基于RCSP 的言语想象多分类任务
2022-06-13刘艳鹏罗建功刘化东
刘艳鹏,罗建功,刘化东
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
0 引 言
脑机接口(Brain-Computer Interface,BCI)[1-2]技术为言语障碍患者提供了一种新的交流方式,这是一种不依赖于正常外周神经和肌肉通路,而是直接通过大脑与外部辅助设备交互的通信系统。目前常见的BCI 系统范式有基于P300 成分[3]、稳态视觉诱发电位(Steady-State Visual Evoked Potentials,SSVEP)[4]、运动想象[5]以及言语想象[6]的系统。其中,基于P300 成分与SSVEP 的BCI 系统需要由外部提供视觉刺激,使用者在使用过程中长时间注视屏幕容易导致视觉疲劳;基于运动想象的BCI 系统会存在部分被试不能执行这一心理任务,即BCI盲现象。
言语想象,即人们在心中默读或想象某些特定的字符或词语,BCI 系统通过识别被试执行言语想象任务时的脑神经信号特征,即可输出对应的控制指令,其不需要持续存在的视觉刺激,也避免了运动想象BCI 盲现象。这一范式有诸多优点,如自发产生且无需刺激、无需训练且对被试友好、可直接表达真实意图,并且能够提供一种自然的交流方式,因此这一范式逐渐受到关注。
在BCI 领域,利用非侵入式技术(即将信号采集电极放置头皮表面)采集脑神经信号的方式有脑电(Electroencephalography,EEG)[7]、功能性近红 外 光 谱(functional Near-Infrared Spectroscopy,fNIRS)[8]及脑磁图(Magnetoencephalography,MEG)[9]等。其中,EEG 信号的采集凭借价格较低、便携易用等优点被广泛深入研究。基于言语想象的BCI 系统大多采集EEG 信号。
虽然EEG 信号有着较高的时间分辨率,但是其空间分辨率较低,因此需要通过空域滤波算法弥补这一缺点。共空间模式(Commom Spatial Patterns,CSP)算法就是用来提取两类模式特征的空间滤波算法。其通过设计空间滤波器来提取两类模式间方差最大的EEG 数据成分以实现分类[10]。并且,CSP及其改进算法已被广泛地应用于基于运动想象的BCI 系统中,并表现出较好的分类性能[11]。
言语想象作为一种新颖的BCI 实验范式,对其特征提取并未广泛开展深入研究,因此本文将正则化与CSP 相互融合以构成正则化CSP(Regularized CSP,RCSP)的特征提取算法,并将其首次应用于言语想象多分类任务。
1 材料与方法
1.1 实验数据
本研究使用2020 年国际BCI 竞赛数据集Track#3 的数据(多分类言语想象任务)。数据可通过公开网站(https://osf.io/pq7vb/)获取。其中包含15 名被试(年龄在20 ~30 岁)的数据。被试被要求执行5个不同单词/短语(“hello”“help me”“stop”“thank you”“yes”)的言语想象任务,这些单词/短语可用于生活中的基本对话。数据集记录了被试执行五类言语想象任务时的EEG 信号。每类言语想象任务包含70 个试次(共70×5=350个试次),60 个试次用于训练,10 个试次用于验证(由于官方并未公布测试集数据,因此在本文分类过程将10 个试次的验证集用作测试集)。
1.1.1 实验范式
在实验数据记录过程中,被试坐在24 英寸LED 显示屏幕前的椅子上,进行指定单词/短语的言语想象任务。在言语想象当中,被试被要求不移动发音器官,也不发出声音,就像他们在真实说话一样进行思维活动。在执行这一心理任务时被试不能进行其他大脑活动。在视觉提示后即为言语想象周期,提示被试不能移动身体,避免眨眼。为了避免其他因素影响大脑的活动,在言语想象期间屏幕呈现黑屏。实验范式时序如图1 所示。

图1 实验范式时序图
5个不同单词/短语通过声音提示随机呈现,然后是为期0.8 ~1.2 s 的“+”字标记,当“+”字标记在屏幕上消失时,要求被试对所提示的单词/短语进行言语想象。每个随机任务包含4个“+”字标记和言语想象期(2 s)。进行4次言语想象任务后,被试有3 s 的休息间隙,以便进入下一个想象任务。
1.1.2 实验装置
EEG 数据由EEG 信号放大器(德国Brain Product 公司生产的BrainAmp)采集,原始数据使用Brain Vision 软件(德国BrainProduct 公司开发)和Matlab 2019a 软件(美国The MathWorks Inc.开发)记录。64 个电极按照国际10-20 系统排布方式进行记录,接地和参考电极位于Fpz 和FCz 上,采样电极和头皮之间的阻抗均保持在15 kΩ 以下。
1.2 特征提取算法
1.2.1 CSP 算法
本节将简要描述CSP 算法。Xa(N*T)表示一类EEG 数据矩阵,其中N为EEG 数据的电极数,T为每个电极采集的样本数。同理,Xb表示的是另一类EEG 数据矩阵。两类数据的协方差矩阵分别为:


对混合协方差矩阵进行特征分解,如式(3)所示:

式中:矩阵U由矩阵C的特征向量组成,矩阵Λ是由矩阵C的特征值组成的对角矩阵。
接着,进行白化变换,如式(4)、式(5)所示:

将Ca和Cb经过白化变换后分别得到矩阵S a和S b,并且得到的两个矩阵具有相同的特征向量,再分别对其进行特征分解,如式(6)所示:

式中:矩阵ya和yb的和为单位矩阵,并且矩阵S a和S b具有相同的特征向量B。由此可知,对一类数据特征值最大的特征向量对另一类数据特征值最小,反之亦然。将EEG 信号进行白化变换,再选取矩阵B的前m及后m列构成空间滤波器,然后按照式(7)可以得到映射矩阵,即空间滤波器,如式(7)所示:

矩阵W-1的列是共空间模式,即两类条件下脑电源分布向量。最后就可以将每次试验的EEG 数据X按式(8)进行分解:

得到的新的矩阵,其方差能最大化区分两类任务。对滤波后的特征信号Z的方差进行归一化,将其作为新的特征,过程如下:

1.2.2 RCSP 算法
正则化首先被应用在正则化判别分析(Regularized Discriminant Analysis,RDA)中,用于解决线性和二次判别分析中小样本的问题。小样本训练往往会导致特征值产生有偏估计,通过引入两个正则化参数可以解决这一问题[12]。CSP 算法对噪声较为敏感,泛化能力也较低,而且EEG 数据的样本量较少。为解决这些问题,可通过应用正则化的方法进行改善,即构成基于正则化的RCSP 算法。正则化的使用对CSP 算法的最终分类性能有着明显的提高。正则化在CSP 算法中的应用一般有两种方法,一种是引入两个正则化参数,并利用其他被试的数据来提高分类性能[13],而另一种方法不需要其他被试的数据,仅需一个被试的数据即可实现正则化[14]。由于第一种方法需要较多的计算量,仅使用一个被试的数据实现正则化的方法更为实用,因此在本文研究选择第二种方法。下面介绍这一算法的实现过程。

式中:Ci表示i类数据的协方差矩阵,表示成对协方差矩阵。基于正则化的协方差矩阵如下:

式 中:α和β为 两 个 正 则 化 参 数(0 ≤α≤1,0 ≤β≤1),I为单位阵,m为执行某一种言语想象任务的次数。两类数据的平均协方差矩阵分解为:
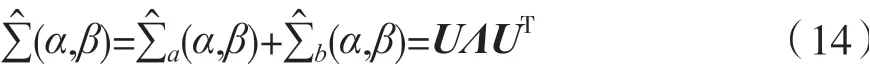

2 实验结果
2.1 数据预处理
成年人的EEG 主要包括δ波(0.5 ~4 Hz)、θ波(4 ~7 Hz)、α波(8 ~13 Hz)、β波(14 ~30 Hz)以及γ波(>30 Hz),并且每种频率的EEG 节律都与大脑特定的生理现象密切相关。在言语想象分类任务相关研究中,JAHANGIRI 等人[15]通过音节想象分类任务发现α波具有最高的分类性能,其次是β波;KOIZUMI 等人[16]通过言语想象分类任务发现,在低γ波段(30 ~40 Hz)的分类精度有一个峰值。因此对原始言语想象EEG 数据选择4 ~44 Hz 带通滤波器进行滤波处理,然后对预处理后的信号应用RCSP 算法提取相应的特征,最后对其进行分类。
2.2 分类结果
在分类过程中,选择支持向量机(Support Vector Machine,SVM)进行分类识别。由于SVM适用于解决小样本、非线性和高维度的模型等问题,而EEG 数据同样具有样本量少且非线性等特点,故本文选择这一算法进行分类。为避免单一分类算法造成最终结果不稳定,本文还选择K 近邻算法(K-Nearest Neighbor,KNN)进行分类。15 名被试执行言语想象任务的分类准确率如表1 所示。
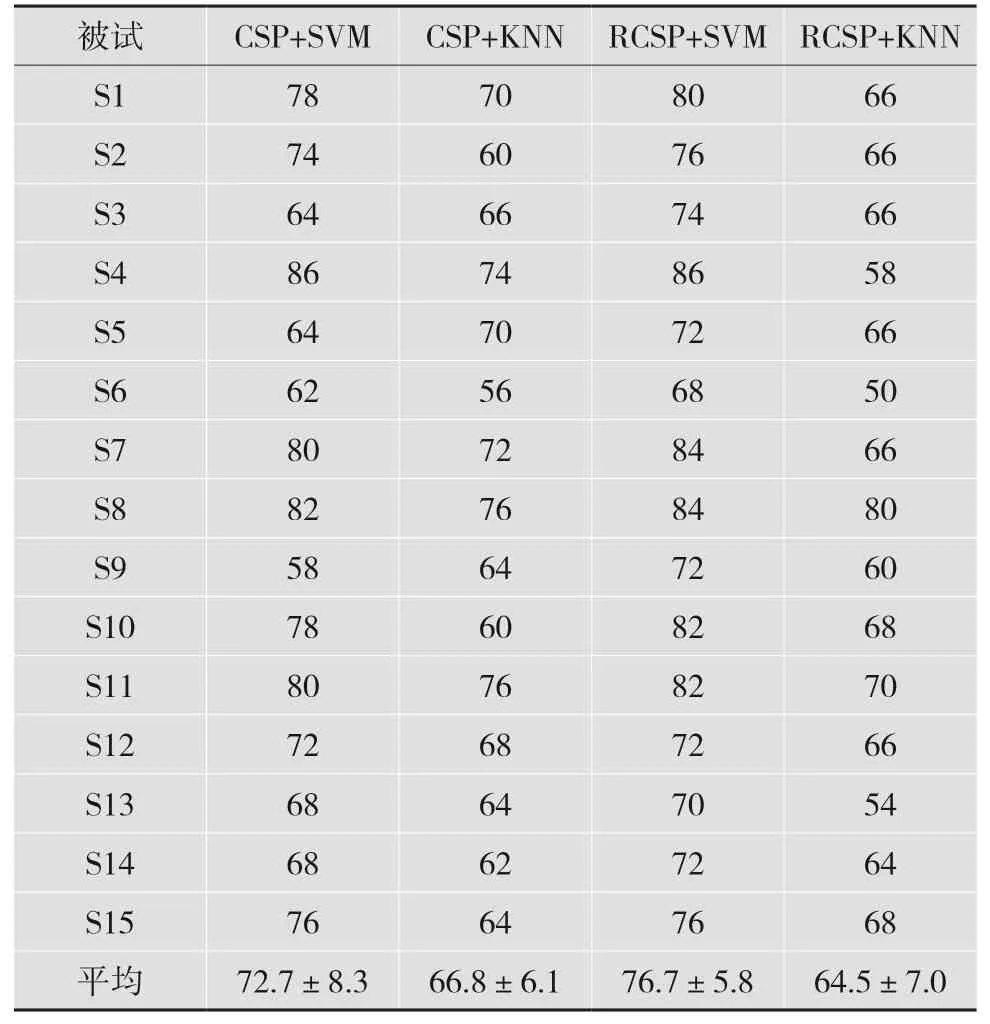
表1 15 名被试执行言语想象任务的分类准确率/%
从表1 的结果可知,RCSP 与SVM 的组合取得了最高的准确率,其次是CSP 与SVM 组合。当分类器为SVM 时,RCSP 算法可以提高分类准确率;而当分类器为KNN 时,RCSP 算法的分类准确率却不及CSP 算法。
另外,本文还将这一算法的分类结果与其他研究进行对比(使用同一数据集),结果对比如表2 所示。
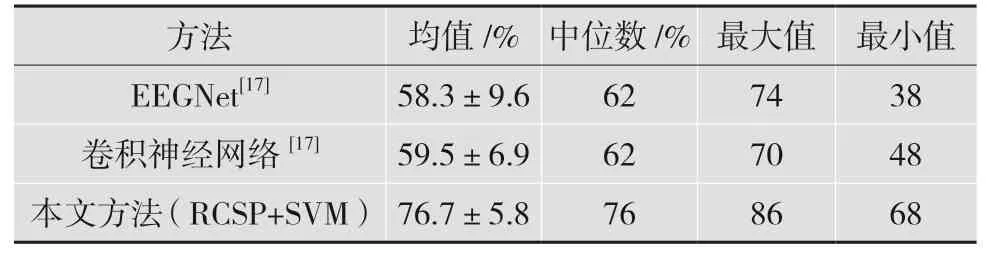
表2 本文方法与其他研究结果的对比
同样,本文提出的方法相比于深度学习网络也取得了较好的分类性能。
3 结 语
本文针对言语想象多分类任务,将RCSP 算法应用于这一范式BCI 数据集。从分类结果来看,当分类器为SVM 时,RCSP 算法可以提高分类性能,并且利用这一算法可使分类准确率提高4.0%;而当分类器为KNN 时,RCSP 算法取得的分类准确率却比CSP 算法低2.3%。因此,对于言语想象EEG信号分类任务,更适合选择SVM 对RCSP 提取的特征进行分类。另外,RCSP 与SVM 组合的准确率达到76.7%±5.8%,比深度学习网络高出17%。深度学习虽然在脑神经信号解码过程中有诸多优点,能表现出较好的解码性能,但在处理言语想象EEG 数据分类任务过程中,深度学习的分类性能却不如经典的CSP 及其改进算法。因此,在EEG 信号特征提取及分类过程中对算法的选择应选择合适的算法,才能取得较好的分类结果。
