认知诊断模型的标准误与置信区间估计:并行自助法*
2022-06-06刘彦楼
刘彦楼
(曲阜师范大学教育大数据研究院,山东 济宁 273165)
1 引言
认知诊断模型(Cognitive Diagnosis Model,CDM)或称诊断分类模型,是一类离散潜变量模型(Rupp et al.,2010),当前已广泛应用于心理、教育或生物学等领域(例如,Tjoe &de la Torre,2014)。潜在属性在不同领域有不同的含义,例如,知识、技能、认知过程、精神障碍、甚至是病原体等(Rupp et al.,2010;Wu et al.,2017)。恰当应用CDM,研究者可以通过被试的外显行为去推论每个个体的多维潜在属性掌握状况,为被试提供及时的反馈、个性化的指导或针对性的补救。
CDM 模型参数的标准误(Standard Error,)是关于模型参数估计不确定性的度量(Liu et al.,2021)。在心理统计与测量模型中,点估计值相同的两个模型参数可能由于不同而具有不同的置信区间(Confidence Interval,CI),因此需要综合考虑模型参数的点估计值与CI。例如,CDM 中两个项目的猜测参数估计值均为0.2,但的估计值分别为0.08 与0.05,那么这两个猜测参数的估计精度不同。根据正态分布理论,第一个猜测参数的95% CI是[0.2-1.96×0.08,0.2+1.96×0.08],第二个猜测参数的95% CI 是[0.2-1.96×0.05,0.2+1.96×0.05]。正因如此,国内外多种心理学期刊(如《心理学报》,或参考:American Psychological Association,2020)要求或建议报告及95% CI。然而,在国内外的CDM 实证研究中,报告模型参数的及CI 的研究仍然较少。造成这种现象的原因是多方面的,主要原因在于缺乏易用的计算方法。接下来,本文将对两类常用的及CI 的估计方法:解析法以及自助法目前存在的问题展开探讨,并提出一类简易、可行的方法。
CDM 中模型参数的(或广义而言,方差—协方差矩阵)在推论统计中具有基础与核心作用(Liu,Xin et al.,2019;Philipp et al.,2018)。除用于计算CI 外,模型参数的在项目功能差异检验(Liu,Yin,et al.,2019;Ma et al.,2021;刘彦楼 等,2016)、项目水平上的模型比较(de la Torre &Lee,2013;Liu,Andersson,et al.,2019;Ma &de la Torre,2016,2019)、Q 矩阵检验(Ma &de la Torre,2020a)以及探索属性层级关系(Liu et al.,2021;Wang &Lu,2021)等领域也有重要价值。对于模型参数的的估计,研究者提出了多种基于解析法的估计方法(Liu,Xin et al.,2019;Liu et al.,2021;Philipp et al.,2018;刘彦楼 等,2016),包括:经验交叉相乘信息矩阵法(Empirical Cross-product Information Matrix,XPD)、观察信息矩阵法(Observed Information Matrix,Obs)和三明治信息矩阵法(Sandwich-type Information Matrix,Sw)。
在模型参数可识别条件下(Gu &Xu,2020;Wang &Lu,2021),研究者通过数据模拟以及实证数据分析的方式探索了使用解析法信息矩阵(Liu et al.,2016;刘彦楼 等,2016)计算的模型参数(包括项目参数与用于描述被试分布的结构参数)的及CI 的表现。关于项目参数的及CI,研究者比较了在理想状况下(即模型与观察数据完美拟合)、在CDM的项目反应模型和/或Q 矩阵错误设定条件下,XPD、Obs 或Sw 方法的表现(Liu,Xin,et al.,2019;Philipp et al.,2018)。研究发现,当模型(包括项目反应模型与Q 矩阵)完全正确设定或存在较少错误设定时,这3 种方法在项目参数的估计的一致性方面都有好的表现;在模型存在严重错误设定时(如,项目反应模型与Q 矩阵同时包括较多的错误),只有Sw 具有健壮性(Liu,Xin,et al.,2019)。关于结构参数的及 CI,研究者在 HCDM(Hierarchical Cognitive Diagnosis Model;Templin &Bradshaw,2014)框架下进行了探索(Liu et al.,2021)。研究发现,对于正确设定的属性层级关系,即结构模型完全正确设定时,在样本量大于或等于3000 条件下这3 种方法均有较好的95% CI 覆盖率;当属性之间存在层级关系但使用饱和CDM 估计时,即结构模型参数存在部分冗余情景下,对于允许存在的结构参数(permissible structural parameter),即根据属性层级关系在理论上不等于0 的结构参数,XPD 和Obs 方法计算的有较好的表现;对于非允许存在的结构参数(impermissible structural parameter),即理论上等于0 的结构参数,XPD 方法计算的结构参数的表现较好(Liu et al.,2021)。
准确地识别与验证CDM 中的属性层级关系能够使研究者深入地了解被试作答的心理过程,具有重要的理论与实践价值(Leighton et al.,2004)。然而,实践中预先正确设定属性层级关系是一个非常具有挑战性的过程(Hu &Templin,2020;Liu et al.,2021;Ma &Xu,2021;Templin &Bradshaw,2014;Wang &Lu,2021)。如果认知诊断测验中存在属性层级关系,使用饱和CDM 拟合作答反应数据,相应的结构参数近似等于0。即,饱和CDM 的结构参数能提供属性层级是否存在的证据(Liu et al.,2021;Templin &Bradshaw,2014)。Liu 等人(2021)初步提出,结构参数的已知时,可以使用统计量探索属性层级关系,具体表达式为,

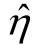
在多数情况下,可以使用XPD、Obs 或Sw 方法有效地计算CDM 中模型参数的,但是这些解析性方法主要有两个缺点。(1)需要信息矩阵正定(positive definiteness)。DeCarlo (2011,2019)发现,CDM 中的边界值问题(boundary problems),会导致使用信息矩阵计算方差—协方差矩阵时存在非正定问题。关于边界值及其可能导致的信息矩阵非正定问题将在第2 部分详细阐述。(2)需要方差—协方差矩阵的对角线元素大于0,如果小于0 则会导致相应的模型参数的无法计算。然而,在实践中由于计算误差的存在,可能会导致使用信息矩阵求逆计算的方差—协方差矩阵中的某个或某些元素小于0 (Liu &Maydeu-Olivares,2014)。例如,第5部分实证数据分析中基于Obs 的方差—协方差矩阵中第2 个结构参数对应的对角线元素小于0,而导致无法计算。这也就意味着,如果出现情形(1),则全部的模型参数的无法计算;如果出现情形(2),相应的模型参数的无法计算。解析法信息矩阵所存在的以上问题,限制了其理论发展及实践应用。
除解析法外,另一类可用于计算及CI 的方法是自助法(Davison &Hinkley,1997;Efron &Tibshirani,1993),最常见的有参数化自助法(Parametric Bootstrap,PB)与非参数化自助法(Nonparametric Bootstrap,NPB)。PB 以及NPB 是一种应用广泛(例如,2019 年1 月至2021 年8 月份发表在《心理学报》上的论文中至少有20 篇论文用到了自助法)、通用性强,但计算密集(computerintensive)、费时的方法。与解析法信息矩阵不同,PB以及NPB 不需要有较强的前提假设以及大量的公式推导。这类方法是通过3 个步骤进行的。第一步是根据观察数据集获得重采样数据集。第二步是根据重采样数据集估计模型参数。以上两步重复进行,直到达到预先设定的重抽样次数。第三步,根据每次重复获得的模型参数估计值,计算以及CI。PB 与NPB 的不同之处在于:PB 是先通过观察数据集估计获得模型参数,再使用模型参数模拟生成重采样数据集;NPB 则是通过有放回取样的方式直接从观察数据集中取样。尽管研究者认为自助法可以用于计算CDM 中的及CI (Ma &de la Torre,2020b),且理论上可以较好地解决解析法信息矩阵在特定条件下无法计算的问题,然而其估计的准确性仍缺乏研究。作为一种计算密集型方法,计算量大、耗时长的缺点不仅限制了PB 与NPB 的理论研究,也造成了实践应用的困难。举例而言,在PB 与NPB 的应用中,进行重抽样时,如果样本量过少可能会影响到自助法的准确性,如果抽样过多会因计算量增大而影响效率。目前,重抽样次数的选择问题仍存在争议(例如,Bai et al.,2016;Efron &Tibshirani,1993;Guo &Wind,2021;Hayes,2009,2018;Lai,2021)。另外,PB 与NPB 在不同情景中估计CDM 的模型参数的及CI 的表现也需要进一步探讨。随着多线程、并行调度等计算技术的发展,并行计算技术被逐步用于计算密集型方法研究(Denwood,2016;Khorramdel et al.,2019)。仅以自助法为例,Zhang 和Wang (2020)开发了使用并行自助法的R 软件包,并探讨了其在统计功效分析中的应用(Zhang,2014);线性混合效应模型软件包(Bates et al.,2015)也提供了并行计算的自助法,Jiang 等人(2021)以此为基础探索了使用自助法计算概化系数的CI 估计值问题。
本文要解决的主要问题有:(1)借鉴以往研究中的并行自助法计算技术,开发适用于CDM 的并行参数化自助法(parallel Parametric Bootstrap,pPB)和并行非参数化自助法(parallel Nonparametric Bootstrap,pNPB),提高CDM 中PB 与NPB 的计算效率。(2)系统探讨pPB 与pNPB 在估计CDM 模型参数的及CI 时的表现。正如本文将要呈现的一样,pPB 与pNPB 是一类简易、可行的方法,不仅能有效解决CDM中与CI 理论研究中的重要问题,而且能有效提升实践应用中的计算效率。
接下来,本文将首先说明解析法信息矩阵计算时存在的问题,然后详细介绍新提出的pPB 与pNPB 方法。第4 部分是模拟研究,分别探讨CDM完全正确设定以及存在属性层级关系条件下这两个方法的表现。第5 部分是实证数据分析,主要用于说明及展示pPB 与pNPB 在估计CDM 模型参数的时的作用与价值。最后是讨论与结论。
2 解析法信息矩阵及其存在的问题
本部分以同一链接(identity link)下的G-DINA(Generalized Deterministic Input Noisy Output“AND” gate;de la Torre,2011)为例,分别呈现3 种解析法信息矩阵并阐述这些方法在计算CDM 模型参数的及CI 时可能会遇到的矩阵非正定,以及方差—协方差矩阵对角线元素可能小于0 等问题。
2.1 饱和的CDM
假设在一份认知诊断测验中有个被试,个项目,个属性,且属性及项目均为二级计分,×维项目反应矩阵记为 x ∈{x},×维Q 矩阵记为 Q ={q}。在饱和的G-DINA 模型中,被试正确作答项目的概率为,

其中,α=(α,…,α)′是第个被试的属性掌握模式,q=(q,… ,q)′是Q 矩阵中所定义的正确作答项目所需要的属性,λ=( ,λ ,,…) ′是项目的所有参数。对于饱和G-DINA 模型进行恰当约束,可以获得多种特殊模型。
为便于理解及行文,以=2,q=(1,1)′,α=(1,1)′为例。饱和G-DINA 的项目反应函数可以表达为,
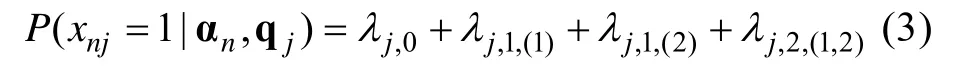
其中,λ为截距参数,表示没有掌握项目所需的任何属性仅凭猜测正确作答项目的概率,λ和λ,2分别是对应于第一个属性()和第二个属性()的主效应参数,λ,是这两个属性的交互效应。
当=2且属性层级关系不存在时,所有可能的属性掌握模式可以表示为,
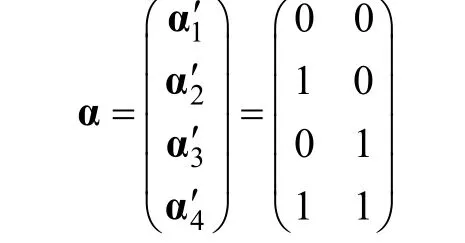
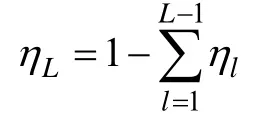
2.2 带有属性层级关系的CDM
当测验所测属性之间存在层级关系时,对饱和模型(如G-DINA)的结构参数以及项目参数加以适当约束,可获得 HCDM (Templin &Bradshaw,2014)。同样以=2,q=(1,1)′,α= (1,1)′为例,且假定这两个属性之间存在线性层级关系:只有掌握才能掌握。那么,所有可能的属性掌握模式为,
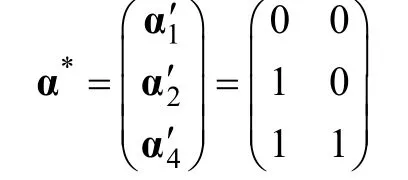
由于属性层级关系约束,饱和结构模型中的第三种属性掌握模式 α不存在,即=(α)= 0。在当前的例子中,HCDM 的项目反应函数可以表示为,

可以发现,如果真模型是 HCDM,但使用饱和G-DINA 模型估计参数时,某些结构参数(例如,)以及项目参数(例如,饱和G-DINA 中的λ)的真值都等于0,在这种情况下会导致CDM 中的一些模型参数冗余。在接下来的部分中,参考以往研究中的表述(Liu,2018;Liu et al.,2021),将真值为0的参数统称为非允许存在的参数,真值不等于0 的参数统称为允许存在的参数。
2.3 解析法信息矩阵及其不足
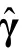

公式(5)中,I表示的是使用模型参数真值以及对单个被试的作答反应向量求期望(即所有可能的作答反应模式)而计算的期望 Fisher 信息矩阵(Liu et al.,2016;Liu,Xin et al.,2019)。但由于模型参数真值在实践中是未知的,并且所有可能的作答反应模式会随着项目的数量呈现指数增长,因此I只具有理论价值,无法应用于实践(Liu,Xin et al.,2019)。
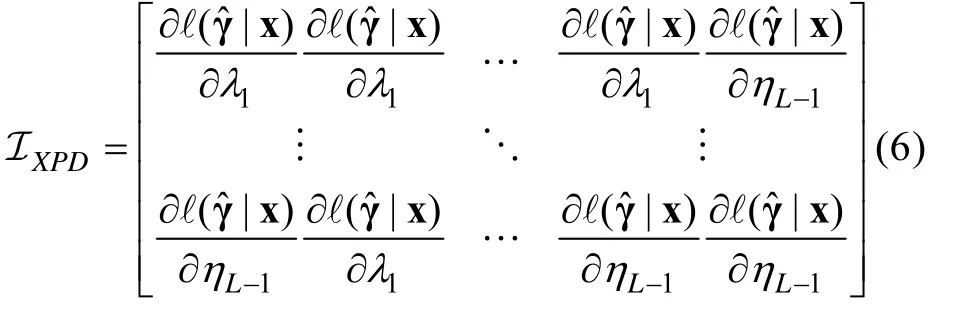
根据观察数据对数似然函数关于模型参数的二阶偏导而计算的Obs 矩阵可表示为(Liu,Xin et al.,2019;刘彦楼 等,2016),
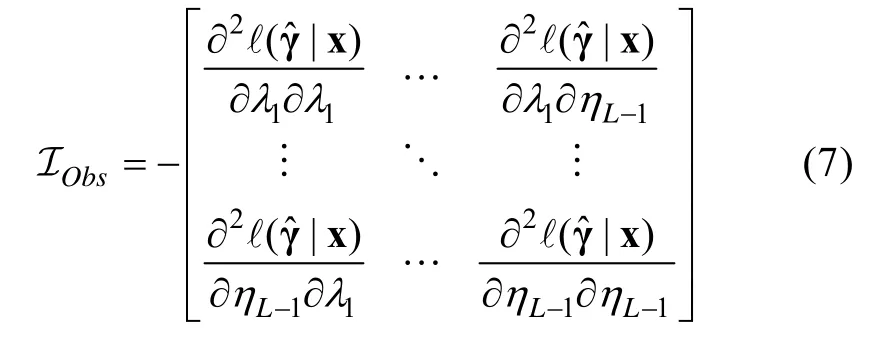
需要特别说明的是,Obs 矩阵中的元素也可以等价地表达为(Liu &Maydeu-Olivares,2014;Liu,Xin et al.,2019),

在公式(8)中,与分别表示任意一个项目参数()或结构参数();υ是作答反应矩阵x 中独特反应模式的数量;与(x)分别代表第υ 个观察到的独特作答模式所占的实际比例以及期望。Sw矩阵因其形状而得名,表达式为,
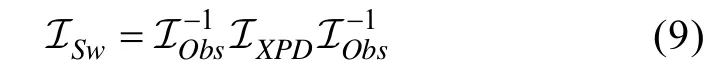
可以发现Sw 矩阵在计算过程中需要Obs 及XPD矩阵的参与。
基于以上陈述,接下来将重点阐述解析法信息矩阵的不足。首先,边界值问题会对解析法信息矩阵造成严重影响。在CDM 中,至少有两种情形会导致边界值问题,使得无法使用解析法信息矩阵计算或者使变大(DeCarlo,2011,2019)。一种可能的情况是:由于项目参数λ表示的是截距项参数,其取值范围介于[0,1]之间。然而,在λ的真值等于0 或1 的极端情况下,由于真值在参数空间的边界上,λ的估计值有较大可能会非常接近0 或1,造成项目参数的边界值问题。另一种可能的情况是:CDM 中有非允许存在的结构参数。当CDM中存在属性层级关系但使用饱和模型估计的时候,不可避免的有非允许存在的项目参数及结构参数。因为结构参数的取值区间为[0,1],非允许存在的结构参数的真值恰好落在参数空间边界上,其估计值可能会非常接近0,例如,10。边界值问题会造成解析法信息矩阵不稳定或者是奇异阵(Liu et al.,2021)。其次,如果非允许存在的结构参数的估计值偏离其真值0,那么这个估计值是有偏的,不再符合公式(5)中的前提假设,因此对XPD、Obs 以及Sw 矩阵的计算会造成不良影响。第三,可以发现,Obs 矩阵等于XPD 矩阵减去公式(8)中最右侧部分的表达式。但是由于计算误差的存在,Obs 矩阵中对角线元素可能会小于0,对应模型参数的无法计算,这是Obs 矩阵的一个不足(Liu &Maydeu-Olivares,2014)。
3 并行非参数化及参数化自助法
3.1 并行非参数化自助法
本研究新提出的pNPB 的具体实施步骤如下:
步骤(1),确定重抽样的次数,设定拟合模型;检测CPU 的核心数量,据此创建并行运算环境中相应数量的副本程序。

3.2 并行参数化自助法
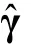
本研究新提出的pPB 的实施步骤如下:
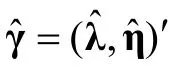
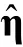

4 模拟研究
4.1 研究目的
CDM 完全正确设定或存在边界值问题时,pNPB 以及pPB 的表现是本研究重点关注的问题。模拟研究的主要目的有两个:(1)探讨在理想条件下,即模型完全正确设定时,pNPB 和pPB 在估计以及CI 时的表现;并与解析法XPD、Obs 和Sw 的表现进行比较。为使结果具有较好的一般性,数据生成模型及拟合模型均采用同一链接下的饱和G-DINA 模型。(2)探讨当属性层级关系存在时,即当模型的结构参数及项目参数均存在非允许存在的参数时,这两种方法在估计及CI 时的表现。需要特别说明的是,属性间存在层级关系时,XPD、Obs 和Sw 很容易出现无法求逆的问题(Liu et al.,2021),因此难以在完全相同的模拟条件下比较自助法与解析法的表现。
检索相关文献(例如,Bai et al.,2016;Efron &Tibshirani,1993;Guo &Wind,2021;Hayes,2009,2018;Lai,2021)发现,研究者对于重抽样次数的设置有较大争议,因此如何找到恰当的重抽样次数也是模拟研究关注的问题。
4.2 研究方法
本研究使用(Ma &de la Torre,2020b)软件包估计模型参数,参考(Zhang &Wang,2020)及(Bates et al.,2015)软件包中开源代码自编pNPB 以及pPB 代码,解析法信息矩阵XPD、Obs 和Sw 估计代码来自Liu 等人(2021),感兴趣的研究者可以联系作者获取。为保证各条件下CDM模型参数具有可识别性,尤其是属性层级条件下的模型参数的可识别性(Gu &Xu 2019,2020),本研究参考Ma 和Xu (2021)的实验设计使用图1 中呈现的Q 矩阵。另外,为清晰地探讨本研究中各自变量对pNPB 以及pPB 的影响,假定数据生成模型中每个条件下的结构参数相等,主效应及交互效应相等,以消除模型参数大小对实验结果的影响。使用云主机运行模拟程序,CPU 型号为英特尔i9-10980XE,18 核36 线程,每种实验条件组合重复=500次以获得稳定的模拟结果。

图1 模拟研究中使用的Q 矩阵
具体而言,数据生成模型有两种:饱和G-DINA 及存在层级关系(→,→)的HCDM。数据生成模型为饱和G-DINA 时,估计方法有5 种:XPD、Obs、Sw、pNPB 以及pPB;数据生成模型为存在属性层级关系的HCDM 时,估计方法有两种:pNPB 以及pPB。pNPB 以及pPB方法的重抽样次数有4 个水平:200、500、3000及5000 次。样本量有两个水平:1000 及3000。项目质量有3 个水平:高质量(( 0)= 0.1,(1)= 0.9)、中等质量((0)= 0.2,(1)= 0.8)、低质量((0)=0.3,(1)= 0.7),其中(0)表示仅凭猜测答对的概率,(1) 表示掌握项目所需要的全部属性的被试正确作答该项目的概率。所有条件下均使用饱和G-DINA 模型估计模型参数,也就是当数据生成模型同样为饱和G-DINA 时,模型参数是完全正确设定的;当数据生成模型为HCDM 时,模型中存在一些真值为0 的项目参数与结构参数,此时模型参数是冗余的。
4.3 评价指标
使用偏差(BIAS)以及95% CI 覆盖率评价估计方法的表现。模型参数估计值的95% CI 为:

4.4 模拟结果
图2 与图3 分别呈现的是CDM 完全正确设定时,使用pNPB 以及pPB 计算的项目参数95% CI覆盖率及的BIAS。在高质量项目条件下,绝大多数项目参数的95% CI 都落在图中灰线的理论范围内,BIAS 能很好地接近于0;并且随着样本量的增加这两项评价指标均在变好。在中等质量项目条件下,= 1000时尽管有少许项目参数的95% CI落在理论范围外且的BIAS 稍有波动,但绝大部分表现较好,这两个评价指标的波动明显高于高质量项目条件;= 3000条件下,尤其是≥500时,绝大多数项目参数的95% CI 覆盖率以及的BIAS 控制均有好的表现。在低质量项目条件下,使用pNPB 以及pPB 计算的项目参数的95% CI 覆盖率以及的BIAS 表现差异明显:在= 1000的条件下,使用pNPB 计算的项目参数的绝大部分在理论区间之上且倾向于高估,使用pPB 计算的项目参数的绝大部分在理论区间之下且会倾向于低估;另外可以发现随着样本量的增大,在= 3000条件下项目参数95% CI 覆盖率及的BIAS 的表现均在变好,且pPB 方法的表现优于pNPB。可以发现,当重抽样次数≥500时,相同条件组合下的模拟结果具有高一致性,尤其是=3000与= 5000两者之间没有发现明显差异。
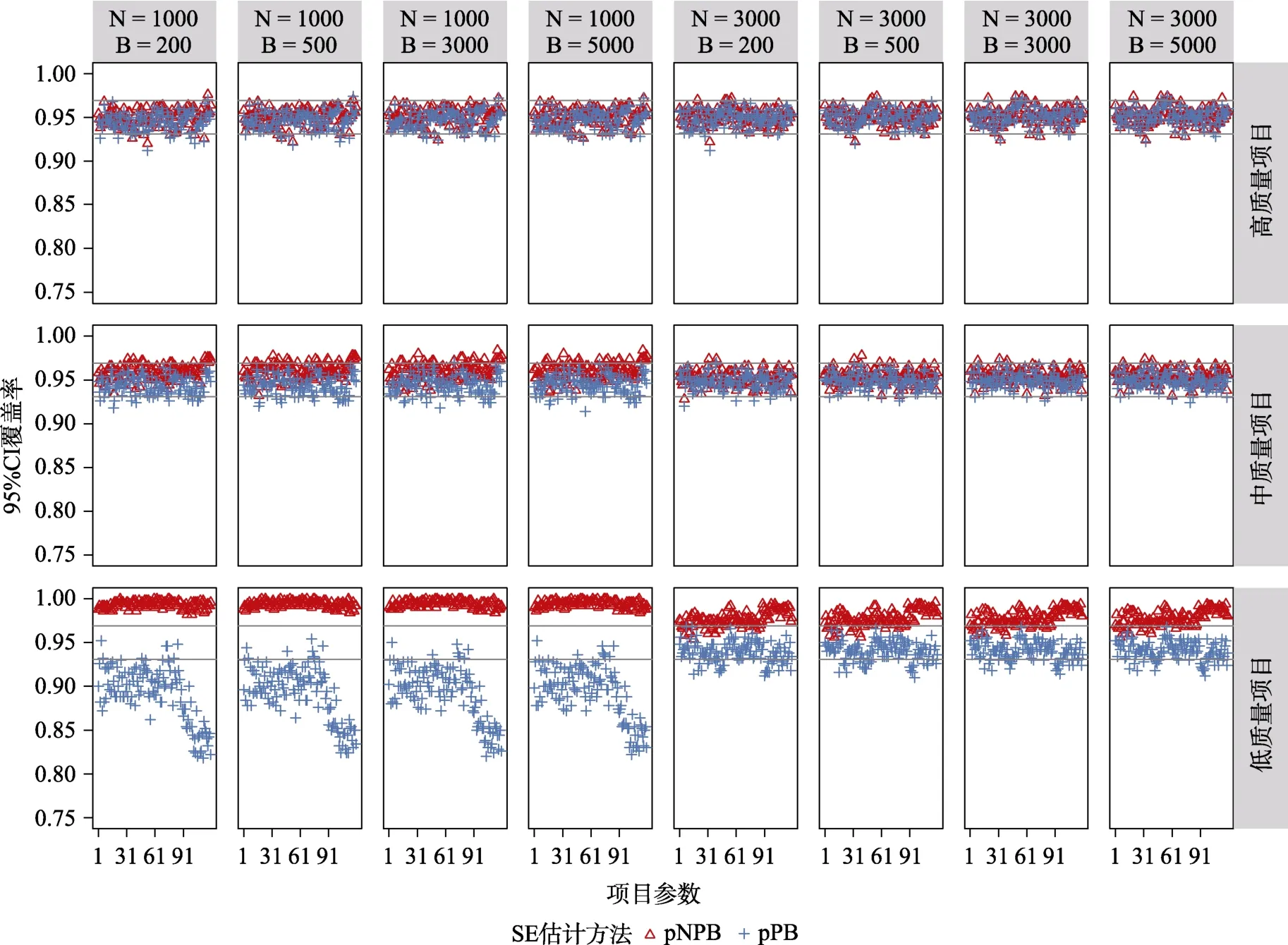
图2 CDM 模型参数完全正确设定时,基于pNPB 与pPB 的项目参数的95% CI 覆盖率
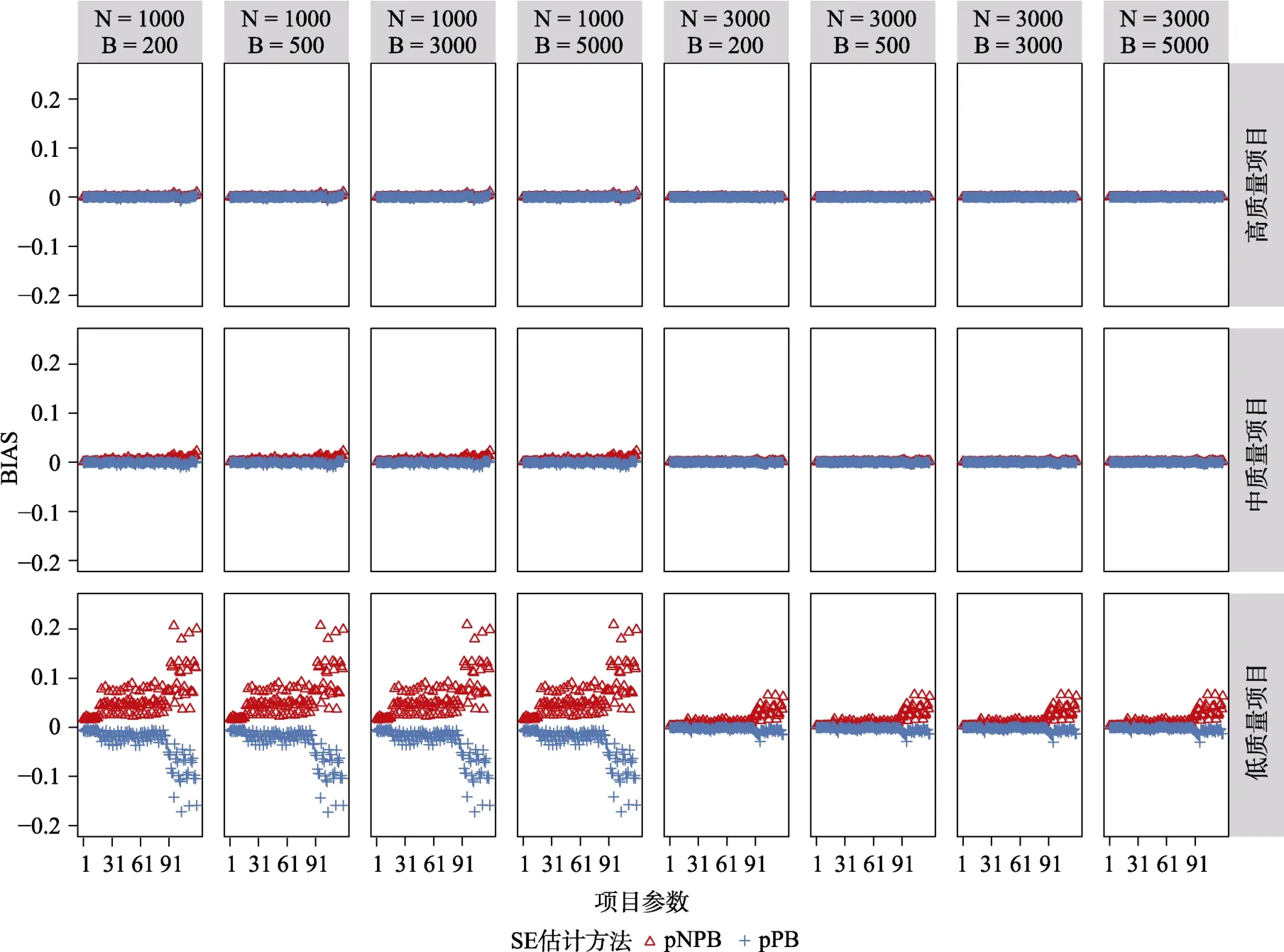
图3 CDM 模型参数完全正确设定时,基于pNPB 与pPB 的项目参数的SE 的BIAS
图4 与图5 呈现的是CDM 完全正确设定时,基于解析法XPD、Obs 与Sw 的项目参数的95% CI覆盖率及的BIAS。可以发现,高质量以及中等质量项目条件下的项目参数的有好的表现;= 1000时,Sw 矩阵的表现略微优于XPD 与Obs;当样本量增加到=3000时,XPD、Obs 以及Sw 矩阵的表现均在变好。对比高质量以及中等质量项目条件下XPD、Obs、Sw、pNPB 以及pPB 的模拟结果,可以发现多数情况下Sw 以及Obs 矩阵的表现略微优于其他方法。低质量项目条件下,XPD、Obs以及Sw 矩阵计算的项目参数的的表现受到较为严重的影响;= 1000时,XPD 与Obs 的95% CI覆盖率绝大部分在理论区间之下且会倾向于低估,Sw 的95% CI 覆盖率绝大部分在理论区间之上且会倾向于高估;=3000时,基于XPD、Obs以及Sw 的95% CI 覆盖率大部分在理论区间内。本研究还发现,低质量项目条件下的BIAS 结果中,基于XPD 及Sw 方法的项目参数的的结果分别有9 个及86 个在区间[-0.2,0.2]之外;检查发现,基于XPD 及Sw 方法计算的中有数值极端偏离正常值的结果(例如,估计值大于1000)。这也就是说,在低质量项目且= 1000条件下,XPD 及Sw方法的表现不稳定。综合对比低质量项目条件下,XPD、Obs、Sw、pNPB 以及pPB 的表现,可以发现Obs 略优于其他方法。
图4 CDM 模型参数完全正确设定时,基于XPD、Obs 与Sw 的项目参数的95% CI 覆盖率
图5 CDM 模型参数完全正确设定时,基于XPD、Obs 与Sw 的项目参数的SE 的BIAS
图6 与图7 分别呈现的是CDM 完全正确设定时,基于自助法的结构参数的95% CI 覆盖率及的BIAS。可以发现,在高项目质量条件下,使用pNPB 以及pPB 计算的结构参数的均有好的表现,所有结构参数的95% CI 覆盖率都落在图中灰线的理论范围内或边界上,BIAS 几乎完全与0 重合。在中等质量项目条件下,当= 1000时,尽管结构参数的95% CI 的波动明显增大,但是大多数结构参数的都有好的表现,且BIAS 波动也很小;当= 3000时,结构参数的的两种计算方法都有好的表现。在低质量项目条件下,结构参数的95% CI 覆盖率以及BIAS 的表现受到严重影响,当= 1000时,绝大多数使用pNPB 计算的结构参数95% CI 在理论范围之上且BIAS 明显大于0,使用pPB 计算的95% CI 全部在理论范围之下且BIAS明显小于0,重抽样次数的增加对于pNPB 及pPB的表现没有明显影响;当= 3000时结构参数的95% CI 覆盖率及BIAS 这两个评价指标均在变好,并且可以发现当≥ 3000时pPB 的表现略微优于其他重抽样次数下的表现;但是重抽样次数的增加对于pNPB 的影响较小。
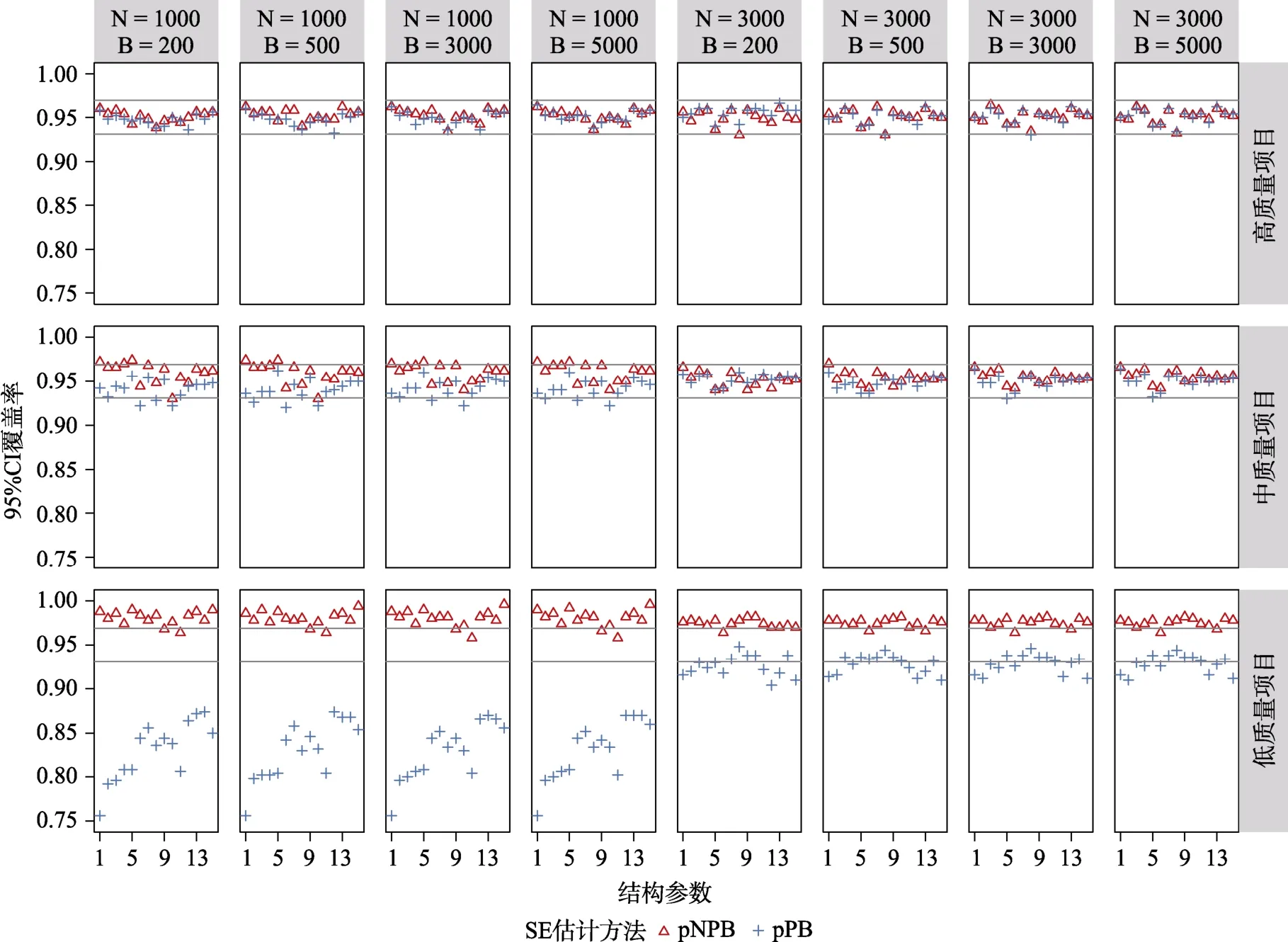
图6 CDM 模型参数完全正确设定时,基于pNPB 与pPB 的结构参数的95% CI 覆盖率
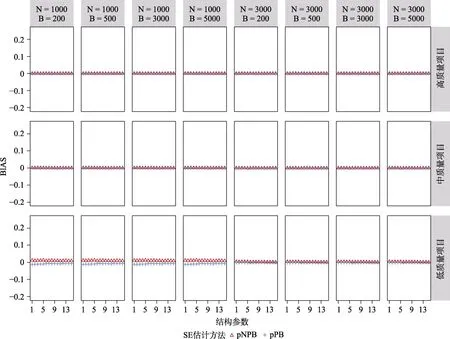
图7 CDM 模型参数完全正确设定时,基于pNPB 与pPB 的结构参数的SE 的BIAS
图8 与图9 中呈现的是CDM 完全正确设定时,基于解析法的结构参数的95% CI 覆盖率及的BIAS。在高和中等项目质量条件下,使用XPD、Obs 以及Sw 计算的结构参数的均有好的表现,几乎所有结构参数的95% CI 覆盖率都落在图中灰线的理论范围内或边界上,BIAS 几乎完全与0 重合。低质量项目严重影响了使用XPD、Obs 以及Sw 计算的结构参数的的表现;= 1000时,使用XPD、Obs 计算的结构参数95% CI 在理论范围之下且大多数BIAS 小于0,使用Sw 计算的95% CI大部分在理论范围之上且BIAS 明显大于0;=3000 时XPD、Obs 以及Sw 计算的结构参数95% CI覆盖率及BIAS 的表现均在变好,尤其是使用Sw计算的结构参数95% CI 大部分在理论范围内。另外,低质量项目且= 1000条件下,基于Sw 方法计算的结构参数的95% CI 覆盖率及BIAS 中分别有1 个及3 个值在图8 及图9 的区间之外;检查发现,与先前一样,也是由于基于Sw 方法计算的中有数值极端偏离正常值的结果。综合对比XPD、Obs、Sw、pNPB 以及pPB,可以发现除了低质量项目且= 1000条件下以上方法表现均比较差之外,Sw 方法的表现与其他方法相当或优于其他方法。
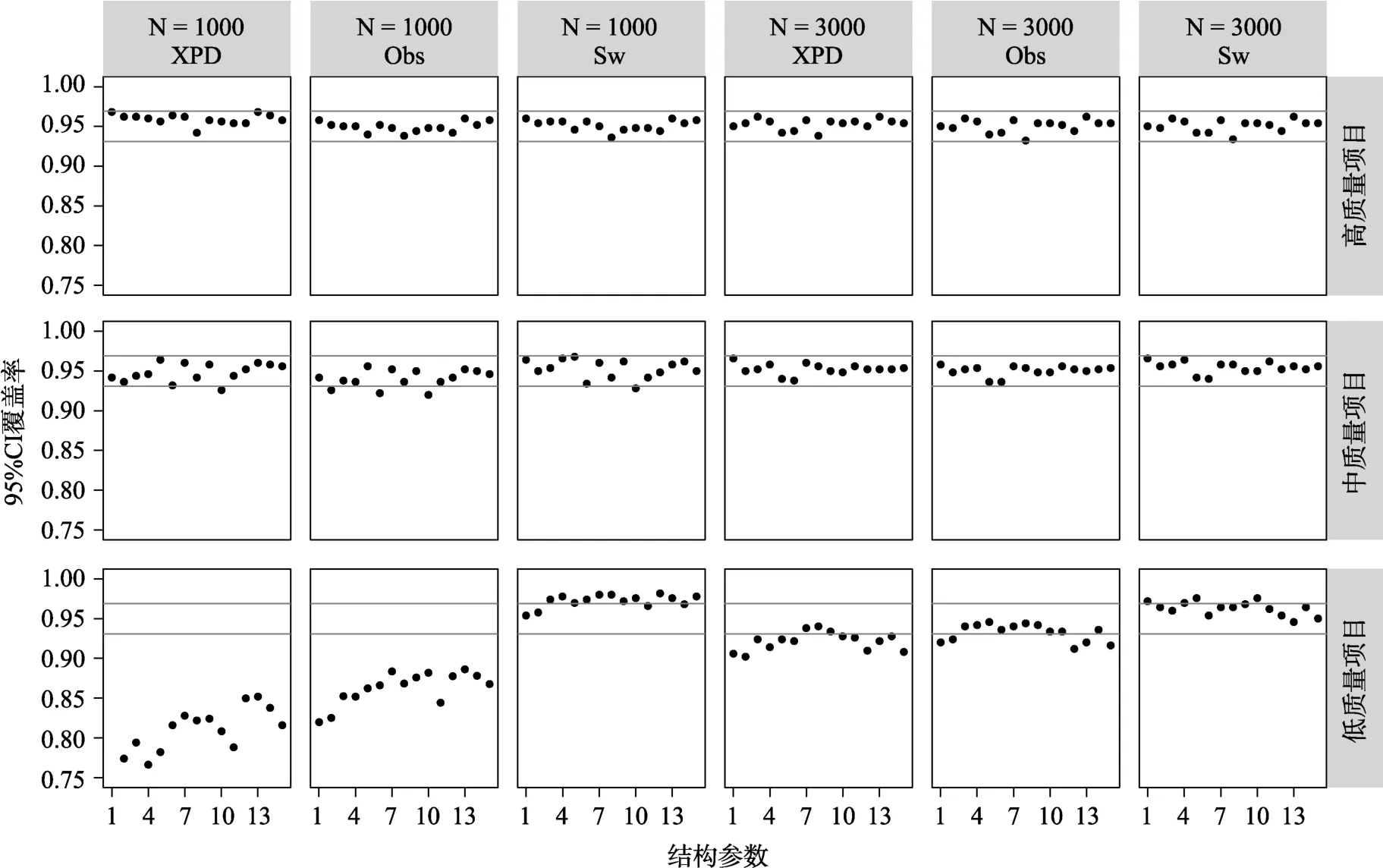
图8 CDM 模型参数完全正确设定时,基于XPD、Obs 与Sw 的结构参数的95% CI 覆盖率
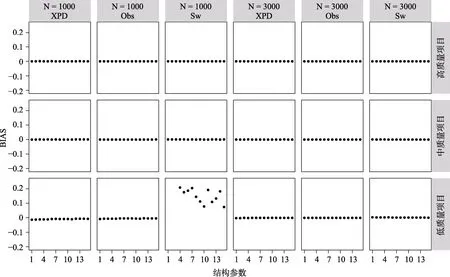
图9 CDM 模型参数完全正确设定时,基于XPD、Obs 与Sw 的结构参数的SE 的BIAS
如前所述,当数据生成模型是HCDM,但使用饱和模型(如饱和G-DINA)估计模型参数时,可能会导致模型参数估计值的边界值问题,造成解析法信息矩阵无法求逆或者会产生不稳定的估计结果。自助法不存在矩阵求逆问题,但这种情况下pNPB 以及pPB 的表现有待进一步探索。
在模型参数冗余条件下,按照允许存在参数及非允许存在参数这两类分别呈现项目参数及结构参数的的研究结果。另外,为完整显示全部结果,将模型参数冗余条件下的95% CI 覆盖率的坐标范围设置为[0.3,1]。图10 与图11 呈现的是允许存在项目参数的95% CI 覆盖率及的BIAS。可以发现,尽管在高质量及中质量项目条件下,绝大多数的项目参数有良好的95% CI 覆盖率及BIAS控制水平,但是有些参数的95% CI 低于图中灰线的理论区间,并且存在较大的BIAS;且在项目质量的所有水平下,这些极端偏离理论区间的项目参数的表现并没有随着其他实验条件的改变而发生明显的变化,甚至在= 3000时更加偏离理论区间。这主要是因为当使用饱和模型估计HCDM 时,由于错误地设定某些“非允许存在”的属性掌握模式为“存在”,造成了项目参数估计值存在偏差,影响了这些项目参数的95% CI 覆盖率及BIAS 表现。例如,对比公式(3)和(4),可以发现如果“真”模型是带有线性层级关系的HCDM,但使用饱和CDM 估计模型参数时,由于“非允许存在”的属性掌握模式α被错误地设定为“存在”,造成饱和CDM 中结构参数以及项目参数λ真值都等于0。除了极端偏离理论区间的项目参数外,仔细对比高质量及中质量项目条件下理论区间附近的项目参数,可以发现随着重抽样次数从200 增加到3000,项目参数的 95% CI 覆盖率略微变好,但是= 3000与= 5000两个水平下的结果高度一致。在低质量项目条件下,允许存在项目参数的95% CI 覆盖率结果波动明显。
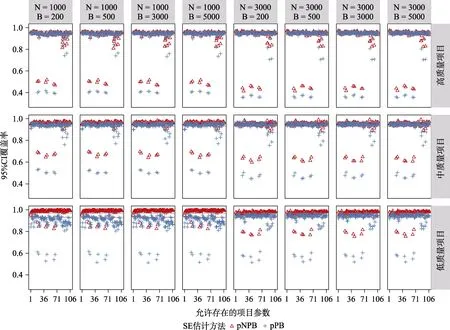
图10 CDM 模型参数冗余时,基于pNPB 与pPB 的允许存在项目参数的95% CI 覆盖率
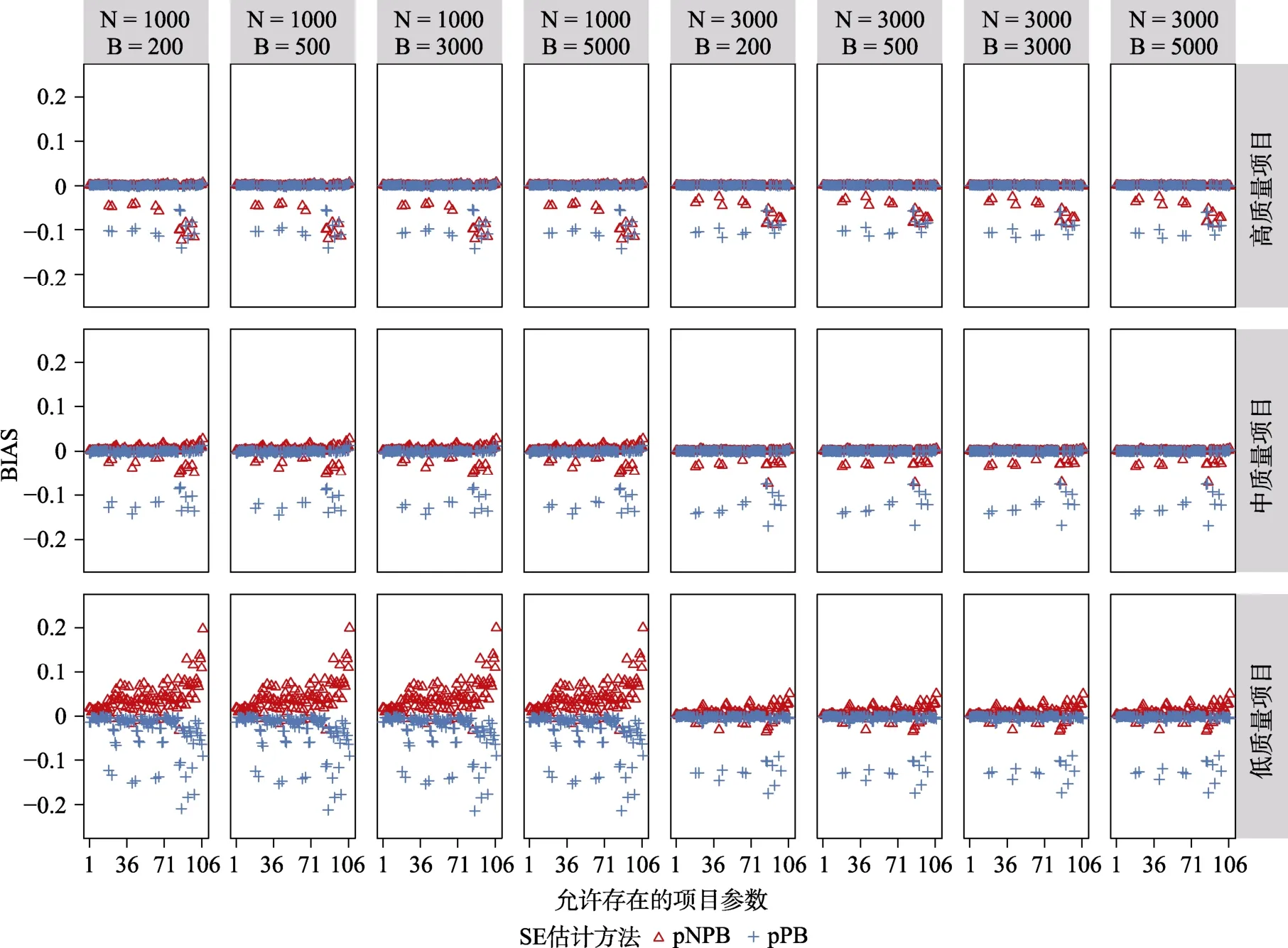
图11 CDM 模型参数冗余时,基于pNPB 与pPB 的允许存在项目参数的SE 的BIAS
图12 与图13 中呈现的是CDM 模型参数冗余条件下非允许存在项目参数的95% CI 覆盖率及的BIAS。整体而言,大部分非允许存在项目参数的95% CI 覆盖率低于理论区间,大部分的BIAS 值也低于0。并且在同一个项目质量水平下,这些非允许存在项目参数的表现具有较高的一致性。另外可以发现样本量、项目质量以及重抽样次数对于这两个指标没有明显影响。从估计方法角度而言,pNPB在估计非允许存在项目参数的的表现要稍微优于pPB。
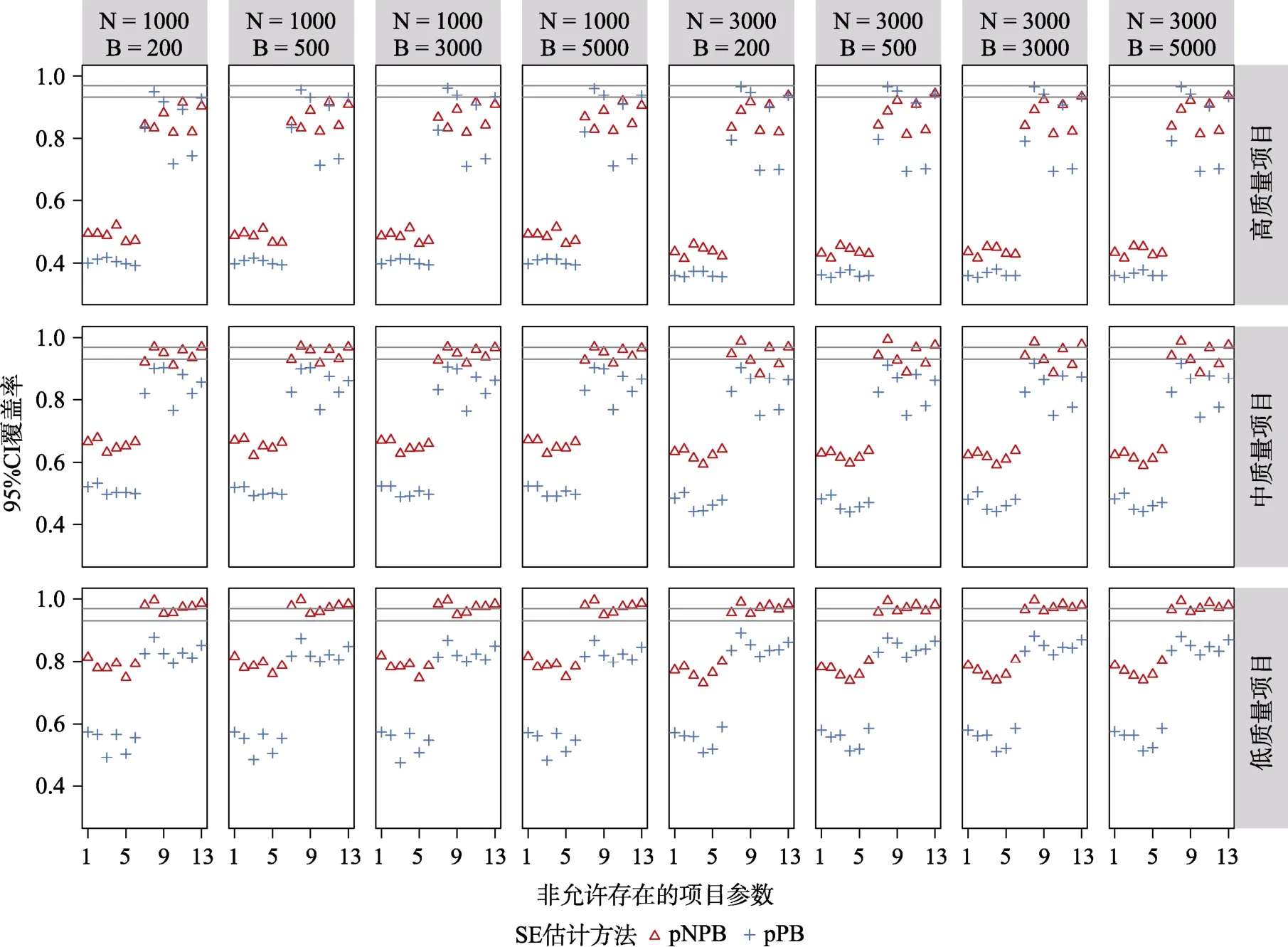
图12 CDM 模型参数冗余时,基于pNPB 与pPB 的非允许存在项目参数的95% CI 覆盖率
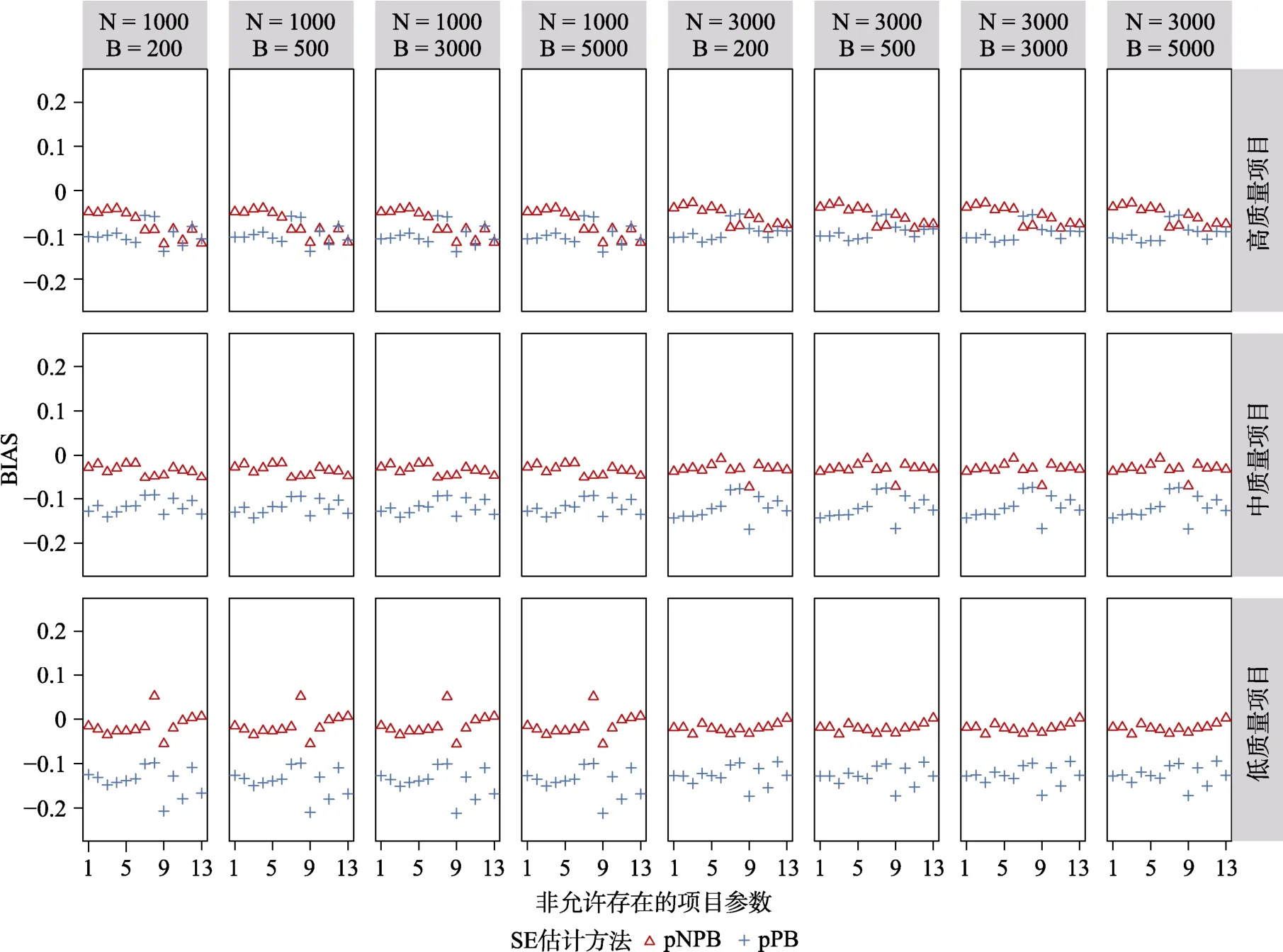
图13 CDM 模型参数冗余时,基于pNPB 与pPB 的非允许存在项目参数的SE 的BIAS
图14 与图15 中呈现的是CDM 模型参数冗余条件下允许存在结构参数的95% CI 覆盖率和的BIAS 结果。对于允许存在结构参数而言,在高质量及中等质量项目条件下,pNPB 及pPB 方法估计的95% CI 均在理论区间内或边界线上,且随着样本量及重抽样次数的增加也在逐渐变好,允许存在结构参数的的BIAS 也几乎完全与0 重合。项目质量对于结构参数的95% CI 覆盖率及BIAS 影响明显,可以发现随着项目质量降低结构参数 95%CI 覆盖率的波动明显增大,BIAS 对于0 的偏离也在增大。在低质量项目条件下,当= 1000时使用pPB 估计的结构参数的95% CI 覆盖率全部在理论区间之下,且通过BIAS 结果可以发现此种情况下pPB 倾向于低估;使用pNPB 估计的结构参数95% CI 覆盖率多数在理论区间之上,且通过BIAS结果可以发现这种方法倾向于高估;另外可以发现增加样本量可以改进pNPB 和pPB 的表现,但是增加重抽样次数几乎没有影响。
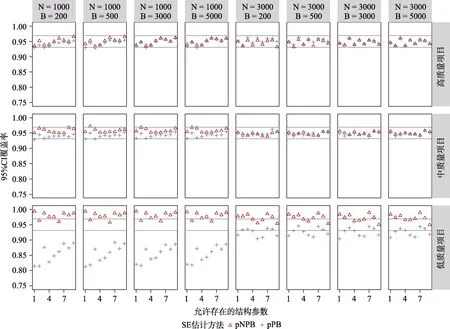
图14 CDM 模型参数冗余时,基于pNPB 与pPB 的允许存在结构参数的95% CI 覆盖率
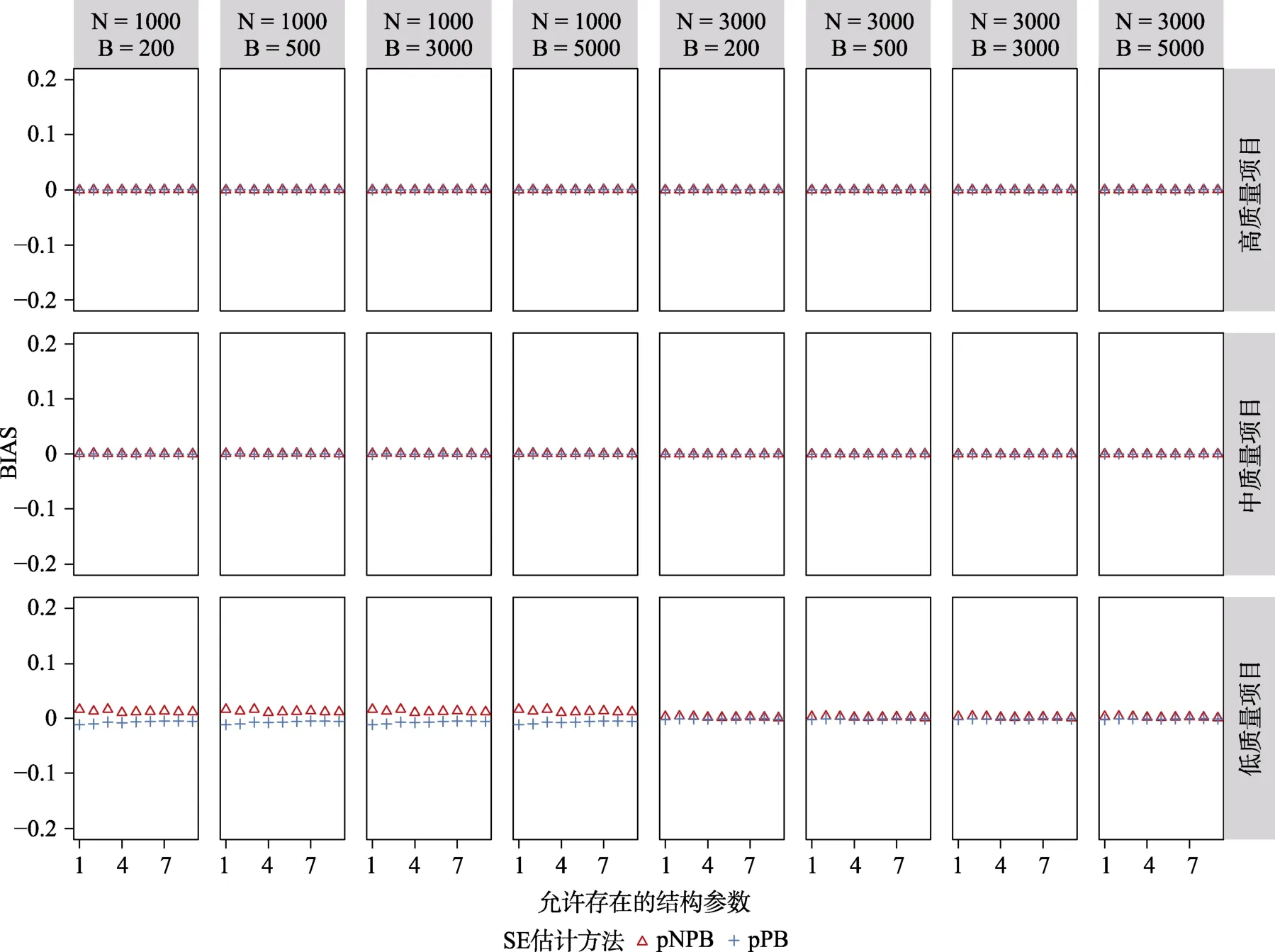
图15 CDM 模型参数冗余时,基于pNPB 与pPB 的允许存在结构参数的SE 的BIAS
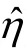
图16 CDM 模型参数冗余时,基于pNPB 与pPB 的非允许存在结构参数的95% CI 覆盖率
图17 CDM 模型参数冗余时,基于pNPB 与pPB 的非允许存在结构参数的SE 的BIAS

5 实证数据分析
在CDM 研究中,ECPE (the Examination for the Certificate of Proficiency in English;Templin &Bradshaw,2014)是经典的实证数据之一。本研究所用ECPE 数据通过(Robitzsch et al.,2020)软件包公开获取,包含2922 名被试在28 个二值计分的英语语法测验项目上的作答。英语测验的内容专家与心理测量专家合作研究认为:在这个数据集中共有3 个属性:(词法句法规则,morphosyntactic rules)、(整合规则,cohesive rules)以及(词汇规则,lexical rules),图18 中呈现了ECPE 数据集的Q 矩阵(Templin &Hoffman,2013);并且这3 个属性之间可能存在线性层级结构关系:→→(Liu et al.,2021;Templin &Bradshaw,2014;Wang&Lu,2021)。先前研究发现结构参数的在探索属性层级关系时有重要价值,因此本文以ECPE 数据的结构参数的估计为例,对比以往相关研究结果(Liu et al.,2021),展示本研究的理论与实践价值。

图18 ECPE 数据集的Q 矩阵
5.1 数据分析方法
5.2 研究结果
图19 中呈现了饱和结构模型中8 种属性掌握模式及其对应的结构参数估计值。表1 中呈现的是使用不同方法计算的图19 中呈现的结构参数估计值所对应的。对比使用不同方法计算的结构参数的估计值可以发现,整体上使用pPB 方法估计的与使用XPD 方法估计的在数值上非常接近;使用pNPB 方法估计的与使用Sw 方法估计的在数值上比较接近。对比pNPB 方法与pPB方法可以发现,pNPB 估计的的值比pPB 方法估计的值要大,这与模拟研究中CDM 模型参数冗余时允许存在的结构参数的及非允许存在结构参数的的结果是一致的。
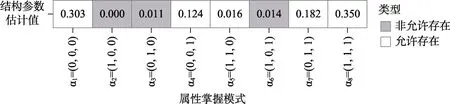
图19 ECPE 数据集中所有可能的属性掌握模式及其对应的结构参数估计值
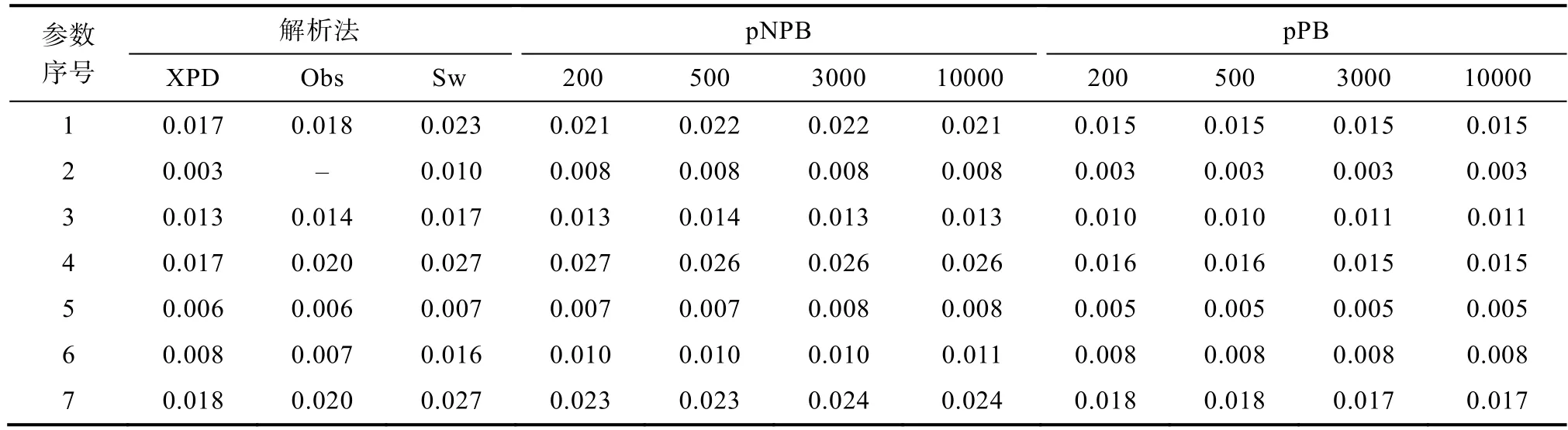
表1 ECPE 数据的结构参数估计值的SE
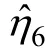
为了直观地说明pNPB 及pPB 在运算效率上的提升,本文比较了使用200、500 及3000 次重抽样时新方法与传统自助法在计算时间上的差异。结果显示:pNPB 耗时分别是10.93 s、25.43 s、135.36 s;pPB 耗时分别是15.42 s、36.01 s、200.96 s;NPB 耗时分别是158.43 s、392.97 s、2282.33 s;PB 耗时分别是220.77 s、537.15 s、3201.17 s。可以发现,pNPB及pPB 极大地提升了计算效率。
6 讨论与展望
CDM 研究中,模型参数的及CI 估计是一个具有重要价值且富有挑战性的问题(de la Torre,2011;Liu et al.,2021;Ma &de la Torre,2019;von Davier,2014)。解析法信息矩阵XPD、Obs 及Sw等在多数的应用情景中虽然有好的表现(Liu,Xin et al.,2019;Philipp et al.,2018;刘彦楼 等,2016),但其缺点在于需要矩阵正定,且易受边界值问题的影响(DeCarlo,2011,2019);传统自助法,如NPB以及PB 虽然具有前提假设少、通用性强的优点,但是存在计算效率低、耗时长的问题(Ma &de la Torre,2020b)。本研究提出使用pNPB 以及pPB 计算CDM 模型参数的及CI,系统探讨了模型设定、样本量、重抽样次数、项目质量及具体估计方法对及CI 估计结果的影响;展示了pNPB 以及pPB 在分析可能存在属性层级关系的CDM 实证数据ECPE 时的检验效果与计算效率。
特别指出的是,除了解析法信息矩阵、自助法外还有其他方法可以用于计算CDM 模型参数的与CI,如MCMC (Markov chain Monte Carlo)方法。MCMC 方法不仅可以用于计算模型参数估计值,而且可以通过计算估计过程中产生的模型参数的标准差,作为的估计。使用MCMC 估计CDM的模型参数,计算耗时可能会特别长(例如,大于1小时)。对于模型参数的及CI 进行研究时,需要进行大量的重复(如500 次或以上)才能获得可靠的模拟结果(Liu,Xin et al.,2019;Philipp et al.,2018;刘彦楼 等,2016)。另外,这类基于贝叶斯的方法可能对于先验分布敏感(Jiang et al.,2021)。因此,本研究没有探讨使用MCMC 算法计算CDM 模型参数的及CI 的表现。
6.1 讨论
(1)自助法在估计及CI 时的表现
本质而言,无论是NPB 还是PB 都是模拟从总体中抽样获得样本数据的过程:将样本或通过样本估计获得的模型参数认为是“总体”再抽样计算的,是对于“样本”的再抽样。也就是,自助法无法超越它所依赖的“样本”而凭空产生出更多的信息。因此,在CDM 的观察数据中所包含的关于未知参数的信息越多、越准确,自助法的效果会越好。模拟研究中发现,模型设定、样本量以及项目质量对于pNPB 及pPB 的表现有重要影响。这主要是因为在模型正确设定条件下,观察数据与模型是完美拟合的;而模型参数冗余条件下的情景与此相反,可以明显地观察到使用饱和模型拟合带有属性层级关系的数据时,由于非允许参数的存在,模型参数估计值的估计准确性受到了很大的影响。这从侧面说明了在CDM 中进行属性层级关系检验或探索的重要性(Hu &Templin,2020;Liu et al.,2021;Ma &Xu,2021)。样本量越大,所包含的关于未知参数的信息越多,模型参数估计值就会越准确;项目质量越高,越能有效区分被试的属性掌握模式状况,也就是说此时样本能够提供更多信息,从而使得pNPB 及pPB 的表现越好。通过模拟数据观察到的一个有意思的现象是在低质量项目条件下,与同实验水平组合的前半段参数相比,后半段的项目参数的 95%CI 覆盖率及BIAS 的表现明显变差。观察Q 矩阵可以发现,在最后4 个项目中每个项目都测量了3 个属性,也就是说每个项目中都有8 个项目参数需要估计,也就是在低质量项目条件下最后的4 个项目中可供利用的信息明显少于其他项目。
(2)重抽样次数对于自助法的影响
自助法是计算密集型方法,特定计算环境中重抽样次数越多计算时间也就会越长(Efron &Tibshirani,1993),就理论而言,重抽样次数的增加会增加估计准确的可能性(Hayes,2009,2018)。如前所述,在自助法中如何确定重抽样次数还没有明确的结论(Bai et al.,2016;Guo &Wind,2021;Lai,2021)。本研究在使用并行自助法计算效率提升的基础上,探索了=200、500、3000 及5000 时的表现。从整体而言,重抽样次数对于pNPB 及pPB表现的影响较小,当重抽样次数≥500时各条件组合下的模拟结果开始变得稳定,= 3000与= 5000两种重抽样次数下的结果则几乎完全相同。模型完全正确设定时一些条件下的参数或模型冗余设定时允许存在参数的95% CI 覆盖率及BIAS的表现随着重抽样次数从200 增加到3000 稍有变好;在一些非理想情景下,如项目质量低、非允许存在参数等,重抽样次数的增加对于pNPB 及pPB 表现没有明显影响。实证数据分析发现pNPB在200、500 和3000 下的结果与10000 次重抽样次数下的结果相比仅有细微的差别,pPB 在3000 次重复时的结果与10000 次重复下的结果几乎一致。理论上而言,CDM 的信息矩阵是关于观察数据中包含的模型参数信息的度量(Liu,Xin et al.,2019),而则是关于模型参数估计值不确定信息的度量(Liu et al.,2021),这也就是说,观察数据中包含“信息”量的多少是影响表现的主要因素。本文的模拟及实证研究支持以上理论,因此作者认为影响自助法表现的最主要因素并非重抽样次数,而是观察数据中所包含“信息”的多少。当然,本文结论是否可以推广到其他情景中有待进一步研究。
6.2 研究展望
有一些重要问题需要在后续研究中进一步探讨。(1)本文仅在项目数量为30,属性数量为4 的条件下展开研究,后续研究者可以继续探讨不同项目数量及属性数量对于pNPB 及pPB 的影响。(2)本研究仅以(→,→)层级关系为例,探讨了模型参数冗余设定对于pNPB 及pPB 表现的影响,然而不同属性层级关系条件下,模型参数的的表现,尤其是结构参数的的表现有待进一步探索。现实中不仅会存在属性层级关系,而且可能会同时存在属性之间的相关(Hu &Templin,2020;Liu et al.,2021),限于研究目的,本研究没有考虑这种情景。本文认为pNPB 及pPB 在探索及验证属性层级关系时的表现值得进一步研究。(3)除了本研究中使用的模型参数95% CI 计算方法外,还有一些基于自助法的CI 计算方法的表现也值得进一步关注(例如,Jiang,2021;Lai,2021)。(4)解析法信息矩阵在属性层级关系存在时经常会遇到无法求逆的问题,因此本研究无法直接比较这两类方法的优劣,Liu 等人(2021)初步提出了通过逐步排除非允许存在结构参数的两阶段模型参数估计的思路,这也是一个具有重要理论及实践价值的方向。本研究在CDM 模型参数完全正确设定条件下对比了解析法XPD、Obs、Sw、pNPB 及pPB 的表现,结果显示,解析法(如,Obs 或Sw)在一些条件下的表现要稍优于pNPB 或pPB。后续研究可以比较两阶段模型参数估计思路下的解析法与pNPB 及pPB 方法的表现。(5)需要特别指出的是,pNPB 及pPB 除可以用于计算及CI 外,还有很多潜在的理论及实践价值。研究者可以进一步探索pNPB 及pPB 在项目功能差异检验、项目水平上的模型比较、Q 矩阵检验等领域中的表现。(6)本文在CDM 框架下探讨了pNPB 及pPB 的表现,但是作为通用性强的一类方法,后续研究者可以在开发并行方法的基础上,在其他统计与测量模型中深入探讨自助法的表现,以解决先前研究没有明确的结论或结论相冲突的问题(例如,Efron &Tibshirani,1993;Hayes,2009,2018;Lai,2021)。
7 结论
结果显示:(1) CDM 完全正确设定时,在高质量及中等质量项目条件下,使用pNPB 及pPB 这两种方法计算的项目参数和结构参数95% CI 覆盖率及BIAS 均有好的表现;且随着样本量的增大及项目质量的变好,这两种方法的表现也在变好。低项目质量严重影响了pNPB 及pPB 的表现,pNPB 倾向于高估模型参数的,pPB 则倾向于低估。(2)在CDM 的模型参数存在冗余时,在高质量及中等质量项目条件下,使用pNPB 及pPB 这两种方法计算的大部分允许存在项目参数和几乎全部允许存在结构参数的95% CI 覆盖率及BIAS 均有好的表现,但是也存在部分项目参数的95% CI 覆盖率极端偏离理论区间且BIAS 值为负数的情况。非允许存在项目参数及结构参数的95% CI 覆盖率在大多数条件下表现较差。(3)探讨了pNPB 及pPB 在实证数据中的效果,发现使用pNPB 及pPB 计算的,获得了同先前研究一致的结论,即ECPE 数据中存在线性属性层级关系;同NPB 及PB 相比,pNPB 及pPB 极大地提升了计算效率,是简易、可行的及CI 计算方法。(4)综合模拟研究与实证数据分析结果,本研究初步认为:在pNPB 及pPB 方法中为快速预览估计结果可以选择200 次重抽样;为获得较为准确的估计结果,审慎起见可以选择3000 或以上的重抽样次数。
