基于众源影像的三维重建方法
2022-05-19王志明刘丹
王志明, 刘丹
(东华理工大学测绘工程学院, 南昌 330013)
随着中国城市化建设的日新月异,城镇化进程日益加速,国家建设、城市管理、交通、旅游等众多领域都在积极响应的数字化、智能化的号召[1-2],而其中,作为三维空间数据的三维模型占据着重要地位。众源影像具有来源范围广,信息量大,数据形式丰富,数据获取门槛低等特点[3],已成为三维重建的一种重要数据源。研究基于众源影像的三维重建在摄影测量与遥感等领域,具有重要的理论和实际意义。
20世纪90年代至今,基于影像数据进行三维重建的方法数见不鲜。Schindler等[4]利用线特征来进行匹配以及重建,但是线特征比较稀疏,导致几何结构不够稳定的问题。Xiao等[5]和Sudipta等[6]从配准后的多张影像中利用灭点计算提取出主方向,这些方法能得到较好的建筑物模型,但是需要大量的人工交互,难以应用于大规模的建筑物建模工作。Irschara等[7]提出了一种增量式的大规模街景建模方法。王伟等[8]提出了一种快速交互式三维场景算法,能够快速重建出多种复杂曲面的场景结构,如各种球面、柱面等结构。Hao等[9]提出了一种从三维点云重建城市建筑几何的综合策略,根据窗户的排列规律,通过分析窗户的相似性和重复性设计一种模板匹配的方法来恢复建筑立面的结构。Alidoost等[10]提出了一种基于深度学习的方法,用于从航拍图像中获取建筑物特征点,从而进行重建工作。陈占军等[11]运用图像特征提取与匹配、相机位置姿态计算与估计、三维点云生成、纹理映射等一整套的方法,完成了古建筑的三维场景重建。Li等[12]开发了一种将多种关系嵌入到程序建模过程中的方法,用于从摄影测量点云生成3D重建建筑物。Sebastian等[13]提出了一种通过求解整数线性优化问题,从具有定向法线的非结构、未过滤的室内点云重建参数化、体积化、多层建筑模型的新方法。孙保燕等[14]兼顾了获取数据的范围与效率,结合了地面拍摄与无人机倾斜摄影测量这两种数据采集方式,提出了一种能够自主融合地摄数据影像与航拍数据影像的三维数字化场景重建方法。袁一等[15]以互联网众源影像数据为数据源,进行三维场景重建,以达到地理定位的目的。王瑞玲等[16]提出了一种基于众源数据的数字化重构思路,针对广武明长城月亮门上已倒塌的场景进行场景重建。这些方法都着重于模型构建的部分,但是众源影像来源广泛,图像质量参差不齐,容易导致生成的模型精度低、噪声大。
基于此,首先采用众源影像需求端与网站服务器交互的方式实现图像获取,然后借助深度学习,实现对搜集到的众源影像进行过滤,最后通过SFM构建三维模型并对比生成的点云模型精度,以改进众源影像数据在构建三维模型时的弊端。
1 研究方法
如图1所示,三维重建流程主要包括:①检索众源影像数据:通过基于网页解析和基于网站API的方法,检索并获取到目标地点、目标建筑物的图片数据集;②筛选图像:通过构建的深度网络模型,对搜集到的图片数据集进行筛选,提取数据集中包含或者包含大部分目标地物的影像;③构建三维模型:采用运动恢复结构方法(structure from motion,SFM)[17],以筛选结果数据集为数据源进行场景重建,得到三维点云模型。

API:application programming interface图1 三维重建流程图Fig. 1 The flow chart of 3D reconstruction
1.1 众源影像的检索
随着网络发展的日新月异,互联网服务端口的开放性也随之逐步提高。目前,获取众源影像的常见渠道有图片分享网站、社交网站和专业摄影网站[18-19]。图片分享网站使用者基数大,影像数量丰富。为获得丰富的众源数据,根据数据源不同,分别采用不同的方法进行检索获取数据。以坐标点为数据源时,采用基于网站API的数据检索方案;而以一幅影像为数据源时,采用基于网页解析的方案。
1.1.1 基于网站API的众源影像检索
在基于网站API的数据检索方法中,选择能提供API服务的网站作为程序抓取的目标服务器,其中包括百度街景地图平台、腾讯街景地图平台等。上述平台都以文本描述的形式开放了API请求的端口,部分第三方源网站还提供了地理信息查找服务,比如指定坐标直接链接目标地区影像的接口以及利用地理范围查询兴趣点(point of interest,POI)数据集的接口[20]。
百度街景数据采集车在采集街景数据时,所设定的采集间距为10 m。因此,论文在采样街景数据时,与采集车的预设参数保持一致,设定为10 m。
人在观察周围事物时的视角约为15°仰角,因此爬取时与其保持一致,设置预设仰角为15°。全景街景影像的尺度范围为360°,在分割时,以45°为一个间隔。以这种方案,在每个采样点上,能够获取8张的影像数据。
百度地图API针对用户,开放了街景爬取的端口。用户在获取街景影像数据时,需要访问网络传输协议下的一个(uniform resource locator,URL)地址,具体参数属性如表1所示。

表1 百度地图API爬取街景图片数据的参数属性Table 1 Parameters for Baidu map to crawl street view images
1.1.2 基于网页解析的众源影像检索
在基于网页解析的数据获取时,针对性到了研究了需要网页解析才能获取影像的网站,包括百度地图相册、百度图库、百度贴吧等[21]。首先,在客户端交互界面提供一定类型的信息关键词,在网站端口中构建模拟搜索结果的URL,并通过唯一标记方法解析出输出界面中包含的每个图像的详细链接;然后转入此链接,深入分析此链接对应源代码所包含的原始影像URL[22]。按照这样的思路,在模拟搜索条件下,遍历输出接口中包含的所有特定链接以获得所有图像。该方法获得的图像数据通常具有更好的相关性和清晰度。
1.2 图像的筛选
深度学习(deep learning)[23]与传统的浅层学习有很大的不同,其突出点不仅在于神经元计算节点的设计建立,还在于多层运算的层次结构。深度学习算法采用针对性的输入层与输出层,不断地进行迭代和优化,生成输入层与输出层的网络联系,得到两者之间的函数框架,以此来进行高难度任务的处理。卷积神经网络(convolutional neural networks,CNN)[24]是深度学习中的一种常用模型,其特点在于针对每个卷积层采用池化的处理,这种处理方式能够深层次得挖掘数据的多尺度特征。因此,卷积神经网络在文本识别、模式定性、图像分类筛选等领域,已经成为常用的模型之一。
基于卷积神经网络和迁移学习的方法[25],采用如图2的VGG-16[26]深度卷积网络模型完成众源影像的筛选。首先通过标准影像数据生成标准数据集,并利用标准数据集采用VGG-16模型进行训练学习,训练成功后得到标准数据集的训练模型,再依据训练模型来剖析众源影像的相关度,将相关度大的影像优先筛选出来。
VGG-16网络将待筛选图像集导入网络,经过卷积层、池化层、全连接层的多层处理、识别和筛选,得到筛选影像集。模型设置输入图像的分辨率为224*224,卷积层的属性参数为64个3*3的卷积核;而池化层是针对卷积后的数据进行池化的,尺寸参数设置为2*2;全连接层共有三层,第3个全连接层参数设置为区分两类影像,分别识别重建对象影像和非重建对象影像。
1.3 三维模型的构建
SFM算法对于相机在获取影像数据时的位置信息并不存在严格要求,仅要求获取的目标物为具有三维的非动态物体即可,在拍摄过程中笼盖目标建筑物,在包含目标建筑物的二维影像中获取特征信息来进行三维场景重建的过程,这种方法也是恢复三维结构时的常用方法之一。
基于SFM方法首先利用筛选得到的众源影像数据,首先通过特征点匹配恢复相机的外方位元素,然后利用摄像机的外方位元素求解特征点的空间三维坐标,从而从获取的图像数据中生成大量的点云,由此得到目标建筑物的三维重建模型。
2 实验结果与分析
2.1 实验数据获取
选取东华理工大学南昌校区的图书馆作为重建对象,如图3所示。
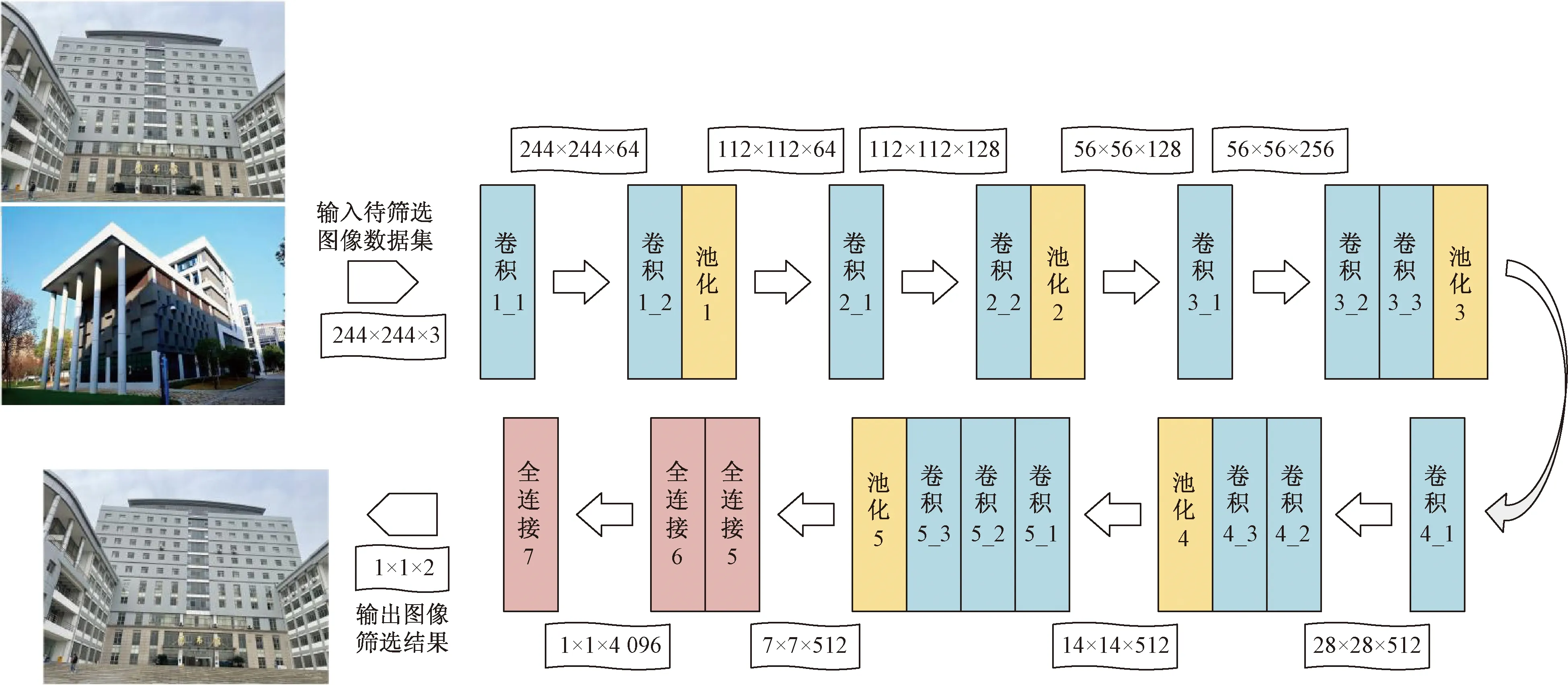
图2 VGG-16卷积网络模型Fig.2 VGG-16 convolutional network

图片来源:百度地图(https://map.baidu.com/search/%E4%B8%9C%E5%8D%8E%E7%90%86%E5%B7%A5%E5%A4%A7%E5%AD%A6%E5%9B%BE%E4%B9%A6%E9%A6%86-a%E6%A0%8B/@12894491.925,3319992.34,20.29z?querytype=s&da_src=shareurl&wd=%B6%AB%BB%AA%C0%ED%B9%A4%B4%F3%D1%A7%CD%BC%CA%E9%B9%DD-A%B6%B0&c=163&src=0&wd2=%C4%CF%B2%FD%CA%D0%C7%E0%C9%BD%BA%FE%C7%F8&pn=0&sug=1&l=12&b=(12867400.55,3285239.29;12928840.55,3345271.29)&from=webmap&biz_forward=%7B);1表示东华理工大学图书馆-A栋图3 研究区域Fig.3 Study area
首先利用基于网站API和基于网页解析的数据检索方案,获取了近300张目标区域的影像(图4),作为三维重建的数据源。但是这些影像中,有部分影像与重建对象图书馆的相关性较小,因此需要进一步对其进行筛选,获取得到高质量的众源影像数据。
此外,为了评价点云模型质量的好坏,论文采用高质量的标准模型进行对比参照。标准模型是在目标地区实地拍摄建筑物图片,并生成标准图片集(图5,图片数量为39张)。由于是有针对性的定点选角度拍摄,获取到的图片集不仅数量少,且精度高质量好。

图4 未经筛选的东华理工大学图书馆众源影像缩略图Fig.4 Unselected crowd-sourced images thumbnails in the library of East China University of Technology

图5 标准图片集缩略图Fig.5 Standard photo gallery thumbnail
2.2 众源影像筛选结果
采用卷积神经网络VGG-16网络模型对上述获取得到的众源影像进行筛选。为验证该模型的有效性,利用K均值聚类算法进行比较。运用VGG-16网络筛选后的东华理工大学图书馆影像数据集如图6所示,经筛选得到了187张影像数据。从筛选得到的数据集来看,与K均值聚类算法相比,利用VGG-16网络筛选结果更为准确,数据集达到了重建的要求。
2.3 基于众源影像的三维重建结果与分析
在实验的整体流程中,仅控制筛选时所采用的两种算法这一变量,筛选时所输入的待筛选数据集、三维重建时所采用的重建算法保持一致。对上述获取得到的标准图像集,由VGG-16网络筛选后的影像数据集以及采用K均值聚类算法筛选后得到的影像数据分别进行三维场景的构建,由此生成的三维模型如图7所示。图7中,标准模型是由上述获取得到的标准图像集通过SFM算法生成的三维模型,点云模型A是由VGG-16网络筛选后的数据集生成的三维模型, 点云模型B则是采用K均值聚类算法筛选得到的图像集生成的三维模型。
为验证方法的有效性,论文对标准模型与重建后的模型的点云数量以及点云之间的距离进行比较。点云数量越接近,点云距离越小,则说明筛选算法越好,重建模型精度越高。分析不同图像筛选算法下筛选后的三维重建的时间和生成建筑物三维点云的数量统计结果(表2)发现,图像筛选算法的不同使得筛选后的图片数量不同,从而影响三维重建的时间和重建点云数量。

图6 经VGG-16网络筛选后的图书馆影像数据集缩略图Fig.6 Thumbnail of Library image data set screened by VGG-16 network

图7 不同筛选算法筛选数据集生成的重建模型Fig.7 Different filtering algorithms filter the reconstruction model generated by the data set

表2 场景重建时间和模型点云数量比较Table 2 Comparison of scene reconstruction time and number of model point clouds
如表2所示,对比重建时间和点云数量,经VGG-16网络筛选过的数据集图片数量较多,模型重建的质量高于K均值聚类算法组(图7)。能够发现,针对同一个待筛选数据集,VGG-16网络算法和K均值聚类算法的筛选结果不同,由于VGG-16网络算法能够过滤出更多相关影像,所以使得建模质量更高。
计算标准模型和点云模型A之间的点云距离,将结果生成距离直方图和距离高斯分布图,用同样的方法处理点云模型B,以此得到模型重建质量评价数据和图表依据,如图8所示。可以看出,无论是高精度点云数量方面、点云的密集程度方面,还是整体点云数量方面,模型A都是超过模型B的,说明模型A的重建效果好于模型B。
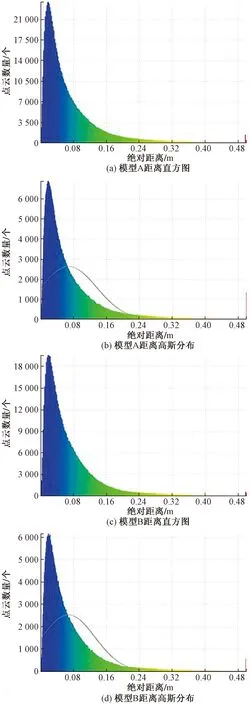
图8 距离直方图和距离高斯分布Fig.8 Range histogram and range Gaussian distribution
计算点云模型A与点云模型B之间的点云距离,生成了点云距离热力图(图9)。可以看出,大楼中部主体部分几乎没有出现热力点云,但是大楼两侧的副楼生成了大量热力点云的情况,则说明大楼中部图片数据集获取程度相近,而两侧部分数据集差异较大,导致了重建效果的不同。

图9 点云距离热力图Fig.9 Point cloud distance heat map
将点云模型A和点云模型B的点云距离进行对比,能够发现,较模型A而言,模型B的重建效果确实不佳,也从侧面反映了由K均值聚类算法筛选得到的图片数据集质量不如运用VGG-16网络筛选的图片集质量。
3 结论
通过基于网站API和基于网页解析的数据检索这两种方案,能够得到数量众多的目标影像数据,实现了众源影像的获取,针对众源数据的获取需求也得到了满足。通过对比构建的模型精度,研究深度学习算法与K均值聚类算法筛选后的数据集生成的点云模型结果,发现K均值聚类算法的缺点明显,体现了深度学习算法对影像数据进行针对性识别的效果更佳,在筛选检索结果的工作中,能够剔除与数据集内相似度不高的影像数据,使得处理后的影像数据保持高度的相关度,使得后期建立的模型精度更高。由此可见,深度学习算法更适用于三维重建。
目前,对于基于众源影像的三维重建来说,已有的图像筛选算法都不具有针对性和专一性,不能很好地过滤大量冗余的影像和低质量的影像,不能够很好地服务于场景的重建。在未来的工作中,笔者将改进已有的图像筛选算法,来提升筛选算法的筛选效率和效果,旨在服务于以众源影像为数据源进行场景的重建工作。
