基于最近邻值和枚举法的车号字符分割及拼接方法*
2022-06-01李吉俊董自健
李吉俊,董自健
(江苏海洋大学 电子工程学院,江苏 连云港 222005)
0 引言
车号字符分割是从字符组成的整个车号区域图像中分割出单个字符的过程。它是车号自动识别系统的中间环节,其分割结果直接影响车号最终的识别率。常用的字符分割方法有模板匹配法[1-2]、连通区域标记法[3-4]、垂直投影法[5-7]以及它们相结合的方法[8-10]等。基于传统垂直投影法的列车车号字符分割基本原理[11-12]为:列车车号各字符之间都存在一定宽度的间隔,对二值化后的车号图像逐列扫描并统计每一列的白色或黑色像素总和,以此即可绘制出车号字符的投影直方图。直方图中的波谷部分对应于车号字符之间的间隔(间隔区域的投影值很小或者为零),根据直方图中各个波谷的坐标位置及车号各字符的宽度先验知识便可实现对车号字符的分割。
针对货运列车车号字符的粘连或断裂问题,有学者提出了相应的车号字符分割方法。
牛智慧等[13]提出了一种基于字符轮廓上下特征以及字符宽度先验知识和数字字符弧特征的字符分割方法,该方法首先对车号字符进行预分割,然后对粘连的车号字符进行再分割以及对断裂的车号字符进行合并处理。杨吉[14]提出了一种基于轮廓检测和字符先验知识的车号字符分割方法:当车号字符不存在断裂或者粘连时,则直接寻找车号字符轮廓的最小外接矩形,并根据获取的矩形坐标信息来实现对车号字符的分割;当车号字符出现断裂或粘连时,则对断裂字符先进行膨胀操作使其形成一个连通域,然后再对粘连字符进行腐蚀操作,最后再根据轮廓检测和字符先验知识的方法对粘连字符进行均分,并依次输出最终的车号字符。王凯[15]提出一种由互相关性匹配、K-means聚类分析和字符比例先验知识组成车号分割方法,该方法首先建立标准数字模板图像并分别与待测车号图像进行二维互相关匹配,然后利用K-means算法聚类分析出所有车号字符最优的匹配结果,最后再根据车号字符高宽比例先验知识精准分割出每个车号字符。由于L70型货运列车车号字符宽窄不一、间距不等,因此该方法不适合本文的车号数据集。张晓丽[16]提出了一种自适应游程算法与包围圆算法相结合的车号分割方法。该方法先运用自适应游程算法对断裂字符的不同连通域进行合并重组,然后利用包围圆算法对车号进行分割。由于各字符的包围圆之间会有重叠,可能无法提取出字符的完整轮廓,因此,该方法也不适合本文的车号数据集。
考虑到货运列车车号前5个字符有着比较明显的规律和先验知识,本文提出了基于最近邻值和车号字符先验知识的分割方法来分割车号的前5个完整字符,然后再根据后5个断裂字符的先验知识,提出基于枚举法的车号断裂字符拼接方法来获取车号的后5个完整字符,最终完成对整个车号的分割。
1 本文方法
本文所提出的货运列车车号字符分割方法主要由图像预处理、获取字符投影区域边界所在列、基于最近邻值和车号字符先验知识的分割方法、基于枚举法的车号断裂字符拼接方法等4个部分组成。图像预处理部分主要是对车号区域图像进行高斯滤波、图像灰度化和OTSU二值化;在获取字符投影区域边界所在列的基础上,先采用基于最近邻值和车号字符先验知识的分割方法,然后再结合基于枚举法的车号断裂字符拼接方法,最终实现对整个车号的分割。
1.1 图像预处理
图像预处理部分主要由高斯滤波、图像灰度化和OTSU二值化操作三部分组成。首先对输入的车号区域图像(见图1a)进行高斯滤波去噪处理,然后对去噪后的图像进行灰度化处理,最后再对该灰度图像进行OTSU二值化处理。图像预处理的具体步骤如下。
步骤1:对输入的车号区域图像进行高斯滤波去噪处理。高斯滤波是对当前像素点及其邻域内像素点的像素值进行加权平均,并将加权平均的结果赋值给当前像素点。计算出图像中每一个像素点的加权平均结果,并用该结果替换所有当前像素点的像素值,即可得到整幅图像的高斯滤波结果。对输入的车号区域图像进行高斯滤波处理,结果如图1b所示。
步骤2:对去噪后的图像进行灰度化处理。车号图像灰度化就是把彩色的车号图像进行灰度处理,使其变成灰度图像的过程。本节选用加权平均法(令灰度值等于R,G,B 3个通道的值,分别乘以各自对应的权值,然后再求和)对车号图像进行灰度化处理,其处理结果如图1c所示。
步骤3:对该灰度图像进行OTSU二值化处理。日本学者大津(Nobuyuki Otsu)在1979年提出最大类间方差法,又称OTSU方法,其目的是最大化图像中目标与背景的类间方差。该方法会遍历所有可能的阈值,并在每一个阈值条件下计算此时的类间方差;当计算的类间方差达到最大时,此时的阈值即为OTSU方法所计算出的最佳类间分割阈值[17]。在经过高斯去噪和灰度化处理后,最大类间方差法处理的效果如图1d所示。

a 车号区域图像
1.2 获取字符投影区域边界所在列
根据车号区域二值化图像的投影直方图特征,可以很方便地获取各个字符投影区域的边界所在列,具体步骤如下。
步骤1:统计图1d中每一列黑色像素的个数总和,绘制出的直方图如图2所示。

a OTSU二值化图像
步骤2:观察图2中每一个投影区域可知,如果第i列像素总个数为0,第i+1列像素总个数不为0,则可将第i列视为该投影边界的起始列;如果第j列像素总个数不为0,第j+1列像素总个数为0,则可将第j+1列视为投影边界的终止列。运用上述方法获取图2中所有投影边界所在列的数值结果见表1。

表1 投影边界所在列的数值结果
步骤3:在由表1的数值结果所组成的列表中,如果列表中第1个元素与第0个元素的差值大于等于50,或者列表中第3个元素与第2个元素的差值大于等于60,又或者第5个元素与第4个元素的差值大于等于60,则表明在车号的底部出现了字符粘连的情况;然后对粘连的二值图像进行裁剪(仅保留倒数第12行之前的部分);最后再次获取裁剪后的图像所有投影边界所在列的数值结果。反之,则不需要进行该步操作。
1.3 基于最近邻值和车号字符先验知识的分割方法
设车号前5个字符的先验知识为:字符“L”的平均宽度为a,字符“7”的平均宽度为b,字符“0”的平均宽度为c,字符“8”的平均宽度为d,字符“1”的平均宽度为e,字符“L”和“7”之间的平均间距为ab,字符“7”和“0”之间的平均间距为bc,字符“8”和“1”之间的平均间距为de,字符“1”所在投影区域像素总数的最大值在整个投影直方图上较大。
车号前5个字符区域的投影边界所在列的数值保存在列表list1中,其投影边界所在列示意图如图3所示。其中,车号半个字符或者噪点边界所在列在图中未标出,完整的字符左右边界所在列由未知数x1,x2,…,x10标出;区间[x1,x2]为字符“L”的所在区域;以此类推,区间[x9,x10]为字符“1”的所在区域。本文基于最近邻值和车号字符先验知识的分割方法如表2所示。

图3 车号前5个字符区域的投影边界所在列示意图

表2 基于最近邻值和车号字符先验知识的分割方法
观察图2可知,投影区域即为车号整个字符或者车号半个字符或者噪点所在的区域。那么,各个投影区域边界所在列即为车号整个字符或者车号半个字符或者噪点边界所在列。在去除噪点区域(投影区域宽度小于8)所在列后,所得到的车号前5个字符边界所在列的数值结果如表3所示。由车号整个字符或者车号半个字符区域所在列的数值结果即可获取相应的字符图像或者半个字符图像,并把它们添加到列表list2中,由此得出的车号字符图像如图4所示。若列表list2的长度等于10,则说明10个车号字符是完整的,此时车号字符分割已经完成;若该列表的长度大于10,则说明有车号字符是不完整的,需要对此进行进一步的分割和拼接处理。
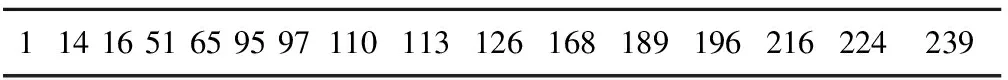
表3 前5个字符边界所在列数值结果

图4 车号整个字符和半个字符图像
由图4可知,车号字符由整个字符和半个字符组成,且它们出现的个数和位置难以确定,而车号前5个字符有着比较明显的规律和先验知识。因此本文采用本节所提出的方法来分割来车号的前5个完整字符。下面以图1d的车号区域二值化图像为例来介绍所提出的分割方法,其具体分割步骤如下。
(1)确定车号字符先验知识。车号前5个字符的先验知识由表4给出。

表4 车号前5个字符的先验知识
(2)分割车号第1个字符“L”。在表3的结果列表中寻找数值a=40的最近邻值,所求得的51即为字符“L”的右边界,设置字符“L”的左边界为1,即可完整地分割出字符“L”。
(3)分割车号第2个字符“7”和第3个字符“0”。在表3的结果列表中寻找数值x2+ab+b=88的最近邻值,所求得的95即为字符“7”的右边界;然后再寻找数值x4-b=70的最近邻值,所求得的65即为字符“7”的左边界。同理可以求出字符“0”的左右边界,因此可以完整地分割出字符“7”和字符“0”。
(4)分割车号第4个字符“8”。在表3的结果列表中寻找数值m-e/2-de=208的最近邻值,所求得的216即为字符“8”的右边界;然后再寻找数值x8-d=168的最近邻值,所求得的168即为字符“8”的左边界。根据字符“8”的左右边界即可完整地分割出字符“8”。
(5)分割车号第5个字符“1”。在表3的结果列表中分别寻找数值m-e/2=224和m+e/2=242的最近邻值,所求得的224和239即为字符“1”的左右边界。根据字符“1”的左右边界即可完整地分割出字符“1”。
采用上述方法所分割的车号前5个完整字符的结果如图5所示。
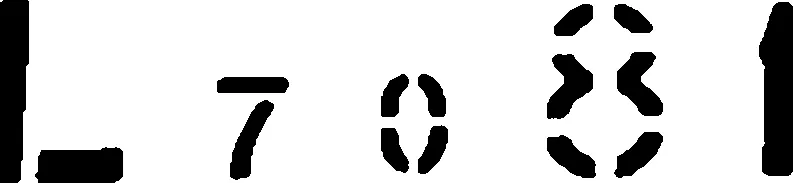
图5 车号前5个字符图像
1.4 基于枚举法的车号断裂字符拼接方法
本文基于枚举法的车号字符拼接方法具体内容为:首先根据车号先验知识判断出第6个字符是“1”还是“0”,如果是字符“1”,则说明它是完整的,不需要进行字符拼接;如果是字符“0”,则需要将两个断裂字符拼接成一个完整的字符。然后再根据车号先验知识对车号后4个字符进行标记,如果字符是完整的,就将其标记为1;如果是不完整的,就将其标记为0,则一共有24=16种可能的结果。最后再针对每一个车号区域图像,求出它的后4个车号字符所对应的标记结果,就可以根据特定的规律对车号后4个字符中的断裂字符进行拼接使其成为完整的字符。
这里仍以图1d的车号区域二值化图像为例,根据去除噪点后车号后5个字符边界所在列的结果,所得到的剩余车号字符图像如图6所示,并把这些字符图像存放在列表list3中。
下面以图6中的字符图像为例,来介绍所提出的基于枚举法的车号断裂字符拼接方法。由图6可知,车号的第6个字符“0”是不完整的,因此需要把列表list3中第0个和第1个元素进行拼接,由此可以得到完整的第6个字符“0”;车号后4个字符标记的结果为0,0,1,0,因此需要把列表list3中第2个和第3个元素进行拼接,由此可以得到完整的第7个字符“8”;同理,可以得到完整的第8个字符“5”和第10个字符“3”;第9个字符“7”是完整的,则不需要进行拼接。

图6 车号后5个完整字符和半个字符图像
采用上述拼接方法对车号后5个字符处理的结果如图7所示。

图7 车号后5个字符图像
本文在垂直投影法的基础上添加了基于最近邻值和车号字符先验知识的分割方法以及基于枚举法的车号断裂字符拼接方法,最终完成了对车号字符的完整分割,其分割结果如图8所示。

图8 车号字符图像
2 实验与结果分析
2.1 实验环境和实验数据
本文实验是在Windows 10专业版64位操作系统下进行,计算机的具体配制为Intel(R)Core(TM)i5-5200U CPU@2.20GHz处理器、8.00 GB内存。实验采用python 3.8.3编程语言对各类货运列车车号进行字符分割。
根据采集到的货运列车车号图像,可以把定位好的365张车号区域图像划分为6类数据集,各类数据集的情况如表5所示。

表5 各类数据集的情况
2.2 实验结果
采用本文方法对货运列车车号字符进行分割实验,并与引言中的某些列车车号字符分割方法进行对比。为了便于表述,将基于传统垂直投影法的车号字符分割方法记为方法一;将基于字符轮廓上下特征、字符宽度先验知识和数字字符弧特征的车号字符分割方法记为方法二;将基于轮廓检测和字符先验知识的车号字符分割方法记为方法三。各方法的分割结果见表6~表9(表中,正确分割示例用“√”表示;错误分割示例用“×”表示)。

表6 方法一对各类货运列车车号字符的分割结果
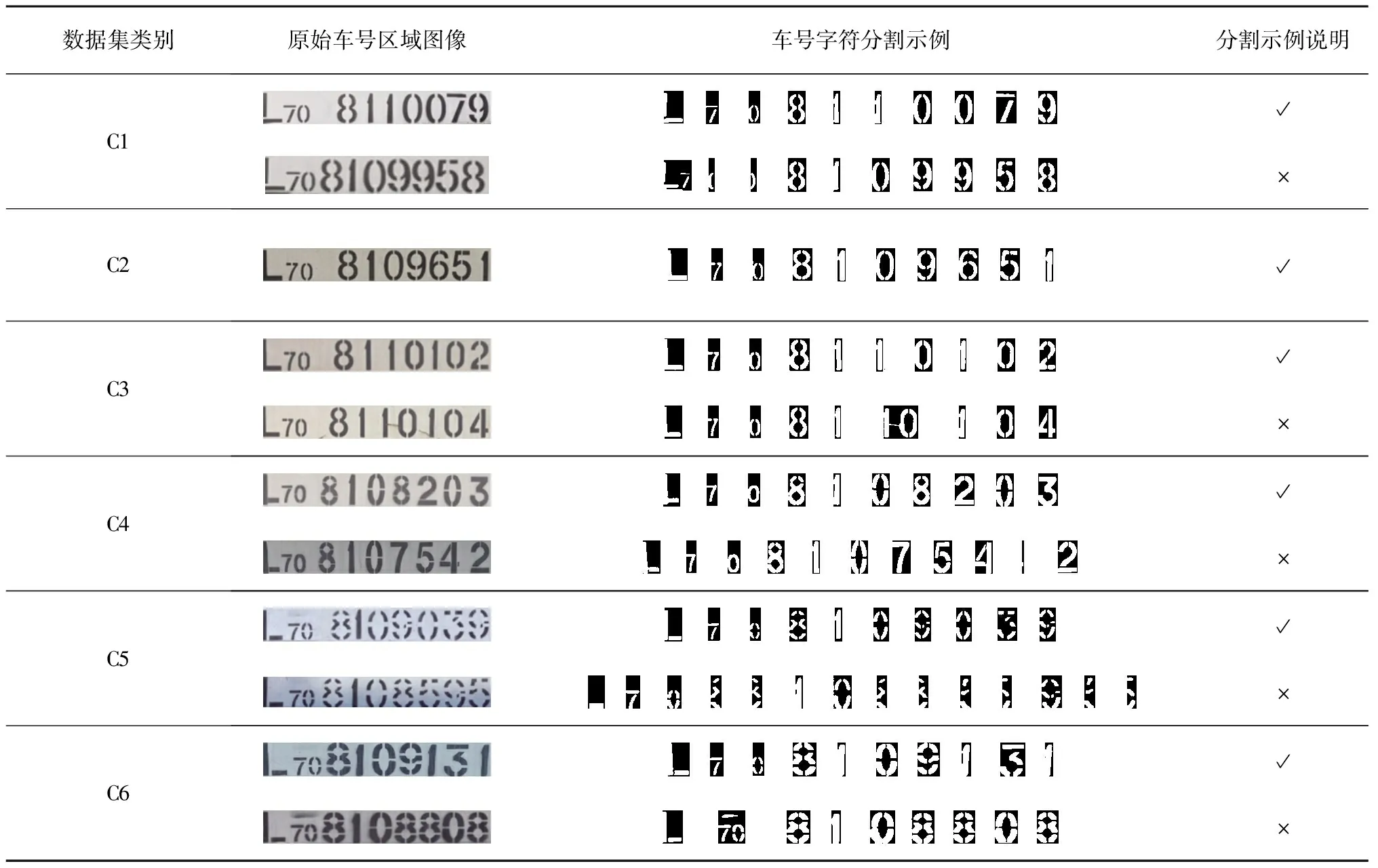
表7 方法二对各类货运列车车号字符的分割结果

表8 方法三对各类货运列车车号字符的分割结果
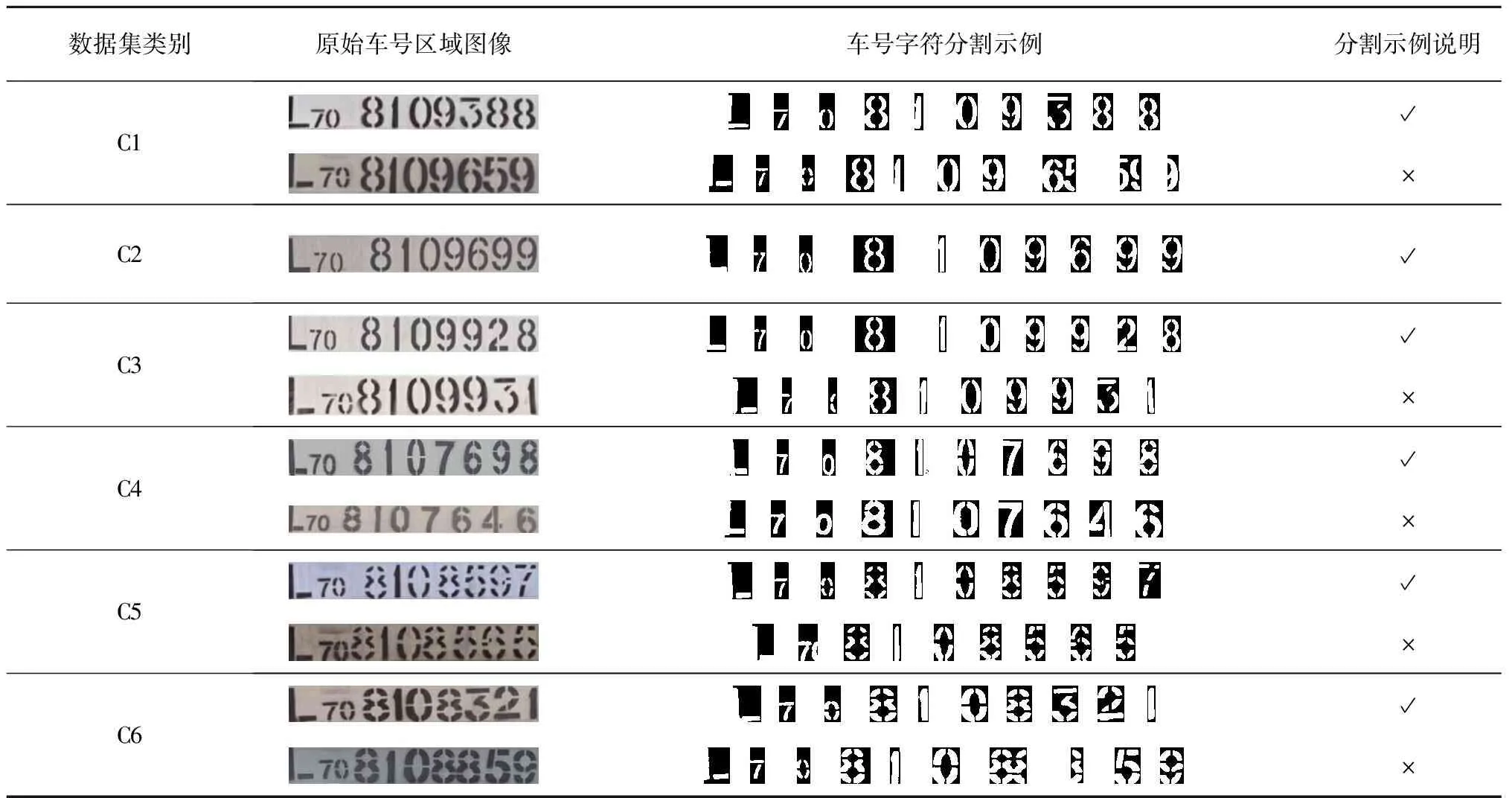
表9 本文方法对各类货运列车车号字符的分割结果
为了确保各类方法对货运列车车号分割的准确率,本文采用手动统计车号分割准确率的方法[18]。该方法首先检查从每一个车号上分割出来的字符是否为单个且完整的字符,若分割出的所有字符都是单个且完整的,则表明车号分割正确,然后统计正确分割的车号数量,并结合所使用的各类车号数据集,最后根据公式(1)计算出车号分割的准确率。统计各类数据集中车号全部分割完毕所用的时间,并重复记录11次,去掉最大值和最小值后所求得的平均值作为车号分割平均时间。各类方法对各类数据集中车号分割准确率和平均时间统计情况见表10。
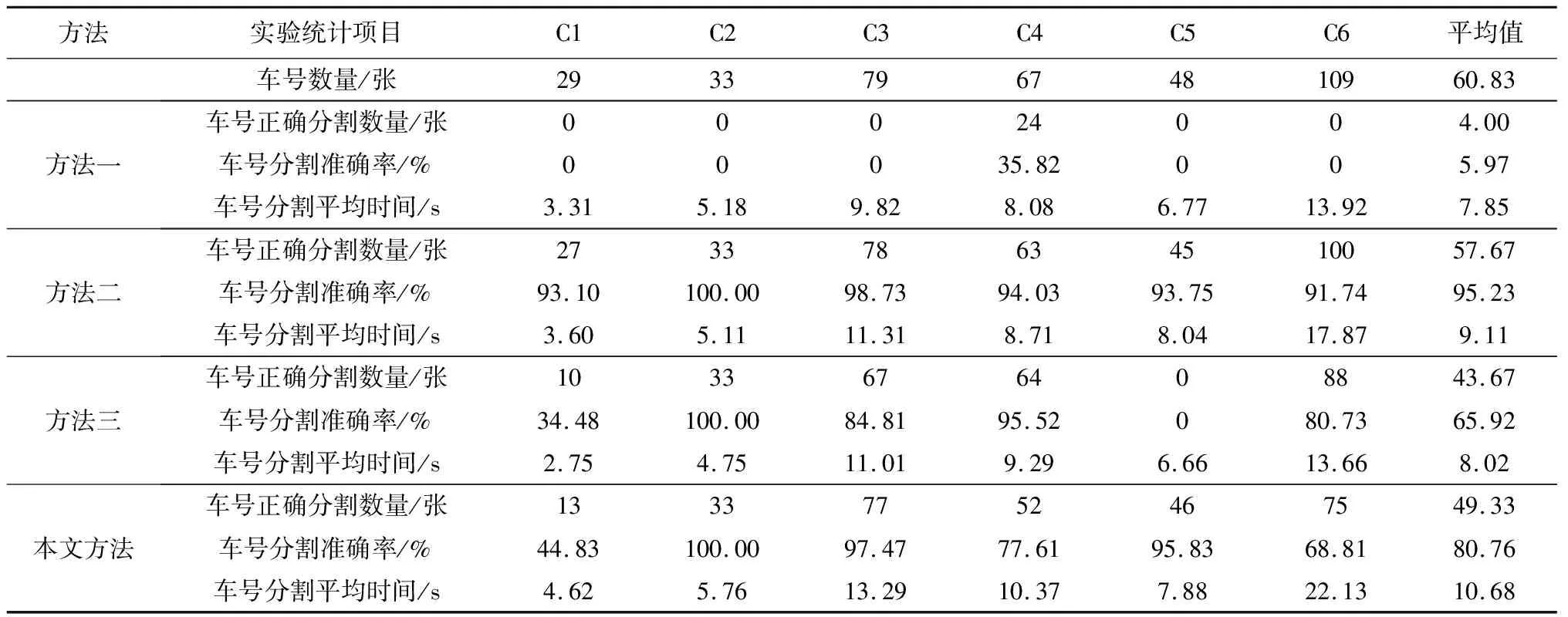
表10 各类方法对各类数据集中车号分割准确率和平均时间统计情况
车号分割准确率=

(1)
为进一步研究C5类车号图像旋转角度对车号字符分割准确率的影响,将车号图像分别旋转2°,4°,6°,8°,10°,12°,14°,16°,18°,20°,得到车号旋转数据集。最终的旋转角度与车号分割准确率的关系见表11。

表11 旋转角度与车号分割准确率的关系
2.3 结果分析
由表6可知,方法一对于质量较好且完整的车号字符分割效果很好,但对于断裂或者粘连的车号字符容易分割错误。
由表7可知,方法二对于车号左下边缘不全、车号自身存在锈迹、车号某些断裂字符不存在左右弧特征和车号某些字符上面存在噪声线条干扰等情况,车号分割时容易出现分割错误。此外,由于字符“7”和“0”之间距离太小或噪声干扰,导致其投影区域粘连在一起,从而使车号分割出现错误。由于车号底部噪声线条的干扰,字符在底部形成粘连导致车号分割出现错误。
由表8可知,方法三对于无法均分的相连字符(如字符“81”等)、形态学操作之后仍然断裂的字符、某些挨太近的字符(比如字符“7”和“0”)和左下边缘不全的这些车号而言,车号分割时容易分割错误。
由表9可知,本文方法对于车号中出现粘连的字符(包括完整字符之间的粘连、完整字符与半个字符之间的粘连和半个字符之间的粘连)、车号中某些挨太近的字符(如字符“7”和“0”)和某些特殊的字符(如字符“4”右边仅断裂一小部分)的这些车号而言,车号分割时容易分割错误。此外,由于极个别车号的第5个字符“1”,因不满足字符的先验知识,而导致车号分割错误。
由表10可知,方法二、本文方法、方法三和方法一对各类车号分割准确率平均值分别为95.23%,80.76%,65.92%和5.97%;方法二、本文方法、方法三和方法一对各类车号分割平均时间的平均值分别为9.11 s,10.68 s,8.02 s和7.85 s。由此可见,在对所有车号进行分割时,方法二要优于本文方法,本文方法要优于另外两种方法。然而在对C5类车号图像进行车号分割时,本文方法、方法二、方法三和方法一对C5类车号分割准确率分别为95.83%,93.75%,0和0;本文方法、方法二、方法三和方法一对C5类车号分割平均时间分别为7.88 s,8.04 s,6.66 s和6.77 s。由此可见,在对本文货运列车重度断裂的车号字符进行分割时,本文方法要优于其他3种方法。
由表11可知,随着旋转角度的增加,本文方法和方法二对车号分割准确率均一直下降至0;本文方法和方法二正确分割的车号数量的平均值分别为23.45张和22.82张;本文方法和方法二对车号分割准确率的平均值分别为48.86%和47.54%。由此可见,在本文货运列车车号出现重度断裂且存在一定旋转角度时,本文方法对此类车号的分割准确率要略高于方法二。
3 结论
本文针对重度断裂的货运列车车号字符分割准确率低的问题,提出了由图像预处理、获取字符投影区域边界所在列、基于最近邻值和车号字符先验知识的分割方法和基于枚举法的车号断裂字符拼接方法四部分组成的货运列车车号字符分割方法。实验结果表明,在对出现重度断裂的车号或者存在一定旋转角度的此类车号进行分割时,本文方法要优于基于字符轮廓上下特征以及字符宽度先验知识和数字字符弧特征的字符分割方法(方法二),但在对所有车号进行分割时,方法二要优于本文方法,本文方法要优于另外两种方法。今后将尝试对本文方法作进一步的优化,以提高其对C1类、C4类和C6类车号分割准确率。
