基于深度学习的车标检测算法研究
2022-05-25薄纯娟
薛 超,薄纯娟,王 欣
(1.大连民族大学 a.机电工程学院;b.信息与通信工程学院,辽宁 大连 116005;2.大连铁路中学,辽宁 大连 116021)
目标检测是计算机视觉领域的分支,主要工作是从图像中找到特定的目标并进行准确地标注,根据选定数据集的不同,检测算法可以检测的目标也不同。一方面,车标作为日常生活中常见的目标,具有小尺度、形状不定、受环境影响严重、种类繁多等特点,如何针对目标检测算法进行改进以适应这些特点,是目标检测研究的一项热门课题,因此车标对于目标检测具有一定的学术研究价值;另一方面,车标检测对道路交通管理具有一定的帮助,通过结合车牌、车型、车标等重要特征,可以快速定位相应车辆,此外汽车厂商通过对交通录像进行车标检测,可以辅助计算汽车品牌曝光度,因此车标检测具有一定的现实应用意义。
1 传统车标检测方法
传统的车标检测算法多基于图像处理,主要步骤包括:图像预处理、窗口滑动、特征提取、特征选择、特征分类和后处理等。首先进行图像预处理,包括归一化、高斯滤波、灰度化处理、边缘检测和二值化等操作;其次需要选定特征,根据待识别车标的特征进行手动参数调整,目前常用的特征有Haar、LBP和HOG等;最后进行分类器的训练。这类算法由于检测效率较低,仅适用于静态和简单场景下的车标检测,同时可检测的类别也较少。卷积神经网络[1]引入目标检测领域后,深度学习目标检测算法相比传统算法检测速度和精度均有所提升。根据算法过程的不同,目前深度学习目标检测算法可以分为一阶段算法(one-stage)和二阶段算法(two-stage)。一阶段算法直接进行候选框的分类与回归,检测速度较快但精度较低,如YOLO[2]、SSD[3]等;二阶段算法首先会将候选框和背景相互分离,然后将对候选框进行分类与回归,由于算法分两个步骤进行,因此二阶段算法检测速度较慢但是精度更高,如Fast R-CNN[4]和Faster R-CNN[5]等。二阶段算法在第二阶段可以选择性挑选样本,因此正负样本较为均衡,一阶段算法则存在正负样本不平衡的问题,Tsung-Yi等[6]提出Facal Loss方法,使得一阶段算法能够超越二阶段算法。
1.1 YOLOv3算法分析
目前车标检测算法主要是基于主流目标检测算法进行改进,而一阶段算法由于其快速检测的特性,更加适合进行车标检测,因此车标检测算法主要是基于一阶段算法进行改进。YOLOv3[7]算法由于其高检测速度,在车标检测领域被广泛应用,如王林等[8]基于YOLOv3进行改进,将Darknet-53改换为层数更少的Darknet-19,同时减少预测层;阮祥伟等[9]基于YOLOv3提出NVLD算法,减少网络层数的同时添加残差学习模块[10],最终在不增加参数的条件下提升网络提取效果;LIU R K等[11]提出SSFPD算法,针对车标小尺度检测效果较差的问题,首次提出约束区域检测和复制粘贴策略;冯佳明等[12]基于YOLOv3提出改进算法YOLOv3-fass,一方面降低网络通道数,另一方面添加尺度跳连结构,减少网络参数的同时提升特征融合效果。
1.2 YOLOv4算法分析
YOLOv4是Bochkovsky等[13]在2020年提出的一种对YOLOv3进行改进的算法,从输入端到输出端都应用了大量技巧性算法,这些算法可分为两类:一类是仅增加训练成本的算法(Bag of freebies),例如数据增强、标签平滑等;另一类是增加少量计算成本的算法(Bag of specials),例如增强接收域、空间注意力模块等,性能上不论是训练阶段还是检测阶段,YOLOv4相比YOLOv3都有一定提升。
YOLOv4预测部分共有三个不同尺度的输入层,有助于提升多尺度目标检测效果,然而车标检测面对的目标大部分为中小尺度目标,对于多尺度敏感性较低;此外,车标数据集图片分辨率通常较低,对于层数较多的网络结构,车标特征相对难以学习,同时过于复杂的网络结构会增加大量计算成本,降低检测速度。针对上述问题,本文针对YOLOv4算法进行改进,使其更好地应用于车标检测。
2 算法设计
2.1 网络结构设计
现实场景中车标通常为小尺度目标,同时考虑车标数据集分辨率不高的情况,本文选取层数较少的Tiny-Darknet作为改进算法的特征提取网络。Tiny-Darknet的优势是网络层数少、检测速度快,相比CSP-Darknet53的104层网络结构,它只有22层,拥有更少的模型参数,更快的检测速度。本文对两种网络结构进行了对比实验,结果见表1。

表1 网络结构对比实验结果
补充FPS与mAP@0.75的含义。从表1可以得知,Tiny-Darknet相比CSP-Darknet53检测速度增加两倍,精度仅下降4.81%,因此本文选择Tiny-Darknet作为本文算法的特征提取网络。
输入图像经过多层卷积后,选择26×26和52×52两种尺度的特征图进行融合操作。首先对26×26特征图进行上采样操作,然后与52×52特征图进行向量拼接,得到拼接后的52×52特征图作为预测层之一;上一步拼接后的52×52特征图经过卷积降维后与26×26特征图进行向量拼接,作为预测层之一。经过自底向上和自顶向下两次特征融合操作后,形成PAN网络[14],提升特征图所含的特征信息,最后选取中尺度(52×52)和小尺度(26×26)特征图进行预测,满足现实场景中车标的特点,改进后网络结构如图1。
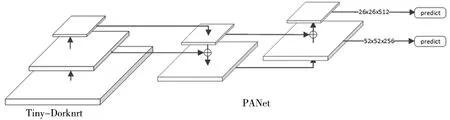
图1 改进后网络结构图
2.2 改进损失函数
模型训练过程中会产生许多预测框,算法会根据预先设定好的阈值计算预测框与真实框的交并比(Intersection over Union ,IoU),大于阈值为正样本,小于阈值为负样本。实际上,负样本的数量往往远多于正样本,根据本文改进后的网络模型,当输入图像尺寸为416×416时,会产生10 140个先验框,而对于车标数据集,每张图片通常只包含一个目标,多数预测框不包含目标,正样本的数量远低于负样本,正负样本不平衡的问题更加严重。Focal loss[6]可以通过调整权重参数,降低负样本的损失权重,因此本文在损失函数中添加Focal loss调整负样本比例,从而改善车标训练过程中正负样本失衡的问题。YOLOv4中引入Focal loss的损失函数如公式(1):
(1)

2.3 K均值重构初始Anchors
基于锚框的检测算法为加快边界框回归速度,在训练之前需根据数据集的不同手动设置初始先验框。针对本文采用的数据集,实验前采用K均值聚类算法计算不同聚类数量下对应的平均交并比,具体结果如图2。
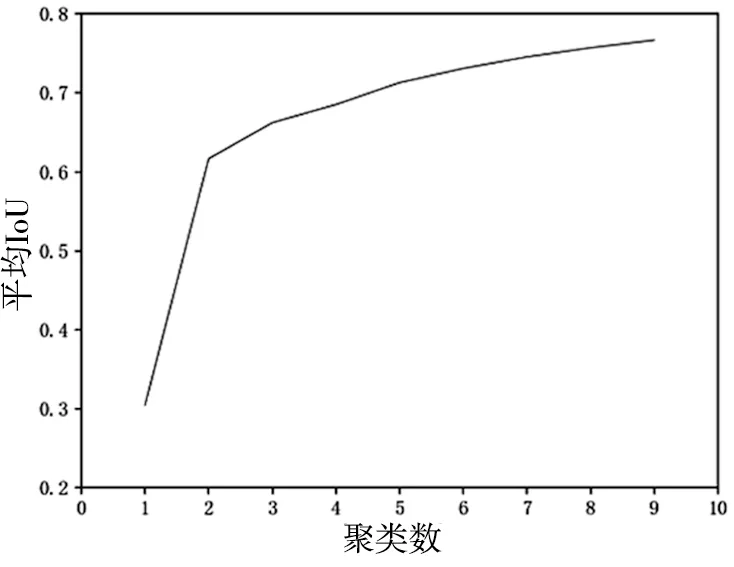
图2 聚类数量与IoU变化图
从图2可以看出,平均IoU值在聚类个数为3之后增长逐渐放缓,因此本文实验选择聚类个数为3,初始Anchor Boxes设为:(11,12);(16,21);(29,30)。
2.4 调整边界框过滤规则
基于锚框的算法在最终检测阶段会产生许多分数不同的边界框(Bounding Box),对于一个检测目标可能会检测出多个边界框,而最终检测结果只需其中一个。Neubeck等[15]提出非极大值抑制算法(Non-Maximum Suppression,NMS)可以过滤掉多余边界框,仅保留精度最高的边界框作为检测结果。NMS先计算边界框之间的IoU值,然后手动设定阈值进行过滤。为解决上述问题,本文算法采用DIoU_NMS[16]作为边界框过滤策略,DIoU是在IoU的基础上添加边界框中心点信息,当两个边界框IoU值较大而中心点距离较远时,DIoU_NMS不会将其过滤,从而避免漏检的情况。DIoU_NMS计算公式如下:
(2)
(3)
式中,d和c分别表示两个边界框的中心点距离和斜对角距离,通过调整β可以控制d和c的比值大小。当β值趋近于+∞时,DIoU逐渐转为IoU;而β值等于0时,与目标中心点不重合的边界框会都得到保留,因此β的选择将直接影响最终检测结果。
2.5 数据集
本文实验采用车标数据集VLD-45-B[17],该数据集共有45个类别,如图3。每个类别含有1 000张照片,共45 000张照片,所有图片均采用现实场景中的车标图片,因此该数据集可以较好地模拟现实中车标检测场景。本次实验将数据集划分为3 6000张训练图片和9 000张测试图片。

图3 VLD-45-B数据集 车标类别图片
3 实验与分析
3.1 实验平台
实验硬件环境为:CPU,Intel i5-10400F;GPU,NVIDIA Geforce RTX 2070;软件环境为DarkNet框架,Cuda 10.1,cuDNN 7.6.5,OpenCV 4.3.0。
3.2 实验设计与结果分析
实验共分为三个阶段。
(1)输入尺寸对比实验。实验选取320×320、416×416和512×512三种输入尺寸作为变量,测试模型精度与检测速度,实验结果见表2。
表中BFLOPs(Billion Float Operations)表示模型需要计算十亿次浮点运算的个数,可表示模型参数的复杂度。从表2可以看出,320×320的输入尺寸虽然模型参数较少,检测速度最快,但精度较差;当输入尺寸为512×512时,BFLOPs相比320×320增加近一倍多,检测速度同时降低,最终检测精度最高,但是mAP@0.75相比416×416输入尺寸仅仅提升1.4%,BFLOPs却增加51%,为平衡检测准确率和检测速度,本文算法采用416×416作为模型输入尺寸。
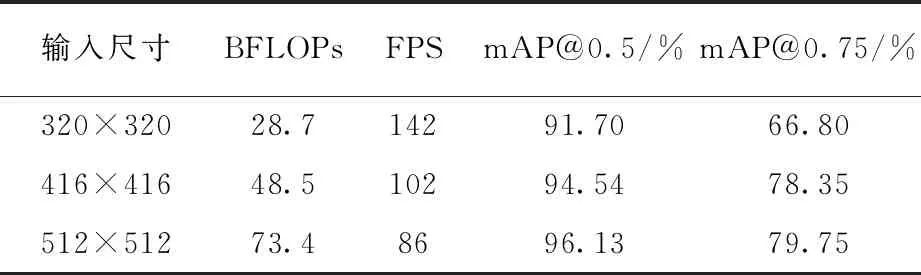
表2 输入尺寸实验结果
(2)边界框过滤策略对比实验。实验分别采取NMS和DIoU_NMS两种过滤策略,同时对DIoU_NMS计算公式(3)中的参数进行调整,根据结果选择最佳的边界框过滤策略,实验结果如图4。

图4 NMS对比实验结果图
从图4可以看出,当采用DIoU_NMS过滤策略时,mAP@0.75相比普通NMS提高约1%,表明DIoU_NMS可以明显提升模型精度;当参数值设定为0.2时,可以达到最佳的检测精度,此时相比普通NMS过滤策略mAP@0.75提升接近2%。因此本文算法选取DIoU_NMS作为算法边界框过滤规则,同时调整值为0.2。
(3)经典算法对比实验。本文实验选取了YOLOv3、YOLOv4、SSD300、Faster R-CNN和RetinaNet五种经典算法与本文改进后的算法进行对比测试。
对比实验中,Faster-RCNN和RetinaNet两种算法均采用ResNet-50作为特征提取网络,同时添加FPN[18]进行特征图增强;YOLOv3-SPP是YOLOv3添加SPP层[19]之后的模型,本次实验也将其作为对比算法;SSD300采用300×300作为输入尺寸,其余算法均采用416×416作为输入尺寸;训练轮数统一设置为90 000轮,batch size设置为16,最终实验结果见表3。

表3 车标检测算法对比
从表3可得知,YOLOv4相比YOLOv3在车标检测精度上有少量提升,模型参数却更少,得益于层数更少的特征提取网络和减少的输出层,本文算法参数计算量较YOLOv4有所下降,最终检测速度高于其他算法;通过对特征图多次融合丰富特征信息、预设先验框、改进损失函数和调整边界框过滤规则操作后,本文算法虽参数更少,但精度仍保持较高水平,其中阈值要求更严格的mAP@0.75达到80.57%,准确率提升较为明显。部分检测效果如图5。

图5 部分检测效果图
4 结 语
本文提出一种基于YOLOv4的改进型车标检测算法,采用层数较少的网络结构,并对特征图进行多次跨纬度融合,极大地丰富了预测层特征图语义信息,选择中尺度和小尺度特征图输入到检测层;改进损失函数以缓解正负样本不平衡问题;预设更加适合车标数据集的先验框,从而加快模型收敛速度;选择最优边界框过滤规则并手动调整参数进一步提高模型精度。实验结果表明,改进后的算法相比经典算法检测速度大幅提升,同时也提高了检测准确率。由于本文算法更加注重检测中小尺度车标,随着目标尺度增大,检测效果会逐渐降低,之后的研究将在增加多尺度车标数据集的同时,进一步改进算法使其更好地适应多尺度车标检测。
