大数据可视化预测分析引擎在煤矿水害监测预警中的应用研究
2022-06-17赵延超段江飞
赵延超,李 鹏,吴 涛,段江飞
(1.中煤地华盛水文地质勘察有限公司,河北 邯郸 056004;2.中国煤炭地质总局 水文地质工程地质环境地质勘查院,河北 邯郸 056000)
1 概况
随着信息技术的高速发展,大量的数字产品也产生了大量的数字用户,而这些数字用户在产品使用过程中一定会产生大量数据,尤其是巨头互联网公司。例如腾讯控股旗下的微信支付产品就存储着海量的交易数据,并以此作为数据基础提供征信服务;字节跳动公司的数据存储中也存有众多的新闻信息、短视频信息、商品信息等内容。所有使用大数据技术都不可避免会在这个过程中遇到数据的采集,处理和分析问题。与此同时,大数据产品也相应出现了变化,慢慢的从以软件为核心转换到以为数据为核心。大数据时代要求我们在新的数据平台去开发新的系统。纵观整个大数据产品市场,大数据可视化工具产品可以说是百花齐放,不同背景的厂商在这个概念下提供着自己的产品和服务。据调查研究,大数据可视化工具的公司大致分为商业智能可视化工具的软件服务商和互联网巨头公司这两类[1-2]。
尽管很多行业做了大量数据可视化的尝试,但其发展仍然面临着关注度不高、对大数据数据源支持有限、价格昂贵等问题,但数字可视化产品依旧是未来大数据发展的方向和趋势。为了更好对大数据挖可视化挖掘,本课题通过使用web 前后端开发技术研究自定义可视化分析引擎关键技术,并完成系统模块的开发。通过本课题开发设计的引擎及系统可以赋予大数据可视化模块自定义的能力,使煤矿水害管理人员直观的看到数据来源及显示样式,更好的贴合管理人员的需求,对系统数据做到良好的展现[3-5]。
2 自定义可视化分析引擎概要设计
2.1 系统软件层次架构设计
大数据可视化预测分析引擎系统软件层次架构设计如图1 所示。

图1 系统软件层次架构Fig.1 System software architecture
2.2 系统功能模块设计
根据不同功能的界限和实际业务需求,将基于大数据的自定义可视化分析引擎共划分为数据管理模块、数据分析模块和数据显示模块,如图2 所示。这3 个模块既各司其职负责本模块的业务和计算,同时也相互共享和传递数据。
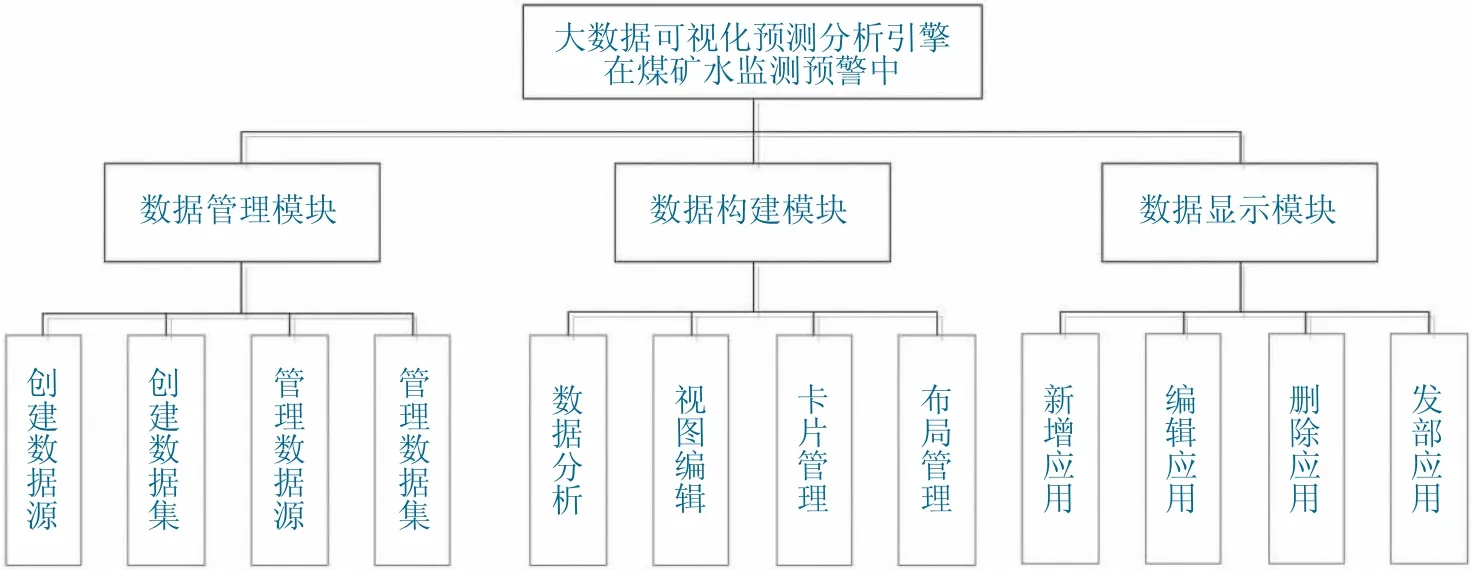
图2 基于大数据的自定义可视化分析引擎功能模块Fig.2 Function module of custom visual analysis engine based on big data
2.2.1 数据管理模块
数据管理模块是数据分析的重要成分,数据管理模块的工作是将管理人员所需要的数据从不同数据源集中到系统中,去解决数据分散、类型不同等问题形成数据集。简化了数据获取流程,节省了整合、清洗数据所花费的大量时间,使用户方便的进行数据存储与管理和数据分析。数据管理模块主要包括创建数据源,创建数据集,管理数据源和管理数据集4 个功能[6]。
2.2.2 数据分析模块
数据分析模块属于构建煤矿水害监测预警可视化应用的核心模块。此次研究采用了XGboost、FP-growth 算法的数据预测分析,能够挖掘出监测数据指标与预警阈值的关系,并提前分析将来一段时间数据的走向,以达到预警的效果,得到两者的相关性以及数据的变化规律[7]。
2.2.3 数据显示模块
数据显示模块能够实现预测数据趋势、维度等直观显示的需求,同时实现了监测检测数据的多角度、多视图、多维度的展示和交互,直观展示了数据隐含的有用信息[8]。
2.3 系统的数据库设计
2.3.1 E- R 图设计
数据库设计是基于开展需求分析获取的用户需求,进行抽象化处理以获取概念模型及信息结构。为了对数据库结构予以描述,此处以E-R 图为工具对数据库的实体关系进行描述。通过对不同模块的数据需求进行提炼,对系统E-R 图进行设计,如图3 所示(由于实体属性较多,在E-R 图中不体现属性)。
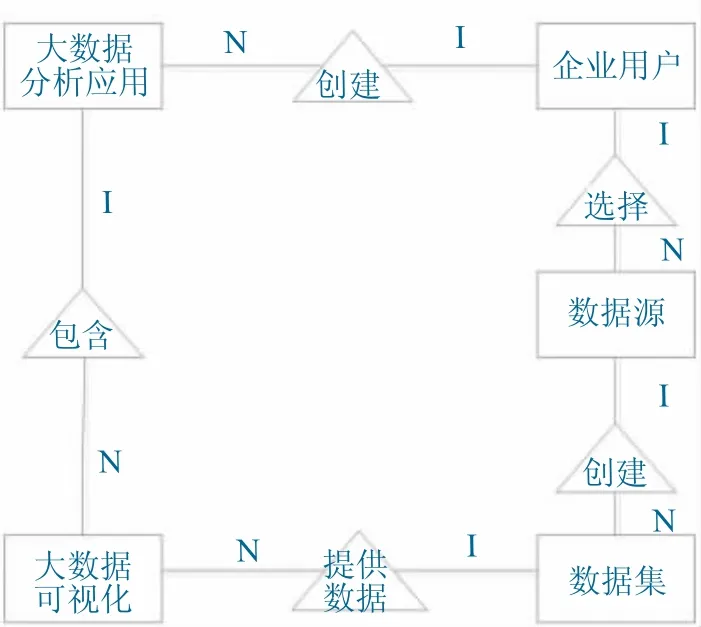
图3 基于大数据的自定义可视化分析引擎数据库E- R图Fig.3 E-R diagram of custom visual analysis engine database based on big data
E-R 图主要包含的信息数据有用户信息、数据集信息和监测数据应用信息。其中一个管理人员可能选择多个数据源或者创建多个数据卡片。一个数据应用一般包含多个数据卡片。另外一个数据集的数据可能提供给多个数据卡片,因此与这两者之间是一对多的关系[9]。
2.3.2 数据库表设计
数据实体及实体间的关系描述了数据库的逻辑结构,根据数据实体及实体属性对数据库物理结构进行设计即数据库表。数据源表主要用于存储系统系统数据源的信息,主键是数据库名称,还有表名称,数据源描述等字段,具体见表1。

表1 文件存储表Table 1 File storage table
自动监测数据主要用于存储数据集信息,包括数据集编号、各项字段等属性,具体见表2。

表2 自动监测数据Table 2 Automatic monitoring data
2.4 前后端通信接口设计
基于大数据的自定义可视化分析引擎使用前后端分离设计,通过接口使用RESTFUL 进行对接,设计接口完成数据传输。因为数据是研究的核心,所以如何设计数据接口非常重要。接口传输过程以Spring 提供的RestController 类为基础,使用RequestMapping 对输入参数进行定义,使用CommonResults 对象进行封装。
3 自定义可视化分析引擎测试与应用
首先配备服务器和浏览器客户端作为测试环境,然后对自定义可视化分析引擎的代码单元和功能性进行测试,确保系统正确运行。然后展示系统应用效果,这里以水土保持监控平台做实际例子来逐步展示整个引擎使用过程[10]。
3.1 系统测试环境
系统测试环境包括软件配置和硬件配置,具体配置内容需根据软件系统的运行需要而定。大数据自定义可视化分析引擎基于前后端分离进行设计,需部署的硬件设备包括各类服务器和客户端。具体配置如下:
3.1.1 服务器测试环境配置
Web 服务器:戴尔服务器(4 个i78700kCPU、128 GB 内存、12 T 硬盘Ubuntu18.04 系统),配置Java8 开发环境和Nginx1.8web 服务器、MySQL5.8数据库。
3.1.2 客户端测试环境配置
客户端设备型号选择Apple 公司于2018 年6月生产的配备2.3GHz 四核Intel Corei5 处理器、8GB RAM 和512GB 固态硬盘的MacBook Pro。使用Google 公司开发的Chrome 浏览器进行测试。
3.2 系统单元测试
完善的单元测试可以帮助开发者更好的维护复杂的基础代码,可以提供描述组件行为的文档,节省手动测试的时间,减少研发新特性时产生的bug,改进设计,促进重构。通过编写细致且有意义的单元测试,能够在构建新特性或重构已有代码的同时,保持应用的功能稳定。本课题的Vue.js 单元测试需要使用Jest 框架。Jest 是一个JavaScript测试框架,专注于简洁明快,可以并行运行测试。前端Vue.js 代码部分的测试步骤。首先添加Jest 测试框,执行vue add unit-jest 命令,执行完后项目根目录会多出一个tests 文件夹,在这里存放所有单元测试代码,文件后缀为.spec.js。当运行npm runtest:unit 之后这些文件就会被执行。环境搭建好后,做Vue.js 代码单元测试,测试方面有data数据类型、添加数据、删除数据、查询数据。在test/unit 下创建一个tstspec.js 文件用来写测试用例的代码,在研究中可以直接对操作进行测试,因为能确保该接口有数据:若不能确定接口是否有数据时,可以直接对接口进行验证,如果验证成功就证明查询成功。
最后通过配置jest.config.json 脚本来生成测试覆盖率报告,生成报告会降低单测的速度,配置中默认是关闭的,需要手动开启。生成的报告在根目录的coverage 文件夹下,可以通过package.json 配置命令行打开测试报告或者在控制台查看。通过测试报告得知,该系统单元测试结果全部通过,语句覆盖率(statementcoverage)58.32%,分支覆盖率(branch coverage)50%,函数覆盖率(functioncoverage)50%,行覆盖率(line coverage)59.5%。
3.3 系统功能测试
功能测试的主要内容是对所有模块各功能进行用例定义使用并记录结果。但是由于该系统功能数量较大,仅对重要的功能用例给出测试说明。
3.3.1 数据管理模块测试
(1) 创建数据集测试用例,测试用例编码CREATEDATALIST-TEST。
(2) 测试流程。管理人员点击系统菜单中数据管理,进入数据管理界面;管理人员选择某项数据源的创建数据集按钮,进入创建数据集页面;管理人员进行数据源选择,并选择所需字段;管理人员进一步处理数据,选择筛选字段,限制数据量,排序方式;将英文字段定义中文名称;连接成功,提示管理人员并提供数据预览功能。
(3) 输入数据。数据集编号,所属数据源ID,字段信息,筛选项,数据量限制,创建时间。
(4) 预期测试结果。系统根据用户新建进行数据添加,并提示添加成功。
(5) 实际测试结果。可以正确的添加数据,并正确的提示添加成功。
3.3.2 应用管理模块测试
(1) 应用发布测试用例,测试用例编码DAS HBOARDPUBLISH_TEST。
(2) 测试流程。管理人员点击驾驶舱构建页面中新建图表,打开卡片管理界面;管理人员选择数据,样式,图表类型和筛选项等选项,点击新增;新建成功,提示管理人员并在列表中变更状态。
(3) 输入数据。用户ID,应用编号。
(4) 预期测试结果。系统根据用户所选择进行发布,并提示发布成功,变更对应状态。
(5) 实际测试结果。系统根据用户所选择进行发布,正确提示发布成功,变更对应状态。
3.3.3 构建模块测试
(1) 卡片管理测试用例,测试用例编码CARDMANAGEMENT_TEST。
(2) 测试流程。管理人员点击构建页面中新建图表,打开卡片管理界面;管理人员选择数据、样式、图表类型和筛选项等选项,点击新增;新建成功,提示管理人员并在布局中正确显示卡片。
(3) 输入数据。数据卡片编号,依赖数据集编号,所属应用编号,卡片X 坐标,卡片Y 坐标,卡片宽度,卡片高度,卡片名称,卡片标示,卡片颜色,筛选类型,筛选值,图表类型,图表维度,图表数值1,图表数值2,创建时间。
(4) 预期测试结果。系统根据用户所填写数据对卡片进行操作并给予反馈,布局渲染出新的设计。
(5) 实际测试结果。系统能够根据用户所填写数据对卡片进行操作,并正确给予反馈,布局正确渲染出新的设计。
3.4 系统应用
首先进行数据连接,打开数据管理模块,点击“添加数据源”进入到数据源列表页,进行连接配置,填入与外部数据连接所必要的信息。mysql 数据源需要的配置项主要有服务器、端口号、用户名、密码和数据库名,并提供进度展示。配置好的监测系统登录界面如图4 所示。

图4 监测系统登录界面Fig.4 Monitoring system login interface
然后系统连接到库后,自动读入各项内容。如果是实时型数据库,系统会连接对应表来获取表内的数据,做数据预览,如图5 所示。

图5 监测界面预览Fig.5 Monitoring interface preview
数据源管理系统中还可以对创建的数据集进行管理。管理人员进入页面后会看到数据集列表、展示数据集名称、所属数据源、创建时间等信息,如图6 所示。

图6 数据管理界面Fig.6 Data management interface
管理功能的结构通过文件夹构成了各个业务的分析框架。管理人员可以在此进行新增、编辑、复制、移动、删除等操作,如图7 所示。

图7 数据文件夹Fig.7 Data folder
4 结论
(1) 根据自定义可视化分析引擎功能的分析和实际业务情况,利用软件开发技术,对自定义可视化分析引擎的网络架构、技术架构、功能模块、数据库以及终端与软件系统的接口进行设计,使其能够满足实际业务的需求。
(2) 设计了Web 端的框架和接口,包括前端请求接口和数据流访问接口,前端页面结构以及服务器的使用和项目部署。
(3) 对本系统进行了前端测试和后端测试。前端测试主要通过不同测试方式考察了前端页面渲染的性能、响应时间和易用性,后端测试了服务程序代码的运行状态,包括稳定性、运行时间和内存使用情况。测试结果表明系统的各个模块耦合良好,系统运行正常。
