基于关联规则对工业铀测量数据挖掘分析研究
2022-05-30刘宇红张荣芬
何 林,刘宇红,张荣芬
(贵州大学 大数据与信息工程学院,贵州 贵阳 550025)
0 引 言
近年来,传统工业正在经历改革变迁中,产业结构发生重大调整,2015年《中国制造2025》的提出为工业改革指明了方向,明确了以“智能制造”为核心的思想[1-2]。生产模式的改变必须注入新的技术,才能给改革带来源源不断的动力。在工业生产中为了提升产品质量,会在生产线上做出各种决策,根据生产情况做出调整,这个过程中会产生大量的数据。对数据的充分利用就起到了举重若轻的作用。工业数据具有多变量,复杂且具有相互耦合的特点。各变量之间相互牵制、相互影响,很难用传统的统计学表达数据之间的关系,数据挖掘技术恰好能解决这个弊端。其目的是挖掘有意义的规则,解决企业中数据利用率不足、技术标准不统一等问题[3-5]。
数据挖掘(data mining)是一门技术。顾名思义是为了发现数据中的知识,帮助人们做出最佳决策[6]。例如,李海洋等人对学生沐浴时间和成绩数据进行挖掘,通过对学生的洗澡数据与成绩挖掘分析,判断成绩的优良与洗浴数据之间的关键因素,发现下午洗澡次数越多,成绩越不理想,相对来说,晚上洗澡次数多的学生成绩比较优秀,并且不太爱洗澡的学生成绩也不太好,为学校学生管理工作提供有效性建议[7]。孔琪等人采用数据挖掘关联规则算法探究针灸治疗重症肌无力(myasthenia gravis,MG)的治疗方案,发现治疗眼肌型MG配合攒竹、阳白、鱼腰等近端取穴,全身型配合三阴交、合谷、阳陵泉等,辨证加减治疗能达到最佳治疗效果[8]。马文等人采用聚类方法将工业电气设备参数进行特征重组,利用重组结果进行数学化处理,进行特征匹配,为特征识别提供可依基础,最终实现大数据的多特征识别[9]。在工业数据挖掘领域,王雪姣等人根据工业生产班组运行质量问题,采用传统Apriori关联规则挖掘算法发现生产最优的最佳搭配班组,通过组合不同的生产班组,生产效果不一样,发现出现生产效果差的班组,进行相应的改造调整[10]。董轩萌等人采用传统Apriori算法对造成煤自燃的因素进行分析,根据煤中所含各种元素的比例,判断各种组成成分对煤自燃的正负相关性[11]。目前,利用关联规则算法对医疗数据进行分析已相对成熟且广泛,但在工业智能化生产领域能找到的相关文献却太少。在这个背景下,该文结合某企业工业铀产品生产的测量数据,将Apriori关联规则算法进行改进并应用于工业产品质量分析,以期为工业生产智能化与精细化提供支持,有一定的应用创新性。
1 数据清洗
数据质量会影响挖掘的效果,甚至会产生误导性的结果。工业生产过程中每时每刻都在产生数据,数据存在结构复杂,来源广泛等问题。例如值超出常规范围,数据不规范以及出现空值等问题。数据清洗能提升数据质量,数据清洗是数据挖掘过程中最重要的一个步骤。数据未经清洗就进行分析会产生误导性结果。如果存在大量不相关和冗余的信息或嘈杂且不可靠的数据,则在训练阶段进行信息发现会更加困难。因此,在对数据进行任何分析之前需要提升数据质量,进行数据清洗[12-14]。
在一些具体的实践工作中,数据库的清洗通常都是直接地占据整个数据分析工作全过程中的50%~80%。该文清洗内容主要包括以下几个过程:
第一,对产品缺失数据的处理,这一类缺失数据主要指的是一些产品应该有的业务信息系统缺失,如产品供应商的单位名称、分公司的单位名称、产品服务信息缺失,业务管理系统中的主表与业务明细表不能正确匹配等。对这一类型的数据进行过滤,按照对缺失的数据内容分别进行备份,标明内容出来,根据每个目标用户判断内容是否存在需要进行补充或者直接进行删除内容即可。
第二,查找数据集中是否存在格式错误,这一类格式错误数据产生的根本原因主要是由于业务后台系统不够健全,在用户接收到输入数据后没有对数据进行错误判断就直接将数据写入后台数据库。比如数值数据被传输成一个全角度的数字字符、字符串输入数据之间有空格操作、中英文符号用错、大小写没区分、日期书写不合规范等等。
第三,对一些出现逻辑问题的数据进行分析处理,这部分处理工作主要目的是为了彻底去掉一些通常只需要简单逻辑推理方法就可以直接快速准确发现这些数据,防止这些出现逻辑问题的数据对处理结果发生走偏。通常矛盾问题可以通过进行数据去重、去除不合理值、修改矛盾文件对象及其内容等多种方式得到有效解决。
2 数据处理
2.1 数据来源
该文的数据来自于某工厂生产铀时所记录的测量数据,总共有12 991条,4个测量参数,分别是:电压C、漏电流ESR、容量CAP、损耗D。在经过清洗之后还剩下12 533条,四个变量所描述的信息与产品质量有关,产品质量可分为三类:“优” best,“合格” ok,“不合格”bad,变量类型如表1所示。
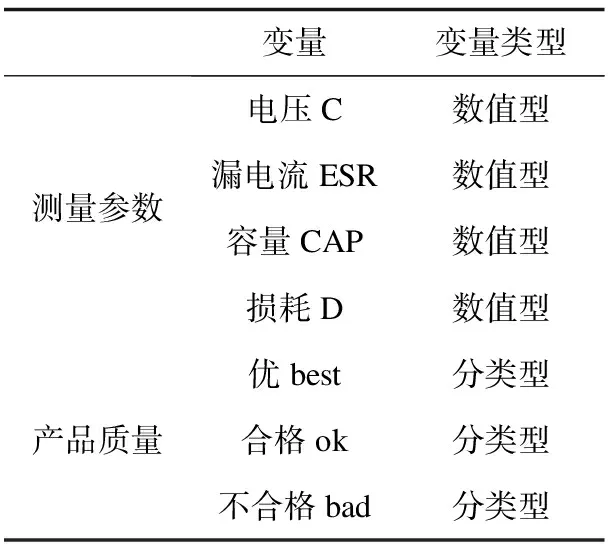
表1 变量描述及说明
2.2 利用K-means对数据进行聚类分析
根据企业的需求,该文需要对产品测量参数挖掘有用的信息。在对数据进行分析之前需要对数据进行离散化处理。离散化结果会对后续挖掘结果产生影响。戴新建利用K-means算法对电视用户信息进行聚类分析,分析各类用户给企业带来的营销价值[15]。张莉为了找到影响成绩的因素,利用K-means算法聚类学生成绩,再结合ID3算法构建一棵完整的决策树[16]。上述学者利用K-means算法对数据集进行离散化处理分析均取了得优的效果。该文利用K-means算法对工业铀的测量数据进行离散化处理,得到不同区间的类别来代替离散化数据。
K-means算法是机器学习中最为经典的算法之一,其主要目的是为了发现数据集的分类情况,根据要求分成适合的簇。
算法基本原理为:
确定需要的K个簇的质心,往往质心是随机选择数据集中的K个点作为初始质心且K个点之间的距离尽量大。计算数据集点与质心之间的距离,并将离最近质心的点分配给该质心所属的簇。经过一轮之后每个质心点都会拥有自己所属的簇,此时通过计算各簇中所有每个点的质心平均值作为计算下一轮的质心,直到质心点不再发生改变。
通常情况下,由于产品质量的差别,测量值会发生较大的波动,不同规格的产品,测量参数往往会聚集在某一区间。利用数据分布区间大,根据数据点间距离远这一特点,采用K-means算法对数据进行离散化处理,将处于不同区间的测量值进行聚类处理,为之后做关联规则分析提供有效的输入。经过K-means算法处理,得到了以下最佳聚类效果,如表2所示。
表2描述了测量数据经过K-means算法处理后,测量参数聚类的类别数以及每个类别所属区间值,其中电压C聚类成4个类别,漏电流ESR聚类成3个类别,损耗D聚类成4个类别,容量聚类成3个类别。
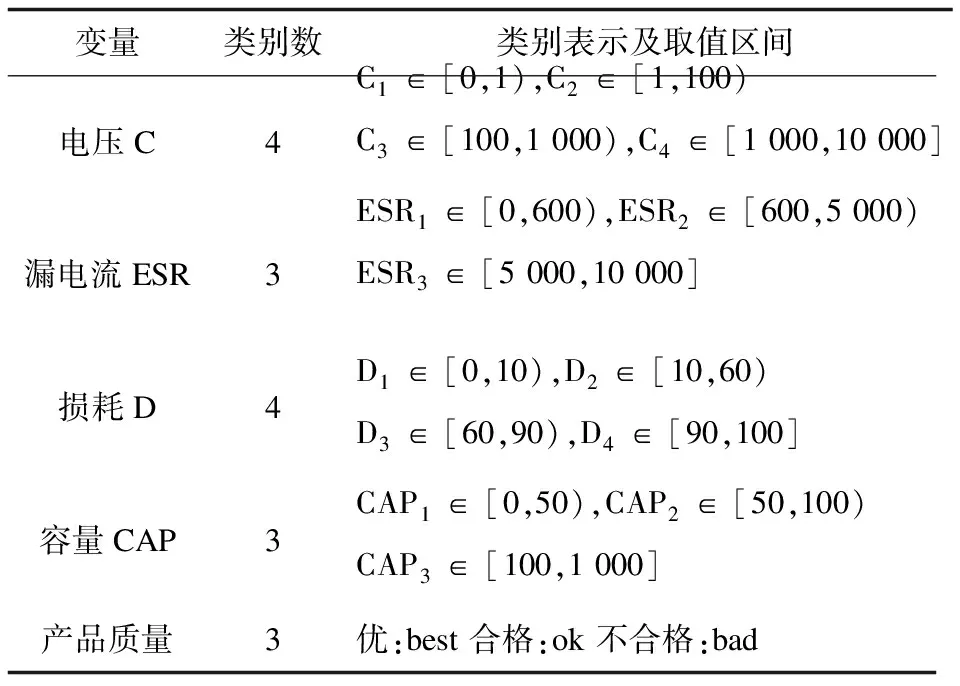
表2 测量数据分类说明
根据分类结果,挑选部分数据进行说明。电压值处于[0,1)会被聚类成C1类,处于[1,100)聚类成C2类,如:表3中编号1这一行中电压值为3.1,根据聚类结果为C2类,如表4中编号1电压C所示;表3中编号4这一行中电压值为0.22,根据聚类结果为C1类,如表4中编号4电压C所示。漏电流值处于[0,600)会被聚类成ESR1类,处于[600,5 000)聚类成ESR2类,如:表3中编号1这一行中漏电流值为188.3,根据聚类结果为ESR1类,如表4中编号1漏电流D所示;表3中编号3这一行中漏电流值为4 354,根据聚类结果为ESR2类,如表4中编号3漏电流ESR所示。损耗值处于[0,10)会被聚类成ESR1类,处于[90,100]聚类成ESR4类,如:表3中编号1这一行中损耗值为1.14,根据聚类结果为D1类,如表4中编号1损耗D所示;表3中编号4这一行中损耗值为97.23,根据聚类结果为D4类,如表4中编号4损耗D所示。容量值处于[0,50)会被聚类成CAP1类,如:表3中编号1这一行中容量值为19.12,根据聚类结果为CAP1类,如表4中编号1容量所示。表3与表4完整地展现了数据集前五条数据分类前后的对比。

表3 聚类前的数据集前5行

表4 聚类后的数据集前5行
3 关联规则的Apriori算法
3.1 传统Apriori算法
关联规则(Association Rule)算法是关联数据分析挖掘算法领域的重要技术分支[17]。关联规则如何发现大量关联数据中项集之间有趣的且互相关联的关系,如何从为数众多的关联变量中快捷地准确选出其中关联性最强的两组或者更多的一组关联变量,这是研究关联规则挖掘算法的一个核心技术问题[18]。关联规则Apriori算法由R.Agrawal等人于1933年正式提出,它其实是一种先验概率处理算法,在数学分类意义上说它属于一种单维、单层、布尔关联代数规则。它是指利用频繁项集挖掘数据先验知识,采取数据层次顺序搜索的一种循环挖掘方法,可用来快速完成频繁项集的数据挖掘处理工作。总的来说,Apriori算法可分为两大步骤,首先从数据库中发现频繁项集,再从频繁项集中挖掘具有强关联规则的项集。
Apriori算法的频繁项集的发现受两个变量的限制,分别是最小支持度(minsup)和最小置信度(minconfi)。只有满足这两个条件的项集才能被筛选为频繁项集[19]。频繁项集还具有随着项越多,支持度越低的特点。也就是说,若K-项集的支持度小于最小支持度,那么(K+1,K+2,…)-项集的支持度也不可能高于最小支持度。因此,当Apriori算法发现K-项集为非频繁项集时,就不会再往下扫描K+1-项集,极大节省了算法计算时间。
Apriori算法的基本思想是:找出数据库D中所有同时满足最小支持度和最小置信度的项集,即为频繁项集。频繁项集中的所有强关联规则均满足最小支持度和最小置信度这个阈值。其主要思想是:对于项集A与项集B产生的关联规则A=>B均大于最小支持度和最小置信度,其中项集A和项集B均满足A≠φ,B≠φ,A∩B=φ。关联规则A=>B的强度由支持度和置信度决定,可由公式(1)和公式(2)表示:
support(A=>B)=P(A∪B)=
(1)
(2)
3.2 改进的Apriori算法
在使用Apriori获取频繁项集之后构造关联规则时,进一步加入提升度[20]的概念判断频繁项集之间的关系。项集A和B出现的概率分别用为P(A)和P(B)表示,所加入的提升度的公式为:
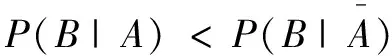
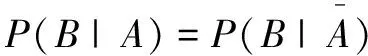

将提升度的概念引入到关联规则的判断中,确保关联规则的有效性及意义。
具体算法流程如下:
输入:事务数据库D;最小支持度阈值minsup;最小置信度阈值minconfi;提升度阈值minup。
输出:频繁K项集。
步骤:
(1)K=1找出所有频繁1项集;
(2)K++,挖掘频繁K项集;
(3)判断频繁K项集产生的规则是否不小于最小置信度阈值、最小支持度阈值以及提升度阈值。
4 实验与结果分析
4.1 关联规则挖掘结果分析
实验主要使用python语言构建测试算法分析模型,测试中通过使用改进的Apriori算法对测量值进行挖掘,将得到的结果进行详细分析,利用得到的有价值的结论为生产管理者进行生产改革或制定相应的决策提供帮助。其中最小支持度阈值与最小置信阈值的设定对最终的结果会产生较大影响。如果最小支持度过大,大量的潜在规则可能会被删除;相反,如果最小支持度过小,则会产生大量冗余的规则,不便于研究和决策度。
图1为提升度UP>0,置信度confidence=0.02,在不同支持度下,改进的Apriori算法挖掘关联规则数量与传统Apriori算法挖掘关联规则数量的对比。
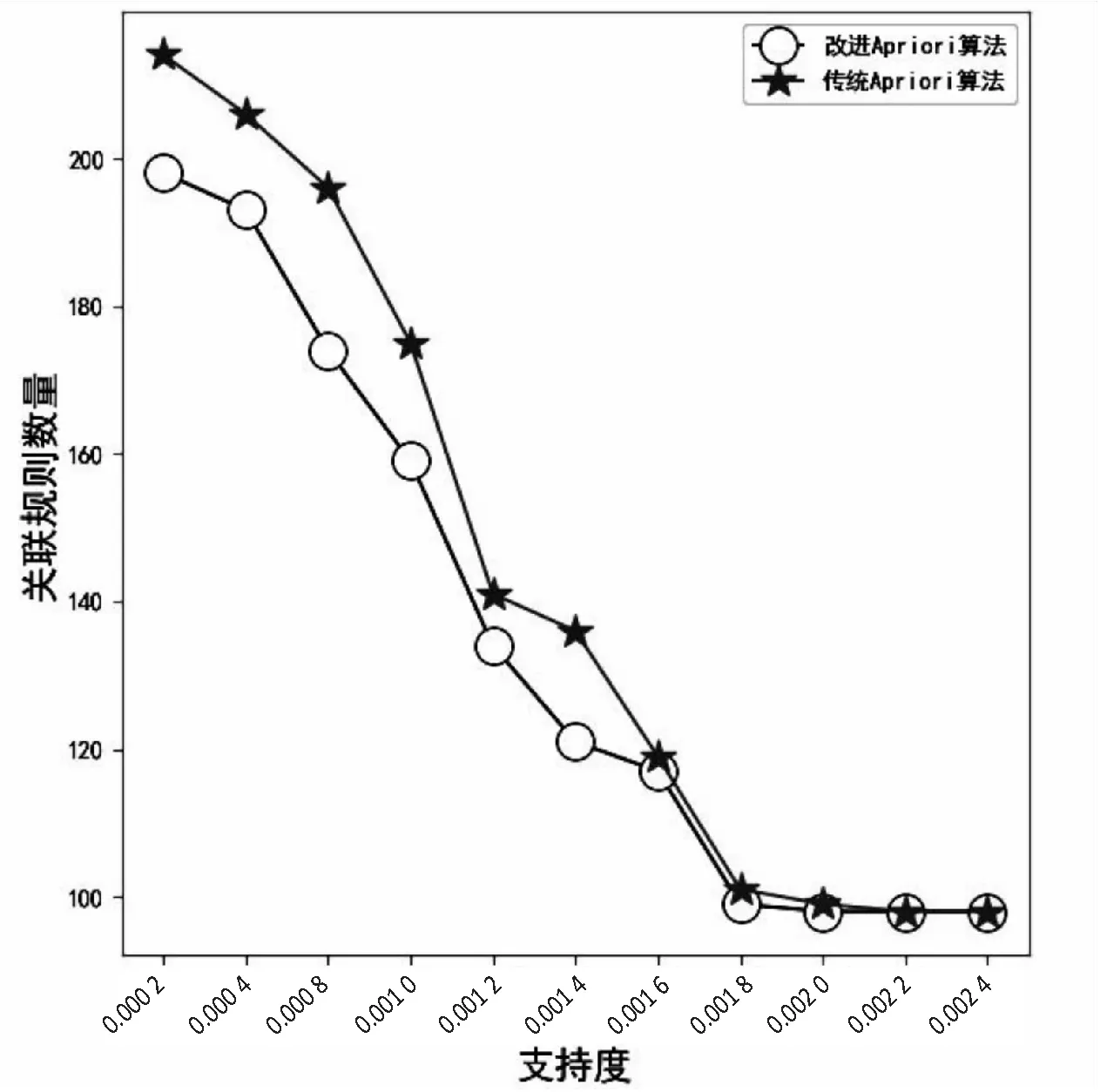
图1 关联规则数目对比
图中可以看出改进的Apriori算法能减少很多冗余的关联规则,优于传统Apriori算法,改进效果相当明显。
经过多次测试对比,最终设定最小支持度minsup=0.005 2,最小置信度minconfidence=0.02,提升度UP≥0。上述数据挖掘模块共产生117条关联规则,这些关联规则均同时满足support≥0.005 2且confidence≥0.02,所以都是强关联规则。由于挖掘产生的关联规则较多,从得到的关联规则中选取一部分进行规则的描述和解读(见表5~表7)。
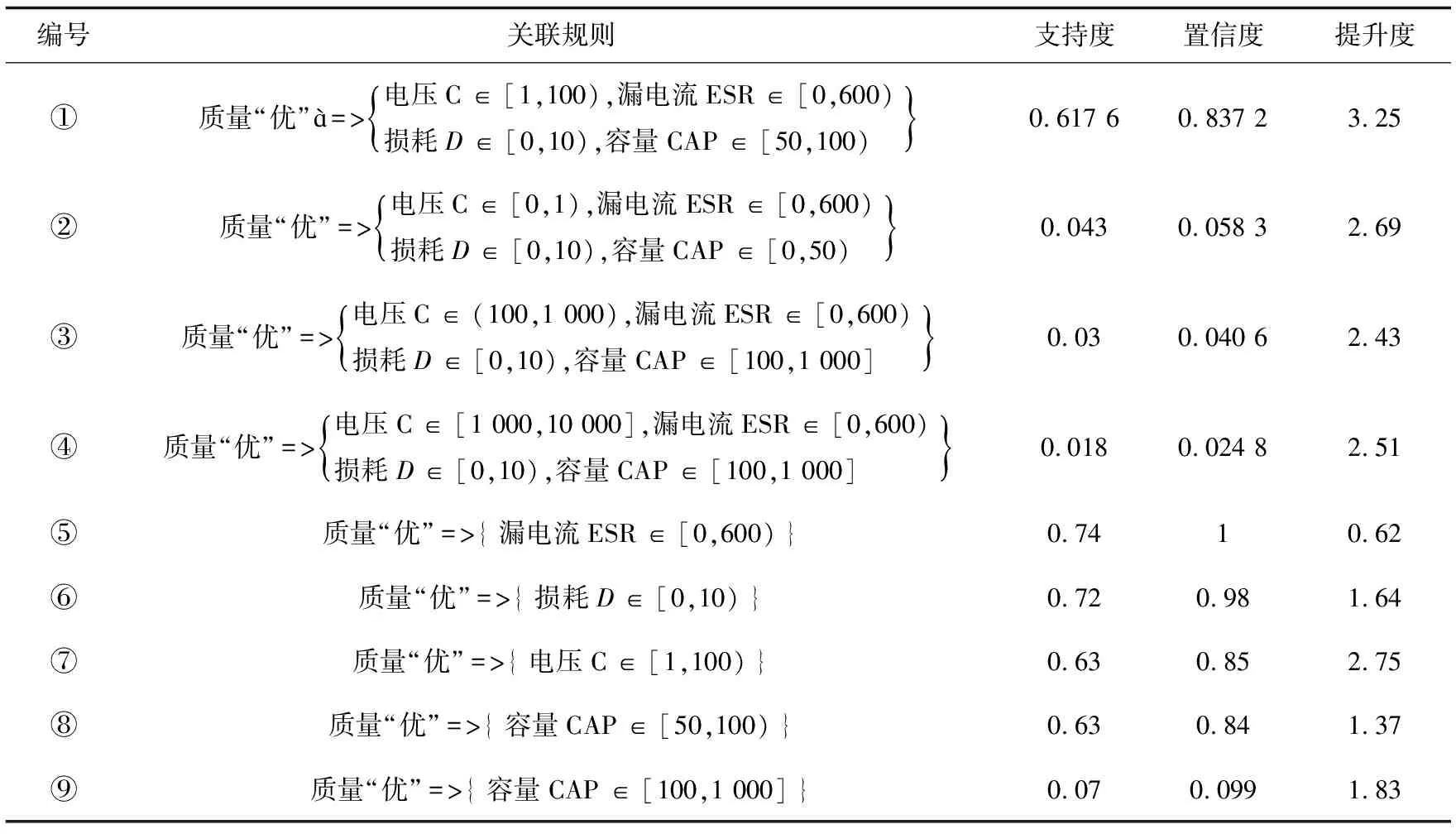
表5 产品质量“优”部分关联规则

表6 产品质量“合格”部分关联规则
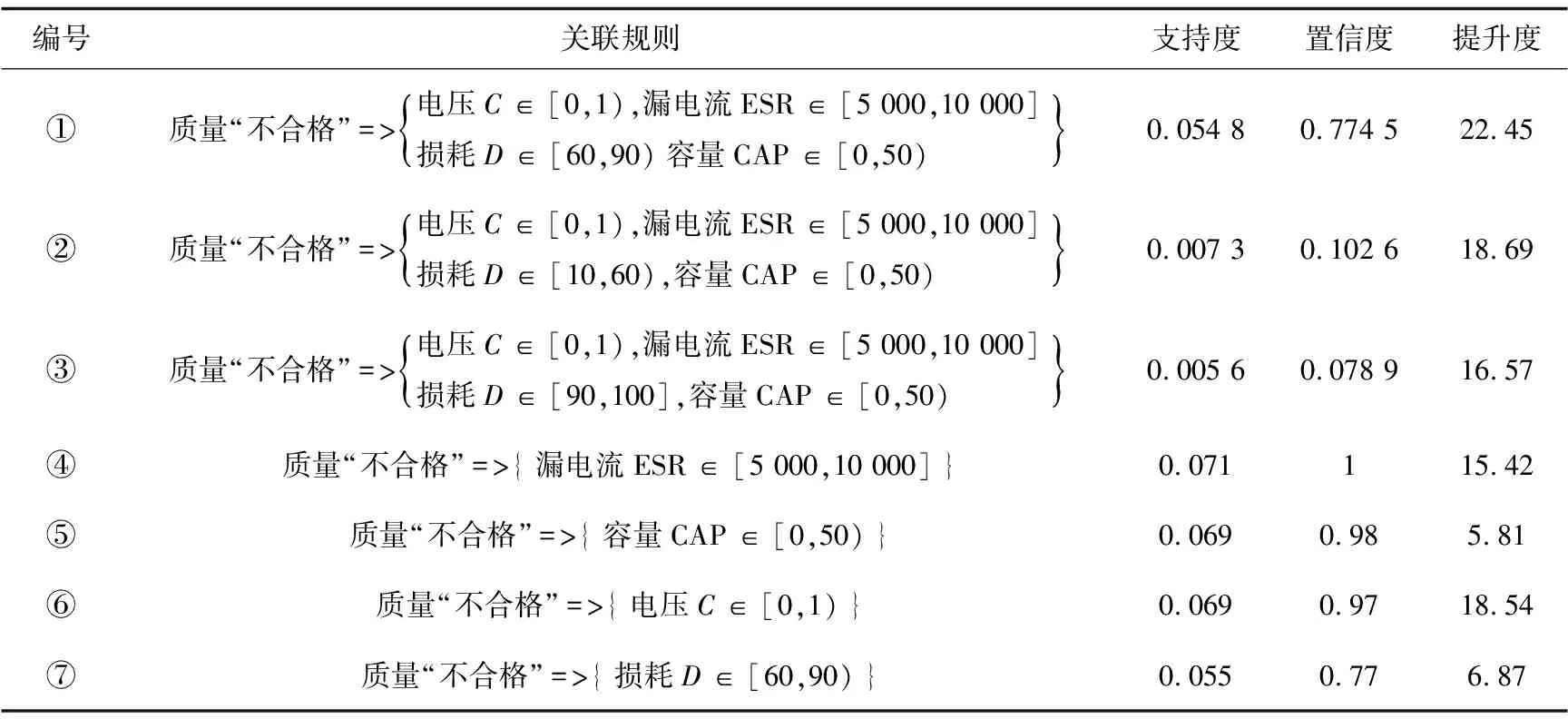
表7 产品质量“不合格”部分关联规则
从表5编号5,6,7,8中可以看出,当产品“优”时,“漏电流”测量值的置信度达到了100%,也就是说,若是产品“优”,漏电流测量值一定会在[0,600)之间。“损耗”测量值的置信度达到98%,“电压”测量值的置信度达到85%,“容量”测量值的置信度达到84%,由此得出结论:当产品“优”时,测量值漏电流ESR在[0,600),电压C在[1,100),损耗D在[0,10),容量CAP在[50,100)的可能性最大。另外,从编号1可以看出,该条强关联规则支持度虽然仅仅为61.8%,但是置信度达到了83.7%,同样验证了上述结论。
从表6中可以发现,当质量为“合格”时,测量参数出现“电压”C∈[0,1), “漏电流”ESR∈[5 000,10 000], “损耗”D∈[60,90),“容量”CAP∈[0,50)的情况最有可能。从表7可以看出,当产品质量为“不合格”时,编号1关联规则支持度为0.054 8,表示数据中有5.5%的记录是产品质量为“不合格”,置信度0.774 5表示该情况下77.5%的可能质量会为“不合格”。
结合表5~表7可以得出以下结论:
(1)产品质量“优”,测量值最有可能所属区间分别是:

(2)产品质量“合格”,测量值最有可能所属区间分别是:

(3)产品质量“不合格”,测量值最有可能所属区间分别是:
根据这些结论,企业可以做出相应的调整,例如企业追踪每个批次产品在整个生产线的情况时,应以结论(1)、(2)、(3)为标准,找出测量值发生动态变化的原因,再以结论(1)作为阈值,监控工业铀在生产中的测量参数,当测量参数波动超过阈值,实施人工干预,有助于提高产品优率。
4.2 挖掘分析结果与实际产品结果对比
根据4.1中得出的3条结论,进一步从实际生产中另外获取了1 000条测量数据,将得出的分析结果与实际产品测量值进行对比分析,测试挖掘分析结果的准确性。
图2是实际产品质量数量与挖掘分析结果预测数量对比柱状图,分别是实际“优”与挖掘分析“优”的对比,实际“合格”与挖掘分析“合格”的对比,实际“不合格”与挖掘分析“不合格”的对比。
根据对比结果,在1 000条测量数据中,实际产品“优”数为765,根据“结论1”得出的产品“优”数为701,准确率达到91.63%,剩下的64条测试为“合格”;实际产品“合格”数为134,根据“结论2”得出的产品“合格”数为112,准确率为83.58%,剩下的22条有17条测试为“优”,4条检测为“不合格”;实际产品“不合格”数为101,根据“结论3”得出的产品“不合格”数为89,准确率达到88.12%,剩下的12条中有11条测试为“合格”,1条为“优”。
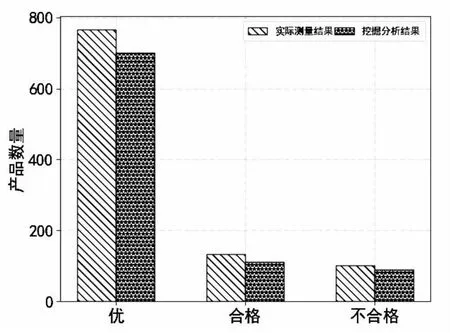
图2 实际测量结果与挖掘分析结果对比
经过上述对比分析,发现三条结论准确率均超过了83%,可为企业提供强有力的数据支持。
5 结束语
对产品参数的研究管理对生产十分重要,生产效率及质量决定企业的收益。分析工业数据,提取有价值的信息对企业生产调节,做出调控起到十分重要的意义。数据挖掘技术涉及的功能很多,常用的功能有关联分析、分类分析、预测分析、聚类分析等等。该文根据数据特点首先采用了聚类分析得到不同区间的类别来代替离散化数据,再利用改进的关联规则技术挖掘出企业产品质量与测量参数之间的相互联系,取得了不错的实验效果。
