面向不完备信息的网络入侵检测方法
2022-05-23张翼英阮元龙周保先
张翼英,阮元龙,尚 静,周保先
(天津科技大学 人工智能学院,天津 300457)
0 引 言
入侵手段的发展呈现多平台感染、产业化的特征,在入侵技术不断升级的网络环境中,入侵检测的重要性日益凸显,建立一套有效网络入侵检测机制尤为必要[1-3]。近年来,随着人工智能的发展,基于深度学习的入侵检测成为研究热点。基于深度学习的入侵检测包括特征提取和分类,特征提取是通过组合低层特征实现特征的降维[4]。但深度学习在处理大规模的入侵检测时,存在两个问题。第一,深度学习比较复杂,过于复杂的深层神经网络需要花费大量的时间训练参数,难以满足检测实时性的要求[5,6]。第二,深度学习的训练必须以大量的完备数据为基础,以增强模型的训练效果,但是在收集与传输网络数据的过程中,常常会出现数据未完全收集或信息不完备的情况[7,8]。因此,当下基于深度学习的网络入侵检测方法,虽然获得了较好的检测准确率,但对数据量要求较高,参数训练也非常耗时。针对上述问题,提出了面向不完备信息的深度信念网络的入侵检测方法(intrusion detection with incomplete information based on deep belief network,IDII-DBN),基于SMOTE方法进行,然后采用DBN进行特征降维和SVM分类,实现了信息不完备下的轻量级高效入侵检测,提高了罕见攻击的检测准确率。
1 相关工作
目前,国内外采用深度学习的方法研究入侵检测均取得一定效果。针对训练效率,文献[9]提出了一种基于卷积神经网络(convolutional neural networks,CNN)的入侵检测方法,该方法可以有效提取原始样本信息,从而提高分类准确率,但是过程相对耗时。文献[10]基于稀疏自编码器(sprarse auto-encoder,SAE)进行特征提取,用自学习(self-taught learning,STL)的方式进行有监督的训练,达到了90%以上的检测正确率,但是有监督的训练对运算的要求过高,难以做到实时检测。文献[11]采用一种完全基于前馈神经网络的检测模型(simplified feedforward intrusion detection,SFID),通过逐级递减神经元个数消除数据中的冗余特征,达到简化模型、缩短训练时长的效果,但相较复杂网络的检测结果仍有提升空间。
针对不完备信息,文献[12]基于SVM-Adaboost结合的检测模型,将SVM作为弱分类器、Adaboost作为集成器,利用其各自优势提升了训练效率,但是没有考虑数据类别不平衡。文献[13]基于神经元映射卷积神经网络,用ReLU激活器作为非线性激活函数,采用Adam算法进行学习,具备较少的连接和参数,具有易于训练和泛化能力强的优点,但暴露了数据不平衡的问题,缺少对不完备信息数据的处理。文献[14]基于小波变换和人工神经网络(artificial neural network,ANN)的混合模型,降低了数据不平衡所带来的负面影响,提高了模型在少量数据类别上的检测准确率。文献[15]基于对数据集数据随机丢弃的方式来解决数据的不平衡问题,仅仅使用40%的数据就获得了较高的准确率,但是对少量数据类别的分类效果准确率较低。文献[16]将DBN与核极限学习机(kernel extreme learning machine,KELM)结合提出了一种混合深度学习算法,但是算法没有考虑数据分布不均,因此对少数类别的数据分类效果也不好。文献[17]考虑特征收集不完整的情况,为了模拟真实的网络环境,提出基于特征丢弃的入侵检测方法,在使用少量特征的情况下,获得了较好的检测效果。文献[18]基于深度信念网络具有较好的非线性学习能力的特征,选取三层受限玻尔兹曼机(restricted boltzmann machines,RBM)和单层反向传播算法(back propagation,BP)对高维数据做降维处理,并使用softmax函数对入侵数据进行分类,但是在检测时间上存在不足。
上述方法基于数据完整实现了对入侵检测的有效监测,但是模型存在对数据特征的敏感度高、数据量需求大、参数过多等问题。因此总体的入侵检测时间长、罕见攻击检测准确率低,在具体应用中存在限制。因此,在真实的网络入侵检测环境中,面对不完备信息的网络数据,如何提高训练的准确率和缩短训练时间也是本文研究的重点问题。
2 基于IDII-DBN入侵检测模型
在数据的收集与传输过程中,会出现数据未完全收集或信息丢失的情况;出于保护用户隐私和安全的考虑,部分数据会被隐蔽起来,无法参与实际的入侵检测。因此,在数据层面,面对信息不完备的网络数据,模型对网络数据进行不完备信息的处理,针对各类别数据量的不平衡进行优化。使用改进后的SMOTE采样方法,对网络数据中的低频样本进行增量处理,实现各类别的数据量进行平衡,从而使得网络数据可以得到更加充分的训练,以此来抵消数据在传输过程中出现的数据丢失问题。模型对采样后的网络数据采用深度信念网络对其进行训练,通过多层RBM对数据进行降维,提取出最有效的特征,利用BP算法对参数微调,获得原始数据最优的特征表示。最后将降维后的数据送入SVM分类器,SVM在低维数据和高维数据上都有良好的分类表现,且正则化方法有效预防过拟合的问题。经由DBN降维后数据大大降低了SVM的训练时间,满足了入侵检测实时性的需求。
与现有的一些算法相比,本文模型有如下的优点。
(1)模型考虑了真实网络在传输过程中可能出现的信息不完备现象,通过SMOTE采样方法的方法来弥补数据在类别上不平衡的缺陷,实现信息特征稳定下的数据均衡化,降低了模型对特征的敏感度,避免因数据污染或特征丢失导致的训练不充分的问题。
(2)在算法层面,模型基于DBN算法对入侵检测的数据进行降维,数据通过RBM映射实现降维、消除冗余特征,获取数据低维特征,实现对海量无标签数据的特征提取。将精简后特征送入SVM分类器进行分类训练,先判断数据是否为入侵数据,若判定为入侵数据则进一步判断是否为已知入侵数据。若是未知入侵数据,对新特征进行学习,并将其加入特征知识库。通过精准捕捉入侵特征,避免了因特征冗余而导致的训练时间过长。满足了网络入侵检测的实时性的需求,以较高的准确率实现低维特征下的轻量级入侵检测。IDII-DBN模型如图1所示。
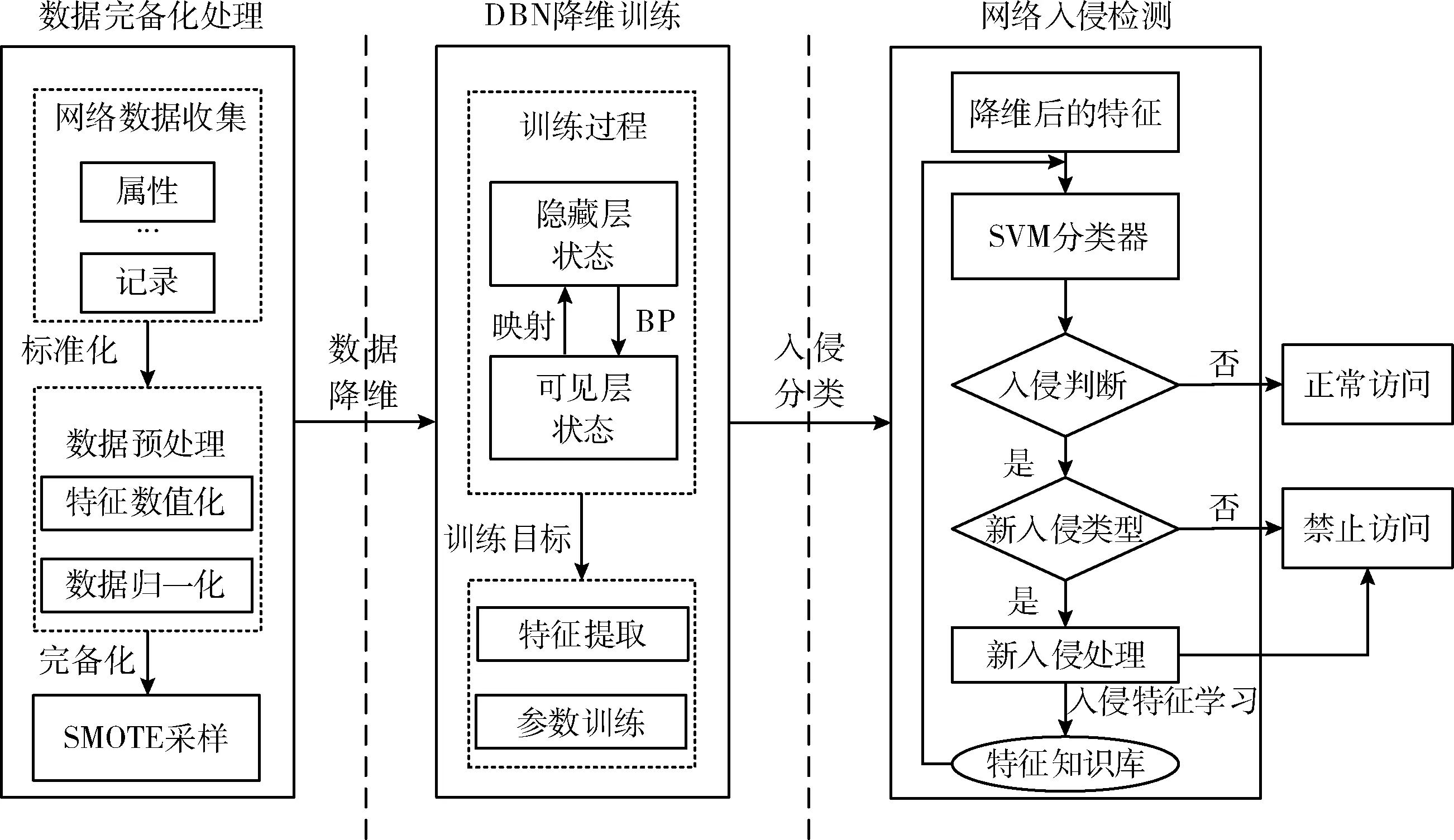
图1 IDII-DBN检测模型
为了弥补网络数据在类别上的不平衡,模型使用SMOTE的采样的方法,避免了分类准确率下降和训练不充分。采样后的数据用DBN算法进行降维,通过RBM网络逐层映射和BP算法的参数微调,实现整体参数的优化。降维后的数据输入SVM分类器,进行攻击类别的识别。
2.1 基于SMOTE采样的缺失数据完备化
尽管近些年网络入侵愈来愈频繁,但是入侵数据相较于正常的网络行为数据依旧不足。由于网络入侵的数据样本过少,而机器学习模型通常以最大化整体分类精确度为目标,当低频攻击实际样本数量过少时,模型进行特征捕捉时往往效果不佳,故对模型无法进行有效的训练,导致最终分类结果的准确率低,特别是对少量样本的检测难度很大。机器学习的算法存在结构简单,特征提取单一,泛化性差的局限性,仅对小批量数据具有良好的拟合效果,当面临大规模类别不均衡的数据集时无法对数据形成有效的非线性映射。大多数机器学习模型及算法中低频攻击样本在训练及分类过程中被忽视,导致训练后的模型存在分类偏向性,在实际应用中的检测准确率下降的问题。
网络数据既有数值型数据又有字符型数据,采用one-hot编码方式对字符型数据做数值化处理。部分数值的量纲差异过大,这会增加训练时间、网络收敛过慢,故预先对数据进行归一化操作,实现了特征在区间上的映射。归一化公式如式(1)
(1)
x′为归一化后的特征值,x为原特征值,xmax,xmin分别是该特征属性中的最大值和最小值。
本文基于已有的非平衡数据处理方式对数据进行过采样,针对信息不完备采用SMOTE采样方法对类别间的数据量进行平衡,在确保特征稳定的前提下实现了数据的完备化。SMOTE核心是通过线性变换函数在一些距离较近的少数类数据中获得新数据,使得原数据集类别间的数量相对平衡[19]。SMOTE通过对原始数据的线性插值来生成原数据集中不存在的数据。对少数类中的每条数据x,选择与其距离较近的K条数据,根据采样的倍数N,在K个近邻中选取N个数据,记为yi(i=1,2,…,N)。 在x和yi之间线性插值产生新的数据pi, 采用弥补了信息在类别上的缺陷,实现缺失数据的完备化。线性插值如式(2)
pi=x+rand(0,1)*(yi-x), i=1,2,…,N
(2)
rand(0,1) 表示生成0到1之间的随机数。
2.2 基于DBN的数据降维
当下的网络入侵数据具有维度高的特点,同时各个数据类别的数量不均,易导致分类结果出现偏差。当下大多数入侵检测模型对类别不平衡的数据分类能力较差,存在训练时间长、分类准确率低的缺陷。因此如何将高维的数据映射成低维的特征数据,从而解决攻击数据不均衡问题是本文需要解决的一个关键问题。本模型针对高维数据的特征冗余特性,采用DBN对数据降维。从结构上看,DBN由多层RBM和一层有监督的BP网络组成,通过对低维特征的组合实现数据降维。模型构造的DBN包含三层RBM和一层BP网络,其结构图如图2所示。
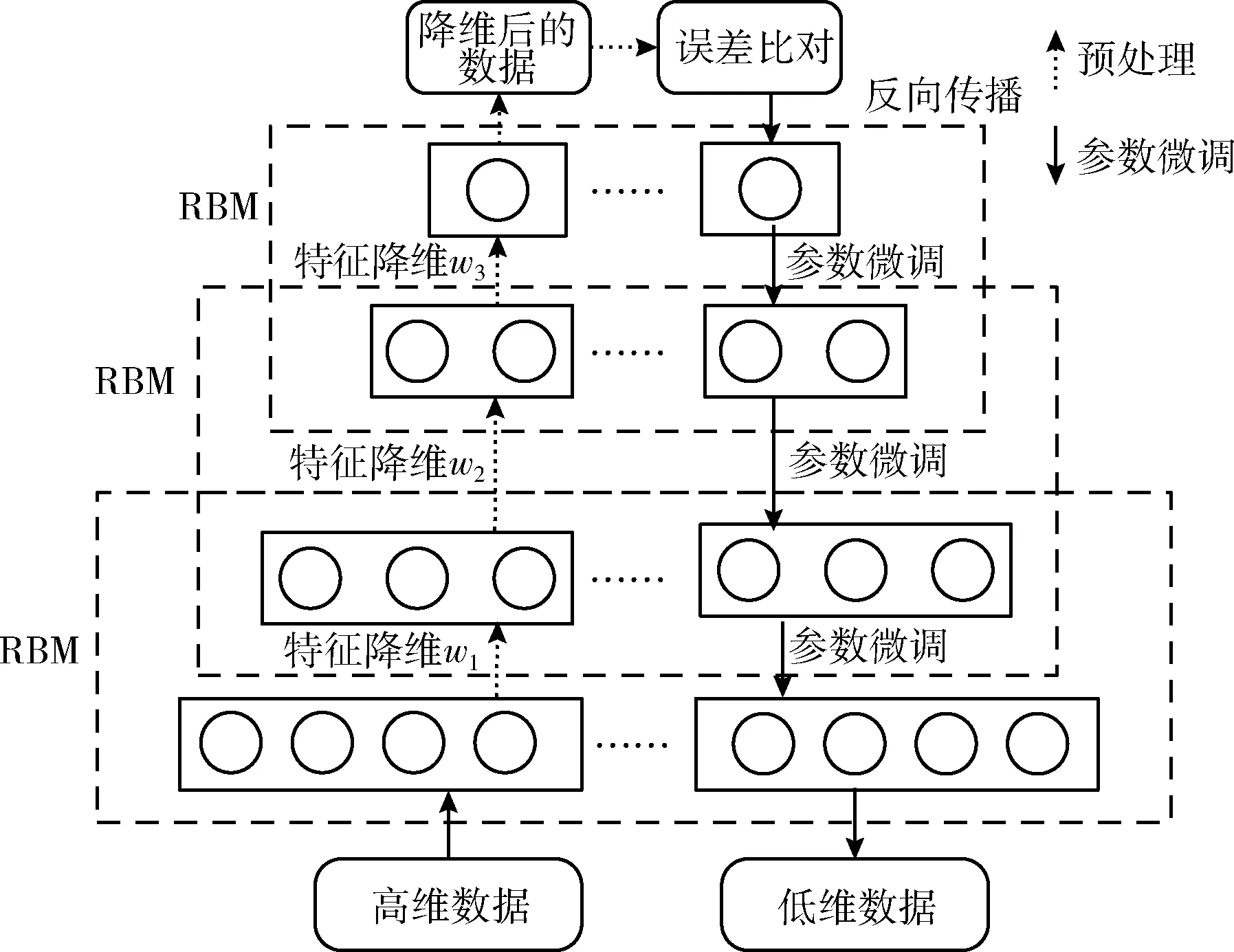
图2 深度信念网络结构
DBN模型的预处理是一个无监督的自上而下的训练过程,通过RBM实现特征降维。微调是对网络整体调优,利用BP算法将误差自上向下的传播,实现参数优化。RBM是一种神经感知机,具有两层结构,分别是可视层和隐藏层,两层之间对称连接,权值相同,层内无连接。RBM的特征降维如图3所示,每层RBM均由可见层和隐藏层组成,数据由可见层输入,由隐藏层输出,并实现降维。其中,可见层特征数n多于隐藏层特征数m。
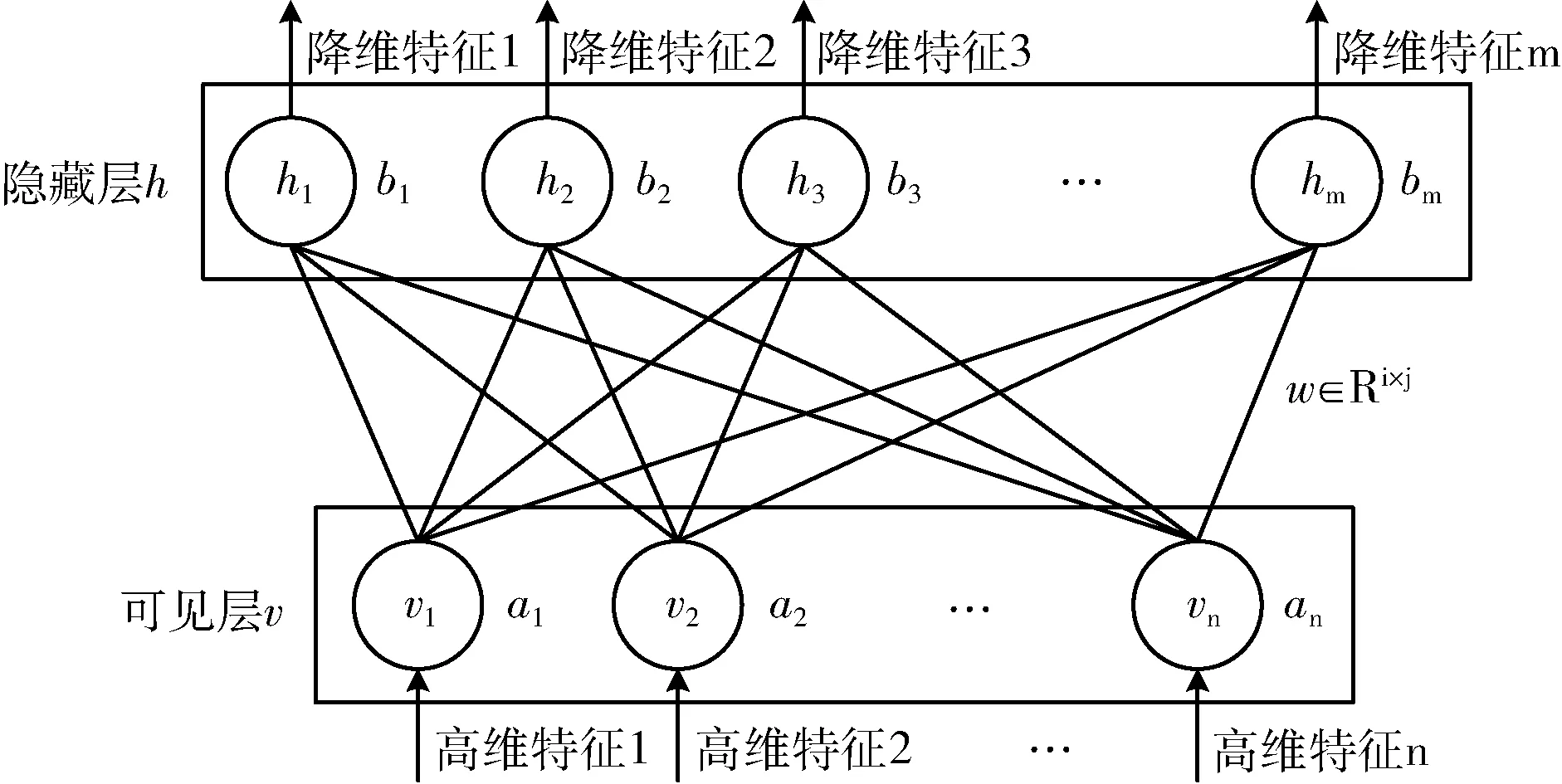
图3 基于RBM的特征降维
RBM的训练可分为前向和重构两个阶段,其中v=(v1,v2,…,vn) 为可见层,表示输入数据,h=(h1,h2,…,hm) 为隐藏层。此外 RBM还包含了3个通过数据学习得到的参数,分别是w、a和b,wij表示可见层和隐藏层间的权重,ai表示显神经元i的偏置,bj表示隐神经元j的偏置。
RBM是概率图模型, 本文模型假设所有显单元和隐单元均为二值变量,即∀i,j,vi∈{0,1},hj∈{0,1}。 用vi表示第i个显单元的状态,hj表示第j个隐单元的状态,Z是归一化因子。则一组给定的状态 (v,h), 其能量函数的定义如式(3)
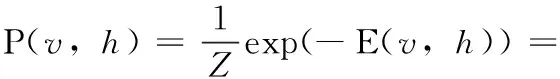
(3)
θ={wij,ai,bj} 是RBM的参数。
当可见层的状态确定时,每个隐藏层单元的激活是条件独立的,隐藏层的第j个单元被激活的概率如式(4)
(4)
当隐藏层的状态确定时,每个可见层单元的激活也是条件独立的,可见层的第i个单元被激活的概率如式(5)
(5)
n维数据X(x1,x2,…,xn) 经RBM降维后得到m维数据Y(y1,y2,…,ym)。
训练过程如下:
(1)数据X经可见层v传到隐藏层h,并基于sigmoid函数获取每个隐藏层神经元的激活概率;
(2)计算可见层和隐藏层中每个神经元的激活概率,得到神经元激活的概率p(h2|v2);
(3)更新RBM中的参数w、a和b;
(4)重复上述过程,得到隐藏层的输出样本Y(y1,y2,…,ym), 实现特征的降维。
DBN基于无标签的数据采用无监督的学习生成模型,获取模型的权重和偏置后,基于BP算法对参数进行更新,实现特征降维。
2.3 基于SVM的轻量级入侵检测
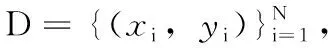
(1)构造优化问题,其表达式如式(6)
(6)
(2)构造带约束的拉格朗日数函数,其表达式如式(7)
(7)
(3)利用对偶性将函数转化为无约束问题,并利用KKT(Karush-Kuhn-Tucker conditions)条件,求出参数ω*,b*。 参数表达式如式(8)所示
(8)
(4)构造决策函数,调整模型参数,并利用测试集对参数进行验证。决策函数表达式如式(9)所示
f(x)=sign(ω*Tx+b*)
(9)
(5)未知样本分类,将新的网络数据样本点导入到决策函数中实现入侵检测。
3 实验设置
基于国际公认的KDD Cup 99数据集是网络入侵的标准数据集[20]。对KDD Cup 99数据集进行预处理,对预处理后的数据使用SMOTE采样,优化各类别的数据量,并将数据分为训练集和测试集。将采样后的数据使用DBN降维,通过多层RBM提取特征,利用BP算法微调网络参数。将降维后的数据送入SVM分类器,利用数据的低维特征实现轻量级的入侵检测。实验中对每个数据集进行多次独立重复实验。
3.1 实验数据
KDD Cup 99数据是有标签的数据集,数据被标记为5大类:正常类型数据(Normal)、拒绝服务攻击(denial of service,DOS)、远程主机攻击(remote to local,R2L)、用户到根攻击(user to root,U2R)、端口扫描攻击(Probe)[21]。数据集中的攻击类型共39种,训练集中有22种已知攻击类型,测试集中有17种未知攻击类型[22]。数据类型数量分布见表1。

表1 数据类型数量分布
3.2 评价指标
使用准确率和训练时长作为模型的评价指标。样例根据其真实类别与分类器的预测类别组合分为真正例(true positive,TP)、假正例(false positive,FP)、真反例(true negative,TN)、假反例(false negative,FN)4种类型[23]。准确率的定义表达式如式(10)
(10)
模型的准确率AC表示预测正确的个数占全部样本的百分比,百分比越大表示模型的检测效果越好。
4 实验及结果评估
为模拟真实环境中信息不完备的情况,实验中递减数据的特征量,观察IDII-DBN算法在准确率和检测时间上的变化情况。
针对检测准确率:第一,设计了数据特征量对准确率的影响实验,特征量从全部特征量的80%开始,以10%递减,直至为总特征量的10%,并与SFID、DBN算法进行对比。第二,设计了采样数据和原始数据的对比实验,验证了缺失数据完备化方法对分类准确率的影响。第三,比较不同降维方法在该模型中对最终检测准确率的影响。
针对检测时间,对比了IDII-DBN、SFID、DBN这3种算法在特征量不同情况下的耗时。
4.1 准确率
实验对比了IDII-DBN、SFID、DBN这3种算法在信息不完备情况下的入侵检测准确率。为了比较特征提取对分类效果的影响,设计了与文献[11]SFID方法和文献[18]DBN的对比实验。文献[11]通过神经元个数逐级递减来消除数据的冗余特征,用降维后的特征完成入侵分类,方法的训练效率较好,但准确率比IDII-DBN算法略低。文献[18]利用多层RBM对高维原始数据进行降维,并利用低维特征完成入侵分类,但参数训练过于耗时。实验结果表明,IDII-DBN的算法在特征量40%时就获得了较高的正确率且稳定性好。
为了验证SMOTE采样方法对入侵分类的效果,对采样后数据和原始数据分别进行对比实验,比较两者在分类准确率上的效果。实验结果表明,采样后的数据分类准确率更高,同时稳定性更好;原始数据的分类准确率较采样后的低,且需要更多的数据。这表明不完备信息处理对入侵检测的分类准确率有很大提升。
3种算法实验的准确率如图4所示。采样数据和原始数据分类准确率如图5所示。
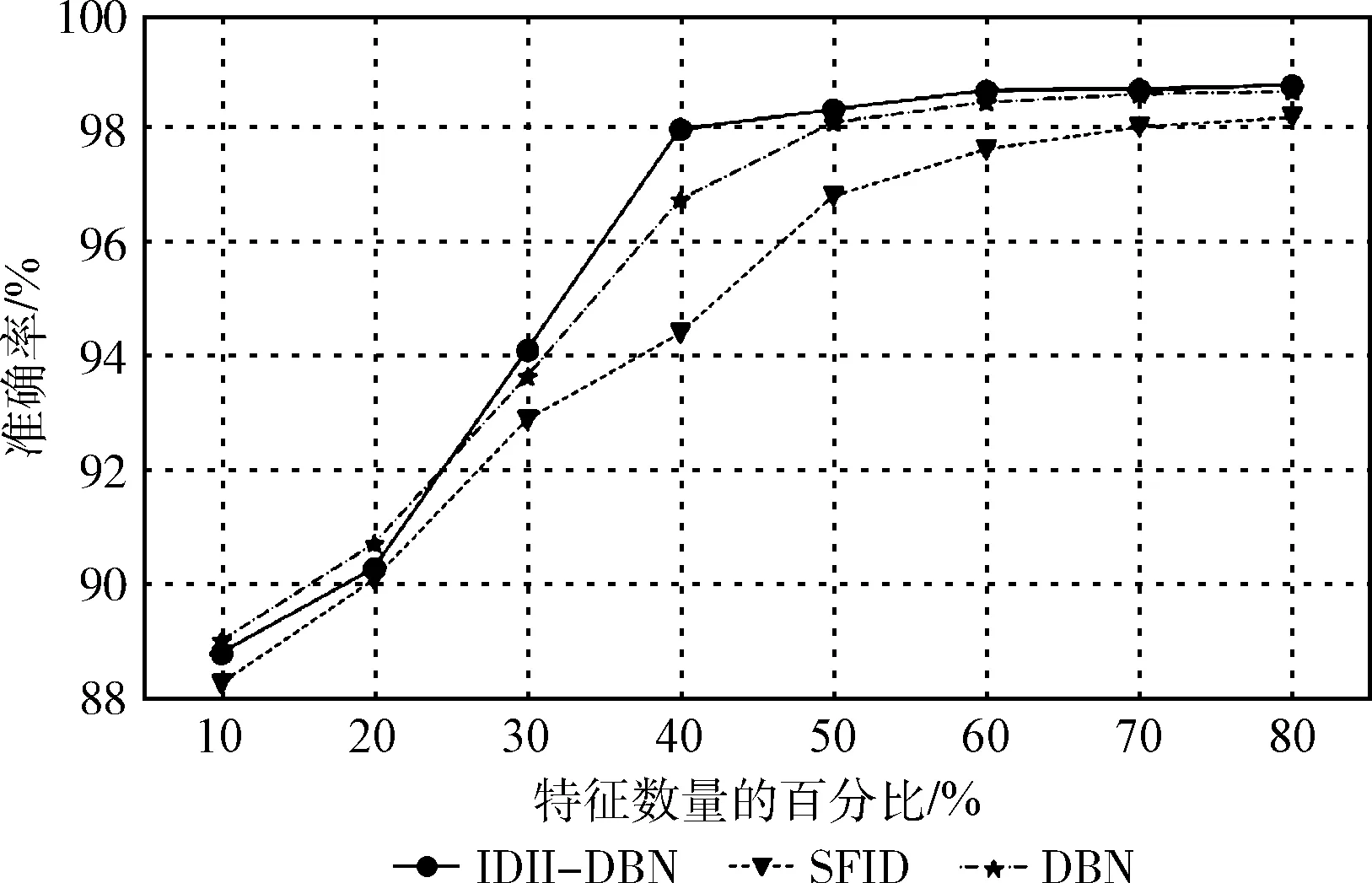
图4 不同特征量下的准确率
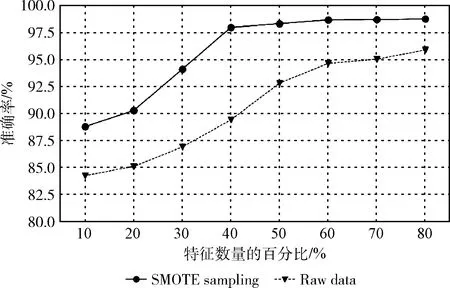
图5 采样数据和原始数据分类准确率
为了解模型对各数据类型的分类准确率,设计了不同特征量下模型对各类别数据的检测对比实验。结果表明,模型对Normal、Dos、Probe这3类数据检测结果较好,在特征量50%时就获得较高的准确率;在特征量较多时U2R、R2L的准确率同样较高。说明IDII-DBN模型对各类别数据的分类均有良好表现。
验证采样效果对各类别数据的分类效果,设计了原始数据在不同特征量下的检测实验。结果表明,原始数据各类别准确率的曲线图和图6相似,但是整体准确率比图7低,U2R、R2L的检测效果难以满足预期。说明模型不完备信息的采样处理优化了对不同数据类型的检测效果。
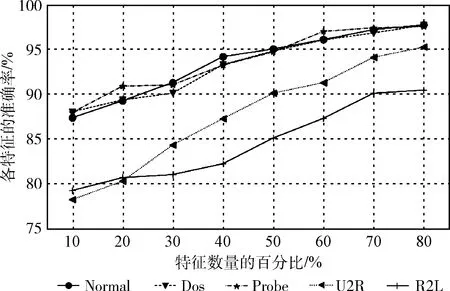
图6 不同数据类型的检测准确率
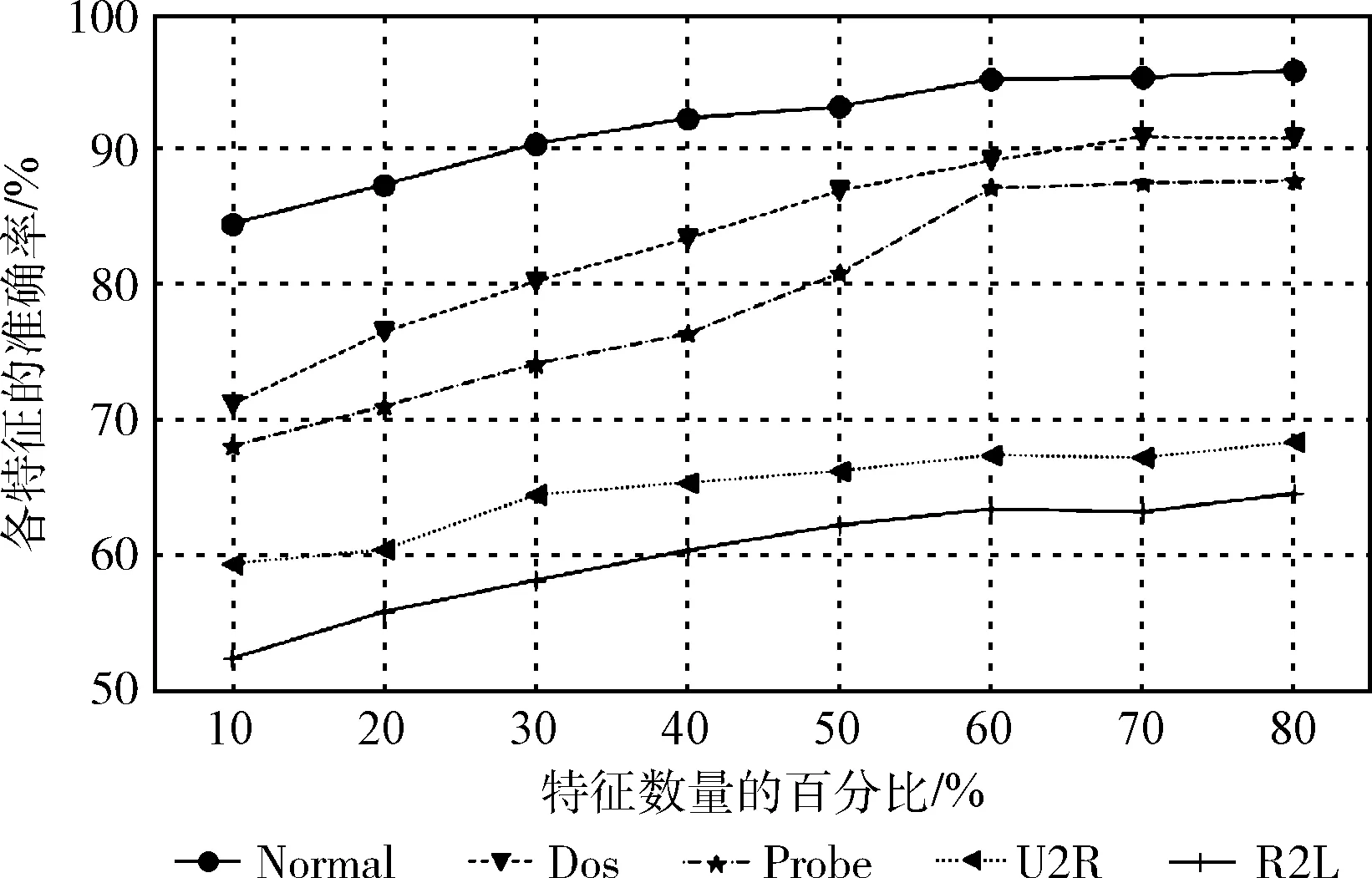
图7 原始数据不同数据类型的检测
不同数据类型的检测效果如图6所示。原始数据不同数据类型的检测如图7所示。
模型采用DBN提取数据特征、实现降维,降低了特征冗余。设计了基于PCA、随机森林(random forest,RF)降维方法的入侵对比实验。结果表明基于RF降维方法的检测效果较平稳,但整体准确率比DBN低;基于PCA降维方法的检测效果在本模型中表现并不好。基于不同降维方法的分类准确率如图8所示。
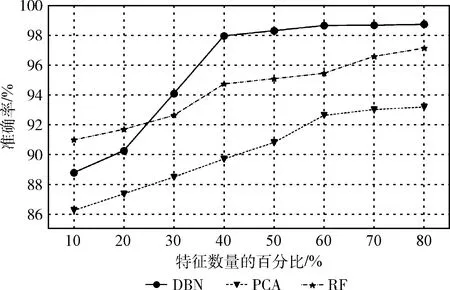
图8 基于不同降维方法的分类准确率
4.2 训练时间
为了验证模型检测的实时性,设计了IDII-DBN、SFID、DBN这3种算法在信息不完备下的训练时间对比实验,IDII-DBN、SFID、DBN在不同特征量下的训练时间对比如图9所示。
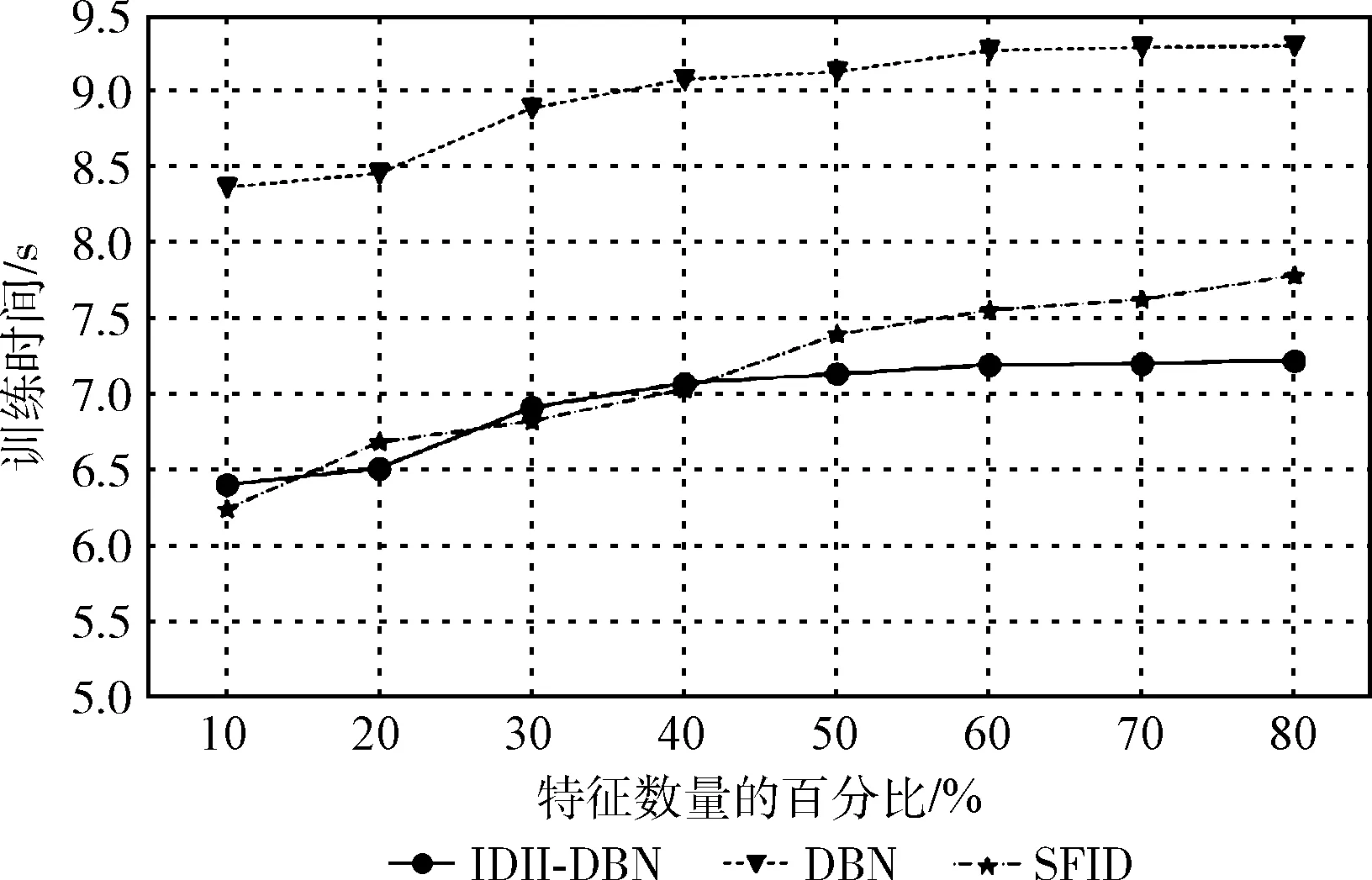
图9 不同特征量的训练时间
结果表明,基于SFID的检测时间在特征量少时较短,是由于数据量少时DBN的降维优势无法充分的体现,但随着数量的增多,IDII-DBN的优势逐渐显现。模型的检测时间没有随着数据量的增加出现较大幅度的波动,体现了训练时间的平稳性,相较之下DBN的整体运行时间略长。随着特征量的变化,IDII-DBN、SFID、DBN这3种算法的运行时间也随之变化,说明特征量对算法的运行时间存在影响。
5 结束语
传统入侵检测方法在信息不完备的情况下,往往基于复杂的神经网络进行参数训练,很难同时满足准确率和实时性的双重要求。本文提出面向不完备信息的网络入侵检测方法。首先,针对信息不完备,对原始数据集使用SMOTE进行采样,实现数据特征稳定下的类别均衡化。其次,基于DBN对数据进行降维,实现原始数据特征的低维映射,获取数据低维特征,以便轻量级检测。最后,将降维后的数据送入SVM,建立逐级分类,精准捕捉入侵特征,实现高效的轻量级入侵检测。实验结果表明,IDII-DBN模型的检测准确率较对比算法稳定,同时缩短了训练时间。表明了该方法具有可推广性,能够满足网络入侵检测实时性的需求。
