基于集成深度学习方法的跨被试EEG 特征情感识别*
2022-06-16唐杰豪
唐杰豪 张 维 尹 钟
(上海理工大学光电信息与计算机工程学院 上海 200093)
1 引言
情感计算是实现高级人机交互的关键技术之一,是人工智能领域中日益受到关注的研究方向。情感识别可利用人的面部表情、语音、姿势、文本、和生理信号识别作为模型输入[1]。基于生理信号的情感计算能反映人内在的心理生理过程。数据模态形式包括脑电、心电、肌电、皮肤电阻、皮肤电导、皮温、光电脉搏、呼吸信号等。此外,近年来国内外有诸多工作利用机器学习方法作为建立生理数据驱动模型的基础,结果表明这些技术对人脑电信号(Electroencephalogram,EEG)的分析是可行的。
集成学习是通过构建并结合多个弱学习器来完成学习任务的方法,即“博采众长”,可以用于分类问题、回归问题、特征选择、异常点检测等的集成。由于现在计算能力不断增强,随着训练数据量的增加,大型神经网络的算法性能与传统的机器学习算法相比体现出越来越大的优越性,而且深度模型有很大的参数量,具有灵活、可调整性大的特点,使得研究者可以更快地验证自己的想法,以便不断试错而得到更好的想法。
本研究的目的是将传统的机器学习算法与集成深度学习的方法应用于跨被试的EEG 特征情感识别任务中,通过比较结果来证明集成深度学习方法的优势。
2 相关工作
相关领域已有不少工作取得了好成绩。文献[2]中将同一时间段,不同通道的信号组合成一个向量,输入至双峰深度自编码器(Bimodal Deep AutoEncoder,BDAE)中,生成EEG 特征。最终得到效价(Valence),唤醒度(Arousal),支配度(Dominance),喜爱度(Liking)维度的情感识别精度分别为85.2%、80.5%、84.9%、82.4%。文献[3]将多元经验模式分解产生的(Intrinsic Mode Function,IMF)归一化,并在其中提取功率谱密度(Power Spectrum Density,PSD)、高阶统计量(Higher Order Statistic,HOS)等特征,再经过独立成分分析(Independent Component Analysis,ICA)进行处理,分别得到valence、arousal 维度的二分类精度为72.87±4.68%、75.00±7.48%。文献[4]采用巴特沃斯滤波器获取θ、α、β三个频段的时域信号,并在此基础上分别计算双频谱功率,最终取得了61.17%、64.84%的valence、arousal 维度二类情感识别精度。文献[5]中将数据集按照熟悉度分为低熟悉度(1 分~2分)和高熟悉度(3 分~5 分)两部分,以分形维度(Fractal Dimension,FD)和PSD 作为特征,结果得到valence、arousal 维度二分类的结果为73.30%、72.50%。
文献[6]中利用快速傅里叶变换(Fast Fourier Transform,FFT)计算功率作为特征,使用了概率神经网络(Probabilistic Neural Network,PNN)模型,得到valence、arousal 维 度 二 分 类 结 果81.21% 、81.76%。文献[7]对数据集里60s 的数据只用后40s 的数据进行实验,将θ、α、低频β(lower beta)、高频β(upper beta)、γ频段的数据每个频段分为3个子频段,在每个子频段上用短时傅里叶变换(Short-Time Fourier Transform,STFT)计算PSD,使用了堆叠降噪自动编码器(Stacked Denoising Auto Encoder,SDAE)和深度信念网络(Deep Belief Network,DBN),其中基于DBN 的模型在arousal、valence、liking 维度上的F1 值分别达到86.67%,86.60%和86.69%。文献[8]用长度为4s的窗将60s的数据分为15 段,计算512 点的FFT 来分离波段,对每个波段求能量,并且用ReliefF 算法进行特征选择给出了排名前15 的通道高频波段,最后valence和arousal维度二分类结果为60%左右。
3 方法
3.1 数据集介绍
第一个数据集是DEAP[9]数据集。32个参与者(被试)参与数据采集实验,每个被试在观看经过选择的40 个不同类型的长度为1min(在这之前有3秒预采样的准备时间)的视频的同时,以512Hz 采集32 通道的EEG 脑电信号,经过预处理后再下采样至128Hz。数据集每个被试的数据分为两个数组,一个是data 数组,格式为40×40×8064(视频/试验×通道×数据),另一个是labels数组,格式为40×4(视频/试验×标签)。标签在Valence,Arousal,Dominance,Liking 四个维度上表示为1~9 的连续值。
第二个数据集是HCI[10]数据集。27 个被试参与数据采集实验,采集的信息包括面部视频,音频信号,眼动数据,周围/中枢神经系统的生理信号。在数据采集实验中,被试观看了20 个情绪视频,并使用Valence,Arousal,Dominance,可预测性(Predictability)以及情绪关键词来自我报告他们的情绪感受。
3.2 数据预处理
在DEAP 中,根据国际10-20 标准,取前32 个电极作为进一步分析。DEAP 数据集有公共参考电极,所以每个电极的电压可确定;在HCI中,同样取32 个通道分析,但HCI无公共参考电极,故取32个导联电极的平均作为公共参考点,每个电极的电势减去此公共参考点即为电压。用巴特沃斯带宽滤波器对数据进行滤波,只保留4Hz~45Hz的数据,参考文献[11]并作修改,分为四个频段,分别为θ(4Hz~8Hz)、α(8Hz~14Hz)、β(15Hz~30Hz)、γ(30Hz~45Hz)。
一个频段内每个被试的一个试验的数据8064个点的数据表示为63s×128Hz,在此去除前3s 的信号,保留后60s 的数据,数组变为(32,60×128)即(32,7680),经过改变形状后为(60,32×128)。选用valence 和arousal 维度作为分类任务的标签,两个数据集处理方法相同,数值小于5.0 标记为0,大于等于5.0 则标记为1,即可把标签转换为二分类标签。
3.3 特征提取
取每秒内每个频道的128 个数据点,参考文献[12],采用微分熵(Differential Entropy,DE)作为工具做特征提取,由:
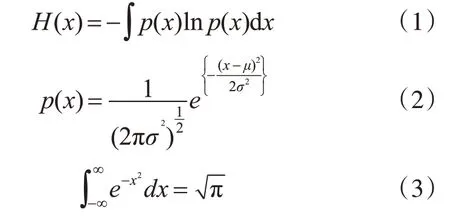
可得:
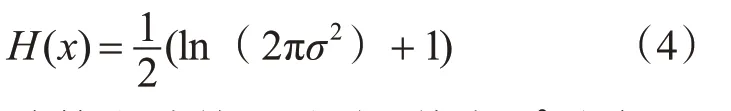
式(4)为计算微分熵的公式,其中σ2为每秒128 个点的数据的方差。经过特征提取后数组形状变为(40×60,32),同理其他三个频段重复此提取过程,再将32 个被试的数据拼接起来,数据集最终处理为(32×2400,32×4)即(76800,128)。HCI只取24 个被试做研究,预处理与特征提取过程类似,经过处理后数据集的形状为(24×2400,128),即(28800,128)。DEAP 数据集提取了微分熵特征后未进行归一化处理,HCI 数据集经过了归一化处理。
3.4 机器学习模型
本研究选取线性分类器(Logistic)、支持向量机(Support Vector Machine,SVM)、K 近邻(K-nearest Neighbor,KNN)、朴素贝叶斯、决策树(Decision Tree)对数据集进行评估。模型使用的最佳参数通过网格搜索、hyperopt工具调参而得到。
3.5 集成模型
本研究采用两种集成学习的方法对EEG 的两个数据集进行分析:Boosting,Bagging。
梯度提升树(Gradient Boosting Decision Tree,GBDT)是一种迭代的决策树算法,是Boosting 家族的成员,GBDT 的核心在于每一个弱学习器学习的是上一轮迭代结论和的残差,即残差与预测值之和等于真实值。XGBoost(eXtreme Gradient Boosting)[13]是Gradient Boosting 算法的高效实现,而且做了许多优化,故将其应用在本研究中。Adaboost(Adaptive Boosting)[14]是一种自适应的boosting 算法,它的自适应在于:前一个基本分类器分错的样本会得到加强,加权后的全体样本再次被用来训练下一个基本分类器。同时,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数。随机森林(Random Forest,RF)是对Bagging算法的改进,基本学习器限定为决策树,一个样本的分类结果由多棵决策树综合决定。
同样,四个集成模型使用的最佳参数通过网格搜索和hyperopt工具进行调参而得到。
3.6 深度学习模型
3.6.1 深度神经网络
参考文献[15]的DNN 网络结构,本研究使用的深层神经网络(Deep Neural Network,DNN)有4个全连接层。第一层输入层有128 个神经元,层后连接 参数keep_prob=0.25 的Dropout 层。隐藏层1和隐藏层2 的神经元个数分别是2000 和200,其后连接的是keep_prob=0.5 的Dropout 层。这三个隐藏层都以线性整流函数(Rectified Linear Unit,Re-LU)作为激活函数。输出层有两个神经元,使用Softmax 函数作为激活函数,输出one-hot 编码形式的标签。DNN的结构如图1所示。
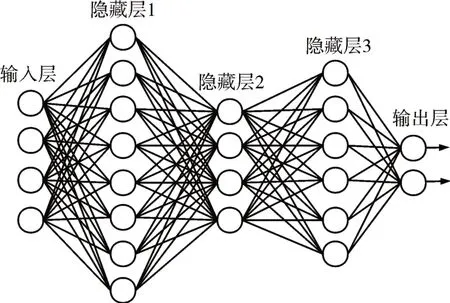
图1 DNN网络结构
3.6.2 卷积神经网络
本研究将卷积神经网络(Convolutional Neural Network,CNN)应用于情感识别的分类任务中,模型结构如图2所示。把DEAP数据集的形状重塑为(76800,16,8,1),即把每个样本看作一个长16宽8通道数为1 的图片矩阵,相对应的HCI 数据集的形状重塑为(28800,16,8,1)。模型第2、3 层都为卷积层,第2 层有64 个神经元,第3 层有128 个神经元,都使用3×3的卷积核以及双曲正切函数(hyperbolic tangent function,tanh)作为激活函数,函数表达式如下:
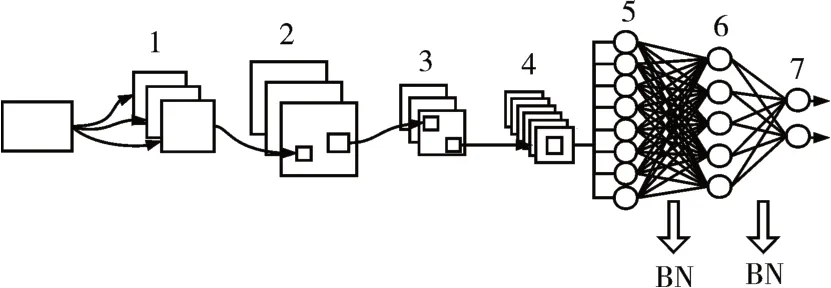
图2 CNN深度模型结构
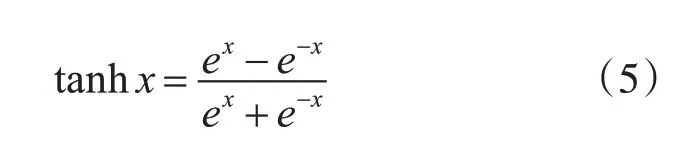
4 是一个最大池化层(max pooling),池化窗口大小为2×2。模型在经过第5 层的flatten 操作后连接的是间隔着批量归一化(BatchNormalization,BN)层[16]的全连接层,BN 层的作用是把数据归一化,防止训练发生偏移,加快训练速度。全连接层6 有128 个神经元,其中加入了L2 正则化以减小过拟合。输出层7的激活函数为Softmax。
3.6.3 GoogLeNet
受集成模型中模型融合策略的启发,多模型结合进行分类任务一般会提高结果的准确率,因此本研究尝试使用一个用于计算机视觉的经典的卷积神经网络架构——GoogLeNet[17]来对EEG数据集进行分析。本研究参考GoogLeNet 而使用的深度模型的结构如表1,Inception module 如图3 所示,其中加入了L2正则化以减小过拟合,第40层Dropout层的参数keep_prob=0.6。

表1 GoogLeNet 网络结构
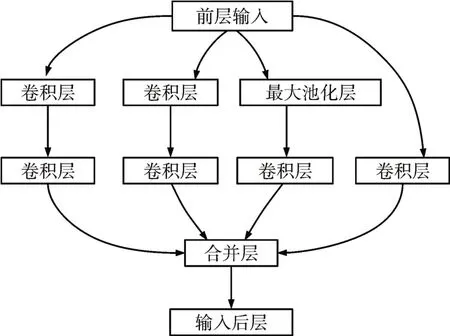
图3 Inception module 结构
3.7 训练方法
本研究中机器学习模型、集成模型与深度模型对数据集样本的训练统一采用K-折交叉验证(K-fold cross validation)的方法(K=32)来达到跨被试研究的目的,即每一次验证取31个被试的74400个样本作为训练集,另外1个被试的2400个样本作验证集进行训练。机器学习模型与集成模型使用准确率(accuracy)、roc 分数(roc-score)作为指标记录下验证集的结果,深度模型使用准确率作为指标记录下每个被试验证的结果。深度模型的参数设置如表2。
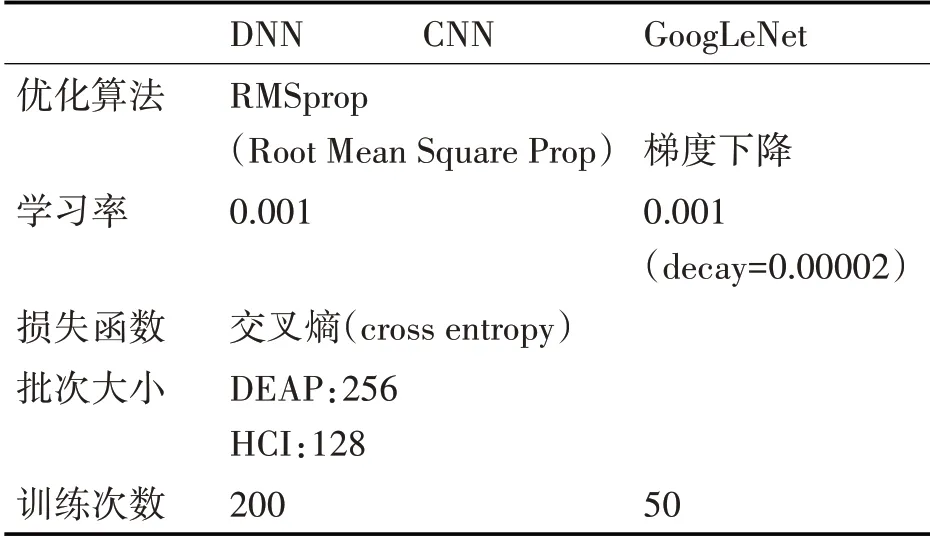
表2 深度模型参数
4 结果与分析
4.1 机器学习模型实验结果
logistic、SVM、KNN、朴素贝叶斯、决策树对DEAP、HCI 两个数据集得到的跨被试交叉验证的准确率(accuracy)与roc 的结果取平均如表3(两个数据集每一列的最大值用粗体表示,最小值用斜体表示),其中SVM 在两个数据集上的跨被试分类准确率箱型图如图4。
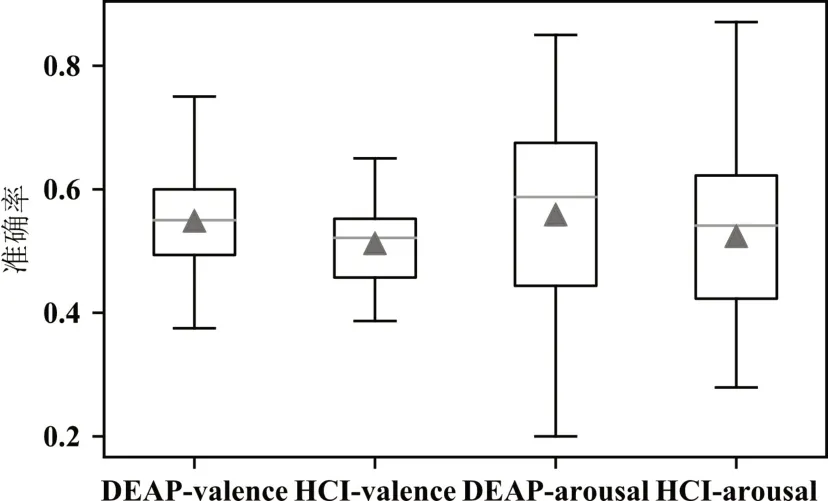
图4 SVM模型的准确率跨被试曲线
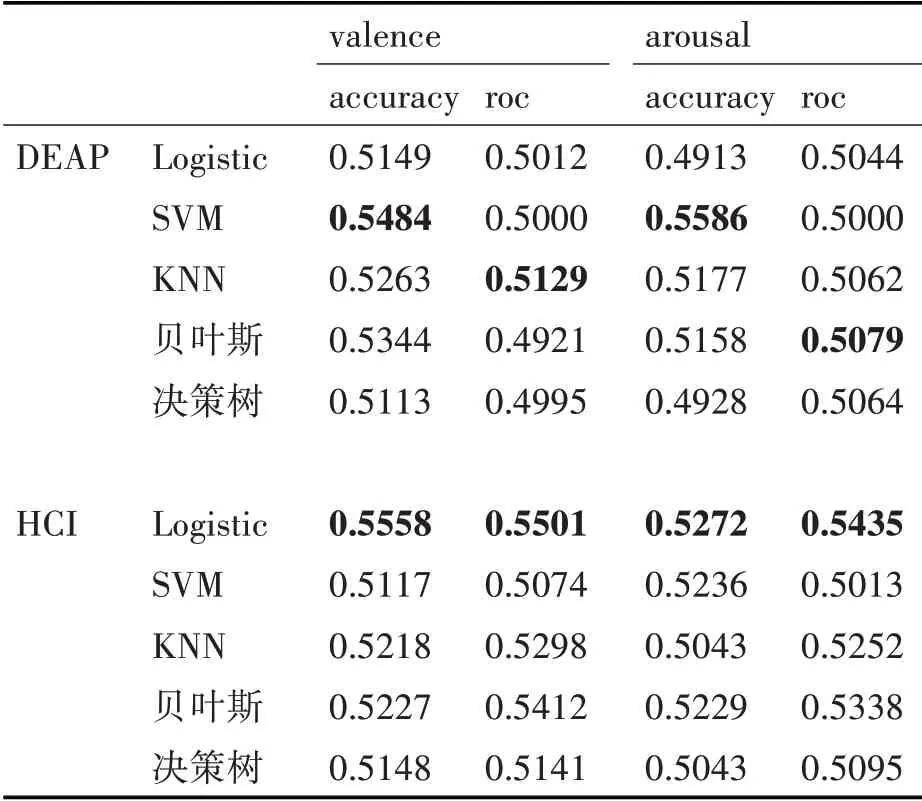
表3 机器学习模型跨被试分类平均结果
4.2 集成模型实验结果
集成学习中的GBDT、Xgboost、Adaboost、随机森林(RF)四个模型对两个数据集进行跨被试交叉验证的准确率、roc 结果取平均如表4(两个数据集每一列的最大值用粗体表示,最小值用斜体表示)所示。其中Adaboost 在两个数据集上的跨被试分类准确率箱型图如图5。

表4 集成模型跨被试分类平均结果
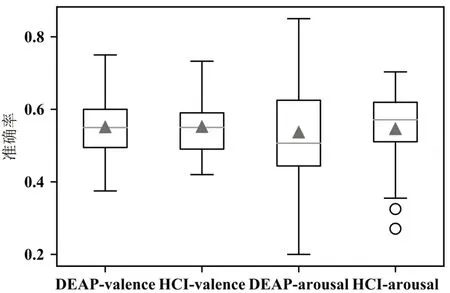
图5 Adaboost模型的准确率跨被试曲线
4.3 深度模型实验结果
深度学习的三个模型对两个数据集进行交叉验证得到的准确率的结果的平均如表5(每一列的最大值用粗体表示,最小值用斜体表示)所示,每个模型在DEAP 的valence、arousal 上的准确率曲线如图6,在HCI 的valence、arousal 上的准确率曲线如图7。
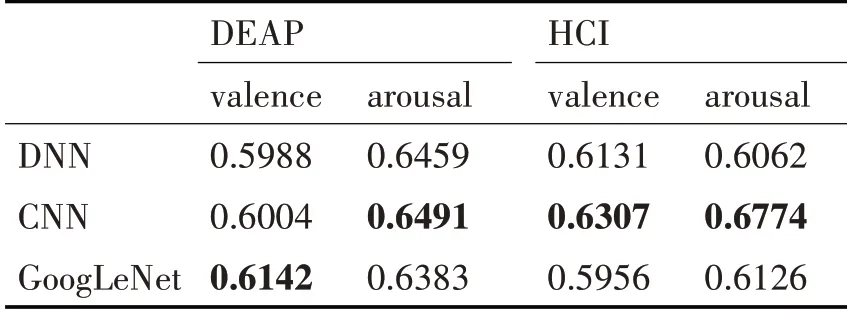
表5 深度模型跨被试分类准确率平均结果
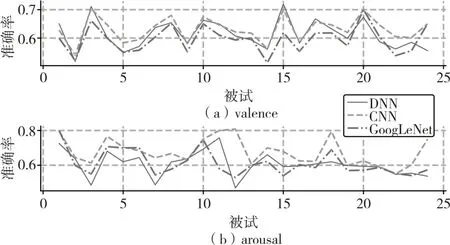
图7 深度模型在HCI数据集上的准确率跨被试曲线
4.4 分析
从表3中可以看出DEAP数据集中取得较高准确率的机器学习算法为SVM算法,HCI数据集中取得较高准确率的为Logistic;表4 显示DEAP 数据集中准确率结果较高的集成模型为随机森林模型,而HCI 数据集中Xgboost 与Adaboost 则取得了较好的结果。集成模型取得的平均准确率与机器学习模型相差不大但略优于机器学习模型的结果。对比图4、5,SVM 与Adaboost 模型的识别准确率比较接近,在valence 上的跨被试准确率数据相比arousal更集中。由表5 可得深度模型在DEAP、HCI 上的valence 和arousal 上的平均准确率分别为0.5988~0.6142、0.6383~0.6491、0.5956~0.6307、0.6062~0.6774。 将三个方法对两个数据集的valence 和arousal 维度取得最好结果的模型进行总结如表6,总体而言在三个方法中,深度学习的方法取得的成绩是最好的,且明显优于机器学习算法与集成模型。
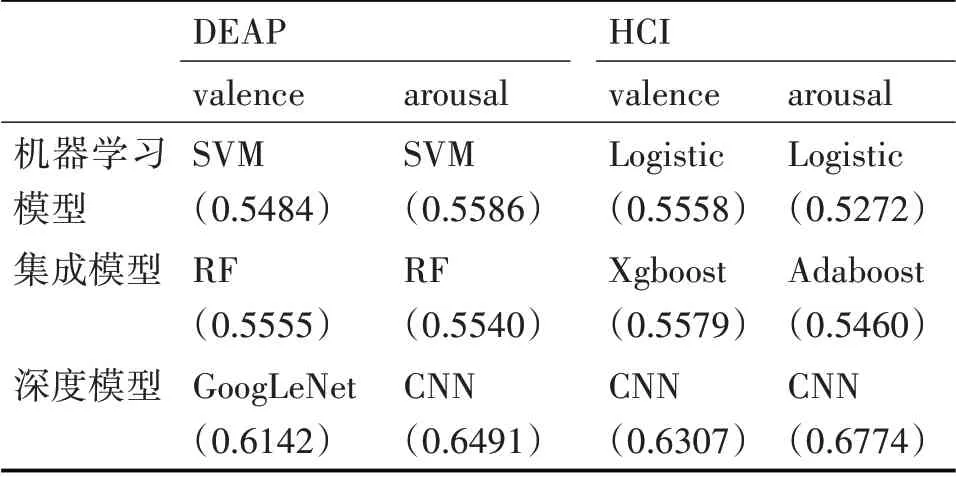
表6 各方法准确率的比较
5 结语
在脑电信号EEG 的特征情感识别中,集成学习具有高效的算法以及模型融合的优点,深度学习方法的神经网络模型参数量大、复杂度高,在样本数量足够多的情况下,深度神经网络能利用样本数据训练出更好的模型。本研究尝试将应用于计算机视觉领域的卷积神经网络模型和复杂度更高的GoogLeNet 架构应用于EEG 的情感识别上,结果没有明显优于使用其他深度模型得到的结果,说明了采取更合适的策略和模型是很重要的。总体而言,本研究利用微分熵作为特征提取工具的基于集成深度学习方法对EEG 的跨被试特征情感识别取得了较好的识别结果。后续可采取效果更好的特征提取方式和模型对研究方法进行优化。
