融合领域知识图谱的跨境民族文化分类
2022-05-10毛存礼雷雄丽满志博王红斌张亚飞
毛存礼,王 斌,雷雄丽,满志博,王红斌,张亚飞
1(昆明理工大学 信息工程与自动化学院,昆明 650000)
2(昆明理工大学 云南省人工智能重点实验室,昆明 650000)
3(昆明冶金高等专科学校,昆明 650000)
1 引 言
采用文本分类技术从互联网中获取与跨境民族文化相关的数据,并自动标注所属文化类别,这对开展跨境民族文化融合研究[1]具有重要的价值.在跨境民族文化的文本分类问题中,如何解决标签歧义是当前需要解决的重要问题,例如,文本1“傣族有很多的节日文化,比如浴佛、丢包、赛龙船等活动”和文本2“傣族清晨男女老少沐浴更衣到佛寺进行浴佛活动,有些寺院的浴佛方法还是与它的规定有所不同,大致说来这些寺院浴佛更侧重于法会的仪规,具体分为4个步骤来进行……”中都含有相同的头实体和尾实体[“傣族”,”浴佛”],但是,尾实体表示的含义又不相同,文本1表示的是傣族节日的活动,而文本2中所表示的就是傣族宗教的活动.文本1中的“浴佛”在知识图谱中的标签为{“傣族”,“节日”,“活动”},文本2中的“浴佛”在知识图谱中的标签为{“傣族”,“宗教”,“活动”},由此可以看出,尾实体产生了歧义的现象,会导致分类错误.
文本分类主流方法主要分为传统机器学习分类算法模型和深度学习神经网络分类算法模型[2].1)基于传统机器学习分类算法模型的核心是利用概率统计的思想对文本中的特征词语进行加权,选择权值较高的词语作为文本特征,以此来进行分类模型的学习[3-6].这类基于特征工程的方法严重依赖于人工选取特征的质量,而且很难获取到文本深层的语义特征;2)深度学习是当前文本分类的主流方法,其核心是将文本中的词语以向量的形式进行表示,通过不断的调整网络参数,使输出的数据能够更好的代表输入数据,使用最后的输出作为文本特征进行学习,以此来得到文本的分类模型,如,Keeling等人[7]提出将卷积神经网络用于法律文献检索任务.肖琳等人[8]提出一种基于标签语义注意力的多标签文本分类方法.Peng等人[9]提出了一种新的层次分类意识和注意图胶囊递归CNNs框架,用于大规模多标签文本分类.Banerjee等人[10]提出一种基于层次迁移学习的多标签文本分类算法.顾天飞等人[11]基于配对排序损失的文本多标签学习算法.Yao等人[12]提出一种基于图卷积神经网络的文本分类方法.以上的方法虽然给跨境民族文化分类任务提供了较好的思路,基于传统的机器学习分类的算法模型依赖于数据标注的准确性,针对于跨境民族文化文本分类的问题,数据稀缺并且存在一定的歧义,仅仅利用机器学习的思想无法准确的对跨境民族文本文化进行准确的分类.基于深度学习的方式是一种数据驱动的方法,需要大规模的分类数据,跨境民族文本文化的数据大多来自于网络,这部分数据较难获取,且如何定义跨境民族文化文本分类的标签也是需要考虑的因素之一,结合知识图谱处理跨境民族文化文本分类问题是一种较好的思路,目前,跨境民族文本文化分类问题中面临的挑战主要有:如何将知识图谱信息有效地和跨境民族分类问题结合以及如何解决民族文化标签歧义的问题.
针对以上在跨境民族文化领域分类存在的问题,提出一种融合领域知识图谱的跨境民族文化分类方法,把跨境民族文化知识图谱中的知识三元组以及实体标签利用TransE知识表示模型[13,14]进行向量化表示,采用BERT预训练模型进行词向量表示,以增强文本的语义表达.本文的贡献具体如下:
1)构建了跨境民族文化的知识图谱,并将知识图谱引入到文本分类中,融合了实体的语义信息,扩充了语义信息的表达,缓解了由于标签歧义导致的文本分类不准确的问题.
2)基于预训练BERT的思想,增强语义信息,将BERT的向量表征与知识图谱向量表征进行融合,得到具有实体语义信息表征的向量,进一步将跨境民族文化中实体信息进行增强.
2 融合知识表示的跨境民族文本分类模型
2.1 跨境民族文化分类模型架构
本文提出的模型架构如图2所示,包含了以下5个部分:
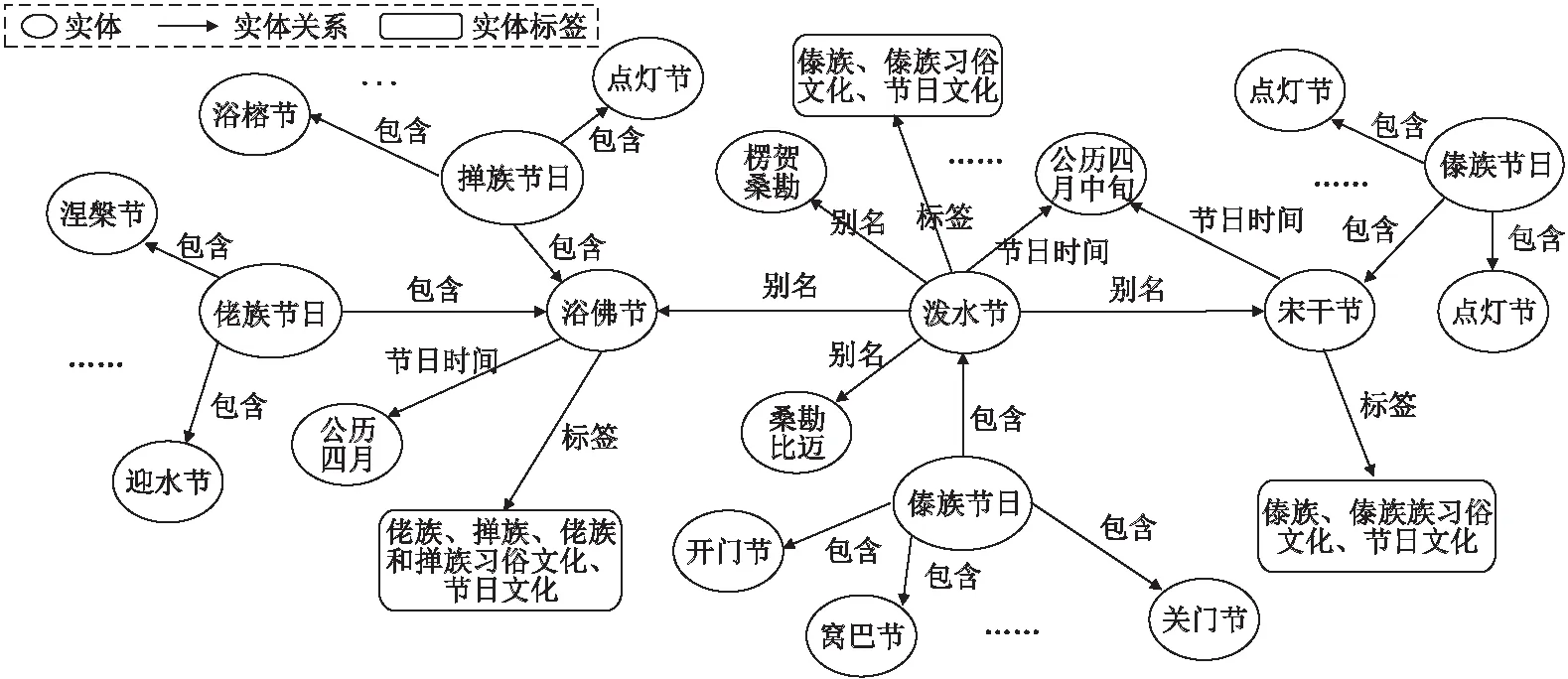
图1 跨境民族文化知识图谱构建示例图

图2 模型构架图
1)数据输入层:把跨境民族文化知识图谱中实体、关系以及实体标签输入到TransE模型中;2)BERT预训练模型层:基于Transformer的最后一层输出的向量作为文本的词语向量;3)TransE实体向量表示层:对输入的实体、关系以及实体标签进行分布式向量表示,然后进行对位融合得到实体语义向量;4)BiGRU神经网络层:该层的输入为TransE模型输出的实体向量和BERT预训练模型层输出的词语向量所融合的增强向量,通过双向GRU的门结构对每个词的进行筛选,保留下重要的词语特征,以此来提高文本特征的质量;5)输出层:该层是通过注意力机制对BiGRU的输出进行注意力加权,并且利用最大池化的思想获取最显著的信息,再经过一个全连接层,最终通过Softmax进行归一化,得到待分类的跨境民族文化文本对应每个类别的得分.
2.2 跨境民族知识图谱构建
知识图谱本质上是一种揭示实体之间关系的语义网络.知识图谱是由(实体,关系,实体)或(实体,属性,属性值)的三元组形式组成的,通过这些三元组之间的相互连接,可以构成网状的知识结构.本文以人工构建的方式构建了跨境民族文化知识图谱.具体的类别如表1所示.

表1 跨境民族文化知识图谱类别
在确定跨境民族文化的分类体系后,需要根据各个类别来定义与跨境民族文化相关的属性包括实体的名称、别称、描述内容、实体标签以及实体存在的一些特征.通过定义实体的这些信息,就可以使实体完整的对跨境民族文化进行详细的描述.如图1所示,对于“泼水节”这个实体来说,它的实体标签类别信息即为“傣族”、“傣族习俗文化”、“傣族节日文化”等.建立实体与实体之间的关系对跨境民族文化领域知识图谱中的知识进行关联整合,使得跨境民族文化知识图谱更加具有表示性以及提高跨境民族文化知识图谱的查询性能.跨境民族文化领域的实体关系错综复杂,主要可以归纳为:包含、跨境、位置、同属、属性.最后通过百科词条信息和结构化知识的组合就可以得到知识三元组信息.具体如图1所示.
2.3 基于TransE的跨境民族文化知识表示
本文采用TransE模型进行实体语义向量表示,将实体、关系以及实体标签信息训练成分布式向量,然后对这3种向量进行对位累加得到实体语义向量.相比于传统的TransE模型来说,由于在训练的过程中添加了实体标签信息,所以本文的TransE基本计算如公式(1)所示:
(h+Lh)+r≈(t+Lt)
(1)
在三元组训练的过程中,由于没有明显的监督信号,也就是不会明确告诉模型学到的知识表示是否正确,所以需要根据正确的三元组S构造一些错误的三元组S′,其中S′的构造规则为将正确的三元组中的实体、关系或者实体标签随机替换为其它元素.在模型训练的过程中,通过设置一个损失函数L来对这些三元组进行打分,相比之下,正确的三元组打分要高于错误的三元组,损失函数设计如公式(2)所示:
(2)
其中,h′和t′为随机构造的负例头实体和尾实体,Lh′和Lt′为随机构造的负例头实体和尾实体标签,γ为大于0的超参,+的作用是筛选,具体规则为大于0取原值,小于0则为0.
训练TransE模型时,首先需要把三元组的实体、关系和该三元组的标签分别按序进行id标记,具体形式为(实体,id)、(关系,id)和(实体标签,id),训练数据格式为(头实体,尾实体,关系,实体标签),模型的输入为随机初始化的实体量、关系向量以及实体标签向量,向量维度一致.通过不断地对实体和关系的向量进行调整,使其满足公式(2)的计算,就可以得到最终的实体向量Eid和关系向量Rid和实体标签向量Lid,把这3种向量进行对位累加得到相应的实体语义向量.

2.4 基于BERT预训练的文本词向量表征
BERT通过双向Transformer对文本进行表征,在模型处理某一个词语时,如:句子“香茅草烤鱼是傣族的传统美食”,分词之后可以得到[香茅草烤鱼是傣族的传统美食],BERT模型会随机遮罩一些词汇得到“香茅草烤鱼是 [Mask] 的传统美食”,然后根据上下文信息对[Mask]进行预测,这样就可以很好的把上下文的语义信息融入到[Mask]这个词语的表示中中句子“香茅草烤鱼是傣族的传统美食”为文本句子,“傣族,傣族饮食文化,傣族食品”为文本中的实体对[香茅草烤鱼,傣族]的标签信息,“傣族,傣族菜,香茅草烤鱼”为知识图谱中的三元组信息.Transformer Encoder的输入Input Embedding为文本经过Token Embedding,Segment Embedding和Position Embedding后按位相加的词语向量,例如文本“泼水节是傣族的传统节日”经过以上3个Embedding的元素按位相加后表示为A={a[CLS],a泼水节,a是,a傣族,a的,a传统,a节日,a[SEP]},其中a[CLS]和a[SEP]为文本的特殊标记向量,每个词语都被表示为k维的向量.对于输入的向量利用Multi-Head Attention(多头注意力机制)计算文本中每个词语与其它词语之间的相互关系,计算公式如公式(3)-公式(5)所示.
(3)
MHA=Concat(head1,…,headk)WO
(4)
(5)

2.5 融合实体语义向量的词向量表征

(6)
2.6 基于BiGRU神经网络的文本特征抽取
GRU是Chung等人[15]提出的LSTM的一个变种,既继承了LSTM可以学习长期依赖信息的特性,而且又减少了训练参数,提高了模型的训练效率.BiGRU的输入x的表示如公式(7)所示:
xi={wi+Ei,p1,p2}
(7)
其中,p1表示第这个词语与第1个实体“香茅草烤鱼”和第2个实体“傣族”之间的位置向量,因为该词语就是第1个实体本身,相对位置的id为0,所以p1的值为与词向量维度相同的随机初始化向量,同理可知该词语到第2个实体的相对位置的id为2,所以p2的值为与词向量维度相同的随机初始化向量.
(8)

ri=σ(Wr·[xi,hi-1])
(9)
其中,σ()是激活函数Sigmoid函数,其值域范围在(0,1)之间.
更新门z决定的是上一个隐含状态hi-1向下一个状态传递的信息.控制hi-1中有多少信息可以流入hi中.
z=σ(Wz·[xi,hi-1])
(10)
隐含状态hi由上一个隐含状态hi-1产生,新的记忆由更新门判定.
(11)
2.7 基于Attention机制的特征加权
根据对跨境民族文化数据的分析,文本中的某些关键特征词具有很重要的语义信息,需要着重的进行考虑.因此,本文利用注意力机制来为这些特征词语分配更高的权重,突出这些特征的重要性.通过2.6节可以得到文本中的第i个文本特征词语的向量表示hi,通过随机初始化一个向量uw作为模型参数一起训练,得到每个词语的注意力得分αi,计算如公式(12)所示:
(12)
令第i个文本特征词语的向量表示hi与其注意力得分αi相乘,从而获得该词语新的特征向量.最后采用最大池化的思想获取最显著的跨境民族文化特征信息,计算如公式(13)所示:
(13)
对于输入的文本来说,通过注意力机制加权后可以得到该句子的向量形式表示C={c1,c2,…,cn},其中C∈Rn×d为句子向量,d为句子向量的维度,n为文本数据的词语数量.再经过一个全连接层可以得到输出为Y的一维向量,表示为Y=[y1,y2,…,yk],其中k为类别数,yi为输入的句子向量C属于第i类的预测值,yi的计算方式如公式(14)所示:
yi=Wi·C+b
(14)
其中,Wi为该句子对应类别i的权重矩阵,b为偏置值,表示为b=[b1,b2,…,bk].通过公式(14)得到yi后,再通过Softmax函数进行归一化处理,得到C属于各个类别的概率值,公式如公式(15)所示:
p(y=j|C)=softmax(yj)
(15)
其中,公式(15)表示句子C属于类别j的概率值.
2.8 模型训练及优化策略
本文使用交叉熵损失函数作为目标函数,通过刻画预测标签与实际标签之间的距离来判定这两者的接近程度,也就是交叉熵越小,距离越近,预测标签与实际标签越相似.目标函数定义如公式(16)所示:
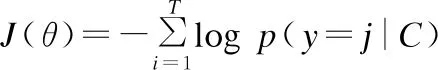
(16)
其中,θ表示模型中的所有参数,初始值随机;T代表句子集合数,本文使用Adam优化器对参数进行更新.
3 实 验
3.1 实验数据集
本文所使用的数据集包含两部分:
1)跨境民族文化知识图谱:其中包括了863个三元组,13个小类.其中知识三元组的具体格式是[“实体”,“关系”,“实体”]或者[“实体”,“属性”,“属性值”],例如:知识三元组[“傣族”,“节日”,“泼水节”]和[“泼水节”,“时间”,“公历4月13~15日”].
2)文本数据:利用已经构建好的跨境民族文化知识图谱中的知识三元组与跨境民族文化文本进行实体对齐所获取的实验数据.如果知识图谱中三元组的头实体和尾实体同时出现在跨境民族文化文本中,我们就把这个文本归为实验所需的标注数据,对于这些标注好的数据则利用人工进行校验,然后对每条数据打上类别标签.标注数据的格式为:[标签->文本].本文实验从跨境民族文化领域文本集中抽取了40种类别共计46251条语料,4000条作为测试集,标注的每条数据的平均长度为67个字符,总共标注的类别有40个.每个类别的数据的数量为1110~1190条.而且本次实验中还加入了一些特殊的文本类别NA(NA:表示句子不属于任何一个文本类别),实验数据示例如表2所示.

表2 标注数据样例
3.2 实验参数设置
实验过程中,通过不断的调节实验参数,以确保模型在参数最优的情况下进行训练,具体的参数设置如表3所示.
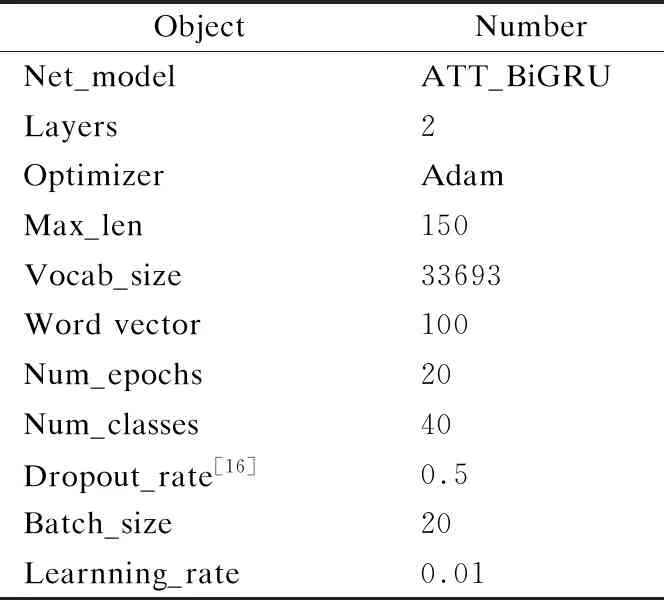
表3 模型参数设置
3.3 实验评测指标
本文为了证明实验的有效性,通过精确率(Precision)、召回率(Recall)和F_1值来对模型进行评估.精确率、召回率和F_1值的计算方法如公式(17)-公式(19)所示.
(17)
(18)
(19)
其中,Right_num为预测正确的文本数量,Recognize_num为识别出的文本数量,All_num为此次测试的文本数量.由于本文的任务是做跨境民族文化文本分类任务,需要在保持高精确率的情况下有一个高召回率,所以F1越高代表模型的平衡性越好,分类效果越好.
3.4 实验结果与分析
实验1.不同方法实验结果对比
为了验证本文方法的有效性,在相同实验语料的情况下,设计了7组不同分类方法的对比实验进行本文方法有效性的验证.其中,各个模型的实验数据完全一致,实验中使用领域分词的方法对文本进行预处理.
1)文献[17]所提出的一种基于word-level级别的深层卷积神经网络模型DPCNN文本分类模型;
2)文献[18]所提出的基于Attention_BiLSTM的神经网络文本分类方法;
3)文献[19]提出的TextCNN文本分类经典模型;
4)文献[20]所提出的Transformer模型应用于文本分类的方法;
5)文献[21]提出的BiLSTM-CNN文本分类模型;
6)文献[22]提出的FastText文本分类模型.实验结果如表3所示;
7)Baseline(Attention_BiGRU):Attention是指注意力机制,这一机制已经被广泛应用于多种领域,包括图像标题生成、文本分类、语音识别和机器翻译[24].双向门控循环神经网络(BiGRU)可以看做双向长短时记忆网络(BiLSTM)的一种拓展[23].
如表4所示,本文方法在跨境民族文化文本分类任务上的精确率和召回率方面都优于本文的Baseline以及其他方法.
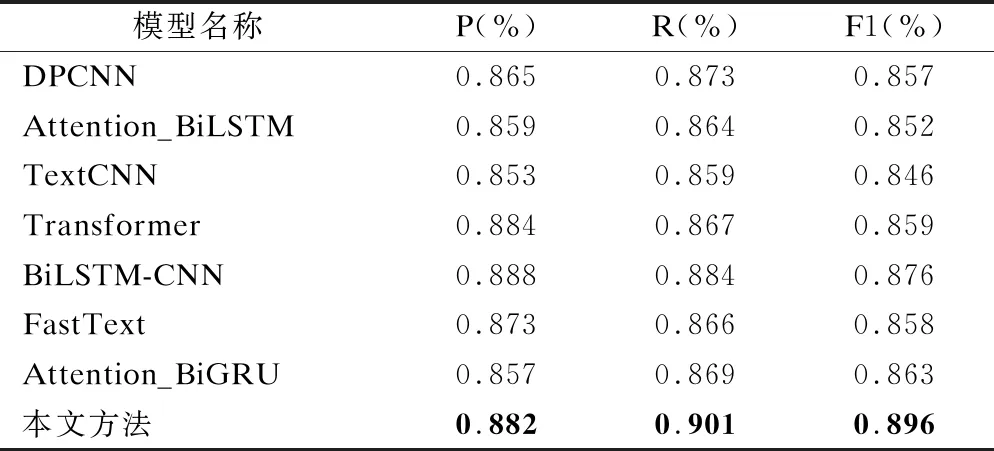
表4 与其它模型的分类效果对比
对于本文的Baseline方法Attention_BiGRU来说,本文方法优于它的原因是本文的词向量表示使用的是BERT模型,所表示的每个词语都带有上下文语义信息,使特征更具有代表性.而Baseline方法的词向量表示使用的是Word2vec模型,而且还没有融入实体向量和对特征进行加权.所以本文方法优于Baseline模型Attention_BiGRU.Transformer模型和BiLSTM-CNN模型的精确率优于本文的模型,造成这种结果的原因是这两个网络模型的网络层数大于本文模型的网络层数.而对于网络层数更深的DPCNN模型来说,其结果不理想的原因是因为网络模型单一,而且词语级的输入不能很好的对文本进行表示.
实验2.不同词向量表示方法对实验结果的影响
为了验证本文所使用的BERT预训练模型表示的文本词向量对于分类任务的有效性.本文通过几种不同的向量表征方式来对文本进行表征,其中的详细实验方式是分别利用Word2vec模型和Glove模型对文本进行词向量表示,并且与TransE模型的实体向量进行融合,而其它保持不变进行模型训练.实验结果如表4所示.
从表5可以看出,本文通过把BERT预训练模型所表示的文本词向量和TransE模型所表示的实体向量进行融合,在跨境民族文化文本分类任务上具有较好的性能.其根本原因在于BERT预训练模型对文本中的词语进行向量表示时,利用双向Transformer对文本中的每个词语进行表示,充分考虑了文本的上下文语义信息;而Word2vec模型只考虑了词语的局部信息,没有考虑词语与局部窗口之外词的联系;GloVe模型虽然弥补Word2vec模型的缺陷,考虑了词语的整体信息,但还存在一个问题,就是所表示的词语在不同语境下的词向量是相同的,没有考虑语境的问题;BERT模型对于上述问题都进行了综合的考虑,即考虑了词语的局部以及整体信息,又考虑了词语在不同语境下的词向量变化,能够充分的对文本中的每个词语进行表示.
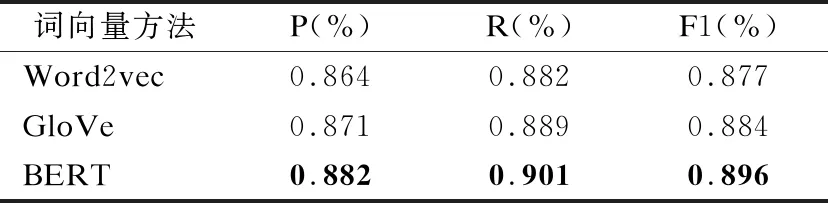
表5 不同词向量方式对实验结果的影响
实验3.领域词汇对实验结果的影响
由于本文需要通过融入领域实体来解决文本中实体特征存在歧义的问题.本文通过领域分词的方法来对文本进行分词处理,以此来保证文本中实体特征词的完整性.所以本文分别采用通用分词工具和领域分词分词实验对比,其中,通用分词使用jieba分词工具,领域分词采用构建的领域词典+jieba分词,实验结果如表5所示.
从表6可以看出,采用领域分词的效果明显高于直接使用jieba分词的效果.本文中将跨境民族文化相关文本中由多个词汇构成的跨境民族文化特征词汇作为领域词汇来处理,如,“南传上部座佛教”这个词语在使用jieba分词时可以分为“南传”、“上部座”和“佛教”这3个独立的词语,而利用领域分词就可以得到一个完整的词语.诸如此类的词语还有很多,如:浅色大襟短衫、大襟小袖短衫.这些词汇如果直接使用jieba分词后将导致具有完整语义的设备缺陷特征拆开后导致语义信息丢失,而作为领域词汇利用BERT进行词向量表征后能够有效获取到跟跨境民族文化相关的词汇的语义特征,更有利于通过Attention层进行捕捉.

表6 领域分词对实验结果的影响
实验4.不同实验参数对实验结果的影响
设置不同的参数迭代次数、批次大小以及随机失活率进行实验的结果如图3-图5所示,根据实验结果可知,设置epochs为20、Dropout为0.4以及Batch为32时,实验结果达到了最佳.
4 结束语
针对跨境民族文化标签类别存在歧义的问题.本文提出了融合领域知识图谱的跨境民族文化文本分类方法,该方法利用TransE知识表示模型得到文本中知识三元组,利用BERT预训练模型得到文本中每个词语的向量表示,再通过BiGRU神提取文本的深层语义信息.实验表明,本文方法对于特定领域的文本分类任务有着良好的效果.在未来的工作中将进一步的解决向量的表征问题和提升文本特征的质量,使模型的抽取效果进一步的提升.

