融合近邻标题图的涉案新闻话题发现
2022-05-23卢天旭余正涛黄于欣
卢天旭,余正涛,黄于欣+
(1.昆明理工大学 信息工程与自动化学院,云南 昆明 650500; 2.昆明理工大学 云南省人工智能重点实验室,云南 昆明 650500)
0 引 言
涉案舆情由于其涉案的特殊性,通常具备敏感性和易爆发性,如何有效地进行涉案舆情监管是一个关键问题。而涉案话题包含了涉案舆情信息的准确凝练和大多数网民的关注点,及时发现涉案新闻的话题并疏导涉案舆情对于维护社会稳定而言至关重要。涉案新闻话题发现是指在司法案件相关的新闻信息中,针对同一案件把描述相同话题的新闻信息归到同一个话题簇中,可以转化为一个话题级的聚类任务。目前现有的话题发现模型主要是通过对文档进行表征和使用聚类算法计算文档相似度度量这两个问题上实现的。通过研究[1-3]发现这些方法在处理大规模涉案新闻语料数据时依赖词频统计信息,表征质量不高,对于同一案件不同话题下的新闻文档,无法区分共现词较少但属于同一话题的情况,且使用的聚类方法对数据输入顺序敏感。此外,应用主题模型在话题检测发现、热点主题挖掘以及子话题关联等相关研究任务上也取得了一定的效果。但通过研究[4,5]发现,这些方法捕获的主题信息由于相似度过高而被归为同一个主题下,同样不能够很好地区分同一案件不同话题下的新闻文档,这些研究表明了话题发现任务很大程度上依赖于文档的表征能力。因此,认为提高涉案新闻文本表征的能力才能得到质量更好的涉案新闻话题簇,从而提高话题发现的准确性。
1 相关研究
近年来国内外学者针对涉案领域话题发现研究较少,在通用领域,目前话题发现方法集中于使用传统聚类模型、主题模型以及改进型的聚类模型等方法实现。
基于传统聚类模型的话题发现方法旨在利用基于划分、密度、增量等经典的聚类算法来计算文档样本之间的欧氏距离,根据相似度度量实现话题发现。Nur'aini等[6]使用经典K-means聚类算法实现了Twitter社交媒体话题发现;Mustakim等[7]使用基于密度的应用程序空间聚类DBSCAN(density-based spatial clustering of applications with noise)算法对Twitter文本数据进行聚类,挖掘社交媒体中用户近期感兴趣的热点话题;Zhang等[8]提出了一种基于多视图文本语义和Single-Pass聚类算法的话题发现方法, 在财经新闻数据集中,通过融合模型的特征可以实现从海量数据中获取对投资者有效的话题信息。
基于主题模型的话题发现方法通过LDA(latent dirichlet allocation)等常见的主题模型以及衍生模型,基于词袋模型考虑词条的共现,生成新闻文档的主题分布。Rortais等[9]使用LDA主题模型快速检测媒体中特定的食品欺诈事件,通过探索大量文档,发现与欺诈事件相关的话题,并组织和总结识别其中包含的话题的文本文档;Kumar等[10]提出了一种用于短文本流聚类的在线语义增强Dirichlet主题模型,将语义信息集成到一个新的图形模型中,并在每个输入的短文本中自动聚类,解决话题发现中短文本语义稀疏问题;Fan等[11]提出了一种基于分层贝叶斯非参数框架在线新闻话题发现和跟踪方法,该方法允许在语料库中的不同新闻故事之间共享话题,应用于在线新闻数据流上取得了一定的效果。
基于改进型聚类模型的话题发现方法是在经典的聚类算法的基础上,融入其它模块以增强数据的表示,解决经典聚类算法自身的缺陷。Li等[12]提出了一种基于时间窗口的改进的基于密度的DBSCAN算法,以实现更加准确的话题发现,并具有降低时间复杂度的辅助优势;Xiao等[13]提出了一种基于图形分解的新型文档表示方法,将每个新闻文档分解为不同的语义单元,然后构建语义单元之间的关系以形成胶囊语义图,最后通过Single-Pass算法实现新闻文档的话题发现;Wu等[14]基于BTM(bayesian sparseto-pic model)和GloVe(global vectors)相似性线性融合的方法,将微博短文本分别使用BTM模型和GloVe词向量建模,计算两种不同的相似度,将两种相似度线性融合作为距离函数,实现K-means聚类,提高了微博短文本话题发现精度。
已有的话题发现方法在处理通用领域的任务时已经取得了不错的效果,但是在涉案领域的话题发现任务上效果表现较差,这是由于这些方法所使用相似度度量方法在计算高维数据时效率偏低,且不具备较强的涉案新闻表征能力。
近年来深度学习在大规模数据表征和处理方面表现突出,在聚类算法上融入深度学习强大的表征能力越来越受到重视。Xie等提出模型的聚类不是从数据本身来聚类,而是学习到数据到隐空间的映射,然后设置了聚类优化目标来学习隐空间的聚类;Yang等[15]未采用以往方法的先降维再进行聚类的模式,认为联合这两个过程可以得到更好的聚类效果,提出一种基于深度网络降维和K-means聚类的联合优化准则。这些方法在涉案新闻表征能力上都明显强于以往的话题发现方法,因此本文考虑将深度学习融入聚类算法,并应用到涉案新闻话题发现任务中以提高模型的准确性。本文在学习数据样本的表征中考虑到了数据样本之间关系的重要性,提出一种融合近邻标题图的涉案新闻话题发现方法,既考虑到新闻文档数据自身的特征,又学习到标题关系间的潜在相似性,通过深度网络和图卷积网络学习的表征融合,来提高涉案新闻话题发现聚类的准确性。
2 融合近邻标题图的涉案新闻话题发现方法
2.1 模型框架
针对已有的话题发现方法在涉案新闻话题发现任务中准确度不高,难以区分同一案件话题下新闻信息的问题,本文提出融合近邻标题图的涉案新闻话题发现模型,模型框架如图1所示。该模型主要分为5部分,分别为标题编码模块、近邻标题图的构建、文档特征提取模块、标题结构信息提取模块和指导模块。

图1 融合近邻标题图的涉案新闻话题发现模型
2.2 标题编码模块
标题编码模块用于编码涉案新闻话题数据集中标题部分,通过BERT(bidirectional encoder representation from transformers)预训练模型[16]训练完成后能够获得标题的表征,以便接下来构建近邻标题图。BERT模型是由多个Transformer模型[17]组合而成的,其训练方式分为两个任务:
其一是随机选择15%的词用于预测,其中80%采用MASK符号遮盖,10%用随机词替换,其余保持不变,这使得模型倾向于依赖上下文来预测词汇,具备一定的纠错能力;其二是预测两句话是否为连贯文本。因此BERT模型在结束训练后能够获得涉案新闻标题的单词表征和句子表征。Transformer模型结构如图2所示。
具体如下,设涉案新闻话题数据集中标题Title数量为N,Title={title1,title2,…,titleN}, 每条涉案新闻标题长度为S,E={e1,e2,…,eS} 为每条标题中词向量的集合,将标题的词向量输入到BERT模型中进行编码,可以得到每条标题的向量表征。以编码一条标题为例,编码过程如图3所示。
BERT模型要求每条标题输入的词元表征必须含有3种类型的嵌入,即词元嵌入rwordi、片段嵌入rA和位置嵌入ri,每条标题的词元前都有一个[CLS]标记用来表示整个标题句子。将词向量集合E输入到BERT模型中,经过多层Transformer网络得到每个词元各自的表征。其中位于输出起始位置的[CLS]表征Ti即为整个标题句子的向量表征。将所有标题的词向量分别输入到BERT模型中编码,最终得到融合语义信息后的标题向量表征集合T,T={T1,T2,…,TN}。
2.3 近邻标题图

图2 Transformer模型结构
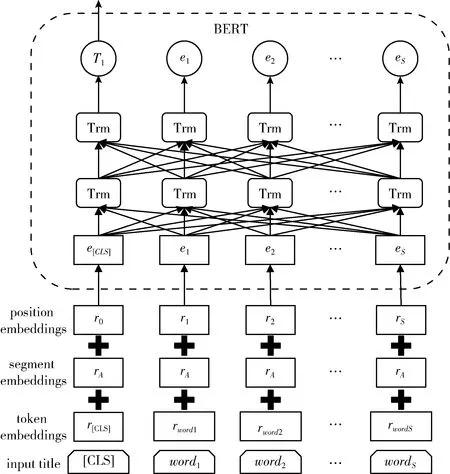
图3 BERT编码涉案新闻标题模型结构
近邻标题图构建模块采用K近邻算法构建近邻标题图来提取标题的全局特征。设标题数据T∈RN×a, 其中每行Ti代表第i个标题样本,N是样本数,a代表维度。对于每个标题样本,首先找到它的前K个相似度最高的邻居作为邻居节点,并通过边来连接,以构成近邻标题图。利用向量的点积运算来计算任意两个标题之间的相似度矩阵Sij,它是一个N×N维矩阵,如式(1)所示
(1)
对于任意两个标题节点ti和tj,令wij为节点之间的权重。如果节点之间有边相连,则wij>0,若没有边相连,则wij=0。由于我们构建的近邻标题图是无向权重图,因此wij=wji。图中任意节点的度为和它连接的所有边的权重之和,定义如式(2)所示
(2)
通过计算每个节点的度,得到一个只有主对角线有值的节点度矩阵D∈RN×N, 如式(3)所示
(3)
主对角线的值表示第i行第i个点的度数。计算所有节点之间的权重,得到N×N维的邻接矩阵M,其第i行第j个元素就是权重wij,wij=sij。
2.4 文档特征提取模块
文档特征提取模块的作用是提取涉案新闻话题数据集中文档的局部特征,本文使用深度神经网络自编码器来学习有效的数据表征。自编码器是一种表示模型,利用输入数据作为参考,不利用标签监督,以用来提取特征和降维。自编码器将输入映射到特征空间,再映射回输入空间进行数据重构。设自编码器有L层,编码器学到的第L层的表征如式(4)所示
H(l)=σ(Wenc(l)H(l-1)+benc(l))
(4)
其中,σ为relu函数,Wenc(l)为编码器中第l层的变换矩阵,benc(l)为偏置。H(0)表示为原始文档数据X。
H(l)=σ(Wdec(l)H(l-1)+bdec(l))
(5)
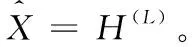
文档特征提取模块的损失函数如式(6)所示
(6)
通过最小化重构误差和梯度下降算法不断优化网络参数进行训练。
2.5 图卷积神经网络
图神经网络GNN(graph neural network)是一类处理图结构信息的方法的统称,其中代表方法是图卷积神经网络。图卷积神经网络是一个对图数据进行特征提取的多层神经网络。传统的卷积神经网络可以处理有规则空间结构的数据,这些数据的结构可以用一维和二维的矩阵来表示。然而许多数据是不具备规则的空间结构的,传统的卷积神经网络就不能处理这些数据。在不规则空间结构的图数据中,每个节点有属于自己的特征信息,每个节点还具有结构信息且图的形状不规则,邻居节点也不固定。图卷积网络可以从这类数据中提取特征,得到图的嵌入表示,从而实现边预测、节点分类等任务。在模型计算过程中,图卷积网络结构如图4所示。
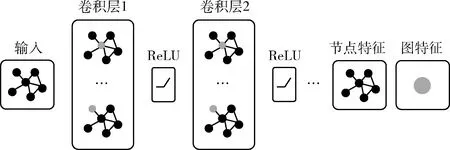
图4 图卷积网络结构
网络首先对节点的特征进行抽取,将每个节点自身的属性信息变换后传送给邻居节点,每个节点收集邻居节点的特征,融合局部结构信息,聚集结构信息和属性信息后做非线性变换以增强网络的表达能力。图卷积网络处理图数据具有以下优势,首先网络中节点的表征与下游任务具有很好的适应性,节点表征与下游任务被统一到一个模型端到端训练,监督信号可以同时指导卷积层与分类层更新参数。其次图卷积网络可以同时学习节点的属性信息与结构信息,使它们协同影响节点的最终表征。
2.6 标题全局特征提取模块
2.4节提到的文档特征提取模块能够从涉案新闻话题数据集的文档中提取有用的表征,但自编码器只提取到了文档局部特征,不能提取到样本之间的关联关系。2.3节构建的近邻标题图蕴含了大量的标题全局结构信息,使用图卷积网络提取近邻标题图中的结构特征,并将自编码器提取到的文档局部特征集成到图卷积网络中,这样模型就可以同时提取到数据的两种不同特征。图卷积网络第l层提取的表征通过卷积运算得到,如式(7)所示
(7)
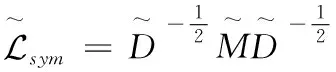
本文为了使图卷积网络学习到的涉案新闻话题数据特征同时具有标题的全局特征和文档的局部特征,将两种表征U(l-1)和H(l-1)通过融合因子结合在一起,得到一种更全面的数据表征,如式(8)所示
(8)

(9)
以此类推得到图卷积网络最后一层输出的表征U(L)。网络的输出端连接了一个softmax多分类器,最终输出的结果如式(10)所示
(10)
模型得到的结果U是一个概率分布,其元素uij表示涉案新闻样本i属于簇中心j的概率。
2.7 指导模块
在上一节中已经将自编码器和图卷积网络学习到的表征通过融合因子结合了起来,并且得到了概率分布U。但是自编码器的作用主要是用来学习文档的局部表征,是一种无监督的学习,而图卷积网络主要用来学习标题的关系特征,它们都不是直接用来做聚类任务的,需要在表征中引入聚类信号。因此本文使用指导模块将两个模块统一到一个框架中同时进行端到端的聚类优化训练。
对于第i个样本和第j个簇,引用自由度为1的student-t分布作为核函数衡量自编码器的表征hi和簇心μi之间的距离,如式(11)所示
(11)
其中,hi表示H(L)的第i行,μi是经过K-means算法初始化后的簇心。我们将q视为文档样本i被分配到簇j的概率,Q即为所有文档样本分配到簇的分布。
为了得到高置信度的分配来迭代聚类结果,提高聚类准确度,构造一个目标分布P来辅助模型训练,如式(12)所示
(12)
在目标分布P中,每一个在文档样本分配分布Q中的聚类分配都被先平方再归一化处理,这样可以获得更高置信度的聚类分配,迫使簇内的样本更加接近簇心,簇与簇间的距离最大化,分配更加清晰。指导模块的损失函数之一为分布Q和目标分布P之间的KL散度损失,如式(13)所示
(13)
通过最小化损失函数更新参数,目标分布P使自编码器学习到更接近簇心的样本文档聚类表征。
为了使标题全局特征提取模块和文档特征提取模块在训练迭代过程中趋于一致,需要将两个模块统一在同一目标分布中,因此也可以使用目标分布P指导图卷积网络输出的蕴含标题全局特征的样本分布U。指导模块的损失函数之二为分布U和目标分布P之间的KL散度(Kullback-Leibler divergence)损失,如式(14)所示
(14)
通过指导模块的不同权重参数可以将两种不同表征的聚类分配统一在同一个损失函数中,模型的整体损失函数如式(15)所示
(15)
β为平衡损失函数一和损失函数二的权重参数。整个模型经过训练达到稳定后,可以将图卷积网络最终输出的聚类分布U作为涉案新闻话题发现的最终结果。
3 实验结果与分析
3.1 涉案新闻话题数据集
涉案新闻话题发现任务属于针对司法案件特定领域的任务,目前尚未有公开的涉案新闻话题数据集。因此本文在自行构建的涉案新闻话题数据集的基础上开展具体工作。
本文通过分析“百度新闻”、“新浪新闻”、“今日头条”等各大新闻网站和公众号平台近年来的涉案重点新闻,选取了“奔驰车主维权案”、“孙小果涉黑案”等十余个网民关注度较高的案件进行涉案新闻话题数据集的构建。使用爬虫技术根据新闻网站上的案件相关话题和案件关键词爬取有关的新闻数据,通过对爬取的新闻进行分析使每条涉案新闻只属于一个案件话题,人工标注新闻与哪个案件话题相关,经过数据筛选和预处理,保存为json格式的文件。数据的筛选和预处理过程包括对新闻数据和案件话题相关性的人工校准,去除非案件话题相关的数据和重复的数据,去除特殊符号和链接等。最终得到每条清晰、准确的涉案新闻标题和文档,构建出涉案新闻话题数据集。数据集的具体信息见表1。
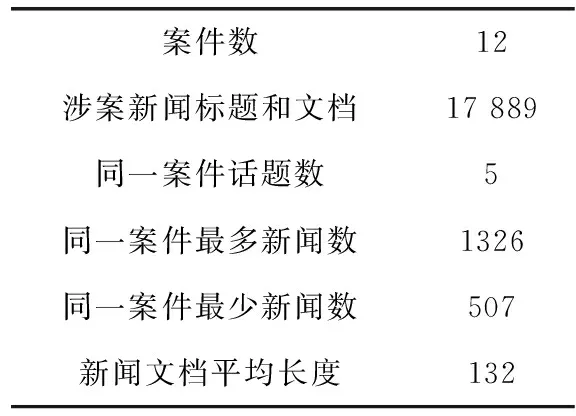
表1 实验数据集统计信息
3.2 评价指标
对涉案新闻话题发现的结果进行评估,本文使用准确率(Accuracy,ACC)、标准化互信息(normalized mutual information,NMI)和调整兰德系数(adjusted rand index,ARI)作为模型的评价指标。
准确率(ACC)是衡量话题发现算法对话题簇划分准确程度的评价指标。具体计算如式(16)所示
(16)
其中,TP,TN,FP,FN为混淆矩阵中的每一项,TP和TN分别表示模型与真实标签同时判定样本为正或负,即聚类准确的样本,反之FP和FN为聚类错误的样本。ACC的取值在0到1之间,取值越大代表话题发现准确率越高。混淆矩阵见表2。
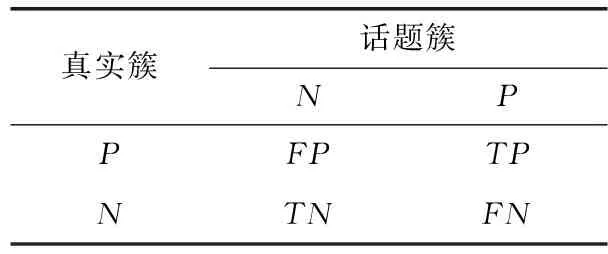
表2 样本混淆矩阵
标准化互信息(NMI)是衡量话题发现聚类结果与真实样本分布之间的熵,NMI的取值在0到1之间,取值越大代表话题发现聚类效果好,如式(17)所示
(17)
其中,Y表示真实的样本分布,C表示话题簇的分布,I(Y;C) 表示Y分布与C分布之间的互信息,H(Y) 与H(C) 表示信息熵。
调整兰德系数(ARI)是衡量话题簇分布和真实分布的重叠程度的评价指标。ARI取值在-1到1之间,取值越大代表话题模型效果越好。其计算公式如式(18)所示
(18)
其中,RI为兰德系数,E(RI)为兰德系数的期望值,计算公式如式(19)所示
(19)
式中:a,b,c,d为表3中的变量。兰德系数变量见表3。

表3 兰德系数变量
3.3 实验设置
在模型的参数设置方面,本文通过预先训练的BERT中文语料库来表征涉案新闻话题数据集中的标题,词表为BERT模型自带词表,BERT模型包含12层Transformer网络,每层网络包含12个注意力头,模型参数为110 M,隐藏层维数为768;文档特征提取模块中自编码器的维数为“输入-768-768-2000-10”,标题全局特征提取模块中使用了4层图卷积神经网络来迭代近邻标题图的关系特征,近邻标题图中K的个数取值为10,话题簇初始簇心由K-means算法经过20次初始化获得,融合因子中平衡系数α设置为0.5;模型训练轮次为200,学习率为1e-3,优化器采用Adam。
3.4 基线模型分析
为了验证融合近邻标题图联合标题和文档进行话题建模对提高涉案新闻话题发现任务聚类效果的有效性,本文选取8个模型作为基线模型,分别在涉案新闻话题数据集上进行实验,其基线模型为:经典K-means算法、LDA、AE+Kmeans、DeepLDA、DEC、DCN、IDEC和NMC。
(1)K-means[6]是一种经典的聚类算法,在给定数据和聚类数目k的基础上,根据某个距离函数将数据分入k个簇中。
(2)LDA是一种经典的主题模型,可将每篇文档的主题以概率分布的形式给出,可根据主题分布进行聚类。
(3)AE+K-means是一种同时利用自编码器的表征和数据重构并结合K-means算法的聚类模型。
(4)DeepLDA[18]是一种融合深度神经网络的主题模型,将文档的词袋表示输入深度神经网络中,将LDA的输出作为一个标签,对神经网络进行监督训练,使神经网络既能学习主题文档分布,又能学习主题词分布。
(5)DEC利用深度网络进行数据降维,通过软分配构造数据样本的簇分布,构造辅助目标分布计算其与样本分布的KL散度。
(6)DCN[15]联合优化降维和聚类任务,利用深度神经网络逼近任何非线性函数的能力的同时,保持降维和聚类共同优化的优势。
(7)IDEC[19]考虑到保留数据的结构,并利用聚类损失作为指导,操控特征空间分散数据点,即模型可以联合聚类并学习代表性特征。
(8)NMC[20]是一种神经主题模型,利用伽马分布的重参数化和泊松分布的高斯逼近,开发了神经变分推理算法来推断模型参数,在大规模数据和特征稀疏的短文本数据上具有优势。基线模型性能比较见表4。

表4 基线模型性能比较
从表4的实验结果中能够看出,经典K-means算法在处理涉案新闻话题数据时效果最差,因为它使用原始数据,不能很好地进行表征,且易受孤立点的影响。LDA主题模型应用于通用领域的话题发现任务可以取得不错的效果,但是由于涉案新闻数据的特殊性,LDA依赖于统计特征,聚类结果经常出现同类不同案的现象,准确率仍然不高。AE+K-means方法通过自编码器对数据降维后,得到数据的表征,再利用K-means算法进行聚类,话题簇的准确性得到了较为明显的提高,说明构造准确有效的表征对提升聚类准确率非常重要。DeepLDA方法通过深度网络加强表征,并将LDA作为监督信号后,模型的计算效率大幅提升,但是由于缺乏标题信息等外部知识和聚类监督信号对主题分布的帮助,模型的内聚性仍然不高。DEC和DCN模型相比较以上基线模型取得了更好的效果,因为这两种模型都引入了损失函数或目标分布作为监督信号,可以同时学习数据表征和聚类分配,并优化聚类样本使其更加接近话题簇心。IDEC模型相较于DEC和DCN模型效果又有了一定提升,因为模型引入了重构损失可以学习到数据中具有局部结构保护的代表性特征。NMC模型是一个比较新型的神经主题模型,相较于其它基线模型,NMC在准确性指标上具有优势,可以较好地模拟具有过度分散和层次依赖特征的随机变量,但受限于数据规模和涉案新闻的特点,通过统计分布学习文档局部特征仍然具有主题不一致问题。
本文方法与其它基准模型相比取得了更优的性能,与NMC基线模型相比,ACC提升了4.33%,NMI提升了2.73%,ARI提升了3.93%。这是因为基线方法在做涉案新闻话题发现任务时,通常只着重提取文档自身的局部特征,而同一涉案新闻不同话题下的新闻文档包含了许多相似案件要素信息,基线方法不能很好地区分。本文的模型利用图卷积网络提取了近邻标题间的关联关系,并将其与文档的局部特征融合起来以增强标题的表征,从而实现话题建模更好的效果。这也证明了通过融入近邻标题图,联合标题与文档进行话题建模是有效的。
3.5 消融实验分析
为了验证本文模型各个模块的有效性,将模型拆解为主模型去除文档特征模块和主模型去除标题全局特征模块两个子模型,3个评价指标保持不变,最优结果用加粗表示。消融实验结果见表5。
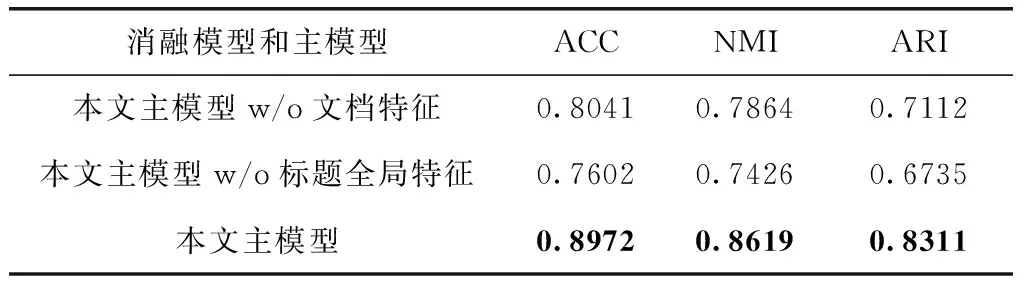
表5 简化模型性能分析
从消融实验结果可以看出,去除模型中的标题特征部分,只利用文档局部特征和指导模块进行建模效果最差,ACC下降了13.7%,NMI下降了11.9%,ARI下降了15.7%。虽然文档中包含了大量的案件要素信息,但是同一案件下不同话题的新闻文档要素有很多相似之处,噪声数据多,容易出现同一案件下划分为同一话题簇的数据却本该属于不同话题,或属于同一类型的案件却不是同一案件的情况。只利用标题全局特征和指导模块建模,效果比仅用文档特征要好一些,ACC下降了9.3%,NMI下降了7.5%,ARI下降了11.9%。因为模型提取到了近邻标题间的结构关系,但是由于标题篇幅的限制,所涵盖案件话题信息的内容有限,容易出现标题的信息偏置。将标题特征与文档特征结合起来建模,即本文主模型,效果提升明显。在获取涉案新闻之间的关联关系的基础上,同时引入文档表征增强标题的表示避免偏置可以更好地实现涉案新闻话题发现,这也从侧面验证了本文模型的有效性。
3.6 不同融合因子权重系数实验分析
为了验证调整融合因子的权重系数,即式(8)中权重系数α是否对模型性能有提升,本文做了如下实验。取步长为0.2的多个α值分别做对比实验。实验结果如图5所示。
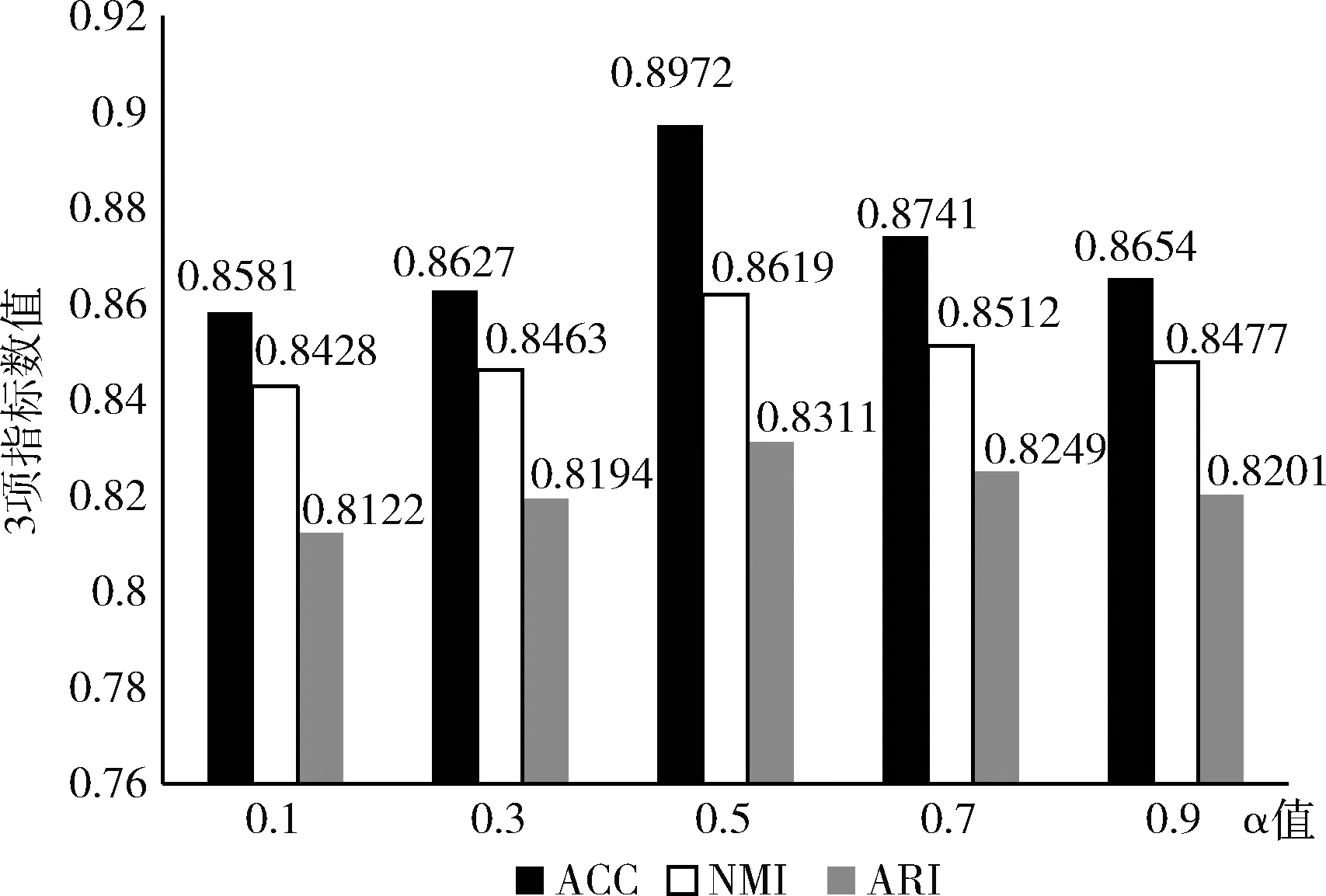
图5 不同融合因子权重系数对模型的影响分析
从实验结果中可以看出,当α取0.5时,本文模型达到了最好的效果,而当α取值比0.5大或者比0.5小时,模型的性能都有所下降。因为α是融合因子的平衡权重系数,起到平衡标题全局特征和文档局部特征的作用。当α过大时,文档的局部特征权重就被削弱,模型只能学习到近邻标题图的关联关系,缺乏文档的内容信息,容易产生标题的信息偏置,图卷积网络容易产生过度平滑,同时模型失去了自编码器的重构损失,涉案新闻话题发现的准确性会降低;当α过小时,标题的全局特征权重被削弱,模型学习到的表征几乎全部来自文档自身,相似要素不能得到很好的区分,涉案新闻话题发现的准确性同样会降低。因此,将融合因子的权重系数α设置为0.5可以很好地融合两种特征。
3.7 随时间变化模型的准确率分析
为了验证时间指标对本文模型性能的影响,选取了DEC、IDEC、NMC这3个在基线对比实验中表现较好的模型和本文模型,在时间指标上进一步对比模型的准确率,如图6所示。
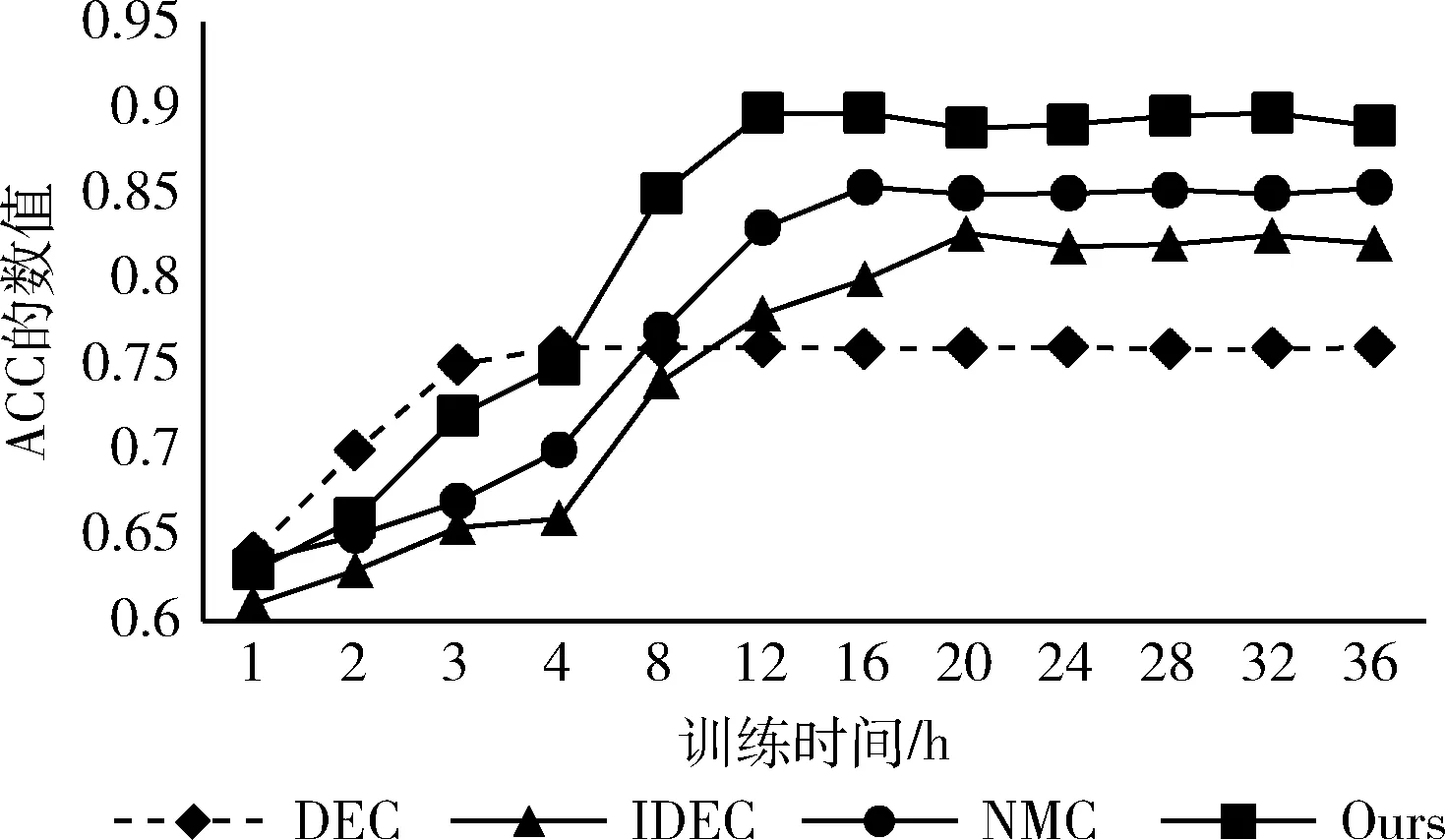
图6 不同模型随训练时间增加准确率的变化分析
从训练模型的收敛时间上可以看出,DEC模型收敛的时间最快,在模型训练4个小时左右即达到了该模型准确率的最优值,但是准确率最高仅有0.7602,不能满足准确性的要求。而NMC和IDEC模型在准确性上要比DEC好很多,但受限于模型复杂程度的影响,需要训练16个小时以上才能达到收敛并达到最佳准确率,在实际应用中可操作性较差,不能及时发现涉案舆情话题。本文模型虽然没有DEC收敛速度快,但是相比另外两个对比模型,仅需一半的时间就可以达到收敛,且准确率可以达到0.89以上,在实际应用中非常适用于涉案舆情新闻早期传播的话题发现,对于有关部门开展舆情监管具有实际意义,也印证了本文方法的实用性。
3.8 实例分析
为了进一步验证本文方法模型的效果,通过实例分析对比了不同方法话题词的效果。以涉案话题“孙小果被判处死刑”为例,本文通过提取不同方法生成的话题簇中新闻文档的关键词,来直观地展示模型效果。实验结果见表6。
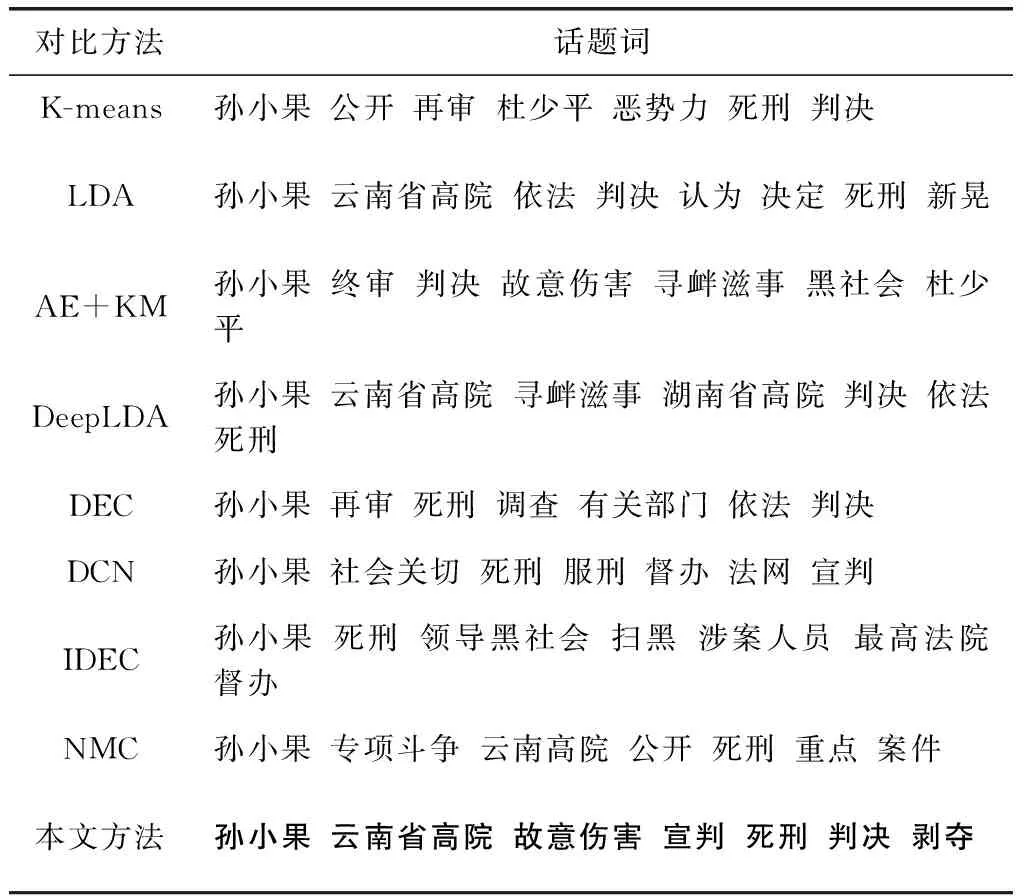
表6 实例分析
从话题词的质量上可以看出,传统的聚类方法和主题模型方法以及它们的改进型方法的话题词中混入了同类型案件话题词,提取出了与“孙小果被判处死刑”话题同类型的“操场埋尸案杜少平被判处死刑”的话题词,说明使用原始数据以及依赖统计特征不能区分涉案新闻的要素信息,导致同类不同案的情况发生。而使用融入深度学习表征的聚类方法的话题词虽然描述的是同一案件,但是掺杂了同一案件下不同话题的词语,比如“孙小果被判处死刑”的话题词掺杂了“孙小果案挂牌督办”的话题词,这是因为此类方法在话题发现的过程中只重视文档自身的表征,没有考虑文档之间的关联,也没有融入外部信息指导。本文方法的话题词全部来自同一话题,话题发现准确率较高,充分说明引入标题的关联关系以及聚类指导模块,适用于涉案新闻话题发现任务。可以取得较好的效果,也验证了本文方法的有效性。
4 结束语
本文针对涉案新闻话题发现任务,提出一种融合近邻标题图,联合标题和文档的表征进行话题建模的方法。解决了同一案件下话题新闻要素信息较为接近,表征不理想的问题,并提升了话题发现的准确性指标。基于涉案新闻话题数据集的实验结果表明,本文方法不仅可以得到质量更高的话题簇,而且在模型训练的时间指标上也有优势。
在未来的工作中,将探索如何从话题簇中得到准确的话题表示,并考虑话题关键信息的摘要抽取,以及长文本的处理工作,来进一步提高话题模型的性能。
