一种面向电力大数据应用的人工智能模型准确度提升方法研究*
2022-05-17靳丹周建宏陈佐虎李宁
靳丹 周建宏 陈佐虎 李宁
国网甘肃省电力公司 甘肃 兰州 730030
1 背景
在音频﹑视频﹑文本识别应用领域,基于深度学习的人工智能技术已经成为工程界的主流[1],如何提升模型准确度是一个不可避免的工程问题。以图像识别为例,针对深度学习技术路线而言,提升图像识别准确率主要有以下几种办法:
1.1 足够多的样本数据
这是最简单也最可靠的解决办法,深度学习模型的准确程度主要取决于样本数据。增加验证准确性的最简单方法就是添加更多数据。除增加原始样本外,一般可以通过图像增强或者生成对抗网络补充样本。
1.2 改进模型和训练强度
向模型中添加更多层可以增强它更深入地学习数据集特性的能力,因此它将能够识别出细微差异。增加训练轮次也可以提升模型准确度,但当训练轮次增加到一定程度后,模型准确度提升将变得极为缓慢甚至可能降低。
1.3 迁移学习和调参优化
使用预训练的模型,并进行参数调谐。
现有人工智能模型的准确度以及样本获取需要通过技术人员主动去发现,这不属于自动化的工业方式。因而,本文提出一种模型准确度提升方法,自动捕捉样本,供后台训练﹑评估用,进而生产出新的模型,进而实现不断改进模型识别准确度的目标。
2 工程需求
对集团企业而言,云端人工智能平台并不能解决所有问题。受限于网络通信条件,许多应用需要采用云边协同方式解决。以最常见办公领域为例。音频识别﹑图像识别﹑OCR识别以及文本识别均得到了广泛应用。典型场景包括会议语音识别﹑话音转文本﹑参会人员识别﹑文件材料OCR读取。集团总部一般通过云中心进行人工智能计算支撑,而分支机构受限于网络条件,通常需要云边协同架构达成目的。
电力行业是数字化信息化较快的领域,随着基层大量的人工智能应用接入,难免会遇到数据处理的反锁问题。特别是在图像﹑音频以及文本识别等融合应用普及后,海量的数据和运算大大增加了成本和云端服务器负荷。在此背景下,新的边缘智能计算技术需求应运而生。
所谓边缘计算,就是把计算前置,更靠近计算场地做实时处理,直接在边缘侧智能分析,只把处理后的结构化数据和少量样本数据上传云。边缘计算设备与云端互动管理设备协同完成应用支撑,极大提升了设备和网络利用率,提高了响应的实时性,对数据的安全性与准确性也有了更近一层的保障。在云边协同模式下,云端一般完成模型训练﹑模型评估﹑模型下发﹑模型版本管理以及样本库管理工作。边缘设备接收云端下发的人工智能模型,利用自身计算能力承担工程计算任务,同时上传处理结果以及某些特定样本数据。
3 方案整体架构
方案面向两级部署应用,逻辑上可分为三个主要部分:①集团-平台侧(云端);②软件/模型/样本分发机制;③边侧应用。
3.1 其中,平台侧功能实现
①针对边侧应用建设样本仓库﹑模型库,管理边侧应用的个性化样本﹑模型;②建立评估标准,从样本中按统计方法选取模型评估集,建立模型评价指标体系;③从集团样本库和边侧样本仓库中按M︰N比例提取样本,训练边侧模型。M﹑N数值按工程需要调整。
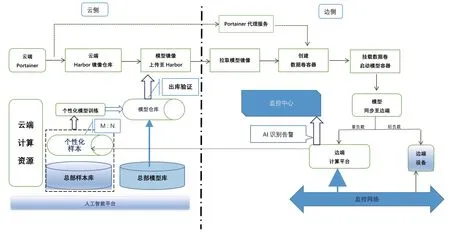
图1 整体部署架构
工作包括[2]:①数据收集:获取什么类型的数据,数据可以通过那些途径获取。常见的数据来源是采集﹑购买或其他方式获取现有数据;②数据理解:获取到原始数据之后,分析数据里面有什么内容﹑数据准确性如何,为下一步的预处理做准备;③数据预处理:原始数据可能会有环境影响或者干扰因素,所以为了保证预测的准确性和有效性,需要进行数据增强。常见的比如调整照片亮度﹑对比度﹑锐化等等;④特征提取:将数据里有用的,有典型特征的抽取出来;⑤模型构建:依托常用框架(Tensorflow﹑Pytorch﹑Darknet(yolov4)﹑百度飞桨),使用适当的算法,获取预期准确的值。⑥模型评估:通常对一个模型进行评估的标准有准确率﹑查全率;⑦模型训练:根据模型评估的结果,对模型进行不断的训练甚至是调整,以达到更好的效果;⑧生成可下发的模型:将模型部署﹑应用到边侧实际场景中。
3.2 软件/模型/样本分发机制负责模型分发
所采用DOCKER仓库使用流程如下:①云端搭建Harbor仓库;推理模型镜像上传至Harbor;云端安装Portainer管理工具;②利用Portainer代理将边端注册到云端;③边端定期拉取/更新AI识别模型镜像;④边端创建数据卷容器;⑤挂载数据卷容器,建立模型数据的映射关系,启动推理模型容器;⑥实现AI识别模型同步至边端数据卷容器中,边端启动应用程序容器,挂载含有AI识别模型的数据卷容器,实现AI识别模型同步至应用系统容器中,应用系统便可实现AI识别工作。
3.3 边侧模型同步机制
边侧模型同步机制如下:①模型和样本采用Public /subscribe模式;②模型描述依据基准测试集建立指标体系;③样本上传通过数据中台通道。
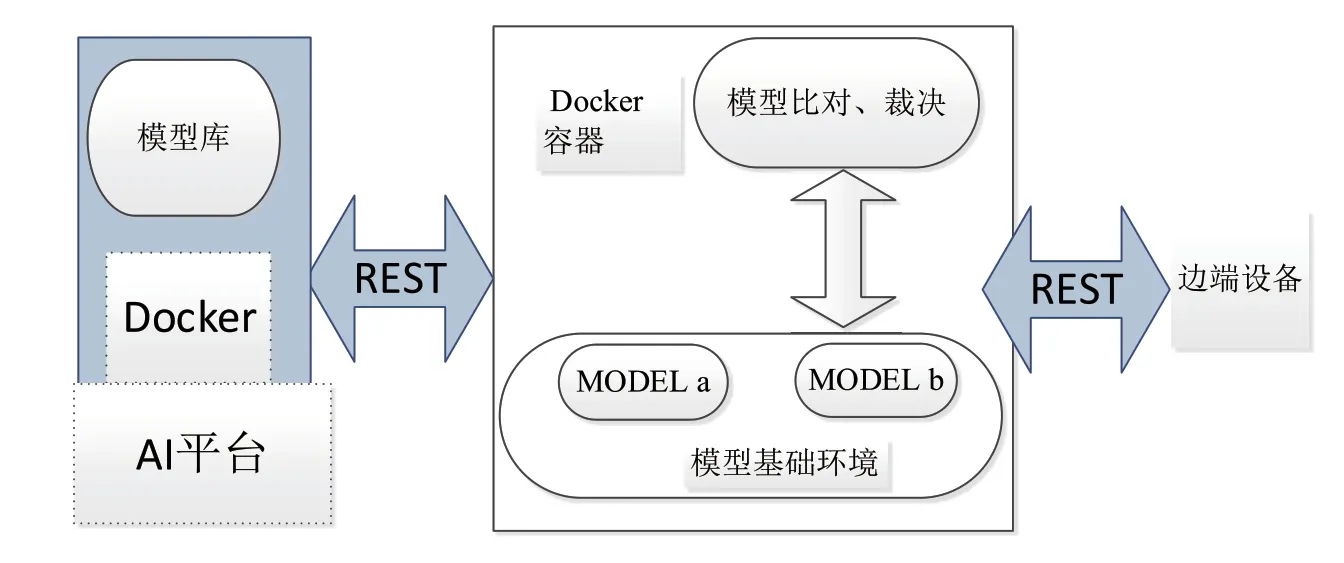
图2 边侧设备部署
4 模型准确度提升方法
该模型准确度提升方法包含以下步骤[3]:①在现有多种开源﹑开放的模型中选取两个作为迁移学习基础模型,并在基础样本集﹑测试集上进行图像识别训练﹑评估,得出精度和召回率;②权衡精度和召回率,使用F1分数作为信度函数

③针对同一目标问题,采用不同样本集训练两个人工智能识别模型,不失一般性,模型a,模型b;④根据模型a,模型b在测试集的表现,即F1(a),F1(b)定义优先级;⑤模型a,模型b均部署在边端设备上;⑥在边端目标识别过程中,当模型a,模型b结果出现差异,将差异图像上传云端人工确认,确认的结果作为模型a,模型b的评价,并累计。同时,将差异图像保存到样本库。⑦当差异信度函数大于阈值设定时,Abs(F1(a)-F1(b))>阈值T,则更新评价分值F1较低的模型。⑧因为只更新一个模型,所以边端设备上的模型始终存在差异,形成更新驱动力。
5 结束语
在某边端实际应用场景中,我们使用了1块FPGA和6块NPU(17Tflops),可以支持128路1080P视频,模型平均更新周期约为2个月。接下来的工作是重点提升边缘设备设备的可靠性。
AI技术相对开放,但入门的门槛也比较高。未来几年内,信创方向有望与AI技术深度融合,率先在业务应用中实现全国产化。因而,以边端识别等轻量级应用为切入点,可以快速积累人工智能应用经验。
