基于Hadoop 的分布式视频转码方案
2015-12-02黄洁琛
黄洁琛,倪 明
(中国电子科技集团公司第三十二研究所,上海 200233)
1 概述
随着网络技术的发展以及家庭网络带宽的提升,网络视频点播已经成为当下人们生活娱乐不可或缺的一部分。由于Flash 视频(Flash Video,FLV)格式具有形成的文件极小、可以轻松地导入Flash、加载速度极快、能起到保护版权的作用,并且可以不通过本地的微软或者REAL 播放器播放的特点,被众多新一代视频分享网站所采用,是目前增长最快、最为广泛的视频传播格式[1]。而用户上传或者视频网站购买的视频源大都不是FLV 格式,这就需要对视频源进行转码。若采用单一服务器进行转码,对服务器压力很大,且耗时较长。Hadoop 是一个开源的分布式处理框架,可以在很多廉价计算机上搭建集群,对数据进行分布式的存储和计算。MapReduce 是Hadoop 的一个核心模块,它很适合处理海量的数据,可以根据输入数据的分布情况自动创建多个并行子任务,并将子任务调度到合适的节点上运行[2]。本文使用Hadoop 框架中的分布式文件系统(Hadoop Distributed File System,HDFS)存储分割后的视频分片,根据MapReduce 分布式计算思想,利用FFmpeg 对视频进行分布式转码,旨在不大幅提高硬件成本的基础上缩短视频转码时间。
2 研究现状
视频转码是一个将已经压缩编码的视频码流转换成另一个视频码流的过程,本质上是一个先解码再编码的过程,因为需要大量空域频域的转换,所以对计算能力的要求较高[3]。而且,随着高清电影的发展,影片片源容量从几兆到几十兆不等,造成了转码时间的急剧增加,这对视频的存储和转码服务提出了很高的要求。
目前主流的转码方式有以下3 种[4-5]:
(1)单机转码:使用单台高性能服务器完成视频的转码工作。将视频传输至转码服务器,服务器对视频进行转码,然后将转码后的视频返回[3]。这种转码方式操作简单,但是单台服务器的性能瓶颈会导致转码时间较长,不适合大量视频的转码工作。
(2)基于云计算转码:使用云的存储和计算能力进行视频转码。一般是有视频转码需要的公司租赁提供云服务公司的实例,利用其强大的计算和存储能力进行视频转码。一般一个视频由一个实例进行转码,本质上也是单节点进行视频转码。
(3)分布式转码:其基本思想是先将一个大的视频分割成分段,然后将这些分段分布到多台转码机器上同时进行转码,再将转码后的分段合并,生成目标视频,然后将合并后的视频返回。这种方法优点是可以降低视频转码的时间成本,并且可以应对大量并发的转码任务,缺点在于实现较为复杂,并且会产生较大的网络开销。
3 Hadoop 和FFmpeg 介绍
3.1 Hadoop
Hadoop 是Apache 组织的一个开源的分布式基础框架,可以将大量廉价的硬件设备组织成分布式集群,并在集群上存储数据和运行程序。其核心部件为分布式文件系统(HDFS)和编程模型(MapReduce)两部分。
HDFS[6]是一个高容错的分布式文件系统,参照GFS(Google File System)实现,适合部署在廉价硬件上,而且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。HDFS 由一个NameNode 节点和多个 DataNode 节点组成。NameNode 用于管理文件系统元数据和处理客户端对文件的访问,而DataNode 节点用于实际存储数据。在HDFS 内部,一个文件被分割成一个或者多个数据块,存储在一组DataNode 上。
MapReduce[7]是Google 提出的一个并行编程架构,适用于对大数据集的并行处理。它将一个大的任务分成多个MapReduce 作业,每个MapReduce 作业又可以分为Map 和Reduce 两个阶段。Map 阶段对数据进行并行处理,Reduce 阶段对Map 阶段的结果进行合并,得到最终结果。通常,需要一个Jobtracker 节点对计算任务进行分配和调度,由多个Tasktracker 执行具体的任务。
3.2 FFmpeg
FFmpeg 是一个开源免费跨平台的视频和音频流方案,属于自由软件,采用LGPL 或GPL 许可证。它提供了录制、转换以及流化音视频的完整解决方案,包含了非常先进的音频/视频编解码库libavcodec,支持MPEG,MPEG4,FLV,Div 等40 多种编码,能快速地进行音视频格式转换、分割、合并等多种操作。FFmpeg 在Linux 平台下开发,但它同样也可以在其他操作系统环境中编译运行[8]。
4 系统架构
整个系统由1 个Manager 和1 个Hadoop 集群组成,系统的拓扑结构如图1 所示。

图1 系统拓扑结构
Manager 主要负责保存用户上传的原始视频,对原始视频进行分割[9],将分割后的视频分段上传到HDFS,对之后整个转码过程进行监控和管理,并且负责转完成后的清理工作。保存原始视频是为了确保在视频转码完毕之前,原始视频不会丢失,一旦转码过程失败,可以重启整个转码过程,增强系统的鲁棒性。对原始视频分割完毕后,Manager 将分割后的视频分段提交到HDFS 中,然后启动视频转码和合并任务。在视频合并结束后,Manager 负责清理转码过程中产生的中间文件,包括转码前和转码后的分段视频等,然后将用户上传的原始视频删除,并且将转码后的视频信息返回给客户端。
Hadoop 集群主要负责对Manager 分割后的分段视频进行转码[2,8],然后对转码后的视频进行合并。当Manager 将分割好的视频分段上传到HDFS后,Manager 会启动MapReduce 转码和合并程序。程序在Map 阶段完成各段视频的转码,在Reduce阶段,由一个Reducer 完成转码后分段视频的合并工作。然后将最终的视频信息(包括视频名、视频位置、视频大小等)返回给Manager。
系统的数据处理流程如图2 所示,其中分段指分割后的视频分段,新分段指转码后的视频分段。

图2 系统数据处理流程
系统按如下流程处理一个用户的转码请求:
(1)用户提交转码请求,Manager 检查用户权限和提交的视频信息,若用户有权限为此视频转码,则回复允许请求,否则回复拒绝请求。
(2)若用户收到拒绝信息,则转码过程结束。若收到允许请求,则用户为视频添加基本信息,开始上传视频。
(3)上传结束后,Manager 回复用户上传完毕确认信息,此时用户可以自己设置转码参数,不设置则Manager 使用默认参数。
(4)系统开始进行转码,转码结束后,NameNode向Manager 返回转码完成后的视频的信息(包括视频名称、视频位置、视频大小等)。
(5)Manager 将转码完成后的视频信息返回给用户,用户可以根据返回的信息读取视频。
5 视频分布式转码的实现
整个转码过程可分为3 个阶段:视频分割,分段视频转码和视频合并。在视频转码的3 个阶段中,所有视频处理类都是基于FFmpeg 软件实现。由于FFmpeg 只提供C/C++的API,Java 只能对FFmpeg的可执行文件进行功能的封装,而FFmepg 的可执行文件只支持本地的文件系统,并不支持HDFS[10],所以,所有的视频处理操作都是在本地文件系统中进行的。
5.1 视频分割
视频是一些数据的集合,在这个集合中,有许多频域和时域的冗余信息。为了减小视频的体积,需要使用视频压缩编码技术来减少冗余数据。视频通常以帧为单位,而视频压缩编码会导致帧与帧之间通常不是独立的,存在依赖关系。以MPEG[11]编码标准为例,其定义了3 类帧,分别为I 帧、P 帧和B 帧。I 帧可以独立进行编码,不需要依赖其他帧;P帧为前向预测帧,需要参考前面的I 帧或者P 帧进行编码;B 帧为双向预测帧,需要参考前后的I 帧或者P 帧进行编码。通常GOP(Group of Pictures)是视频最小的显示单位,它是由3 种帧按一定顺序组合而成。每一个GOP 必须以I 帧开始,然后按照依赖关系插入P 帧和B 帧。图3 所示为2 个GOP 的编码过程。
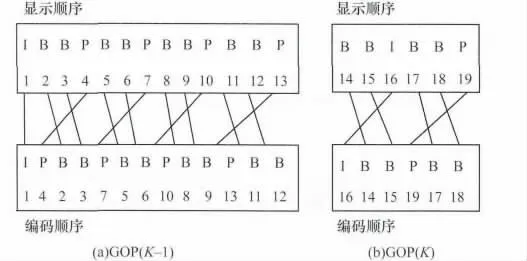
图3 帧编码顺序
由图中可以看到,要分割视频,必须找到关键帧I,从I 之前开始切割,否则会导致GOP 不可用,使分割后的视频缺少信息,以至于转码后GOP 丢失,出现视频卡顿的现象[12]。所以切割视频的关键在于找到关键帧I,而使用FFmpeg 可以很容易找到关键帧的位置。
由于要验证分段大小对转码时间的影响,因此需要按固定的块大小来切割视频。FFmpeg 只能根据时间跨度来切割视频[10],需要根据视频码率和块大小计算分段视频的时间跨度,从而估算切割点的大致位置,然后在时间点周围找到关键帧,在关键帧之前切割视频。视频分割的流程如图4所示。

图4 视频分割流程
5.2 分段视频转码和视频合并
当Manager 将分段视频上传到HDFS 后,便启动分段视频的转码工作。首先,使用Hadoop 的balance工具,使视频尽量均匀地分布到各个DataNode 上。这是为了保证:
(1)数据本地化[2]。因为在Map 阶段进行转码时,需要将分段复制到本地文件系统。这样可以使针对于某一分段的转码工作尽量在存储有该分段的节点上进行,无需从远程节点复制,避免了网络传输所造成的时间消耗和对网络的压力。
(2)使转码任务均匀分配到各个节点[2]。因为在资源充足的情况下,JobTracker 会优先在存储该分段的节点上启动针对该分段的转码任务。使分段均匀分布到DataNode 可以将转码任务均匀分布到各个节点,避免单节点压力过大,保证数据的并行性,以减少转码时间。
然后,MapReduce 程序启动,JobTracker 会为各个TaskTracker 分配任务,Map 阶段每个TaskTracker分到一个或几个分段的转码任务。TaskTracker 会将分配到的需要转码的分段复制到本地文件系统,然后对每一个分段使用FFmpeg 工具,根据设定的编码参数进行转码。同时,TaskTracker 可以监控FFmpeg的转码过程,记录转码日志,若转码失败可以重启转码任务。待分配到的全部分段视频转码结束后,TaskTracker 会将其发送到将运行Reduce 程序的节点上进行视频合并。
当Map 阶段运行结束后,Reduce 阶段会启动。此时运行Reduce 程序的节点已经收到转码后的全部分段视频。使用FFmpeg 工具,可以顺序地对视频进行合并操作,合并后将会生成一个本地的视频文件。最后,Reduce 程序会将这个视频文件上传到HDFS,然后将其信息(主要是位置信息)发送给Manager,此时分段视频转码和合并过程完成,其流程如图5 所示。

图5 分段视频转码和视频合并流程
6 实验结果及分析
6.1 实验环境
由于缺少服务器,本文在一台8 核CPU、64 GB内存、6 TB 硬盘、安装CentOS6.2 64 位系统的服务器上建立了9 台虚拟机进行实验,虚拟化软件为KVM(Kernel-based Virtual Machine)虚拟机统一配置为:2 核CPU,4 GB 内存,50 GB 硬盘,系统为CentOS6.2 64 位系统。虚拟机角色如表1 所示。
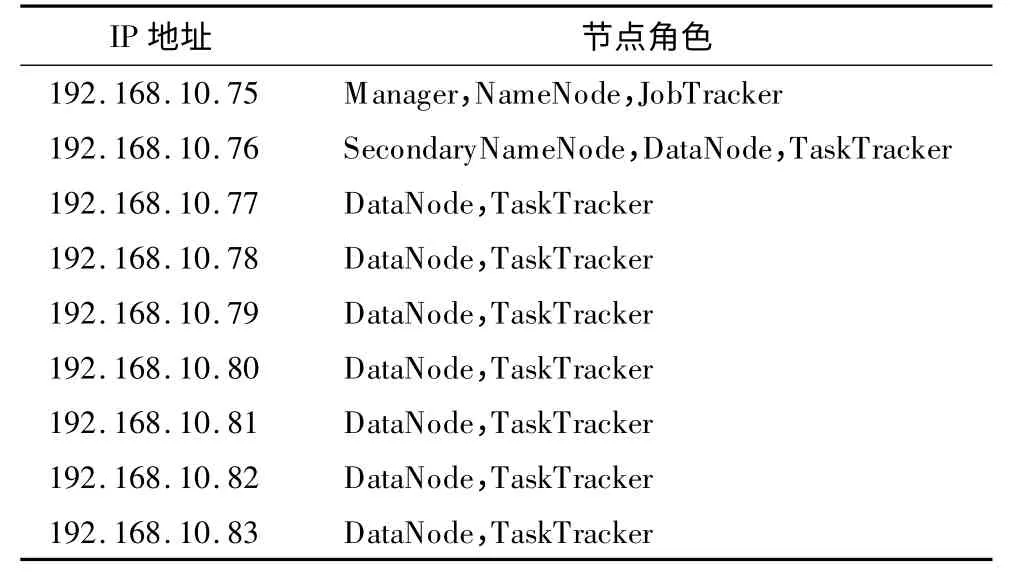
表1 节点角色
实验所用视频大小为1.4 GB,将其分别按不同大小的分配进行分割,所得到的分段视频的数量如表2 所示。

表2 分段大小与分段数量
分别使用单机转码和分布式转码2 种方式对所用的视频进行转码,分布式转码时,设置DataNode(TaskTracker)的数量分别为2,4,6,8,转码前后视频的参数如表3 所示。

表3 转码前后视频参数
6.2 实验结果
在单个节点上使用FFmpeg 工具对视频进行转码时,耗时1 422 s。在使用分布式转码时,耗时如图6所示。图7 为分段大小为64 MB 时,分布式转码消耗的时间随TaskTracker 数目增加的变化趋势。

图6 分布式转码消耗时间
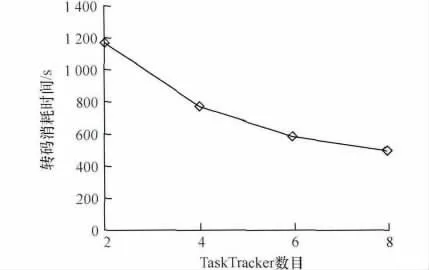
图7 分段大小为64 MB 时转码消耗时间
6.3 实验分析
在单节点上使用FFmpeg 工具对视频进行转码时,耗时1 422 s,从图6 可以看出,只有在2 台TaskTracker,分段大小为16 MB 时,分布式转码耗时多于单节点视频转码耗时。使用大于2 个TaskTracker 进行分布式转码耗时都远少于单节点转码,尤其是使用8 台TaskTracker、分段大小为64 MB时,仅需要495 s,相比于单节点,节约了大约65%的转码时间。所以,本文提出的分布式转码方案可以很大程度上提高视频转码的效率。
同时可以看到,在TaskTracker 数量相同的情况下,随着分段大小的增加,分布式转码消耗时间呈现一个先下降后上升的趋势,当分段大小为64 MB 时转码时间最短。这和2 个原因有关:(1)分段太小,会导致分段数目太多,MapReduce 的启动时间增加[2]。(2)分段太大,对每个分段的转码时间增加,在任务无法完全平均分配的前提下,会导致节点压力不均,并行粒度减小,从而导致性能下降[13]。
从图7 中可以看到,随着TaskTracker 数目的增加,分布式转码消耗时间呈下降趋势,但是下降的幅度越来越小。这可能是因为实验环境是在一台服务器上搭建的虚拟机,它们都是使用物理机的磁盘。当并行度太大,会使磁盘I/O 速度成为性能提升的瓶颈。
7 结束语
本文提出了一种基于Hadoop 的集存储与转码于一体的分布式转码方案。使用HDFS 的多机备份机制可以有效保障视频存储的安全性,而使用MapReduce 编程框架,可以很方便地实现分布式转码工作。实验结果表明,与单节点转码相比,使用本文方案在有8 台TaskTracker 的Hadoop 集群中进行转码可以节省大约65%的转码时间,大大提高转码效率。然而,本文方案还存在如下不足:(1)在对视频进行处理(分割、转码、合并)时,只能在本地文件系统中进行,不能直接在HDFS 中操作,从而需要对视频进行复制和网络传输,增加了存储和时间消耗。(2)只有在所有Map 结束之后,Reduce 才会执行,造成了时间损失。针对上述不足,今后的改进主要是采用Java 完成视频处理,不依赖于FFmpeg 的可执行文件,使其在HDFS 中就可完成处理。并且修改Map 和Reduce 的处理机制,使相邻的视频段完成转码即可进行合并,提高转码效率。
[1]王奎澎,刘建辉.Flv 文件格式及其嵌入式应用[J].计算机系统应用,2010,19(3):190-193.
[2]Lam C.Hadoop 实战[M].韩冀中,译.北京:人民邮电出版社,2011
[3]林杰聪,黄祥林,杨占昕.视频转码技术研究[J].中国传媒大学学报:自然科学版,2006,13(3):43-51.
[4]Zhang Hao,Sun Shuxia.Application of Hadoop in Video Transcoding Based on Cloud Computing[J].Computer &Telecommunication,2011,(12):36-37.
[5]Ji Wen,Chen Min,Park J J,et al.Distributed Video Coding:An Overview of Basics,Research Issues and Solutions[J].International Journal of Ad Hoc and Ubiquitous Computing,2012,9(4):258-271.
[6]许春玲,张广泉.分布式文件系统Hadoop HDFS 与传统文件系统Linux FS 的比较与分析[J].苏州大学学报:工科版,2010,30(4):5-9.
[7]李建江,崔 健,王 聃,等.MapReduce 并行编程模型研究综述[J].电子学报,2011,39(11):2635-2642.
[8]覃 艳.基于FFMPEG 的视频格式转换技术研究[J].电脑知识与技术,2011,7(12):2912-2913.
[9]Wu Yuan.ffmpeg 视频分割的方法[EB/OL].(2012-04-13).http://wuyuans.com/2012/04/ffmpeg-split.
[10]吴张顺,张 珣.基于FFmpeg 的视频编码存储研究与实现[J].杭州电子科技大学学报,2006,26(3):30-34.
[11]雷国平,周 琨,吉吟东.MPEG 标准发展和研究综述[J].计算机工程,2003,29(12):185-187.
[12]邱 多.基于MPEG 压缩域视频关键帧提取技术的研究[D].秦皇岛:燕山大学,2011.
[13]田浪军,陈卫卫,陈卫东,等.云存储系统中动态负载均衡算法研究[J].计算机工程,2013,39(10):19-23.
