一种轻量型人体行为识别学习模型
2022-05-25建中华宁传峰
南 静,建中华,宁传峰,代 伟
中国矿业大学信息与控制工程学院,徐州 221116
随着微电子技术和计算机技术的快速发展,人体行为识别(Human activity recognition, HAR)已经成为普适计算中一个重要研究方向. 其在医疗保健、智能建筑和军事等领域发挥着极其重要的作用.例如:在医疗保健中,医生可以通过HAR系统对病人进行连续的观察,然后给出诊断和治疗方案[1-3],进而提高医疗资源的利用率;在智能建筑中,物业人员可以利用居住者的行为信息来提高环境舒适度和实现能源的高效使用[4-6]. 在军事上,通过对军人体能训练的连续监测,可以防止由于过度疲劳而导致意外损伤[7].
事实上,人体行为识别研究的源头可以追溯到20世纪90年代末[8],发展至今日,其主要分为基于视频和基于可穿戴传感器这两大方向. 基于视频识别人体行为具有破坏性、成本昂贵和容易受环境影响(如:物体遮挡)等缺点,并且在某些情况下容易侵犯用户隐私. 而基于可穿戴传感器的识别提供了一种快速、低成本、隐私性好且不易受环境影响的替代方案. 文献[9]首先使用可穿戴传感器收集人体行为数据,其次分别利用随机森林(Random forests, RF)和朴素贝叶斯模型作为行为分类器. 实验结果表明,随机森林在识别性能上优于朴素贝叶斯模型;文献[10]将高斯随机投影方法引入极限学习机(Extreme learning machine, ELM)隐含层参数分配中,以加强模型的多样性,然后使用包含三轴加速度和陀螺仪传感器数据的2个真实数据集进行人体行为识别研究,结果表明该分类器在两个数据集上分别实现了97.35%和98.88%的识别精度. 由此可知,多传感器数据的使用有助于提高人体行为识别模型的识别性能. 但上述可穿戴传感器存在价格昂贵、部署繁琐等难题,不利于HAR的广泛实际应用.
智能手机因具有内置众多传感器、价格低廉和普适性等特点成为它们的替代品,并吸引许多科研工作者开展基于智能手机的人体行为识别研究. 由于智能手机传感器数据含有噪声,因此为识别模型提取一组鲁棒性特征是非常有必要的. 而时频域特征是一种机器学习中广泛使用的鲁棒性特征. 其中,时域特征包括平均值、最大值和最小值等,它们一般被用来区分lying和standing等简单行为;而频域特征是指通过将原始数据转化到频域再提取的特征,它包括向量夹角和最大频率分量等. 由于频域特征注重局部的数据变化,因此被用来区分模态相近的行为. 但是,在时频域特征中往往含有一些不利于建模的特征,故需要进行特征选择. 文献[11]首先使用主成分分析(Principal component analysis, PCA)从时频域特征集选择最优的特征子集,其次提出了隐马尔科夫模型(Continuous hidden markov model, HMM)和支持向量机(Support vector machine, SVM)相结合的识别模型. 实验的结果表明, HMM-SVM模型的识别性能远高于HMM和SVM. 文献[12]使用离线提取器从候选的时频域特征集中选择对传感器方向不敏感特征进行人体行为识别, 并利用K近邻(K-nearest neighbors, KNN)进行仿真实验, 结果表明这种方法能够用更少的特征取得相近或更好的识别性能. 然而上述特征选择技术仅仅关注了特征的冗余性,缺少对特征相关性的考虑. 最近,深度学习也被广泛用于人体行为识别[13-14]. 文献[15]首先提出了利用卷积神经网络和递归神经网络分别提取空间域和时间域的特征的方法,其次使用长短期记忆网络模型基于所提特征进行行为识别建模和分类. 结果表明,该方法实现93.7%的识别精度. 文献[16]首先利用递归框架从传感器数据中提取局部特征,然后使用长短期记忆网络模型识别人体行为. 虽然深度学习模型在特征提取方面有很大的优势,但其也有两个主要缺点:建模时间过长和需要大样本集. 而智能手机资源(CPU, 内存)的有限性使得基于智能手机进行人体行为识别建模的模型必须满足结构紧致、模型轻量和建模速度快等特性,因此,深度学习不适合此类研究.
近年来,Wang和Li[17]提出一种具有建模速度快、实现简单和结构紧致等特点的单隐层前馈神经网络随机学习方法,即随机配置网络(Stochastic configuration networks, SCNs). SCNs作为一种增量式构建网络的学习模型,其首先在一个动态可调区间内根据不等式监督机制随机分配隐含层节点参数;然后,利用全局最小二乘来计算网络输出权值. 这种网络构建方法不仅保证了网络模型的无限逼近性还减少了人为干预和增加了模型结构的紧致性. 因此,可以说SCNs是一种轻量模型. 目前,SCNs已经被应用到赤铁矿磨矿过程[18]、光纤预警[19]等众多领域. 但SCNs在隐含层节点过多时容易出现过拟合现象,极大地降低SCNs的泛化性,进而影响SCNs的实际应用.
综上,针对上述问题,本文从以下两个创新点出发进行人体行为识别的研究:
(1) 针对原始人体行为特征集维数过高且可分性差,不利于建立轻量型人体行为识别模型问题. 本文提出基于近邻成分分析(Neighbourhood component analysis, NCA)的特征选择技术对原始的人体行为识别特征集进行高相关性特征选择,提高特征集的可分性和降低特征集的维数,进而提高行为识别模型建模计算过程的轻量性;
(2) 针对随机配置网络隐含层节点过多时会导致模型过拟合问题. 使用L2正则化优化模型结构,进而增强SCNs模型的泛化性和轻量性.
本文中所提的HAR学习模型主要包括数据采集及特征处理、NCA特征选择和建立模型等三个步骤. 其中,数据采集及特征处理是指利用传感器采集人体行为信息,然后进行归一化和特征提取;NCA特征选择是指利用NCA从上一步骤中获得的特征集中选择高相关性最优特征子集;建立模型是指采用本文所提L2-SCNs建立HAR模型.
1 NCA-L2-SCNs人体行为识别模型
1.1 基于NCA的行为特性选择
特征选择结果的优劣直接关系到所建人体行为识别模型的轻量性和质量好坏[20],过多冗余和不相关特征不仅对模型泛化性的提升不利,还容易增加建模难度和计算负荷. 因此,本文从行为特征之间相关性的角度出发,使用NCA从人体行为特征集中选择高相关性最优特征子集,进而提高行为识别模型计算过程的轻量性. NCA是一种简单高效的距离度量算法[21-22]. 它通过最大化留一法的分类精度来选择对于人体行为识别模型最优的特征子集.


1.2 基于L2-SCNs的行为识别模型
SCNs作为一种先进的网络模型,其在模型结构紧致性、建模速度等方面的高性能已经被证实[23-24]. SCNs结构如图1所示. 本小节针对SCNs泛化性和轻量性不足问题,基于L2正则化理论[25],提出了L2-SCNs模型,并将其应用于人体行为识别研究之中.
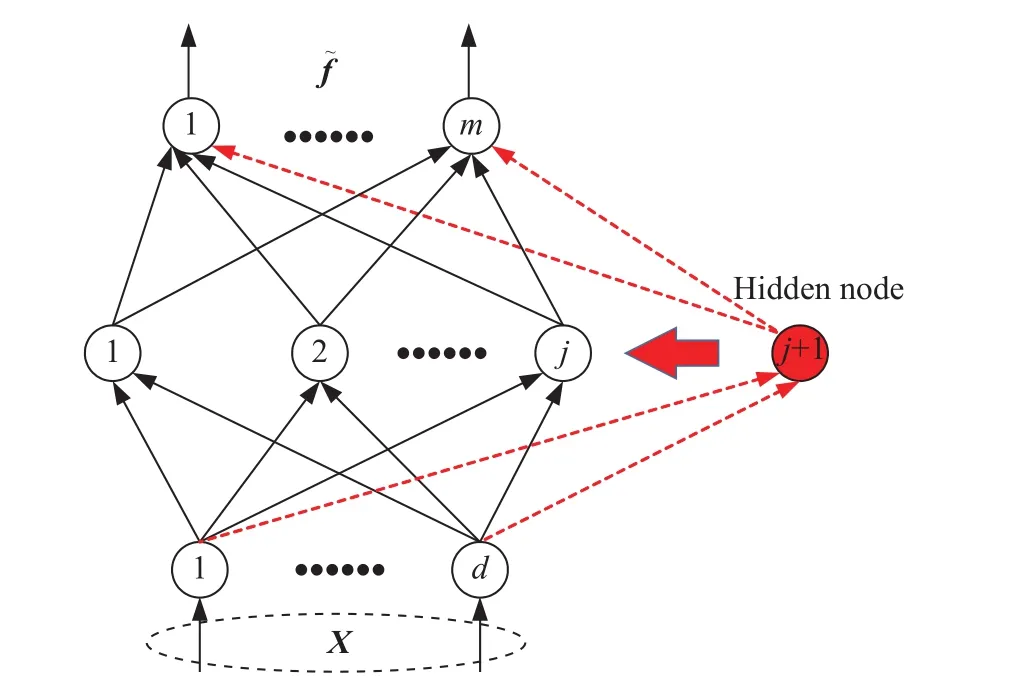
图1 SCNs网络结构图Fig.1 SCNs network structure


1.3 算法步骤


1.4 算法建模过程分析
为了进一步体现本文所提算法在轻量型方面的优势,本文分别从建模计算复杂度和所需节点数(隐含层参数量)两个方面进行分析.
1.4.1 建模计算复杂度
本文针对三种随机算法的计算复杂度进行了深入地分析,具体结果如表1所示,其中,561表示原始数据集的特征数,111表示经过NCA处理后数据集的特征数. 同时,. 通过观察该表可以看出,引入NCA和L2正则化有助于提高模型的轻量性.

表1 不同算法的计算复杂度对比Table 1 Comparison of the computational complexity of different algorithms
1.4.2 建模所需节点数
为了能够进一步清楚地展示出所提模型在轻量性方面的优势,本文从建模过程所需节点数方面进行说明. 这里分别比较了SCNs和L2-SCNs在保证相同停止均方根误差(Root mean square error,RMSE)时两种模型的节点数,具体结果如图2所示. 该结果表明,L2正则化的引入使得模型的建模节点数从原来的25减少到20,故有助于提高模型在参数量上的轻量性.
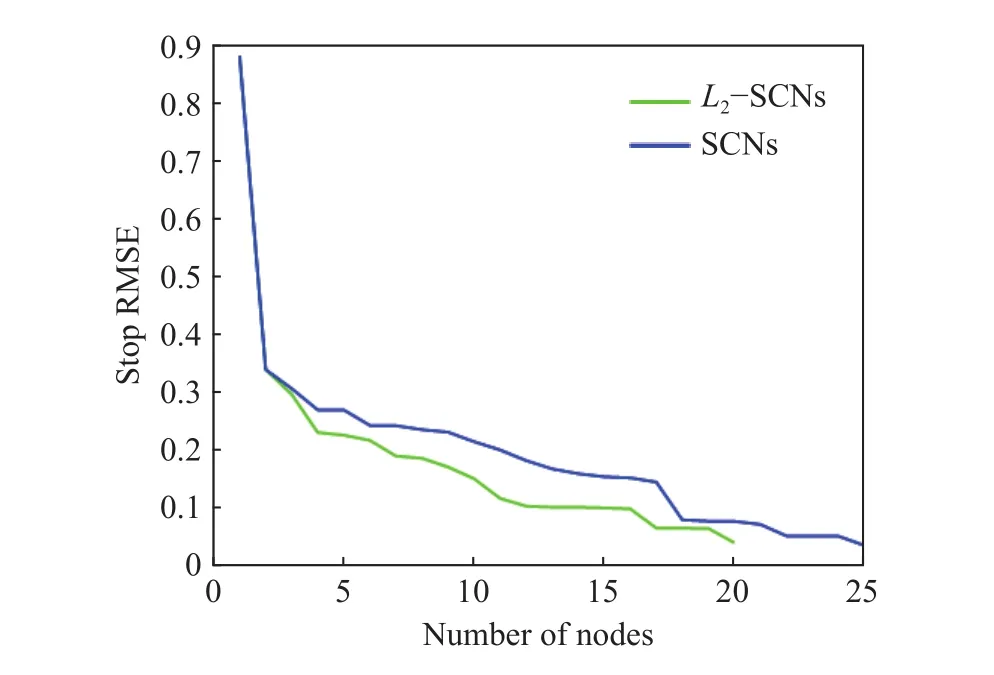
图2 使用L2正则化前后SCNs的RMSE对比图Fig.2 RMSE comparison of SCNs before and after L2 regularization
2 实验结果与分析
为了验证所提行为识别学习模型的有效性,本文首先使用NCA技术在UCI HAR特征集上进行特征子集选择,并针对特征子集的最优与否问题进行了分析研究;其次利用L2-SCNs在特征子集上建立NCA-L2-SCNs人体行为识别模型;最后,将所提NCA-L2-SCNs与SCNs、SVM和LSTM等先进模型进行了实验对比,并对实验结果进行深入讨论.
2.1 实验设置
本文所使用的特征集为UCI HAR特征集,该特征集是由30名年龄在19~48岁之间的志愿者组成,每人腰间佩戴智能手机(三星Galaxy S II)进行 standing、 sitting、 upstairs、 lying、 walking以 及downstairs 6项行为. 它包括特征(时域和频域特征)数为561的10299条人体行为样本,其中训练集为7209条,测试集为3090条[26]. 同时,本文所有实验仿真均是利用MATLAB 2019b,在CPU为E3-1225 v6,3.30 GHz,内存为32 G RAM的PC机上进行的. 对于SVM, 本文采用径向基函数(RBF)为核函数. LSTM使用一个含有200个隐含层节点的LSTM层,一个大小为6的全连接层,最后使用softmax层进行预测. 而对于SCNs和L2-SCNs,激活函数和分别为sigmoid和500,其余参数为:中参数,使用网格搜索方法在得到. 本文中呈现的所有模型的实验结果皆是执行了30次后的统计结果.
2.2 实验结果对比与分析
本文利用NCA特征选择技术从UCI HAR特征集(包含561个特征)选择高相关性特征子集用于实验仿真研究,图3展示了UCI HAR特征集中561个特征的权重系数. 为了获得利用NCA技术选择最优特征子集,本文给出了在原始特征集和使用NCA选择后的特征子集上利用L2-SCNs模型实验仿真的结果,如表2所示. 通过观察表2可知,L2-SCNs在原始特征集上用29.85 s实现了94.27%的平均识别精度;在利用NCA技术选择含有111个特征的特征子集上用18.03 s实现了97.48%的平均识别精度;在利用NCA技术选择含有94个特征的特征子集上用19.88 s实现了97.19%的平均识别精度. 通过上述实验结果可知,若不使用NCA选择最优特征子集,那么模型的实验结果不仅耗时而且很差. 此外,对NCA(111)和NCA(94)两个特征子集结果的分析可知,特征子集的维数和实验结果没有固定的比例关系,只有在包含最详细人体行为信息且维度适当的特征集才能使模型达到轻量型的要求. 因此,本文选择NCA(111)作为所提学习模型的最优特征子集.
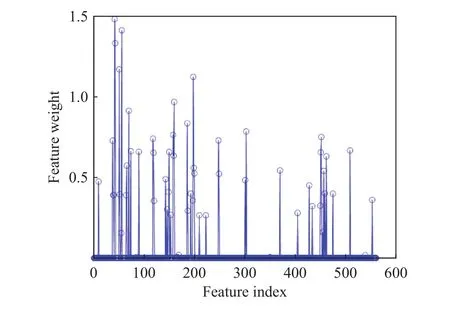
图3 特征权重分析图Fig.3 Analysis chart of feature weight

表2 使用NCA特征选择前后L2-SCNs模型结果对比Table 2 Comparison of L2-SCNs model results before and after using the NCA feature selection
本文将所提的NCA-L2-SCNs学习模型与SVM、LSTM、SCNs和L2-SCNs这几种模型进行了实验对比. 结果如表3所示,值得注意:由于SVM模型不涉及参数的随机分配,因此,它在多次运行后具有相同的精度. 本文使用MATLAB中libsvm工具箱进行SVM模型的仿真实验. 而LSTM模型虽然实现比SVM更好的识别精度,但其建模时间却最长达到了529 s,远超于其他模型. 这主要是因为LSTM是一种深度学习模型,其为了实现好的识别精度需要进行模型参数的寻优而LSTM模型参数众多,因此建模时间较长. 事实上,这也说明LSTM并不是一种轻量型模型,而这与资源有限条件下人体行为识别模型必须保持轻量性相背. 因此,LSTM模型并不适合这种基于智能手机开展的人体行为识别研究. 而对于SCNs和L2-SCNs而言,由于L2正则化的存在,L2-SCNs模型有着更好的性能:识别精度上从94.18%提升到97.27%;建模时间上从60.59 s下降到29.85 s. 造成建模时间大幅度下降的主要原因是SCNs中在求解输出权值时使用了Moore-Penrose广义逆方法,而L2-SCNs使用的是普通的求逆方法. 从数学角度看,Moore-Penrose广义逆的计算复杂度远远高于普通求逆方法,故计算过程比较耗时. 此外,本文所提NCA-L2-SCNs模型,在可接受的建模时间内,对于人体行为识别研究能够实现最好的识别精度.
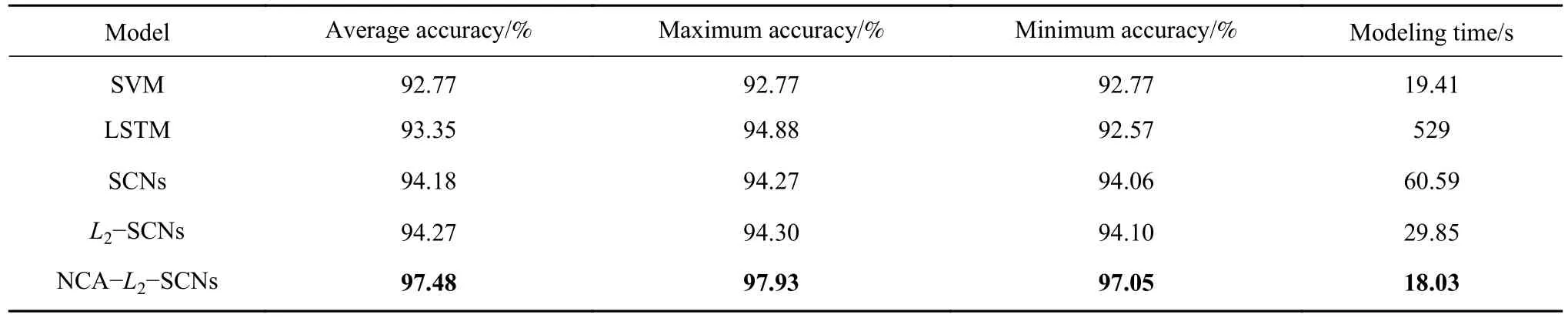
表3 五种方法在UCI特征集上的对比Table 3 Comparison of five methods on the UCI feature set
为了研究NCA特征选择提高L2-模型性能的本质,本文绘制了使用NCA前后L2-模型的收敛曲线图,如图4所示. 通过观察图4可知,随着L2-SCNs隐含层节点数的逐渐增加,NCA-L2-SCNs的RMSE由一开始高于L2-到98个节点后低于L2-SCNs直至最后建模完成. 造成这一结果的主要原因是未经过NCA选择的特征集中含有大量低相关性特征,而这些特征能够在L2-SCNs人体行为识别模型构建初期增强模型的非线性映射能力,进而获得较低的RMSE.
此外,为了分析哪些数据被错误分类,本文在测试集上计算了NCA-L2-SCNs学习模型的预测行为(输出类)和实际行为(目标类)的混淆矩阵. 该模型的混淆矩阵如表4所示. 可以观察到所有模型的错误分类主要发生在sitting和upstairs两种行为模态上. 其中sitting有20条数据被误分为standing,而standing中有1条数据被误分为sitting. 造成这一结果的主要是因为两种行为的模态比较相近,而且在收集这类行为的传感器数据时,陀螺仪传感器的数据几乎全部为0,同时仅仅利用三轴加速度传感器数据去识别各种行为时会出现模型识别能力低下的问题. 而行为模态的相似性使得upstairs的23条数据被错误地分成了walking.

表4 NCA-L2-SCNs模型识别结果混淆矩阵Table 4 Confusion matrix of NCA-L2-SCNs model recognition results
3 结论
(1) 针对人体行为识别研究中资源有限问题,本文提出了一种轻量型NCA-L2-SCNs人体行为识别学习模型.
(2) NCA特征选择方法能够提高人体行为识别特征集的可分性和轻量性,进而达到提高模型的识别精度和降低模型建模过程计算复杂度.
(3) 使用L2正则化技术解决SCNs由于隐含层节点过多导致的过拟合问题,增强SCNs模型结构的紧致性,进而提高模型的泛化性和轻量性.
(4) 在UCI HAR特征集上的实验结果表明,在可接受的时间内,本文所提NCA-L2-SCNs学习模型相比于其他模型具有更好的识别精度,且计算复杂度更低. 因此,模型更加轻量.
