基于LS-SVR 的高速列车车内声品质主观评价
2022-05-11王增政王岩松郑立辉
王增政, 王岩松, 郭 辉, 袁 涛, 郑立辉, 孙 裴
(上海工程技术大学 机械与汽车工程学院, 上海 201620)
0 引 言
目前,针对高速列车车内声品质评价方式的研究,大多数还是沿用传统的问卷调查和主观评价实验等评价形式。 而高速列车车内噪声信号具有复杂性、多特征性,这种简易的评价方式用于评价高速列车车内声品质的准确性和合理性有待商榷。 因此,通过结合信号本身的心理声学参数特性和人的主观评价结果,利用多参数建立可以预测人的主观评价结果的评价模型是非常有必要的。
高速列车车内声品质主观评价研究中,一般会根据评价对象和评价目标进行评价方法和评价模型的改进。 Hardy采用了多种评价内部噪声环境的标准,如:噪声准则(NC)、首选噪声准则(PNC)、噪声等级(NR)、房间准则(RC),研究轨道车辆噪声抑制过程中的固有问题,确定了该噪声与乘客响应之间的关系;周家中基于交通网络距离重新划分影响范围,用分距离影响带的线型和指数型空间权重系数方程,构建轨道列车交通客流的LS-SVM 预测模型,结果显示,模型不仅可以简化数据的需求量,还能明显提高客流量的预测精度,但受地域因素影响较大;孟凡雨以高速列车车内噪声声品质的评价参量和主观评价结果分别作为输入和输出,确定网络的结构和参数,建立具有预测主观评价结果功能的BP 神经网络模型,研究声音的物理属性和心理声学属性之间的关系;郑德署开发了一个基于NET 平台的噪声预测系统,通过图形化的形式展现,实现了对噪声的计算分析功能; Park 等利用具有不同语音噪声比和背景噪声水平的噪声源与隔间噪声进行了两次实验,结果显示语音隐私和烦恼受声噪比的影响显著。
而对于高速列车车内声音信号的声音特性的筛选,以期用有效心理声学参数量化表征主观评价结果的研究还是相对较少,大部分还是用线性回归模型进行分析,难以很好地表达复杂的数据,而且对于具有相关性的特征数据难以建模。 在此基础上,区别于最小二乘支持向量机,本文中的最小二乘法—支持向量机回归(LS-SVR)首先利用最小二乘法(LS) 筛选得到样本,再通过支持向量机回归(SVR),建立高速列车车内声品质预测模型。
1 高速列车车厢内噪声信号采集及筛选
1.1 车厢内噪声信号采集
车厢噪声信号由数字人工头记录采集,并由LMS Test.lab 软件同步记录噪声数据。 每个测点记录4 种不同工况类型的信号,根据ISO 3381:2005并结合实际情况选择5 个测点,人工头在车厢内安装位置如图1 和图2 所示。 图1 中人工头的站姿高度为1.6 m,图2 中人工头的坐姿高度为1.2 m。 采集前用吊锤校准人耳与车厢地面的垂直度。

图1 人工头站姿 Fig.1 Standing pose

图2 人工头坐姿Fig.2 Sitting pose
1.2 样本信号的筛选
列车不同工况平稳运行时,原始信号被记录,每次记录时长17 s。 根据实验需要和标准要求,截取样本时长为5 s,目的是挑选合适的短时信号,用于评价实验。 本着信号不重叠的原则,先由原始信号截取出每种工况下的3 个样本,再根据每个样本的A 计权值进行拟合,常用的拟合方法有插值拟合和曲线拟合,插值拟合适合于理想测量情况(没有测量误差)的数据拟合,曲线插值则允许误差存在。而在实际测量中有不可避免的系统误差,所以选用曲线拟合。 曲线拟合的原理是最小二乘法原理,即根据样本数据点拟合后,再反向挑选出与拟合线误差平方最小的样本点所在的样本,即为实验听音样本。 这里对加速和减速工况下的原始样本进行截取时,虽然速度区间有差异,但是本质都是同一原始信号截取的,速度作为一个维度可以进行比较。 而且5 s内速度变化引起的变化量可以忽略,如匀速240 km/h 情况下,原始信号的3 个不同时间段内的样本点拟合,如图3 所示。
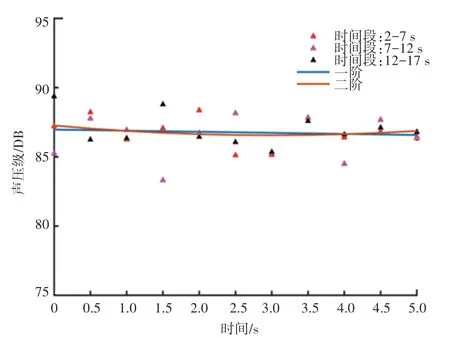
图3 同源信号不同时间段拟合Fig.3 Fitting of homologous signals of different time periods
目的是明确一阶(直线)拟合和二阶(曲线)拟合哪种拟合方式得到的拟合残差平方和更低,即确定样本中的时间和声压级之间的函数关系。 分别计算了拟合后各样本点与拟合点间的残差平方和,见表1。 由表1 可知,同源不同时间段的一阶拟合残差平方和最低。 故选择原始信号的2~7 s 时间段作为实验样本。 同理,按照此方法依次选取30 个实验样本,得到样本后分别计算样本的声压级、粗糙度、尖锐度、抖动度和指数等心理声学参数值,见表2。
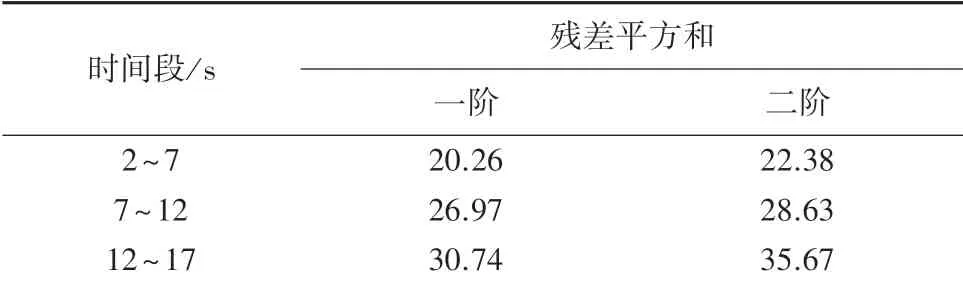
表1 残差平方和Tab.1 Sum of squares of residuals
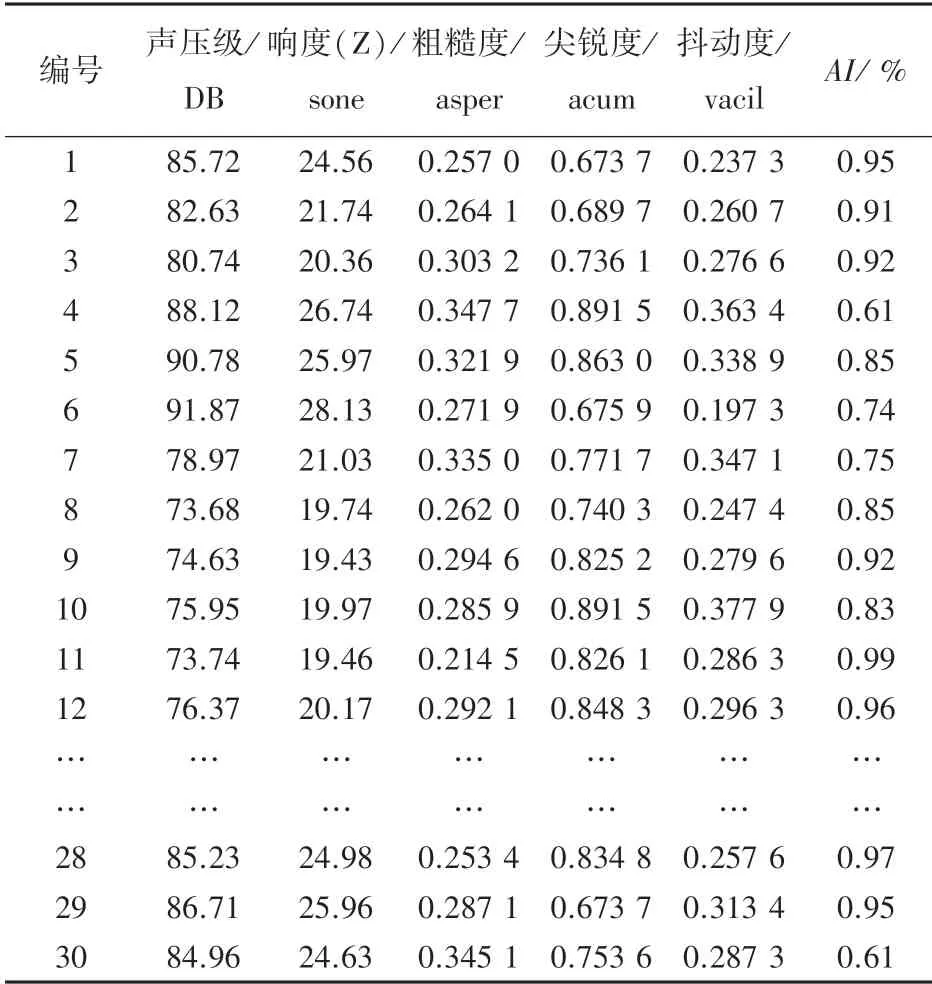
表2 样本的心理声学参数值Tab.2 Psychoacoustic parameter values of samples
2 主观评价实验
首先,设计9 级语义评分表,结合数字等级评分法,赋予形容词数字属性,评分间隔为单位间隔。 在区分对声音的“情感反应”和“情感评价”的词汇中,常用的有尖锐度、愉悦度、烦恼度。 尖锐度是可以通过人的分析能力判断得出的,也就是对声音情感上的评价;而烦恼度在情感表达上则较复杂,是对声音情感上的反应,这两个都是主观感觉的量化体现。 但是尖锐度在主观的基础上略微偏客观。主观评价指标选择“烦躁度”,相比于其他噪声评价指标,高铁内部复杂噪声给人带来的烦躁程度更明显,同时还设置具有“中性感觉”的样本作为参照,避免评分差距过大,评分等级为“5”,主观评价见表3。 参考声样本由课题组声学专家在听完所有样本后根据声学经验选出,选出的所有参照样本被试听完后都认同这种“中性感觉”。 30 个声音打乱顺序随机呈现,听者独自坐在隔音室,待听者情绪平静后,被指示用具有9 个等级的评分表对样本进行打分,从非常嘈杂到非常安静。 30 个样本由21 名评价者评价打分,21 名评价者中有14 位男性,7 位女性,每位评价者均没有听力障碍。 评价实验后,最终得到30×21 维数值矩阵,进而将抽象复杂的主观感受量化成数值,对声音定量判断的评价结果通常可以作为一个区间尺度被认可。 评价实验前,对所有被试进行听音训练,训练的声音在实验中不使用,被试会被告知这些声音来自高铁车厢噪声。

表3 主观评价表Tab.3 Subjective evaluation form
以30 个样本作为横向维度,21 名评价者作为纵向维度,并由这21 名评价者根据表3 对样本进行打分,最终得到30×21 维评价结果数值矩阵,对每个样本的横向主观得分求和,并计算其算术平均值。30 个样本的烦躁度得分均值,如图4 所示。
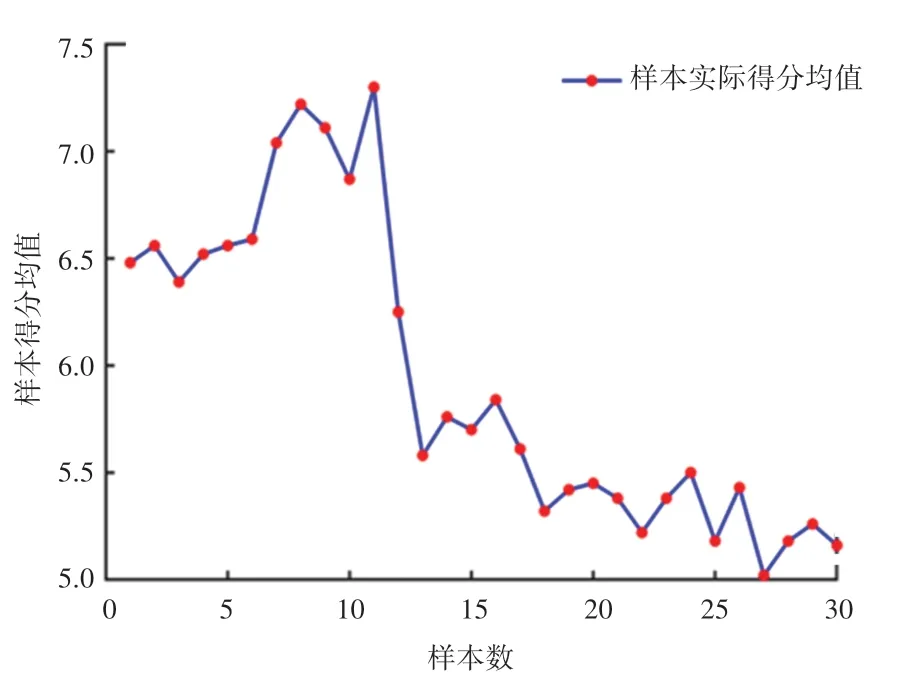
图4 样本的实际得分均值Fig.4 Actual mean scores of the samples
3 高速列车车内声品质LS-SVR 预测模型的建立
支持向量机(SVM)是一类按监督学习方式对数据进行二元分类的广义线性分类器,是建立在统计学习理论VC(Vapanik-Cher-vonenkis)维理论和结构风险最小原理的基础上的。 通过寻求最小结构化风险来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本较少的情况下,亦能获得良好统计规律的目的,SVR 在解决小样本、非线性及高维模式识别中表现出许多独有的优势。 高速列车本身的特殊构造决定列车内部噪声特性的复杂性,在对其做评价研究过程中,精确的选取噪声数据样本对分析心理声学参量与评价结果之间的关系尤为重要,本文用最小二乘法对截取的车厢噪声样本进行精确筛选后,再通过SVR预测分析,建立高速列车车内声品质预测的最小二乘法——支持向量机回归LS-SVR 评价模型。
将SVM 由分类问题推广至回归问题可以得到支持向量回归(SVR)。
由最小二乘法反向筛选出的样本计算的客观参数和样本的得分均值组成训练样本{x,y},1,2,3,…,,x∈R,且∈,对于传统回归模型通常直接基于模型输出() 与真实输出之间的差别来计算损失,当且仅当() 与完全相同时,损失才为0。 而SVR 假设() 与之间最多有的偏差,即仅当两者之间的差别绝对值大于时才计算损失,相当于以() 为中心,构建了一个宽度为2的间隔带,于是SVR 问题可形式化,如式(1)所示:
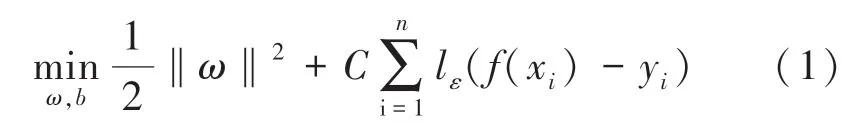
其中,(,,,…,ω) 为法向量;为正则化常数;l为不敏感损失函数,如式(2)所示:
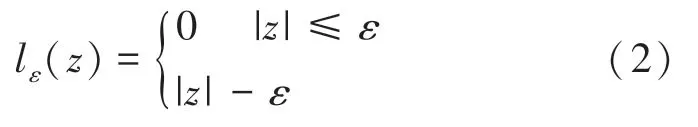
其中,为自变量,l() 为因变量。
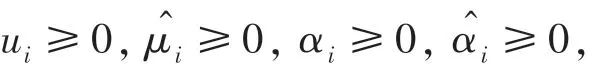
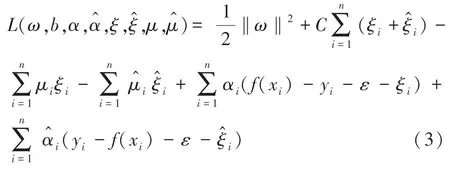
再由式(3)分别对,,ξ和^求偏导为0,可得SVR 的对偶问题,如式(4)所示:
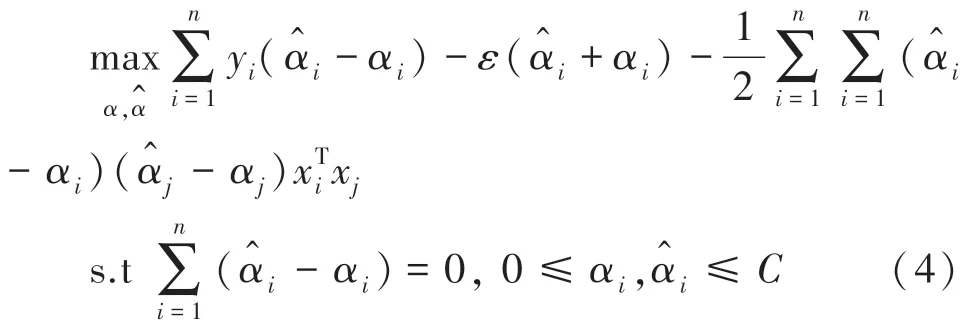
对于上述不等式约束优化问题,需要满足前提KKT 条件,KKT 条件是解决最优化问题时用到的约束方法,其一是对拉格朗日函数取极值时的必要条件;其二是对拉格朗日系数的约束优化;KKT 条件公式表达,如式(5)所示:
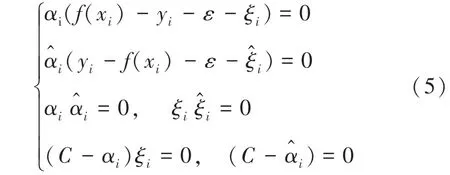
在满足KKT 条件下,将式(2)对的偏导为0带入到式(6)可得SVR 解,如式(7)所示:
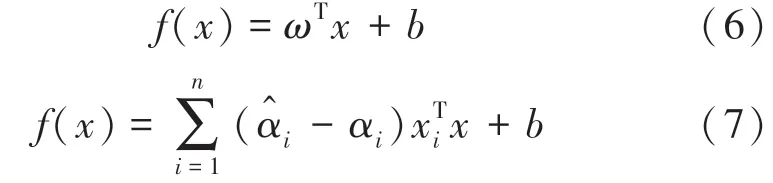
由于高铁噪声中复杂的声学特性,输入的心理声学参数和输出的主观评价结果之间存在复杂的非线性关系,所以引入核函数将原始空间映射到一个更高维的非线性特征空间进行分析,常用的核函数有线性核、多项式核、高斯核等,由于本文中的样本数据点具有多维度特征,而高斯核函数具有优越的可分性和局域性,因此本文选用更稳定且泛化能力更强的高斯核函数,如式(8)所示:
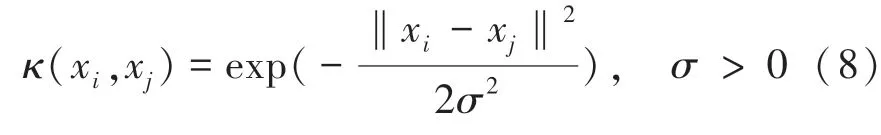
则最后得到SVR 的非线性高维解,如下所示:
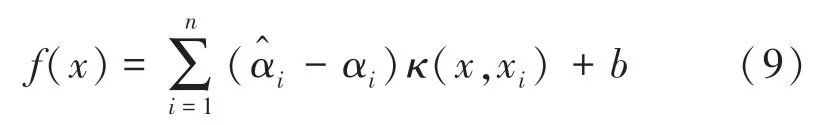
以上过程在代码实现前,首先要设置好参数,其中,种群数量设置为15;交叉概率设置为0.8;迭代次数设置为100;初始的,,由交叉验证后直接得到默认值。 对原始样本进行多次训练预测,最终的训练集预测结果如图5 所示。
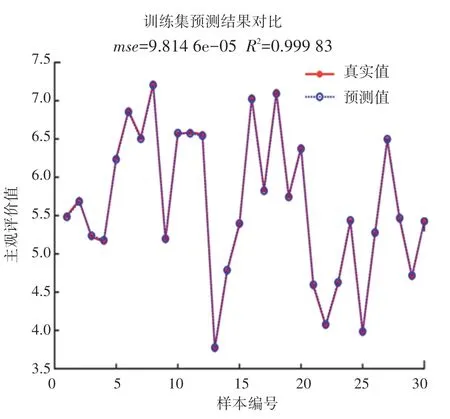
图5 训练集样本预测结果Fig.5 Training sample prediction results
4 LS-SVR 预测模型的检验
为了进一步验证LS-SVM 模型预测结果的准确性,再随机选取12 个噪声样本作为测试集,并与传统多元回归模型进行比较。 12 个样本都来自同一数据源,测试集中的数据点与训练集样本中数据点的获取方法相同。 测试集的预测值与实际值之间的预测结果对比如图6 所示。 图6 中测试集预测的达到0.85,说明测试集的预测效果较理想。
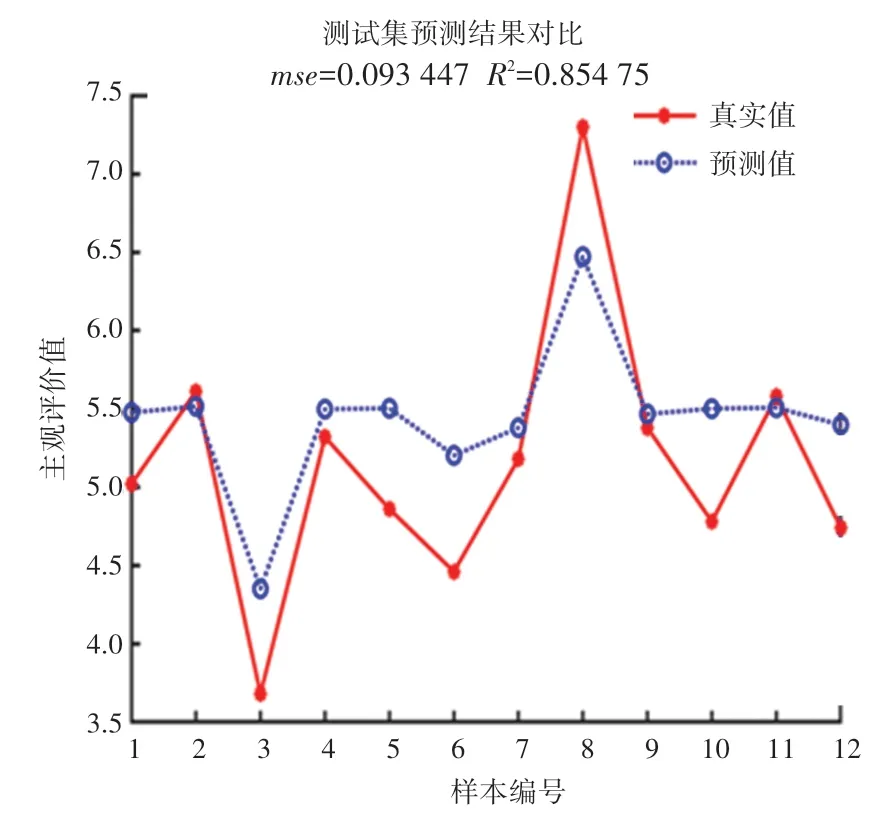
图6 测试集样本预测结果对比Fig.6 Comparison of testing sample prediction results
多元线性回归是用多个影响因素作为自变量来解释因变量的变化,通常用来研究自变量与因变量之间的线性关系。 LS-SVM 预测模型与多元回归模型之间的测试集预测误差率对比见表4,可以看出LS-SVM 模型的预测误差率比多元回归模型低,而且线性回归模型的预测误差率最大达到21.9%,进而说明高铁噪声信号的心理声学特性与主观评价结果之间的非线性关系更明确,证明LS-SVM 评价模型针对高铁噪声评价时是适用的。
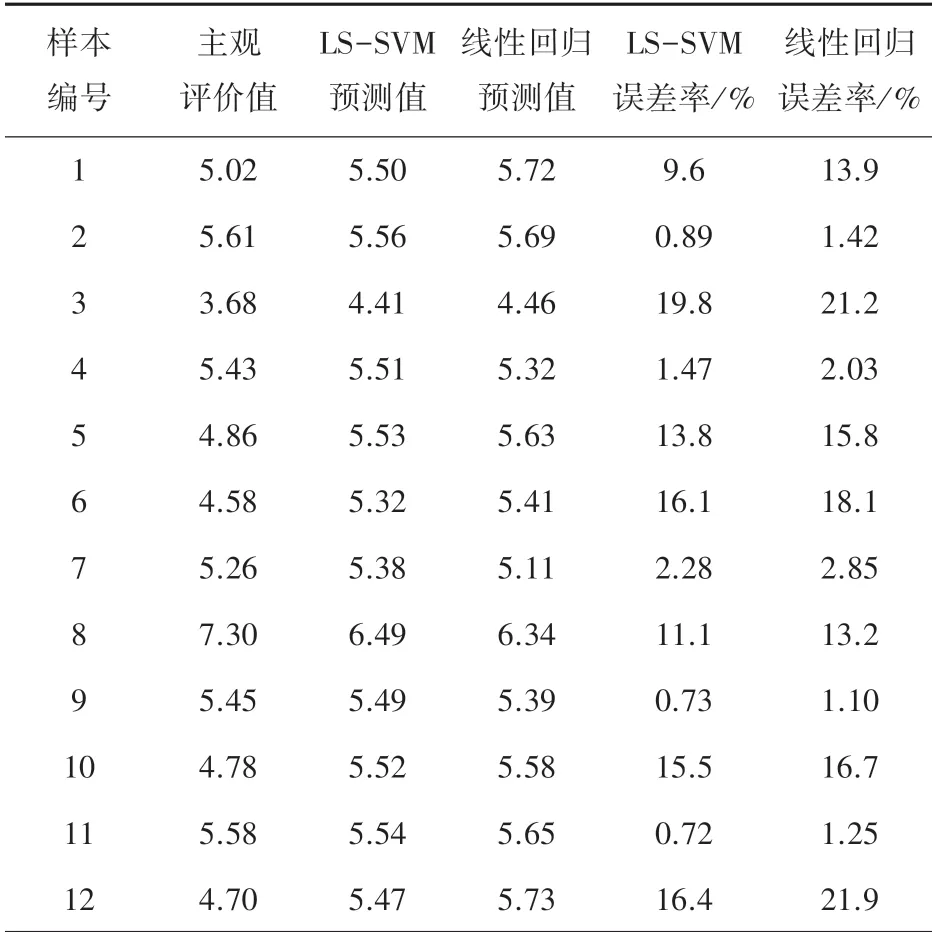
表4 模型测试集预测对比Tab.4 Comparison of prediction results of testing samples
5 结束语
高速列车车内噪声评价预测是高铁噪声评价中极为重要的一部分,不仅可以明确噪声特性和人耳听觉之间的关系,还能对车内声品质的改善提供实际工程意义。 为得到更精准的噪声样本集,本文首先通过最小二乘法对截取的噪声样本进行曲线拟合;再反向挑选出原始样本的样本点与拟合点误差平方和最小的样本点所在的时间段,作为实验样本。分别计算实验样本的声压级、响度、粗糙度、尖锐度、抖动度和AI 指数6 个心理声学参数的算术平均值;结合语义细分法,并赋予每个词性数字属性,建立主观评价表,对样本进行主观评价实验,得到评价结果;最后,结合SVR 建立高速列车的车内声品质主观评价LS-SVR 预测模型,并对模型进行对比验证。实验结果说明LS-SVR 模型针对高速列车车内声品质预测是适用有效的。
