基于GRU-LSTM 组合模型的云计算资源负载预测研究
2022-05-14贺小伟徐靖杰张博文
贺小伟,徐靖杰,王 宾,吴 昊,张博文
(1.西北大学 网络和数据中心,西安 710127;2.西北大学 信息科学与技术学院,西安 710127)
0 概述
云计算[1]是基于虚拟化技术和网格计算而发展起来的一种新兴计算模式,与网格计算相比,云计算的任务更具复杂性,在这种模式中,应用、数据和IT资源以服务的形式经过网络提供给用户使用,给用户带来诸多方便。近年来,越来越多的公司将应用部署在云端,这使得云数据中心的功耗波动更加剧烈,从而导致云数据中心资源利用率不平衡问题[2]。在负载快速增加时,从分配主机资源到使用主机资源的过程会产生时间延迟,在负载变化后分配资源时服务水平协议(Service Level Agreement,SLA)将遭到破坏。
为了给用户提供高性能的云服务,在云分布式控制系统中进行资源管理非常重要[3],它可以降低云数据中心能耗成本和二氧化碳排放量[4-5]。负载预测技术[6]是对云分布式控制系统进行资源管理的关键技术,其可以在不破坏SLA 和不影响数据中心运行的前提下,通过对云数据中心的历史数据进行分析,以掌握负载数据的变化规律并准确预测下一时期的负载值,从而通过合理地分配云数据中心的资源来提高其资源利用率。
目前,针对时间序列的负载预测大多基于深度学习中的循环神经网络(Recurrent Neural Network,RNN)来进行建模,但是RNN 在预测时间序列时存在梯度消失和梯度爆炸的问题。本文针对负载预测模型中存在的预测精度低、预测时间长的问题,提出一种组合预测模型GRU-LSTM,该模型结合门控循环单元(Gate Recurrent Unit,GRU)预测时间短、长短期记忆(Long-Short Term Memory,LSTM)预测精度高的优点,对云计算资源进行高效预测,从而提高云数据中心的资源利用率。
1 相关工作
对云计算资源负载进行预测是一个典型的时间序列预测问题。目前,针对时间序列的预测方法主要分为基于机器学习的方法和基于深度学习的方法两类。
在基于机器学习的方法中,KHAIRALLA[7]提出一种混合模型,其将自回归移动平均模型(Auto-Regression and Moving Average Model,ARIMA)与支持向量机(Support Vector Machine,SVM)进行组合,然后对金融时间序列进行预测,并与人工神经网络(Artificial Neural Network,ANN)和SVM 进行对比。BI等[8]提出一种小波分解与ARIMA 的混合模型以对未来负荷进行预测,该模型通过SavitzkyGolay 滤波平滑任务时间序列,并通过小波分解将其分解为多个分量,通过小波分解重构它们的预测结果,以估计到达任务数。但是,该模型可以通过使用更好的数据平滑算法来进一步提高其预测精度。LIU[9]利用支持向量回归(Support Vector Regression,SVR)建立0-1 整数规划模型,将工作负载分类问题转化为任务分配问题,并提供在线解决方案。ZHΟNG[10]提出一种基于WSVM 的预测算法,其利用小波分解对输入信号进行分解然后使用SVM 完成预测,最后利用Google 提供的集群公开数据集进行实验验证。GUPTA[11]提出一种基于分数差分的方法来捕捉时间序列数据的长相关性,并在Google 提供的集群公开数据集上进行实验验证,结果表明,与非分数差分的方法相比,分数差分的方法具有更好的预测结果。
在基于深度学习的方法中,ZHANG[12]引入一种深度学习模型,利用规范多元分解来预测云负荷,并使用深度学习模型来学习虚拟机中复杂负载数据的重要特征,最后应用规范多元分解来压缩模型参数以提高训练效率。目前,针对时间序列的预测大多基于RNN 来建模。文献[13]利用RNN 对云计算资源负载进行预测,并使用Google 提供的集群公开数据集进行实验来验证该方法的准确性,RNN 的循环自回归结构能对时间序列进行很好地表示,但它在对时间序列进行预测时存在梯度消失和梯度爆炸的问题。因此,由RNN 衍生出的LSTM 网络被广泛应用于时间序列预测任务。SUDHAKAR[14]将LSTM与RNN 进行组合,以对服务器未来的工作负载进行预测,并与ARIMA 模型进行比较,结果表明,LSTMRNN 模型的预测精度高于ARIMA,同时也验证了组合预测模型的预测精度高于单一预测模型,但由于LSTM 与RNN 都含有较多参数,因此预测时间较长。文献[15]提出一种改进的LSTM 预测模型GSΟLSTM,利用该模型对云主机负载进行预测,并通过实验验证了利用萤火虫智能优化(Glowworm Swarm Οptimization,GSΟ)算法对LSTM 进行优化具有可行性。文献[16]提出一种组合预测模型ARIMALSTM,以对云平台资源进行预测,并利用CRITIC 数据融合对误差值进行预测,实验结果表明,该预测模型的预测精度优于单一预测模型。CHEN[17]对LSTM 采用集成学习的思想,通过丰富模型的输入维度来解决由于缺乏历史数据而无法建模的问题,但是,由于模型的输入维度增加,导致该方法训练时间较长。在使用LSTM 对时间序列进行预测时,增加网络层数也可以取得更好的预测结果。文献[18-19]分别提出Refined LSTM 与Stacked LSTM预测模型(Refined LSTM、Stacked LSTM 均为多层网络结构),对电荷数据进行预测后得出结论,Refined LSTM 与Stacked LSTM 预测精度都优于LSTM。在对时间序列进行预测时,虽然LSTM 在预测精度上优于其他单一预测模型,但是LSTM 参数过多,导致预测时间较长。
作为LSTM 的变体,GRU 在对时间序列进行预测时,由于减少了一个门而使得预测时间变短。GUΟ等[20]提出GRU 和自相关分析相结合的多步预测方法,仿真分析结果表明,所提GRU 预测模型在进行负载预测时预测时间得到优化。对于一些特定的时间序列问题,采用时间卷积网络(Temporal Convolutional Network,TCN)进行建模也可以取得很好的效果。文献[21]利用TCN 对几个真实世界的数据集进行实验,结果表明,TCN 对于点预测和概率预测具有较好的效果,但是对于长时间预测的效果较差。
现有的预测模型通常是单一预测模型,或者是一些基于集成学习的组合预测模型[22]。单一预测模型虽然在预测时间上优于组合预测模型,但预测精度明显低于组合预测模型。而现有的一些组合预测模型预测精度虽然高于单一预测模型,但是预测精度相对也较低且没有考虑预测时间的问题。为提高云平台负载的预测精度和预测效率,本文结合GRU与LSTM 各自的预测优势,提出一种基于GRU 与LSTM 的组合预测模型,以对云平台资源负载进行预测。
2 负载预测模型
2.1 问题描述
本文主要对云计算资源的负载情况进行预测。假设云计算原始资源负载序列值为xt={x1,x2,…,xn},其中,xt为t时刻集群的负载情况。将CPU 利用率和内存(mem)利用率的负载值进行组合后作为新的输入,原因是这2 个指标可以最直接地体现集群在某个时刻的负载情况,也是使用随机森林算法[23]进行特征选择后得分最高的2 个指标。设置步长为k,从原始资源负载序列值xt中选取前k个时刻的数据作为负载预测模型的输入向量z={zn-k,…,zn-2,zn-1},通过负载预测模型训练后得到k+1 时刻集群的负载情况。
云环境中工作负载存在一定的依赖关系,每个时刻的负载情况都和之前时刻的负载情况有着十分密切的联系,当历史值越接近当前时刻t的值,它们之间的关系就越密切。对于模型选择而言,长距离的依赖信息可以提供趋势信息,不能完全忽略掉,为了更好地利用过去的负载数据,需要对历史数据进行有选择地保留和丢弃。LSTM 中的遗忘门可以控制进入当前时刻的历史信息量以及需要被舍弃的信息量。因此,本文模型选择LSTM 以及与LSTM 具有相似网络结构的GRU。
2.2 LSTM
LSTM 作为一种改进的RNN,其继承了RNN 模型的优点,并且利用独特的门结构有效解决了RNN中的梯度爆炸和梯度消失问题,因此,LSTM 可以有效处理长时间序列问题,并已经成功应用于语音识别、图像描述、自然语言处理等领域。相较RNN 和GRU,LSTM 模型的拟合和预测精度总体较高,但是,由于LSTM 参数过多导致其训练过程耗时较长。
LSTM 由多个循环单元组成,通过更新神经元状态信息,使用输入门、输出门、遗忘门来控制历史信息的权重从而存储过去的信息。基于LSTM 的移动云主机t时刻负荷预测模型的单元结构如图1 所示。

图1 LSTM 单元结构Fig.1 Unit structure of LSTM
在图1 中:Ct-1为前一时刻神经元的状态;Yt-1为前一时刻神经元的输出;Zt为当前时刻的输入。
遗忘门决定上一时刻的单元状态Ct-1有多少可以保留到当前时刻Ct,遗忘门的输入包括前一时刻的输出Yt-1和当前时刻的负载Zt,最后通过最左边的激活函数sigmoid 得到ft,计算如式(1)所示:

其中:Wf是遗忘门的权重矩阵;bf表示偏差向量;σ表示激活函数sigmoid;ft表示最后一层神经元被遗忘的概率,取值范围为[0,1],0 表示完全丢弃,1 表示完全保留。
输入门决定Zt中哪些新的输入可以存储在神经元中,神经元主要分为it和νt,其计算方法分别如式(3)和式(4)所示:
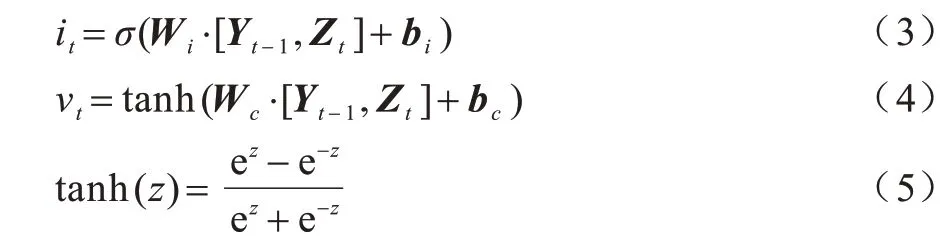
其中:Wi和Wc是输入门的权重矩阵;bi和bc为偏差向量。it和νt表示当前需要保留的负载信息的比例,其与前一时刻保留的神经元状态相加,生成更新后的神经元状态信息Ct,计算方法如式(6)所示:

输出门控制神经元状态的输出并将状态转移到下一个神经元,输出门οt的计算方法如式(7)所示:

其中:Wο为输出门的权重矩阵;bο为偏差向量;Yt为当前时刻神经元的输出。通过最后一层的计算得到最终的负载预测值,如式(8)所示:

2.3 GRU
GRU 作为LSTM 的一种变体,也可以有效地解决RNN 中的梯度爆炸和梯度消失问题。与LSTM相比,GRU 的结构更为简单,其将遗忘门和输入门合并为一个更新门。由于GRU 减少了一个门,矩阵乘法变少,因此当训练数据量很大时可以节省大量的时间,GRU 网络结构如图2 所示。

图2 GRU 网络结构Fig.2 GRU network structure
在图2 中:Zt为当前时刻的输入;Yt-1为上一时刻的输出;Yt为当前时刻的输出。GRU 有2 个门:
1)第一个门为更新门νt,其决定有多少历史信息可以继续传递给未来,即更新门νt决定是否将隐藏状态更新为新状态。从功能上看,GRU 的更新门νt类似于LSTM 的输出门,更新门νt的计算方法如式(9)所示:
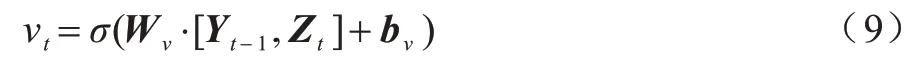
其中:Wν为更新门的权重矩阵;bν为偏差向量。
2)第二个门为重置门rt,其主要功能是确定有多少历史信息不能传递到下一个状态,类似于LSTM中遗忘门和输入门的组合。重置门rt的计算方法如式(10)所示:

其中:Wr为重置门的权重矩阵;br为偏差向量。
计算出更新门νt和重置门rt后,GRU 将计算候选隐藏状态ht。候选隐藏状态ht计算方法如式(11)所示:
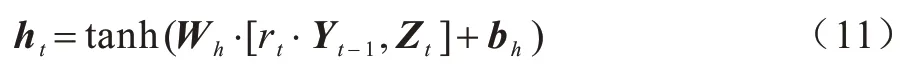
其中:Wh为对应的权重参数;bh为对应的偏差参数。从式(11)可以看出:当重置门rt的值接近0 时,重置门对应的候选隐藏状态值也为0,即丢弃上一时刻的隐藏状态;当重置门rt的值接近1 时,表示保留上一时刻的隐藏状态。因此,重置门的作用是有选择地丢弃与预测无关的历史信息。
最后,t时刻GRU 的输出Yt的计算方法如式(12)所示:

2.4 组合预测模型
综合考虑预测精度和预测时间2 个方面的因素,本文建立一种基于GRU 与LSTM 的组合预测模型,以对云计算资源负载进行预测。组合预测模型网络结构如图3 所示。

图3 组合预测模型网络结构Fig.3 Network structure of combined forecasting model
本文组合预测模型的网络结构包括3 层:第一层网络结构采用GRU,由于GRU 的网络结构简单,参数少,更易收敛,因此在训练数据时GRU 训练速度快,可以减少训练时间,但是,GRU 的预测精度低于LSTM;第二层和第三层网络结构均采用LSTM,LSTM 参数较多,预测精度更高,并且双层LSTM 的预测精度优于单层LSTM。
2.5 模型评价标准
本文采用平均绝对误差(Mean Absolute Error,MAE)、平均绝对值百分比误差(Mean Absolute Percentage Error,MAPE)、均方误差(Mean Squared Error,MSE)、均方根误差(Root Mean Square Error,RMSE)、决定系数(R2)作为模型的性能评估标准。预测时间主要以模型的训练时间作为评价标准。在对模型进行泛化实验时,采用可释方差得分(explanied_variance_score,简写为S)对模型的拟合程度进行评价。各指标的计算方法如下:
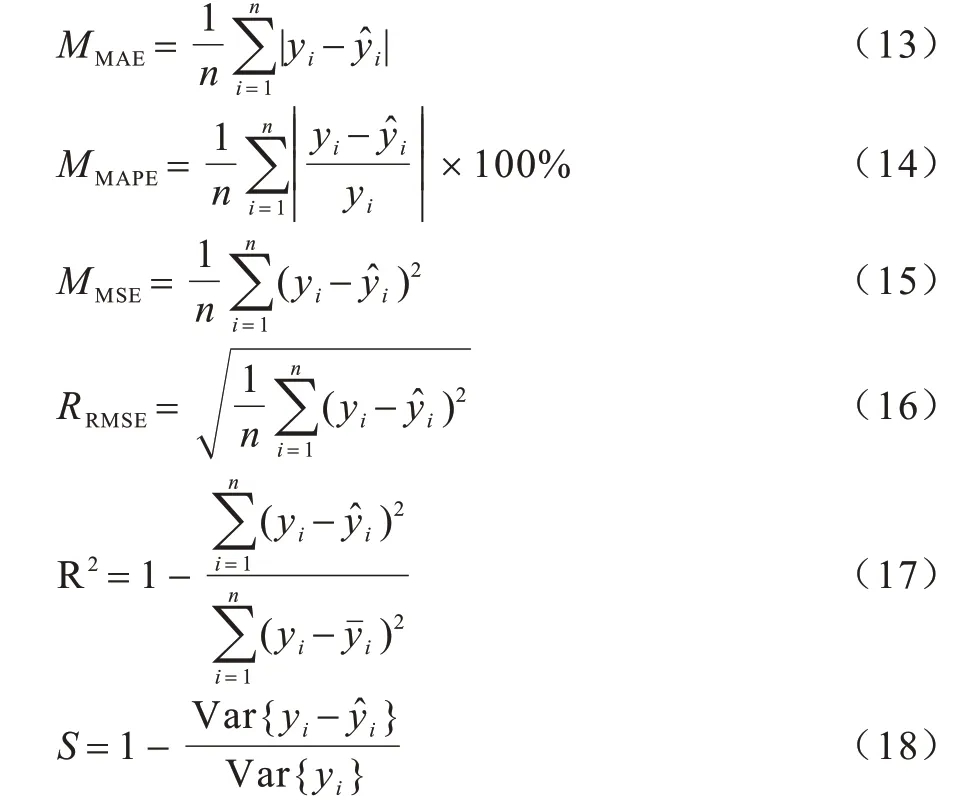
其中:n为负载预测值个数;yi为负载的实际值;为负载的预测值;为负载的平均值。
3 实验结果与分析
3.1 数据来源与处理
为了验证本文负载预测模型的预测性能,使用阿里云2018 年发布的集群公开数据集Cluster-tracev2018[24]进行实 验。Cluster-trace-v2018 包括大 约4 000 台机器在8 天内的资源使用情况,本文实验使用其中1 台机器在8 天内的资源使用情况,共3 300 条数据记录,选取前80%的数据作为训练集,后20%的数据作为测试集。本文对数据集进行如下处理:
1)缺失值处理。利用均值填充法进行缺失值处理。
2)标准化处理[25]。为了提高神经网络的收敛速度、迭代求解速度以及预测精度,采用式(19)(Min-Max 归一化)对训练集的2 600 个数据进行标准化处理:

其中:X*t为归一化处理后的值;Xt为原始数据在t时刻的值;Xmin为原始数据的最小值;Xmax为原始数据的最大值。
3)特征选择。特征选择可以从原始数据特征集中选出若干个具有代表性的特征子集,这不仅可以实现数据降维,还可以提升在该特征子集上所构建的回归模型的性能。随机森林算法通过特征随机置换前后误差分析,计算每个特征的重要性得分,得分越高,特征越重要,与其他特证选择算法相比,随机森林算法不仅能体现特征间的相互作用,而且还具有准确性高、鲁棒性好等优点[26]。因此,本文使用随机森林算法进行特征选择,特征选择结果如图4 所示,横坐标为特征。

图4 特征选择结果Fig.4 Feature selection results
从图4 可以看出,CPU 利用率和mem 利用率是除时间特征之外经过特征选择后得分最高的2 个特征,因此,本文实验选择CPU 利用率和mem 利用率的组合值作为云平台资源的负载值。负载值的计算公式如下:

其中:W为组合后的原始负载值;W1和W2分别代表CPU 负载值和mem 负载值;L1和L2分别代表CPU 和mem 的权重参数。本文根据特征的得分指数比例,设置L1为0.6,L2为0.4。
3.2 实验过程
本文实验是一个单步预测过程,预测流程如图5所示。
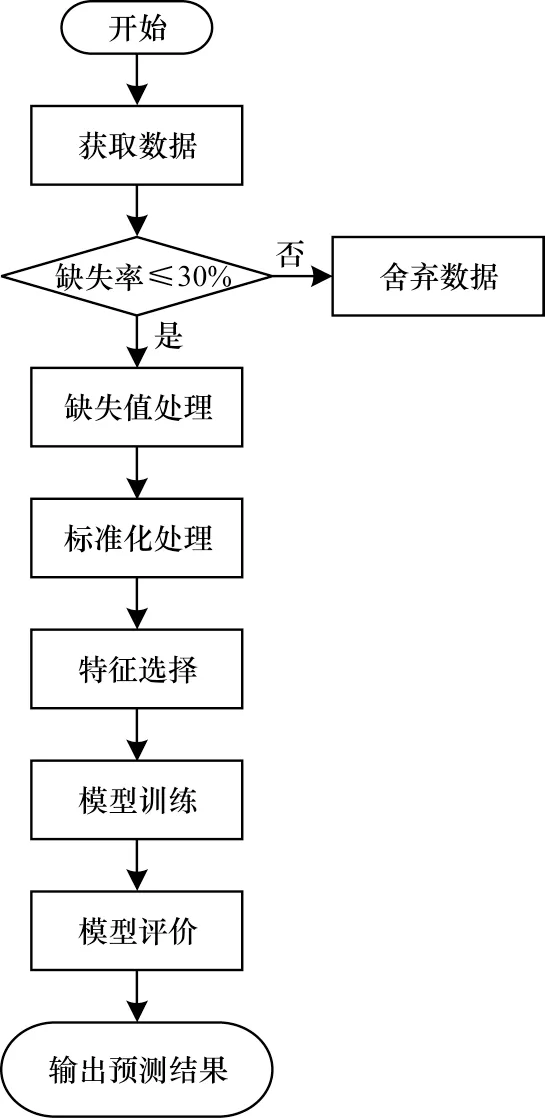
图5 预测流程Fig.5 Procedure of prediction
在获取数据后,首先对原始数据进行缺失值和标准化处理,当原始数据缺失率大于30%时,舍弃该条数据,若缺失率小于等于30%,则使用均值填充法对缺失值进行填充,并将填充后的数据通过归一化方法进行标准化处理,利用随机森林算法对标准化后的数据进行特征选择,根据特征的重要程度将特征选择后得到的特征数据加入权重参数进行组合,将组合后的负载值输入GRU-LSTM 组合预测模型进行训练,设置步长为12(根据前12 个数据来预测第13 个数据)。最后,使用5 个评价标准对模型性能进行评价,同时输出模型预测结果。预测模型参数设置如表1 所示。

表1 参数设置Table 1 Parameters setting
模型预测结果(64 个样本)如图6 所示,从图6 可以看出,本文所提GRU-LSTM 组合预测模型的预测结果与原始序列的趋势基本一致。从图7 可以看出(640 个样本),本文GRU-LSTM 模型经过训练后得到的预测数据与真实数据的误差大多集中在-5.0~5.0 之间,误差较小,因此,该组合预测模型预测精度较高。

图6 GRU-LSTM 模型的预测结果Fig.6 Prediction results of GRU-LSTM model
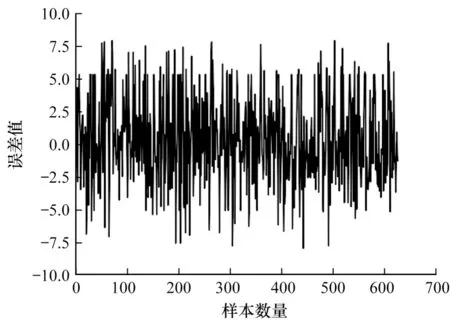
图7 GRU-LSTM 预测误差结果Fig.7 GRU-LSTM prediction error results
3.3 结果分析
将本文模型与传统的单一负载预测模型ARIMA、GRU、LSTM 进行对比,同时还与文献[16]提出的ARIMA-LSTM 组合预测模型、文献[18]提出的Refined LSTM 模型、文献[19]提出的Stacked LSTM模型进行实验对比。各模型的负载预测结果如图8所示(64 个样本),评价指标结果如表2 所示,最优结果加粗表示。

图8 各模型的负载预测结果Fig.8 Load prediction results of each model

表2 各模型的评价指标结果Table 2 Evaluation index results of each model
从图8 和表2 可以看出:相较传统的单一预测模型ARIMA、LSTM 以及GRU,本文GRU-LSTM 模型的预测精度较高,同时也验证了组合预测模型的预测精度要优于单一预测模型;相较组合预测模型ARIMA-LSTM、Refined LSTM 和Stacked LSTM,本文模型的预测精度同样较高。虽然2 层网络结构相比3 层网络结构减少了参数,但是这在一定程度上削弱了模型的学习能力。本文所提GRU-LSTM 模型结合GRU 训练速度快、LSTM 预测性能好的优点,在预测精度和预测时间上取得性能提升。
为了对模型的泛化能力进行验证,设置不同的步长重复进行实验,使用explanied_variance_score 作为评价标准,结果如图9 所示。

图9 不同步长下的可释方差得分结果Fig.9 explanied_variance_score results under different steps
通过图9 可以看出,GRU-LSTM 组合预测模型的可释方差得分介于0.510~0.535 之间,即该组合模型在不同的步长情况下均可以有效地对云计算资源负载值进行预测,其具备一定的泛化能力。
4 结束语
针对目前负载预测模型预测精度低且预测时间长的问题,本文提出一种基于LSTM 与GRU 的组合预测模型GRU-LSTM,以对云计算资源负载情况进行预测。在阿里云平台发布的集群公开数据集上进行实验,结果表明,相较ARIMA、LSTM 等模型,该负载预测模型具有较高的预测精度以及较短的预测时间,同时具有一定的泛化能力,将该模型应用到实际的云平台中,可以解决目前资源利用率不平衡的问题。下一步考虑通过优化算法寻找模型的最优参数,或对数据进行降噪处理,以提升本文模型的预测精度。此外,探索多变量和长时间序列的内在关联性并解决深度神经网络对输入变化不敏感的问题,也是今后的研究方向。
