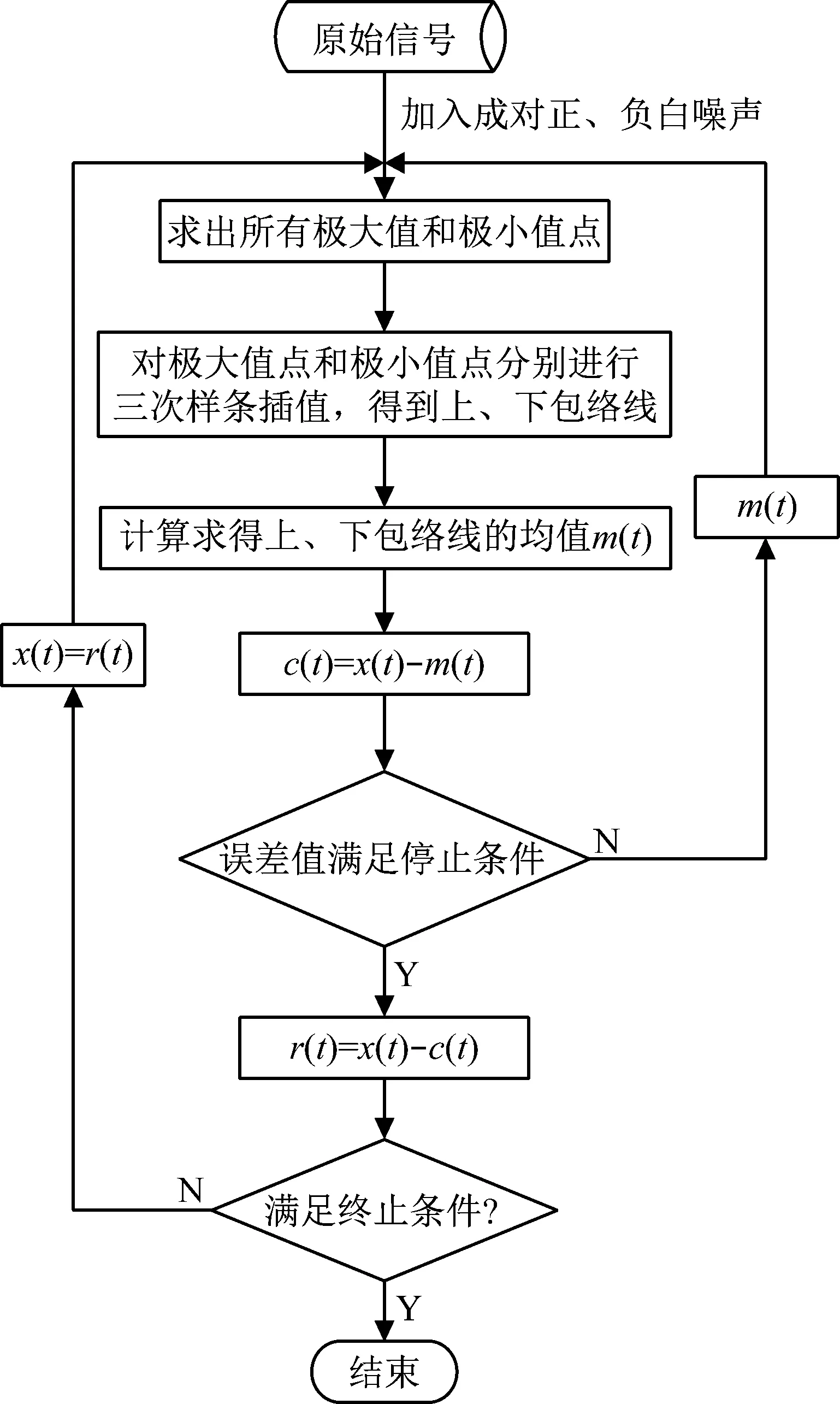
图3 CEEMD原理流程图Fig.3 Flow chart of CEEMD working principle
(1) 将一组符号相反的噪声加入到目标信号中,每组噪声的幅值相同,然后产生一对新信号
(2)
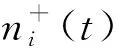
(2) 分解新信号,得到两组含有白噪声的信号分量IMF1和IMF2,且这两组分量正负互补。
(3) 将两组信号的IMF分量进行整合得到最终的IMF分量。
对加速度信号进行CEEMD分解之前,为了避免试验数据出现饱和现象,对试验数据进行归一化处理,使其样本数值处于[0,1]之间。
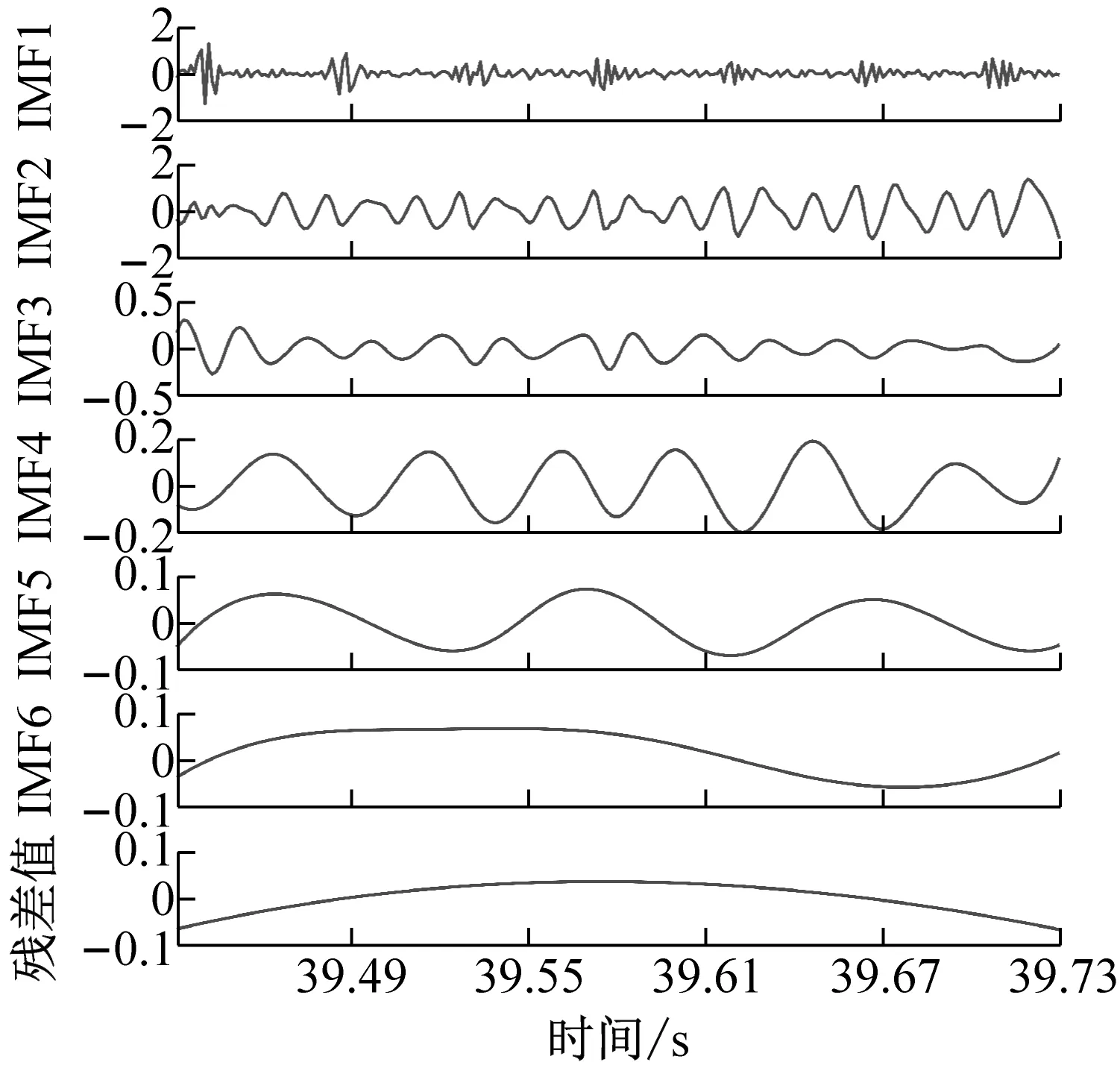
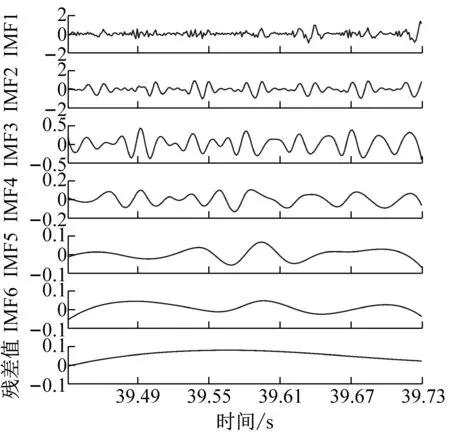
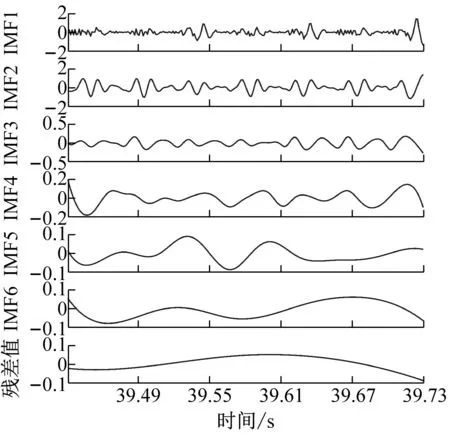
为了获得前瞻预测试验中所需输入源信号,对铣削振动加速度信号进行CEEMD分解,得到5个频域稳定的固有模态分量IMF1-IMF5和一个剩余分量Res的波形图,不同工况下的CEEMD分解如图4所示。
从图4中可以看出,分解后IMF分量图与处理前的铣削振动加速度信号相比,IMF分量图的波动变化较为平稳,频谱特征由分量从高频到低频依次表征出来。该方法将原有不平稳的铣削振动加速度信号分解成了多个平稳子序列,保存了处理前的信号特征,又可以将平稳的信号序列输入到支持向量机中,能够最大程度上学习和训练数据集。
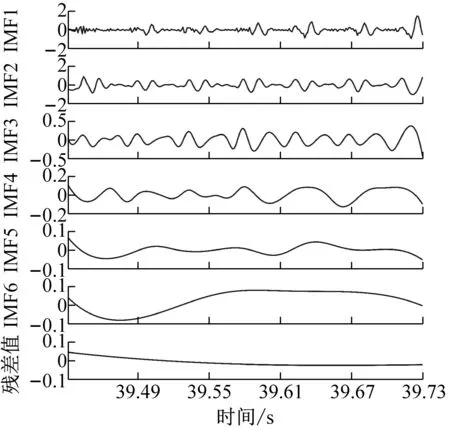
(a) ae=0.1 mm时工件X、Y两个方向加速度信号CEEMD分解图

(b) ae=0.2 mm时工件X、Y两个方向加速度信号CEEMD分解图

(c) ae=0.3 mm时工件X、Y两个方向加速度信号CEEMD分解图

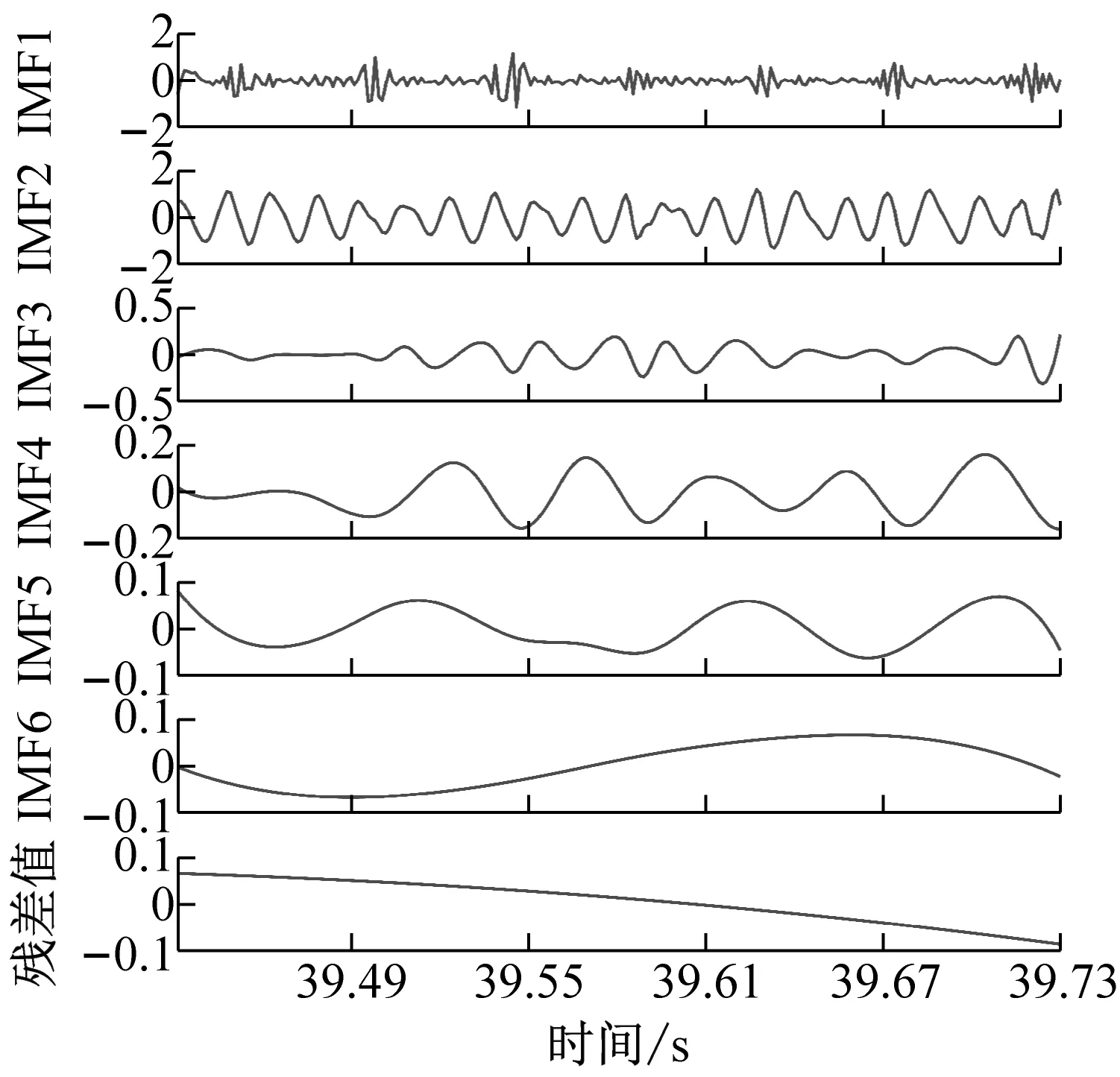
(d) ae=0.4 mm时工件X、Y两个方向加速度信号CEEMD分解图图4 不同变切深下的振动数据CEEMD分解图Fig.4 CEEMD decomposition diagram of vibration data under different variable depths of cut
2 支持向量机回归方法
基于支持向量机的数据回归算法与分类算法相似,都是以结构风险最小化原则进行求解。本文基于改进的支持向量回归方法预测铣削振动数据的发展趋势。支持向量回归(support vertor regression,SVR),它对非线性时间序列的预测较稳定,首先通过非线性函数变换φ(xi),把数据xi映射到高维特征空间,继而在高维特征空间里面,找到一个能够准确地表明输出数据及输入数据存在关系的函数f(xi),即SVR函数
f(x)=wTφ(x)+b,φ:Rn→F,w∈F
(3)
为了使实际风险达到最小的效果,根据结构风险最小化原理,优化的结构风险目标函数为
(4)

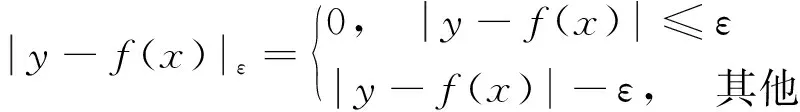
(5)
SVR即为式(4)的优化问题的求解公式
-yi+wTΦ(x)+b≤ε+ξi

(6)
(7)

(8)
利用KKT(Karush-Kuhn-Tucker)条件计算出偏差b
(9)
最后得到回归函数f(x)的表达式
(10)
式中,K(xi,x)=Φ(xi)Φ(x)为一个满足Mercer条件的核函数。此函数可以越过具体形式从而达到非线性变换的非线性化操作,这是SVR的一个显著特点。目前SVR核函数中使用最多的是带有宽度为σ的径向基核函数(RBF核函数),使用径向基核函数的SVR预测模型的预测效果要优于使用其它核函数预测模型[21],径向基核函数为
exp(-1xi-x12/2σ2)]+b
(11)
3 改进的GWO-SVR预测模型
3.1 灰狼优化算法
灰狼优化算法(gray wolf optimization, GWO)是由澳大利亚学者Mirjalili等[22]提出来的一种群智能优化算法,该算法受到了灰狼捕食猎物活动的启发,它具有收敛性能强、参数少、易实现等特点。
灰狼隶属于群居生活的犬科动物,且处于食物链的顶层。灰狼遵守着一个社会支配等级关系,群组织为金字塔结构,最顶层为α狼,具有领导地位;第2层β狼属于从属狼,可以作为α狼的候选者;第3层是δ狼,地位次β狼;最底层ω狼是所有狼群的基础。
灰狼群狩猎过程分为以下几个阶段:
(1) 追踪猎物
灰狼在狩猎过程中围绕猎物,将其行为做出以下定义
(12)
(13)

(14)
(15)

(2)包围猎物
灰狼有识别猎物的强能力,且α狼可以领导灰狼包围猎物,但在猎物(最优解)位置未知的情况下。为了模拟灰狼捕猎行为,假定α狼、β狼和δ狼了解猎物的潜在位置,保存三个最佳解决方案,并且要求其他灰狼(ω狼)作为搜索代理,根据最佳解决方案进行灰狼位置的迭代更新,公式为

(16)


(17)
(18)
式(17)代表ω狼朝三个潜在解α狼、β狼和δ狼的步长和方向;公式(18)代表ω狼的最终位置。
(3) 攻击猎物
(4) 寻找猎物
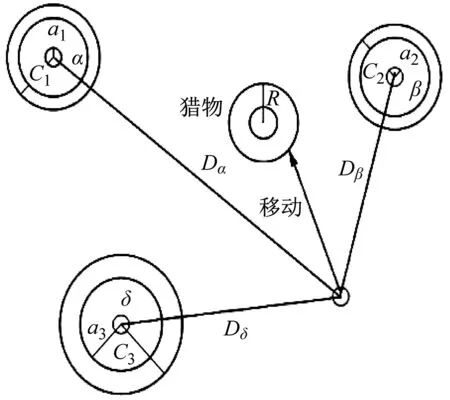
图5 狼群围捕猎物位置更新图Fig.5 An updated map of the location of wolves hunting prey
3.2 GWO-SVR模型
本文建立了基于灰狼算法优化支持向量机(GWO-SVR)的铣削振动信号预测模型,灰狼算法优化SVR过程如图6所示。该模型主要是使用GWO算法优化SVR的惩罚系数C和核函数参数g(径向基核函数参数带宽σ),通过选择全局最优参数来提高SVR的预测精准度和预测速度。同时选取了传统常见的GA算法和PSO算法进行对比,分析三种寻优算法的优劣。
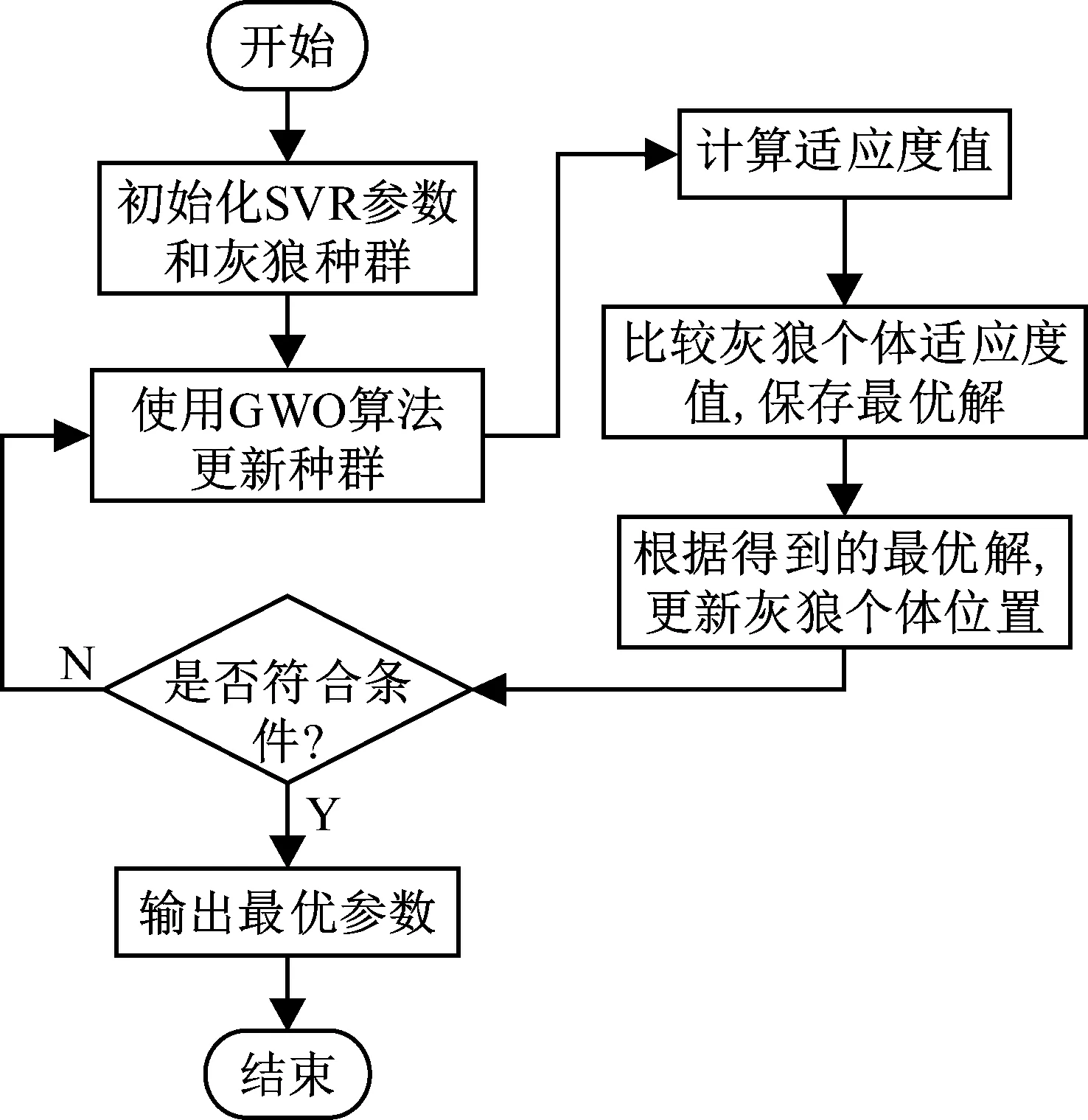
图6 灰狼优化算法流程图Fig.6 Flow chart of gray wolf optimization algorithm
4 试验测试及结果分析
本文首先对模具样件拼接缝中测得的铣削振动信号数据进行CEEMD分解,得到各个分量序列和残余项,然后基于GWO-SVR预测模型对每个分量进行训练和预测,训练和预测时基于GWO算法对SVR的参数C和g进行全局寻优,将各个分量的预测结果相加得到短期铣削振动总预测结果,预测模型如图7所示。
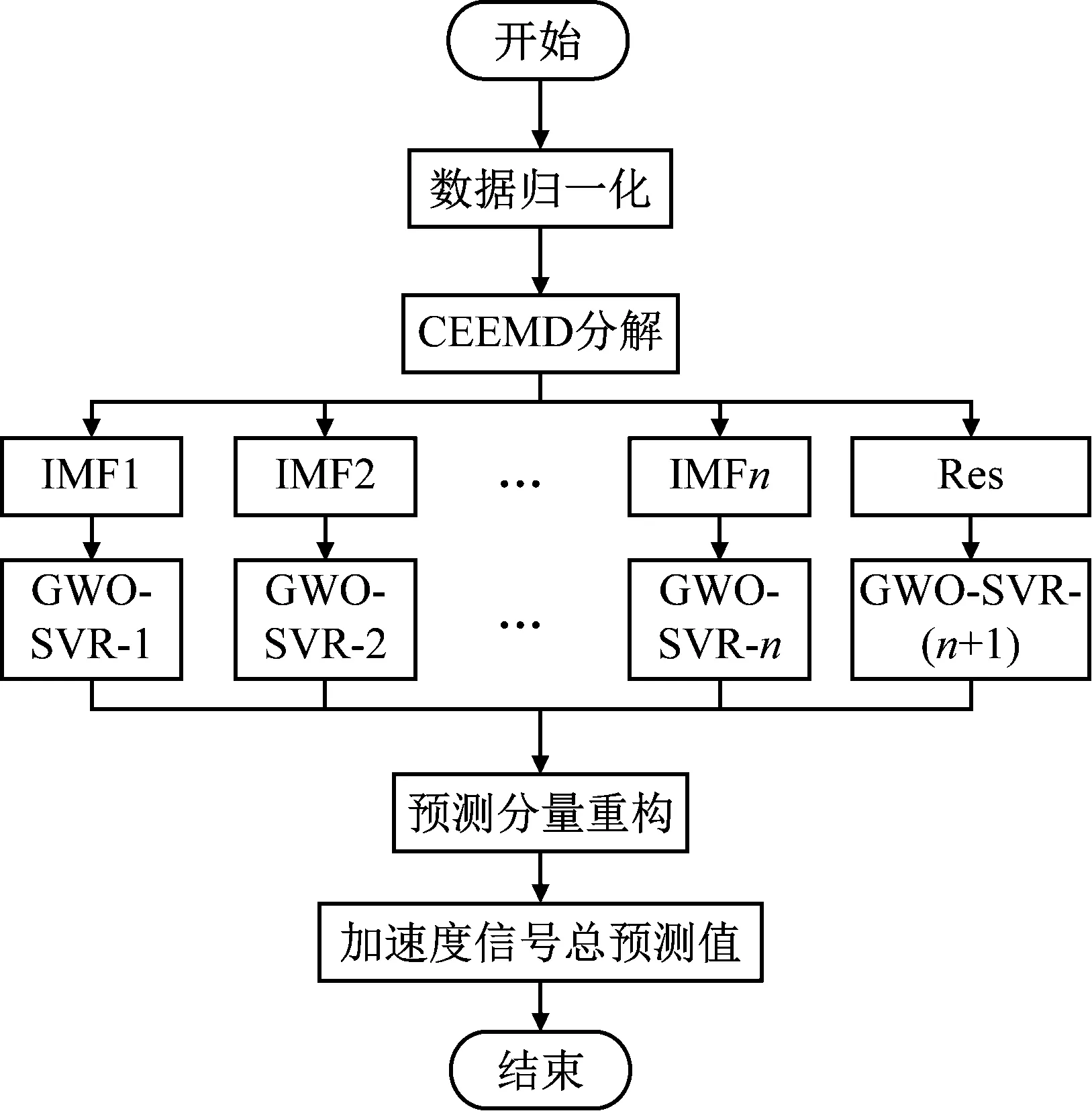
图7 CEEMD-GWO-SVR预测方法Fig.7 CEEMD-GWO-SVR prediction method
基于GWO对SVR中的参数C、g进行参数寻优过程中,首先进行初始化:种群规模N=20,最大迭代次数为200,C和g的范围从0.01~100。铣削振动加速度值被作为预测值输出,算法被用于训练模型时,GWO、PSO和GA三种寻优算法的适应度如图8所示。

图8 不同算法的适应度函数曲线Fig.8 Fitness function curves of different algorithms
三种算法对于适应度函数的计算不同,所以将会产生各自算法的全局最优参数,进而基于不同算法的支持向量机回归预测的精度也有所不同,不同寻优算法的最优参数寻优结果如表2所示。
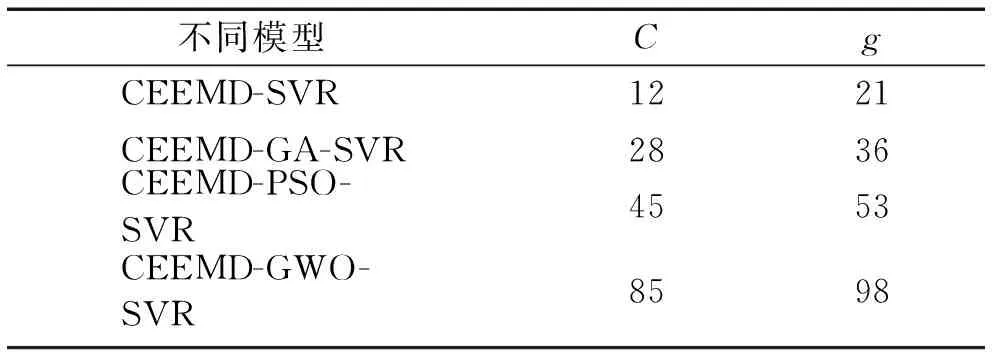
表2 不同方法参数寻优表Tab.2 Parameters optimization table of different methods
图8中可以看出,PSO算法在迭代次数达到第78次左右适应度函数完全收敛得到最优性能,其收敛性较差;而GA算法和GWO算法寻优速度和收敛性均大于PSO算法,其中GA算法在迭代次数为第50次时适应度函数趋于收敛,GWO算法则是在迭代次数为第5次时适应度函数完全收敛,可以看出GWO算法在寻优速度和收敛性方面性能优越,最终得到的全局最优惩罚因子C=76,全局最优核函数参数g=88。
建立SVR滚动预测模型,使SVR预测模型充分学习数据集内的数据规律,本文采用铣削振动信号中的第1~100时序数据点预测第101点,用第2~101时序数据点预测第102点,输入记为X,输出记为Y,一个X和Y记为一组样本,共计753组;前452组样本构建为训练集(占总样本数的60%),后301组样本构建为测试集(占总样本数的40%)。训练集是预测模型用来训练数据规律的数据集,当预测模型训练完成过后得到数据集的变化规律,然后预测模型根据预测集的步长预测步长相对的数据,得到一段模型预测后的数据,最后把预测数据和训练集的真实数据进行图形对比。
对经过CEEMD算法分解得到的加速度信号(IMFs信号)通过GWO-SVR预测模型进行预测,并将预测曲线进行反归一化处理;然后将各个经过反归一化处理后的预测曲线进行预测信号结果重构,得到振动加速度总信号(IMFs信号)的预测曲线,预测曲线如图9所示。
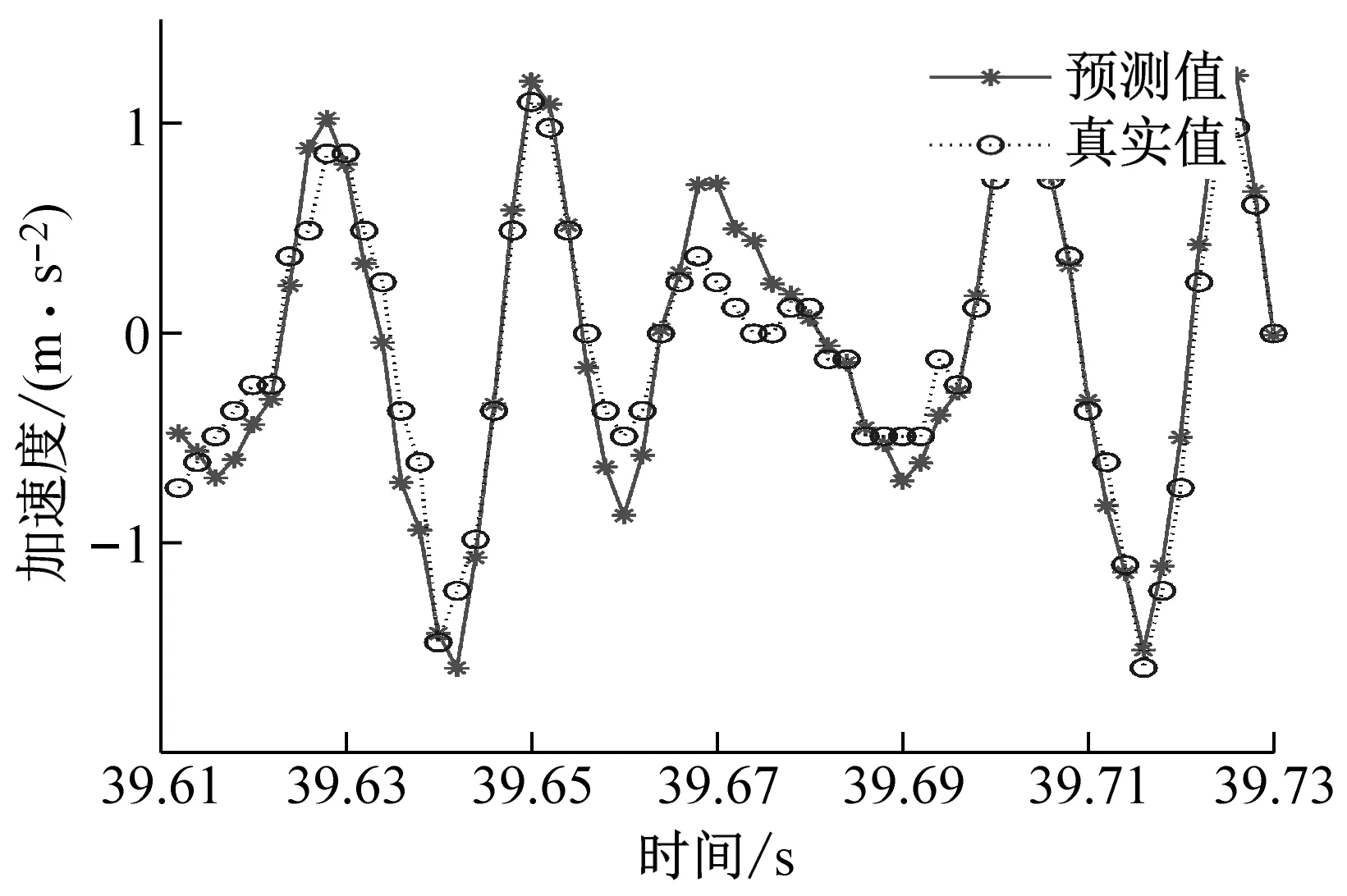

(a) ae=0.1 mm时工件X、Y两个方向加速度信号预测图
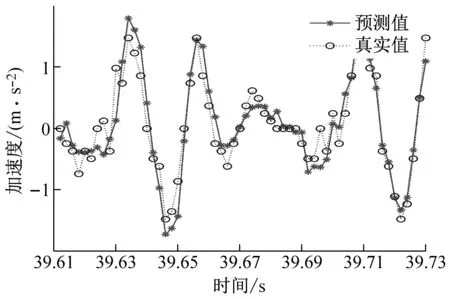
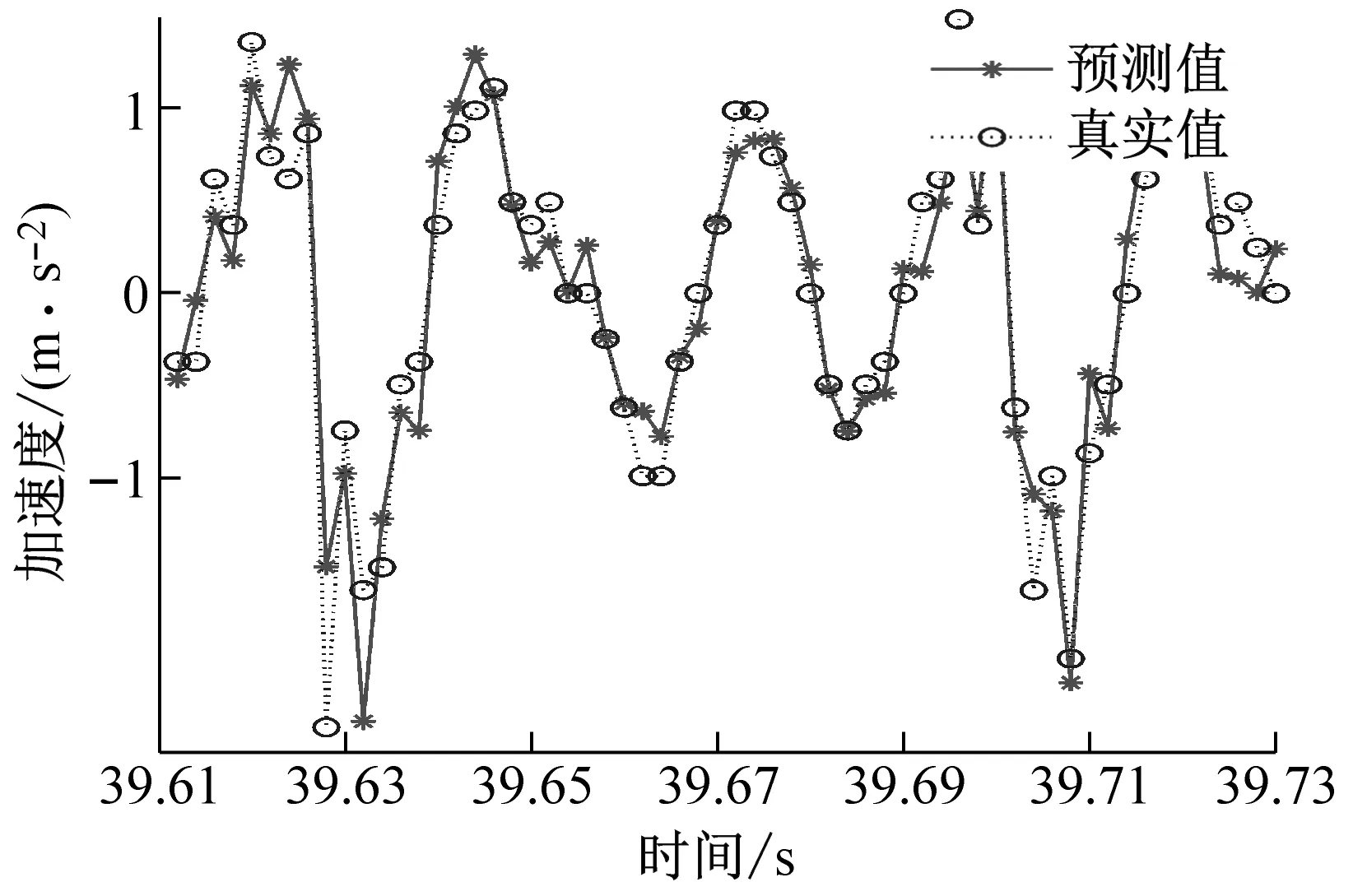
(b) ae=0.2 mm时工件X、Y两个方向加速度信号预测图
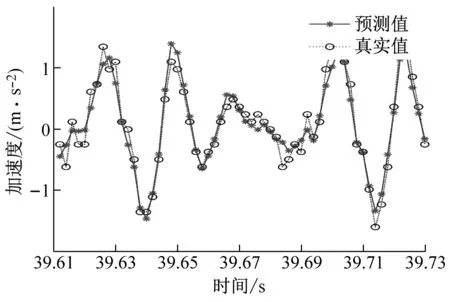
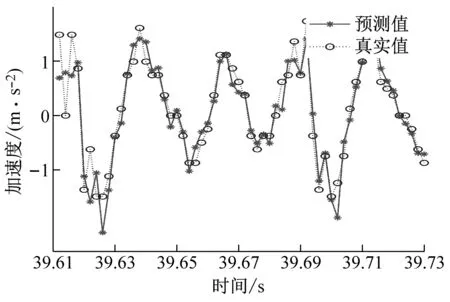
(c) ae=0.3 mm时工件X、Y两个方向加速度信号预测图
(d) ae=0.4 mm时工件X、Y两个方向加速度信号预测图图9 不同变切深下的振动数据预测结果图Fig.9 Vibration data prediction results at different variable depths of cut
从图9中可以看出,不同切深下的加速度信号预测结果图,可以明显地看出GWO-SVR模型对工件X方向的预测曲线拟合度高于工件Y方向的预测曲线拟合度,所以工件X方向的预测精度是高于工件Y方向的。
铣削振动幅值的不同归根到底是铣削力的差异,Y方向的铣削力要大于X方向的铣削力。在铣削过程中Y方向为主方向也就是进给方向,X方向为径向方向,刀具在进给方向对于材料的切除率要大于刀具径向方向对材料的切除率,在进给方向所受到的铣削力也就越大。
预测准确度的计算采取的方法是先计算预测值与实际值的差值,然后与实际值进行比较,具体预测准确度见表3。
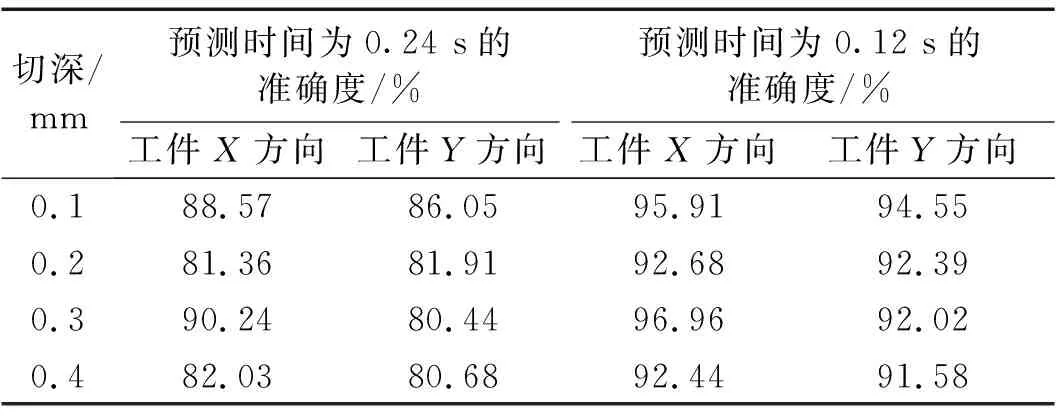
表3 工件X、Y方向铣削振动加速度信号预测准确度Tab.3 Prediction accuracy of vibration acceleration signal of workpiece in X and Y directions
如表3所示,在信号分解和前瞻预测方法确定的前提下,MSE的大小主要取决于原始振动信号数据的幅值大小,振动信号变化越强烈、非线性特征越强,得到的MSE结果也就是越差。因为多个子序列叠加的原因,不同的原始信号数据会产生较大的MSE差距,有时甚至为指数级别变化。当切深ae=0.30 mm时,加速度信号预测误差最小,当预测时间为0.24 s时工件X方向准确度最高达到90.24%,当预测时间为0.12 s时工件X方向准确度最高达到96.96%,整体准确度(工件X方向和Y方向两者共同的准确度)为94.49%。
分析中分别基于CEEMD-SVR模型、CEEMD-GA-SVR模型、CEEMD-PSO-SVR模型和CEEMD-GWO-SVR模型对数据进行预测,得到了四条预测曲线,如图10所示。

图10 不同模型预测曲线图Fig.10 Forecast curves of different models
从图10可以看出基于CEEMD-GWO-SVR模型的预测数据精准度要高于EMD-SVR模型、CEEMD-GA-SVR模型和CEEMD-PSO-SVR模型的预测精准度,这是由于经过了CEEMD算法优化,信号分解效果要强于EMD分解算法;且CEEMD算法寻优效果也要优于GA和PSO算法。具体预测数据见表4。

表4 预测时间为0.12 s的不同优化算法的性能对比Tab.4 Comparative of the performance of different optimization algorithms with a prediction time of 0.12 s
当切深ae=0.30 mm时,工件X方向加速度的预测相对误差如图11所示,此模型在预测刚开始时和预测中段有较大的误差,前期误差可能是刚开始时预测模型对预测集数据处于前期训练阶段,未完全掌握数据集规律,造成了预测精度低;而中期误差是由于所选预测集数据中期局部极值较多,此类型真实值不好预测而造成的预测误差增大;其余时间段预测精度都比较的高。
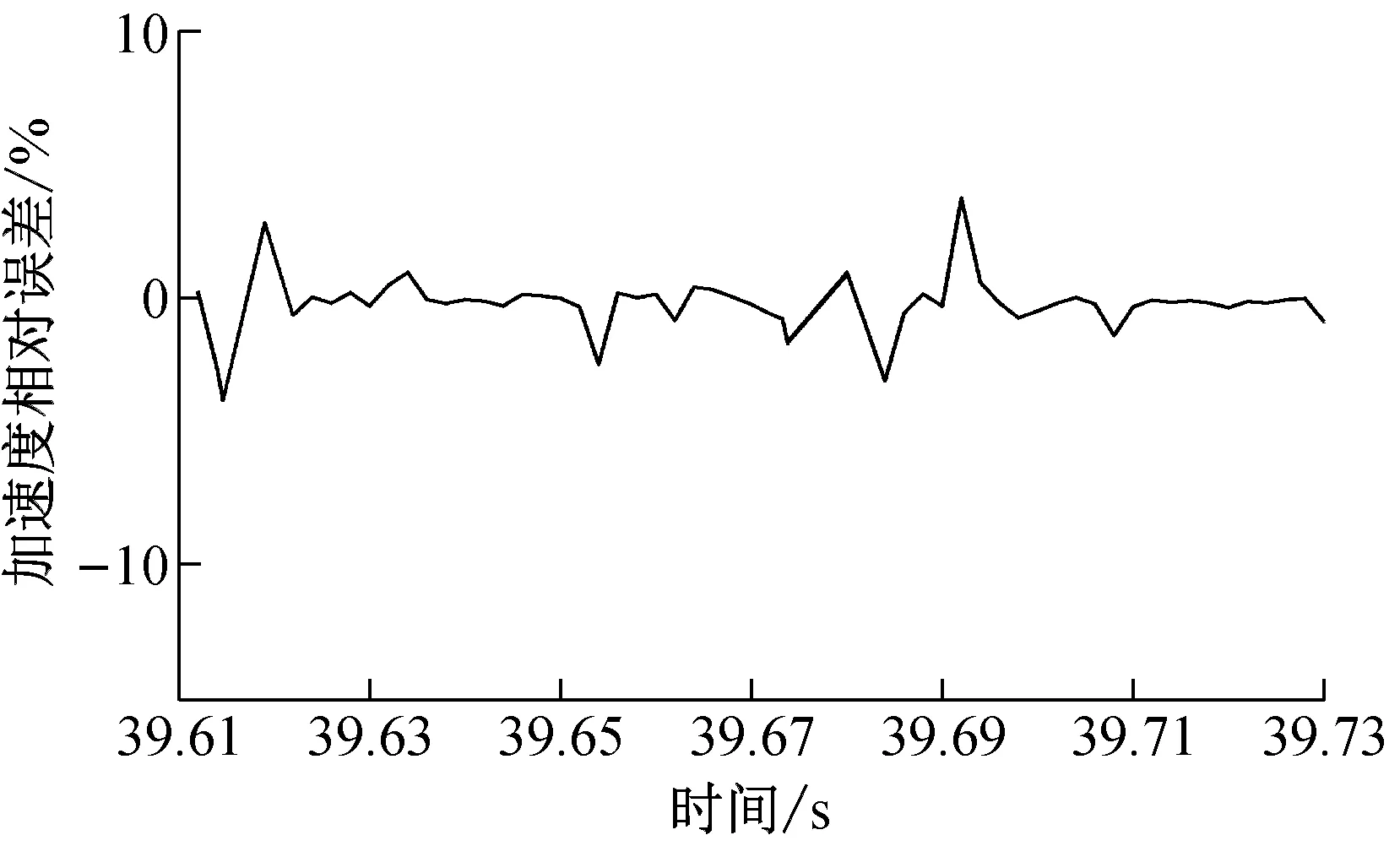
图11 ae=0.3 mm时工件X方向加速度相对误差图Fig.11 Relative error graph of acceleration in X direction of workpiece when ae=0.3 mm
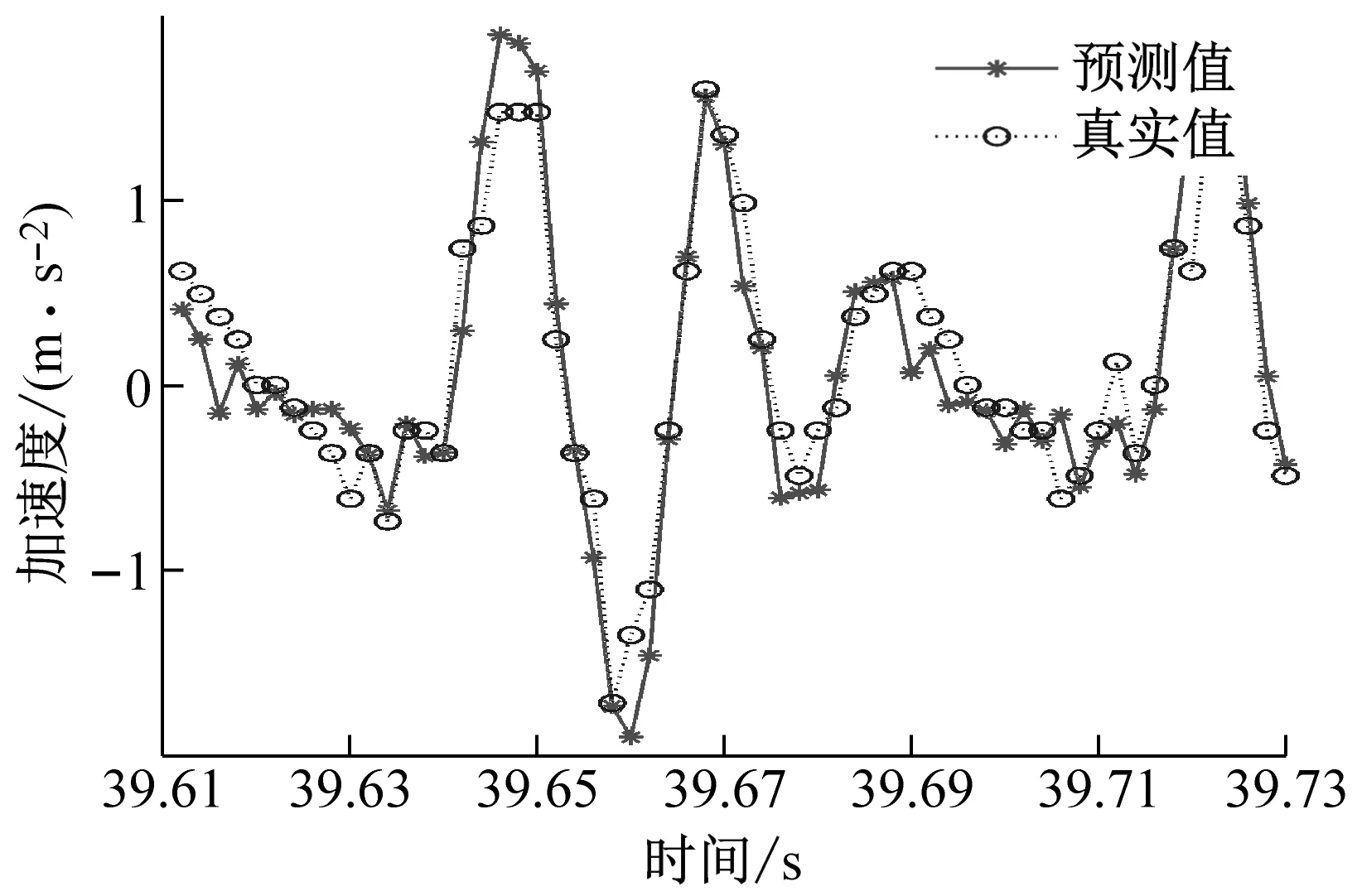
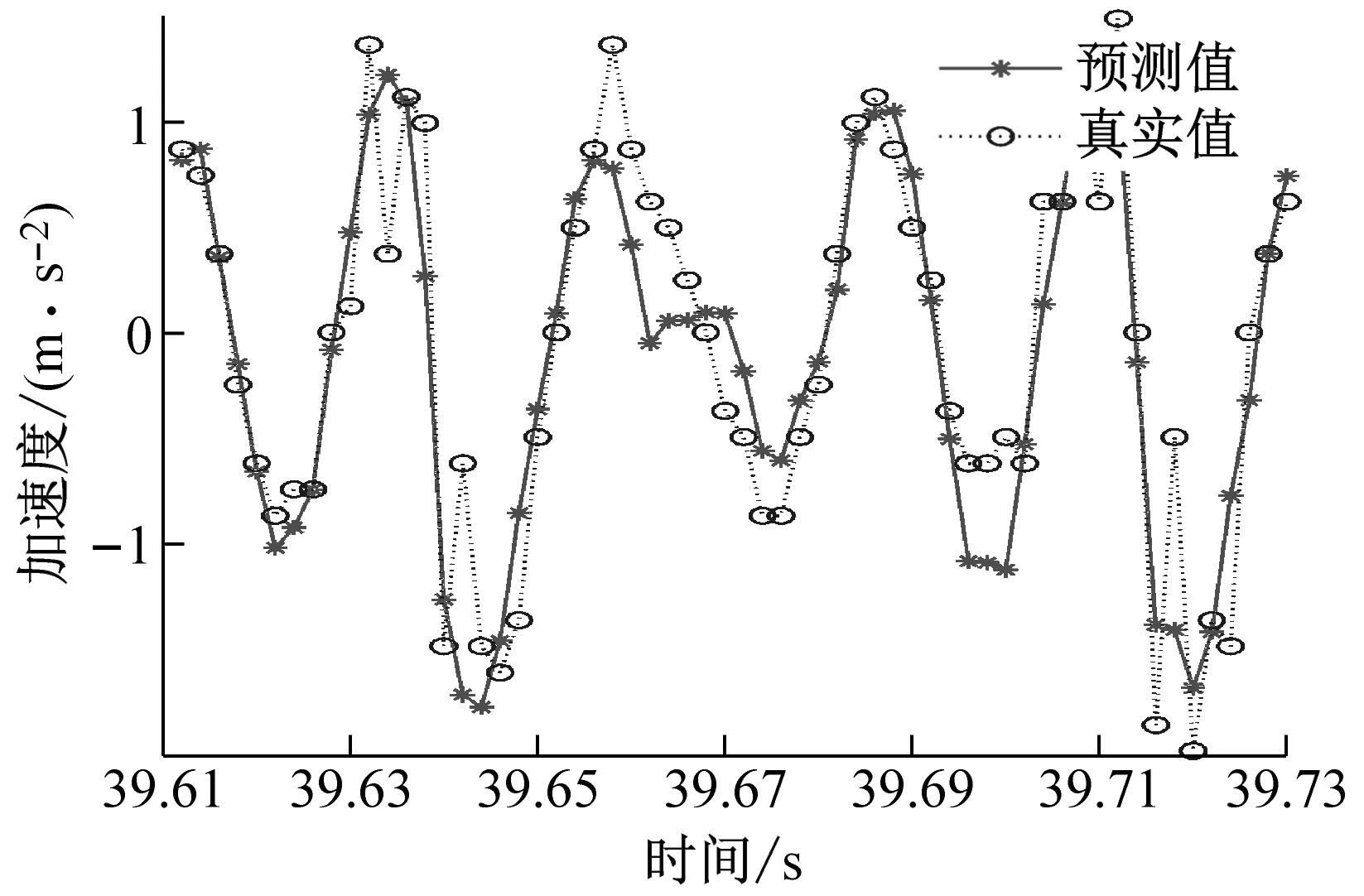
本文选取两个训练集和测试集比例,一个是训练集为总体数据量的60%,测试集为总体数据量的40%,另一个是训练集为总体数据量的20%,测试集为总体数据量的80%。当训练集时序数据减少,预测时序数据增加1倍时,观察所预测数据的精准度变化情况如图12和图13所示。
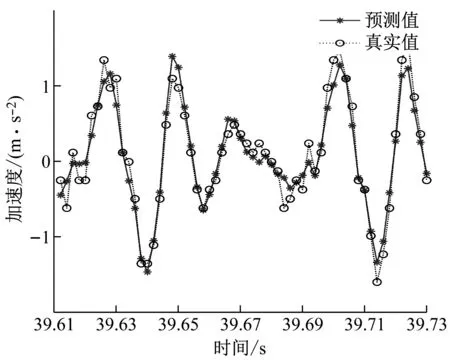
图12 预测时间0.12 s时的预测曲线图Fig.12 Forecast curve diagram at forecast time 0.12 s

图13 预测时间为0.24 s时的预测曲线图Fig.13 Forecast curve diagram at forecast time 0.24 s
当训练集的数据比例由60%下调到了20%,预测误差明显上升,预测精准度下降,这是由于训练集比例的降低会造成SVR所训练的样本个数的下降,训练样本数不足导致了SVR模型无法充分地学习数据样本的规律,从而导致预测精度的下降,为了进一步定量地评估预测结果,分别计算预测时间分别为为0.12 s和0.24 s的MSE(均方误差),计算结果如表4、表5所示。其中MSE函数一般用来检测模型的真实值和预测值之间的偏差,MSE值越大,表明预测结果越差。MSE公式为
(19)
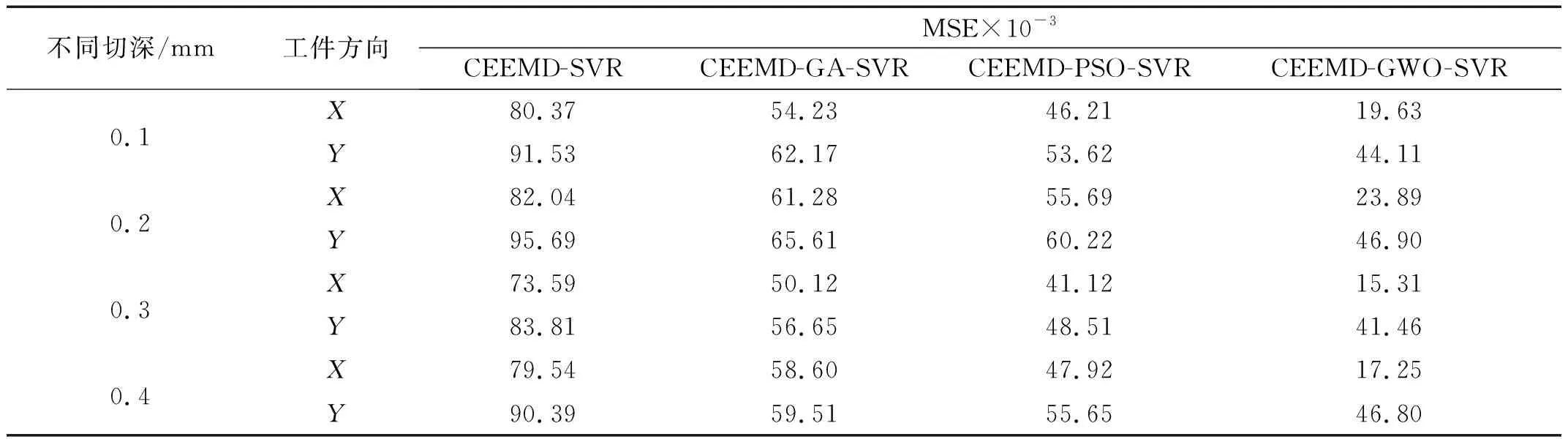
表5 预测时间为0.24 s的不同优化算法的性能对比Tab.5 Comparative of the performance of different optimization algorithms with a prediction time of 0.24 s

从表4和表5的试验结果可以看出,预测时间为0.12 s的预测步长模型的MSE要优于预测时间为0.24 s的预测步长模型的MSE,比如切深ae=0.30 mm时,基于CEEMD-GWO-SVR模型的工件X方向0.12 s预测步长的MSE为10.24要小于0.24 s预测步长MSE的15.31,所以0.12 s预测步长模型的预测性能要优于0.24 s预测步长模型的预测性能。
其中切深ae=0.30 mm时同一预测模型的MSE要低于其他切深预测模型的MSE,而且工件X方向MSE低于工件Y方向的MSE,如表4,当切深为ae=0.30 mm时工件X方向的MSE为10.24,当切深为ae=0.10 mm时工件X方向的MSE为14.15,当切深为ae=0.20 mm时工件X方向的MSE为17.38,切深为ae=0.40 mm时工件X方向的MSE为13.02;当切深ae=0.30 mm时工件X方向的MSE为10.24,切深为ae=0.30 mm时工件Y方向MSE为29.60。
在对工件X方向加速度信号进行步长为0.12 s的预测且切深ae=0.30 mm时,CEEMD-SVR模型、CEEMD-GA-SVR模型、CEEMD-PSO-SVR模型和CEEMD-GWO-SVR模型各自的MSE分别为68.14、39.96、31.87和10.24,CEEMD-GWO-SVR模型预测得到的MSE误差要低于CEEMD-SVR模型、CEEMD-GA-SVR模型、CEEMD-PSO-SVR模型,所以相比于CEEMD-SVR模型、CEEMD-GA-SVR模型、CEEMD-PSO-SVR模型,CEEMD-GWO-SVR模型具有更小的预测误差,证明了此方法更适用于预测铣削加速度信号。
5 结 论
(1) 提出了针对拼接模具铣削振动信号的CEEMD分解的方法,采取分解6层IMFs和残余项的方法,得到了稳定的子序列供后续的前瞻预测;
(2) 采用灰狼优化算法对支持向量机回归(SVR)中的参数C和g进行寻优,得到铣削振动信号规定时间段内的全局最优参数,然后将CEEMD和GWO-SVR结合起来预测铣削拼接模具振动加速度信号。试验数据显示,在对工件X方向加速度信号进行步长为0.12 s的预测且切深ae=0.30 mm时,CEEMD-SVR模型、CEEMD-GA-SVR模型、CEEMD-PSO-SVR模型和CEEMD-GWO-SVR模型各自的MSE为68.14、39.96、31.87和10.24,CEEMD-GWO-SVR模型的MSE低于其他三种模型的MSE,该方法相比其他方法具有较高的预测精度和更好的泛化能力,在预测步长为0.12 s时总体预测准确率为94.49%。
(3) 在淬硬钢拼接区铣削过程中,当切深为0.10 mm、0.20 mm、0.30 mm和0.40 mm时各自的MSE为14.15、17.38、10.24、13.02;在切深ae=0.30 mm时,拼接区铣削振动信号预测误差最小;在振动加速度信号为0.3 s的时间段内,0.12 s预测步长MSE为17.38,0.24 s预测步长MSE为23.89。在0.3 s的数据集中,0.12 s预测步长模型(预测集为全部数据集的40%)的预测误差小于0.24 s预测步长模型(预测集为全部数据集的80%)。
