基于文本挖掘的国家重大工程审计风险分析
2022-05-30赵庆华张琳曹庆王笙宇
赵庆华 张琳 曹庆 王笙宇

摘要:文章以审计署的审计公告为研究对象,利用文本挖掘技术对国家重大工程项目审计公告展开研究,分析导致重大工程项目审计风险的主要原因和规律。同时,文章利用词云图将统计结果进行可视化呈现,运用TF-IDF算法找出导致重大工程项目审计风险的主要因素,并提出切实有效的重大工程项目审计风险管理建议。
关键词:重大工程;文本挖掘;审计公告;审计风险
随着我国经济的高速发展,一系列重大工程项目相继启动给我国的经济发展产生了巨大的助力,如三峡水利枢纽工程、港珠澳大桥、铁路“八横八纵”等。但因重大工程项目投资量大、社会参与度大、决策过程复杂、技术要求高、施工难度大、利益相关者多及项目的社会影响范围广等特点,导致这些项目面临着较高风险。因此,审计风险识别与分析对重大工程项目审计风险管理有极大的影响,更是重大工程项目审计风险管理必不可少的环节。
本文提出利用文本挖掘(Text Mining,简称TM)方法对审计署审计公告进行数据分析。通过对重大工程项目审计公告进行结构化处理,得到工程风险相关信息,进而利用关联分析技术对所得到的风险信息进行分析,探究重大工程项目风险发生原因及规律,以期为工程风险分析提供新的思路。
一、数据来源及分析工具
(一)数据准备
审计公告及解读是对国家重大工程进行项目投资决策、项目设计管理、项目招标投标、项目合同、工程造价、项目财务收支、项目管理、项目投资绩效等方面的审计解读。审计署网站搜集2004~2019年的审计报告48篇作为文本挖掘的语料,覆盖了保障性住房、大型机场场馆、灾后重建等房建市政类国家重大工程项目,以确保后续利用文本挖掘方法分析重大工程风险的客观性。
文章选取审计报告中发现的主要问题作为文本挖掘的语料,由于审计公告仅可以网页浏览,不能下载,便利用八爪鱼采集器从审计署网站上进行数据提取整理至数据库中,形成初始文本数据库。
(二)数据预处理
审计公告中的文本数据包含较多对本研究无用信息,因而需要对其进行文本预处理。本文主要研究重大工程审计风险发生的原因和规律,因此审计公告中的工程基本情况及审计总体评价、整改方法、审计建议等暂时不列入研究范围。
数据预处理中,准确合理地分解审计报告中各条结论至关重要。如审计报告中的某条的审计结论是“施工工艺和设备设计不合理”,分词得“施工”“工艺”“和”“设备”“设计”“不”“合理”,并未将“施工工艺”“设备设计” “不合理”分解成工程管理专用词语。为使分词结果达到预期效果,避免工程管理或工程审计专业词汇切分误差及停用词的干扰,在词典中加入了土木工程、审计相关词典和自建停用词表。预处理步骤如下:
1.语料库:利用python语言编程读取爬取的审计数据,数据存储类型为txt、csv等格式,形成语料库。本文利用python语言open("xx.txt",'r',encoding='utf-8').read()代码读取数据形成语料库。
2.自定义词典:分词工具虽然有默认词典和识别新词的能力,但仍会出现分词歧义,难以保证分词质量,需加入自定义词典保证分词准确。从搜狗输入法中下载审计常用词汇.scel、审计术语.scel、建筑词汇大全.scel及土木工程专用词库.scel等多个词典。使用jieba.load_userdict(file_name)加载自定义词典。
3.停用词典:分词后出现的某些语气词、虚词和数字,如“的”“呢”“2016”等,这些字词、数字的实际意义不大。为提高检索效率,本文对分词中出现的停用词进行筛选和过滤。建立适合的停用词表,与默认停用词表共同使用以过滤停用词,保证分词和可视化分析准确性。在python语言中,使用stoplist=[line.strip()for line in open("stopwords.txt",encoding='utf-8').readlines()]命令来达到去除停用词的目的。
做好以上分词准备工作后进行分词,并将相应的词频统计信息自动存储为csv文件保存至文件夹中。
二、基于文本挖掘的重大工程风险分析
目前,重大工程风险研究常用方法主要为案例总结法、专家调查法等定性分析方法,研究結果较为主观。文本挖掘则通过处理庞大的文本信息,挖掘文本中隐含的结构规律,以结构化方式表示,其分析结果相对客观。文本挖掘主要包括数据的收集及预处理、可视化分析和统计决策三个步骤。
(一)词频分析
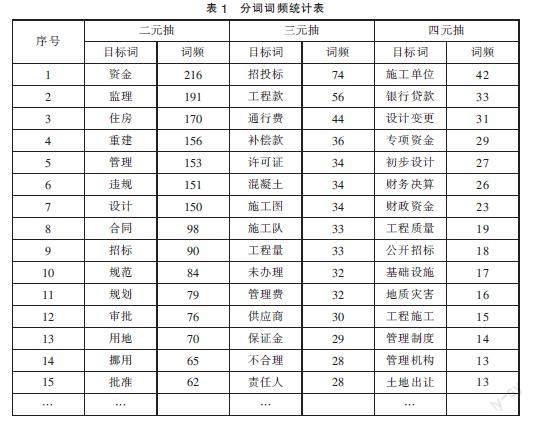
在python语言中利用jieba分词工具进行分词处理,去除词频数影响较小或词频数较低的词语,得到统计词频前500的词语。由于审计风险词语广、种类多、词语字数不一,因此使用split函数并自定义多元抽函数,通过for函数对其进行循环,利用count函数得到各风险词组词频。为了尽可能有效地挖掘到所需信息,本文主要针对由两个字、三个字、四个字的专业词汇及其所构成的词语进行重点分析。本文分别将两字词汇、三字词汇、四字词汇统计的分词按词频降序排列,然后选择其中词频较高的词语生成文档词矩阵列表,如表1。
在表1中可以看到,二元抽中“资金”一词出现的频率最高,共216次,相应可能发生风险的原因是投资控制不严,套取建设资金,多报、虚报骗取中央专项资金等。词频频数大于60的二元词汇审计风险多集中于工程项目申报,建设程序审批,招投标与合同以及资金管理,换言之,审计风险多发生于工程项目前期。其次,“合同”、“招标”、“规划”、“挪用”等与建设单位有关。可见,重大工程审计风险的发生与建设单位的制度完善和廉洁程度有较大关联。
在三元抽的情况下,“招投标”一词出现的频数最高,共出现74次,说明重大工程项目风险常出现在项目招投标阶段。在四元抽情况下,“施工单位”是出现频数最高的词语,共出现42次,阐释了重大工程项目风险来自施工单位。在这两种抽取模式下,“工程款”“施工图”“施工队”“工程量”“管理费”“设计变更”“工程质量”“工程施工”等词语说明主要风险词汇都集中在施工阶段,即审计风险主要来源于施工单位的施工风险和造价风险。
(二)可视化分析
数据可视化起源于20世纪50年代计算机图形学早期,将大型数据以图像形式表示,并利用数据分析和开发工具发现其中未知信息与规律的过程。本文利用词云图技术对文本数据进行分析,并生成可视化图像进一步分析其内在规律。根据分词所得到的语料库,利用python软件中“Wordcloud”包制作词云图,如图1、图2、图3和图4。
(三)基于TF-IDF算法的工程审计关键风险检索与分析
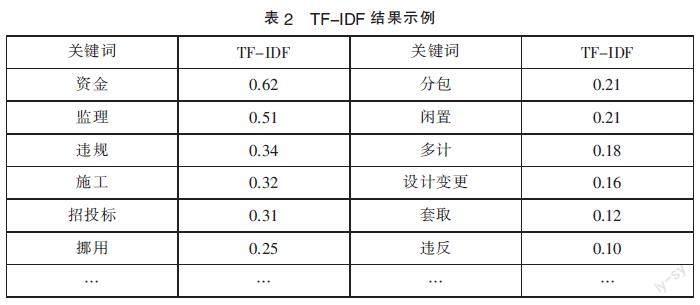
从词云图来看,虽然能够发现导致重大工程项目审计风险的分布情况,但高频词语中出现了大量的诸如“资金”、“管理”等对工程审计风险原因的判断没有明显影响的词语。因此需要运用其他方法提取工程审计关键风险。
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于文本挖掘与信息检索的常用加权算法。TF-IDF算法如下:
式中:N为文件集中文本的总数;N(x)为文件集中包含词x的文本总数。词x的TF-IDF则定义为:
利用TF-IDF算法进行关键词的筛选和整理,得到部分词语的重要性大小如表2所示。
1.建设资金(决策阶段):项目申报立项时,部分项目建设单位为套取国家资金,重复申报,随意扩大项目规模;项目施工时,挪用、挤占项目资金,多计工程款项,造成国有资源浪费。部分工程项目立项后各方资金到位情况难以把控,影响工程进度与质量。
2.招投标过程(招投标阶段):项目招投标时,标书审核不严,违规更改招投标方式,将应招标的工程化整为零规避招标,甚至有的单位将工程违规分包给无相应资质的单位,给工程项目建设带来质量、安全等风险,进而导致项目审计风险。
3.项目设计(项目设计阶段):在部分重大工程项目中,设计阶段管理混乱,因勘察设计失误,违反基本建设程序,设计变更多,变更交底不及时等,造成资金浪费和质量风险,导致工程项目审计风险增加。
4.项目施工(项目施工阶段):施工过程中,施工单位施工方案编制不合理,未按施工图施工,施工未严格按照施工工序,偷工减料;监理单位人员及其人员资质不足,相应申请表,变更签证等无监理单位意见,造成工程质量问题和进度滞后。
三、结语
本文利用文本挖掘技术对审计署审计公告数据就国家重大工程审计风险进行了统计分析。根据数据特征,提取出影响重大工程项目建设过程中的各种审计风险,利用文本挖掘,词云图等方式对统计结果做出分析与展示。结果表明:项目决策阶段,国家审核部门应对申报项目进一步了解,以防项目重复申报,项目规模与需求匹配,项目建议书中应考虑项目周边配套设施;招投标阶段,国家审计部门对项目展开跟踪审计,严格规范项目招投标行为,确保招投标过程公平、公正;项目设计阶段,建设单位组织项目设计、勘察、施工、运维单位审图,及时发现问题,确保项目设计变更较少,减少返工;施工阶段,施工单位做好施工人员安全知识培训,严格按照施工图和施工方案施工。监理单位严格检查隐蔽工程,变更签证,确保档案完整。
参考文献:
[1]向鹏成,罗玉苹.重大工程项目建设的社会稳定风险传导机理研究[J].世界科技研究与发展,2014,36(04):420-425.
[2]崔淼.审计视角下重大工程项目风险研究[D].扬州:扬州大学,2020.
[3]王明达,陈泼,陈子新,等.基于文本挖掘的物探作业事故分析方法[J].西安石油大学学报(自然科学版),2019,34(04): 119-126.
[4]郑石桥,时现,王会金.论工程审计内容[J].财会月刊,2019,861(17):102-106.
[5]Ma L,Zhang B,Cui M,et al.Adopting a Qca Approach to Investigating the Risks Involved in Megaprojects From Auditing Perspective[J].Discrete Dynamics in Nature and Society,2019.
[6]沈亮,戴洪帅,王天娇,等. 基于文本挖掘的石化安全管理及可视化研究[J].化工管理,2020,568(25):127-130+133.
[7]石凤贵.中文文本分词及其可视化技术研究[J].现代计算机,2020,684(12):131-138+148.
[8]Chen Z.A Dynamic System Approach to Risk Analysis for Megaproject Delivery[J].Proceedings of the Institution of Civil Engineers-Management,Procurement and Law,2019.
[9]严越,郑静,林德南,等.面向脑卒中防治知识图谱的风险评估与分类[J].医学信息学杂志,2020,41(09):31-36.
[10]李岩,郭凤英,翟兴,等.基于jieba中文分词的在线医疗网站医生画像研究[J].医学信息学杂志,2020,41(07):14-18.
[11]倪冰苇,赵鸿萍,顾月清.基于词云图和层次聚类的天然产物研究热点分析[J].中国新药杂志,2020,29(12):1326-1333.
[12]汪東升,黄传河,黄晓鹏,等.电信大数据文本挖掘算法及应用[J].计算机科学,2017,44(12):232-238.
[13]李金海,何有世,熊强.基于大数据技术的网络舆情文本挖掘研究[J].情报杂志,2014,33(10):1-6+13.
[14]马世龙,乌尼日其其格,李小平.大数据与深度学习综述[J].智能系统学报,2016,11(06):728-742.
(作者单位:赵庆华、张琳、曹庆,扬州大学建筑科学与工程学院;王笙宇,扬州维扬发展投资有限公司)
