基于触觉传感器和强化学习内在奖励的机械臂抓取方法
2022-06-17宋相兵季玉龙俎文强杨红雨
宋相兵, 季玉龙, 俎文强, 何 扬, 杨红雨,
(1.四川大学视觉合成图形图像技术国防重点学科实验室, 成都 610065;2. 四川大学空天科学与工程学院, 成都 610065;3.四川大学计算机学院, 成都 610065)
1 引 言
人们对周遭环境和物体进行探索时,非常依赖触觉,并依靠触觉感知来引导下一步操作.比如,人类可以在没有视觉的情况下灵活操纵某一物体,但是在失去触觉后,人们操纵物体的灵活性将大大降低[1,2].同样机器人在密集接触的任务中也非常依赖触觉提供的局部信息(如压力、震动、接触印记[3]等),因为这些信息在机器人进行灵巧操作[4]或抓握动作[5]时起着至关重要的作用.
与视觉传感器相比,触觉传感器提供的接触信息能让智能体更充分地感知环境和获取交互情况,比如,感知到物体发生滑动,或者已经牢牢抓住物体[6].通常在视觉被遮挡或者识别不准确的情况下,智能体将无法准确感知环境,因而无法完成任务,而Wu等[7]发现智能体仅依靠触觉信息仍可以通过尝试与探索完成抓取任务.因此触觉传感器在智能体中的应用逐渐成为研究热点.目前基于视觉的触觉传感器因其能获得高分辨率的反馈信息在机器人领域很受欢迎,并已经产生了很多应用和设计.比如Dong等研发的GelSight[3]、 GelSlim 2.0[8]、GelSlim MPalm[9]、GelSlim 3.0[10],Lambeta等[11]设计的DIGIT,Padmanabha等[12]利用多个微型摄像头制作的OmniTact传感器,以及She等[13]在柔性手指中嵌入的触觉传感器等.另外TacTip[14]虽然也是通过摄像头获取触觉信号,但是其触觉印记的分辨率远低于上述几种传感器.除此之外,阵列式传感器在机器人领域也很受青睐.它们大都利用新材料将外部刺激或压力转化为电信号,并且感知单元的布局相对规则.这类传感器根据感知原理主要分为:压阻式传感器[15]、电容式传感器[16]和气压传感器[4]等.不论信息的获取方式是怎样,每一个新的传感器都有其固有的属性,如脆性、体积、分辨率、延迟和生产成本等[17].
虽然基于视觉的触觉传感器能获取高分辨率的触觉信息,但由于其数据大都是图像格式,若想获取有效信息还需要经过复杂处理,而基于阵列的触觉传感器不仅获取触觉信息效率较高,而且还易于进行模拟仿真,这使得我们可以方便地根据触觉信号给予智能体相应的奖励.因此考虑到这些特性和其不同的应用场景,本文将仿真阵列传感器进行实验,具体传感器仿真细节在3.1节中详细阐述.
在机器人抓取方面,触觉信息大多数情况下都作为深度神经网络的输入用于机器人训练.比如Hogan等[9]、Calandra等[5]和Hellman等[18]先利用机器学习训练了一个预测模型,然后让机器人根据其结果来判断状态后再执行相应任务.这类方法计算复杂,会拖慢训练速率.而如今深度强化学习已在多个领域表现出巨大的潜力,如电子游戏、仿真模拟、机器人控制[19]以及图像处理[20]等.且Dong等[21]试验得出强化学习在机器人抓取等复杂任务中的表现要优于监督学习.另外Chebotar等[22]将深度学习与强化学习结合,利用触觉的时空特征训练了一个抓握稳定判别器,让智能体学会以更优姿态重新抓取物体.
而另一些研究人员则仅将触觉信号当成是强化学习环境的状态观测值,让智能体通过试错与奖励反馈学会抓握物体,比如文献[6]让机器人学会自适应控制力的大小避免物体掉落、文献[23]研究表明加入触觉反馈可以显著提高多指机器人抓握物体的鲁棒性,同样的方法也被用于其他非抓取的任务,如文献[24]让智能体根据触觉反馈学会控制方块;文献[4]将气压传感作为触觉让机械手指学会旋转和移动物体.这种方法虽然能提高智能体学习效率,但其本质是增加了环境的状态维度,提高了采样机器人的采样效率,而没有真正利用有价值的触觉信息.
与以上工作不同的是,另一些学者则根据触觉信息制定奖惩函数来诱导智能体尝试和探索,比如Huang 等[25]根据触觉反馈制定奖惩机制,让机械手学会温柔的触摸和操纵物体;文献[26]将触觉信号作为内在奖励,鼓励智能体进行更有效的探索.本文的工作也受此启发,首先基于阵列式传感器设计了一种“倒T”字形的触觉传感器的排列方式,然后通过分析机械末端与物体接触时的受力情况,提出了新的奖励函数来鼓励智能体能以更合适、更稳定的姿态去抓取物体,最后将该方法适配到新的机器人仿真环境中,验证该方法的有效性.
2 问题描述和模型建立
2.1 问题描述
机器人抓取是指将物体从起始位置拾取到另一目标位置的一套连续动作.在强化学习的训练过程中,智能体需要不断试错,不停地用末端接触物体,尝试不同位置将其夹起.当物体表面比较粗糙,末端和物体之间摩擦力比较大时,机器人能非常轻松完成抓取任务,而当物体比较光滑且表面是弧面时,机器人夹取物体的成功率则会大大降低.
机器人用刚性末端夹取光滑物体类似于我们生活中用筷子夹取某些豆类食物或者夹弹珠,其成功率主要取决于接触力的大小和接触点位置.如果接触力太小,接触点的摩擦力小于重力,物体自然会因此掉落;若接触点处于错误位置,增加接触力只会增大物体滑落的可能性.以夹取球型物体为例,如图1a所示,当夹具与物体接触点位于物体形心上方时,接触力方向偏离形心,如果此时夹具与物体间的摩擦系数太小,将不能保证有效夹取.图1b和1c所示的方式则可以进行有效抓取.但是图1b中接触点和接触力虽然处于被抓取物体的最佳位置,但该接触点位于夹具边缘,容错率很低,若机器稍有震动将导致物体滑落.因此该夹取方式仍不是最优解.而图1c所示的夹取情形中,物体和夹具上的接触点都到达最佳位置,即使在夹取过程中物体发生轻微偏移,也可以将物体成功抓取.图1d展示了俯视时的最佳抓取位置.

本文认为图1c和1d是机械臂夹取过程中非常理想的中间状态,因此我们希望塑造一个合理的奖励函数来引导智能体到达这种中间状态.这种中间状态可利用触觉传感器来间接表示,但是在强化学习中,奖励塑造是一个很棘手的问题.因为一项复杂任务往往具有多个中间状态,如果我们针对每一个状态都进行奖励,那样奖励函数将会非常复杂,而且这样往往也会使智能体找到得分漏洞,然后陷入刷分的循环,从而导致训练失败[27].而如果仅将达到最终目标作为奖励体条件,会使得智能体进行过多随机且无用的探索,从而拖慢训练速度甚至出现算法一直无法收敛的情况.
所以我们将用触觉信号作为内在奖励引导智能体去探索,使其更快速地到达中间状态(即末端以更优位置去接触物体),但同时又允许智能体能够进行其他不同的探索,也就是利用现有的机械臂仿真环境进行实验,通过增加触觉传感区域来扩展强化学习环境的状态空间,并根据触觉累计值修改奖励函数,从而引导智能体进行更有效的探索.
2.2 强化学习模型
本文通过深度强化学习和内在触觉激励来优化机械臂抓取物体的任务,该任务是将目标物体夹取到一个目标位置,从而获得任务奖励.其中机械臂抓取物体的过程可归纳为一个马尔可夫决策过程(Markov Decision Process, MDP).该过程可以用元组(S,A,P,R,γ)来表示.其中S表示状态空间;A表示动作;而P表示在状态S下执行动作A后,状态变成S′的概率,可写作(P:S×A→S′);R表示智能体在状态S下执行动作A所获得的奖励函数,即R:S×A→[0,1];γ代表折扣因子,它表示未来奖励对现在的重要性,其值越大代表智能体越看重未来奖励,其值越小则表示智能体更重视短期回报.
在整个交互过程中,机械臂作为智能体,在t时刻,观察当前状态,然后根据策略π选择动作at,at∈A(其动作由一个四维向量表示,前三维数据表示一个与机械臂夹具中心绑定的Mocap动作捕捉点的世界坐标,后一维数据表示夹具开合的状态),然后观察得到新的状态st+1,最后根据状态计算上一步动作的奖励,再进行接下来的决策.智能体的最终目标就是找到最优策略π*,得到最大化累计奖励Rt,即:
(1)
其中ri代表即时奖励.
3 方 法
3.1 触觉传感器的设计与任务设置
与文献[26]类似,我们在机械臂末端夹具上添加了传感区域,本文和他们不同的是,他们将整个夹具用一个传感区域覆盖,对所有接触位置一视同仁,而我们认为夹具的区域是有优劣之分的,正如2.1节所讲到的,物体与夹具的接触位置不同,会影响夹取的稳定性,因此我们根据前面定义的接触位置的好坏给予了不同传感器不同的重视程度(重视程度与位置关系如图2所示),另外为了既鼓励夹具与物体接触,又能引导智能体以最优位置夹取物体,本文在夹具上设计了如图2所示的倒“T型”传感区域阵列.该阵列由3个传感区域组成,最下面的一整块传感区域是为了能更全面地捕捉刚接触的信号,上面的两块方形传感区域是为了引导智能体用这些区域(尤其是区域1)去夹取物体.每当末端夹具与物体在某一传感区域接触时,物理引擎就会计算出相应的值.通过奖励函数设置,我们将鼓励智能体用末端去接触目标物体,并鼓励它尽量用重视程度最高的位置去接触物体.

图2 传感器布局与相应区域重视程度
接着为了证明本文方法的有效性,我们在提高原始任务难度的情况下(即增加了目标位置在空中生成的概率和高度,以及将目标物体由方块替换成圆球和椭球),使用不添加传感器、只加传感器、最新内在奖励[26]以及本文内在奖励4种方法分别进行球形抓取和椭球抓取的任务训练,通过对比它们各自夹取的成功率来佐证本文观点.
3.2 奖励函数设定
强化学习算法旨在让智能体学习一种能在环境中获得最大长期回报的策略,而在大多数任务中这些奖励都是稀疏的,即智能体只有完成了目标才能获得相应奖励.这就会让智能体产生太多无意义的尝试,从而降低学习效率.因此,为了提高智能体探索的效率,本文引入了内部激励机制[28,29]来鼓励智能体进行更有效的探索.我们的奖励函数由外部奖励rext(s,g)和与目标无关的内部奖励rint(s)两部分组成,其表示如下.
r(s,g)=ωext*rext(s,g)+ωint*rint(s)
(2)
其中ωext和ωint分别表示外部奖励和内部奖励的权重.外部奖励是完成目标后获得的稀疏奖励,只要物体位置在目标范围之内即返回1,否则返回0,具体表示如下.
(3)
其中g表示目标位置;xobj表示物体位置;εpos表示距离阈值.而本文内部奖励又分为两部分,表示如下.
rint(st)=ωc_frc_f+ωc_prc_p
(4)
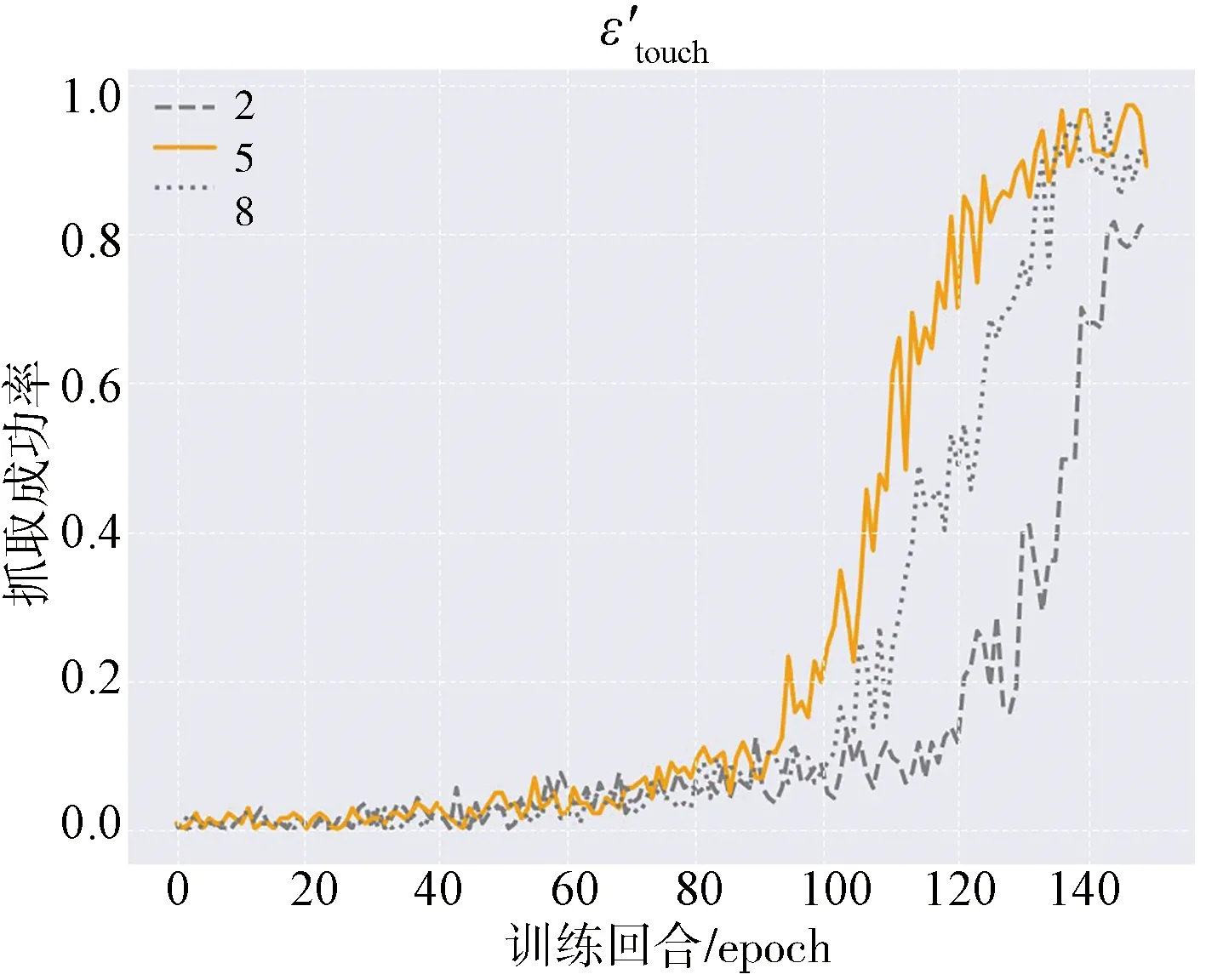
其中c_f、c_p分别表示接触力和接触位置.接触力奖励仅根据触觉信号来设定,只要一幕训练过程中所有触觉信号累计值∑v超过阈值εtouch就返回1,否则返回.其表示如下.
(5)
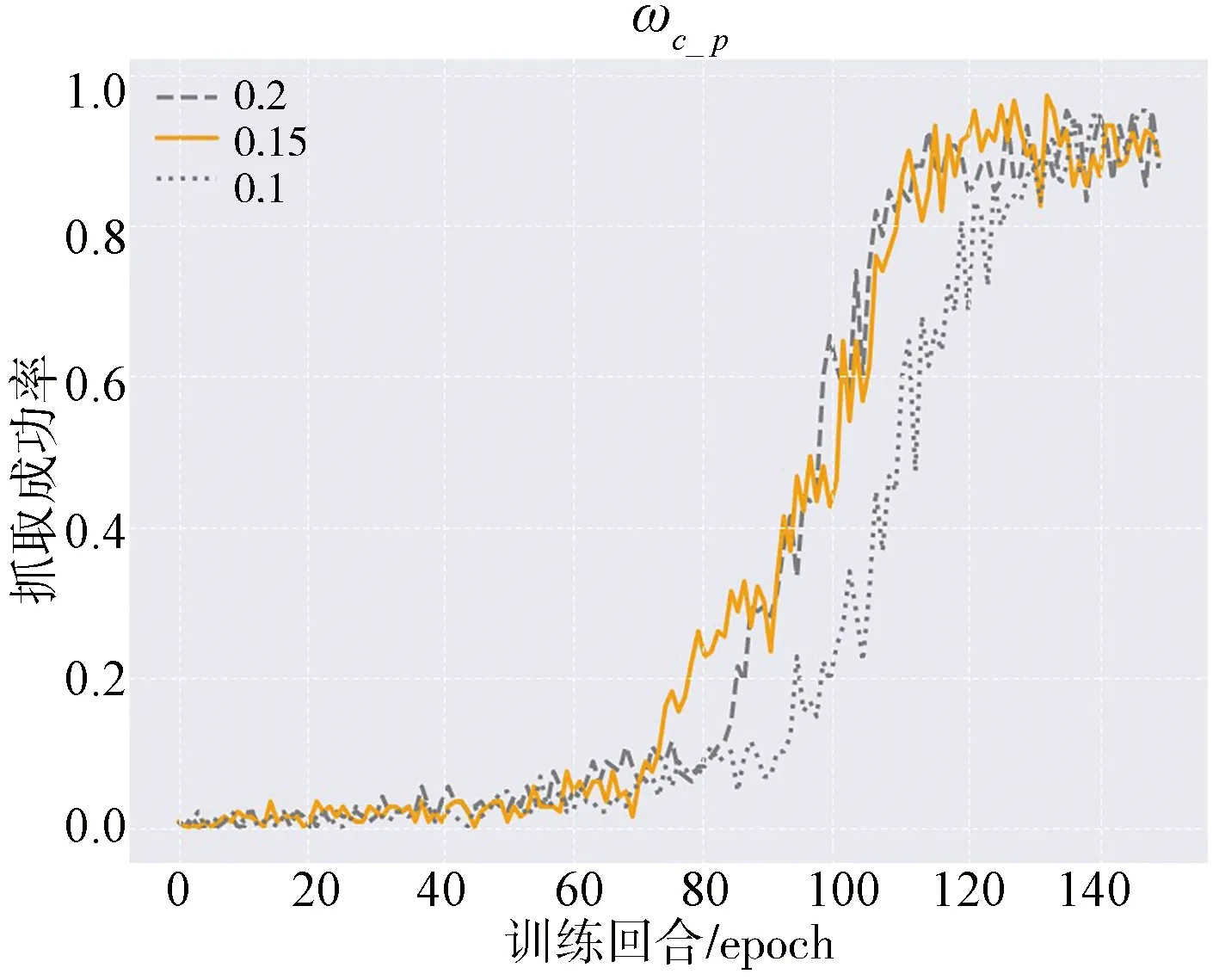
而对于接触位置奖励,我们按照图2传感区域的重要程度,根据接触信号累计值的区域的不同给予不同奖励,其表示如下.
(6)
其中,v1i、v2i、v3i分别表示区域1、2、3的触觉信号值.
4组实验结果如图3所示,4幅图中的黄色曲线分别表示所选参数在各自最优值下的训练效果.最终本文确定以表1中的值作为奖励函数的参数.

(b)
(c)
(d)

表1 奖励函数中的参数值
3.3 训练算法
由于机器人抓取是一个连续动作控制问题,所以本文采用集成了时间差分学习和策略梯度的深度确定性策略梯度算法(Deep Deterministic Policy Gradient,DDPG)[30]来训练智能体,并且将之与事后经验回放技术(Hindsight Experience Replay,HER)[31]结合来提高数据利用效率.
其中,DDPG是一种基于演员-评论家(Actor-Critic)框架的离线策略(Off-policy)算法,即使用两套不同的网络进行动作的选择和评价.其中Actor是直接学习策略的网络,它接收从环境中获取的当前状态S,然后根据策略π,输出相应的动作A.而Critic网络则根据当前状态和动作计算Q值来评价动作的好坏,即学习动作价值函数Qπ.在训练期间,Actor网络通过行为策略去探索环境,该行为策略是目标策略加上了一些噪声后的策略,即πb=π(s)+N(0,1).在式(7)中, Critic通过最小化rt+γQ(st+1,π(st+1))和Q(st,at)的lossLc来更新网络.
Lc=rt+γQ(st+1,π(st+1))-Q(st,at)
(7)
其中,rt+γQ(st+1,π(st+1))表示真实的动作状态值;Q(st,at)表示估计的动作状态值.而Actor使用策略梯度通过损失函数的梯度下降来训练网络,该损失函数表示为
La=-Es[Q(s,π(s))]
(8)
其中,s是从经验回放池采样而来.而La关于Actor网络的参数的梯度可以通过结合了Critic和Actor网络的反向传播计算得到.
HER[31]是Andrychwicz等提出的一种数据增强技术.在机器人任务中,如果目标比较复杂而且奖励很稀疏,那么智能体在学到一些经验前会进行很多失败且无效的尝试.因此HER就鼓励智能体从失败的经验中学习一些东西.在探索过程中,智能体根据真实目标对一些轨迹进行采样.HER的主要思想就是将选定的一次状态转移中的原始目标替换为已经达到的目标,即用一个虚拟目标替换真实目标.这样智能体就可以获得足够数量的奖励信号来开始学习.
HER包含4种采样策略,每种策略具体内容如下:(1) future模式:当回放某一状态转移时,从同一幕的该状态之后,随机选择k个状态进行回放,即,如果现在的样本为(st,at,st+1),就从t+1开始到最后的状态中选择k个已经达到的目标(achieved goal)作为新目标;(2) final模式:把每一幕的最后一个已达到目标作为新目标;(3) episode模式:与future模式有些类似,但是该模式直接从同一幕中随机选择k个已达到目标作为新目标,没有限制是否要往后采样;(4) random模式:随机选择整个训练过程中的k个状态进行回放;
本文采用的是future模式,HER计算流程图如图4所示,其主要步骤如下.
(1) 随机选取一幕训练的完整样本;
(2) 用智能体当前的已完成状态替换掉最终目标(desired goal);
(3) 更新“info”信息;
(4) 重新计算奖励.

图4 HER计算流程图Fig.4 The calculation flow chart of HER
4 仿真实验环境及结果
4.1 实验环境
本实验环境是在OpenAI Gym[32]中的Fetch机器人抓取与放置(Fetch-PickAndPlace)仿真实验环境的基础上进行的改进,其整个实验场景如图5所示.该实验环境是以MuJoCo[33]作为物理引擎.在机器人运动仿真过程中,MuJoCo具备关节防卡死、多约束、多驱动以及细节化仿真等特点,十分适用于机器人姿态控制及机械臂运动仿真.MuJoCo可以仿真许多类型的传感器,比如触摸传感器、惯性测量单元、力传感器、力矩传感器、关节速度传感器等.这些传感器在仿真环境里不参与模型的碰撞计算,它们只为用户的计算提供相关信息数据信息.例如触摸传感器是在执行器上定义一块特定形状的传感区域,只要执行器在该区域与其他物体产生接触行为,相应的接触力就会被计算出来.该传感器的读数是非负标量,它是通过将被包含在接触区域的所有法向力(标量)相加来计算的.

图5 实验场景Fig.5 The experimental scene
该实验任务就是将桌上的目标物体抓取并移动到空中红色的目标位置,只要物体与目标的距离不超过阈值即可判定完成任务.
而本文对环境的主要修改如图2所示.这3块传感区域的宽度都相等,而第3块区域的长度是前两块的3倍,且与末端夹具等宽.同时,为了避免智能体在探索过程中产生误触(如夹具触碰桌面而产生读数),本文将3块传感区域沿末端长边依次上移了2.5 mm.然后将这3块区域作为site被绑定在末端夹具body实体下,其在xml文件中的表现形式如下:
(其他属性)……
(其他site)……
最终将环境的观察值增加了2*3维,即从25维增加到31维.最终改进后的环境状态信息如表2所示.

表2 仿真环境状态值信息
4.2 实验设置
本实验中的所有超参数以及训练过程都在文献[31,34]中有详细描述,并且这些超参数和强化学习算法都被集成于OpenAI的Baselines[35]中.Baselines是基于TensorFlow而开发的一套强化学习算法的实现框架.本文利用其中的DDPG和HER来训练智能体.
本文设置了4组实验环境,每组环境完成2项不同物体(球体和椭球体)的夹取任务.其中,1组为本文的实验环境,其观察值如4.1节所述是31维.另外3组为对比实验环境,而对比实验环境中2组的观察值也是31维,另一空白组的观察值只有初始的25维,每组详细设置如表3所示.

表3 实验环境信息
然后基于以上4种环境在Windows平台Intel 16核电脑上用15核通过MPI实现150回合的并行训练,最终以每回合训练结束后测试抓取的成功率作为主要判断指标,以第一次达到基准成功率的回合数作为辅助判断指标.抓取成功率就是在每回合训练结束后,再在每个核心上进行10次确定性的测试试验,接着综合计算所有核心上试验夹取成功次数而得到的成功率.
4.3 结果及分析
本实验通过夹取球体(图6)和椭球体(图7)任务对比了3.1节中提到的4种情况(即未加传感器的原始情况、只加传感器不修改奖励函数、最新提出的传感器结合内在奖励机制以及本文的传感器结合内在奖励机制,后文中这些情况简称如表3最后一列所示),所得结果如图8、图9、表4以及表5所示.其中图8、图9横坐标表示训练回合,纵坐标表示每回合得出的抓取成功率.表4前4列给出了4种情况下130~150回合的平均成功率,后两列计算了本文平均成功率与情况1和2平均成功率的比率(由于在150回合内情况3的成功率未见显著提升,因此本文未计算该情况下的比率).表5以表4中情况1的平均成功率(由于情况2在150回合内未见收敛的趋势,故不予考虑)作为基准成功率,列出了情况1与本文环境第一次到达该成功率的回合数以及回合比率.比如,情况1的圆球抓取任务中第一次达到0.861成功率的回合是第133回合,而本文环境第一次达到该成功率则是在112回合,收敛速度是前者的1.188倍.

图6 实验中的球体

图7 实验中的椭球体
图8和图9中蓝色实线是本文所使用的方法得出的抓取成功率曲线,橘黄色虚线是Vulin等[26]提出的传感器结合内在奖励方法(即情况1)得出的结果,红色和绿色虚线分别表示只加传感器不修改奖励(即情况2,仅拓展智能体的观测空间)和没加传感器(即情况3)情况下的训练情况.可以看出,在球体和椭球体抓取任务中,加入传感器增加了观测空间后,智能体的学习效率相较于不加传感器的情况有较大改善.而橘黄色虚线则表明情况1的确能大大提高智能体的学习效率.不过,结合表4和表5可知本文所提方法同样远远优于未经

图8 圆球抓取任务结果Fig.8 The result of grasping sphere
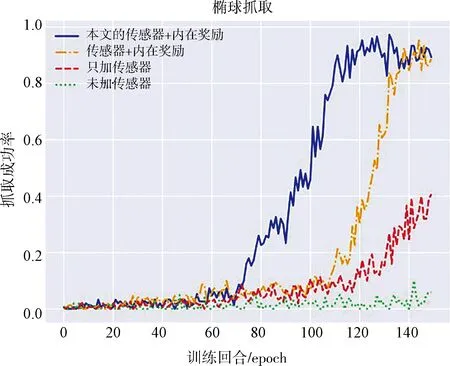
图9 椭球抓取任务结果Fig.9 The result of grasping ellipsoid
优化的传统方法(情况2和情况3),而且在同样条件下,比最新的情况1提前约20回合收敛,并且在后者收敛之前就达到了最优的正确率.这是由于情况1没对接触位置作区分,仅仅是鼓励智能体去接触目标物体,而忽略了接触位置的差异,从而导致智能体在训练过程中仍会多次尝试以2.1节中描述的次优或最差姿态去接触物体,最终导致夹取失败而拖慢训练速度.

表4 130~150回合平均成功率

表5 第一次到达基准平均成功率的回合数
因此,本文所提方法极大地提高了智能体抓取球形物体时的学习效率.在本实验中,我们利用了传感器提供的位置和压力信息,有效地捕捉到了物体的接触信息,然后通过内在奖励机制鼓励智能体进行有效的探索.在这里内在奖励就像一个指导员,引导智能体达到一个容易达到且有意义的状态.有了内在奖励引导,智能体能够返回一个比较合适的状态,并且不会因为随机探索而丢失该轨迹,因此内在奖励机制可以提高智能体有意义的探索.
5 结 论
针对智能体在对球形物体进行抓取时容易产生滑动的问题,本文提出了一种新的呈“倒T”形排布传感器阵列和相应的内在奖励函数;并且结合DDPG+HER强化学习算法在MuJoCo仿真环境中对比了4种方法;最后验证了以触觉传感器累计值和接触位置作为内在奖励信号能够引导智能体更快地完成球体的夹取任务,同时又不会限制智能体探索其他状态.
当然,我们可以设计一个完美的末端夹具来执行相关任务.但在现实世界,物体的形状有成千上万种,要设计这样一种末端机械装置十分困难,因此目前的大多数末端执行器能达到的都只是在特定情况下的最优控制[36].人类的手之所以能抓握大部分物体,除了因为其灵活的关节外,还因为其具有敏锐的触觉.所以在现有末端装置条件下加入触觉传感是提高物体抓取的有效途径.
未来,我们将继续开展相关工作,如将该方法应用于更多类型的物体,包括但不限于圆柱体、正方体以及不规则物体等;并且将该方法应用于不同类型的末端执行器上来验证该方法的鲁棒性.此外,本文是仅在仿真环境下进行的相关实验,下一步我们会将算法迁移到真实机器人上,在复杂真实的环境中验证其效果.
