面向5G MEC 基于行为的用户异常检测方案
2022-05-14张伟成卫红权刘树新王庚润
张伟成,卫红权,刘树新,王庚润
(战略支援部队信息工程大学国家数字交换系统工程技术研究中心,郑州 450001)
0 概述
在万物互联时代,人与物、物与物之间的信息交互更为频繁。物联网、车联网、工业互联网、AR/VR等技术的蓬勃发展,促使智能设备数量和数据量呈指数级增长。Machina Research 报告指出,到2025 年全球智能设备的总数将超过270 亿,根据思科云指数预测,截至2021 年,终端每年产生的数据量将达到847 ZB,集中式的云计算将难以应对指数级增长的设备数量和数据量对用户极致体验的要求。移动边 缘计算(Mobile Edge Computing,MEC)[1-2]通过将云计算能力和IT 服务环境下沉到网络边缘,就近向用户提供服务,能有效弥补云计算的不足。
移动边缘计算具有丰富的应用场景,如企业园区专网应用、车联网等,这在带来便利的同时也面临更多的安全挑战[3-4]。一方面是用户侧带来的威胁。边缘侧的MEC 节点汇聚着周边用户的敏感信息,恶意用户能够利用边缘节点进行横向或纵向攻击[5]。Haystax 于2019 年发布的网络内部安全威胁报告[6]指出,内部恶意用户是造成数据泄露的第二大原因。恶意用户可以分为两类,一类是非法身份的攻击者,另一类是合法身份的攻击者,而最具破坏性的是合法身份的攻击者。合法身份的攻击者通常具备内部权限,了解敏感数据的存放位置。攻击者冒用合法用户的身份以及合法用户有意或无意的恶意行为都将对MEC 安全防护提出巨大的挑战。另一方面是MEC 资源受限等特性带来的挑战。MEC 节点呈资源约束性、分布式等特性,使MEC 难以承载云计算中的防护配置[7]。因此,对MEC 场景内用户异常进行轻量级监测,对保护MEC 安全至关重要。
将机器学习及其子领域深度学习应用于对异常用户的检测,是当前的主流选择[8]。但MEC 场景下的异常检测面临着诸多挑战,存在正负样本严重不均衡、样本特征位置异常、不能满足大数据量和复杂模型的训练[9]等问题。
本文针对5G MEC 架构,提出一种基于行为的用户异常检测方案。将云数据中心的计算任务卸载到用户侧和边缘侧,在用户侧进行数据预处理,在边缘侧进行模型训练,并在边缘侧选择轻量级机器学习算法,缓解云数据中心计算压力。同时,避免使用存在缺陷的公开数据集,而是选用真实的用户行为数据进行训练,保证所设计方案的可行性。针对样本不均衡、异常样本特征未知的问题,在对特定用户的异常检测过程中采用无监督的单分类机器学习算法,从而确保检测方案的安全性。
1 相关工作
异常检测是检测数据是否符合预期行为的过程[10]。异常可以被定义为不符合预期的行为模式,直接异常检测方法是定义一个表示正常行为的区域,将任何观察到的不属于这个区域的行为都认为是异常行为,如同“白名单机制”。此机制存在以下不足:1)正常行为和异常行为的边界不精确,难以划定正常的区域;2)一些狡猾的恶意行为通过伪装可以被观察为正常值。间接异常检测方法如同“黑名单”机制,是通过定义一个表示异常行为的区域,核心思想是穷举现有的异常行为,不足是难以检查未知的异常行为。而基于机器学习的异常检测有别于“查黑”“查白”的防护体系,而是通过“查行为”的方式,以大数据为基础,以机器学习、人工智能的分析为核心,通过建立正常行为基线对超出基线的行为进行告警,可以抽象为机器学习领域中的分类问题。
文献[11]将判别受限玻尔兹曼机(Discriminative Restricted Boltzmann Machine,DRBM)技术应用于用户异常检测,使用公开的网络流量数据进行训练,并针对实际的数据进行测试,数据特征主要以数据包的大小、类型、数据包之间的时间间隔、源IP 地址及端口、目的IP 地址及端口等数据包的外部属性为主。但此模型的训练过程计算消耗较大,不适用于资源受限的边缘设备。
文献[12]提出一种混合机器学习方法以检测内部威胁,该方案先使用多状态长短时记忆网络(Multi State Long Short Term Memory,MSLSTM)对每个用户行为动作序列进行编码,再将固定大小的特征矩阵作为卷积神经网络(Convolution Neural Network,CNN)的输入进行内部威胁检测,从而判断特定用户的特定操作是否异常。
文献[13]提供了一种可以直接部署在资源受限设备上的异常检测方案,该方案使用公开的流量数据(包含已经标记的恶意流量)作为异常检测的数据集,利用机器学习中的支持向量机(Support Vector Machine,SVM)进行二分类。实验结果表明,该方案对恶意流量的识别准确率可达98.22%,但要求数据集正负样本有标签且样本均衡。
文献[14]所设计的方案能够在边缘设备直接托管和执行,该方案采用孤立森林(isolation Forest,iForest)和局部影响因子(Local Οutlier Factor,LΟF)对正常流量与异常流量进行识别检测,训练数据集为流量数据,其所需训练样本不需要进行标注,能够应对未知的威胁。
文献[15]针对5G 网络用户流量设计了一个可扩展的异常检测框架,该框架采用深度学习技术,从网络流中提取144 个流量特征分两个阶段对用户流量进行检测,第一阶段采用深度神经网络(Deep Neural Network,DNN)进行异常检测,第二阶段采用LSTM 进行异常检测,实现了检测系统的资源消耗优化。所提方法对边缘服务器配置要求较高,需要支持多种深度学习框架、搭载较强的图形处理器(Graphics Processing Unit,GPU)。
文献[16]所提方案由云服务器负责存储数据,由雾节点和MEC 服务器进行模型训练,采用样本选择极限学习机(Sample Selected Extreme Learning Machine,SS-ELM)算法进行异常检测,降低了云数据中心的计算负担,减少了训练时间,提高了训练精度,但方案所使用的KDD Cup 99 数据集不能进行网络入侵检测系统的评估[17]。
文献[18]基于MEC 的方法将核心网的计算任务卸载到边缘侧的MEC 服务器上,以真实的用户呼叫记录为数据驱动,采用前馈深度神经网络算法进行异常检测,克服了高误报率和低准确性的限制,提高了用户服务体验质量。文献[19]在此基础上采用CNN 实现了同样的目标,但不足是将计算任务分配到资源受限的边缘侧进行深度学习算法训练,增加了模型的训练的时间成本。
对上述异常检测方案进行对比,如表1 所示。现有的基于机器学习的异常检测方法,可以分为有监督和无监督两类。有监督的异常检测主要是通过对正常样本和已知的异常样本进行分类训练,是一种二分类或多分类的判别过程,即观察到的异常行为是已知的、训练样本中存在的,此类方法对未知的攻击手段识别度不高。无监督的异常检测以深度学习和单分类为主,训练样本只有正样本或者仅有极少量的负样本,样本没有标签,异常检测过程符合实际网络需求。在计算资源消耗方面,相较于深度学习算法,传统的机器学习算法对计算资源要求较低,基于深度学习的异常检测计算消耗往往较大。与传统的云计算模式相比,采用边缘计算架构的方案能够降低云数据中心的计算压力,提高用户服务体验质量。

表1 异常检测方案对比Table 1 Comparison of anomaly detection schemes
2 面向5G MEC 的用户异常检测方法
本文针对5G MEC 架构中易在用户侧发生的仿冒攻击和内部威胁,提出基于行为的用户异常检测方法。在缓解云数据中心计算压力方面,将云数据中心的计算任务卸载到用户侧和边缘侧,在用户侧进行数据预处理,在边缘侧进行模型训练。基于边缘侧资源有限的特性,在算法选择上避免使用神经网络等需要大量计算资源的深度学习算法,而是以传统的轻量级机器学习算法为主,从而在边缘侧不需要搭载高性能的设备即可完成模型训练。在数据集选择上,避免使用存有缺陷的公开数据集,选用真实的用户行为数据进行训练保证所设计方案的可行性。同时,在对特定用户的异常检测过程中采用无监督的单分类机器学习算法,解决样本不均衡和异常样本特征未知的问题。
2.1 设计思想
将用户产生的行为数据完整地上传到云数据中心进行预处理及模型训练,会加重云数据中心的训练负担,大量数据在上传过程中也会产生额外的时间消耗,同时还可能导致用户隐私信息泄露。本文所设计的检测方案在边缘计算框架内实施,数据在本地进行预处理,模型在边缘进行训练,并对用户进行异常检测。
对用户进行异常检测的流程如图1 所示,分为以下两个阶段:

图1 用户异常检测流程Fig.1 Procedure of user anomaly detection
第一阶段为用户一致性检验阶段,主要对已知用户的身份进行一致性检测。通过将园区内全部合法用户的历史行为数据训练为一个多分类器,然后利用多分类器对进入园区的用户进行有监督的分类识别,识别正常且一致的为正常合法用户,识别不出或者识别结果不一致的为异常用户,其中模型可以根据用户量的大小由部署在园区的边缘服务器进行单独训练或者分布式联合训练,也可由云数据中心进行训练。本文采用在边缘服务器上训练的方式,依据历史数据对已知用户的身份进行一致性检验。
第二阶段为异常检测阶段,主要针对单个合法用户进行异常监测,监测用户可能产生的异于常态的行为。此过程由部署在园区内的边缘服务器执行,主要是通过一个单分类算法对每一个合法用户的行为数据进行训练,每个用户分别训练一个检测模型,用户新产生的行为数据通过检测模型进行异常检测,以判断合法用户是否存在异于常态的行为。
2.2 用户行为建模
除网络流量特征之外,终端用户的各种活动也能表征每一个用户,例如用户位置信息、应用程序使用记录、用户运动轨迹、电池电量的变化率等。由于应用程序已经成为理解人类行为动态和影响力的重要媒介,本文对用户使用应用程序产生的记录进行行为建模,从而对用户进行异常检测。用户的行为模型如下:

异常的行为主要从3 个维度进行表述:

2.3 检测流程
基于图1 所示的用户异常检测流程,第一阶段(用户一致性检验)和第二阶段(用户异常检测)的详细流程如图2 所示。

图2 用户异常检测详细流程Fig.2 Detailed procedure of user anomaly detection
2.3.1 数据预处理和特征选择
在机器学习中,多数算法只能处理数值型数据,不能处理文字、字符串等数据。为了让数据适应算法需要对数据进行编码的要求,即转换数据类型为数值型,本文采用独热编码(Οne-Hot)对用户的行为记录进行编码。独热编码主要是采用N位状态寄存器来对N个状态进行编码,每个状态都有独立的寄存器,并且在任意时候只有一位有效。独热编码是分类变量作为二进制向量的表示。
由于MEC 场景的轻量级限制,特征维度较大的数据在边缘侧进行训练会加重边缘侧的计算负担,因此需要对独热编码产生的行为特征数据进行特征选择,在不引起重要信息丢失的前提下去除无关特征和冗余特征。本文主要采用互信息(Mutual Information,MI)法进行特征选择。MI 是测量两个特征之间相互依赖关系的一种特征选择方法,可以过滤无关的特征以降低数据的维度,从而降低运算开销,提高训练速度。
2.3.2 用户一致性检验阶段
如图3 所示,用户一致性检验阶段主要是对园区内用户身份的合法性进行检测。本文采用机器学 习[20]中的极 限梯度提升(eXtreme Gradient Boosting,XGBoost)算法对用户合法身份进行检测。XGBoost 是一种提升树模型算法,其将许多树模型集成在一起形成一个很强的分类器,能够比其他使用梯度提升的集成算法更加快速,并且已经被认为是在分类和回归上都拥有超高性能的先进评估器。通过采用XGBoost 算法对园区内所有合法用户进行模型训练,形成一个多分类器,然后对带有身份标签的用户进行分类区别:若无法识别出用户的身份,则表明此用户非园区内合法用户;若识别出用户身份但与用户的身份标签不一致,则表明合法用户之间存在权限资源滥用现象;若识别出用户身份但且与用户的身份标签一致,则表明此用户为合法的正常用户。此阶段训练数据集为固定园区内所有合法用户的历史行为记录,属于有监督的训练。

图3 用户一致性检验过程Fig.3 User consistency verification process
2.3.3 单个用户异常检测阶段
本文方法流程的第二阶段为对单个合法用户的异常检测,主要依据单个用户的历史行为记录对当前的行为是否为异常进行判别,由于样本较为单一(均为正样本,或仅有少量的负样本),因此此阶段主要采用单分类算法中的(Οne-Class Classification,ΟCC)孤立森林(iForest)算法进行模型训练。单分类[21]是多分类算法中的一种特殊情况,其中在训练期间观察到的数据主要来自正类。单分类方法广泛用于异常图像检测和异常事件检测等领域,而孤立森林[22]是常见的用于挖掘异常数据的单分类算法,通常用于网络安全中的攻击检测和流量异常等分析。iForest 算法主要针对用户行为数据特征中容易被孤立的离群点进行检测、评分、标注。此阶段通过iForest 算法建立训练模型后,从用户行为数据的时间维度、空间维度、时间-空间维度产生特征的疏离程度进行自动评分,评分结果为负值的标记为异常用户行为,反之,则为正常。实验过程也可设定阈值对模型判别结果进行干预。
3 实验分析与仿真结果
3.1 数据集
当前智能终端已经成为人们生活中必不可少的一部分,各类应用程序如影音娱乐、出行导航、金融理财、社交通信等丰富着人们的日常生活。借肋搭载在智能终端上的应用程序,可以对用户进行辨别,并以此对特定用户的日常行为是否异常进行分析判断。本文所使用的数据集是由麻省理工学院人类动力学实验室发布的真实的用户数据集[23]。该数据集记录了130 名参与者基于传感器的完整人类行为记录,包括通话记录、应用程序使用记录、GPS 定位记录、Wi-Fi 接入点、短信息记录、电池使用情况记录等数据。
3.2 评价指标
不同的机器学习任务具有不同的评估指标,每个指标的侧重点也不同,混淆矩阵[24]详细描述了分类结果,可用于对分类模型性能进行评估。二分类的混淆矩阵如表2 所示。其中:TP表示正样本被正确分类的数量;FN表示正样本被错误分类的数量;FP表示负样本被错误分类的数量;TN表示负样本被正确分类的数量。
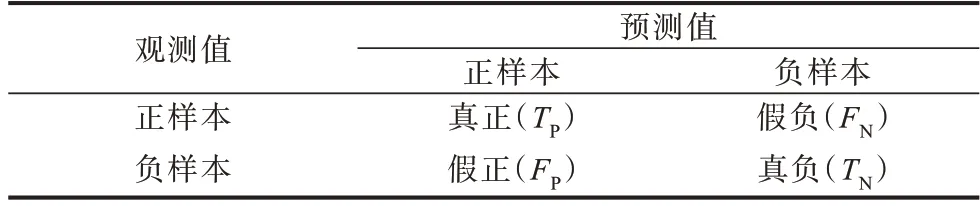
表2 二分类混淆矩阵Table 2 Binary confusion matrix
在网络安全领域,评估模型中常用的指标是精确率、召回率和F1 值[8]。在对内部人员威胁的检测过程中,异常样本占比较小,而本文更关注的是对异常的识别概率,因此,本文主要采用准确率、F1 值、FAR 来对模型进行评估。
准确率为正确分类的样本占全部样本的比例,如式(1)所示:

精确率为正确分类的正样本占分类为正的样本的比例,如式(2)所示:

召回率为正确分类的正样本占实际正样本的比例,如式(3)所示:

F1 值为精确率与召回率的加权调和平均,如式(4)所示:

一般来说,F1 值越高,模型的表现越好。
误报率(FAR)为预测错误的负样本数量占实际负样本数量的百分比,如式(5)所示:

3.3 实验分析
3.3.1 实验环境
本文使用Intel®CoreTMi7-7700 CPU@3.60 GHz,64 GB 内存和安装Window 10 操作系统的电脑模拟边缘服务器,使用kirin 980、8 GB 内存和安装Android 10 操作系统的荣耀手机模拟终端用户设备,使用Python 语言、sklearn 库中的数据预处理与特征选择模块以及XGBoost 模块进行仿真。
3.3.2 实验步骤
本文从数据集中随机选取20 个用户作为小型固定园区P 的合法用户,对20 个用户进行编号,记为P={U1,U2,…,Un},其中,Un代表第n个用户,n为1~20的整数。从数据集中随机选取4 个用户作为恶意用户(不含P 中合法用户),对4 个恶意用户进行编号,记为Hacker={H1,H2,…,Hm},其中,Hm代表第m个恶意用户,m为1~4 的整数。实验数据样本如表3 所示。

表3 实验数据样本Table 3 Samples of experimental data
数据预处理在用户侧执行,以用户U1为例,对U1产生的行为记录采用独热编码进行处理,形成一个包含172 个特征的数据集。在特征选择过程中,计算特征的互信息(MI)值,在172 个特征里有70 个特征的互信息值为0,102 个特征的互信息值大于0,选取102 个与分类相关的特征进行训练。图4 所示为用户U1行为记录在用户侧进行数据预处理时间消耗,横坐标为行为数据的样本数量,纵坐标为处理样本数量所需要的时间,实验结果表明,处理10 000 条行为记录用时仅为0.014 s,能够满足用户侧的计算需求。

图4 U1行为记录数据预处理时间消耗Fig.4 Pre-processing time consumption of U1 behavior records data
用户一致性检验阶段采用XGBoost算法进行多分类,本文用P 内的20 个已知用户的行为数据进行模型训练。测试集Test 由P 中的合法用户与Hacker 中的恶意用户共同组成,由Hacker对P 中的前4 个用户进行对应仿冒,结果如图5 所示。可以看出:U5~U20的单个用户的识别准确率分布在0.9~1.0 之间,整体识别准确率为0.953,表明本文所采用的用户行为模型能够有效区分各个用户;攻击者H1~H4的分类准确率要显著低于U5~U20,表明本文所采用的用户行为模型能够有效区分合法用户与非法用户。

图5 用户一致性检验准确率Fig.5 Accuracy of user consistency test
对单一用户的异常检测在边缘服务器上进行,采用单分类iForest算法进行异常检测。本次实验未考虑用户有新下载应用程序的情况,主要针对用户有相对固定应用程序的使用环境。实验测试集由5 000条数据组成,其中正常的用户行为数据4 500条,异常的用户行为数据500 条,异常数据采用人工注入的方式生成。以用户U1为例,U1产生的混淆矩阵如表4 所示,可计算得到F1 值为0.958,误报率为0.01。

表4 U1产生的混淆矩阵Table 4 Confusion matrix generated by U1
图6 为边缘侧服务器对U1不同样本数据量进行模型训练的时间消耗,结果显示,使用10 万条数据进行训练所需时间仅为6 s,表明所设计方案能够满足资源受限边缘设备的计算要求。

图6 边缘侧模型训练时间消耗Fig.6 Model training time consumption in edge side
3.3.3 检测方案对比
本文采用真实用户所产生的用户应用程序使用记录作为数据驱动,使异常检测过程更贴近实际。对比各个方案的评估指标,如表5 所示。可以看出:综合考虑准确率和F1 值,本文方案表现较优,能够达到与采用网络流量进行异常检测同样的效果,而在FAR 值方面,本文方案要优于其他方案;在模型训练时间消耗方面,本文方案采用传统的轻量机器学习算法,模型训练时间为秒级,优于采用深度学习的方案;同时,本文方案训练样本不需要标注,能够应对未知的异常情况。整体来看,本文方案性能较优且能满足边缘计算场景。

表5 检测性能对比Table 5 Comparison of detection performance
3.3.4 可扩展性、复杂度和安全性分析
对本文方案的可扩展性、复杂度、安全性进行分析,如表6 所示。在可扩展性方面,本文方案第二阶段通过对每一个合法用户训练模型来实施检测,新加入的用户只需单独进行模型训练,并不影响其他用户的检测过程,具有一定的可扩展性;在算法复杂度方面,本文方案采用传统的机器学习算法,模型训练的计算复杂程度要优于采用深度学习的算法;在安全性方面,文献[11-16]方案主要针对的是恶意网络流量所产生的一系列流量相关的攻击,文献[18-19]方案主要应对的是用户所在基站服务区内可能发生的拒绝服务攻击,本文方案针对用户可能产生的内部威胁,能够应对非法用户的仿冒攻击以及合法用户的权限滥用和恶意行为;在应对未知威胁方面,本文方案在异常检测过程中采用单分类算法,能够应对未知的威胁。整体来看,本文方案在可扩展性、复杂度、安全性方面能够满足设计要求且性能较优。

表6 可扩展性、复杂度与安全性对比Table 6 Comparison of scalability,complexity and security
4 结束语
针对边缘计算场景下的内部安全威胁,本文提出一种基于行为的用户异常检测方案。通过用户一致性检验,分析判断固定园区内的用户是否遭受仿冒攻击或者存在权限滥用,从而表征用户之间的差异性。在此基础上,采用单分类算法iForest 进行针对单一用户的异常检测,解决样本单一、异常行为未知这两个问题。本文方案将机器学习技术应用于边缘计算场景,在用户侧进行数据预处理,在边缘侧进行模型训练,其中数据处理采用独热编码的方式进行,同时采用互信息法进行特征选择以降低计算复杂度。实验结果表明,该方案对多用户分类准确率达到0.953,能够准确区分合法用户与非法用户,且对用户异常行为的误报率仅为0.01。同时,其在用户侧进行数据编码处理和在边缘侧进行异常检测时模型的训练耗时能够满足边缘计算场景要求。本文方案的不足之处是对特定用户的异常检测存在局限性,仅验证了部署边缘服务器的小型固定园区。下一步将提升方案的灵活性和可靠性,使其适用于数据量较大的应用场景。
