基于改进A*算法的路径规划在海战兵棋推演中的应用
2022-05-13张韬项祺郑婉文孙宇祥周献中
张韬, 项祺, 郑婉文, 孙宇祥, 周献中,2
(1.南京大学 工程管理学院, 江苏 南京 210093; 2.南京大学 智能装备新技术研究中心, 江苏 南京 210093)
0 引言
随着Alpha Go程序的问世,其方法创新、技术突破和认识论上的进步都给兵棋推演领域带来了新的热潮和机遇。在军事智能化发展的大趋势和计算机广泛普及的大背景下,计算机兵棋推演既是战争推演、战术设计和技术验证等领域的一种重要辅助手段,又是全民学军事、学战例、提高国防意识、开展国防教育与军事科普的一种有效手段。
路径规划作为计算机兵棋推演的重要组成部分,其主要任务是根据不同的推演地图,在起始点和终止点之间快速规划一条由多个路径点依次连接而成的最优路径。在兵棋推演的背景下,最优路径的含义不仅是两点之间的距离最短,而且是综合考虑距离、装备效能和威胁等因素后的最优路线。
A算法作为一种智能启发式算法,因其良好的通用性和拓展性,已广泛应用于物流运输、建筑工程、岩石工程、物联网、航空航天和无人驾驶等众多领域。又因为回合制兵棋推演中静态路径规划的需求,本文尝试将A算法引入海战兵棋推演的最优路径规划中,解决棋子的路径选择问题。在兵棋推演过程中,由于推演地图的特殊类型和对路径方案的多目标需求,传统A算法无法有效解决兵棋推演中的路径规划问题。针对上述问题,本文对A算法进行了优化改进:通过增加地图信息映射机制,解决了A算法正六边形栅格地图中的应用问题;通过改进估价函数的设置,提高了海战兵棋推演中的路径规划质量,保证了最优路径方案的生成。
1 海战兵棋推演的环境
本文使用的推演环境为第二届全国“先知·兵圣”人机对抗挑战赛提供的“中国舰队”回合制海军战术兵棋推演平台。
该推演平台使用的地图类型是目前兵棋推演中常见的正六边形栅格地图,如图1所示。该推演平台使用的栅格共有6种属性。
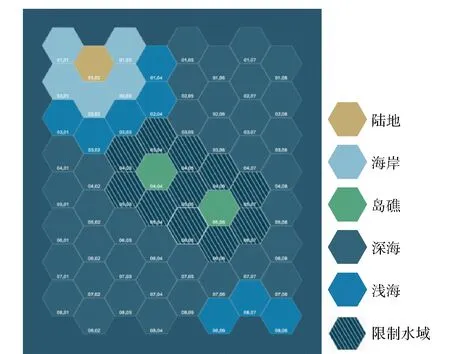
图1 推演地图示例Fig.1 Example ofwar gaming map
该推演平台中的棋子共分为水面单位、空中单位、水下单位、岸基单位和基地单位5个大类。棋子的状态可分为完好、受损和战毁3个类别,棋子的状态将直接影响其属性的高低。棋子的属性可分为机动、侦察、攻击和防御4个主要类别。根据棋子的属性,不同类型栅格将对棋子产生不同的影响,例如区域不可达、增加被敌方发现的可能性和增加被攻击时的毁伤概率。
随着推演的进行,推演双方可以通过击伤、击毁敌方棋子,或者夺取夺控点而得到相应的分数;当推演结束时,得分高者获胜。根据胜负的判定规则,推演双方的目标均为保证己方棋子尽可能少地受到攻击,尽可能多地打击敌方棋子,并尽可能多地占领夺控点。为了达成该目标,推演中使用的路径方案需要有意识地避让不利于己方棋子生存的区域。
2 路径规划算法设计
2.1 A*算法的原理
A算法是一种由Hart等在文献[16]中提出的智能启发式搜索算法,可用于在静态路网中实现全局路径规划。A算法的算法流程是从起始节点开始向相邻节点拓展;对于待拓展节点,通过估价函数()计算该节点的估计代价,从周围节点中选择拥有最小估计代价的节点作为下一个拓展节点;重复上一过程,当搜索到目标节点时便可生成最优路径。估价函数()用于确定拓展方向,是A算法的重要组成部分,其一般形式为
()=()+()
(1)
式中:()表示实价函数,用于计算从起始节点至到达待拓展节点的实际代价;()表示启发函数,用于计算从待拓展节点到目标节点的估计代价,即启发信息。
为了能让A算法总能得到正确的最优路径,启发函数()对于路径探索过程中的任意节点必须满足(2)式:
()≤()
(2)
式中:()表示任意节点到目标节点的估计代价;()表示节点到目标节点的实际最小代价。
传统A算法通常采用实际距离来表示实际代价,采用欧氏距离或者曼哈顿距离来表示启发信息。以欧氏距离为例,对应的启发函数()如(3)式所示:
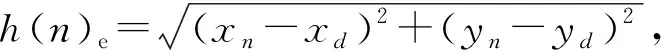
(3)
式中:、分别表示待拓展节点的横坐标和纵坐标;、分别表示目标节点的横坐标和纵坐标。
传统A算法从当前节点进行拓展时,需要搜索如图2所示的8个相邻节点,包括左上方节点、上方节点、右上方节点、右方节点、右下方节点、下方节点、左下方节点和左方节点。
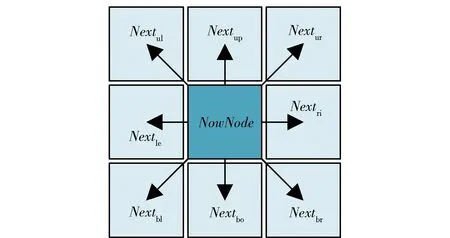
图2 传统A*算法的节点拓展示意图Fig.2 Node expansion diagram of classical A* algorithm
2.2 A*算法的改进优化
2.2.1 映射机制的构建
栅格法是环境建模的经典方法,该方法使用栅格对环境信息进行表示。兵棋推演中大量使用栅格法构建推演地图,传统A算法也通常使用栅格法量化提取地图信息,但二者使用的栅格类型不同。兵棋推演正如本文涉及的推演平台,通常使用正六边形栅格地图,而传统A算法则使用正四边形栅格地图。因此,本文首先需要在两种地图间构建一种映射机制,使A算法的环境模型适应兵棋推演环境。
为了让A算法能够处理推演地图,本文将推演地图的六角格按序映射至A地图的四角格。以图3为例:图3(a)为处理前的正六边形栅格地图,图3(b)为处理后的正四边形栅格地图。推演地图中每个栅格的坐标按照推演平台的规则确定;推演地图中的六角格按照其坐标映射到A地图中具有相同坐标的位置。
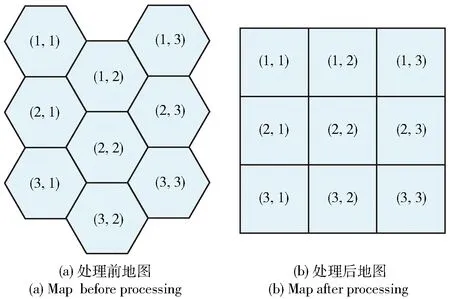
图3 地图信息映射的示例Fig.3 An example of map information mapping
由于上述映射机制改变了节点之间的相邻关系,需要从四角格坐标的角度解析相邻六角格之间的坐标关系。四角格节点进行拓展时,需要搜索周围的8个节点;六角格节点进行拓展时,需要搜索如图4所示的6个相邻节点。
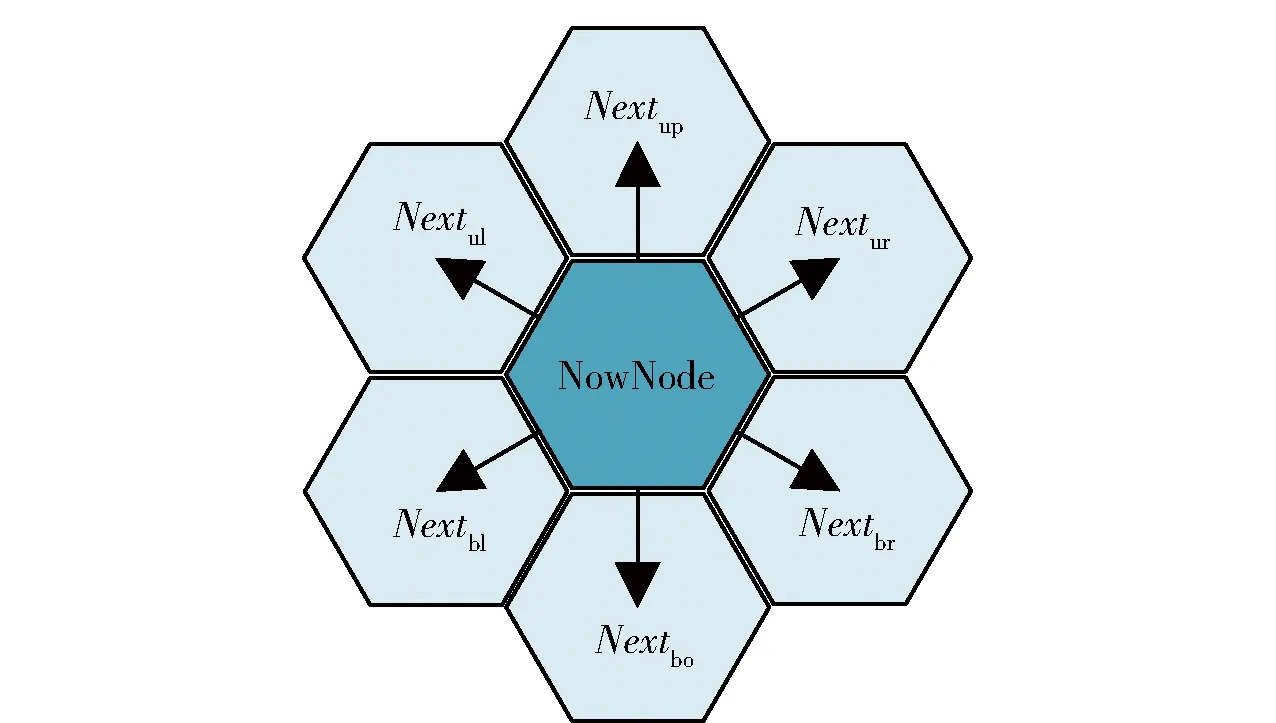
图4 改进A*算法节点拓展示意图Fig.4 Node expansion diagram of improved A* algorithm
假设的坐标为(,),则的坐标为(-1,),的坐标为(+1,)。六角格的排列方式导致了剩下4个节点的坐标与的取值有关。当为偶数时,的坐标为(,+1),的坐标为(+1,+1),的坐标为(+1,-1),的坐标为(,-1);当为奇数时,的坐标为(-1,+1),的坐标为(,+1),的坐标为(,-1),的坐标为(-1,-1)。
通过构建上述映射机制,即可实现A算法在正六边形栅格地图上的初步应用。
222 估价函数的构建
传统A算法以路径最短为目标,而仅以路径最短为目标搜索得到的路径无法满足海战兵棋推演的需求。在海战兵棋推演中,不同的海域类型和与敌方棋子的距离也将直接影响己方棋子在裁决时的点数修正,进而影响战斗的结果。因此,本文选出3个指标作为路径规划时需要考虑的因素和评价路径方案质量的依据,对各指标进行定义。
路径长度指数。路径长度指数,简称路径指数,表示棋子从起始节点到目标节点的过程中需要经过的路径长度,其表达式如(4)式所示:
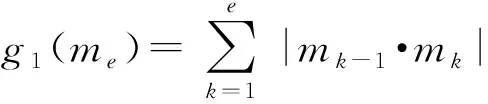
(4)
式中:()表示该路径的路径长度指数,其值越大表示路径长度越大、路径质量越差,表示路径的末端节点,且编号为不小于2的整数;|-1·|表示从节点-1到节点的路径长度,根据本文涉及的推演平台可知该值为1,表示路径上编号为的节点,∈[1,]。
根据路径长度指数的定义可知:在其他条件相同的情况下,应选择拥有较小路径长度指数的路径方案,保证能及时到达指定地点的同时节省我方棋子的机动值。路径长度指数与传统A算法中的实价函数相同。
装备限制指数。装备限制指数,简称装备指数,表示棋子从起始节点到目标节点的过程中各个海域类型对棋子性能或装备效能的影响情况,其表达式如(5)式所示:
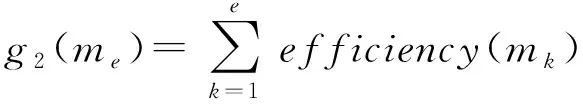
(5)
式中:()表示该路径的装备限制指数,其值越大表示棋子性能或装备效能被限制得越严重、路径质量越差;()表示节点对棋子性能或装备效能的影响,取值与棋子类别和节点的海域类型有关,取值范围为[0,1]。需要注意的是:若某个节点的装备指数为1,则表示棋子不可到达该节点;一个可行路径方案中每个节点的装备指数都应小于1。
与实际战争一样,兵棋推演中也充满着不确定性。因此,在其他条件相同的情况下,应选择能最大程度地发挥棋子性能或装备效能的路径方案,保证我方棋子以相对较好的状态应对突发情况。
敌方威胁指数。敌方威胁指数,简称威胁指数,表示棋子从起始节点到目标节点的过程中受敌方棋子威胁程度的总和,其表达式如(6)式所示:
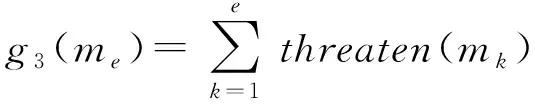
(6)
式中:()表示该路径的敌方威胁指数,其值越大表示我方棋子被击毁的可能性越大、路径质量越差;()表示棋子在节点受敌方棋子威胁的程度,其取值范围为[0,1]。需要注意的是:若某个节点的威胁指数为1,则表示我方棋子在该节点处将被击毁;在正常情况下,一个路径方案中每个节点的威胁指数都应小于1。
根据敌方威胁指数的定义可知:在其他条件相同的情况下,应选择拥有较小敌方威胁指数的路径方案,保证我方棋子的存活。
综合考虑路径长度指数、装备限制指数和敌方威胁指数3个因素,本文改进A算法中的实价函数如(7)式所示:
()=·()+·()+·()
(7)
式中:()亦可称为总评价指数,用于评价路径方案的质量,其值越小表明路径方案的质量越高,即路径方案更优;()表示从起始节点到节点的实际路径长度指数;()表示从起始节点到节点的实际装备效能指数;()表示从起始节点到节点的实际敌方威胁指数;、和分别表示对应指数的修正系数,三者的关系如(8)式所示:
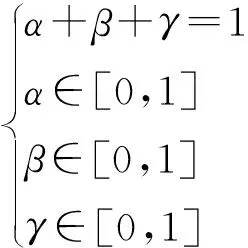
(8)
、和取值大小表示对应指数在实价函数中的重要性,可根据棋子属性和当前态势等信息,由指挥员或者领域专家确定。
针对本文正六边形栅格地图的类型,在立方体坐标系下可以计算出任意2个栅格之间的准确距离,而在21节涉及的笛卡尔坐标系下则不能。立方体坐标系下任意两点(,,)和(,,)之间的距离如(9)式所示:
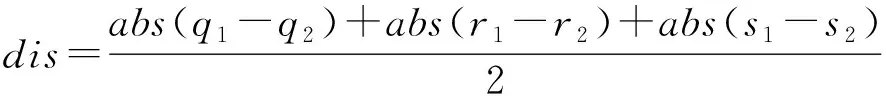
(9)
假设笛卡尔坐标系中某点的坐标为(,),与之对应的立方体坐标为(,,),则二者的转换关系如(10)式所示:
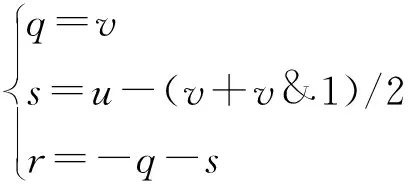
(10)
式中:&表示按位与运算,即参加运算的2个数按二进制位进行与运算。
结合海战兵棋推演的特点和(9)式、(10)式,本文设计的启发函数()如(11)式所示:
()=·((-)+(-+
(+&1--&1)2)+
(-+-+
(+&1--&1)2))2
(11)
式中:修正系数与(7)式中路径长度指数的修正指数相同。由于装备限制指数和敌方威胁指数具有较大的不确定性,本文没有将其纳入启发函数中。
根据启发函数的性质和本文背景,可得到如下定理1。
对于路径方案={,,…,}中的任意节点,不等式()≤()在正六边形栅格地图中恒成立。其中,()表示本文构建的启发函数。
该定理可用数学归纳法证明,具体的证明过程如下。
当=时,()≤()显然成立。
合作小组组长不仅要有管理,还要有示范。既然是示范,就要有一定标准。为此,我要求小亮做3个工作:一是对自己进行“全身体检”,检查自己存在哪些问题,必要时做全面整改;二是密切注意其他3位成员的表现,在看得见的地方,不能做得比他们差;三是做人做事要有底线,不能突破底线。
假设当=+1时,定理1成立。
根据(11)式可得()≤(+1)+;
又根据(7)式可得(+1)+≤(),
则(+1)≤(+1)
⟹(+1)+≤(+1)+
⟹()≤()
因此,当=时定理1成立。证毕。
根据定理1可知,本文构建的启发函数符合(2)式中对启发函数的限制,即保证了本文提出的改进A算法在求解最优路径方案时的正确性。
通过构建上述实价函数,可以满足兵棋推演中对路径方案的多目标需求;通过构建上述启发函数,可以保证最优路径方案的生成。综合实价函数和启发函数,本文提出的估价函数如(12)式所示:
()=()+()
(12)
2.2.3 算法流程
本文改进A算法沿用传统A算法中对节点的管理方式,即使用open表管理正在探索的节点、closed表管理探索过的节点。算法流程如图5所示。
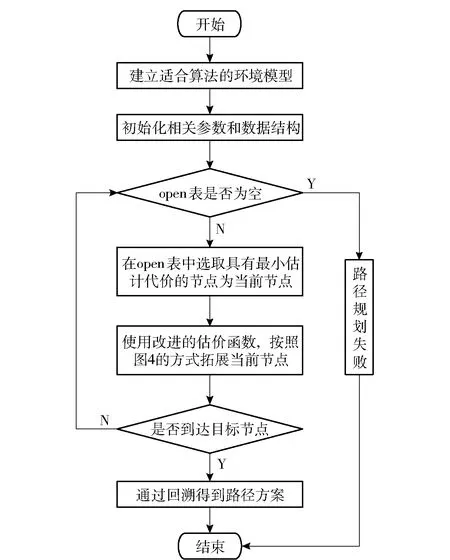
图5 改进A*算法流程图Fig.5 Flow chart of improved A* algorithm
具体步骤如下:
提取推演地图中的信息,建立符合A算法要求的环境模型。
构建估价函数,初始化open表和closed表,计算起始节点的估计代价并将其放入open表中。
判断open表是否为空。若open表不为空,则执行步骤4;若open表为空,则因无法搜索到可行路线而结束。
在open表中选取具有最小估计代价的节点为当前节点,并将该节点从open表移至closed表。
使用本文估价函数计算周围节点的估计代价,并将其存入open表中。拓展方式如图4所示。需要注意的是:在拓展节点时,若节点已在open表中,则需要重新计算其估计代价并据此判断是否需要更新其父节点;若节点的装备限制指数或者敌方威胁指数为1,则直接将该节点移至closed表中。
判断是否到达目标节点。若已到达,则执行步骤7;否则返回步骤3重复操作。
保存规划的路径。从目标节点开始,按每个节点的父节点回溯至起始节点,即可得到相应的路径。
3 实验与分析
本文在推演平台提供的地图上对改进A算法进行了效果验证。
在兵棋推演中,由于每类棋子具有其特定的属性特点,不同类型的棋子评价同一路径方案的结果不同,即需要针对每类棋子给各类节点的3个指数设置特定的参数。以更适合深海机动的棋子A和更适合浅海机动的棋子B为例,总评价指数中各参数设置如表1所示。

表1 参数设置
在相同起点和终点的情况下,本文让棋子分别用具有传统估价函数的A算法(简称传统A算法)和改进A算法生成路径方案。实验1是棋子A和棋子B使用传统A算法在两种地图下进行路径规划,其路径方案如图6所示。由于传统A算法仅考虑路径长度因素,棋子A和棋子B的路径方案是一样的。实验2是棋子A使用改进A算法在两种地图下进行路径规划,其路径方案如图7所示。实验3是棋子B使用改进A算法在两种地图下进行路径规划,其路径方案如图8所示。
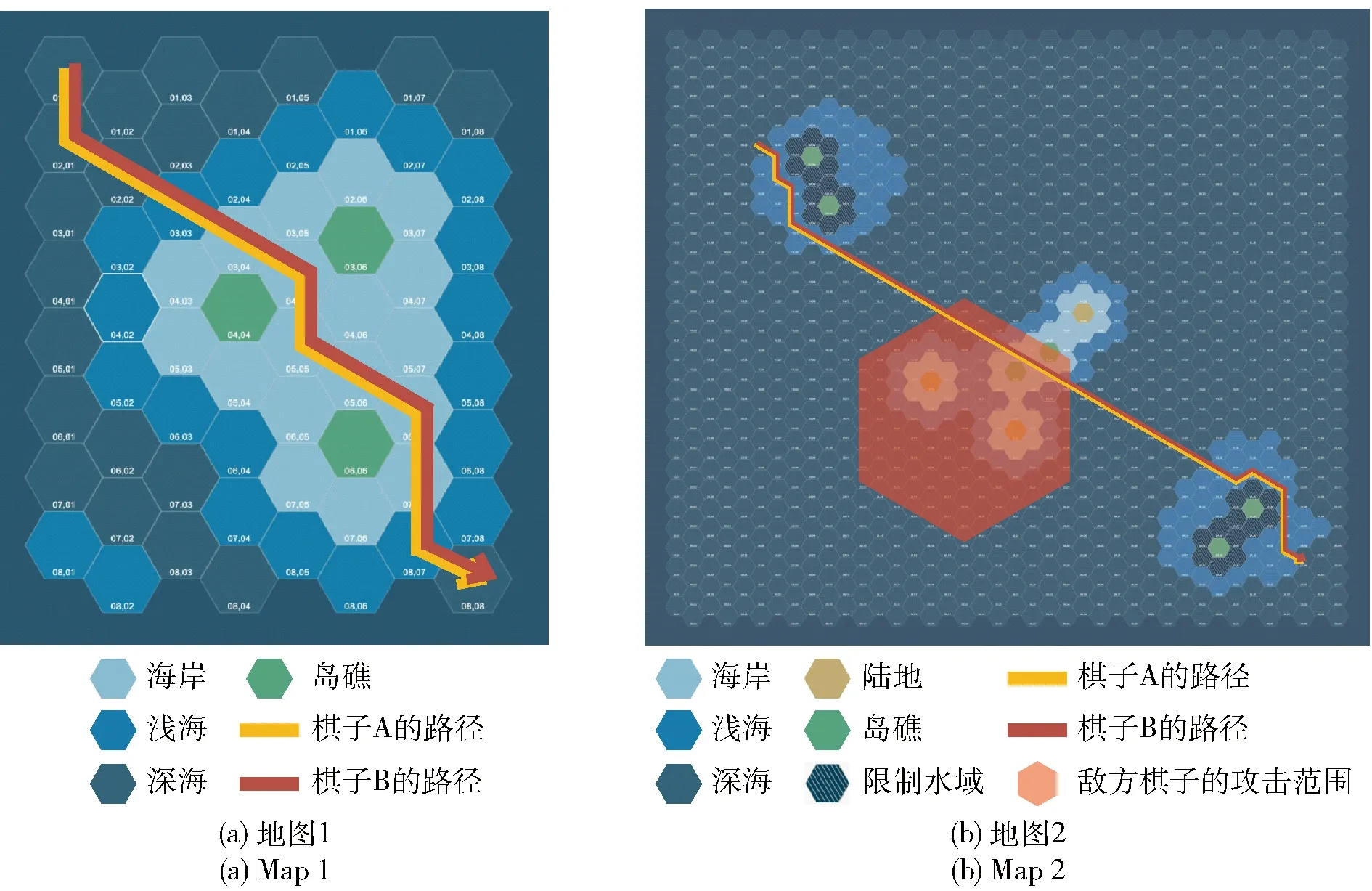
图6 棋子A和棋子B使用传统A*算法进行路径规划(实验1)Fig.6 Operator A and Operator B using traditional A* algorithm for path planning (Experiment 1)
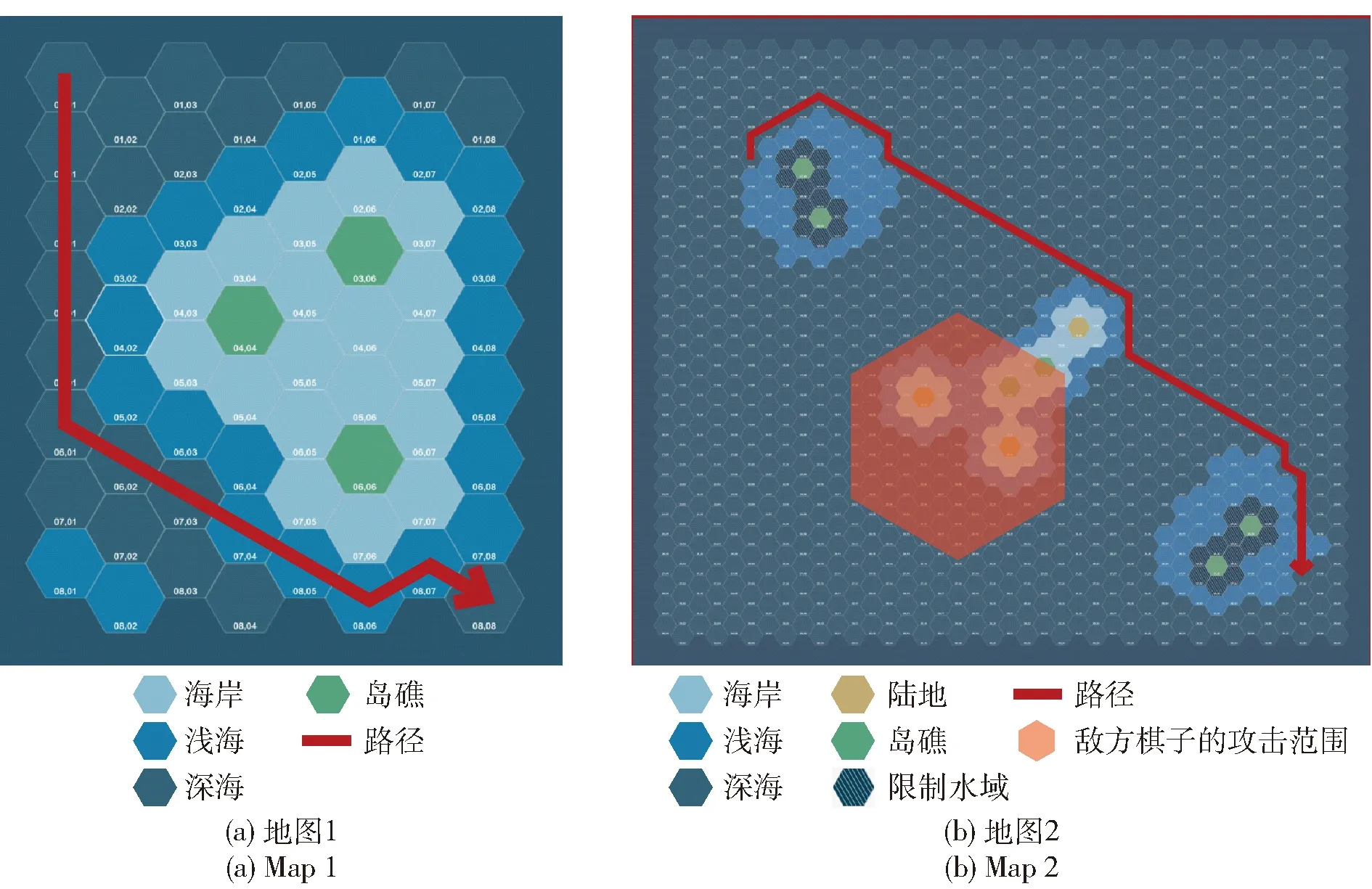
图7 棋子A使用改进A*算法进行路径规划(实验2)Fig.7 Operator A using improved A* algorithm for path planning (Experiment 2)
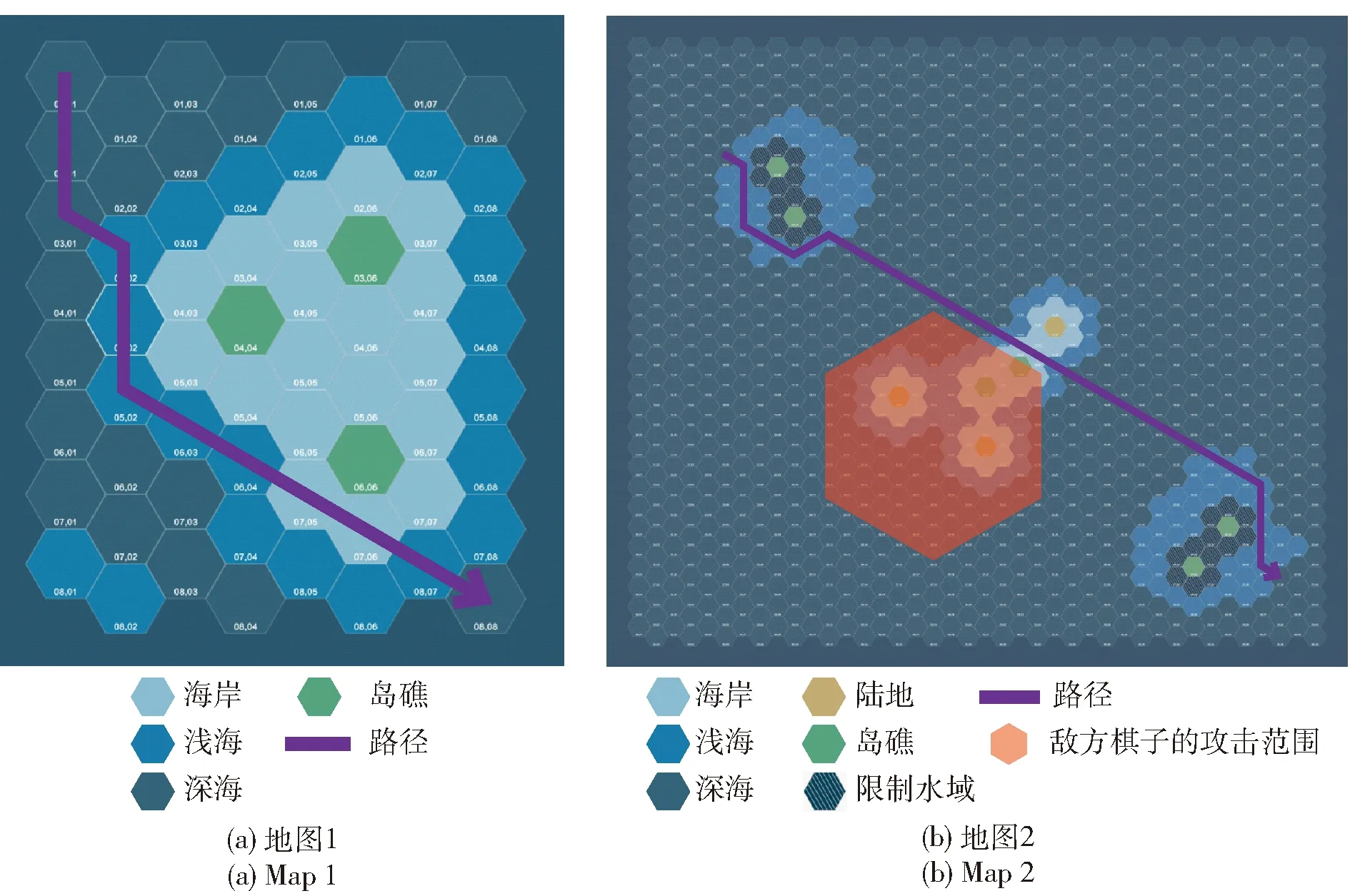
图8 棋子B使用改进A*算法进行路径规划(实验3)Fig.8 Operator B using improved A* algorithm for path planning (Experiment 3)
实验1、实验2和实验3的结果数据分别如表2、表3和表4所示。表2和表3中的百分比表示改进A算法相对于传统A算法的性能提升。
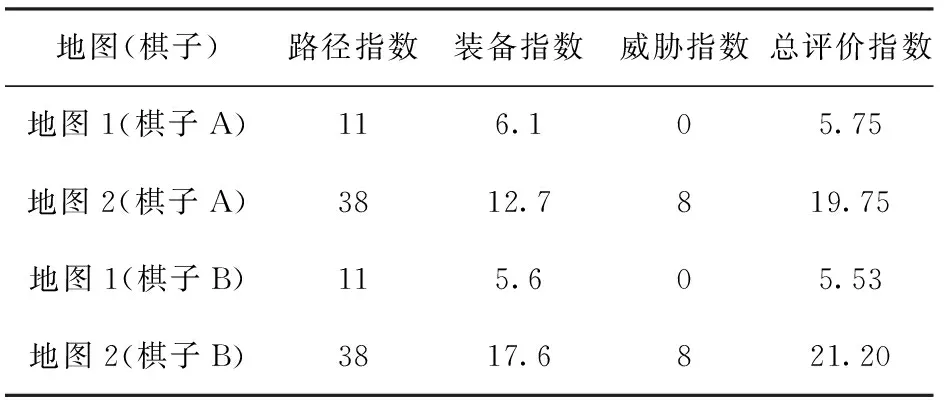
表2 实验1的结果

表3 实验2结果及其相对实验1结果的提升幅度

表4 实验3结果及其相对实验1结果的提升幅度
通过实验2和实验3的对比可知,改进A算法可以为不同类型的棋子提供符合其特性的路径方案。分析表3和表4的数据可知,在不同类型的棋子上,本文提出的改进A算法较传统A算法而言,除了路径指数外,装备指数、威胁指数和总评价指数都出现了不同程度的降低。根据2.2.2节中对这4个指数的定义,本文改进A算法虽然在路径指数部分的性能略有下降,但是在装备指数和威胁指数部分的性能都有大幅度提升,且总评价指数所表示的路径方案质量也得到了提高。此外,生成实验中路径方案的用时均小于0.5 s. 总之,本文改进A算法可以实现对3个指标的较好平衡且能结合不同棋子类型的特性规划出各自最佳路径,与传统A算法中只关注路径的长度不同,在提高路径方案质量的同时也更加符合实际兵棋推演的需求。
4 结论
本文在传统A算法基础上引入地图信息映射机制,提出既能满足多目标需求又能保证生成最优路径的估价函数,使改进A算法可高效地用于海战兵棋推演中的路径规划任务。得出主要结论如下:
1)本文算法可按照棋子属性和当前态势等信息提供符合其需求的路径方案,有效地提高了海战兵棋推演中路径规划的质量。
2)本文工作使A算法更加契合海战兵棋推演的需要,进一步优化了实际推演过程中的路径规划模块。
3)本文研究成果已成功运用于第二届全国“先知·兵圣”人机对抗挑战赛的海战比赛中,并且所属团队在全国“先知·兵圣”群队级兵棋推演中获得了智能AI优良奖。
