新能源专利文本术语抽取研究
2022-05-10陈海涛吕学强游新冬
孙 甜,陈海涛,吕学强,游新冬
1(北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101)
2(北京信息科技大学 外国语学院,北京 100192)
1 引 言
新能源主要是指可再生、可持续的非传统清洁环保能源.新能源产业主要是指将太阳能、地热能、风能、海洋能、生物质能和核聚变能等非传统能源产业化的一种高新技术产业[1].基于1995-2019年全球以及中国专利公开的新能源产业数据信息统计,中国新能源专利总申请量为423134件,全球新能源专利总申请量为1734849件,年均申请增长率保持稳定,这表明世界各国政府和企业的大力关注和支持[2].如何推动中国专利文献走向世界,更快速更准确地翻译专利文本成为一个值得关注的问题.
当前专利文献的翻译方式主要有两种,一种是经由专业领域人士的翻译,但高质量翻译是一项高要求且耗时的生产任务,对人类翻译专家的要求较高,能满足该要求的合格翻译人才比较缺乏,况且由于专利文献具有新颖性、可靠性和权威性的特点,翻译人员在翻译过程中需要利用领域术语表来把握对领域术语的准确翻译,术语库的构建就显得尤为重要.另一种翻译方式是先对专利文本进行机器翻译,然后再进行译后编辑,据统计,市面上翻译引擎对专利文本的翻译经常存在语义缺失、语义不准确、术语错误等问题,其中术语错误更是占了翻译错误的很大比例[3],这就对机器翻译技术提出了更高的要求,如何利用术语词表改进机器翻译的质量值得深入研究.无论是人工翻译还是机器翻译,都离不开领域术语库的构建,这些现象都凸显了领域术语抽取的重要性.
专利文献中的领域术语为专利文献分析提供了结构化知识单元,这些领域术语为查阅人员准确且快捷的掌握专利方向及其核心技术带来了很大的方便.从专利文献中自动抽取术语,构建术语库的过程,对于机器翻译[4]、对话系统[5]、信息检索[6]等方面发挥着重要的基础性作用.随着科学技术的不断发展、大量新能源领域专利文本的不断申请,新能源领域术语的抽取需求也在与日俱增,往日依靠人工方法收集和传统机器学习算法来抽取领域术语的方法也往往有其自身的局限性,还有很大的改善空间,利用深度学习实现更高效、更准确的自动抽取领域术语的方法已经成为必然的发展趋势.
针对新能源领域专利文本进一步提升术语抽取准确率的任务,本文提出了基于BERT-BiLSTM-CRF的新能源专利术语抽取方法,主要包括以下3个贡献点:1)构建了一个新能源领域专利文本的语料库以及领域词典,包含3002条新能源专利语料以及26873个术语词汇.2)提出了基于BERT-BiLSTM-CRF的新能源专利术语抽取研究方法,通过BERT预训练模型对新能源专利文本进行文本向量化,以更好地捕捉文本的语义,与其他深度学习抽取模型相比,本文提出的方法在准确率、召回率和F1值均有了显著提升.3)在新能源专利文本语料上的实验表明,本文提出的方法能有效识别字符较多的新能源专利长序列术语,对领域词典的构建起到了很大的帮助作用.
2 相关研究
领域术语的抽取作为一项基础性的研究,国内外也已经有许多学者对其抽取方法做了很多工作,研究方法主要包括基于规则、统计以及规则与统计两者相结合的方法.2010年周浪等人[7]通过分析词组型术语的特点及其在语料中的分布特征,使用子串归并、搭配检验和领域相关度计算技术3个方法有效提升了低频术语和基础术语的排序位置,但缺陷在于研究者需具备丰富的语言知识来制定抽取术语所用的语言规则,语言学规则制定难度大,耗时耗力.2014年刘辉等人[8]分析了通讯领域的术语,并根据其特点制定规则进行人工标注,使用基于字符级特征的条件随机场进行实现,分别达到了80.9%、75.6%、78.2%的精确率、召回率和F值.这种方法虽然优于将词和词性作为特征来进行抽取,但是不利于在大规模语料上进行,因为规则制定需要具备领域知识的专家,而且人工标注比较耗时耗力.2015年何宇[9]选取了6种特征,分别是词、词长、词性、依存关系、词典位置和停用词作为特征模板,利用条件随机场模型有效抽出了新能源汽车领域的术语,但该方法只提高了短术语抽取的效果,对长术语的抽取仍存在缺陷.综上所述,利用基于统计和规则的方法虽然取得了一定的效果,但专业领域的中文术语实体识别仍旧依赖人工界定的特征和领域专业知识,术语的识别精确率和召回率因受到特定领域情境的限制而无法推广应用.
神经网络的深度学习方法和基于规则或统计机器学习的方法相比,有更强的泛化能力,更少依赖人工特征选择的优点.深度神经网络采用基于词向量的特征表示,把词向量作为深度神经网络的输入,自动学习文本上下文深层语义信息,把术语抽取任务转化为序列标注任务,很大程度上减少了对人工特征和领域知识的依赖.2015年Huang等人[10]构建了Bi-LSTM-CRF模型,BiLSTM模型用于获取输入文本到深层隐藏特征并输出,将BiLSTM的输出作为CRF模型的输入,实现了对文本信息的序列标注.2017年Gridach[11]首次在生物医学领域利用BiLSTM-CRF实现了字符级神经网络的命名实体识别并达到了90.27%的准确率.2018年孙娟娟等人[12]构建了Character-LSTM-CRF实体识别模型,并以字向量作为模型的输入,避免了分词不准确对命名实体识别效果造成的影响,实现了对渔业领域命名实体识别的研究.2019年武惠等人[13]提出了一种基于实例的迁移学习算法,将源域的知识迁移到目标域,有效缓解了对人工特征和专家知识的依赖,在小规模数据集上取得了80.0%的F值.2019年张应成等人[14]应用包含词向量层、BiLSTM网络层、CRF层结构的BiLSTM-CRF模型,以50000条招标平台上的招标文件为语料,对招标人、招标编号、招标代理进行了识别,F1值最高达到了87.86%.他的研究也进一步指出,BiLSTM方法优于LSTM方法,并且引入CRF算法可以给不同模型带来程度不等的效果提升.2019年马建红等人[15],提出了一种基于attention的双向长短时记忆网络与条件随机场相结合的领域术语抽取模型,并使用基于词典与规则相结合的方法对结果进行校正,准确率可达到86%以上.2020年李灵芳等人[16]利用中文电子病历提出了BERT-BiLSTM-CRF命名实体识别模型,在准确率、召回率、F1值3个方面都有显著提升.
鉴于近年来BERT预训练语言模型[17]在英文自然语言处理(NLP)任务中的优异表现,自动挖掘隐含特征可以有效解决发现新词的特点,同时减少人工定义特征和对领域知识过度依赖的问题.本文从深度学习的角度出发,提出基于BERT-BiLSTM-CRF的新能源专利术语抽取模型.该模型首先利用BERT中文预训练向量将新能源专利文本转为字符级嵌入向量训练出单词的字符集特征,然后将字符集特征输送到BiLSTM模型进行训练,更深层次地挖掘专利文本中术语与其它词汇之间的语义信息,更好地捕捉前后文隐含的信息,最后与CRF层相结合,解决输出标签之间的依赖关系问题,得到全局最优的术语标记序列.
3 基于BERT-BiLSTM-CRF的术语抽取模型
近年来不依赖人工特征的端到端BiLSTM-CRF模型成为术语识别的主流模型,随着自然语言处理在深度神经网络模型研究的不断深入,不少研究指出,经过预训练的词嵌入模型能更好理解文本语义信息,应用到专业术语识别这一类的命名实体识别任务中能取得不错的效果,提升后续实验任务的准确性.
3.1 BERT-BiLSTM-CRF新能源专利术语抽取模型整体框架
BERT-BiLSTM-CRF新能源专利术语抽取模型整体结构如图1所示,首先是BERT预训练语言模型层,被标注的字符级语料经过该层将每个字符转化为低维词向量.其次是BiLSTM层,将上一层输出的词向量序列输入到这一层进行语义编码,自动提取句子特征.最后是CRF层,利用这一层解码输出概率最大的预测标签序列,得到每个字符的标注类型,对序列中的实体提取分类,最终实现新能源领域专利术语的抽取.该模型与其他深度学习术语抽取模型相比最主要的区别是利用了Google在大规模中文语料上习得的BERT预训练中文向量,因为其更强的上下文长距离语义学习能力,可以更好地解决字向量一词多义的问题,更深层次挖掘新能源领域专利文本的特征,为下游任务提供更丰富的语义信息.

图1 BERT-BiLSTM-CRF新能源专利术语抽取模型
3.2 BERT预训练语言模型
从one-hot语言模型的提出,再到Word2Vec[18]、Glove[19],近几年又有ELMO[20]、GPT[21]到BERT预训练模型的出现,语言模型的发展对文本语义的表征理解越来越充分.2018年Devlin等人提出的BERT模型综合了ELMO和GPT两者的优势,利用Transformer[22]的编码器作为语言模型的基础,从前后两个方向捕获句子的信息,self-Attention机制获取单词与单词之间的语义权重,相应生成的字嵌入分布式表示具有更强的语义表征优势.
Transformer之所以具有较强的特征提取能力,是由于其内部的多头注意力机制.self-attention机制主要是根据同一个句子中词与词之间的关联程度调整权重系数矩阵来获取词的表征,也就是说,BERT模型对每个单词编码时,都会考虑到句子中其他单词的语义权重,因此具有很强的编码能力.具体操作可以解释为:首先向量经过3个不同的全连接层,得到Q,K,V3个向量,然后Q和KT进行矩阵相乘得到单词和其他单词相关程度的向量QKT.最后将标准化的QKT放入到softmax激活函数中,得到词与词之间的关联度向量,再乘以V得到最终向量,如公式(1)所示:
(1)
再通过多头结构拼接向量结果:
MultiHead(Q,K,V)=Concat(head1,…,headh)WO
(2)
(3)
为了使网络更容易训练,Transformer还引入了残差连接和层归一化:
(4)
FFN=max(0,xW1+b1)W2+b2
(5)
为了解决注意力机制不提取时序特征这个问题,Transformer在数据预处理前加入了位置编码,并与输入向量数据进行求和,得到句子中每个字的相对位置.
(6)
(7)
最后,BERT将位置嵌入和词嵌入拼接起来作为模型输入,如图2所示.

图2 Transformer的编码器
3.3 BiLSTM层
LSTM的全称是Long Short Term Memory,它是循环神经网络RNN的一种变体,巧妙地运用了门控概念实现长期记忆,有效解决了RNN训练时所产生的梯度爆炸或梯度消失的题,非常适合文本类时序特征的数据,单元结构如图3所示.
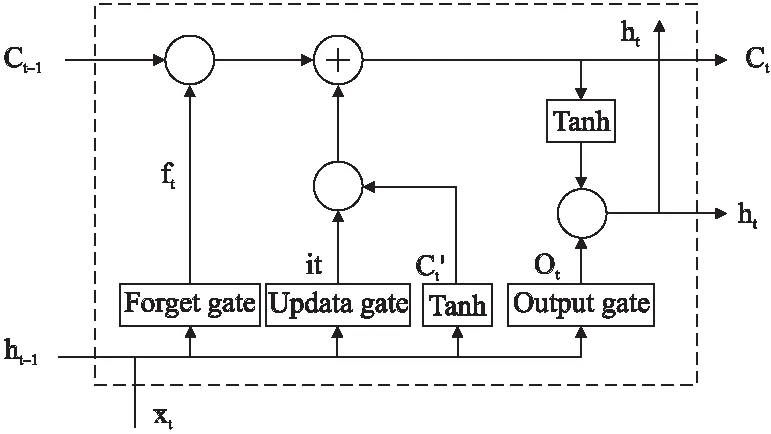
图3 LSTM单元结构
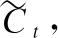
it=σ(Wxixt+Whiht-1+Wcict-1+bi)
(8)
ft=σ(Wxfxt+Whfht-1+Wcfct-1+bf)
(9)
ct=ftct-1+ittanh(Wxcxt+Whcht-1+bc)
(10)
ot=σ(Wxoxt+Whoht-1+Wcoct+bo)
(11)
ht=ottanh(ct)
(12)
改进的LSTM通过门控机制实现长时序类型数据的编码,但是单向的LSTM只能对数据从一个方向编码,即无法编码从后到前的信息,这就导致句子语义理解不充分.BiLSTM综合考虑了正向特征提取和逆向特征提取,构建了两个方向相反的隐藏层,通过这种方式,BiLSTM可以更好地捕捉双向的语义依赖,取得更好的语义表达效果.
3.4 CRF层
输出的预测标签之间的依赖关系也是术语抽取很重要的一个方面.比如以“I-TERM”作为单词首词的标签就是一个非法标签,因为一个单词只可能是两种情况,一种是术语,标签是“B-TERM”,一种不是术语,标签是“O-TERM”,利用条件随机场模型[23]则可以规避这种非法情况的发生.通过为预测的标签添加一些约束,通过概率转移矩阵捕捉标签之间的依赖关系,排除非法用语的情况,获得一个最优的预测序列,弥补BiLSTM的缺点.
对于任一给定的输入序列X=(x1,x2,…,xn),其对应标签序列Y=(y1,y2,…,yn)的CRF评估分数函数可以由公式(13)表示:
(13)
公式中的W表示转移分数矩阵,Wyi-1,yi表示标签yi-1转移到标签yi的分数,Pi,yi表示第i个词xi映射到标签yi的非归一化概率.
预测序列概率p(Y|X)可以通过如下的softmax函数来进行计算:
(14)
两头取对数得到预测序列的似然函数:
(15)
(16)
4 实 验
本文利用BERT-BiLSTM-CRF模型抽取面向新能源领域的专利术语,整体流程如图4所示,主要包括以下几个方面,分别是新能源领域专利文本数据集的获取与处理、新能源领域术语词典的构建、语料的自动标注及人工校对、模型训练和结果评测.
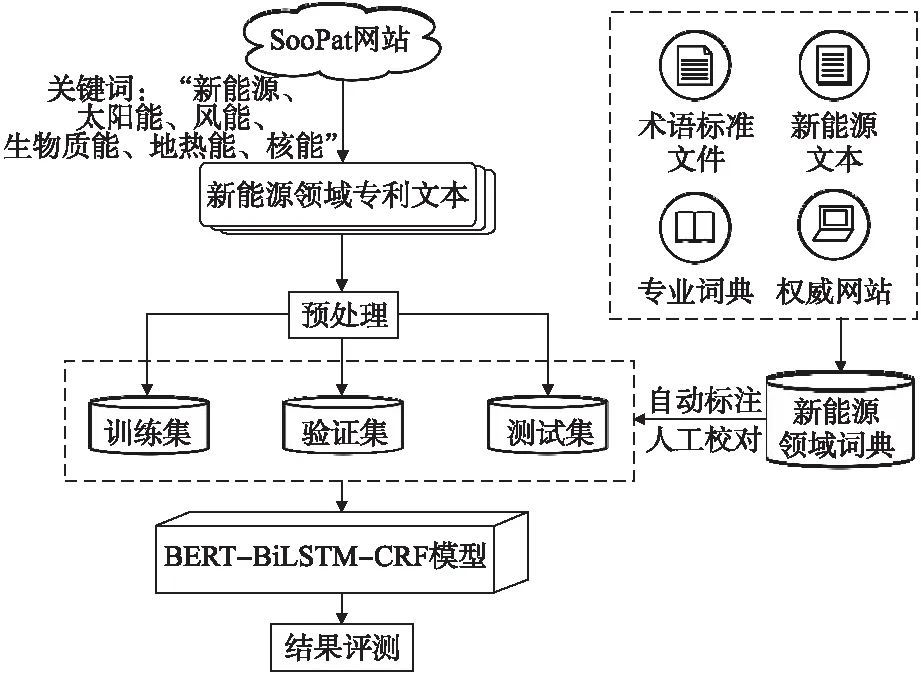
图4 实验整体流程图
4.1 新能源语料及术语库的构建
本文实验所采用的新能源领域的专利文本是从SooPAT网站(1)http://www.soopat.com/上下载下来,然后经过处理手工构建的语料.以“新能源”、“太阳能”、“风能”、“生物质能”、“地热能”、“核能”为关键词对新能源专利进行搜索,将获取下来的专利文本按一定规则进行预处理,以句号为分隔符将摘要和权利要求书进行切分,并进行标点符号规范化处理,随机挑选其中3002条数据用作实验对象,2101条句子用于训练,601条用于验证,300条用于测试.
新能源领域术语集的构建大致可以分为两类:一类是对现有术语资源的整理,主要参考了《GB/T 10097-2018地热能术语》《GB/T 30366-2013生物质术语》《GB/T 33543.1-2017海洋能术语第1部分通用》《GB/T 24548-2009燃料电池电动汽车术语》等标准文件中所包含的术语词条以及专业词典、相关论著、权威网站涉及到的专业术语等.另一类是对新能源专利文本里涉及的术语进行手工识别和整理.筛选的标准参考了标准文件中的样式,术语需要具有领域代表性、单义性、准确性和简明性,根据实际情况,对新能源领域术语集进行了修正和更新,术语样例展示如表1所示.通过对以上资料进行整理及人工筛选,总共得到新能源领域术语26873个,其中训练集中包含6206个术语,验证集中包含术语2122个,测试集中包含术语1145个,数据集统计如表2所示.

表1 术语样例展示
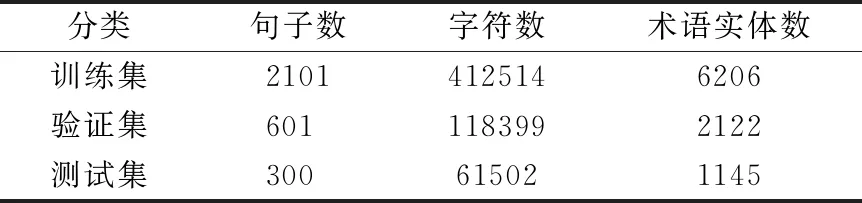
表2 数据集统计信息
4.2 人工标注及评估标准
为了减少人工标注的成本,本文采用基于以上手工构建的领域术语表自动标注训练语料和测试语料中的术语,先利用jieba库对新能源语料按自定义词典进行分词,然后采用代码匹配的方式自动标注术语,如算法1所示.由于新能源领域词典中的术语数量有限,不可能涵盖文本中的全部术语,另外术语实体存在缩写、嵌套、中英文混合等情况,本文的数据在自动标注以后又人工校对了一遍,把与新能源领域不相关的术语词处理掉.采用BIO三元标注的方法,B-TERM表示术语实体的第一个词,I-TERM表述术语实体的非首字,O表示当前字符不是术语实体.表3是新能源术语实体的示例标注,每一行是一个字及其对应的标签,之间用空格分开,句与句之间用空行隔开.

表3 新能源专利文本标注样例
算法1.Bert Char Tagging
Infile:each line is segmented by terms
Outfile:BERT-tagged format file
1.terms ← list of new energy terms
2.forline in Infiledo
3. word_list ← Split line with space separator
4.forword in word_listdo
5.iflen(word)==1then
6. Outfile ← word+O-TERM
7.elseif
8. Outfile ← word+B-TERM
9.forw in word[1:len(word)-1]do
10. Outfile ← word+I-TERM
11.endfor
12. Outfile ← word+I-TERM
13.else
14.forw in worddo
15. Outfile ← word+O
16.endfor
17.endif
18. Outfile ← “ ”
19.endfor
20.endfor
本文采取了准确率(P)、召回率(R)和F1值3个指标来验证所提出模型的有效性,具体计算如公式(17)-公式(19)所示:
(17)
(18)
(19)
4.3 实验设计、结果与分析
4.3.1 实验环境配置
BERT-BiLSTM-CRF新能源专利术语抽取模型的运行环境为64位Ubuntu16.04操作系统,具体实验的训练环境如表4所示.

表4 训练环境配置
4.3.2 实验参数配置
本文实验采用了Google提供的BERT中文预训练BERT-base模型,transformer有12层,隐藏层维度为768,12个attention-head,共110M个参数.实验中BERT模型参数设置batchsize为32,dropout为0.5,learning_rate为1e-5,BiLSTM中前后隐藏状态维度为128,clip为0.5,使用Adam优化器最小化模型损失,具体超参数设定如表5所示.
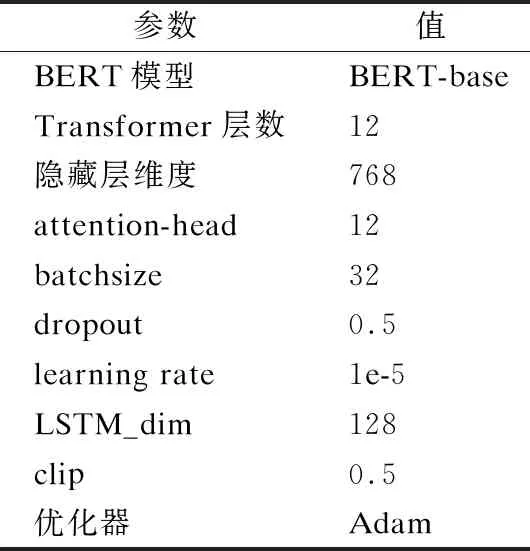
表5 参数设置
4.3.3 实验结果
为了验证BERT-BiLSTM-CRF模型对新能源专利术语抽取结果的有效性,本文选取了以下两种模型进行实验对比.模型1是BiLSTM-CRF模型,该模型是序列标注领域的经典模型,采用传统预训练好的词向量,对输入字符序列进行上下文语义的学习,然后通过CRF模型输出全局最优的标记序列.模型2是基于Glove字嵌入结合LSTM-CRF模型,先使用Glove预训练模型完成词向量训练,接着BiLSTM-CRF神经网络使用Glove输出的文本词嵌入向量继续训练.模型3是本文所研究的基于BERT-BiLSTM-CRF新能源专利术语抽取模型.实验对比结果如表6所示,可以看到模型1达到了84.79%的F1值,模型2比模型1提高了约5个百分点,BERT-BiLSTM-CRF新能源专利术语抽取模型在准确率、召回率和F1值较其它两个模型都有较高的提升,F1达到了92.28%.为了更加进一步直观地对比3个模型在准确率,召回率和F1值的实验效果,图5列出了各个对比实验的的柱状图结果:
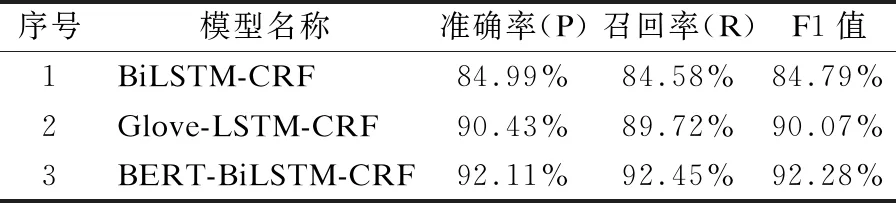
表6 基于深度神经网络的术语抽取模型实验结果
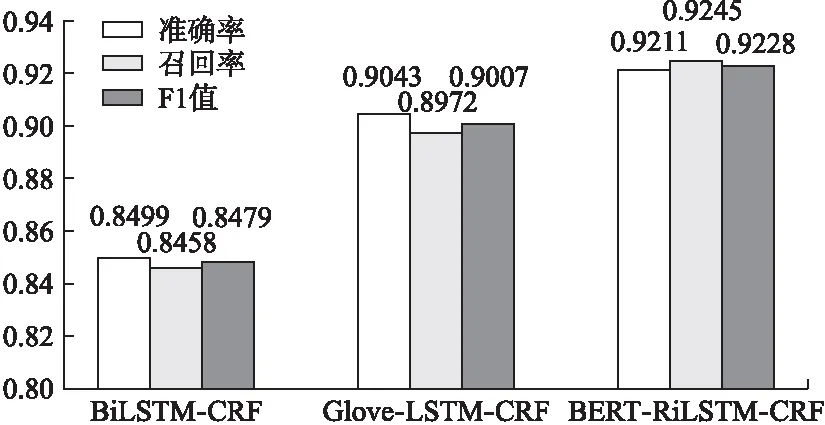
图5 3种术语抽取模型实验结果
4.3.4 实验分析
通过图5和表6的结果我们可以看出,本文所提出的基于BERT-BiLSTM-CRF的新能源专利术语抽取模型在精确率、召回率和F1值3方面均优于其它模型.表7是3种模型对3个不同句子术语抽取结果的展示.可以观察到,模型1仅使用了BiLSTM-CRF模型,虽然得到了84.79%的F1值,能抽取出句子中部分的新能源领域的专利术语,但是抽取的结果不够全面,还有一些字符数量较长的术语未识别出来,最终抽取效果还有提高的空间.模型2在实验1的基础之上加入了Glove字嵌入向量,实验的准确率提高了5.44%,召回率提高了5.14%,F1值提高了5.28%.由此可以得出,加入字嵌入的词向量更好地结合了上下文,对提高新能源领域专利术语的抽取起到了一定的作用,但由于Glove模型是基于词语进行的分词,可能会存在专业术语词切分不当、术语之间边界切分不准确而导致词向量学习效果不佳的问题,术语抽取结果不全.为了解决这个问题,本文所提出的BERT-BiLSTM-CRF新能源领域术语抽取模型是基于字粒度的,不存在分词错误带来的影响,因此对文本语义的理解会更加透彻,最终实验取得了92.28%的F1值.而且在实际新能源专利文本术语抽取中能够有效地识别出字符较多的新能源专利长序列术语,如表7中黑色加粗的字体所示,说明BERT预训练语言模型生成的字向量能更好地学习到术语词与其他词语之间的关系,取得比传统的词嵌入向量更加准确的术语实体抽取效果.

表7 3种术语抽取模型结果的样例说明
通过在新能源领域专利文本上的实验验证,本文设计的经过预训练之后的基于BERT-BiLSTM-CRF的新能源专利术语抽取模型不需要在模型中添加人工特征,仅仅通过利用程序自动标注语料,然后需要少量的人工校对成本,就能够取得有竞争力的实验效果,节省了大量的人力物力.在实际的新能源专利文本的术语抽取中,尤其是针对字符数量较多的新能源专利术语也能有效抽出,因此具有较好的跨领域、跨行业应用前景
5 总 结
综上所述,本文针对新能源领域中文术语的抽取任务,构建了一个新能源领域专利文本的语料库和术语词典,提出了一种基于深度学习的BERT-BiLSTM-CRF新能源专利术语抽取方法,通过对比实验结果可以得出,利用BERT对新能源专利文本进行向量化,能有效提高术语抽取结果的准确率,抽取效果优于当前主流的深度学习术语抽取模型,并在新能源领域专利文本术语抽取中得到了实际应用,可以识别出字符较多的新能源专利长序列术语.本文下一步的工作重点是继续扩大领域核心词典,在现有模型抽取结果的基础上制定高效可行的规则筛选新能源术语,自动标注并训练更大规模的新能源领域专利术语抽取模型,进一步提高模型的泛化性,从而构建更丰富的新能源领域专利术语词典.
