面向综合能源系统的多智能体协同AGC策略
2022-05-09席磊王昱昊陈宋宋陈珂孙梦梦周礼鹏
席磊, 王昱昊, 陈宋宋, 陈珂, 孙梦梦, 周礼鹏
(1.三峡大学 电气与新能源学院,湖北 宜昌 443002; 2.中国电力科学研究院有限公司 需求侧多能互补优化与供需互动技术北京市重点实验室,北京 100192)
0 引 言
高比例接入的风、光、生物质能等多种类型分布式能源、电动汽车及能量转换装置会给电网带来强随机扰动,严重影响电网安全稳定运行[1]。学者们试图从自动发电控制(automatic generation control,AGC)角度进行探索,以解决随机扰动带来的控制性能下降问题。AGC实际上是一个多级动态决策过程,以实现全系统发电出力和负荷功率相匹配[2]。按照控制策略设计和实现方式的不同,当前AGC控制策略包括传统解析式和机器学习等[3]。前者以比例-积分-微分(proportional-integral-derivative,PID)控制[4]为代表。文献[5]提出了基于随机帝国竞争算法的级联模糊分数阶CFFOPI-FOPID控制器,在发生负荷扰动后能够快速将区域频率和联络线功率的偏差收敛到零,最终获取最优AGC控制性能。
然而,上述传统PID控制框架下的集中式AGC控制系统的控制参数固定,且基于单一的区域控制偏差(area control error,ACE)确定系统总的调节功率,控制机组出力,会导致AGC动态性能较差。随着多种形式能源以及微电网的开发利用,电网的结构模式及能量管理系统逐步走向分散,基于传统PID控制框架下的集中式AGC控制策略已逐渐不能够满足如此复杂的电网需求[6]。而对于分布式多区域电网,区域间信息交互方式灵活复杂,具有协同和自学习属性的多智能体强化学习方法[7]逐渐被学者们应用到分布式多区域电网中。
随着“碳达峰”和“碳中和”的提出,以新能源为主体的新型电力系统势在必行,电力系统结构将发生巨变[8]。此模式下为了追求更高的控制精度,需要智能体从环境中感知更多的状态特征。因此,对系统状态和决策动作均进行了离散化的传统强化学习方法,在面对高维且连续性的状态空间和动作空间时,智能体的收敛速度和控制精度也会大幅下降[9]。学者们发现,神经网络强大的特征提取能力和函数拟合能力,一定程度上能够提高强化学习决策的正确性与控制效率。例如,文献[10]提出相比于经典强化学习中基于有限维度Q表的智能体,基于深度Q网络(deep Q network,DQN)[11]训练的智能体理论上具有更强的感知电网复杂运行态势的能力,能够实现多智能体的相互博弈,从而使AGC探索到最优解。
然而,在面对高维且连续性的状态空间和动作空间时,上述Q框架体系下的传统启发式方法在平衡“探索-利用”过程中,面对随机低质量样本带来的当前Q值与目标Q值误差较大的问题仍没有解决。同时,上述多智能体深度强化学习所采用的经验回放机制,仅是在经验中继存储器中等概率地对样本数据进行采样,这种方式忽略了各个样本之间的重要性差异,导致网络训练缓慢[12]。
针对上述两个问题,本文提出具有基于置信区间上界(upper confidence bound,UCB)的深度强化学习算法(deep Q network-upper confidence bound,DQN-UCB)。UCB策略通过感知样本的历史经验,一方面,解决Q框架体系下的传统启发式方法在平衡“探索-利用”过程中,面对随机低质量样本带来的当前Q值与目标Q值误差较大的问题;另一方面,提高未被选择的样本和表现优秀的样本被选取的概率,样本的多样性得到增加,使智能体能更有效率地选择动作,进而获取分布式多区域电网的最优协同。通过对不同模型在多种工况条件下进行大量仿真,验证了所提算法的有效性。
1 DQN-UCB算法
DQN-UCB算法通过运用UCB策略[13]限制误差以及解决采样问题,最终获得分布式多区域综合能源系统的最优协同。
1.1 DQN
基于Q学习和深度神经网络的DQN是一种值函数迭代的深度强化学习算法。采用经验回放机制,将智能体与环境交互得到的奖励值及状态更新情况以记忆单元(sk,ak,rk,sk+1)的形式作为样本储存,通过最小化损失函数进行神经网络的训练,更新网络参数为
(1)
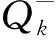
(2)
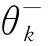
每经过C轮迭代,将当前值网络的参数θ复制给目标值网络θ-,表达式为
(3)
式中θk+C为经过C步延迟后当前网络参数。
通过延迟参数更新的方式降低当前网络Q与目标网络Q-的相关性,进而提升了算法的稳定性。
然而,DQN中等概率随机采样不能充分利用有价值的样本数据,导致学习效率低下;同时,智能体在探索初始阶段受ε-贪婪策略[12]影响,单次随机低质量样本使当前Q值与目标Q值之间误差较大,导致智能体无法快速探索到最优策略。
1.2 Q-UCB
Q框架体系下的强化学习或深度强化学习大多采用ε-贪婪策略、SoftMax策略[14]等启发式策略。上述两种策略分别是在贪婪策略或确定性策略的基础上,只将每个动作的回报或者平均回报作为选择的依据,并且“探索-利用”的平衡很容易受到参数初始化的影响,使潜在最优动作被访问的概率相对较低,不利于智能体探索到最优动作。
UCB策略通过考虑探索过程中产生的平均奖赏值和其对应的置信度构成的动作指标值大小进行动作选择,这在一定程度上消除了上述策略参数初始化的影响。第k个指标值表达式为
(4)
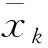
文献[15-16]在强化学习Q算法中融合UCB策略,即在每次动作选择过程中充分利用历史信息,并且遵循乐观原则选择区间上界作为每次动作值函数的值,做出最优动作决策。智能体的最终目标是在状态s下选择最优动作值函数Q*对应的最优动作a。但是,第k次迭代中,真实的Qk+1(sk,ak)是未知的,且估计的Q值与真实的Q值之间存在误差,利用霍夫丁(Hoeffding)[15]不等式限制这一误差,表达式为
Qk+1(sk,ak)-Q(sk,ak)≤bτ。
(5)
式中bτ表示信心奖励或者置信度,表明算法对当前状态-动作对的确定程度,即
(6)
式中:c为大于0的绝对常数;S和A分别为外部环境所有可能的状态集合和智能体可能产生的动作集合;k为到目前为止总共的迭代次数;τ为智能体对状态-动作对的访问次数;q为置信度因子。最优策略取式(5)的上界,可表示为
(7)
1.3 DQN-UCB
受Q-UCB启发,本文在DQN基础上引入UCB思想,提出DQN-UCB控制策略。DQN-UCB构建了两个结构相同的神经网络,即当前网络θ和目标网络θ-,均采用深度学习中反向传播算法,分别拟合当前Q值与目标Q值。DQN-UCB算法框架如图1所示。
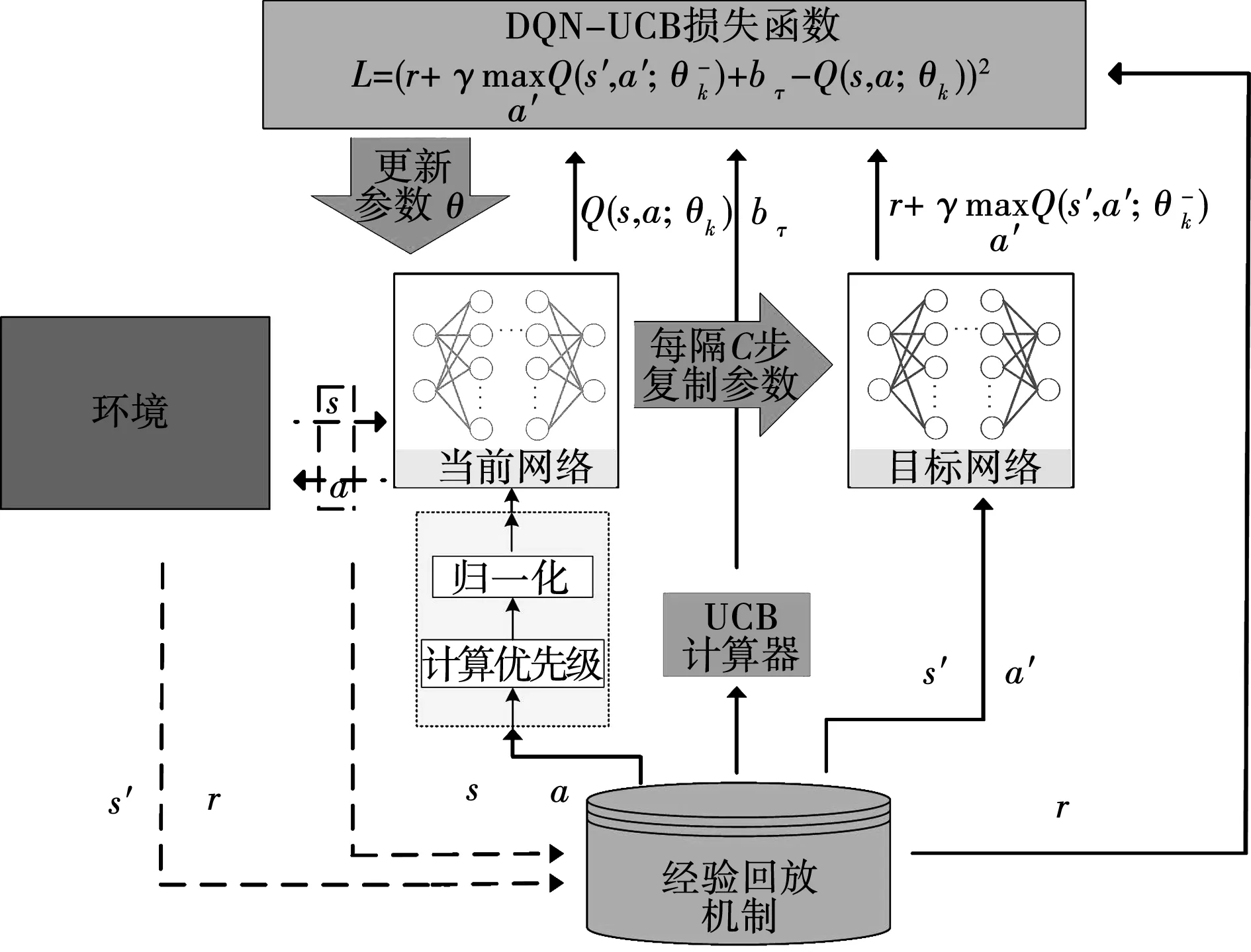
图1 DQN-UCB算法框架Fig.1 DQN-UCB framework
(8)
通过神经网络的梯度反向传播更新网络参数θk和θk-为
θk+1=θk+α▽θkLk(θk)。
(9)
式中α为学习率。当前网络参数实时更新,目标网络参数每隔C步更新同式(3)。
目标值函数为
(10)
同时,针对DQN所采用的经验回放中采样机制的问题,提出基于UCB的优先级采样方式,如图1虚线部分。在每一次执行动作后,从经验中继存储器中提取样本,计算样本优先级并执行归一化操作,可以优先选取经验中继存储器中优秀的样本,从而使智能体选择最优动作。
对于每个样本的选取概率更新公式为:
(11)
(12)
式中:pi是选取第i个样本的概率,初始时,所有样本被选取的概率相等,即pk,i=pk,j(i,j∈[1,N])且满足Σpi=1,N为样本总个数,即|S|×|A|;每次迭代后对所有样本被选取的概率进行归一化操作,如式(12)所示;ri为第i个样本所得到的奖赏值,k是目前为止的采样步数;τi为第i个样本被选择的次数;c是探索权重,当c=0时,以等概率方式选取样本。
2 AGC系统设计
多区域协同的分布式AGC系统框架如图2所示。区域电网调度中心实时监测ACE和互联电网频率偏差Δf,通过调节AGC功率调节指令ΔPord对ACE进行闭环校正控制,并依据控制性能标准(control performance standards,CPS)和Δf(变化范围不得超过±0.2 Hz)来评估区域电网控制性能。
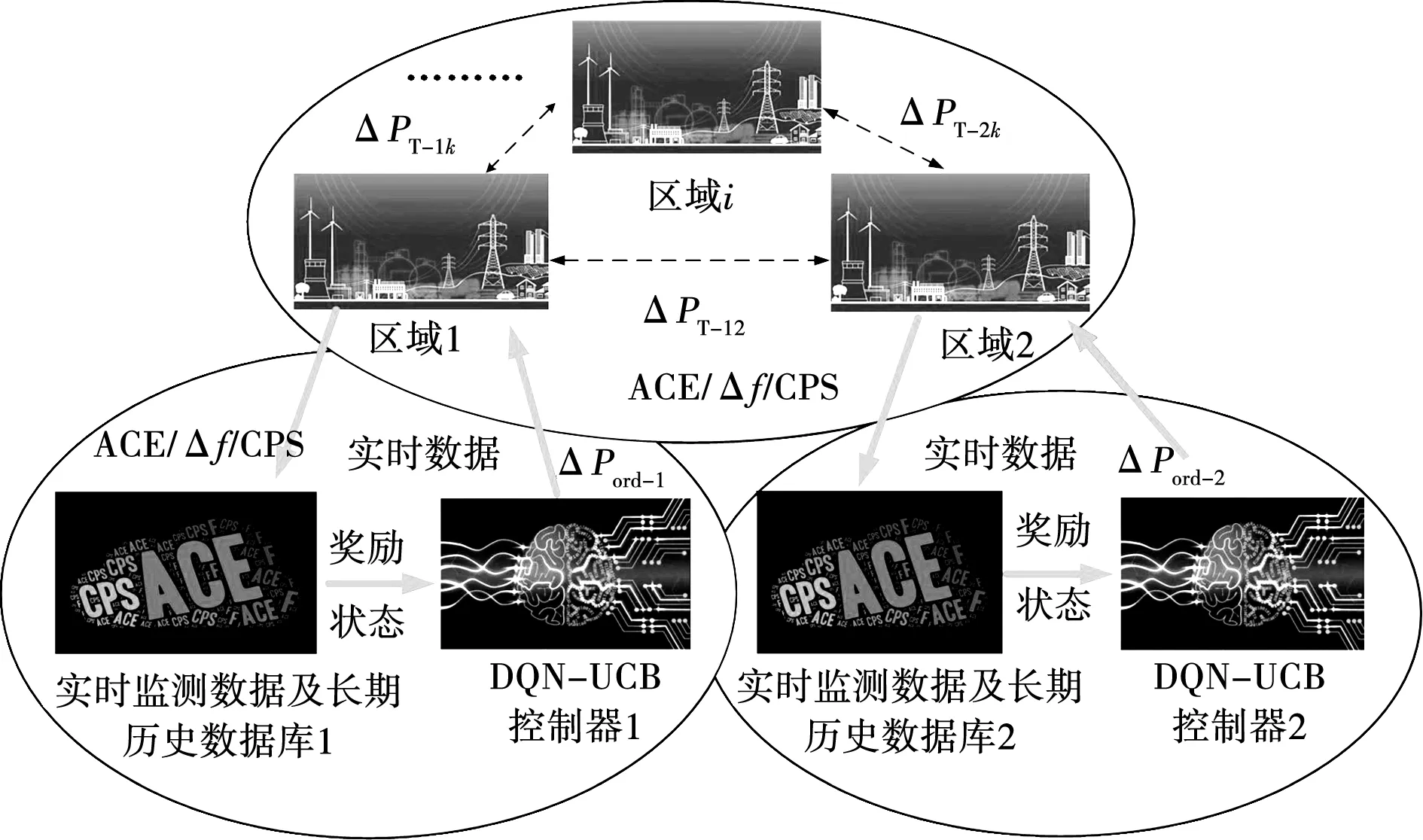
图2 分布式多区域AGC架构Fig.2 Distributed multi-region AGC architecture
分布式AGC系统的状态Si由区域电网实时监控的环境状态量(ACE/Δf/CPS数据及长期历史记录)构成,将功率离散集Ai={-50,-40,-30, -20,-10,0,10,20,30,40,50}MW定义为控制动作。控制器输出最优控制信号,即该区域系统总的调节功率指令ΔPord-k。
2.1 奖励函数
以区域控制误差瞬时值ACE(k)和频率偏差绝对值|Δf(k)|的线性加权作为综合目标奖励函数,获取最优AGC机组出力,在最优AGC控制策略下达到系统功率平衡。对ACE和Δf的量纲进行归一化处理,奖励函数表示为
R(k)=-η|Δf(k)|-(1-η)[ACE(k)]2/1000。
(13)
式中η和1-η分别为|Δf(k)|和ACE(k)的权重系数,这里选择η=0.5。
2.2 参数设置
为了保证在线学习效果,需要对5个参数α、γ、q、c、N进行合理设置,参数设置如表1所示。
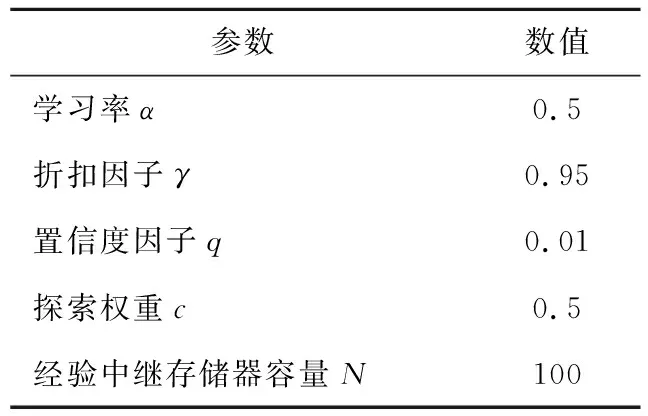
表1 DQN-UCB算法参数
2.3 算法流程
DQN-UCB的算法流程图如图3所示。

图3 基于DQN-UCB策略的执行流程Fig.3 Execution process based on DQN-UCB strategy
3 算例分析
3.1 IEEE标准两区域LFC模型
以典型IEEE标准两区域负荷频率控制模型[17]作为研究对象,结构如图4所示,该系统基准容量为5 000 MW,工作周期为4 s。
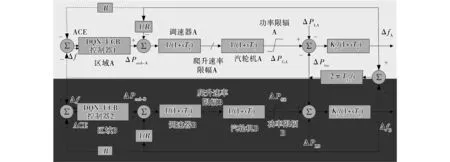
图4 IEEE标准两区域负荷频率控制模型Fig.4 IEEE standard two-area load frequency control model
在线运行前,DQN-UCB需充分进行随机探索试错训练,使控制器在预学习阶段收敛于最优控制策略,再投入到在线运行环境。
3.1.1 预学习
预学习阶段采用正弦负荷扰动(周期1 200 s,幅值1 000 MW,时长10 000 s)对DQN-UCB进行训练。DQN-UCB两区域负荷扰动下预学习收敛过程及性能指标如图5所示。由图5(a)可见DQN-UCB控制器输出功率可以快速跟踪负荷扰动曲线。图5(b)为A、B两区域CPS1预学习阶段的变化曲线,可知CPS1经过一个微小的调整后,快速收敛到一个稳定范围内,两区域对应的指标分别是199.977%、199.981%,说明所提算法CPS1指标已满足最优策略要求。图5(c)显示了频率变化过程,两区域的Δfmax(最大频率偏差)分别为0.002 5、0.001 9 Hz。经过分析,在预学习阶段的各项指标均达到要求,可将控制器投入在线运行状态。
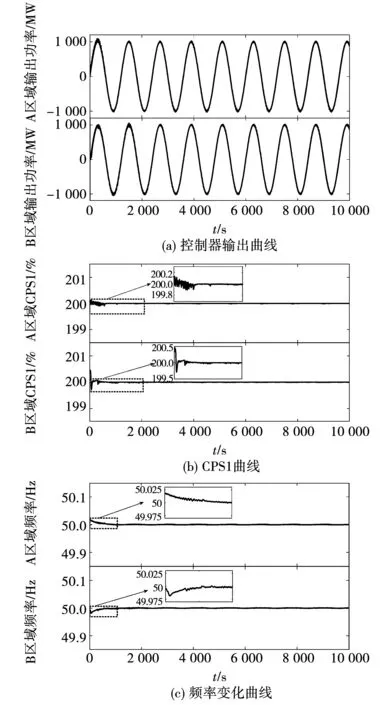
图5 A、B区域DQN-UCB预学习效果Fig.5 Pre-learning of DQN-UCB in area A and B
此外,为了展示所提算法的收敛性能,引入Q[17]、PDWoLF-PHC(λ)[7]、Q-UCB、DQN[10]与所提算法进行对比分析,在相同的仿真环境下集中进行训练,得到智能体训练过程的平均奖励值收敛图如图6所示。
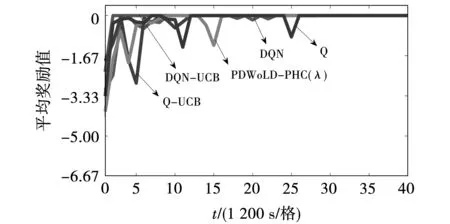
图6 平均奖励值收敛图Fig.6 Convergence graph of average reward value
由图6可知,DQN-UCB策略相比其他4种策略具有更好的训练效果,大约2 400 s时能收敛至最优解,收敛速度较其他策略提高3~5倍。且由于DQN-UCB通过奖赏、时间步和采样次数等历史信息作为经验中继存储器样本优先级考量指标,使更有价值样本的被选概率得到一定程度的提高,因此奖励值振荡次数及幅度均小于其他策略,表明其具有更优越的动态性能。
3.1.2 随机负荷扰动
考虑到众多分布式能源的间歇性和强随机性,引入随机负荷扰动,分析上述5种策略在复杂环境下的动态控制性能。图7为5种策略在相同测试条件下的控制器出力变化图,其中间实线表示以60 s为单位时间绘制的负荷需求平均值。而覆盖实线的区域表示不同控制器在单位时间内输出功率上下限组成的动态调节范围,可以看出,5种策略均能实现与扰动变化步调一致的均衡调节。但在同一时刻下,DQN-UCB的覆盖面积最小,表示基于DQN-UCB的AGC控制器出力范围更逼近负荷平均值,功率控制偏差最小,能够实现更优的动态控制效果。5种算法性能对比如图8所示,相比于其他算法,DQN-UCB能使频率偏差的平均值|Δf|降低41.47%~57.47%,CPS1的平均值提高0.436%~1.46%,|ACE|的平均值降低48.93%~62.13%。
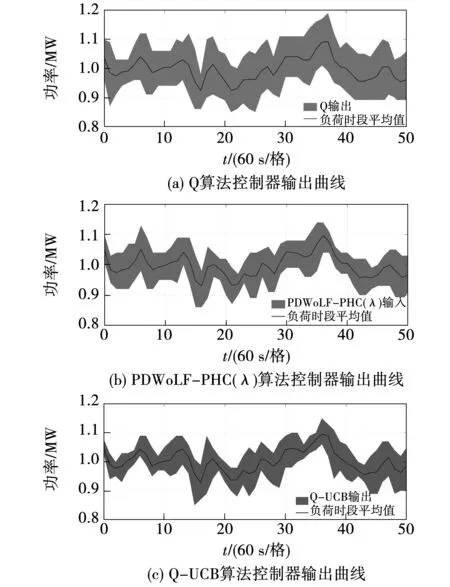
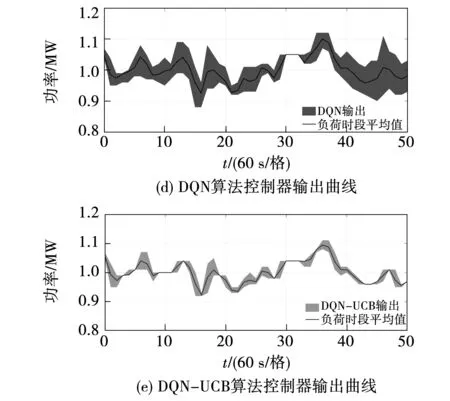
图7 5种算法控制器输出曲线Fig.7 Output curves of five algorithm controllers
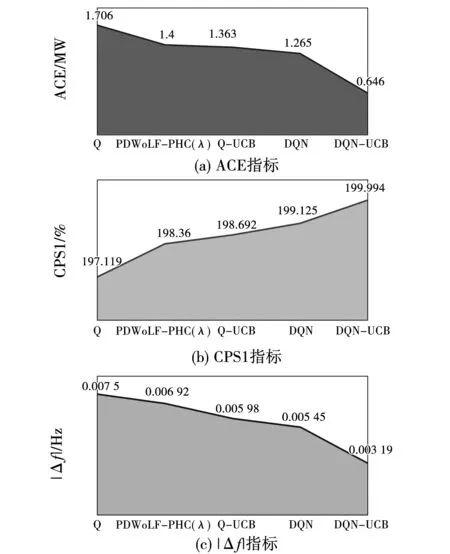
图8 随机负荷扰动下5种算法性能对比Fig.8 Performance comparison of five algorithms under random load disturbance
3.1.3 连续阶跃负荷扰动
采用幅值为500、1 000、 1 500 MW的连续阶跃负荷扰动进行测试,模拟电网中单位时间段内负荷连续增加的环境。图9为5种控制器的在线优化曲线,可知DQN-UCB在电力系统中发生负荷突增的情况时能够迅速跟随负荷变化,曲线变化幅度限制在最小范围内。图10为各算法在该扰动下的频率指标,其中,各算法的|Δf|平均值分别为0.010 4、0.002 5、0.001 5、0.001 2、0.000 56 Hz,对比各算法DQN-UCB有94.61%的提升。表明了所提算法能减少频率偏移,具备较强动态控制性能。
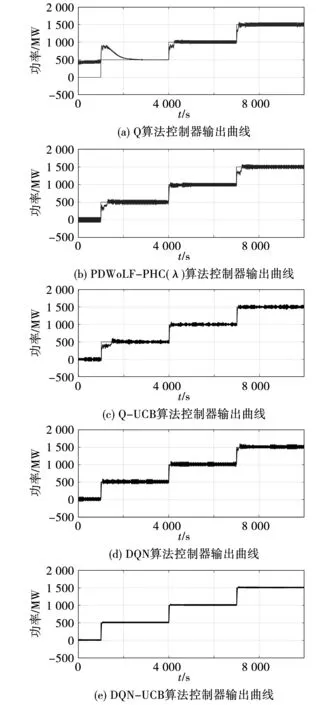
图9 连续阶跃负荷扰动下控制器输出曲线Fig.9 Controller output curve under continuous step load disturbance

图10 5种算法在连续阶跃负荷扰动下的频率对比Fig.10 Frequency comparison of five algorithms under continuous step load disturbance
3.2 综合能源系统模型
搭建分布式多区域综合能源系统模型,其中,冷热电联产系统(combined cooling heating and power,CCHP)的加入能更加逼近真实的综合能源系统,实现能源的梯级利用。CCHP系统结构如图11所示,各机组的相关参数如表2所示,综合能源系统模型如图12所示。
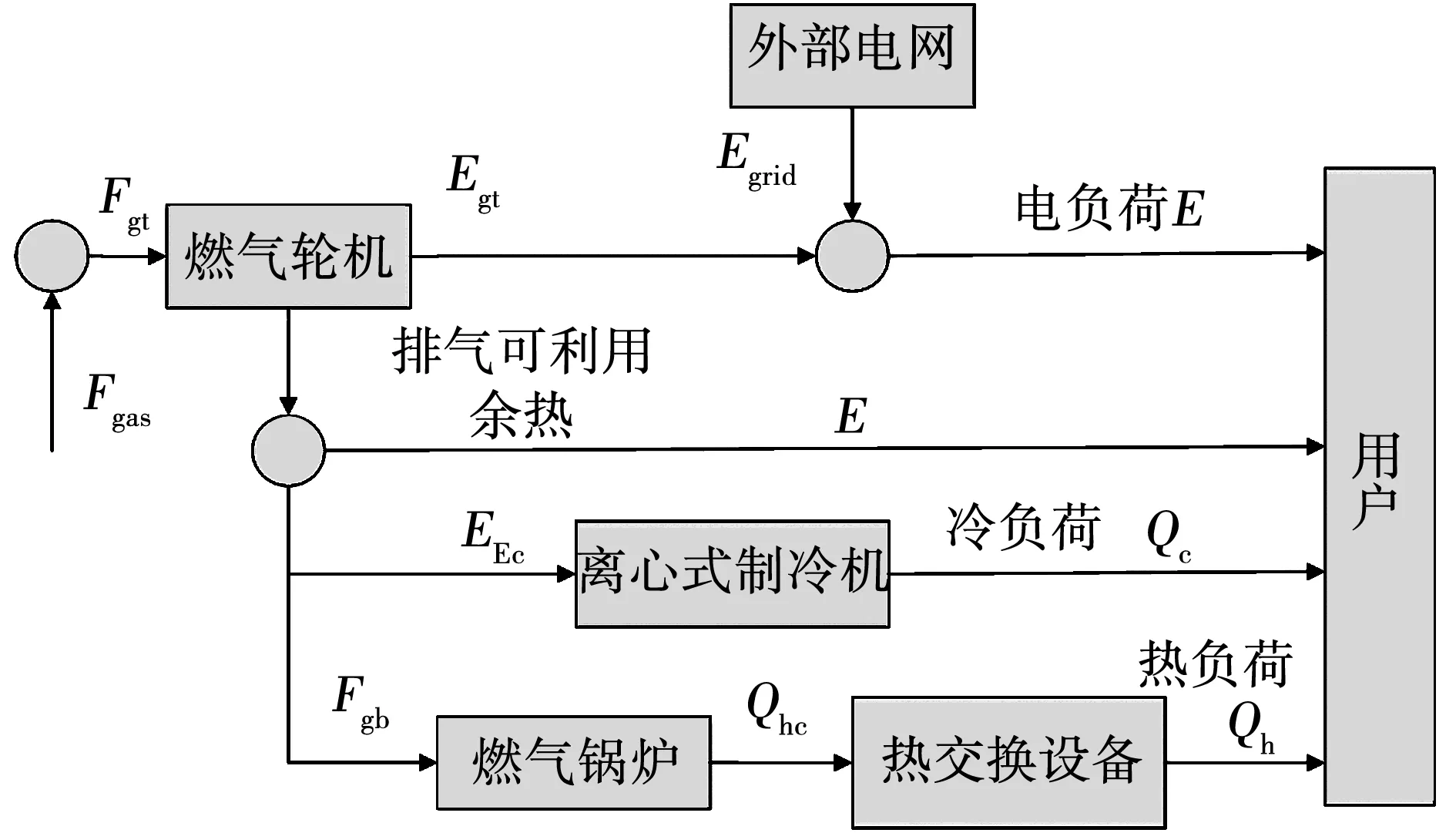
图11 CCHP系统原理图Fig.11 Principle of the CCHP system
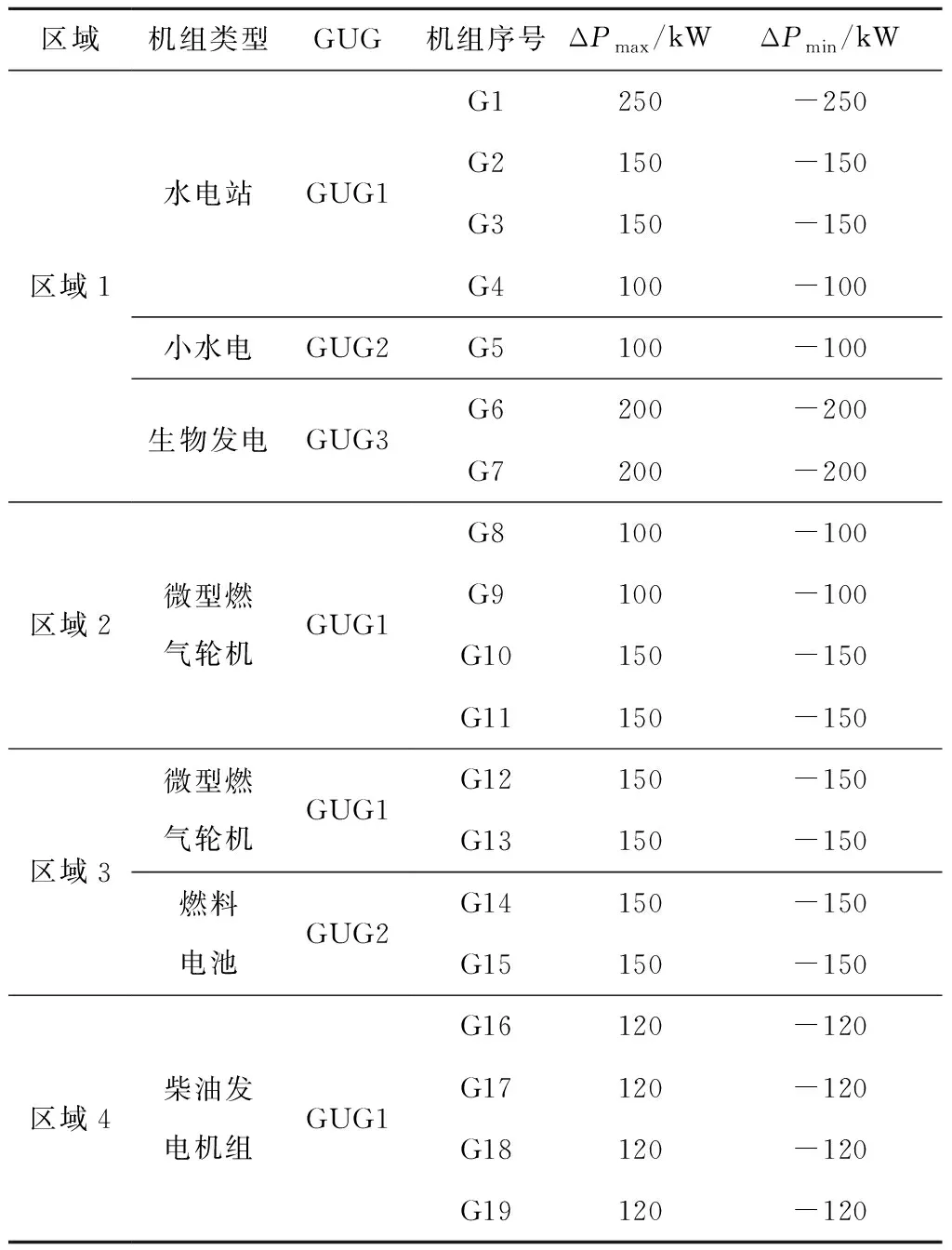
表2 综合能源系统模型机组相关参数
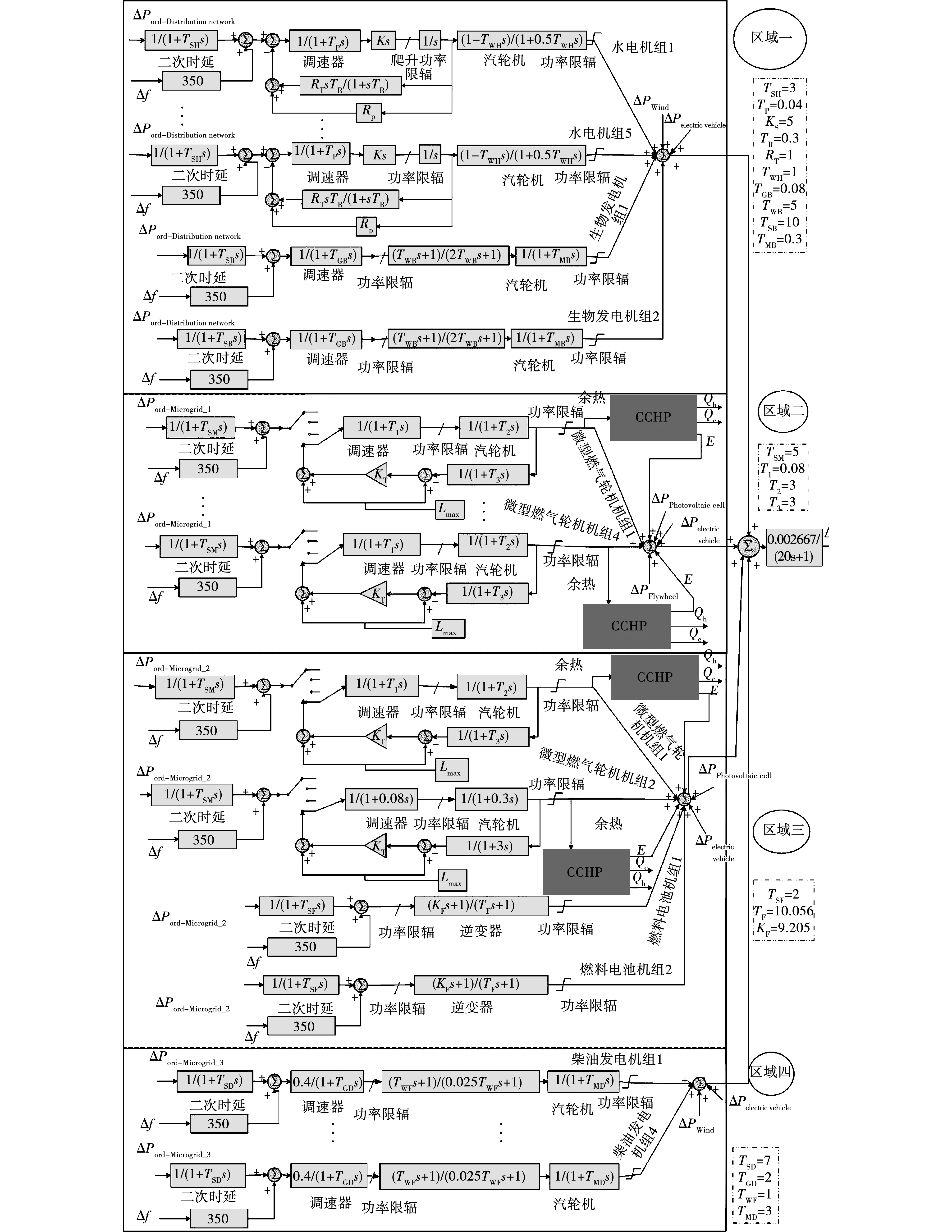
图12 四区域综合能源系统结构Fig.12 Four-region integrated energy system structure
3.2.1 白噪声负荷扰动
引入白噪声负荷扰动来模拟在未知分布式能源大规模并网环境下,电力系统负荷随机变化的复杂工作条件。图13为5种算法在白噪声负荷扰动下控制器输出曲线,可以看出相比其他策略,DQN-UCB控制器对负荷变化有更快更平滑的跟踪效果,符合机组二次调频过程越平滑,发电效率越高的特点。白噪声扰动下各算法的频率变化曲线如图14所示,表明所提策略的|Δf|平均值能够减小50%~89.09%,具备稳定的控制性能。
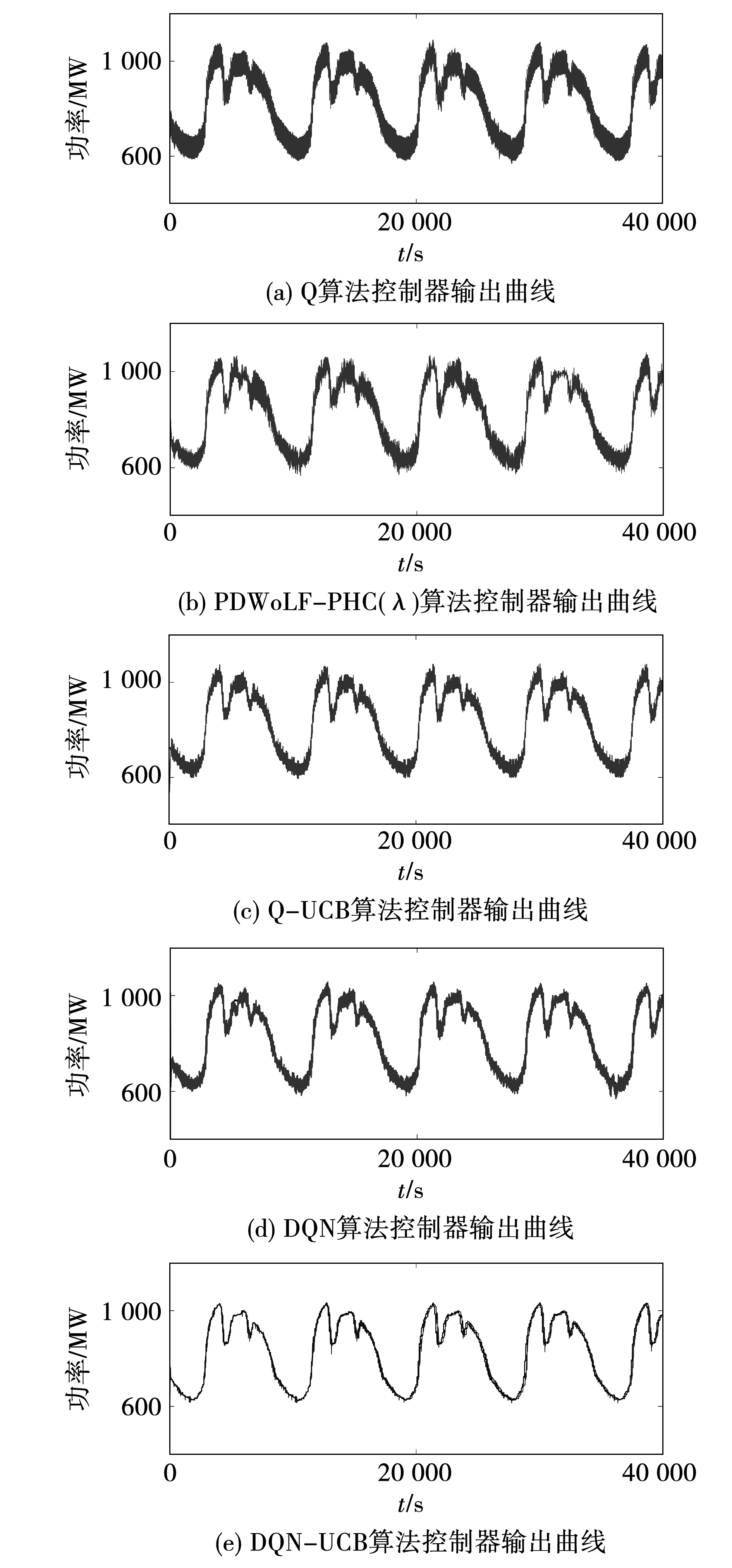
图13 5种算法在白噪声负荷扰动下控制器输出曲线Fig.13 Output curves of five algorithms under white noise load disturbance
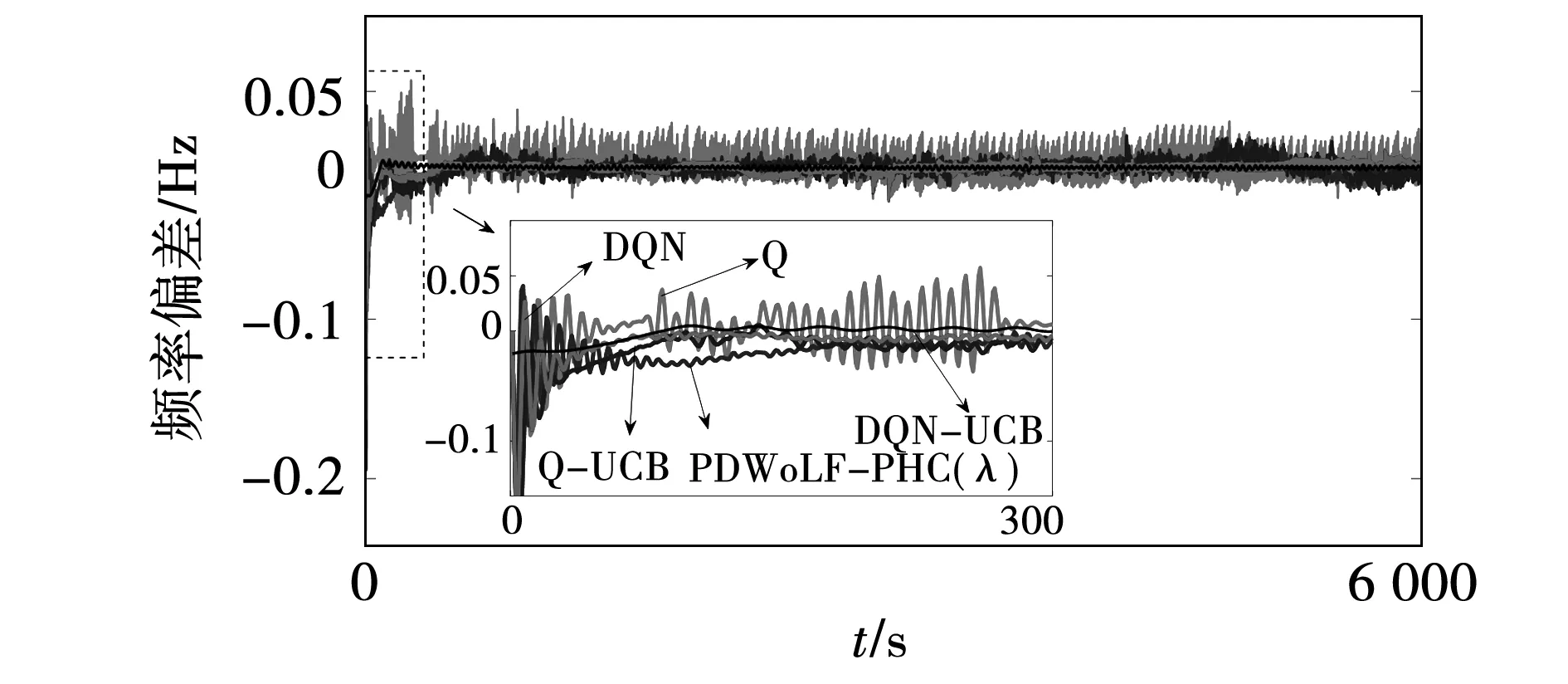
图14 白噪声扰动下5种算法的频率变化曲线Fig.14 Frequency variation curves of five algorithms under the disturbance of white noise
3.2.2 随机方波负荷扰动
为了进一步验证DQN-UCB的控制表现,借助随机方波负荷扰动来模拟电力系统中负荷不规则地突增、突减情况。图15为随机方波扰动下DQN-UCB的输出曲线,可以看出所提策略可以快速准确地实时跟踪负荷扰动。表3给出了在随机方波扰动下不同算法仿真试验指标结果,可知,在区域1中,与其他算法相比,所提策略的|Δf|的平均值下降了45.19%~73.09%,|ACE|下降了52.11%~78.85%,CPS1提高了0.67%~2.46%,适应性及稳定性满足实际要求。
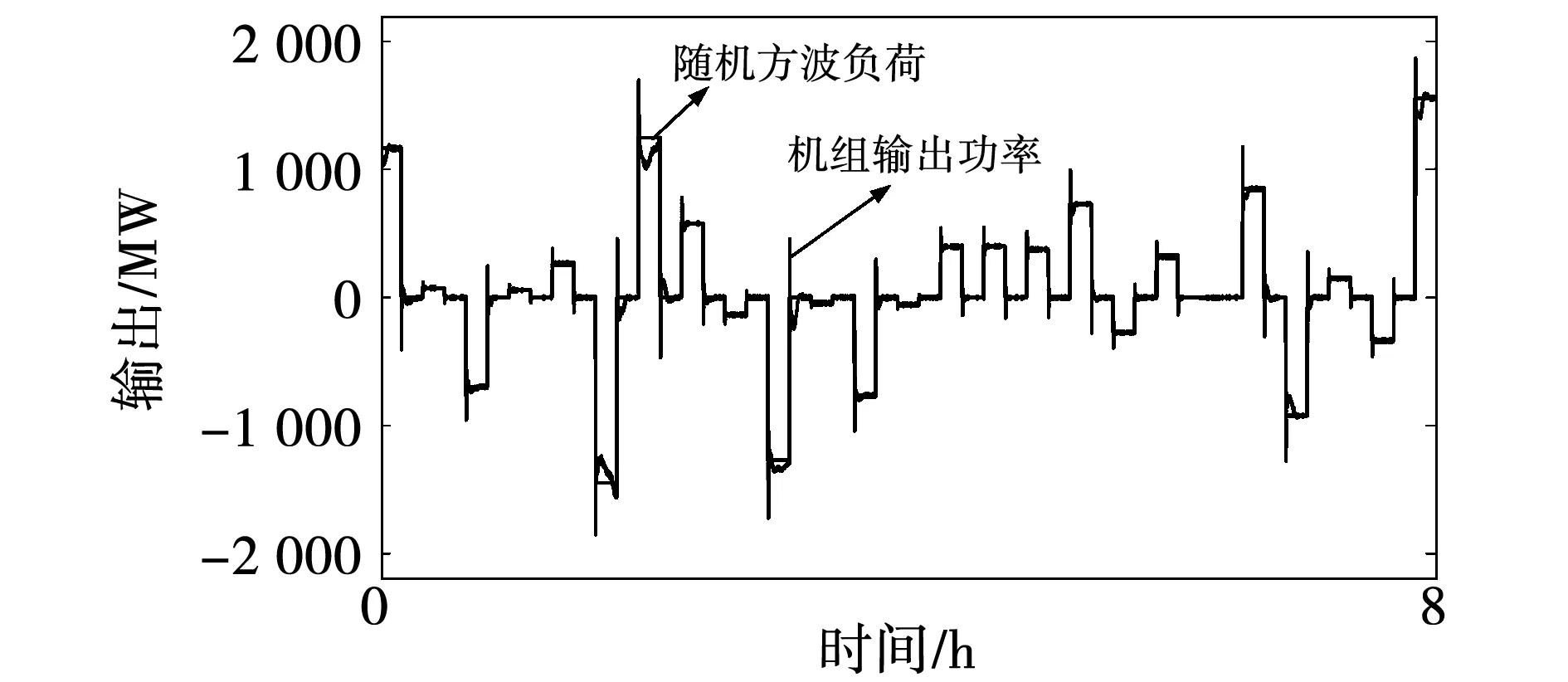
图15 DQN-UCB控制器输出曲线Fig.15 DQN-UCB controller output curve
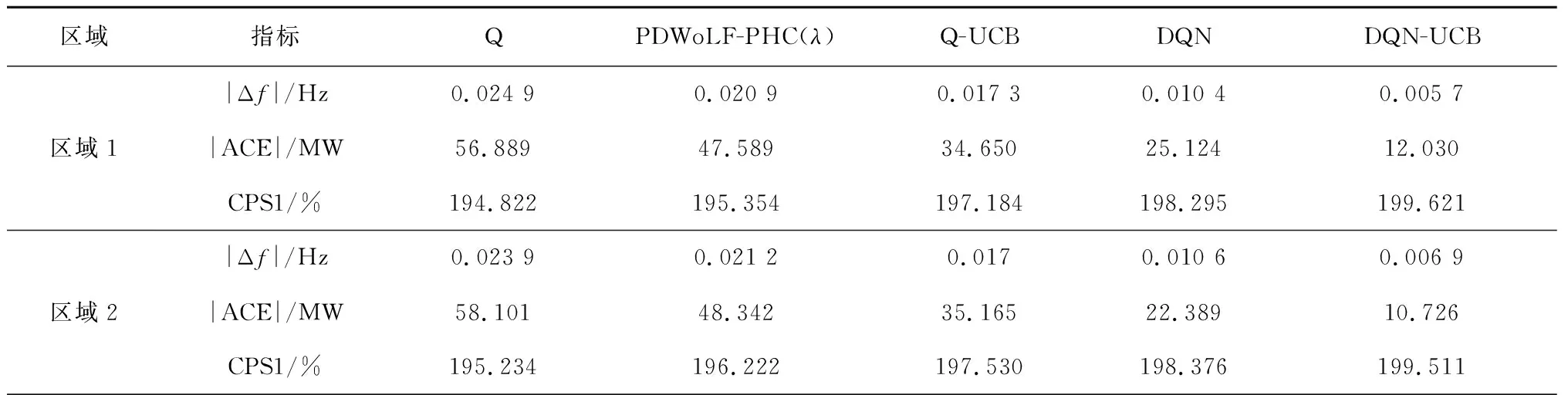
表3 随机方波扰动下不同算法仿真试验指标统计表
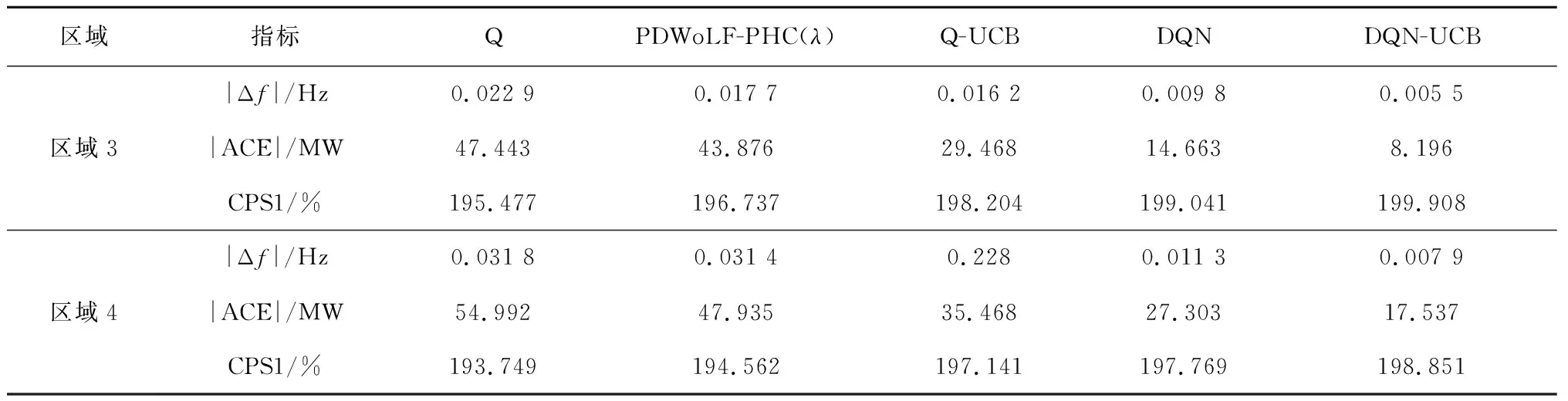
表3(续)
4 结 论
本文面向分布式多区域综合能源系统,从AGC角度提出一种具有感知历史经验的多智能体深度强化学习DQN-UCB算法,在分布式能源大规模接入电网的背景下,解决产生的随机扰动造成电网控制性能下降的问题。
所提算法对经验中继存储器优先级采样,提高了选择优秀样本的概率,进而提升探索效率,加快收敛速度。同时,UCB策略能够降低当前Q值与目标Q值之间误差,获得多智能体协同的最优解,进而来提高分布式多区域综合能源系统的控制性能。
通过对IEEE标准两区域负荷频率控制模型及集成多个分布式能源的综合能源系统模型在多种不同负荷变化工况条件下进行仿真,结果表明,DQN-UCB相比其他算法拥有较强的自学习能力和稳定的控制效果,能够获得分布式多区域综合能源系统的协同。
