结合拓扑势与信任度调整的重叠社区发现算法
2022-05-14李晓红王闪闪周学铭
李晓红,王闪闪,周学铭,宿 云
(西北师范大学计算机科学与工程学院,兰州 730070)
0 概述
复杂网络是指具有自组织、自相似、吸引子、小世界、无标度特征中部分或全部性质的网络,如现实生活中的交通网、社交网、基因调控网等。社区是指具有相同或相似特性的节点构成的集合,同一社区内部节点之间链接的概率比不同社区间节点的链接概率高得多,这反映了复杂网络中个体行为的局部特征及其相互之间的关联关系。对于社区发现的研究有助于揭示网络重要结构和功能信息,在过去的几十年中,研究人员设计了大量的社区发现算法,但随着研究的深入发现社区结构还表现出重叠特性,例如社交网络中有一些节点同时归属于不同社区,且这种同时属于多个社区的节点又是信息传播和网络演变中的关键节点。因此,区分稳定的重叠社区并设计高效的发现算法是亟需解决的问题,受到研究人员的广泛关注。
目前,重叠社区发现算法主要包括基于派系过滤、基于局部扩张及优化、基于线图或边社区3 类。基于派系过滤的重叠社区发现算法[1-2]是一种基于网络拓扑结构的社区发现算法,从网络特性出发,认为社区由多个K 派系组成,每个派系都是一个全连通网络,网络中的每一个节点可以划分到不同的K派系中。EVANS[3]提出的Clique Graph 借鉴了派系过滤的思想,通过在网络中建立派系图来研究社区结构。卢志刚等[4]提出一种基于贪婪派系扩张(Greedy Factional Expansion,GFE)的重叠社区发现算法。该算法根据企业社会化网络中极大派系间的链接强度将原始网络图转换成最大派系图,在最大化适应度函数的条件下贪婪扩张最大派系图中的种子派系进行社区发现。但是,基于派系过滤的重叠社区发现算法受限于网络中缺失完全子图,自由参数较多,不同参数设定对结果影响较大,并且经常产生较大的时间复杂度。WEN 等[5]提出一种基于最大团的多目标进化算法(MΟEA)检测重叠社区。该算法用原始图的一组最大团作为节点定义,两个最大团可共享原始图的相同节点。MΟEA 以类似于非重叠社区检测的方式处理重叠社区检测问题。基于局部扩张及优化的重叠社区发现算法通常将种子节点作为初始社区,通过不断优化质量函数扩展社区,最终得出社区划分结果[6-7]。代表算法为局部扩展算法(Local Fitness Method,LFM)[8],LFM 随机选取一个节点进行扩展,通过迭代局部社区得到重叠社区。CHANG 等[9]提出一种新的重叠社区发现算法ENFI,该算法利用网络的微观特征,通过计算朋友亲密度提取本地社区并形成网络的重叠社区。WILDER 等[10]用随机游走算法为每个节点找出一个子图,同时计算出该节点的权重以及正比于权重的概率,并以此判定初始节点,该算法的时间复杂度较高。但是以上算法具有不确定性和向外扩展性,形成的网络模块容易存在不稳定性和漂移性。基于线图或边社区的重叠社区发现算法计算过程复杂,不适用于小规模边社区。AHN 等[11]根据链接网络非重叠与重叠的转化思想,对网络中的链接进行层次聚类提出LINK 算法,该算法揭示了这种边社区在真实网络中的普遍存在性。除了以上3 类重叠社区发现算法之外,研究人员还提出了一些其他的改进算法[12-14],均取得了不错的效果。
本文借鉴物理学势能中的拓扑势思想,提出一种基于拓扑势与信任度调整的重叠社区发现算法。由于网络中的每个节点周围存在一个作用场,场中的任何节点都将受到其他节点的联合作用,因此利用拓扑势选取核心节点,然后从核心节点出发构建初始社区群,并且充分利用社区间的共享边越多社区越相容、节点间频繁的交互和联系促使社区发生融合这两个特性,通过调整信任度进行社区合并与调整。
1 相关工作
假设复杂网络表示为有向图G=(V,Ε,A),其中:顶点集合V={ν1,ν2,…,νi,…,νn},n表示节点数;Ai={ai1,ai2,…,aim}表示节点νi的属性集合,m=|A|表示网络属性数。
1.1 改进的节点拓扑势
在物理学中,场表示物体间的相互作用,这种相互作用并不是接触才有的,势表示特定场中的质点从一点移动到另一点时产生的功。势和场的分布对应物质粒子之间由位置确定的势能分布[15-16],并且这种势能分布与粒子之间的距离成递减关系,随着距离的增长势能下降,直至衰减为0。类比于势场,网络中的每个节点周围存在着一个作用场,位于场中的任何节点都将受到其他节点的联合作用。通过路径描述节点之间的联系,利用路径长度描述节点间相互作用力的强弱。因此,节点间的相互作用与节点属性及节点间的距离密切相关,并且每个节点的影响力会随着节点间路径长度的增长而衰减。采用高斯势函数描述这种相互作用,将复杂网络中节点νi的拓扑势定义为某个范围内其他节点在该节点处产生能量的累加和,如式(1)所示:

其中:Γ(νi)表示节点νi影响某个范围内的节点集合;常数σ∈(0,+∞)用来控制节点的作用范围;d(νi,νj)表示节点νj到节点νi的最短路径长度(i≠j)。
首先,为了突出各个节点固有属性的差异,m(νj)的值由节点属性值决定[17]。假定节点νi的属性值为{wi1,wi2,…,wij,…,wim},则节点νi的属性重要性表示为其次,由于节点在网络中所处的位置及其链接关系存在差异,使得各个节点在网络中具有不同的重要性。为了突出这种差异,引入位置权重wweight(νj),表示距离核心节点越远,位置权重越小。wweight(νj)计算公式如下:

同时,假设式(1)的拓扑势满足规范化条件,则∀νi∈V的拓扑势可重写为:
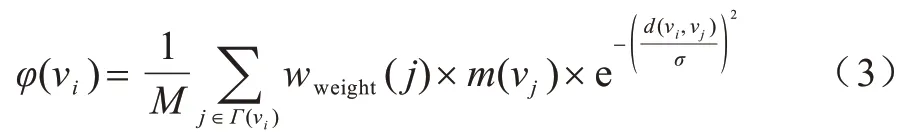
1.2 信任值调整
从网络结构的角度来看,两个节点νi与νj之间拥有的公共邻居越多,它们越相似。扩展至社区,同样地,如果两个社区共享边较多,就意味着社区间重叠的部分越多,社区就越相容。用于比较有限集合之间的相似性与差异性的Jaccard 系数[18]可描述这种结构上的重叠程度。除此之外,网络中的节点不是独立存在的,它们之间具有不同亲疏的交互和联系。社区间的信任解析为彼此所含节点之间的认同,而这种认同实质上是一个互动问题,互动会改变它们之间的关系,使它们发生交叉甚至融合,因此,采用节点间相似度来体现这种互动。综上,本文基于社区间的共享边越多社区越相容及节点间频繁的交互和联系会促使社区发生融合这两个特性判断两个社区能否合并,称此过程为调整信任度。调整信任度的计算公式如下:

其中:λ为调节参数(0<λ<1),用于控制分析社区间共享边数和社区间信任度的占比;NNE(Ci,Cj)表示两社区共享的边数;T(Ci,Cj)表示社区Ci与Cj的信任度[19],为两社区内所有节点间信任度的和。NNE(Ci,Cj)和T(Ci,Cj)的计算公式如下:
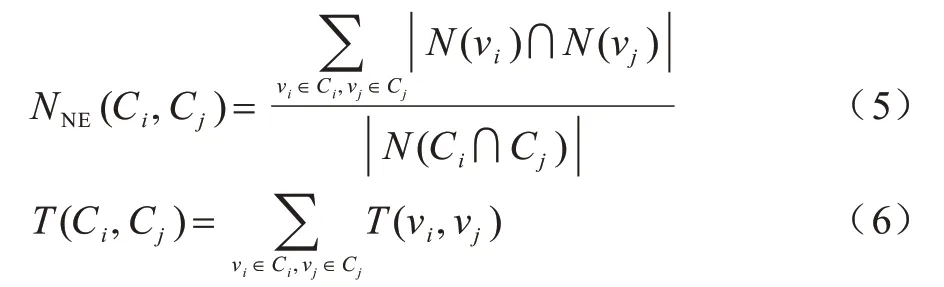
其中:N(νi)为节点νi依附的边构成的集合;N(Ci,Cj)表示社区Ci与Cj合并后所包含的边。
节点间的信任度采用基于节点属性的相似度来度量,计算公式如下:
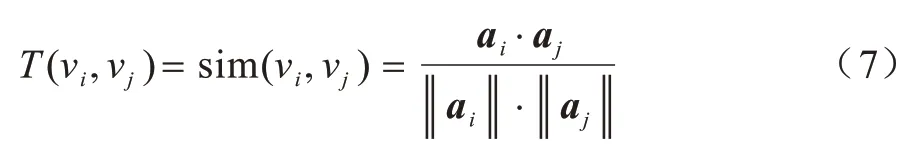
其中:ai、aj分别为节点νi、νj的属性向量。
2 重叠社区发现算法
本文提出的基于节点拓扑势和信任值调整的重叠社区发现算法本质上是发现核心节点并以该核心节点为中心进行扩展形成社区的过程。为方便描述,将本文算法简称为CTPT 算法。CTPT 算法流程如图1 所示,其中q表示最终合并社区的个数。
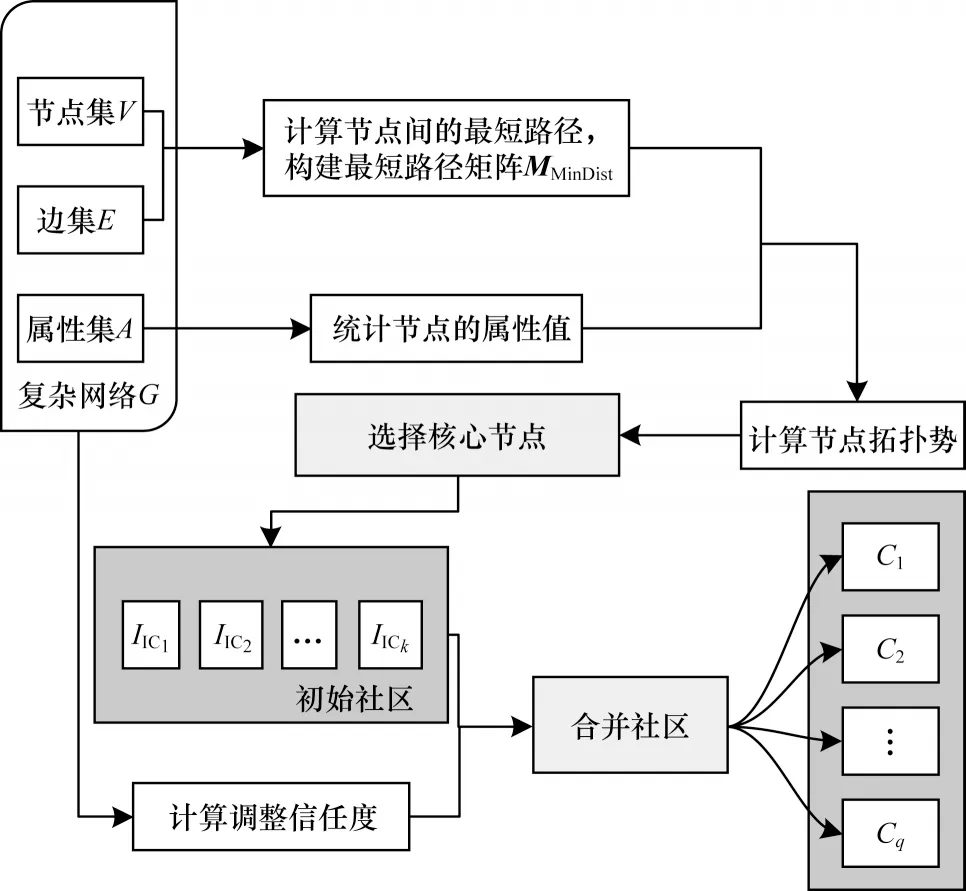
图1 CTPT 算法流程Fig.1 Procedure of CTPT algorithm
2.1 核心节点选取
首先,计算网络G中任意一对节点νi和νj的最短路径长度d(νi,νj),构建最短路径矩阵MMinDist。然后,利用MMinDist提供的路径信息,生成每个节点νi的作用节点集合Γ(νi)。接下来,按照式(3)迭代地计算每个节点的拓扑势φ(νi),并以此为判断依据选取K个φ(νi)最大的节点作为核心节点,保存在Top 数组中。核心节点选取流程如图2 所示。

图2 核心节点选取流程Fig.2 Procedure of core node selection
2.2 社区形成与再调整
在初始化时,将Top[K]中的每一个核心节点视为一个社区。首先,从单节点社区出发,依次取出V中的节点νi并尝试加入社区IICk,计算模块度函数Q[20]。如果Q增大,则将该节点加入社区,否则尝试将节点νi加入下一个社区IICk+1,其中emm表示社区m内部所有节点之间的边的集合,am表示所有连接到社区m的边数,emn表示社区m和社区n之间的边数。然后,通过调整信任度对已形成的初始社区群落进行合并与再调整,上述步骤完成后形成最终社区。未加入任何社区的节点被视为离群点,并将其剔除。社区形成与合并流程如图3 所示。
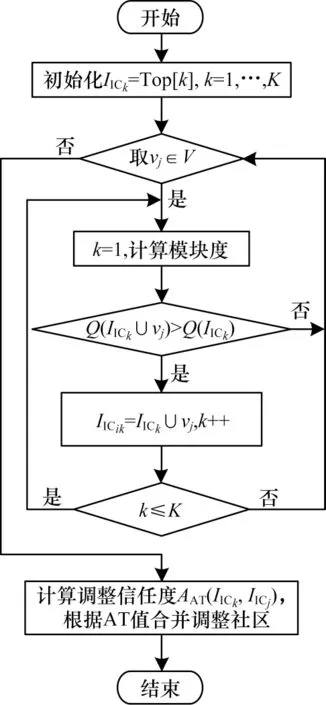
图3 社区发现与合并流程Fig.3 Procedure of community discovery and merging
3 实验结果与分析
3.1 实验设置
3.1.1 数据集
为评价CTPT 算法性能,实验采用两类数据集:1)LFR 人工网络数据集,由经典的LFR 基准程序生成,可以模拟具有重叠社区结构的网络数据集,主要用于测试社区检测算法的优劣;2)真实网络数据集,来源于斯坦福大学的大型网络数据集网站(http://memetracker.org/data/index.html)。表1 给出了人工网络数据集Net1、Net2 和Net3 的参数信息,其中,Οn表示重叠节点数,µ表示LFR 网络中的混合系数,其值越大表明所生成的网络拓扑结构越复杂。表2 给出了真实网络数据集ego-Facebook、Musae-twitch 和Web-flickr 的参数信息。ego-Facebook 数据集由facebook 的朋友列表组成,是facebook 上用户间的社交网络。Musae-twitch 数据集是使用某种语言进行流式传输的游戏玩家的Twitch 用户-用户网络,该网络中的节点是用户本身,链接是他们之间的好友关系。Web-flickr 是用户分享图片和视频的社交网络,该网络中每一个节点都是flickr 中的用户,每一条边都是用户之间的好友关系。另外,每一个节点都有标签,用于标识用户的兴趣小组。
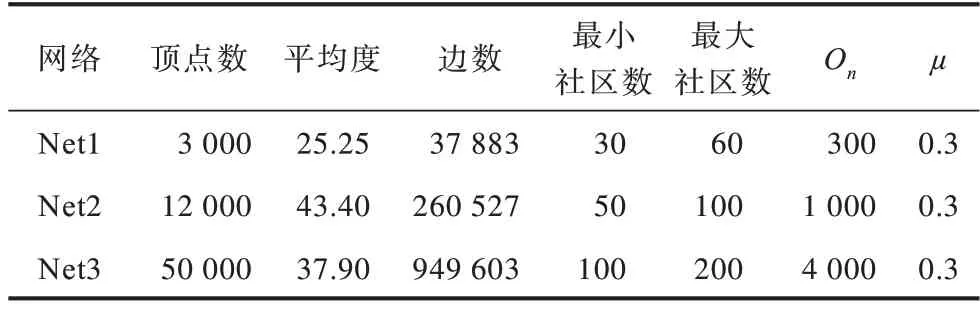
表1 LFR 人工网络数据集参数设置Table 1 Parameter setting of LFR artificial network dataset
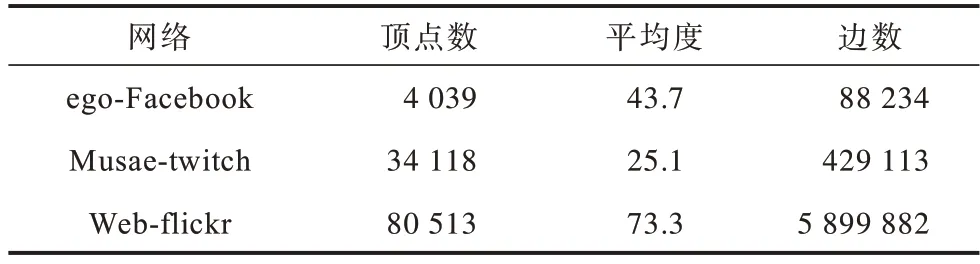
表2 真实网络数据集参数设置Table 2 Parameter setting of real network dataset
为评价算法性能,通常需要选取度量社区划分好坏的性能指标。扩展模块度是最常用的指标之一,计算公式如下:
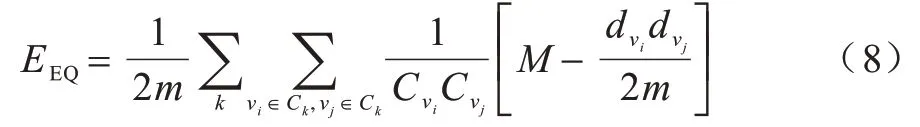
指标归一化互信息(Normalized Mutual Information,NMI)[21]用于度量检测到的社区与真值之间的距离,计算公式如下:
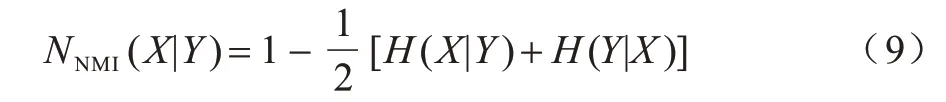
其中:H(X|Y)表示X对Y的规范条件熵;H(Y|X)表示Y对X的规范条件熵,该值越大,意味着算法所发现社区与网络真实社区相吻合的程度越高。
3.1.2 对比算法
将本文提出的CTPT算法与以下4种算法进行对比:
1)基于隶属度传播(Membership-Degree Propagation,MDP)的重叠社区划分算法[22]:以种子节点的基本特征为依据构建网络节点之间的隶属度传播模型,将种子节点的社团隶属度传播至非种子节点进行社区发现。
2)面向属性网络的重叠社区划分算法(overlapping community discovery Algorithm for Attributed Networks,ANA)[23]:利用节点的密集度和间隔度搜索局部密度中心,并将其作为社区中心,通过计算非中心节点的社区隶属度实现重叠社区的划分。
3)基于GFE 的重叠社区划分算法[4]:根据网络中极大派系间的链接强度将原始网络图转换成最大派系图,在最大化适应度函数的条件下,贪婪扩张最大派系图中的种子派系进行社区发现。
4)基于种子扩张(Two Expansions of Seeds,TES)的重叠社区划分算法[24]:首先根据网络节点的拓扑特征形成初始社区,然后采用重力度再次进行社区的合并和扩展。
3.2 结果分析
3.2.1 LFR 人工生成网络数据集上的结果分析
图4 给出了在不同规模的LFR 人工生成网络数据集上5 种重叠社区发现算法随重叠社区数量变化对应NMI 的变化规律。CTPT 算法考虑不同结构和属性的影响,分别设置调整信任度的调节参数λ为0.4、0.5、0.6,实验结果显示λ=0.5 时效果最好。
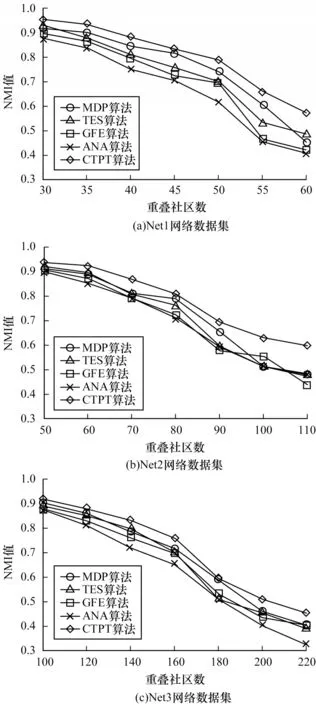
图4 不同重叠社区数量对算法NMI 值的影响Fig.4 Influence of the number of different overlapping communities on the NMI value of the algorithm
通过观察图4 中NMI 变化曲线可以发现:随着重叠社区数量的增加,5 种算法在3 组数据集上的NMI 值不断减小;随着网络规模的增大,5 种算法的效率均有所下降,但CTPT 算法的社区划分效果相对较好,并且具有较好的稳定性。其中,ANA 算法在Net3 网络数据集上表现较差,NMI 值下降较快,比其他算法效率差。同时,对比CTPT 算法在3 个网络数据集上的效果后发现,CTPT 算法在Net3 网络数据集上得到的NMI 值低于Net1 和Net2 网络数据集,意味着网络越复杂,CTPT 算法的执行效果越差,这是下一步需要改进之处。由此可见,在大规模复杂网络数据集的重叠社区检测方面,CTPT 算法具有较好的检测效果和稳定性。
3.2.2 真实网络数据集上的结果分析
在真实网络数据集上采用扩展模块度进行重叠社区发现算法的性能评估。表3、表4 给出了CTPT算法在3 个真实网络数据集上实验结果,分别选取社区数量|C|在不同值的情况下,运行15 次CTPT 算法所得的EQ 均值作为最终结果。

表3 真实网络数据集上社区发现的EQ 值(|C|=20)Table 3 EQ value of community discovery on real network dataset(|C|=20)
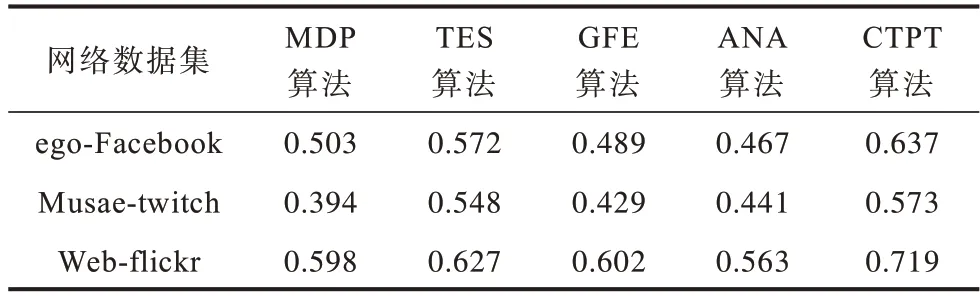
表4 真实网络数据集上社区发现的EQ 值(|C|=30)Table 4 EQ value of community discovery on real network dataset(|C|=30)
由于CTPT 算法充分考虑了社区形成过程中各种因素的共同作用,一方面引入拓扑势,考虑了网络结构(最短路径长度)不同导致的节点重要性不同,另一方面多次融合节点属性,兼顾了节点交互对社区的影响,因此在真实网络数据集上性能表现良好,实验结果整体优于对比算法。TES 算法与CTPT 算法的第一阶段均为使用网络的节点拓扑特征得到初始社区,在3 个网络上的EQ 值仅次于CTPT 算法,表现较好,尤其是在Musae-twitch 网络数据集上,在最好情况下EQ 值仅相差0.025。ANA 算法实现时会产生较小的链接社区,阻碍了社区的形成,导致难以获得较好的性能,因此在3 个数据集上的实验结果均是最差的。
4 结束语
本文充分考虑社区形成过程中各种因素的共同作用,提出基于网络拓扑势与信任度调整的重叠社区发现算法。由于节点在网络中所处位置及其链接关系存在差异,使得节点重要性不同,通过网络拓扑势来体现这一特征,并且每个节点又具有独立的固有属性,因此将属性的影响力叠加在拓扑势的计算过程中。在社区合并阶段,将节点间的信任度作为初始社区能否合并的依据,形成最终的社区划分。在不同数据集上的实验结果验证了本文算法相对于同类算法的优越性。在下一阶段的研究中将尝试在核心节点的选取中加入注意力机制来体现节点重要性,利用图嵌入技术优化生成的属性向量,提升重叠社区发现算法的实现效率,并最终将其应用于实际网络分析及网络推荐系统。
