基于神经网络的敏感文档检测*
2022-06-16沈麒宁
沈麒宁
(江苏科技大学 镇江 212000)
1 引言
随着近年来企业敏感信息外泄导致的安全事件频发,数据防泄漏技术逐渐成为国内外业界研究的热点,而电子文档作为主流的信息载体之一,如何将敏感文档准确识别出来,是实施防泄漏手段的前提。
目前主流的检测技术包括三类:基于关键字匹配、基于机器学习和基于神经网络。基于关键词匹配的检测方法的核心思想是:通过人工筛选出敏感信息的关键词构成词表,利用以AC 算法[1]、WM 算法[2]为代表的多模匹配算法将待测文本与词表进行对比,根据事先设定的阈值来判断文本内是否含有敏感信息。该方法依赖人工筛选关键词构造的关键词词表,最终的识别结果很大程度上取决于词典制定者的偏好;并且这种检测方法是完全与语义无关的,通过一些简单的词语替换即可规避。基于机器学习的检测方法将检测过程视为文本的二分类过程,根据人工事先标注的统计学特征学习并进行分类。如文献[3]提出了一种基于SVM 的敏感信息检测方法;文献[4]提出了一种基于敏感信息语义结构,通过上下文词共现关系的电子文档密级检测方法。文献[5]提出了一种基于K-近邻算法的利用加权语义相似度比对进行敏感信息检测的方法。这一类方法忽略了自然语言语序和上下文关系,导致模型对文本内容挖掘能力不足。文献[6~7]提出了利用RNN 的线性序列结构收集文本中的敏感信息,刻画特征并用于分类检测。受益于模型对文本语义的学习能力,此类方法的检测准确率通常高于机器学习方法。
在实际的检测场景中,一段文字是否敏感往往取决于上下文语境,例如“兵员部署”一词在军事类文档中是绝密,而在新闻和通俗读物中敏感程度不高。这对检测模型的文本语义表达能力提出很高的要求,而实际应用于训练的敏感文档样本往往数量有限。为此,本文提出一种基于改进的elmo[8]的检测模型,引入基于通用语料的预训练动态词向量丰富模型的语义表达能力,并构建数据集,通过与其他静态词向量表示模型进行比较,验证了方法的可行性和先进性。
2 基于elmo的预训练词向量
2.1 模型原理
Elmo 模型于2018 年由Peters M,Ammar W 等人提出,利用双向语言模型生成上下文相关的词向量,对于解决一词多义问题有很好的效果。该双向语言模型的目标函数为

在训练中,elmo 使用的是双向长短期记忆网络[9](Long Short-Term Memory,LSTM)。对于位置为k 的词wk,令其通过一个L 层的biLM 计算得到共2L+1个表示:
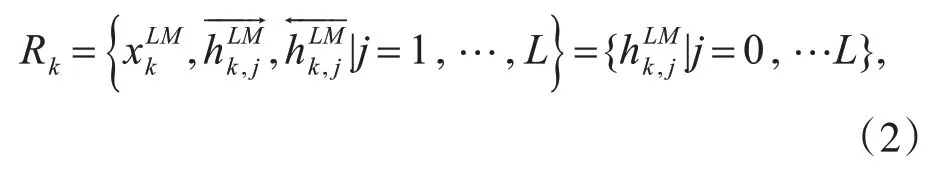
该模型结构如图1所示。
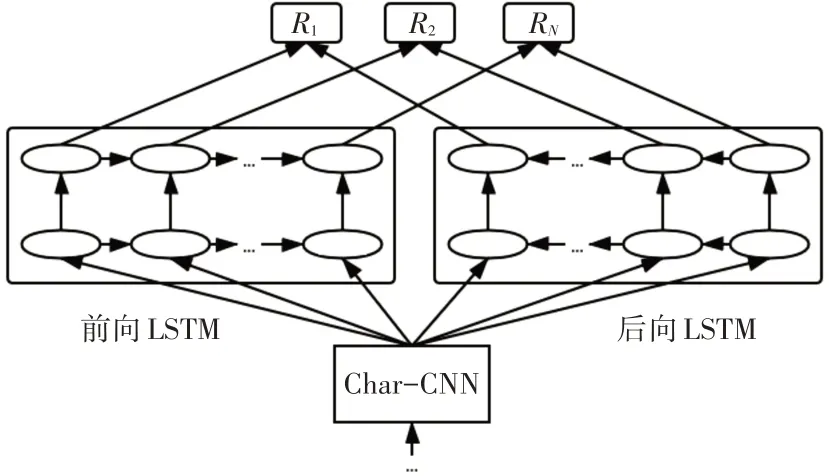
图1 Elmo模型结构
对于一个文本序列输入,首先使其通过字符卷积进行词向量的初始化,再将词向量分别送入两个双层的LSTM 网络并行训练,这里前向和后向LSTM 的网络参数是独立的。在需要使用时,可以简单地提取最上层的结果作为词的表示:E(Rk)=,也可以根据下游任务设置参数将所有层的结果组合从而压缩得到最终的词向量:
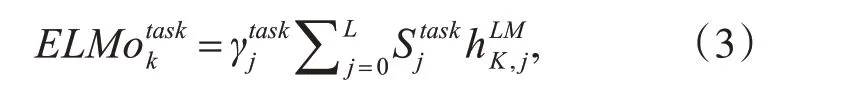
2.2 改进设计
对于输入层,原模型中使用字符级别的CNN对词向量进行初始化,对于英文单词可以很好地提取子词信息;在中文场景中,汉字不具备类似的语言学特性,因此本文选取Fasttext[10]作为初始化词向量的方法,一方面避免了多层叠神经网络的梯度消失问题,另一方面提高了预训练通用语料的利用率,加强词向量的文本表示能力。
由于LSTM 网络参数数量较多,训练时间过长,本文提出使用门限递归单元(Gated Recurrent Unit,GRU)[11]代替LSTM 单元结构。GRU 将LSTM单元结构中的遗忘门和输入门组合为更新门,同时隐去了单元的内部状态。它包括两个门限结构:重置门用于采集需要保留的输入向量和记忆信息;更新门用于记录当前时序需要更新的信息的权值状态。采用Bi-GRU 代替Bi-LSTM 可以在不损失词向量质量的同时进一步加快模型的训练速度。

图2 GRU的单元结构
从自然语言的角度,人们在顺序读取文本序列时理解文本内容比逆序读取时更容易,语义表达更明确。因此本文猜想双向语言模型中,前向网络和后向网络对词向量表示的贡献程度存在区别,前向网络贡献更大。为此,引入贡献参数θ,不同于原模型中将前后向网络输出拼接作为词表示的做法,以式(6)作为Bi-GRU的隐层输出。
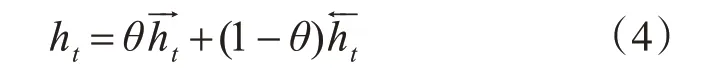
3 基于神经网络的敏感文档检测模型
本文提出的检测模型包括输入层、elmo 层、神经网络层和输出层。
3.1 输入层
未经处理的原始中文文本往往包含一些干扰和无用信息,为保证训练数据质量,必须对文本进行预处理。预处理的步骤包括去除符号、分词、去停用词等。
3.2 elmo层
elmo层的作用是生成词向量的表示,该网络基于一个较大的通用语料训练,因此网络结构保存了大量的语言学信息。将改进的elmo 模型整体迁移到下游任务中时,仅需要少量的标注数据集训练就可以达到较好的分类效果。预训练完成后,将待检测的敏感文本作为输入,根据式(3)、(4),以一定权重组合Bi-GRU 中同一位置不同层的词表示,从而完成对文本的向量化表示。
3.3 神经网络层
神经网络层接收词向量的序列矩阵并抽取文档特征,从而实现分类检测。本文选取文献[12]中提出的Text-CNN模型。该模型在处理文本分类任务时已经被证明可以取得较好的结果,并且相对RNN 模型具备高训练效率的优势。由于CNN 处理的是定长序列,因此需要根据训练样本集中的文本长度进行截断或填充。对于定长文本序列构成的二维矩阵,采用不同尺寸的卷积核以滑窗形式进行卷积,并采用1-max pooling对得到的特征图池化拼接得到最终的文本特征向量。
模型对敏感文档的检测流程如图3所示。
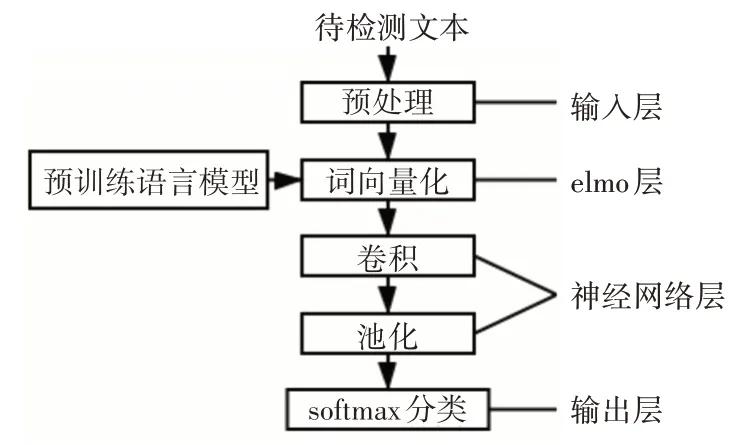
图3 敏感文档检测模型
4 实验
为验证模型的文本表达能力对敏感检测结果的影响,本文选取word2vec[13]、glove[14]两种静态词向量作为对照。word2vec 是一种基于局部信息预测的无监督训练模型[15],glove 是一种基于主题模型、依托全局语料中词的共现频率生成词向量的模型[16]。两者在文本分类领域中已经得到广泛应用并有着较好的效果,因此适合作为基线模型用于对比。
4.1 数据集
实验所需的数据集包含两部分,一是用于词向量训练的通用语料,二是用于下游分类任务的专项语料。针对词向量训练的无监督学习过程,本文选用了中文维基百科语料,从中随机选取20MB 左右的共13793 个文档作为预训练的通用语料;针对敏感信息检测任务,该任务是一种有监督学习任务,本文爬取了维基解密中的原涉密中文文本作为“敏感”标签的数据,从来源于搜狗实验室的搜狐新闻数据集中随机选取作为“非敏感”标签的数据。
4.2 实验结果
首先验证引入贡献参数θ的影响,在分类任务中θ取不同值时对准确率的影响如表1所示。

表1 不同θ 取值的影响
结果表明贡献参数θ=0.7 时,分类准确率最优,验证了引入参数θ区别前后向网络贡献的有效性。后续实验中的改进elmo-CNN 模型均将θ值设为0.7。同时在模型的训练过程中,与原elmo 模型对比发现,将Bi-LSTM 替换为Bi-GRU 后,模型每经过一个epoch 损失下降更多,网络训练的收敛速度加快。
为模拟实际检测场景中上下文语境变化对文本敏感程度的影响,从前述数据集中选取了“军事”和“政治”两大类别的文档,将其中来自维基解密的文档标注为敏感,来自搜狐新闻的文档标注为非敏感,形成对抗语境变化能力的测试集。结果如表2所示。

表2 不同预训练词向量的检测结果对比
从表2可以看出,使用改进的elmo作为预训练词向量的检测效果明显优于另外两者,提升幅度达到了6%左右。这是因为elmo 词向量根据下游文本的上下文即时生成,并且融合了语序和语法特征,故而其语义表达的能力高于word2vec 和glove。另外,在实际检测场景中,机构或企业往往由于业务领域的细分会存有大量处于同一类别的文档,能否在这些同领域文档中将敏感信息识别出来是评判检测算法实用性的重要依据。在本实验中设置类别相似而语境、语法发生改变的情况下,word2vec-CNN 和glove-CNN 的检测能力均存在明显下降,而改进的elmo-CNN 的检测准确度下降程度较小,验证了本文提出模型的优越性。
5 结语
本文构建了基于神经网络的敏感文档检测模型,通过引入预训练elmo 词向量利用卷积神经网络对敏感文档实施检测分类,缓解了敏感文档训练样本不足的问题;并对原elmo 模型作出改进,提高了模型的语义表达能力以应对敏感检测的复杂场景。实验表明本文提出检测模型是有效的,对敏感信息检测领域的应用具备一定参考价值。由于敏感文档的收集比较困难,在未来工作中,希望从提升验证数据集质量和提高文本特征抽取能力两个方面进一步对敏感信息检测方法进行研究。
