基于时序特征的网络流量分类方法
2022-06-15赵力强师智斌雷海卫
赵力强, 师智斌, 石 琼, 雷海卫
( 中北大学 大数据学院, 山西 太原 030051)
0 引 言
伴随互联网的迅猛发展, 网络管理以及网络安全方面呈现出越来越高的复杂性, 给网络服务的高效性和安全性带来巨大挑战. 网络流量分类作为应对这一难题的有效方法引起了国内外学者的极大兴趣. 近年来, 大量机器学习算法被用来分类网络流量[1-2].
网络流量分类领域的机器学习算法分为传统机器学习和深度学习两种[3].
应用在流量分类领域的传统机器学习方法有支持向量机[4]、 决策树[5]和贝叶斯[6]等. Moore等[7]设计了249个流量统计特征, 通过结合不同传统机器学习算法, 实现了网络流量的分类. Shafiq等[8]采用支持向量机、 C4.5决策树、 朴素贝叶斯、 贝叶斯网络实现了网络流量分类. 传统机器学习的分类效果取决于人工设计特征的好坏, 需要大量领域内知识, 面对日益复杂的流量分类问题, 设计合适的流量特征变得愈发困难.
深度学习不依赖人工设计特征, 通过对输入数据进行高维特征自主学习得到原始数据的高维特征表示[9]. 王勇等[3]将Moore数据集[7]中的249个特征归一化处理后映射成灰度图片作为输入, 利用改进的卷积神经网络实现了流量特征自主学习的分类模型. Wang等[10]使用原始流量数据作为输入, 利用卷积神经网络实现特征自主学习的同时提高了分类的精度. 但是, 深度学习方法自主学习到的高维特征过于抽象, 不可解释, 无法为网络管理者提供更多的决策依据.
网络流量作为典型的时序数据, 也有研究人员采用基于时序的方法进行分类. Acar等[11]将网络流表示为传输层数据包大小的序列, 利用筛选后的时序特征结合多种传统机器学习算法构造最佳分类器, 实现了网络流量分类. Conti等[12]利用传输层的数据包字节大小生成3个时间序列来表示流, 将流量分类问题抽象为多维时间序列的分类问题. 文献[13] 中提出了一种基于循环神经网络的网络流量分类方法, 利用LSTM自主学习每个数据包的时序特征以及数据包之间的序列关系来用于最终分类. 上述基于时序特性的分类方法仍然不能兼顾特征自主学习与可解释性, 无法为决策提供必要的依据.
在时序分类领域, 基于shapelet的时序分类方法具有可解释性强、 准确率高、 可以自主学习时序特征等优点, 成为近几年分类研究的热点. shapelet表示在形状上具有足够的辨识度, 是最大程度表征一类时间序列的子序列. 因此, shapelet可以表示一类时序数据的特征, 具有可解释优点, 通过提取shapelet, 可以进一步分析数据特点, 实现数据深层次理解, 提供优质决策依据. shapelet最早在文献[14]中提出, 研究人员遍历所有子序列后, 利用信息增益选出分类能力最佳的shapelet, 同时结合决策树构建了分类器. 初始shapelet算法只能与决策树结合构建分类器, 针对这一缺陷, Hills等[15]提出Shapelet-Transform算法, 通过单次扫描筛选出分类能力最佳的k个shapelet后, 利用这k个shapelet作为特征完成时序数据的转化, 转换后的时序数据可以结合大部分机器学习算法构建分类器.
针对以上研究, 本文提出一种基于时序特征的网络流量分类方法, 引入Shapelet-Transform算法用于挖掘网络流量的时序特征, 同时改进Shapelet-Transform使其可以处理大规模网络流量数据集. 本文所提方法可以从时间序列表示的网络流量中挖掘出形状上最具有辨识度的子序列作为特征, 避免人工设计特征的问题, 分类精度接近深度学习方法, 同时还可对分类依据作进一步解释.
1 网络流量数据分析
1.1 流量数据集
本文希望能够从流量数据中自主学习到时序特征, 因此, 实验数据选择提供原始流量的USTC-TFC2016数据集[13], 共包含10种恶意流量数据与10种正常流量数据, 具体信息如表 1、 表 2 所示.
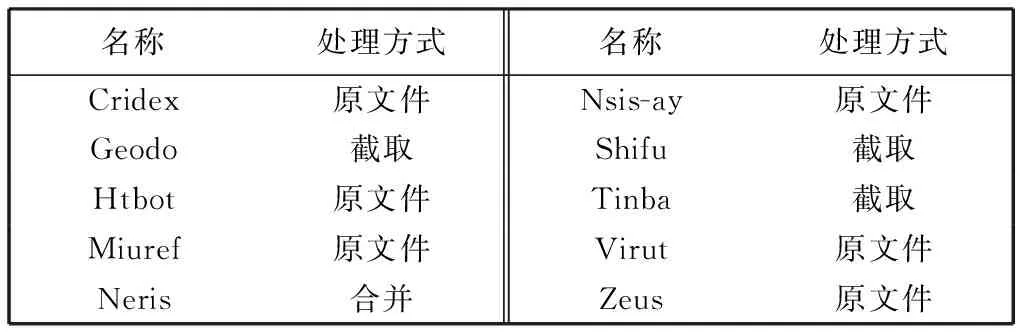
表 1 恶意流量数据集信息Tab.1 Information of malware traffic dataset

表 2 正常流量数据集信息Tab.2 Information of normal traffic dataset
1.2 网络流量数据分析
网络流量按粒度可以分为: TCP连接、 会话、 流、 服务和主机[16]. 其中, 流由五元组(源IP、 目的IP、 源端口、 目的端口、 传输层协议)相同的所有包(packet)组成; 会话由双向流的所有包组成, 比单独的流包含更多的交互信息[13]. 因此, 本文以会话为粒度将流量处理为多个离散单元, 同时保留会话中每个包的所有协议层次.
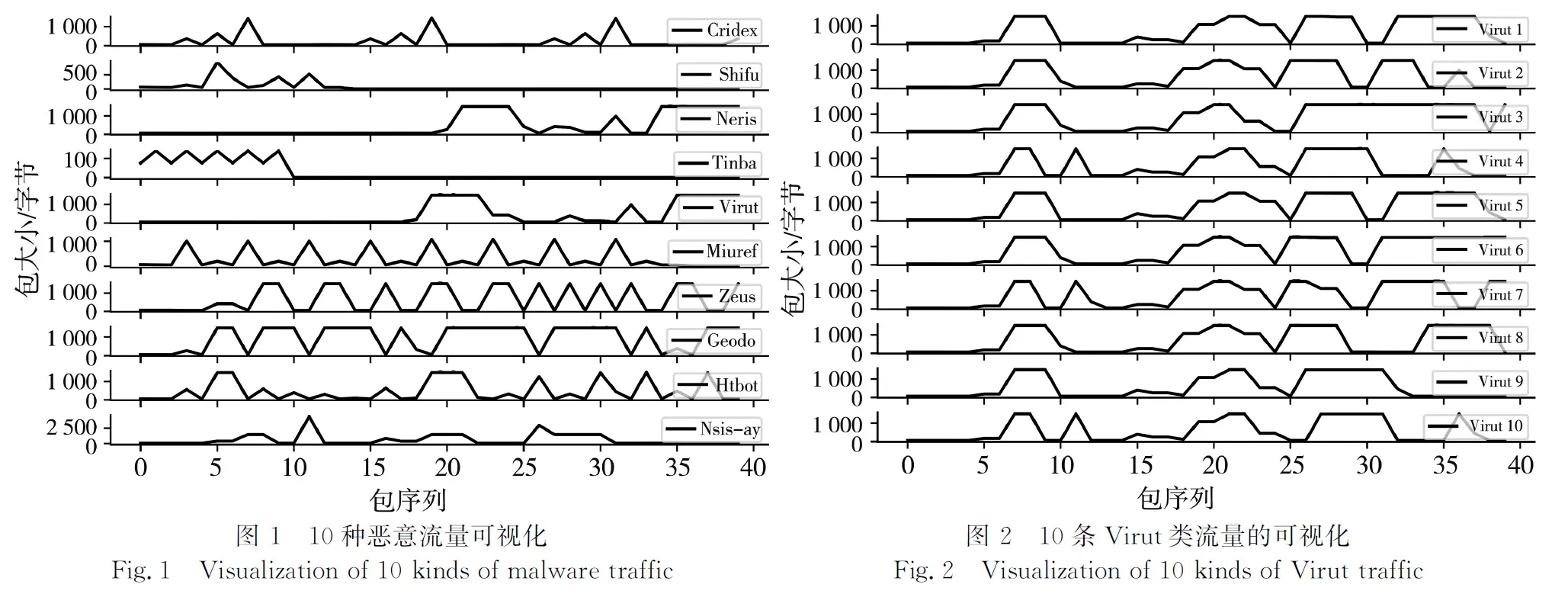
进一步将会话表示为由包大小(packet size)组成的等长时间序列, 其中包大小以字节(byte)为单位, 可视化结果如图 1、 图 2 所示. 从图中可以看出, 将会话表示为时间序列后, 不同种类的流量之间表现出较高的区分度, 同一种流量生成的时间序列却明显相似, 具有很多相似的子序列. 因此表明, 流量数据, 特别是恶意流量, 带有丰富的时序特征, 通过从表示会话的流量时间序列中提取表征时序特征的子序列, 可以很好地将不同种类的流量区分开, 实现网络流量分类.
2 基于时序特征的网络流量分类方法
本文所提方法对网络流量进行分类的核心思想是先对数据集进行预处理, 然后基于Shapelet-Transform算法自主学习其时序特征, 同时利用学习到的时序特征将预处理后的流量数据转化为特征向量, 结合支持向量机(SVM)构造分类器完成分类. 整体架构如图 3 所示.

图 3 基于时序特征的网络流量分类方法架构Fig.3 Framework of the network traffic classification method based on time series features
2.1 数据预处理
针对Shapelet-Transform算法能够从时间序列中挖掘出最具有代表性的子序列(shapelet)的特点, 设计了流量数据预处理流程. 将数据集中原始流量数据(pcap格式)经过流量切分、 时序数据生成、 统一长度等步骤处理为等长时间序列的集合.
步骤1: 以会话即双向流为流量粒度, 借助SplitCap工具实现每一类流量的切分并且保留包的所有协议层次.
步骤2: 提取会话中的包大小构建时序数据, 以字节为单位解析会话, 获取包大小, 组成时间序列.
步骤3: 每个会话中的包数量并不完全相同, 需要统一时间序列长度. 由于随着输入序列长度的增加, 计算量会呈指数级增长, 因此, 综合考虑分类精度与计算用时, 确定时间序列长度为40. 如果序列长度大于40则截取, 小于40则在其后用0补充, 统一长度后的时间序列连同其类别一起作为Shapelet-Transform的输入数据. 这与文献[3]和文献[13]中确定输入数据形式的思路类似.
2.2 基于Shapelet-Transform算法的时序特征挖掘
基于Shapelet-Transform算法挖掘网络流量的时序特征分为三个阶段. 第一阶段: 单次扫描挖掘出分类能力最强的k个shapelet作为时序特征; 第二阶段: 通过聚类去掉k个时序特征中相似的部分; 第三阶段: 利用聚类优化后的特征集合完成时序数据的转化.
2.2.1 最佳的k个时序特征的挖掘
第一阶段主要分为三个部分: 生成候选shapelet集合、 相似度测量、 shapelet分类能力评估. 第一阶段结束后, 可以得到包含k个分类能力最强的shapelet的时序特征集合.
预处理后的网络流量时序数据集为T={T1,T2,…,Tn}, 每一个Ti对应一个类标签ci.第一阶段的具体过程如算法1所示.
算法 1挖掘最佳的k个shapelet
输入: 时序数据集T, 候选shapelet的最小长度min, 最大长度max, 要保留的shapelet数目k
输出:k个shapelet
1)kShapelets←∅
2) for allTiinTdo
3) shapelets←∅
4) forl←min to max do
5)Wi,l←generateCandidates(Ti,l)
6) for all subsequenceSinWi,ldo
7)Ds←findDistances(S,T)
8) quality←assessCandidates(S,Ds)
9) shapelets.add(S, quality)
10) sortByQuality(shapelets)
11) removeSelfSimilar(shapelets)
12)kShapelets←merge(k,kShapelets, shapelets)
13) returnkShapelets
算法1中第2~5行表示生成候选shapelet集合, 利用不同长度的滑动窗口遍历时间序列Ti, 从而找到长度在min和max之间的所有子序列. 第7行针对每一个候选shapelet进行相似度测量, 即计算长度为l的shapelet与T中每一个Ti之间的距离, 具体的公式为
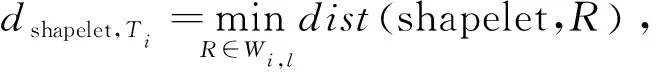
(1)
式中:Wi,l为Ti中所有长度为l的子序列集合,dist函数为求解两个等长时间序列间欧式距离的公式.通过相似度测量可以得到一个距离列表Dshapelet=〈ds,1,ds,2,…,ds,n〉,ds,i表示该shapelet和Ti之间的距离.
第8行评估每一个候选shapelet的分类能力. Shapelet-Transform算法引入F-statistic(F统计量)作为shapelet分类能力评估标准, 公式为

(2)
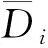
第11行针对来自同一Ti的shapelet集合, 去掉了其中自相似的部分. 第13行返回了时序数据集T中分类能力最强的k个shapelet.
算法1可以挖掘出分类能力最佳的k个shapelet作为时序特征, 但需要大量计算, 超出了CPU计算模式的处理能力. 因此, 本文在2.3节改写算法1的计算逻辑, 利用GPU缩短运算时间. 由于算法1并未考虑来自不同Ti的shapelet可能存在相似的情况, 所以仍需对时序特征集进行聚类, 去掉其中相似的部分.
2.2.2 时序特征集聚类
第一阶段得到的时序特征集中, 可能存在多个shapelet彼此相似, 需要对shapelet集合聚类, 去掉其中相似的shapelet. 在时序特征集中, 参照式(1) 计算shapelet之间的相似度, 构建k×k相似矩阵. 将相似度最高的两个shapelet归为一类, 只保留其中分类能力评估值更高的shapelet. 重复上述操作, 直到剩下的shapelet集合满足预先设定的停止条件. 聚类后, 只保留10个shapelet, 在第三阶段用这10个shapelet完成时序数据集的转化.
2.2.3 网络流量时序数据集转化
经过聚类后的shapelet集合为S=〈s1,s2,…,s10〉, 其中,sj表示第j个shapelet,j=1,2,…,10.利用集合S可以将时序数据集T中的每一个Ti转化为特征向量Ti-transform=〈ds1,Ti,ds2,Ti,…,ds10,Ti〉, 其中,dsj,Ti表示Ti与sj之间的距离值, 由式(1)可得.时序数据集T经过转化后, 符合大部分机器学习方法的输入要求.
2.3 基于GPU的改进算法
算法1计算时间较长, 无法处理大规模网络流量数据, 因此本文引入GPU加速计算过程. GPU包含很多独立的计算核心, 可以并行处理大量简单计算, 但GPU的计算逻辑与CPU有着本质区别, 需要重新设计算法1, 将其中的循环结构改为流式处理的矩阵运算. 具体过程如算法2所示.
算法 2基于GPU挖掘最佳k个shapelet
输入: 时序数据集T, 候选shapelet的最小长度min, 最大长度max, 要保留的shapelet数目k
输出:k个shapelet
1)kShapelets←∅
2) candidatesAll= cut(T, min, max )
3) for allTiinTdo
4) shapelet←∅
5)D←∅
6) Stream=StreamDesign(candidatesAll, min, max,Ti)
7) for all streamjin Stream do
8)Dtemp= GPU_calculate(streamj)
9)D.add(Dtemp)
10) quality←assessCandidaates(candidatesTi,D)
11) shapelets.add(candidatesTi, quality)
12) sortByQuality(shapelets)
13) removeSelfSimilar(shapelets)
14)kShapelets←merge(k,kShapelet,shapelets)
15) returnkShapelets
算法2中第2行得到不同长度的候选shapelet, 保存在多维矩阵candidatesAll中. 第6行针对每个Ti设计流式处理结构. 第7~8行替代了算法1中第4~7行实际运行时的循环结构, 流式处理了Ti中所有候选shapelet的相似度测量. 第10行整体评估了Ti中的候选shapelet.
为了测试基于GPU改进算法的效果, 本文对整个训练数据集以及随机选取的1 000条网络流量数据预处理后, 分别利用算法1与算法2进行时序特征挖掘, 实验结果如表 3 所示.

表 3 两种算法计算用时对比Tab. 3 Comparison of calculation time with two algorithms
实验结果证明, 本文所提优化方法大幅度缩减了计算用时. 尽管时序特征挖掘可以离线进行, 并不影响分类的速度, 但是算法1在处理大规模数据集时耗时过长, 因此对其进行改进是必要的.
2.4 分类模型训练
本文基于SVM构造2分类器和10分类器, 2分类器用于分类正常流量和恶意流量; 10分类器实现普通流量10分类和恶意流量10分类.
10分类器基于one-against-all[17]实现. 构造10个SVM二分类模型后, 依次将训练集中的每一种流量作为正样本, 其余流量作为负样本, 利用本文方法从不同的正负样本中自主学习更适合的特征用于训练分类模型.
以恶意流量10分类器训练为例, 其训练流程如图 4 所示. 首先将恶意流量训练集中的Virut类流量标记为正样本, 其他9类恶意流量标记为负样本. 然后利用本文方法从正负样本中自主学习10个最佳的时序特征来完成训练集的转化, 利用转化后的数据集训练SVM分类模型. 依此类推, 直至10个分类模型训练完毕.

图 4 多分类器训练流程Fig.4 Training process of multiple classifiers
3 实验结果与分析
为了验证本文方法的可行性, 在USTC-TFC2016数据集[13]上实验了所提算法, 数据集总大小为3.71 GB, 随机选取9/10作为训练数据, 剩余1/10作为测试数据. 其它实验环境参数如表 4 所示.

表 4 实验环境参数Tab.4 Parameters of experimental environment
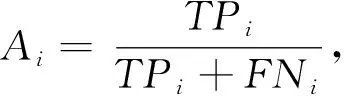
根据评价指标的各个参数进行实验, 具体实验结果和文献[13]中基于深度学习的方法进行对比, 结果如表 5~表 7 所示.
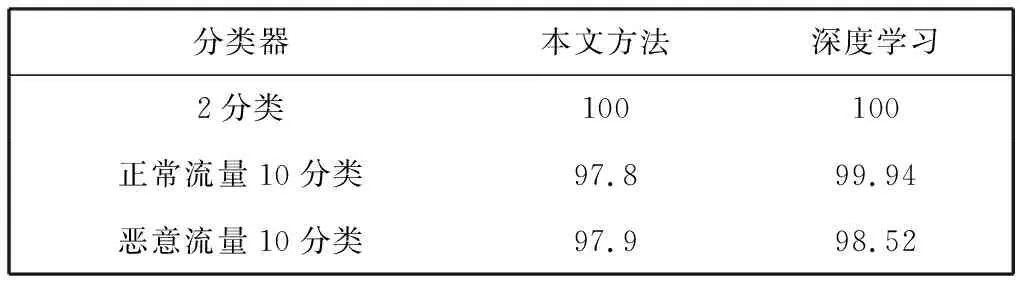
表 5 不同分类器的整体准确率Tab.5 Overall accuracy of different classifiers %
实验结果表明, 本文设计的2分类器的准确率较高, 10分类器的准确率接近深度学习方法. 相较于深度学习的黑盒属性使其结果不可解释, 本文方法在分类精度接近深度学习的情况下可以解释分类过程的识别依据, 可以用于进一步分析流量特性. 以下从两个方面进行分析.
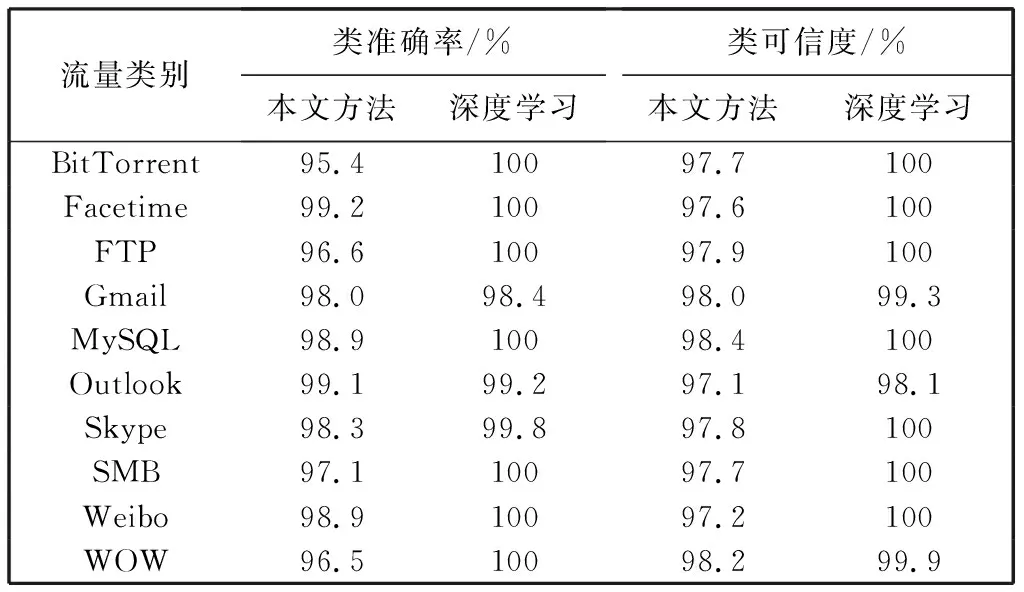
表 6 正常流量10分类的类准确率和类可信度Tab.6 Class accuracy and class reliability of normal traffic 10 classification
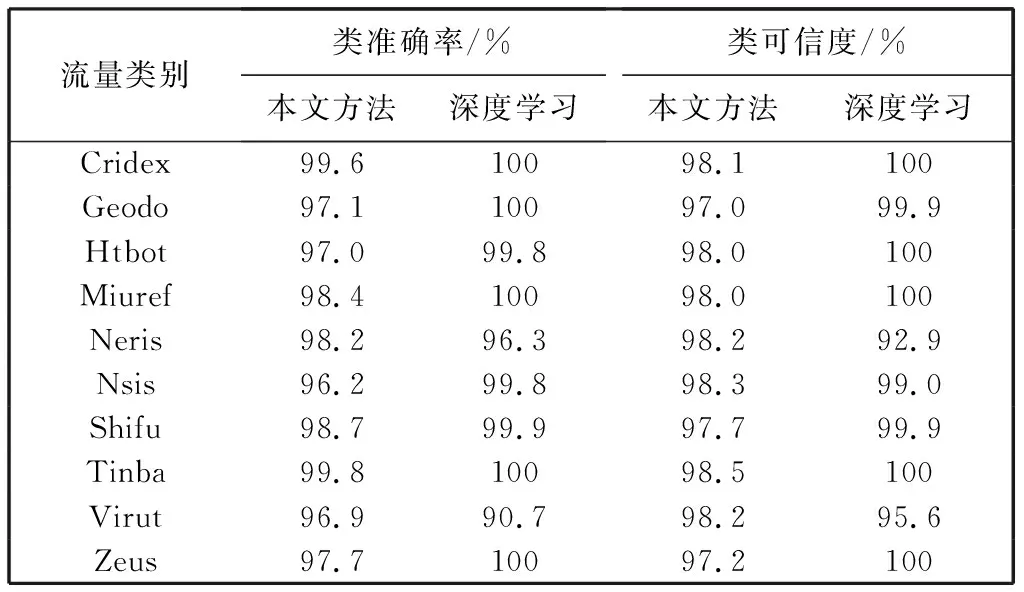
表 7 恶意流量10分类的类准确率和类可信度Tab.7 Class accuracy and class reliability of malwaretraffic 10 classification
1) 时序特征解释
以恶意流量10分类器为例, 在Miuref类数据为正样本, 其余为负样本的SVM模型中, 所提方法从正负样本中共挖掘出10个适合的shapelet作为分类特征, 对来自Miuref类的2个shapelet和随机选取的2个来自其他类的shapelet可视化, 将其表示在一条Miuref流量上, 如图 5 所示, 其中, shapelet1和shapelet2属于Miuref类, shapelet3和shapelet4属于其他类.

图 5 shapelet可视化Fig.5 Visualization of shapelets
从图 5 可以看出, shapelet1、 shapelet2和Miuref类流量的某些子序列相似度很高, 而shapelet3、 shapelet4则与该类流量明显不同. 利用这些shapelet对数据集进行转化, 可以得到区分度很高的特征向量, 使用SVM模型可以很好地将Miuref类和其他类流量区分开.
2) 流量特性分析
以恶意流量Htbot为例, Htbot是一种木马网络, 可以通过一种隐蔽的方式控制计算机并进行远程访问. 本文从正样本为Htbot类, 其余类别为负样本的训练集中, 自主学习到10个shapelet作为分类特征, 其中有2个来自于Htbot类, 将其可视化表示在随机选取的一条Htbot流量上, 如图 6 所示.
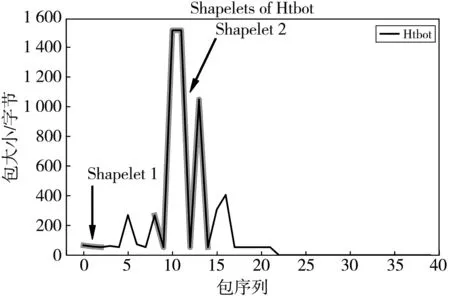
图 6 Htbot类流量shapelet可视化Fig.6 Visualization of Htbot shapelets
图 6 中横坐标轴8~14之间的shapelet2表示了该类流量的某种特殊的包大小变化方式, 其中, 第10个, 第11个包大小超过1 400字节, 进一步分析流量数据可以发现, 这是Htbot的病毒主机在向宿主机传递指令. 本文方法可以很好地挖掘出这一特性, 提供给网络管理者关于Htbot流量的更多细节.
4 结束语
本文首先分别介绍了基于传统机器学习与深度学习的网络流量分类方法, 然后在相关研究的基础上, 提出了一种基于时序特征的分类方法, 首次引入Shapelet-Transform用于自主学习可解释的网络流量时序特征, 同时重新设计算法计算逻辑将其部署在GPU上, 进而可以处理大规模网络流量数据, 并结合SVM构造最优分类模型, 最终实现网络流量分类. 为了验证分类方法的可行性, 利用现有数据集进行实验分析, 将原始流量数据输入所提方法中, 可以自主学习到可解释的时序特征, 同时得到较高的分类精度. 在将来的工作中将针对以下几个方面做进一步研究: 1)探讨更多网络流量可能的时序表达方式; 2)针对Shapelet-Transform算法做进一步优化, 加速运算; 3)将本文所提方法部署在大数据平台之上用于实时处理大规模网络流量分类问题.
