基于Hadoop的分布式视频转码系统研究
2022-05-30邢艳芳周舒琪
邢艳芳,周舒琪
(南京传媒学院,江苏 南京 211172)
0 引 言
随着各类音视频平台的发展升级,产生了多种音视频封装格式和音视频编码格式。用户相应的转码需求日趋多样化且高清转码请求也日益增多。目前普遍采用的单机版视频转码技术的处理时间过长,占用服务器资源高,受制于单节点计算量和转码算法的并发能力[1]。在此基础上进行的技术革新仍会受到基本物理条件的影响,无法实现大幅度的转码速度提升。
音视频数据具有的数据量庞大以及数据非结构化的特点,导致难以使用普通的关系型数据库满足其数据存储的需求。虽然当前主流应用的磁盘阵列存储方法,其保密性和稳定性都达到很高的水平,但价格高昂,有一定的应用压力,而且无法实现数据储存与数据解析的一体化[2]。因此,为了解决存储额数据处理的问题,分布式的存储计算方式得到了研究发展。当前主要应用于互联网领域,如Facebook社交网站、淘宝、华为等。HDFS是根据Googles在创业初期设计发展的GFS(Google File System)分布式文件系统发展而来,它的工作机制是利用Hadoop实现海量数据存储的关键。
Hadoop系统通过底层的分布式存储系统HDFS优化存储方式,扩大存储容量,提高读写速度[3]。应用其突出的技术优势,该文提出一种基于Hadoop的分布式视频转码系统。依托Hadoop云计算平台,采用开源项目FFmpeg实现音视频编解码及格式转换等功能。
1 系统应用技术概述
1.1 Hadoop云平台概述
Hadoop由Apache基金会开发,是一种稳定的开源分布式结构框架,为当前常用的云计算存储平台之一,被国内外企业如Facebook、Amazon、网易、中国移动等广泛应用[4]。Hadoop的任务实现主要靠Client机器、主节点和从节点三部分。由主节点负责HDFS和MapReduce两大Hadoop关键任务模块的监督。
Hadoop由HDFS、MapReduce、HBase、Pig等成员组成,其中最基础的组成成分为底层数据存储系统HDFS和执行编程程序的MapReduce模型。采用开源项目FFmpeg实现音视频编解码及格式转换等项目。
1.2 HDFS分布式文件系统
HDFS是基于GFS发展实现的分布式文件存储系统。以流访问的形式对整体程序应用数据进行访问,减少数据错误率,提高数据吞吐量。同时对于音视频类特殊的非结构式的数据仍具有很好的存储能力。单个NameNode节点搭配多个DataNode节点进行工作是一个HDFS架构的典型集群方式。通常只有一台机器在存入中使用NameNode,处理实现过程中存储及管理元数据文件,设置数据文件命名,数据块复制,集群配置等功能。DataNode节点将数据存储在空间中,是文件存储的基本单元,并且每次写入中的设备都使用DataNode模型,周期性发送文件块报告给NameNode进行反馈通信。
1.3 MapReduce计算模型概述
MapReduce编程框架是适合应用于超大型数据集处理的编程模型。将数据运算分成了Map和Reduce两部分实现,互相独立又相互协同工作[5]。在Map阶段将完整数据分片发送至多节点上进行并行计算,完成后在Reduce阶段将其合并成为最终计算结果。可以简化在数据处理中涉及到的任务分配、容错处理、负载均衡量等问题。适合应用MapReduce计算方式的数据集必须要满足两大前提条件,首先元数据文件可以被分解为多个小型数据集,其次分成的每一个小的数据集都可以满足并行处理方式。
2 系统分析及方案设计
2.1 系统功能概要
视频文件常以帧形式存储,对于存储方式的选择具有很大的要求,视频的画面大小,拍摄质量,帧率编码的不同会导致存储容量发生变化。由于视频文件本身的特殊性,存储数据库需要满足连续读写以及数据流量大等特点。为实现多种编码格式之间的相互转换,则需要进行大量的数据分析运算。现有传统系统主要应用以下三种转码模式,很难高效完成如此体量的实时并发转码请求。
(1)单机模式:最基础也是最简单的服务方式。由用户和转码服务器直接交换数据实现。仅适合用于低转码量的目标文件,并且受单一转码服务器的性能限制,转码时间很难得到大幅度提升,转码质量也无法应对高数据量的转码任务。
(2)基于云的转码模式[6]:将第一种转码方式的转码服务器部署在云平台进行。利用云计算大幅提高了数据计算量和处理速度。但基本转码方式内核未得到改变,仍不具有高效率处理多并发转码任务的能力。
(3)分布式转码模式[7]:将大任务量视频分解成多个小任务量视频,分别传送到多个转码机器上进行数据处理,完成后将分片任务合成返回给用户。应用了并行转码的思想,降低了时间成本。但是操作复杂,很容易造成数据丢失和乱序排列。应用成本高昂。
根据现有的视频转码模式的问题进行总结,本课题利用分布式转码的并发转码思想和云服务器部署解决了实体转码服务器价格高昂的问题[8]。Hadoop平台自身的HDFS文件存储系统和MapReduce编程框架分别为海量视频存储和视频分段及任务下发的难题提供了简便的应用条件。系统应用的开源可编译的FFmpeg为视频转码过程中的解码和再编码提供了丰富的函数库支持。本系统结合视频存储和视频转码功能,大幅减少了转码时间,提高了转码效率。
2.2 系统的架构设计
2.2.1 系统架构模型
时至今日,“泰诺”投毒案仍未告破,强生公司的10万美元奖金还无人领取。但我们相信在安保体系更加完善的今天,恐怖袭击的阴霾终将消散。
系统整体架构模型如图1所示,系统主体由一个网络服务器(WebServer)和搭建其上的Hadoop集群组成。可以由多种形式的客户端(Client)对中心WebServer服务器发送访问请求,接收用户需要进行转码的视频文件。这类接收工作由服务器上Hadoop集群中的NameNode节点完成,并将其转发给集群中的多个DataNode节点进行数据处理,完成任务调度。
2.2.2 系统运行流程
本系统处理完成一个用户转码请求的步骤如下:
①用户Client发送请求:用户向中心服务器发送视频请求,如所需视频名称、视频格式、视频码率及其他视频信息。

图1 系统整体架构模型
②发送转码命令:由WebServer服务器对用户请求进行接收处理,并将其发送给承载的Hadoop集群中的NameNode节点上。
③进行分布式转码:由NameNode节点负责调用集群中的DataNodes节点,多节点进行转码任务的并行计算。
④完成视频转码任务:分布式转码进程结束后,文件会暂存在DataNode节点中。由NameNode向WebServer返回转码完成后的视频文件所在地DataNodeX。
⑤发送视频所在位置:将WebServer接收到的视频所在位置DataNodeX发送给用户端。
⑥读取视频:用户从DataNodeX节点上获取转码完成后的新视频文件。
3 系统模块设计
3.1 视频数据在HDFS上的存储模块
通常采用的视频分段思想主要分为以下两种:独立视频独立成段、单一视频多个分段方式。由于音视频文件本身数据为非结构化数据,不可直接采用传统压缩编码方式进行存储。HDFS中所有的文件都以数据块形式进行存储,每个数据块的大小都可以根据需求进行调整[9]。在执行集群处理时,由NameNode进行HDFS文件存储系统的监督调度,由从节点负责运行系统大部分功能,实行数据分析和计算,并需要对自身与主节点的通信进程进行监督守护[10]。
在文件写入HDFS文件管理系统的过程中,首先需要Client节点向NameNode名称节点获取文件写入许可;NameNode启动工作,此节点是整个文件系统中数据目录和元数据存放地点,负责获取和管理其下管理的各数据节点的运行信息,将文件存储的地址位置信息发送返回给Client;Client接收后,将各数据片段文件按顺序写入到对应的DataNode中。在文件读取的过程中,由Client向NameNode节点发起文件读取请求,NameNode节点对其回复文件存储的DataNode节点信息,以使Client获取完整文件数据。
视频帧分为IP、PF和BF三种形式。其中IF为关键帧,它是GOP的第一个帧,包含第一个场景的全部信息;RF为单项预测帧,它只保留与前一帧的画面差值信息;BF为双向预测帧,它存储了前后两帧全部的画面信息[11]。如果直接将视频数据存储至HDFS系统中,在后续分段中会导致视频分段之间存在关联性。由此可见,视频分片不可随便切割,要严格按照IF帧进行分片,以保证帧的完整性以及GOP画面的完整。
本系统利用了FFmpeg进行独立分段,将一个视频文件切割成多个独立段。首先设置一个固定的视频文件大小m(通常将视频切片数据大小设定为16 MB~64 MB),依照m的大小将整个文件分割成n份可以独立播放的视频文件。此时,在存储系统中会存在(n-1)个大小等于m的分段文件和1个小于或等于m大小的分段文件。之后将分段文件存储至HDFS中的n个大小为m的block中,在Hadoop的集群中进行存取。分割方式如表1所示。

表1 视频分割方式
由于分段视频文件大小m的选取存在差异,因此即使对于同一视频,也会存在不同的分段视频量n。虽然单一小数据量的视频段可以减少数据节点的运算压力,但是视频合成压力也应运而生,会对视频文件的读取和写入过程产生较大的影响[12]。以下选取一个1.2 G视频量的目标视频,探究不同数据量m和分段量对视频读取速度的影响,结果如图2所示。
从图表结果中可以看出,在整体趋势下,不同数据量m和分段量n在视频切割阶段的读取速度并没有存在很大的差异。但是,在对大数据量视频进行视频转码时,小数据量m的选取会导致分段量n的增加,这时会影响后续视频合成时的速度。并且过多切割可能会对切口处的数据量存在一定范围的丢失,不利于视频转码后的完整性,还是存在很大弊端,因此需要寻找一个最佳数据量mmax,以此实现功能的最大化。

图2 视频分段对视频读取速度的影响
在系统分片存储完成后,在分段分发的过程中应注意在NameNode节点上使用Hadoop balancer的命令,保证数据量均衡分布在各DataNode节点上,在后续MapReduce的工作过程中减少网络数据传输误差。
3.2 基于FFmpeg的分布式转码模块
FFmpeg[13]是一种适用于多种编译环境的跨平台开源多媒体架构,遵循LGPL/GPL许可协议。可以实现编解码在内的多种功能。包含了先进音视频编解码库libavcodes,因此在视频格式不断推陈出新的今天,它仍然可以支持最古老的视频格式。
在Map端实现转码时,需要对任务视频的多个分段部分分别进行转码,因此需要确保原视频文件的分段均匀发送给多个负责视频处理的DataNode节点,从而实现节点的最大化利用,将数据并行化处理的优势发挥到极致。在数据节点上,启动安装的FFmpeg设定转码参数,按照用户需求,对视频文件进行转码业务。在Reduce端进行视频分段的合并,和多节点转码不同,视频合并通常采用单一Reduce进行,负责将来自多个Map端的转码完成后的输出视频文件进行合并。
在功能上MapReduce实现将一个任务视频文件划分为多个Key/Value形式对的子任务文件。采用单个Map数值对应单个视频分段文件的方式进行文件输入,以保证单独视频段的完整性。依据特定的Map数值在HDFS存储系统中找到对应的视频分段文件,将其作为对应Key的value值返回,以Key/value函数对的形式写入Map函数,由Map()函数调度启用转码程序。
用户提交任务文件给JobTracer,一般一个处理过程中只存在单个JobTracer节点进行数据任务的分配和传达,而存在多个TaskTracer节点执行具体的数据处理操作。随后将分段后的切片文件作为小型数据块传送至Map节点;Map节点得到每个Key/value数据对,并通过处理写入文件;Reduce节点获取暂存文件中的多个Key/value数据对,根据相同的Key值进行匹配后迭代计算,从而将最终数据存入文件。由于整个Hadoop系统框架都是使用Java语言编写完成的程序,而FFmpeg的函数库是由C/C++语言编写,因此需要使用Hadoop Pipes工具或使用如图3所示的JNI技术调用[14],实现Java语言和C++程序之间的通信。

图3 JNI调用C/C++接口
视频转码系统的基本步骤是先解码后编码。在整个视频转码过程中,首先使用函数av_read_frame( )的调用实现视频码流中的单帧读取;随后通过向终端窗口输入avcodec_decode_video0( )视频文件格式解码命令和avcodec_encode_video0( )编码命令分别实现单帧视频的解码和重编码,最后写入文件[15]。
4 系统测试与数据分析
4.1 实验环境部署
本系统的部署主要分为两大部分,第一部分是完成Hadoop完全分布式集群的搭建与环境变量设置;第二部分是完成FFmpeg的转码功能部署。并且完成Hadoop核心文件core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml的部署。配置分发节点和集群全启动。本课题使用虚拟机进行系统测试。WebServer:使用2核CPU、12线G内存的笔记本作为小型服务器。Hadoop集群:三台虚拟机都使用Linux CentOS 7 64位系统。配置一台作为NameNode,其余两台虚拟机为DataNode。
4.2 实验视频输入条件
该实验视频文件按照FFmpeg模块设计的m值范围进行分片切割。分割后的视频片段数如表2所示。
4.3 实验结果与分析
实验从两种变量方式进行了设计,分别探究了不同条件影响下的转码能力差距。
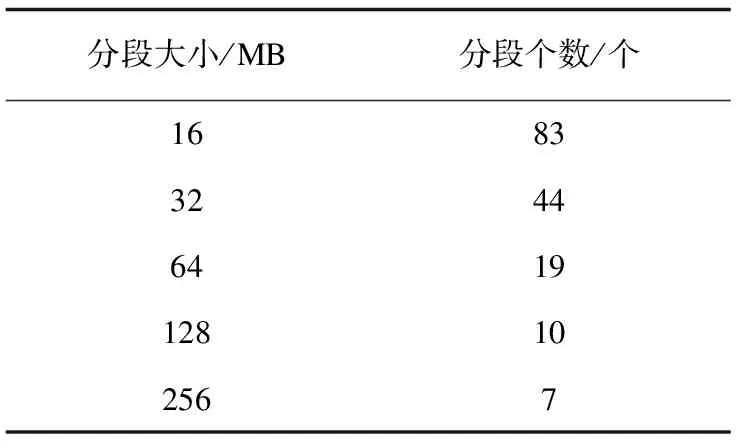
表2 视频分段大小与分段个数
(1)按以上实验视频的选取标准,将1.2 G的目标视频进行转码实现,实验目的是将MKV的视频格式转化为MP4的视频格式。转码方案都采用本课题设计的基于Hadoop的分布式视频转码系统。实验变量为目标视频不同大小的分段量,通过比较不同变量条件下对应使用的转码时间,得出最优分片大小。其结果如图4所示。

图4 分段式转码时间对比
从图中可以看出,当分段大小为32 MB时,达到折线最低点,仅使用351秒,转码速率最快。结合之前图3中的分析得出结论:当视频分段过多时,虽然单一视频分段所需的处理时间变短,但同样也增加了视频段合成的时间,造成了总体转码时长的增加。而在分片量为32 MB时,各节点处理任务的速度和合成节点还原视频文件的速度互相平衡,使系统运行速度达到最大值,因此32 MB为视频处理的最优分片量。
(2)在实验一的基础上,选取最优的32 MB视频分段。分别使用单台DataNode模拟的单机转码方式和多台DataNodes组成的分布式集群方式进行视频转码。利用本实验探究本课题设计系统相对于传统单机转码的优势,其实验结果如图5所示。

图5 32 MB分段下不同转码方式的转码时间
从图中可以看出,对于相同的目标视频,转码时间由单机方式转码消耗的952秒缩短至分布式视频转码方式的475秒。由此得出结论:使用分布式集群方式进行数据转码,可大幅度降低转码时间,提高转码效率。
5 结束语
相比于单机转码方式,分布式转码的转码时间更短,实验中的数据可以看出至少实现了50%的速度提升。增加数据节点数量可以分担各节点上的数据处理量,提高转码速度。但由于服务器计算能力的限制,越多的数据节点需要越高质量的处理器运行,因此转码时间也不会一直缩减下去,而是维持在一个临界点附近。在当前三网融合的发展策略下,企业和用户的需求得到了多样化变革。因此在挑战和需要并存的当下,该系统可以提供一种更高效、更便捷、更经济化的转码方案,是具有现实应用和客观商业价值的一款视频转码系统。
