基于联合损失函数的多视角步态识别方法研究
2022-05-11赵佳鑫张雅丽施新凯李御瑾
赵佳鑫, 张雅丽, 施新凯, 李御瑾
(中国人民公安大学 信息网络安全学院, 北京 100038)
0 引 言
视频侦查技术具有可以突破时空限制、证据固定等优势,逐步成为公安办案的新手段。 在视频侦查工作中,目标识别与追踪工作一直是案件侦破的重要环节,其效率与准确性至关重要。 犯罪分子因其反侦查意识越来越强,在作案过程中往往是全副伪装,使得很多技术手段受限。 现有的人脸识别技术主要应用在人像卡口或装有高清监控设备的场景下,犯罪嫌疑人在实施犯罪的过程中会故意利用摄像头盲区、伪装人脸图像信息等致使身份无法识别。 而步态识别可以利用现有摄像头进行远距离识别,嫌疑人难以隐藏与伪装,在视频侦查中具有明显的优势,成为近年来身份识别领域研究的热门。
步态识别是一种分析行人走路的姿态,利用算法将其从步态数据库中识别出来的方法,已经在行人无更换外衣、无携带、摄像方向无改变的情况下,具有较高的识别正确率,然而面对复杂的真实场景,该技术仍有许多不容易解决的问题,如:行走路面不平和摄像头角度变化会产生视角问题,有无穿外套和是否携带包裹产生遮挡问题,这些因素导致其在复杂的实际行走过程中识别正确率仍然较低。
本文主要研究基于深度学习的步态识别技术,在GaitSet 模型中利用Triplet 和Softmax 联合损失函数来提升行人在穿大衣和携带包裹这两种情况下的步态识别正确率。
1 研究方法
1.1 GaitSet 网络
识别步态有两种主要方法, 第一种方法将步态视为图像,典型的代表是提取步态能量图。 步态能量图是步态识别任务中最常用的特征图,其主要工作是把一组剪影图对齐压缩成一张图片,利用步态模板对行人进行分类,通过计算在长时间范围内的平均步态剪影,可以减少在预处理阶段中由于处理不完全而残留的噪点。 步态能量图是当前最常用的步态识别方法之一,能够实现计算量与识别准确率相对均衡,一直以来都被当作步态识别的代名词。但这种方法没有考虑到步态中的时序信息和空域信息,其步态识别正确率并不高。
第二种方法将步态视为视频序列来处理,直接从最初的剪影序列中提取步态特征,常使用LSTM方法、3D-CNN 方法或者双流法(two stream)。 视频信号和语音信号都含有时序信息,而LSTM 模型通常用于处理这些带有时间顺序的信息,首先利用卷积神经网络提取每帧视频的步态特征,然后利用LSTM 对时序关系建模;3D-CNN 模型可以处理视频比图像多出的时间维度,常被用于视频分类工作,然而由于其计算任务重以及计算周期较长,往往难以在实际中得到真正的应用。
双流法是包含RGB 图像和光流两个通道的视频行为识别方法。 其中,光流通道被用来建模时序信息, RGB 图像通道被用来建模空域信息,该方法将两个通道进行信息融合,并联合训练,可以很好的建模步态序列中的时序和空域信息,但其往往会受限于一些外部因素。
为了兼顾运算量与识别正确率,Chao 等人提出了一套新的解决方案:把步态特征看作一组由视频帧组成的图像序列。 行走是一种周期性的运动,所以步态可以选用其中一个周期进行表示。 在一个周期的步态序列中,可以观察到不同位置的剪影,都具有可以区别于其他剪影的外形,如图1 所示。

图1 一个周期的步态剪影Fig.1 A cycle of gait silhouette
仅需通过观察步态剪影的大致形状,便能一一分辨,即使面对已经被全部打乱顺序的步态剪影图,也能再次组成其原本正确的顺序。 因此,假定步态剪影的外形本身就包含着顺序,进而剪影图的先后信息将不再是必要的输入,能够直接把步态视为一组图像来提取时序信息。 Chao 等人在此理论基础上,提出了一种GaitSet 深度学习网络模型,添加联合损失函数后网络框架如图2 所示。
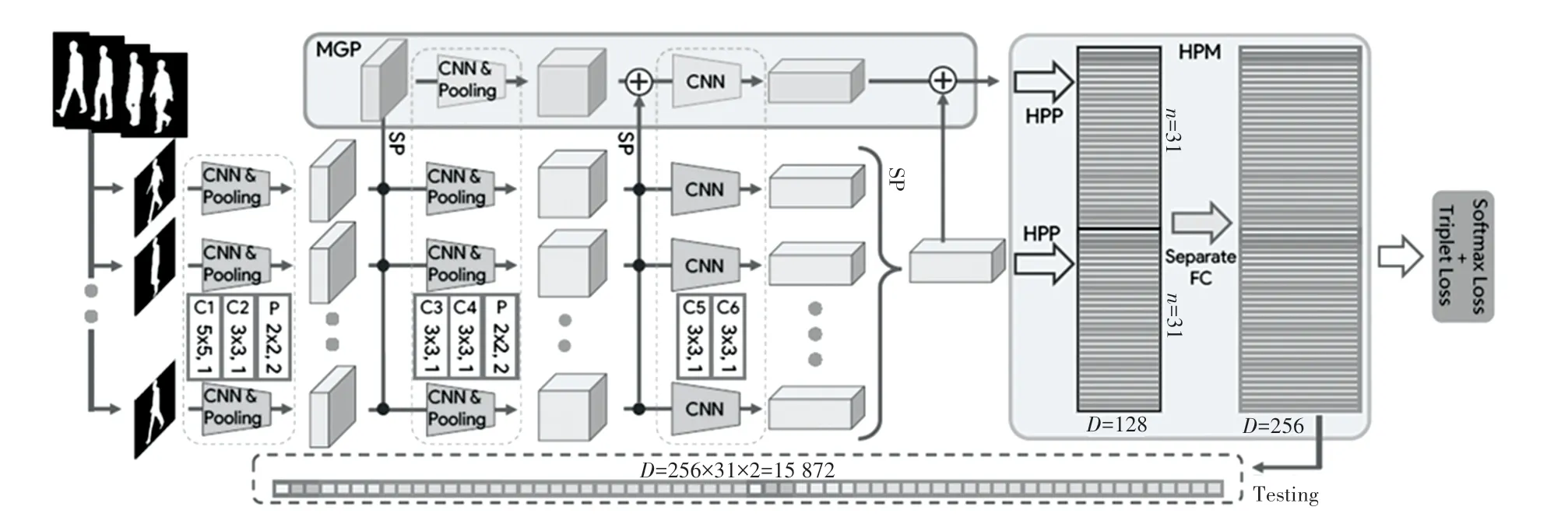
图2 添加联合损失函数GaitSet 框架图Fig.2 GaitSet frame diagram for adding joint loss function
本文采用GaitSet 模型结构。 GaitSet 模型十分灵活,输入仅会对轮廓图的大小加以限制,即输入的序列可以包含有不同角度、具有随意组合的行走状态、数量不受限的、可间断的剪影。 该模型不计算一对步态序列间的相似度,而是直接学习步态的表示。因此,只需要对每个样本的表示计算一次,就能够通过测量不同样本的表示之间的欧式距离来进行分类识别。 GaitSet 极 大 地 提 高 了 在 CASIA - B 和OUMVLP 两大公开数据集的识别性能,显示了其在不同视角和多行走条件下的强大鲁棒性以及对大型数据集的高泛化能力。
1.2 联合损失函数
联合损失函数将多种损失函数结合,起到联合优化的效果。 本文采用Softmax loss 和Triplet loss两个损失函数联合训练的方法,增大步态示例类间距离,缩小步态示例类内距离,使得模型在多个损失函数的优化下,提高表征能力。
Triplet 损失函数通常用于训练差异性较小的示例,其具体公式(1):
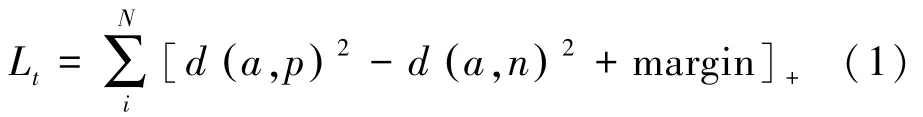
其中,L表示损失;表示锚(anchor)示例;表示正(positive)示例;表示负(Negative)示例;表示一组Batch 中的所有示例个数。
Softmax 损失函数最常用于处理图像多分类任务,其具体公式(2):
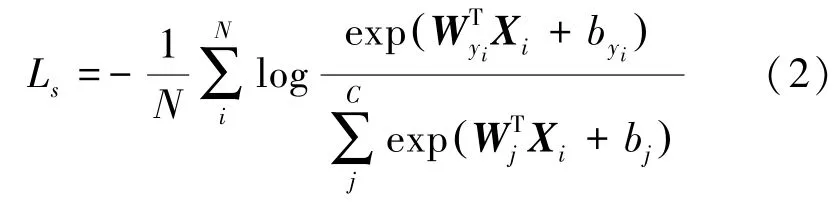
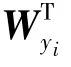
最终的联合损失函数公式(3):
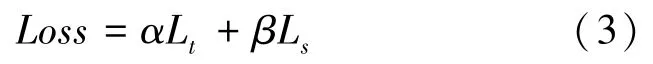
其中,和分别代表Triplet 和Softmax 两个损失函数的权重;当0 且≠0 时为Softmax 损失函数;当0 且≠0 时为Triplet 损失函数;当≠0 且≠0 时为联合损失函数。
2 实验
2.1 CASIA-B 数据集
CASIA-B 是2005 年由中国科学院自动化研究所提出的免费公开人体步态数据集,该数据集是一个具有大规模、多角度、多行走条件等优势的通用数据集,在步态识别领域具有很高的地位。 数据集中的步态信息共包含124 个不同身份的行人(ID 编号为1 ~124),每个行人分别从11 个视角(0° ~180°)对普通行走(NM)、穿大衣(CL)和携带包裹(BG)这3 种行走条件进行录制, NM 行走条件录制6 次、CL 和BG 两种行走条件各录制2 次,视频中某个ID 的行人在普通行走条件下,不同视角的步态图像例子如图3 所示。

图3 NM 类型步态图像示例Fig.3 Example of NM type gait image
2.2 数据预处理
每个数据集具有13 640 个步态视频,同时拥有1 364 个背景视频,总计15 004 个,视频帧的长度也在几个到几百个不等,共占用16 GB 的内存。 而在实验时,在对数据集的信息进行整理分析的过程中,发现026 和027 两个行人ID 的步态视频因为数据本身存在瑕疵而无法正常使用,同时剪影图中行人轮廓在109 号视频中也基本没有出现,所以能用到的视频总共有14 614 个,步态视频约占91%,其余各类视频占9%。 数据经过预处理之后,产生人体步态图像约1 116 300 张,占用内存3.2 GB 左右。预处理后,行人ID 为010,在携带包裹条件下,01 次录制,视角为90°的剪影图像如图4 所示;预处理后,行人ID 为010,在穿大衣条件下,01 次录制,视角为90°的剪影图像如图5 所示。

图4 CASIA-B 数据集预处理后携带包裹剪影图像Fig.4 BG silhouette image after preprocessing of CASIA-B data set

图5 CASIA-B 数据集预处理后穿大衣剪影图像Fig.5 CL silhouette image after preprocessing of CASIA-B data set
2.3 模型训练
在GaitSet 网络模型的基础上,将CASIA-B 数据集采用大样本训练的划分形式。 按照惯例,所划分的训练集部分要完全的输入到GaitSet 网络进行训练。 但在验证的过程中,由于所有行人中的部分步态图像需要作为对照组,所以另一部分未被作为对照而是用作识别的步态图像被称为探针。 因为要均衡NM、BG、CL 三者之间的量,防止其中某一行走条件的信息过多或者过少,所以实验过程中,将所有行人ID 中的nm-05、06、cl-01、bg-01、cl-02、bg-02剪影图像用作识别,剩余的nm-01、02、03、04 剪影图像组成步态图库。
本次实验使用8 个NVIDIA Tesla K80 12 G 显卡,全连接隐层数量为256,学习率为0.000 1,视频提取帧数为30,批尺寸为8×16,三元组损失Margin为0.2,训练轮数80 000。
在训练过程中,把100 轮分为一组,共训练800组,每组的平均损失函数如图6 所示。 可以观察到,与单独使用Triplet 损失函数单调递增趋势不同的是,联合损失函数整体呈现单调递减趋势。 由于训练的所有Batch 数据都是由随机目标ID 的随机类型、随机角度和随机帧序列等组成,所以每个相邻Step 之间都有一定程度的震荡,因此损失值最终能收敛到margin 值附近即合理。
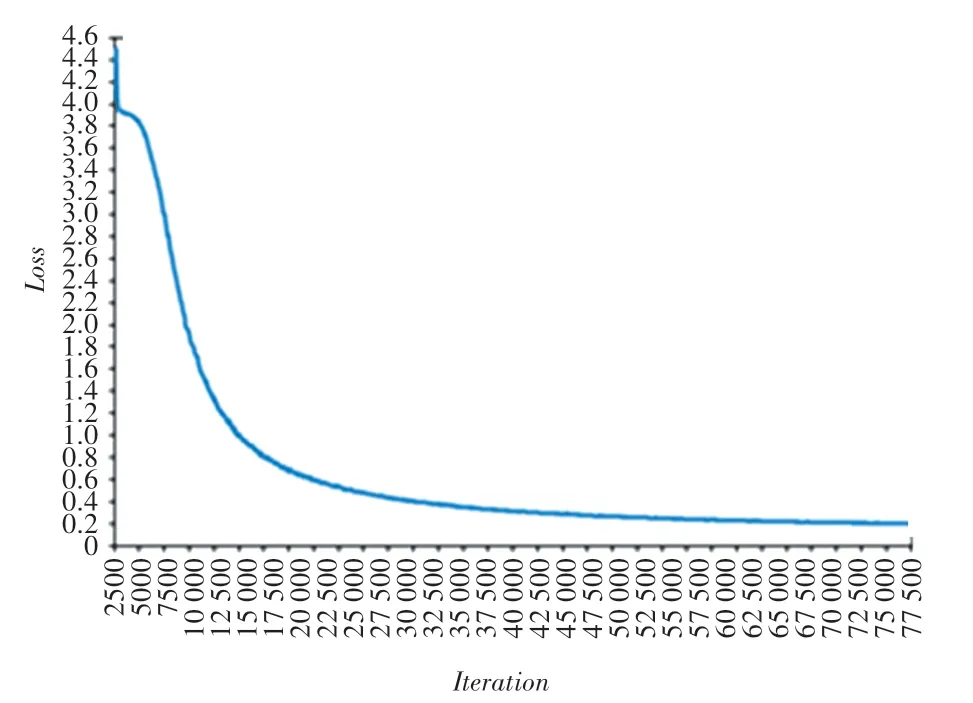
图6 损失函数曲线Fig.6 Loss function curve
3 实验结果分析
3.1 联合损失函数权重取值
在联合损失函数权重的设置中,公式(3)中和的不同取值,会影响模型的最终识别效果,为了达到在穿大衣和携带包裹两种情况下较高的识别正确率,需选取最佳的值和值,本文对和分别采用1:0、0.9:0.1、0.8:0.2、0.7:0.3、0.6:0.4、0.5:0.5、0.4:0.6、0.3:0.7、0.2:0.8、0.1:0.9、0:1,共11 组不同的权重分配方法进行实验,对比结果如图7 所示。
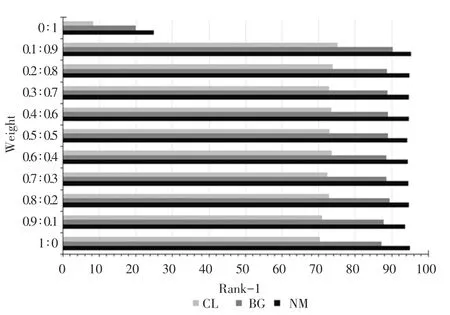
图7 两类损失函数在不同权重下的测试结果对比Fig.7 Comparison of the test results of the two types of loss functions under different weights
当0 且1 时,表示单独使用Softmax 损失函数训练GaitSet,精确度曲线如图8 所示。
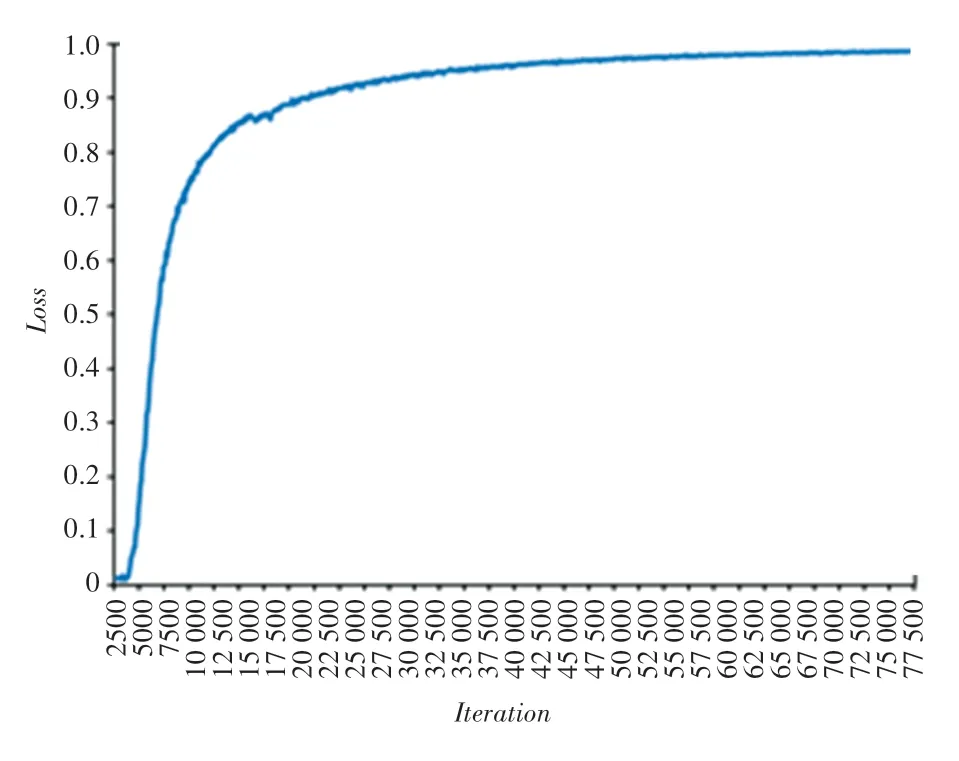
图8 仅使用Softmax loss 训练GaitSet 的精确度曲线Fig.8 Only use the Softmax loss to train the accuracy curve of GaitSet
可以看出,虽然在单独使用Softmax 损失函数训练GaitSet 网络时,最终分类精确度很高,但是在图7 的测试结果中,采用0、1 权重训练得到的模型,在3 种行走状态下的识别正确率都很低,可见Triplet 损失函数是必不可少的;而在Triplet 损失函数和Softmax 损失函数联合训练的测试结果中,穿大衣和携带包裹两种行走条件在所有权重下识别正确率均有不同幅度的提升,其中0.1:0.9 权重的识别正确率提升最大;而在0.2:0.8、0.3:0.7、0.4:0.6、0.5:0.5、0.6:0.4、0.7:0.3、0.8:0.2、0.9:0.1 这几种权重的测试结果中,普通行走条件下的识别正确率相较于GaitSet 原网络均有小幅下降,唯有0.1:0.9权重的识别正确率有小幅上升,所以选定01、09,最终损失函数如公式(4)所示。
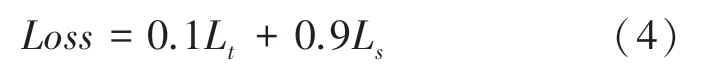
3.2 实验结果分析
在LT 的训练集划分形式下,将本文的实验结果根据行走条件同GaitSet 和CNN-LB 进行对比,记录在11 个不同视角下的识别正确率,并分别计算每种行走条件下的所有视角识别正确率的平均值,结果如表1 所示。
表1 中3 种算法在正常行走条件下的识别情况差别不大,识别正确率都高于91%,尤其是GaitSet算法和本文的方法均已高达95%;在携带包裹的行走条件下,可以推测三种算法都因行人身体被部分遮挡导致识别正确率受到影响,但相对来说,受到影响最小的是本文利用联合损失函数训练GaitSet 网络的方法,步态识别正确率突破90%;三种算法对于行人因穿大衣而导致身体被大面积遮挡的情况,识别效果都不理想,而本文的方法达到了75.1%的识别正确率,具有相对更好的识别结果。
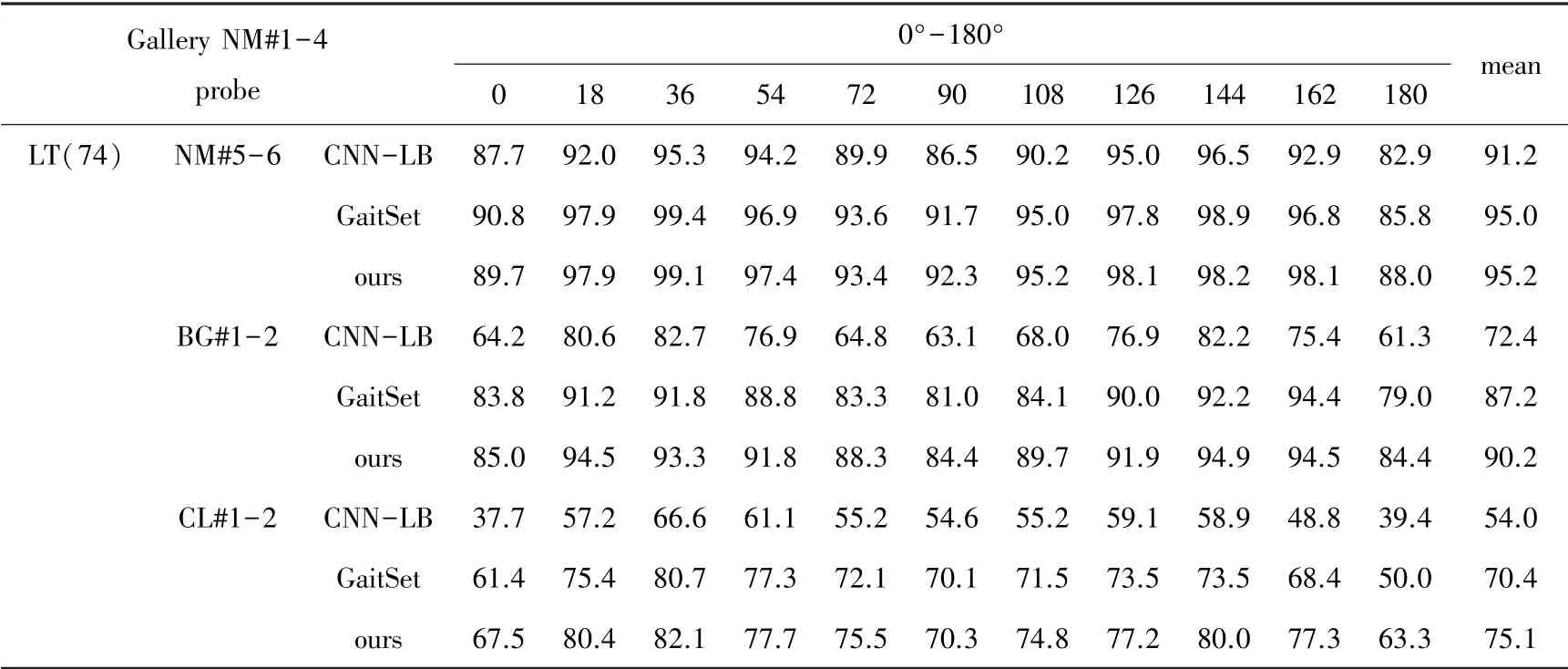
表1 多视角下的步态识别实验结果对比Tab.1 Comparison of experimental results of gait recognition under multiple viewing angles
4 结束语
在多视角的监控视频下,对携带包裹和穿外套的步态识别效果普遍不佳。 针对上述不足,本文提出了一种Triplet 损失与Softmax 损失联合监督的步态识别方法,增强模型的泛化能力,在几乎不增加模型运算量的同时,提高了携带包裹和穿大衣这两种行走状态下的识别正确率。 由于实际场景的复杂性,步态识别技术目前还难以直接应用于视频侦查实战。 但是,当犯罪嫌疑人进行面部遮挡、伪装以及光照条件较差时,人脸识别技术将会受限,步态识别技术可以作为人脸识别的重要补充间接应用于公安实践中。
