基于Holt-Winters及长短期记忆的云资源组合预测模型
2022-06-14李新飞谢晓兰
李新飞, 谢晓兰,2*
(1. 桂林理工大学信息科学与工程学院, 桂林 541004; 2. 广西嵌入式技术与智能系统重点实验室, 桂林 541004)
容器技术凭借着其灵活、弹性、高效、快速的特点促使了容器云的快速发展,缓解了使用者在有限计算资源和激增的应用需求之间的矛盾。容器云可以更高效地利用海量计算资源,从而弹性地进行业务扩展,充分满足了用户平常时期与爆发时期的业务需求。基于容器的技术(如Docker)作为基础设施即服务 (IaaS) 级别的轻量级虚拟化解决方案和 PaaS 级别的应用程序管理解决方案,促进了从容器中的单个应用程序到可以跨集群主机运行容器化应用程序的容器主机集群,越来越受到关注和使用[1]。
传统云计算的资源池化和快速弹性可以快速动态地分配给消费者所需资源,弹性地提供基于需求的内外扩展能力。而容器云有着资源开销少、灵活、弹性、高效、快速等优点,容器是轻量级和快速的,启动一个容器就像启动一个进程不会因启动整个操作系统而启动和消耗资源[2-3]。然而,容器云技术发展起步较晚,发展不成熟,在资源供应方面面临着不合理的资源管理问题,比如云资源过度调配造成的资源浪费和供应不足导致服务质量降低会造成企业经济效益的降低和资源利用率问题。
如何根据容器云资源的历史数据准确预知未来对资源的需求从而达到提前规划好资源分配、预留、避免浪费等目标,是容器云资源预测问题的关键,现提出一种基于Holt-winters和长短期记忆神经网络(long short-term memory,LSTM)(HW-LSTM)的云资源组合预测模型,使用解决短期趋势性和周期季节变化时间序列预测问题的高级指数平滑季节模型(Holt-Winters)和可挖掘时序数据隐藏信息的长短期记忆神经网络(LSTM)进行建模,通过对集群使用的容器云资源进行分析预测未来需响应的资源需求,同时提出对Holt-Winters和LSTM模型预测残差的变异系数进行赋权,解决数据波动性问题,中和两者之间残差距离,进一步提高模型预测精度和稳定性有效提高资源利用率。
1 相关工作
云资源预测为管理云资源提供了一种有效的方式,国内外学者在考虑到计算资源动态变化趋势时结合机器学习技术提出了基于支持向量机、贝叶斯模型等多种预测模型。文献[4]构建灰色预测模型利用马尔科夫修正预测结果,灰色预测模型在处理不确定性的短期数据序列也可以进行建模,而针对灰色模型对波动性信息拟合较差的缺点引用随机动态模型马尔科夫模型,提高了应用在医学诊断预测的精度。文献[5]采用一种有监督的统计学习方法,即支持向量回归技术来预测多属性资源的未来使用情况,使用径向基函数作为支持向量重训练方法(support vector retraining,SVRT)的核函数提高预测精度,在选择最佳的径向基函数(radical basis function,RBF)核参数时使用k折交叉验证技术,并应用序列最小优化算法进行预测方法的训练和回归估计,有效地证明了SVRT在建模和预测方面的优势。随着生物启发式算法的发展,启发式搜索算法解决模型构建过程中参数最优选择的方法被广泛应用于云资源预测模型参数最优匹配中。文献[6]使用自适应概率的多选择策略遗传算法优化长短期记忆(adaptive probability multiselection strategy genetic algorithm-long short term memory,APMSSGA)调整长短期记忆神经网络的时间步(timesteps)、单位(units)、预测步数(predictsteps)3个参数,搜索由这3个参数组成的三维空间的最佳参数组合,以遗传算法的全局优化能力智能调参,进一步提高了云资源数据的预测精度。
Manrich van Greunen定义了时间序列数据,将固定时间内搜集的云资源负载数据看作时间序列数据,所以可以把对云资源的预测问题看作时间序列数据的预测,神经网络模型、移动平均模型、回归模型、指数平滑技术被广泛使用,季节性Holt-Winter方法的三重指数平滑技术在考虑水平、趋势和季节性作为平滑因素基础上在云资源需求预测的方面具有巨大优势。文献[7]为解决保持服务质量的同时实现成本和能源消耗方面的效率,提出了结合实时预测资源利用率的预测方法,以网络信息准则和赤池信息准则的最小值拟合训练数据,将侧重点放在适合云资源自适应供应的资源利用率预测上,与基于工作负载预测的资源供应相比具有良好的性能。文献[8]考虑需求高效的云维护系统来有效地管理云工作负载,而不违反服务水平协议(service level agreement,SLA),预测对虚拟机(virtual machine,VM)请求的需求同时降低云基础架构的运营成本,提出一个差分自回归移动平均模型(autoregressive integrated moving average mode,ARIMA)和季节性Holt-Winter 模型的非线性混合方法在实时非线性云环境中进行需求预测具有良好的表现。作为时序预测领域的最佳算法,回归神经网络(regression neural network, RNN)和LSTM被广泛使用,文献[9]研究云资源负载的长期预测,提出一种基于长短时序特征融合的边缘计算资源负载预测方法,利用格拉姆角场将时间序列转变为图像格式数据,以长短期记忆神经网络提取时间序列的长时序依赖特征,通过卷积神经网络提取空间特征和短期数据特征,最后将所提取的长、短时序依赖特性通过双通道进行融合,从而实现长期资源负载预测,与单通道的CNN和LSTM模型、双通道CNN+LSTM、ConvLSTM+LSTM模型相比预测准确率更高。可以看出季节性Holt-Winter方法在针对季节性和趋势性时间序列数据预测方面优势巨大,LSTM神经网络在处理长期依赖性的时序数据时可以很好地挖掘时序信息,具有显著的时序数据预测性能。
但是在巨量的云计算节点和各异的云服务需求中,现有的单一预测模型已经不能实现优异预测结果的产生,多种预测模型的集成组合在提升预测模型的预测精度和性能方面效果显著。文献[10]考虑线性与非线性的云资源负载数据,以自回归移动平均模型和长短期记忆网络构建组合模型,在组合赋权中使用客观赋权法中的基于层间相关性的客观赋权法(criteria importance though intercrieria correlation,CRITIC)方法进行权重累加,并再次预测误差进行修正,效果很好。文献[11]为预测云数据中心中虚拟机的CPU、内存等使用情况,提出了一种门控循环单元和LSTM结合的模型,利用该模型的预测负载来减少备用资源,最大限度地减少功耗成本、带宽成本和 SLA 违规。
基于以上研究内容,现提出一种基于残差变异系数客观赋权法HW-LSTM组合预测模型,以变异系数法有效中和由于残差带来的不同模型的预测误差,利用Holt-Winters模型处理趋势和季节性周期变化时间序列的优势以及LSTM模型改善预测过程中长期依赖问题,组合两者的优势构建出可以准确、全面处理波动性、非线性等特点的云资源时间序列数据的组合预测模型,以期提高传统模型组合的误差性能和预测模型拟合峰值的精度,使其能更好地跟踪原始数据趋势,且预测准确度更高,稳定性更好。
2 HW-LSTM模型
2.1 Holt-Winters预测模型
Holt-Winters 预测方法可以很好地处理具有趋势、季节性和随机波动的时间序列数据[12],通过指数平滑法建立长期趋势及增量和季节性的预测模型,指数平滑法可以很好地对时间序列数据进行非等权处理且简便易行,在预测模型能自动识别数据做出适应性的调整,由于很难预测时间序列数据的波动转折点,所以多用于短期预测,Holt-Winters模型多用于对兼有长期趋势和季节周期的数据进行预测,Holt-Winters 季节模型包括两种分模型:加法和乘法,对具有稳定的季节性波动的时间序列数据,首选加法模型,云资源时间序列整体变化选择季节性加法模型如下。
Holt-Winters 季节模型的加法模型t时刻稳定成分为
St=α(Xt-It-L)+(1-α)(St-1-Bt-1)
(1)
模型t时刻季节成分为
It=β(Xt-St)+(1-β)It-L
(2)
模型t时刻趋势成分为
Bt=λ(St-St-1)+(1-λ)Bt-1
(3)
预测期数m的预测值公式为
Ft+m=St+mBt+It-L+m
(4)
其模型各项初值公式为
(5)
式中:Xt为t时刻观测值;St、It、Bt分别为t时刻稳定成分、季节因子和趋势[13];因数据集为每5 min所采集的,按照每小时一周期,季节长度L设置为12;α、β、λ为平滑参数;m为预测期数;F为期数的预测值。
2.2 LSTM预测模型
LSTM在1997年被提出,是增加门控装置的循环神经网络(RNN)的变体,它可以有效地预测时间序列数据中的长期相关性,通过学习时间序列数据发现隐藏的规律,挖掘时序数据中的时序信息以及语义信息。RNN 通过隐藏层中的反馈循环机制存储时间序列中之前的信息,而输入的是一个包含特定时刻和过去时刻的特征,由于每时刻的隐藏状态不仅由该时刻的输入决定,还取决于上一时刻的隐藏层的值,当输入特征过长时会产生长期依赖性而导致后续节点会遗失前面的信息,且隐藏层中的权重大小也会出现“梯度消失和爆炸”问题,导致很难收敛。
LSTM的引入则解决了RNN的弊端,LSTM利用门控单元和存储单元来解决如何在一段时间内重新收集数据的问题[14],存储单元具有存储最近经历的数据的单元状态,信息到达存储单元的每一刻,都通过门控单元状态的组合来控制结果选择性的存储信息,然后刷新单元状态处理输出,隐藏层中包含3个用来更新历史信息的门控单元:输入门、遗忘门、输出门,其结构如图1所示。
每一时刻从输入层输入的信息首先经过输入门的筛选,σ为门控单元,t时刻输入门和遗忘门公式分别为
it=σ(wiht-1+wixt+bi)
(6)
ft=σ(wfht-1+wfxt+bf)
(7)
t时刻细胞记忆状态公式为
cellt=ftcellt-1+ittanh(wcht-1+wcxt+bc)
(8)
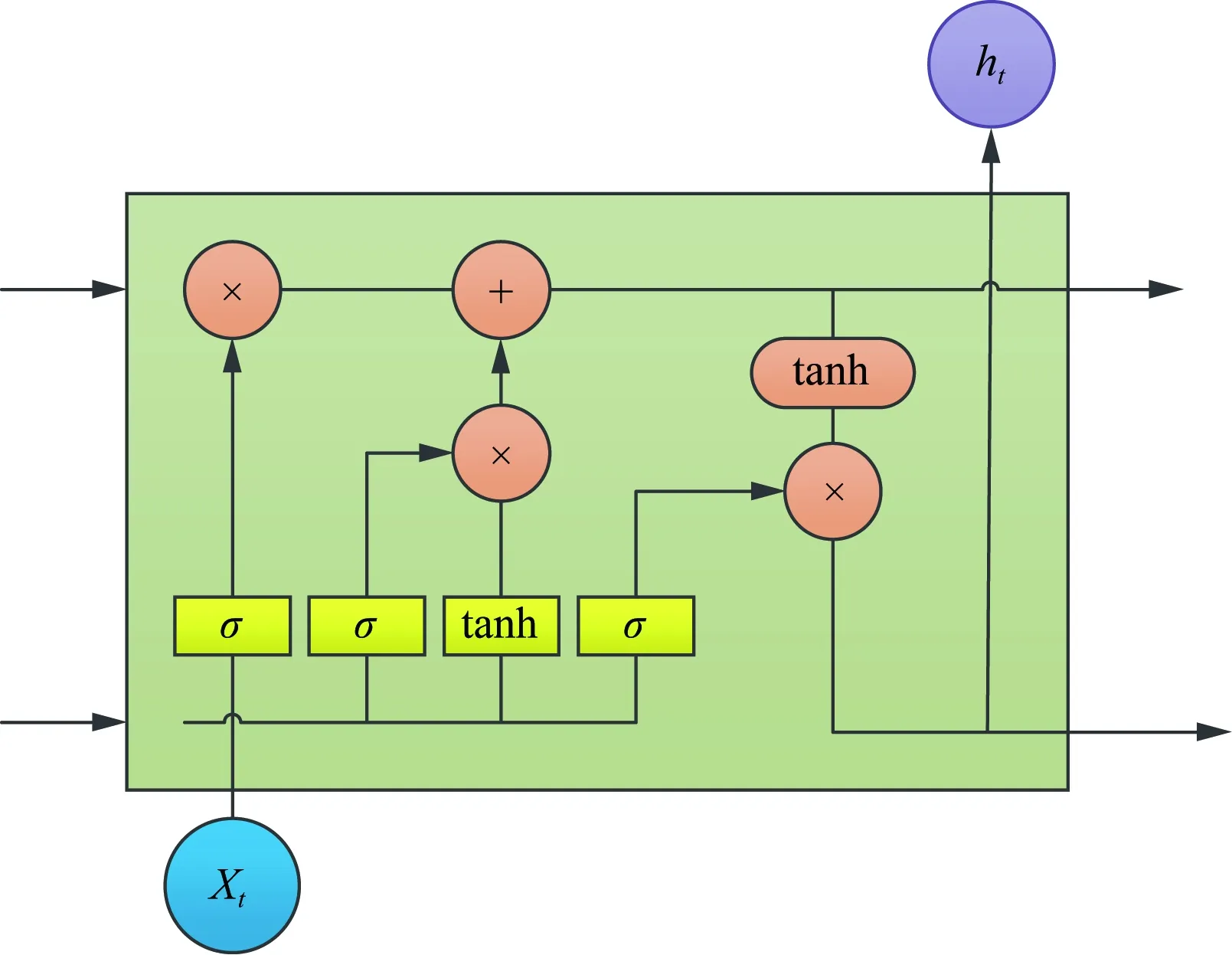
图1 LSTM结构图Fig.1 LSTM structure diagram
在已知细胞更新状态后,可计算输出门为
ot=σ(woht-1+woxt+bo)
(9)
ht=ottanh(cellt)
(10)
式中:ht、ht-1为t时刻以及上一时刻外部状态;w和b为神经网络学习参数;tanh为激活函数。
LSTM单元结构的计算步骤为:xt和ht-1经过循环单元中的遗忘门产生一个状态决定上一时刻信息是否被通过即细胞的状态值是否通过此门控单元;xt和ht-1经过输入门tanh层激活产生新的细胞状态值即更新细胞记忆单元cellt与sigmoid 门的输出相乘输出最终确定的值。
2.3 组合预测模型
针对HW-LSTM云资源预测模型,根据模型分析预测值与真实值的残差的离散程度,设计了一种基于HW和LSTM预测值残差变异系数赋权的方式,这里变异系数是衡量模型预测残差离散程度的指标,变异系数权重法利用数据各项指标通过计算进行赋权,有效避免人为赋权的主观性。由于云资源数据收集具有周期性和波动性,该组合预测模型吸收Holt-Winters模型进行非等权处理具有趋势、季节性和随机波动的云资源数据的优点,且结合LSTM模型能够挖掘时序数据中的时序信息、隐藏规律和改善预测过程中长期依赖问题的优势,并通过绝对值后的变异系数法进行赋权,可以有效中和由于残差带来的不同模型的预测误差。相较于遍历赋权最优的方法,为HW和LSTM模型分配客观权重,可以优化不同模型带来的误差,从而提高模型精度和稳定性。
变异系数公式为
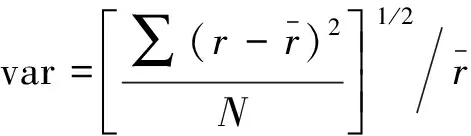
(11)
HW-LSTM的计算公式为
(12)
式中:Yt为模型最终预测值;Lt、Ht分别为LSTM模型预测值和HW模型预测值;var为模型的变异系数;将var绝对值标准化后范围在0~1;Lt和Ht的系数权重之和为1;r为预测与真实值的残差;N为时间序列长度。
3 实验结果与分析
3.1 实验数据及参数
使用Kaggle平台的亚马逊云服务公共数据集,是一个间隔5 min采集的集群CPU平均使用率数据集,且对数据集进行预处理以均值处理缺失值,用此数据集检验HW-LSTM预测模型的性能,选取从2014年5月21日开始的大约6 d数据,以1/5划分测试集与训练集,预测未来26.6 h的CPU使用率序列。
本文模型是基于Holt-Winters 季节模型与LSTM模型建立的,LSTM 模型的结构较为复杂,故主要设置网络层数(layers)、训练批量(batch)、更新期(epochs)等参数,由于数据是间隔5 min的集群数据,这里Holt-Winters 季节模型的季节长度按照小时周期设置为12,而LSTM 模型的训练批量(batch)也因数据的周期性设置为12,LSTM模型网络层数(layers)为2,设置第二层接收第一层的计算结果。为选定较为合适的更新期epochs,设置不同的epochs循环测试10次,消除结果偶然性的影响,以均方根误差RMSE为指标选定确定值,epochs 数的箱形图如图2所示。
从图2可以看出,epochs为1、10和100出现异常值偏离误差的平均水平,离散程度大,由于考虑到运行时间问题,虽然epochs为200时均方根误差最低也在1.65~1.70,但是运行时间长于epochs为50时,所以确定epochs为50,而不同模型的权重根据式(11)、式(12)进行赋值。

图2 epochs箱型图Fig.2 Epochs box plot
3.2 实验结果性能对比
分别研究组合模型的分模型HW和LSTM,在进行一定的优化后,分别预测以及组合预测未来26.6 h内的CPU使用率序列,组合模型需要在研究HW和LSTM模型预测值与真实值的残差上进行比对,以变异系数进行赋权,图3为HW和LSTM模型残差图,图4为组合模型残差图,图5为模型性能对比图。
从图3的残差图可以看出Holt-Winters 季节模型受数据的峰值波动比较大,呈现一种季节性误差波动,且波动误差普遍很大,在5~10,较大的波动误差使模型预测的拟合效果不准确,但预测的时序数据的趋势和周期变化总体一致。而LSTM模型只有很少的峰值残差,残差分布较为集中在-2.5~2.5,只有个位数数量的较大误差,可以看出LSTM模型拟合较好,离散程度较低从而计算变异系数时权重比重高,可以有效中和误差。

图3 HW和LSTM模型残差图Fig.3 HW and LSTM model residual

图4 组合模型残差图Fig.4 Combined model residual plot

图5 模型性能对比图Fig.5 Model performance comparison
图4的组合模型残差图很清晰地显示残差波动集中在-1.5~1.5,说明模型拟合较准确,虽然在波动较大时出现明显误差,但组合预测模型在峰值上的拟合效果更接近真实值。从图5可以看出,各个模型总体上预测趋势和周期变化与真实数据相差较小。这是因为HW-LSTM模型可以根据分模型预测残差的变异系数吸收LSTM模型拟合较好的优点和HW模型跟踪趋势和季节性变化的优点,分配拟合效果好的模型较大权重从而减少波动性拟合误差,提高了模型预测效果。
3.3 实验结果误差对比
为了说明预测结果误差,以5种预测性能指标做对比,分别为均方根误差(root mean squared error,RMSE)、平均绝对误差(mean absolute error,MAE)、平均绝对百分比误差(mean absolute percentage error,MAPE)、平均绝对比例误差(mean absolute scaled error,MASE)、方差D(n),并且以方差指标对模型稳定性进行分析判断。以模型Holt-Winters、LSTM、CNN、本文模型预测数据做对比,结果如表1所示,各项指标的值均越小越好。
均方根误差公式为
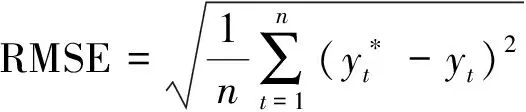
(13)
平均绝对误差公式为
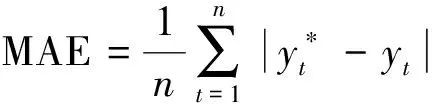
(14)
平均绝对百分比误差公式为

(15)
平均绝对比例误差公式为
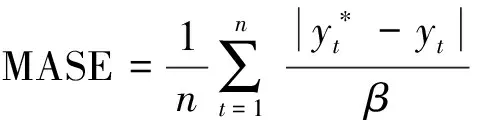
(16)
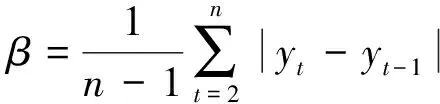
(17)
方差D(n)作为样本偏离程度即数据波动程度来判断结果的稳定性,公式为
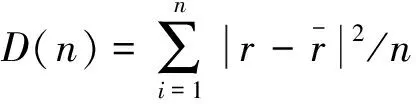
(18)
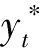

表1 预测误差对比Table 1 Forecast error comparison
从表1可以分析图5中重合不明显处的误差对比,单一云资源预测模型中Holt-Winters和CNN预测效果较差,而LSTM模型与组合模型效果相似,组合预测模型在各项误差指标对比中比Holt-Winters降低1.026、0.269、0.004、0.004、4.125,与LSTM和CNN模型相比降低范围分别为0.065~0.081、0.023~0.188、0.001~0.007、0.004~0.039以及0.079~0.211,可以明显看出提出的HW-LSTM模型比传统预测模型性能更好,各项误差评价指标都要更低,HW-LSTM模型根据预测值误差变异系数赋权后的误差修正可以明显提高传统模型组合的误差性能,使其能更好地跟踪原始数据的趋势和变化,预测准确度更高,且稳定性更好。
4 结论
提出了一种新的容器云资源组合预测模型,该模型结合了Holt-Winters 季节模型和LSTM模型,吸取LSTM模型学习长期依赖关系时间序列以及Holt-Winters 季节模型很好预测具有长期趋势和季节周期变化数据的优势,在提高预测精度和稳定性的同时,有效中和了真实数据集频繁波动处峰值的误差,提高了预测模型拟合峰值的精度和稳定性,提出的残差变异系数赋权的方法在组合模型的权重分配上起到了很好的效果,在亚马逊集群数据集上验证并且与单一Holt-Winters、LSTM、CNN模型对比,结果证明HW-LSTM预测模型表现更好,可以有效进行容器云资源的规划,进一步提升容器云技术发展。
