基于隐式描述符的三维模型对应关系计算
2022-05-14HAYTHEMAlhag
HAYTHEM Alhag,杨 军
(兰州交通大学电子与信息工程学院,兰州 730070)
0 概述
三维模型具有显著的几何信息[1],在三维模型研究初期,学者们就利用这些显著的几何信息来进行三维模型分析与处理。现有三维模型对应关系研究是通过基于描述符的方法来完成模型间各部件的准确对应。虽然基于描述符的方法有效利用了丰富的几何信息,但识别特定模型以及对其进行进一步分析仍然需要人工干预,从而导致计算所得到的描述符具有主观片面性,严重依赖于专家经验,泛化能力较差。
现有三维模型对应关系计算方法仅通过几何信息来进行有意义的相似性对应计算,这些算法采用描述符来描述兴趣点周围的局部几何特征,通过距离度量即可以很容易地进行相似度估计。此外,采用更高级别的描述符(如基于主成分分析和曲率分析的描述符)能够同时编码模型的局部属性,然而,仅依据低层次几何线索计算出的对应关系准确率并不理想。
从1987 年开始,机器学习方法就被用来计算三维模型的特征描述符,直到2006 年,深度学习方法开始流行起来,将其应用到数据驱动方法中所得到的特征描述符泛化能力较强,能够推广到不同的任务场景中,而且不需要人工构建特征描述符,具有更好的模型特征表征能力。鉴于深度学习在计算机视觉领域取得的成功,本文提出一种基于深度学习的三维模型对应关系计算方法。具体地,对文献[2]中所提的先验知识表达和应用的方式进行改进,通过将三维模型投影为视图数据并进行预分割来标记相应的模型“部件”,以提高模型的部分对应关系计算性能,然后采用多视图卷积神经网络进行特征提取。在此基础上,计算紧凑的隐含具有较高表面点之间相似性的信息的数据驱动描述符,并利用已构建的数据驱动描述符推导出最终的三维模型对应关系。
1 研究现状
三维模型的部分对应关系计算问题在计算机视觉和计算机图形学领域均具有重要的研究意义。从传统意义上来说,模型间对应关系计算问题是在几何处理的范畴内进行研究的[1],与此密切相关的模型检索[3]、模型识别[4]以及模型分析处理[5]也是如此。现在的主流三维模型对应关系计算方法是基于语义驱动的方法。文献[6]允许模型之间存在明显的形变,但由于它们依赖于几何相似性,因此没有达到语义建模的预期效果,文献[7]也存在相同的问题。
传统三维模型分割方法利用几何特征[8]来识别整体模型的各个部件[9]。此外,利用固有的表面度量或曲率进行聚类的方法也很常见[10]。以上方法主要关注拓扑结构[11],虽然这些方法都能取得令人满意的分割结果,但无法完成模型之间的一致性分割任务[12]。文献[13]解决了一致性分割问题,但没有考虑模型在大尺度变化下语义信息不同的情况。文献[14]在模型的部位处于非均匀拉伸情况下提出一种图像分割方法。文献[15]在未进行数据驱动的情况下提出将先验知识纳入模型分割的方法。文献[16]提出不需要带标签分割的高效的模型对应关系计算方法,其中,对应关系计算不需要从模型的构成部分以及特征值中提取信息。文献[17-18]通过无监督学习的方式完成三维模型的对应关系计算。
本文受到文献[2]研究内容的启发,并作出如下改进:
1)文献[2]通过一致预分割和标记来计算模型的手工特征描述符,相当于在模型表面上分配分割的概率标签,而本文则通过一致预分割和标记相应模型部件的丰富视图特征来计算得到数据驱动描述符,这样可以隐式地将语义标签分配给紧凑的数据驱动描述符。
2)文献[2]所提方法采用一种学习的方式来增强算法的特征表示能力,具体地,将训练集中的模型表面进行对应,同时利用分类器来进行学习,为相关模型的表面间的几何类型分配概率标签。上述过程的缺点在于如果目标模型不在训练集中,这些模型间的对应关系计算则无法使用这个学习结果,同时,如果采用的人工描述符泛化能力较差,那么该方法的有效性会进一步降低。因此,本文利用隐式标记的数据驱动描述符来指导算法的几何相似性计算,并通过在一个相对大的数据集中训练本文网络来解决文献[2]方法所存在的问题。由于初始的非刚性对齐是由语义标签引导的,因此即使在同一标签部分之间存在的任意几何变形,计算出的描述符编码也不会受其影响。
3)在文献[2]中,几何相似性在建立三维模型对应关系中起到了重要的作用,只有在建立了模型表面之间的对应关系之后,这些模型的各个部位才会被赋予相应的语义标签。而本文利用深度学习网络模仿人类计算先验知识的过程,以此指导对应关系计算,从而提高三维模型对应关系计算的准确率。此外,在现实世界的场景处理中,研究人员往往会先识别出相关模型,然后再推导其各部分之间的对应关系。受此启发,本文首先采用多视图卷积神经网络完成三维模型分割,接着用分割的部件进行对应关系计算。
2 三维模型对应关系计算
2.1 问题定义
本文目标是计算2 个三维模型之间的有意义的对应关系,如在模型A和B之间,将A模型上的一组表面映射到B模型上的一组相关面,传统的低层次特征描述符首先捕捉2 个模型表面的几何属性和上下文信息,然后使用基于描述符相似性的方法得出最终的对应关系。
2.2 语义信息
低层次的特征描述符存在几何信息不足的问题[1],特别是当涉及的模型发生显著变化时,此时需要在学习网络中模仿人类识别图像的先验知识。与文献[2]方法不同,本文的语义先验知识是从一组预先分割和标记的训练集中得到的,每个模型部分通过一个分类器模型来表征,其中,每个分类器模型捕捉属于同一标签的表面特征。本文使用包含丰富视图特征的视图数据来计算图像分类的先验知识,这些视图数据传递了一致的预分割和标记的相应模型的部件信息,本文将其输入到多视图卷积神经网络中进行特征提取。
本文方法将获取训练阶段和测试阶段的所有特征信息,并对其进行增强,以实现有意义的模型对应关系计算。此外,本文在训练阶段和测试阶段采用不同的数据处理方式:
1)在训练阶段,本文采用的数据是一致的预分割和标记的以三角网格或点云表示的三维模型,将这些数据输入到多视图卷积神经网络以提取视图特征,这些视图数据既传递了语义类别信息,也传递了几何结构信息,本文方法使用其中的语义标签来指导训练集模型之间的初始对应关系计算,然后将相应模型部分的视图输入到深度学习架构中,并采用孪生网络进行训练。但是,如果这个过程发生大尺度形变时,会丢失大量几何信息,因此,本文采用非刚性配准进行辅助计算,从而提高对应关系计算的准确率。
2)在测试阶段,本文采用2 个以三角网格或点云表示的模型。为了进行准确的对应关系计算,本文使用文献[17,19]中的2 个识别架构和1 个融合层,其中,融合层用来决定2 个输入模型是否属于同一类别。从本质上来讲,本文方法构建了基于深度学习的三维模型对应关系计算网络架构,通过训练可以识别语义相关的模型部件,从而避免了人工设计三维模型特征描述符的弊端。
在整体网络结构上,本文方法结合了文献[20-21]的网络架构:首先对文献[20]中的多视图卷积神经网络架构进行改进,利用它来提取更具鉴别力的特征,使得最终的三维模型对应关系计算结果更准确且平滑;然后优化文献[21]中计算通用描述符的架构,使其计算出最适合三维模型对应关系计算的描述符。
2.3 描述符计算网络架构
文献[21]中通用描述符的计算网络架构是建立在经过预训练的CNN 上的,这些CNN 在二维图像处理领域取得了较大成果。本文对该架构进行优化,如图1 所示。首先,利用ShapeNetCorel[22]和文献[2]中的数据集模型进行一致预分割和标记,并使用标签来指导和初始化非刚性对齐;然后,将表达语义和几何信息的对应点传递给卷积神经网络进行特征提取。使用照相机对三维模型进行多方位拍照,以得到三维模型的渲染视图信息,具体地,使用Phong 照相机和单一方向光从每个选定的视点渲染三维模型表面。此外,含有冗余图像的渲染视图将被进一步修剪,在选定的观察方向上调用K-mediods聚类算法来实现修剪,K设置为3。通过将视点M设置为3 来获取每个表面点的多尺度上下文及其选定的观察方向信息,这些视点分别放置在模型的边界球半径为0.25、0.50 和0.75 距离处。对相应模型的部分设定4 次旋转,每个点共产生36 幅图像,所有图像的分辨率为227×227 像素。

图1 用于提取模型对应关系描述符的CNN 架构Fig.1 CNN architecture for extracting model correspondence descriptor
本文网络总体框架与AlexNet[23]类似,但去除了AlexNet 的最后2 个全连接层。每一个输入图像都要经过2 个卷积层、2 个池化层和ReLU 非线性激活函数层的处理,最后是3 个带有ReLU 非线性的卷积层、1 个池化层和1 个全连接层。
每幅图像通过识别架构提取特征得到一个4 096 维的特征描述符。为了产生一个单点特征描述符,本文通过使用最大池化操作来聚合输入的36 个渲染视图中的描述符,该操作选择了各视图中最具鉴别力的特征描述符。
2.4 识别网络架构
文献[20]基于卷积神经网络,采用预训练微调的方法来提高模型的识别准确率,该方法使用2 种摄像机设置用于获得视图数据:第1 种摄像机设置中假设模型是直立,沿中心轴线间隔均匀地放置12 台虚拟摄像机,然后调整到与地面成30°,且每个摄像机朝向网格的形心,这样可以获得12 个视图;第2 种摄影机设置中假设沿着模型的竖直方向,将20 个虚拟摄影机放置在环绕该模型的二十面体的20 个顶点上,使用4 个旋转角度(0°、90°、180°和270°)来创建80 个视图。
如图2 所示,本文的识别网络架构首先使用文献[23]中 的VGG-M 网 络,该网络 由5 个卷积 层conv1,conv2,…,conv5、3 个 全连接层fc6,fc7,fc8以及Softmax 分类层组成。该网络在ImageNet 图像上进行预训练,图像由1 000 个类别组成,然后在训练集中进行微调。网络第1 部分中的所有分支在CNN1中共享参数,并采用1 个视图池化层进行特征聚合得到一维特征描述符。本文通过添加特征融合层来改进网络体系结构,识别网络构架的其余层与文献[20]相同。
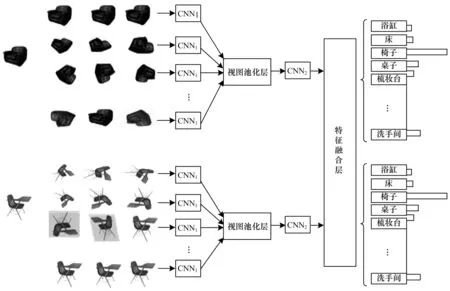
图2 本文识别网络构架Fig.2 The architecture of the recognition network in this paper
在测试阶段,由于本文事先不知道模型间的对应关系,因此通过输入模型的相关性特征值来缩小对模型相应部分的搜索范围。
2.5 模型配准
如图3 所示,本文使用隐式的描述符来完成最终的三维模型对应关系计算。
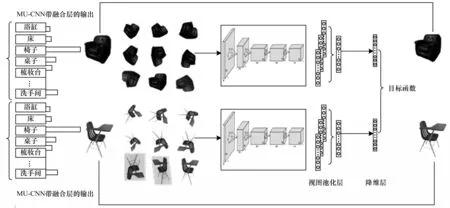
图3 基于隐式标记描述符的对应关系计算过程Fig.3 Process of correspondence calculation based on implicit marked descriptor
给定一对一致分割并标记的模型A和B,首先,本文从其网格表示中抽取10 个点,这些点被分配了相应面的部分标签。对于每个部分,本文为其计算一个初始仿射变换,以使其具有相同的定向边界框,然后对于这些部分的每个点进行一个平移操作,使其尽可能接近所对应的表面,同时相邻点的偏移尽可能保持均匀,确保产生的变形是平滑的。为了计算相邻点的偏移量,本文将表面变形最小化,同时设置正则化项来惩罚2 个部分点集之间的距离以及相邻点之间偏移量的不一致,如式(1)所示:

其中:N(a)和N(b)分别是a点和b点的邻域(在本文中,每个点使用6 个最近邻点);dist 为计算平移点到另一个点集最接近兼容点的距离的操作;ο()是偏移计算分别是各自模型上的点集。
可以使用基于ICP 的方法来最小化式(1)。首先在2 个部分上给定最接近的一对对应点;然后通过最小化式(1)来计算偏移量,更新最接近的点对,通过迭代执行上述过程来计算最终的结果;最后求得的偏移量可用于计算A和B间的密集对应关系。
2.6 网络训练
通过最小化损失函数[24]来估计描述符计算网络的参数。损失函数对描述符差异较大的对应点进行惩罚,以防止参数值任意变大。该损失函数的计算公式如下:
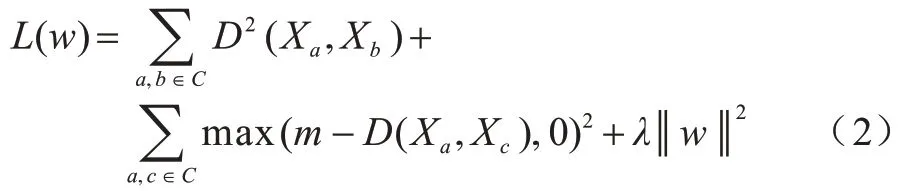
其中:C是从基于部分的配准过程中得出的一组相应的点对;D是测量一对输入描述符之间欧几里得距离的操作。正则化参数被称为权重衰减,其值设置为0.000 5,余量m设置为1,其绝对值不影响参数的学习,仅缩放距离,以使非对应点对至少留有一个单位距离的余量。
卷积层的参数是在ImageNet[25]数据集上初始化得到的。由于图像包含模型以及纹理信息,因此在大量图像数据集上训练的卷积核可以捕获模型信息。本文采用批量梯度下降法使损失函数最小化。在每次迭代中,随机选择32 对相应的点,并且预先对其进行基于部分的配准计算。另外,选择32 对非对应点,使总批次为64。实验采用Adam 优化算法在每次迭代中更新模型参数,与其他算法相比,Adam具有更快的收敛速度。
3 实验与结果分析
将本文方法与文献[2,26]方法进行实验对比,通过定性和定量对比来验证本文方法在计算准确率以及所生成的对应关系结果质量上的优越性,其中,文献[26]方法是目前最新的非等距模型间对应关系计算方法。实验的软件及开发环境配置如下:Ubuntu 16.04,RTX 2080TI,CUDA 9.0,cuDNN 7.0,Caffe 深度学习框架。
3.1 数据集
本文实验使用3 个数据集,所有数据集均已预先进行了分段和标注,同时对应关系的ground-truth都为已知。第1 个数据集采用文献[2]中的数据集,由四类人造模型组成,具有明显的几何拓扑变化,同时某些形状在同一模型上重复出现多次;第2 个数据集由网格分割基准[27]中选定的数据集组成,本文使用文献[16]中的方法为这些模型创建分割的标签,数据集选择了具有不同姿势和较大结构与几何变化的模型;第3 个数据集使用源自三维模型库的BHCP 和ShapeNetCore[22]数据集。
3.2 结果分析
图4 所示为本文方法对应关系计算可视化结果。从图4 可以看出,本文方法的对应关系计算结果非常平滑,质量较高。

图4 本文方法的对应关系计算结果Fig.4 The calculation results of the correspondence of the method in this paper
模型对应关系计算结果的准确率一般采用测地误差(Geodesic Error)来度量,即目标模型上的点与真实对应点(Ground-truth Correspondence)之间的测地距离与目标模型表面积之比。假定点x为源模型X上的一点,目标模型Y上存在与点x对应的点y,(x,y*)为标记的真实对应关系,则定义测地误差gerr(x)为:

其中:dy(y,y*)为目标模型上的点y与标记的点y*之间的测地距离;area(Y)为目标模型的表面积。测地误差越小,表明对应关系计算结果准确率越高。
表1 所示为本文方法和文献[2,26]方法的对应关系测地误差对比,最优结果加粗表示。从表1 可知,与文献[2,26]方法相比,本文方法的对应关系计算测地误差均有所降低,在各个类别中可以获得更为准确的对应关系结果。

表1 各方法的测地误差对比Table 1 Comparison of geodesic errors of various methods
文献[2]方法是以预分割标注形状部分的形式传授先验知识,本文也以预分割标注形状部分的形式使用先验知识,将本文方法与文献[2]方法获得的结果进行对比,在每一个类别的计算中,本文方法的测地误差都有所降低,其中,在Vase 这一类别中误差降幅最大,达到0.155,在Οctopus 这一类别中误差降幅最小,也有0.041,这是由于不同形状的三角网格质量不同,有些形状边界画得更准确,结果会较好,而有些形状边界不清晰,结果会较差。
相较文献[26]方法,本文方法在所有类别上表现均更好,在Lamp 这一类别中,本文方法误差降幅最大,达到0.059,在Airplane 这一类别中,本文方法误差降幅最小,达到0.004。
4 结束语
本文提出一种基于隐式描述符来计算三维模型对应关系的方法。该方法首先在多个尺度上获取形状区域的多个渲染视图,然后通过多视图卷积神经网络对其进行特征提取以计算局部形状描述符,最后对模型中的相应形状部分进行非刚性对齐,进而获得准确的对应关系计算结果。实验结果验证了该方法的有效性。但是本文研究仍存在下列不足:用于识别输入模型的多视图卷积神经网络存在视图信息冗余的问题;最初为训练集计算的对应关系结果不如人工标注的结果理想;对三维模型进行多方位投影时丢失了其几何拓扑信息。解决上述问题并提高本文方法的适用性将是下一步的研究方向。
