大数据环境下的投票特征选择算法
2022-05-10翟俊海黄雅婕申瑞彩侯璎真
周 翔,翟俊海,2,黄雅婕,申瑞彩,侯璎真
1(河北大学 数学与信息科学学院,河北 保定 071000)
2(河北大学 河北省机器学习与计算智能重点实验室,河北 保定 071000)
1 引 言
目前,云计算、物联网和人工智能等技术的不断进步,不仅使技术飞跃式地发展,数据的维度也呈指数型上升,导致大数据问题变得越发突出,但大数据除了带来巨大的价值,其中还存在大量不相关、不完整和有噪声的数据影响计算的性能和模型的鲁棒性,导致计算机存储量巨大和计算复杂度高等问题.为了解决高维数据的问题,特征选择算法已逐渐成为数据挖掘领域中至关重要的组成部分[1].特征选择算法是检测和挑选相关特征并丢弃不相关特征的过程,从高维数据集中挑选出具有代表性的特征子集来代替原始数据集进行计算和存储,使学习者在学习效率、概括能力和便捷归纳模型方面得到巨大改进,以到达数据降维和减少计算复杂度的目的.关于特征选择算法和用于推断模型的归纳学习方法之间的关系,可以区分为4种主要方法:过滤式[2]、封装式[3]、嵌入式[4]和混合式[5].
过滤式方法基于性能度量选择特征,不考虑数据建模算法,先对原始数据集进行特征选择,再训练数据模型.过滤式方法可以对单个特征进行排序或评估整个特征子集.目前,已提出的过滤式方法的度量方法大致可分为:信息、距离、一致性、相似性和统计度量.过滤式方法主要依赖于训练数据的特征进行选择,并且特征选择过程为预处理步骤独立于归纳算法.过滤式方法对比封装式方法具有更低的计算成本,更快的计算速度和更好的泛化能力,但其主要缺点是缺少与数据模型的交互.例如,Hoque等人[6]提出了一种基于互信息的贪婪特征选择方法,将特征互信息和特征类互信息结合起来,最大限度地提高特征之间的相关性,寻找特征的最优子集.Sikonja和Kononenko[7]提出一种属性估计方法称为消除(Relief)算法,Relief算法能够检测属性之间的条件依赖关系,通过回归和分类的训练,将数据统一映射到视图来进行特征选择.Dash和Ong[8]为了克服Relief中存在大量不相关特征和大量噪声的问题,对Relief进行了改进,将Relief进行聚类组成Relief-C(Relief-Clustering)来选择相关的特征以解决此问题.Yu和Liu[9]提出了一种引入了优势相关概念的快速过滤式方法,无需对特征进行成对的相关分析,就可以识别相关特征和消除相关特征之间的冗余.Witten和Tibshirani[10]提出了一种稀疏聚类方法将自适应选择的特征子集进行聚类,并使用套索机制来选择特征.
封装式方法是将数据模型作为选择过程中的一部分,使用训练模型来选择特征子集,其创建的模型被视为黑盒评估器.封装式方法具有与分类器交互和捕获功能相关性的特点,但是计算成本高,且有过拟合的风险,计算效率也主要取决于数据模型的选择.从模型处理性能来说,封装式方法比过滤式方法效果更好,缺点是通常使用迭代计算,计算花销较大,并且只能使用较为简单的模型才能选择出最优的特征子集.对于分类任务,封装器基于分类器评估特征子集,例如朴素贝叶斯[11]或极限分类机[12].而对于聚类任务,封装器基于聚类算法评估子集,例如,Kim等人[13]使用K均值聚类算法来选择特征.特征子集的生成依赖于搜索策略,封装式特征选择的每次迭代都会基于所用的搜索策略,例如前向搜索[14]、后向搜索[15]和启发式搜索策略[16].实际上,封装器不只适用于贪婪搜索策略和快速建模算法,搜索策略和建模算法的任何组合都可以组成封装器.Cortizo和Giraldez[17]提出了一种使用依赖性信息作为指导的搜索最优特征子集的封装器,并选用NaiveBayes分类器作为模型.Liu等人[18]提出了一种用于故障诊断的全局几何相似特征选择算法(GGSS),利用线性支持向量机和回归神经网络(GRNN)建立的分类器进行选择特征.Benot等人[19]使用极限分类器选择出合适的特征子集.刘兆赓等人[20]提出基于森林优化算法的增强特征选择方法(EFSFOA),高效地处理高维数据.
嵌入式方法在训练模型的同时执行特征选择,即将特征选择过程和数据模型训练过程结合在一起,使特征选择和数据模型在一个训练过程中完成,通常嵌入式方法都基于特定的学习模型,所以其性能主要取决于所选的归纳算法.嵌入式方法具有与模型交互、低计算成本和可捕获相关性功能的优点,故嵌入式方法执行效率比封装式方法更高,但是其计算效率主要取决于数据模型.例如,Shuangge等人[21]提出了一种发展式的惩罚特征选择算法,用于高维输入的生物信息学的研究.Zou和Hastie[22]提出了一种使用弹性计算的网络正则化算法(LARS-EN),将弹性计算与线性分类器一起工作,将对模型没有贡献的特征进行剔除.
混合式方法是结合了过滤式方法和封装式方法的优点所构成的特征选择方法.首先,为了减少特征维度空间,使用过滤式方法获得几个候选子集,然后,使用封装式方法来寻找最佳候选子集,故混合式方法通常同时具有封装式方法的高精度和过滤式方法的高效率.例如,Cadenas等人[23]提出了一种以模糊随机森林为基础的特征选择方法,通过将过滤和封装方法集成到一个序列搜索过程来处理低质量的数据,提高了算法的分类精度.Seok等人[24]提出了一种用于特征选择的混合式遗传算法.Ali和Shahzad[25]提出了一种基于条件互信息和蚁群优化的特征子集选择算法.Sarafrazi和Nezamabadi-Pour[26]将引力搜索算法(GSA)与支持向量机(SVM)相结合,提出了一种混合式重力搜索特征选择算法(GSA-SVM).
随着大数据时代的来临,将传统的特征选择算法扩展到大数据环境变得至关重要.近几年,余征等人[27]提出针对海量人像小图片的特征提取方法.Fan等人[28]提出了一种基于不相关回归和自适应谱图的多标签特征选择方法.Rashid等人[29]提出了基于随机特征分组的协同进化特征选择算法(CCFSRFG)对大数据集进行动态分解,提高了相交互的特征分到同一元组中的概率.Long等人[30]提出了一种K均值聚类算法,将特征选择和K-means聚类结合在一个统一的框架中,选择细化后的特征,提高计算性能.赵宇海等人[31]提出一种面向大规模序列数据的交互特征并行挖掘算法,提高了针对序列数据进行特征选择的有效性和执行效率.张文杰和蒋烈辉[32]提出一种基于遗传算法优化的大数据特征选择方法,该方法用特征权重引导遗传算法的搜索,提升算法的搜索能力和获取特征的准确性.胡晶[33]对云计算海量高维大数据特征选择算法进行了研究,针对云计算大数据的高动态与高维度特征,提出了基于竞争熵加权结合稀疏原理的在线学习特征选择算法.
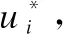
2 基础知识
本节将对本文所涉及的基础知识进行简要介绍,包括决策树算法,MapReduce编程框架模型和Spark编程框架模型.
2.1 决策树
决策树是数据挖掘和知识发现中强大、高效和流行的方法,用于探索大型和复杂的数据集以找到有用的模式.因为决策树支持从大量数据中提取知识和建模,在保证低成本的同时,建模过程更容易,准确和有效,所以决策树算法在包括数据挖掘、机器学习、信息抽取、文本挖掘和模式识别在内的各个学科中都是非常有效的工具.
决策树[36]是为监督数据挖掘设计,并以树状方式分析数据的预测模型,其中每个内部节点代表一个特征的测试,每个分枝代表特征测试的结果,每个叶节点代表类标签.最初,所有数据元祖都在根节点,此时,根节点的入度为零,这意味着没有引入边.决策树通过分割树的分枝来实现分类,其中每个分割点代表对数据属性的测试,以根节点为起点依据每个数据集的属性值划分子节点,在孩子节点上根据数据集的属性值优劣递归划分新的叶节点,这种分割一直持续到终端层,最终一个节点上的所有数据元组都由一个类的样本组成.构建决策树一般采用启发式的方法,即在每次对属性进行分裂时,都自动将满足条件的最优特征作为划分的标准,为的是将选定的数据集进行归纳分类,组成可视化模型.图1为决策树的算法流程图.
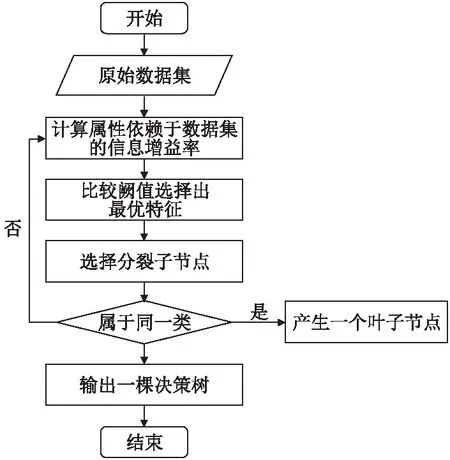
图1 决策树算法流程图
信息熵(entropy)是衡量样本信息的纯度和不确定性的度量,信息熵由公式(1)定义.
(1)
H(D)的值越小,提取D的精确度越高.
信息增益(gain)是衡量特征能为该分类带来信息量的度量,利用属性值A来划分数据集D时所用的信息增益由公式(2)定义.
(2)
g(D,A)越大,就意味着属性A划分的精确度越高.
信息增益率gR(D,A)是由信息增益和分裂信息熵比值决定的信息度量.算法2中使用信息增益率对划分属性进行选择.信息增益率公式(3)定义.
(3)
分裂信息熵Sp(A)是衡量当前分裂的纯度和不确定性的度量,由公式(4)定义.
(4)
信息增益率越高,该属性的纯度越高,即代表该属性具有更高的代表性.
2.2 ID3算法和C4.5算法
ID3(Iterative Dichotomiser 3)算法是Ross Quinlan发明的一种决策树算法,采用自顶向下的贪婪搜索策略,遍历所有可能的决策空间.主要基础为奥卡姆剃刀原理,即用较少的计算代价做更多的事,越是小型的决策树越优于大型的决策树.核心思想就是以信息增益来度量属性的划分,选择分裂后信息增益最大的属性继续进行分裂,直到满足终止条件.算法1为ID3算法伪代码.
算法1.ID3算法
输入:训练样本S;
输出:一棵决策树Ti.
1.初始化阈值;
2.判断该样本的类别,若为同一类Di,则标记类别为D,并返回单节点树T,否则执行下一个样本;
3.判断属性,若为空则返回T,并标记该类为样本中输出类别D中样例最多的类,否则执行下一个样本;
4.根据当前划分,计算S中各个属性对D的信息增益,选择出其中信息增益最大的属性AMax;
5.若AMax的信息增益小于阈值,返回T;否则,按AMax的不同值AMaxi将对应的D划分为其他类别,每类产生一个子节点,对应属性值为AMaxi,增加T;
6.D=Di,A=AMax,在所有子节点递归调用2-5步;
7.得到子树Ti并返回.
本文使用的C4.5算法也是由Ross Quinlan开发的用于产生决策树的算法,该算法是对ID3算法的一个改进,将ID3使用的信息增益改为更有说服力的信息增益率来建树,使C4.5算法产生的决策树产生的分类更易于理解,准确率更高.算法2为C4.5算法伪代码.
算法2.C4.5算法
输入:训练样本S;
输出:一棵决策树Ti.
1.设置根节点N;
2.若S属于同一类,则返回N为叶节点,标记为类C;
3.Ifattributes=null或S中剩余的样例数少于阙值,返回N为叶节点,标记N为S中出现最多的类;
4.For eachattributes
5.计算信息增益率,找出attributes中信息增益率最高的属性;
6.End for
7.For新的叶子节点
8.若该叶子节点样本子集S′空,则分裂此叶子节点生成新叶节点,并标记为S中出现最多的类;
9.Else
10. 在该叶子节点上继续分裂;
11.End for
12.后剪枝.
13.得到子树Ti并返回;
2.3 MapReduce和Spark基础介绍
Hadoop是一个由Apache基金会所开发的开源分布式计算平台,目前已成为工业界和学术界进行云计算应用和研究的标准平台.Hadoop最先受到Google Lab开发的GFS和MapReduce的启发,后逐渐发展到现如今的规模.Hadoop的核心组件为HDFS和MapReduce,HDFS(Hadoop Distributed File System)是Hadoop的高性能、高容错和可扩展的分布式文件存储系统,为海量的数据提供了多种的存储方式和巨大的可用空间,MapReduce是并行处理大规模数据的分布式运行框架,为用户提供了计算.在Hadoop框架上,可以将成百上千个节点组成的大规模计算机集群规范整理为大数据开源平台,用户基于此平台可编写处理大规模数据的并行分布式程序.Hadoop具有高可靠性、高扩展性、高效性、高容错性、低成本等优点,现已被全球几大IT公司用作其“云计算”环境中的重要基础软件.
Spark是一种用来实现快速和通用计算的集群数据平台,最初于2009年在加州大学伯克利分校AMP实验室诞生,到现在,Spark已经成为一个功能完善的生态系统.Spark扩展了MapReduce计算模型,可以高效地支持更多的计算模式,包括流的处理、交互查询和迭代计算.Spark在满足简单和低能耗的前提下将各种处理流程整合为一套流程,使其在统一的框架下支持不同的计算模式,大大减少了原先需要对各种平台和信息分别处理的问题.
3 大数据环境下的投票特征选择算法介绍
本节首先介绍大数据环境下的投票特征选择,然后分别介绍在MapReduce平台和Spark平台上实现大数据投票特征选择算法的具体实现思路.图2为大数据投票特征选择流程图.
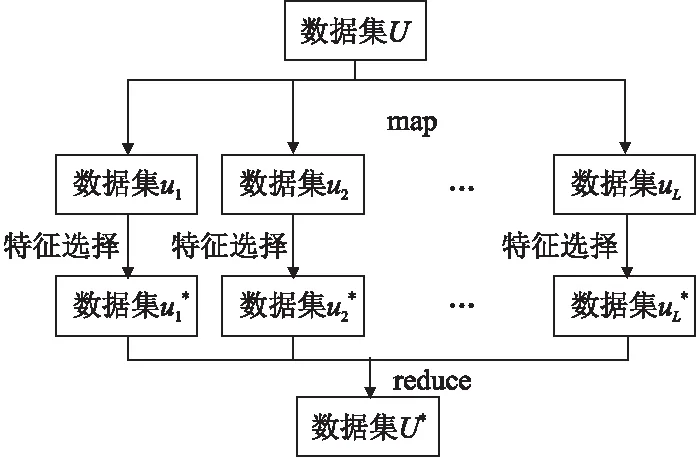
图2 大数据环境下的投票特征选择算法流程图
其中,使用决策树算法的目标就是从训练数据集上归纳出一组分类规则,决策树分类器通常分为3个步骤:选择最优特征、决策树生成和决策树剪枝.选择最优特征的标准就是判断一个特征对于当前数据集的分类效果,在当前节点根据信息增益率作为判断进行切分,按照切分后节点数据集合中的分区有序程度找到局部最优的特征,然后将不同分类的数据尽可能分开.划分后的分区数据越纯,证明当前划分规则就越合适.生成决策树模型后,对决策树进行剪枝操作,即后剪枝,将决策树模型中的冗余子树用叶节点来代替,防止过拟合,提高决策树计算精度和泛化能力.
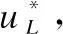
算法3.大数据环境下的投票特征选择算法
输入:数据集U;
输出:数据子集U*.
1.初始化空集U*用于储存特征选择的集合;
2.将特征选择的数据集进行预处理;
3.其中将U随机分成L份部署到L个节点上;
4.对数据子集UL使用决策树算法进行分类,训练出决策树分类器DT;
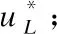
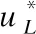
8.ReturnU*.
3.1 MapReduce环境下的投票特征选择算法的实现过程
本文主要解决大数据中高维数据处理的问题,结合对决策树分类算法和大数据平台的分析,将本算法在MapReduce并行计算框架下进行实现,可以有效地对高维数据执行特征选择.同时,将高维数据集在MapReduce框架中进行建树分类的操作,既提高了算法的容错率,减少了算法的时间复杂度,实现了算法的可扩展性,还可根据算法的实际处理效率对MapReduce框架进行计算空间扩展.算法4是在MapReduce框架上的投票特征选择(记为MR-VT-FS)的计算流程,MapReduce分为Mapper和Reducer阶段.
算法4.MR-VT-IS算法
Mapper阶段
1. 数据预处理;
2. 初始化空集F,存放选择出的特征子集;
3.DecisionTreetree=newDecisionTree(numFeatures);
4.List
5.tree.train(trainData,features);
6. 计算特征的对于tree分类器的信息增益率,选择出大于阙值的特征
Reducer阶段
1.tree=train(v2);
2.vote=Tree(features);
3.context.write(features,vote);
4.ReturnU*.
3.2 Spark中的投票特征选择的实现过程
在Spark并行计算框架下,决策树分类首先查找可能划分的分裂点(split)和桶(bin),然后针对每次划分split,计算每个样本应该所属的bin,通过聚合每个bin的属性信息计算每次split的信息增益率,并选择信息增益率最大进行划分split,按照该划分split对当前节点进行分割,直到满足终止条件.为了防止过拟合,采用后剪枝,即在构造决策树完成后进行剪枝,作为终止条件,本文设定阙值来停止创建分枝.算法5为Spark中的投票特征选择算法(记为Spark-VT-FS).
算法5.Spark-VT-FS算法
输入:训练集T;
输出:被选出的特征集合U*.
1.对训练集中的样本进行预处理;
2.将数据广播到L节点;
3.在L个子节点训练出L个DecisionTree分类器;
4.TREERDD=dataRDD_.mapPartitions();
5.计算特征的信息增益率,选择出大于阙值的特征
6.vote=DecisionTree(features);
7.//投票筛选数据集合U*.
4 实验结果与分析
4.1 实验环境
实验所用到MapReduce和Spark大数据平台,设置如下,由1个主节点和7个从节点结构,用千兆以太网交换机H3C S5100连接,平台操作系统为CentOS 6.4,CPU为Intel E5 2.20GHz,Hadoop版本是2.7.1,Spark版本是2.3.1.客户端开发环境为Idea,JDK版本为jdk-1.8.0_144-windows-x64,表1为集群环境配置的详细信息表.
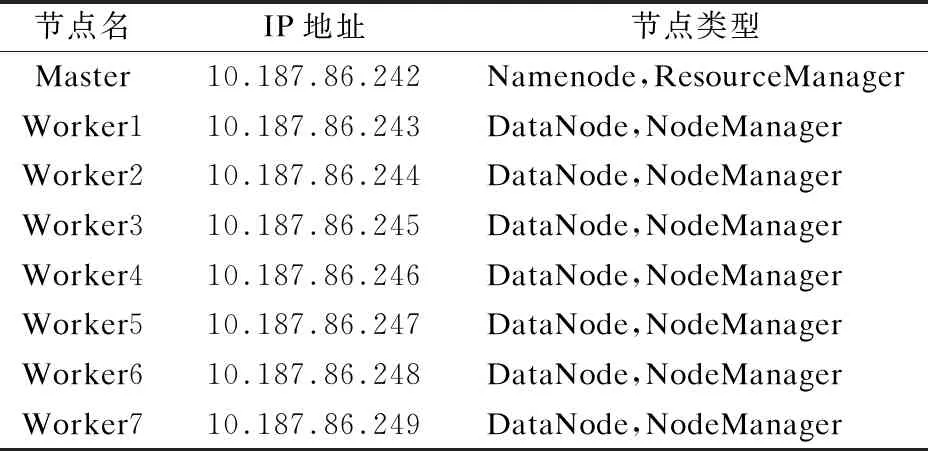
表1 平台各节点配置详情
4.2 实验指标
本实验的评价指标为选择出的特征数、测试精度和运算执行时间.
选择出的特征数:进行特征选择后选择出的特征数,特征数越少,越能验证大数据环境下的投票特征选择算法选择特征的有效性.
测试精度:数据集划分为训练集和测试集,训练集训练出的分类器,用测试集对分类进行测试,测试结果为测试精度,测试精度越高,证明特征选择算法的性能越好.
运算执行时间:从开始到完成大数据环境下的投票特征选择所花费的时间.
4.3 实验数据
本实验采用UCI数据集进行训练,将数据进行归一化处理提高计算的精度.所选的数据集均为含有类标的高维数据集,其中含有一定的噪音,比较适合验证特征选择的实验结果.Hadoop与Spark平台的实验数据信息如表2所示.
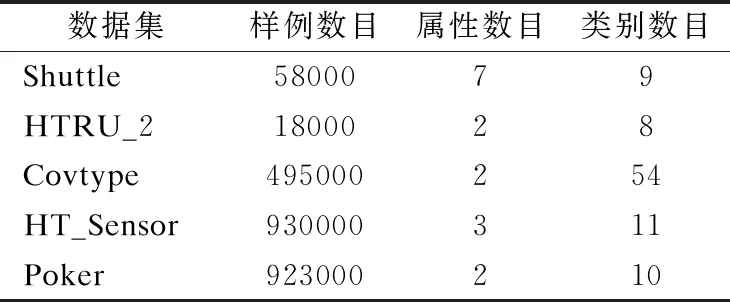
表2 数据集基本信息
4.4 MapReduce和Spark平台上的实验对比与分析
本小节主要是对在MapReduce和Spark平台实现的大数据投票特征选择算法进行实验对比,实验比较的结果列于表3中.
由表3实验结果可知,对于不同的数据集,在测试精度数值方面MR-VT-FS和Spark-VT-FS算法近乎相似,由MapReduce和Spark运行逻辑和本文算法结构可知,MapReduce和Spark都采用分布式处理,并且执行相同运算逻辑的算法,选择出的特征也基本相同,故在测试精度相仿,但两种算法的在不同的平台上所运行的时间有着很大的差距,主要原因是在MapReduce和Spark大数据处理平台上在数据处理方面采用完全不同的两种策略,在Spark平台上对数据进行分区操作时虽然会产生比MapReduce更多的中间文件,但是在数据传输方面采用导管式传输,很大程度地减少了中间数据传输时间.在同步方式上,MapReduce采用同步式执行方式,当所有Map端的任务完成后,才会继续执行Reduce端的任务,而Spark采用异步式执行方式,各个节点独立地执行计算,加快了运算效率,节省了中间数据排序时间,所以在运行时间上Spark会比MapReduce上节约更多时间.但也不意味着MapReduce对比Spark平台没有优势可言,在稳定性方面MapReduce更加具有优势,在处理中间数据时,MapReduce会等待中间数据全部保存后再进行后续计算,使性能方面的要求减弱,保证算法运行更为稳定,适合长期后台运行.当处理需要长期存储的数据时MapReduce中的HDFS可以提供多种存储方式和巨大的存储空间,此外,MapReduce还具有安全功能和控制权限功能,所以MapReduce在稳定性上更具有优势.
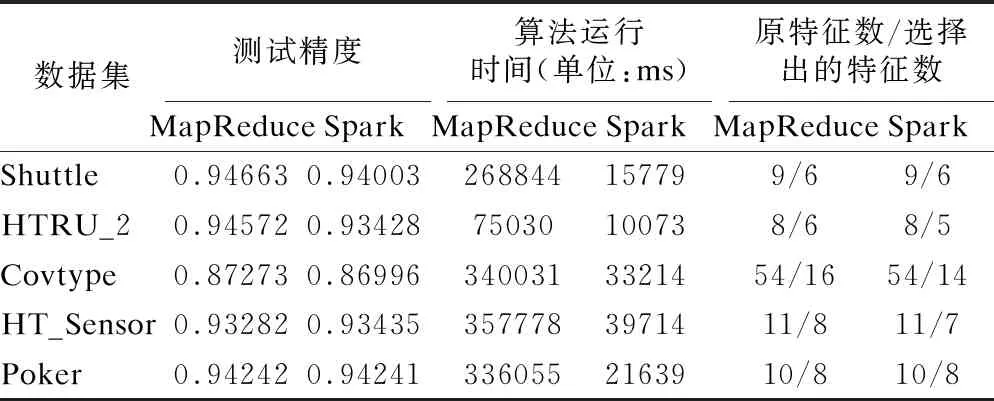
表3 MapReduce和Spark上各数据集实验的比对
综上所述,虽然在MR-VT-FS和Spark-VT-FS算法的程序运行思想和算法逻辑相同,但在两个平台采用了两种不同的执行方式,导致在算法执行效率上差异较大,在数据的传输调度方面,MapReduce会对数据进行暂存,当满足执行下一步的条件,才会对数据进行处理,而Spark采用导管式传输,将数据直接进行处理,大幅减少了同步的次数和传输时间,所以Spark在算法运行时间上有更好的表现.但在稳定性方面,MapReduce提供了相对简单的运行框架、丰富的存储资源和诸多安全保障功能,使MapReduce在计算稳定性上表现更佳.
4.5 与其他算法的实验对比与分析
表4是本文算法与单变量特征选择算法和基于遗传算法的特征选择算法对相同的高维数据集进行特征选择的实验结果.
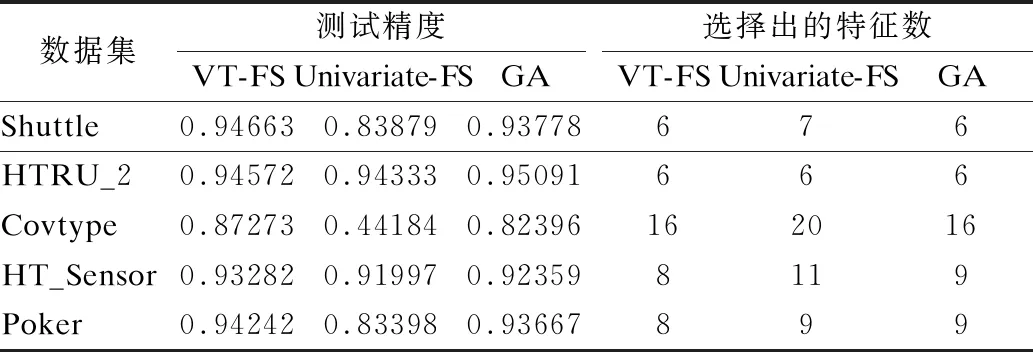
表4 在不同数据集上特征选择实验结果
单变量特征选择算法(Univariate feature selection)是一种常用的特征选择方法,该方法思路简单,具有通用性,采用卡方检验来对数据集的每个特征进行评价,从而衡量每个特征对分类的贡献大小,选择出对分类贡献最大的若干个特征.遗传算法(GA)是一种模拟进化算法,通过数学方式模拟生物界中的进化过程,借助群体搜索来搜寻最优个体,找到问题的最优解.GA算法其中每个个体由一串0-1码表示,1表示选取该个体,0表示不选该个体,通过模拟交叉、变异、选择来模拟生物界中生物进化的过程,通过选择适应度最优的个体来完成特征选择.
在搜索策略方面,本文算法和遗传算法都属于群体搜索,单变量特征选择属于逐个搜索,通过不同的搜索方式,便于比较算法的性能优劣.在算法逻辑方面,本文算法和遗传算法都属于迭代算法,但不同的是遗传算法计算的是最优生存率,决策树算法计算的是当前特征的最优适应程度.为了便于与本文算法进行比较,将选出的特征的参数设置为与本文选出的特征数相同.
从表4可以看出,在较小的数据集中,本文算法和Univariate-FS、GA算法的测试精度近似相同,但是随着数据规模的增大和维度的提升,本文提出的方法具有更高的测试精度,代表具有更优的计算性能.而从选择出的特征数上来看,本文算法选择出的特征集,在维度较低的数据上选出的特征数几乎相同,但在高维度的数据集上选择出了更少的特征,证明本文算法提出的大数据环境下的投票特征选择算法,可以有效地从高维数据集中选择出更具代表性的特征子集,降低高维数据集的维度.通过极限学习机(ELM)[37]对原始数据集和选择出的特征子集进行比对验证,发现选择出的特征子集可以有效地代替原数据集进行计算,达到了数据降维和降低计算复杂度目的.
5 结 论
本文提出了大数据环境下的投票特征选择,在MapReduce和Spark大数据处理平台上都进行了算法实现,并基于提出的算法在对MapReduce和Spark大数据处理平台进行了比较.此外,提出的算法还和单变量特征选择算法与基于遗传算法的特征选择算法进行了实验比较.从MapReduce和Spark大数据平台的实验对比来看,因两平台对文件执行方式和传输方式的不同,导致本算法在两个大数据平台上的适用程度有所不同,实验指标中,测试精度和选择出的特征数相近,而在算法执行时间上有较大差异,而差异主要在于MapReduce平台提供的是更好的稳定性和容错性,而Spark平台上保证的是算法具有更高的执行效率.从本文提出的算法与单变量特征选择算法和遗传算法的实验结果比较发现,本文提出的算法对高维数据集进行特征选择时,具有更高的计算精度,选择出的特征子集更加精炼,证明本文提出的大数据环境下的投票特征选择算法在高维数据特征选择上具有更优的执行效率,并且能选出更具代表性的特征子集,降低数据维度.综上所述,本文提出的算法是行之有效的.
