基于GRU 网络的会话型混合电商推荐算法*
2022-06-16李镇宇朱小龙周从华刘志锋
李镇宇 朱小龙 周从华 刘志锋
(1.江苏大学计算机科学与通信工程学院 镇江 212013)(2.江苏大学京口区新一代信息技术产业研究院 镇江 212013)
1 引言
随着大数据时代的到来,我们每个人都会成为海量数据的缔造者和接收者。当网络上海量数据呈献给我们的时候,我们很难在短时间内处理这么多的信息量。所以如何解决信息过载问题成为十分热门的研究话题。在电商领域,信息过载问题显得尤为严重。个性化推荐算法[1]就是为了解决这一问题而提出。目前主流的推荐算法有基于用户或物品的协同过滤推荐算法、基于内容的推荐算法、基于知识的推荐算法、基于社交网络的推荐等。
目前应用最普遍的推荐算法是协同过滤推荐算法[2],协同过滤推荐算法又分为两种:基于用户的协同过滤[3]和基于物品的协同过滤。基于用户协同过滤的主要思想是为相似度高的用户推荐可能喜欢的商品。基于物品的协同过滤算法[4]的主要思想是如果用户喜欢A 商品,物品B 与A 相似度高,则将物品B推荐给改用户。
如何解决推荐系统冷启动[5]问题成为学术界和工业界研究的一个焦点。文献[6]针对数据稀疏问题,使用基于内容的推荐算法[6],通过对商品属性的分析寻找拥有这些属性的其它商品并将其推荐给用户。但这种方法由于仅仅依赖商品本身属性导致给出的推荐结果并没有做到个性化。文献[7]采用矩阵分解技术,通过构建用户-物品矩阵可以简单高效地提供准确率不错的推荐结果。尽管矩阵分解技术比较有吸引力,但该技术并未考虑数据的时间变异性。最近,基于递归神经网络[8]的推荐算法通过考虑用户和物品的时间特性,取得了不错的推荐准确度而受到关注。递归神经网络有很多种,LSTM 网络[9]就是其中的一种。Huijuan 等[10]采用LSTM 神经网络获取用户的短期偏好,然后将用户长期偏好与短期偏好进行结合,得出最终的推荐结果。这种方法比只考虑长期因素的推荐算法准确度有所提高,但是由于对用户短期偏好获取过程中对用户浏览过的物品采取同样的权重,导致很难获取到用户的真实意图。比如用户在浏览衣服类商品的时候,被几个无关的商品短暂的吸引然后点击后很快就离开。这种情况下不应该对无关商品做过多的关注。
针对以上传统推荐算法存在的问题,本文提出一种基于门限循环单元(GRU)[11]的会话型推荐算法。首先,获取用户和商品信息构建用户-项目矩阵。然后,按照时间顺序划分数据集得到用户序列和商品序列。然后通过将用户、商品序列化数据输入到GRU 网络中得到数据在短期内随时间变化状态特征。同时将矩阵分解算法得到的用户、商品特征作为全局因素来计算GRU 网络中每个隐藏状态的权重,由此判断用户的主要意图。得到用户和商品的特征表示后,通过使用一种双线性差值匹配机制来计算用户和个物品间的相似度,这种方法不仅减少了模型参数而且提升了准确率。
2 门限循环单元网络
在实际生产环境中,虽然LSTM 网络已经取得了不错的成绩。但由于其训练过程比较复杂,所以在它的基础上演变出很多变体。门限循环单元网络(Gated Recurrent Unit,GRU)便是其常见变体的一种。GRU 网络解决循环神经网络中梯度消失和梯度爆炸的问题。其单元结构图如图1所示。
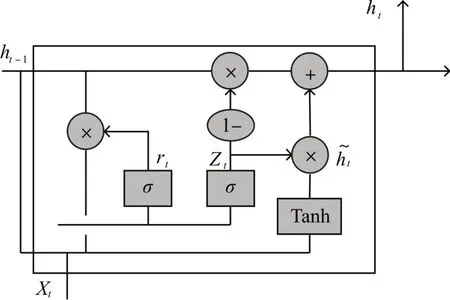
图1 GRU单元结构示意图
其中Zt代表更新门,更新门的作用类似于LSTM 中的遗忘门,他能决定要丢弃哪些信息和要增加哪些新信息,更新门的值越大说明前一时刻的状态信息带入的越多。Rt代表重置门,重置门决定丢弃之前信息的程度,重置门的值越小说明忽略的越多。
更新门的计算公式如下所示:
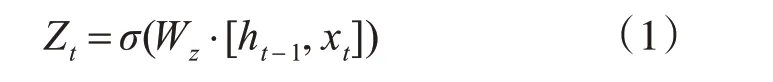
其中,Wz表示更新门的权重;σ表示Sigmoid 激活函数,ht-1表示在t-1 时刻的隐藏状态,Xt表示在t时刻的输入向量。更新门的作用是将t-1时刻的隐藏状态和t时刻的输入信息相加的结果压缩到一个大于0 小于1 的值,以此来表示有多少隐藏状态和当前状态信息可以被传递到下一时刻。
重置门的计算公式如下所示:

其中,Wr表示重置门的权重,σ表示Sigmoid 激活函数,ht-1表示在t-1 时刻的隐藏状态,xt表示在t时刻的输入向量,重置门的作用是通过将对ht-1和xt的线性变换结果压缩至0~1 的范围内,这个值决定了前一时刻有多少信息会被遗忘。
当前记忆的计算公式如下所示:
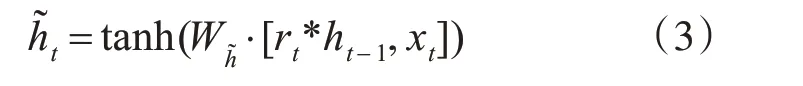
通过更新门决定前一时刻信息和当前时刻的记忆内容需要保留多少信息到当前时刻,将两部分信息相加即得到当前时刻的最终记忆内容。ht的计算公式如下所示:
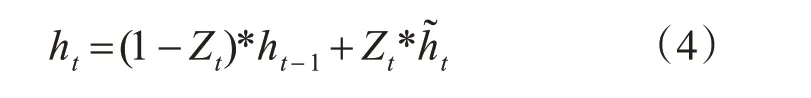
3 基于门限循环单元的会话型推荐算法
3.1 模型的提出动机
传统的矩阵分解算法通过对用户长期偏好的获取虽然能在一定程度上为用户提供商品推荐,但由于其没有考虑到用户的兴趣可能会随着时间发生改变导致其在用户短期偏好的预测上存在明显缺点。一些基于神经网络的推荐算法解决了用户短期偏好的获取问题,却在神经网络的长期偏好的预测上存在短板。当然也有文章将这两种算法进行结合提出一种混合推荐模型[12],但其使用的网络模型计算复杂、模型训练过程中需要学习众多参数,因此需要使用很大的空间和时间来保存和训练这些参数。基于对以上算法存在的缺点的思考,我们提出了基于门限循环单元的会话型混合推荐算法。具体来说,我们通过门限循环单元网络训练用户和商品按时间划分的序列化数据,得到用户和商品的隐藏表示。在此过程中通过矩阵分解得到的用户和商品的全局因素,通过注意力机制得到t 时刻的上下文向量并将上下文向量作为额外的输入用来计算下一时刻的隐藏层状态。通过使用注意力机制[13]计算上下文向量的好处是赋予用户真正关注的商品更大的权重、发掘用户的真实意图。
3.2 基于门限循环单元的推荐算法
在本文中,我们使用门限循环单元作为循环神经网络的基本单元,将用户和商品数据按照时间顺序进行划分并将这个时间序列作为循环神经网络的输入,输入数据通过转换从高维稀疏变为稠密的隐藏层向量表示。得到用户和商品在t时刻的特征向量表示之后,通过计算这两个向量之间的相似程度可以判断出用户购买这件商品的可能性。例如,输入的用户i 时间序列为,…,,GRU网络将输入的时序数据转换为高维的隐藏层表示。其中表示用户i 在t 时刻的隐含特征向量表示。的计算公式为
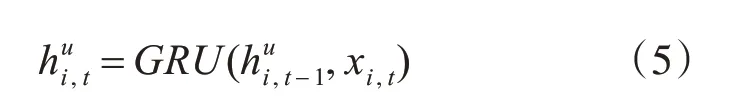
用同样的方法可以求得商品j 在t 时刻的隐含特征向量表示。其中,表示商品j 在t 时刻的隐含向量表示。的计算公式如下:

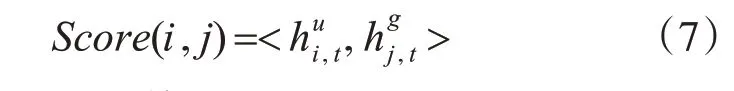
3.3 矩阵分解推荐算法
矩阵分解算法在目前的推荐系统中应用非常广泛并取得了非常好的效果。矩阵分解的基本原理是通过建模用户-项目评分矩阵,将用户-项目矩阵分解为两个矩阵的乘积[14]。例如,有m 个用户、n件商品、用户对商品的评分矩阵Sm×n,可以将Sm×n分解为矩阵P 和矩阵Q 的乘积,计算公式如下所示:
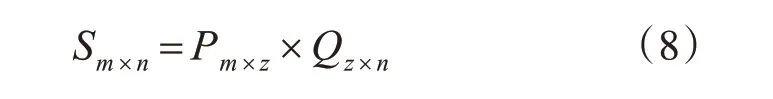
其中矩阵P 为m*z 维,矩阵Q 为z*n 维,z 代表主题的个数。则P 矩阵代表了用户和z 个主题的关系,Q 矩阵代表了z 个主题和商品之间的关系。z 个主题具体是什么需要根据实际情况设置,一般为一个10~100 以内的整数。矩阵P 的第i 行代表第i 位用户的全局隐含因子,记为。矩阵Q 的第j行代表第j件商品的全局隐含因子,记为。
通过矩阵P 和矩阵Q 的乘积可以计算出用户-项目矩阵中的缺失值,这些缺失值即为某一用户对某一商品的评分值,将评分高的商品推荐给用户即可。
3.4 基于门限循环单元的会话型混合推荐算法
本文提出的基于门限循环单元的会话型推荐算法[15]的基本思想是构建一个当前会话的隐藏表示,然后基于这个隐藏表示生成当前会话的下一次预测结果。混合模型中将对用户-物品矩阵进行矩阵分解得到的用户、商品全局因子作为GRU 网络的上下文向量并用于隐藏层状态的初始化。模型的整体结构如图2所示。
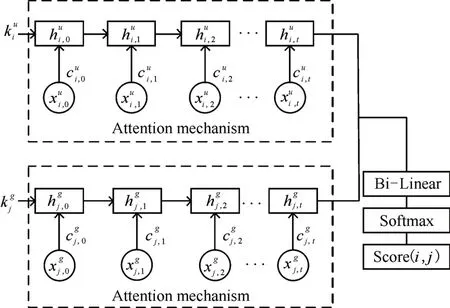
图2 推荐模型整体结构示意图

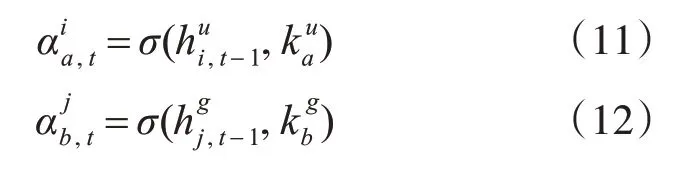
其中,σ为一种前馈神经网络。
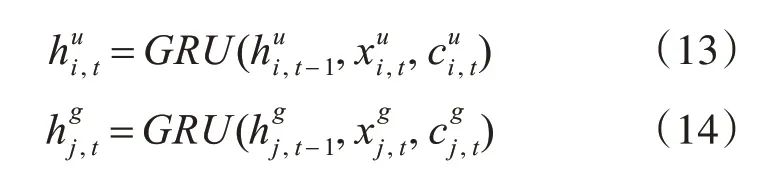
对于隐藏层状态的解码我们没有使用传统的全连接层,因为使用全连接层需要训练的参数众多,需要耗费很大的时间和空间。所以在这里我们使用一种双线性差值法来计算用户隐藏状态和商品隐藏状态之间相关性数值,然后用softmax 函数对相关性数值进行归一化得到最终评分。计算相关性的公式如下所示:

其中W 是一个双线性插值法的参数矩阵,W 矩阵的维度远远小于使用全连接层作为隐藏层状态解码器的矩阵维度。
最终的相关性评分Score(i,j)计算公式为
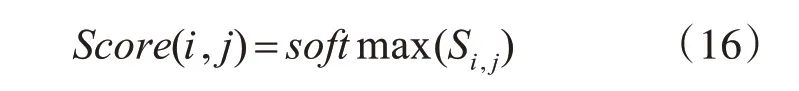
将用户i 对各个商品的相关性评分进行排序,将得分高的相关商品推荐给用户。
4 实验
4.1 实验环境和数据
实验环境:编译工具Python 3.6.2,操作系统Windows7,处理器Intel(R)Core(TM)i5-3337U,主频1.8GHz,运行内存16G,硬盘容量1T。
实验数据集:RecSys 2015 YOOCHOOSE 数据集和CIKM Cup 2016的DIGINETICA 数据集。选取两个数据集中的点击流历史数据,过滤掉其中被点击次数小于6 的商品和点击流长度小于3 的会话。过滤后,YOOCHOOSE 数据集保留了6174930 条会话和30817 件商品,DIGINETICA 数据集保留了188317条会话和38523件商品。
4.2 评价指标
1)Recall(召回率)
该指标用来表示用户真实点击的商品数占推荐物品个数的比例[16]。该指标不考虑推荐列表中商品的顺序,即只要出现在推荐列表中即可。Recall的计算公式如下所示:
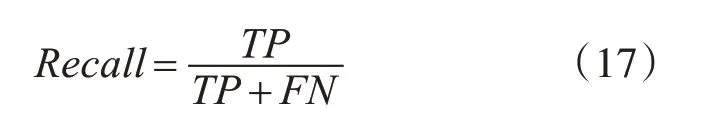
其中TP和FN的具体含义如表1所示。

表1 预测结果与真实情况的误差矩阵
2)MRR(平均倒数排名)
平均倒数排名是推荐领域常见的评价机制,如果第一个结果匹配则分数为1,如果n 个结果匹配则分数为1/n,如果点击的商品没有出现在推荐列表中则值为0。最后将所有匹配的结果分数值加起来求均值即可。MRR 的值越大说明更多排名靠前推荐结果被用户点击、推荐结果越符合用户的需求。平均倒数排名的计算公式如下所示:

其中,Q为样本集合,ranki为i在集合中的排名。
4.3 实验结果与分析
我们将本文提出的基于GRU 网络的会话型混合推荐模型(HGRU)与几种流行的推荐性算法进行对比。分别为POP、Session-POP、GRU-Rec、Improved GRU-Rec。
POP 算法的原理是将整个训练集中出现频率最高的商品推荐给用户,这种基于流行度的算法原理比较简单,但很多时候也能取得不错的推荐效果。
Session-POP 算法的原理是将当前会话情境下最受欢迎的商品推荐给用户。
GRU-Rec算法[17]是一种利用GRU网络训练序列化数据的推荐算法模型,该模型使用了并行计算和优化随机负采样方式的策略。
Improved GRU-Rec 算 法[18]是Y.K.Tan 等 提 出的一种在GRU-Rec 基础上改进的会话型推荐算法,该算法使用了数据增强等方式使得模型的表现有显著提高。
HGRU 和四个对比算法在YOOCHOOSE 数据集和DIGINETICA 数据集上的实验结果如表2 所示,推荐列表中商品的个数设置为20。
从表2的实验结果对比图中可以看出:
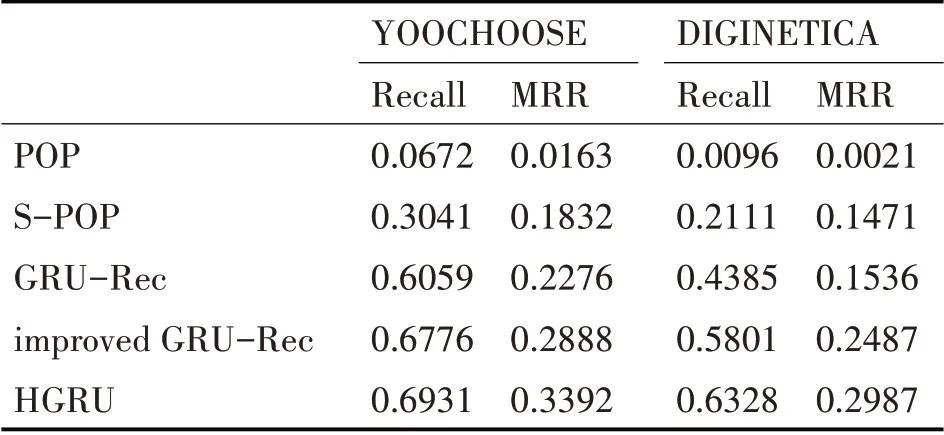
表2 HGRU与其他算法的实验结果对比
1)总体来说基于GRU 网络的推荐算法效果要明显好于两种基于流行度推荐算法。基于时间序列的会话型推荐算法效果明显更好。
2)S-POP 算法由于考虑了当前会话的上下文情况,选择当前会话有关的热门商品进行推荐,推荐效果与POP算法比有明显改善。
3)Improved GRU-Rec 算法在Recall 和MRR 两个指标上都要优于GRU-Rec算法。
4)由实验结果可以看出HGRU 算法比Improved GRU-Rec 在两个评价指标上都有所提高,特别是通过MRR 指标可以看出HGRU 算法推荐的结果中,用户真实点击的物品是在列表中比较靠前的。这也从侧面印证了该算法确实正确捕捉了用户当前的主要意图。
将HGRU 算法与目前相关领域比较受欢迎的Improved GRU-Rec 算法在推荐列表个数变化的情况下,对比两种算法在Recall 和MRR 两个指标在DIGINETICA 数据集上的表现情况,Recall 指标的对比结果如图3所示。
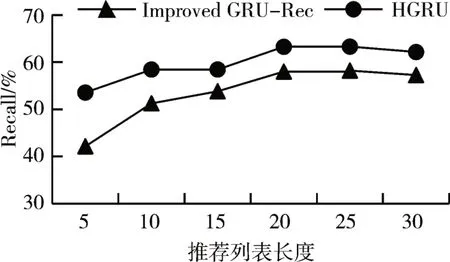
图3 DIGINETICA数据集上两种算法Recall对比图
两种算法在DIGINETICA 数据集上的MRR 指标的对比结果如图4所示。
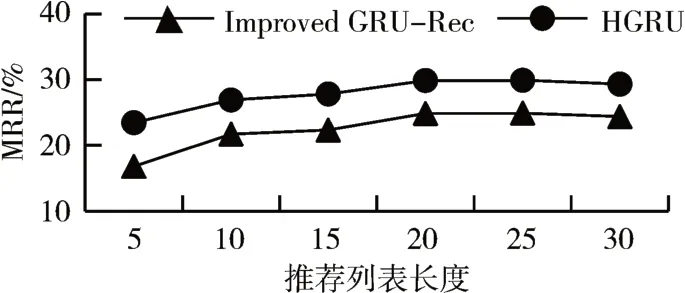
图4 DIGINETICA数据集上两种算法MRR对比图
通过图3 的实验结果可以看出:在DIGINETICA数据集上,HGRU算法的Recall指标效果总体上都要好于Improved GRU-Rec 算法。通过图4 的折线图可以看出HGRU算法不仅提高了召回率,在平均倒数排名这个指标上比起Improved GRU-Rec 算法也有明显的提升。
由于HGRU 中使用了注意力机制来获取用户的主要意图,所以接下来我们将没有使用注意力机制的情况(记为HGRU-WA)与HGRU 算法进行对比。
HGRU-WA 算法仍然保留了矩阵分解得到的全局因素作为GRU 网络中计算隐藏层节点的额外输入,只不过使用的是全部的全局因素。
在YOOCHOOSE 数据集和DIGINETICA 数据集上对HGRU 算法与HGRU-WA 算法进行对比实验,实验结果如表3所示。
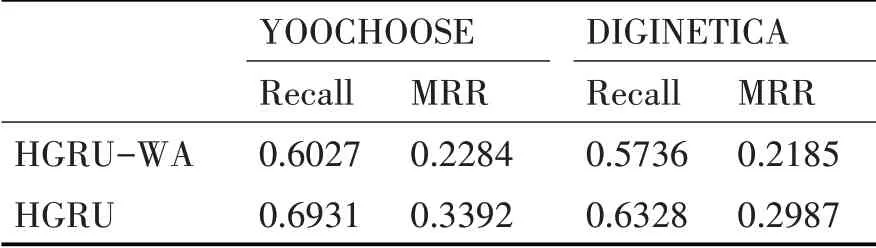
表3 HGRU与HGRU-WA算法的实验结果对比
通过表3的结果可以得到如下结论:
1)HGRU 算法和HGRU-WA 算法在两个数据集上的运行效果差距是非常明显的,使用了注意力机制的运行效果要明显好于没有使用注意力机制的情况。
2)HGRU-WA 算法的效果虽然相对差了一些,但由于该算法也同时考虑了用户全局因素和当前的短期偏好,效果比起传统的流行度算法比如POP、S-POP等还是有一个明显的提升。
5 结语
本文针对电商个性化推荐算法领域中传统会话型推荐算法缺乏对用户长期信息的考察、未能识别用户当前主要购买意图、模型训练参数众多且需要占用大量的空间和时间等问题,提出了一种结合了循环神经网络和矩阵分解的HGRU 算法模型。该算法中循环神经网络部分系采用了GRU 网络。GRU 网络可以通过用户的序列化操作判断出用户的短期兴趣。矩阵分解算法在模型中起到提供全局因素的作用,通过注意力机制可以将全局因素赋予不同的权重用于GRU 网络中隐藏层的计算。注意力机制用于判断用户的主要购买意图、忽略无关的操作以提高推荐效果。
