基于多模态融合的人脸反欺骗算法研究
2022-05-09颜增显欧卫华
颜增显,孔 超,欧卫华*
(1.广西现代职业技术学院,广西 河池 547000;2.贵州师范大学,贵州 贵阳 550025)
0 引 言
随着网络和图像编辑技术的进步,人们很容易通过社交网络等平台获取别人的人脸图像,并将其用于人脸识别系统的攻击[1],如照片、回放视频或3D面具攻击等。准确识别所捕获的人脸图像是真实人脸而不是虚假人脸是人脸识别系统广泛应用的重要前提。人脸反欺骗就是研究判别捕获的人脸图像是真实人脸还是虚假人脸的一种技术,是人脸识别系统的重要安全保障[2]。
传统的人脸反欺骗算法主要使用人工设计的特征,如LBP[3]、HoG[4]、SURF和DoG[5],来刻画真实人脸和虚假人脸的不同特征分布,然后使用分类器(如支持向量机分类器)对真实人脸和虚假人脸进行分类。如Boulkenafet等人[6]从HSV或YCbCr颜色空间中提取局部二值模式特征描述真实人脸和虚假人脸之间的细微差别,然后利用支持向量机进行分类。基于Lambertian模型,Tan等人[7]提出了一种基于高斯差分(DoG)滤波器的方法来提取真实人脸或照片的不同表面特征的基本信息,并利用稀疏逻辑回归模型进行分类。Patel等人[8]将多尺度LBP和基于图像质量的颜色矩特征[9]结合起来作为单一特征向量输入到支持向量机进行分类。传统的人脸反欺骗方法可以在受限环境(如特定光照、静态等条件)中取得良好的效果,但在无约束条件下性能会大幅度下降[10]。
由于卷积神经网络(CNN)在计算机视觉中的成功应用,人们开始研究基于卷积神经网络的人脸反欺骗方法。研究人员把人脸反欺骗视为一个二分类问题,将卷积神经网络当作特征提取器,提取判别性特征实现真实人脸和虚假人脸的分类。例如,Yang等人[11]利用深度卷积神经网络(CNN)学习高分辨力的特征来对真实人脸和虚假人脸进行分类。Atoum等人[12]通过从人脸图像中提取局部特征和整体的深度图,提出了一种基于双输入CNN的人脸反欺骗方法。Liu等人[13]提出了一种CNN-RNN模型,利用像素级监督来估计人脸深度,用序列监督来估计心率(rPPG)信号,最后将估计的深度图和rPPG信号进行融合以区分真实人脸和虚假人脸。上述方法证明了卷积神经网络可以非常有效地用于人脸反欺骗。
因不同模态图像提供不同信息,如红外、深度图像和RGB图像,如何有效融合不同模态信息实现人脸反欺骗成为近年来的研究热点。例如Aleksandr等人[14]提出了一种多模态反欺骗网络,分别对每一模态进行处理,并在不同网络层上聚合特征,旨在增强神经网络的RGB、红外和深度分支之间的信息融合。Yu等人[15]将单模态网络中心差分卷积网络扩展到多模态情形,用于提取模态之间丰富的判别特征。Tao等人[16]提出了一种多输入CNN结构FaceBagNet,并在训练过程中随机去除一个模态特征,以防止过度拟合和更好地学习融合特征。然而,已有多模态人脸反欺骗方法缺乏不同模式态间的信息交互,很难有效地利用模态间的互补信息。
针对上述问题,该文提出了一种基于多模态融合的人脸反欺骗方法。先通过多模态共享分支网络实现特征提取过程中不同模态间的信息交互,然后利用多模态通道注意力网络融合不同模态的特征。与已有工作相比较,该方法具有以下创新:
(1)提出了一种多模态共享分支网络,实现了不同模态间的信息交互。
(2)提出了一种多模态通道注意力网络,实现了不同模态特征的有效融合。
(3)在基准数据集CASIA-SURF上获得了最好结果。
1 多模态融合人脸反欺骗模型
1.1 整体结构
该文提出了一种基于多模态融合的人脸反欺骗模型。如图1所示,模型主要由两部分组成:
(1)对RGB、深度、红外人脸图像块进行多模态特征提取;

图1 基于多模态融合的人脸反欺骗模型的网络结构
(2)对不同模态特征进行融合。
1.2 多模态特征提取
1.2.1 网络框架
从不同模态输入图像随机提取图像块作为模型输入,选择ResNet-34网络[17]作为主干,其中包括六个由卷积层和残差层组成的卷积块(即res1,res2,res3,res4,res5,res6),一个全局平局池化层和两个完全连接层。
1.2.2 多模态输入数据
不同于已有方法,对不同模态数据,该文随机选择人脸图像中的图像块作为输入,进行模型训练,其原因如下:
(1)防止过拟合。例如,CASIA-SURF数据集包含1 000名测试者,每个人有7个视频片段。尽管从每个视频中提取数百张图像,但由于跨帧的高度相似性,模型容易出现过拟合现象。
(2)提高特征判别性。真假人脸的判别信息分布与整个面部不同区域,使用图像块则可以有效学习判别信息[16]。
(3)减少模型参数,提高训练速度。相对于使用全脸图像,使用图像块作为输入可以减少模型的参数,极大缩短模型的训练时间。
1.2.3 多模态共享分支网络
不同模态间信息具有互补性,如RGB图像具有丰富的细节,深度图像距离信息,红外图像则包含热辐射能量分布信息。为了充分利用不同模态间的互补信息,如图1所示,分别在res1,res2,res3,res4后设计多模态共享分支网络实现不同模态间的信息交互。多模态共享分支网络结构如图2所示,包括两部分:

图2 多模态共享分支网络的网络结构
(1)先将不同模态的特征进行拼接,并利用通道注意力网络(SEN)计算拼接特征中不同通道的权重,然后对输入特征重新加权。与直接采用不同模态的拼接特征相比,通道注意力网络可以进行模态间的对比来选择信息量更大的模态特征和相应的通道特征,同时抑制来自信息量较小的模态特征。
(2)将不同模态的拼接特征拆分,并与前一层多模态共享分支网络提取的特征对应元素相加,输入到相应的网络块中提取特征,最后将提取的特征添加到主网络的各个模态,从而实现不同模态间的信息交互。
1.2.4 通道注意力网络
该文选择通道注意力网络[18]来构成多模态共享分支网络。首先输入一个通道数为c,宽高为w、h的特征,然后通过下面三个操作来重标定输入的特征:
(1)压缩(Squeeze)操作。通过全局(最大或平均)池化操作分别将不同的通道特征压缩为单一的数值,该数值在一定程度上包含了特征的全局感受野。其中输出和输入特征的通道数相同为c。
(2)激励(Excitation)操作。将压缩操作的输出结果输入到两个全连接操作(FC)中以描述不同通道间的相关性,最后输出通道数为c的权重。
(3)重新加权(Reweight)操作。由于激励操作所得到的权重可以在一定程度上代表每个通道特征对于所给任务的重要程度,为每个通道特征乘以其所对应的权重值,可以实现输入特征在通道维度上的重新标定。
1.3 多模态特征融合
该文基于通道注意力融合网络实现不同模态特征的融合。
1.3.1 单模态通道注意力融合网络
与直接将不同通道特征拼接起来不同,通道注意力融合模块根据通道特征进行重新加权,以选择信息量更大的通道特征,同时抑制无用的通道特征。
通道注意力融合模块可以增加对区分真实人脸和虚假人脸更有效的通道特征的权重,使卷积神经网络可以学习到更多虚假人脸特有的鉴别性信息。通道注意力融合模块对单一模态的特征进行了有效通道特征的选择。但RGB、深度和红外三种模态的图像对于人脸反欺骗具有互补性,为了对不同模态的特征间进行对比进而选择更有效的模态特征,同时抑制判别性差的模态的无用通道特征,该文设计了一种多模态通道注意力融合网络,以实现不同模态间信息融合。
1.3.2 多模态通道注意力融合网络
具体如图3所示,先采用通道注意力网络在不同模态的拼接特征中进行重新加权,以选择更有效的模态特征,然后将拼接特征重新拆分成三种不同模态的特征,接着采用通道注意力网络在每个模态内选择信息量更大的通道特征,最后将三种模态的特征再次拼接起来生成多模态特征。

图3 多模态通道注意力融合网络的网络结构
2 实验和结果分析
2.1 数据集
采用的CASIA-SURF数据集[19]是目前最大的人脸反欺骗数据集。该数据集由三种不同模态的数据组成:RGB、深度和红外图像,共分为训练、验证和测试三个子集,分别有6,300(每个模态2,100个视频)、2,100(每个模态700个视频)、12,600(每个模态4,200个视频)个视频。由于数据量大,研究人员在每10帧中选取1帧,在预处理后分别形成约148K、48K、295K的采样集,分别用于训练、验证和测试。
2.2 评价度量及对比方法
2.2.1 评价度量
为了保证评估的公平性与客观性,采用了人脸反欺骗中常用的5个指标:攻击呈现分类错误率(APCER)、真实呈现分类错误率(BPCER)、平均分类错误率(ACER)、假正率(FPR)和真正率(TPR)。各自计算公式如下:
APCER:把虚假人脸预测为真实人脸的比例,其计算式为:
BPCER:把真实人脸预测为虚假人脸的比例,其计算式为:
ACER:APCER和BPCER的均值,其计算式为:
TPR:将真实人脸预测对的比例,其计算式为:
FPR:将虚假人脸预测为真实人脸的比例,其计算式为:
True Positive(TP)为将真实人脸预测正确的数量;True Negative(TN)为将虚假人脸预测正确的数量;False Positive(FP)为将虚假人脸预测为真实人脸的数量;False Negative(FN)为将真实人脸预测为虚假人脸的数量。
2.2.2 对比方法
为了评估所提出方法的有效性,选择了以下多模态人脸反欺骗方法进行比较:
·单尺度多模态融合(NHF)[19]。该方法采用ResNet-18作为主干分别处理三种模态的数据,然后将特征连接起来,最后由全局平均池化操作(GAP)和两个完全连接层构成。
·基于通道注意力融合模块的单尺度多模态融合(Single-scale fusion)[19]。在单尺度多模态融合方法的基础上,对每个分支最后一层的特征通过通道注意力网络进行重标定。
·基于ResNet-18的多尺度多模态融合(Multi-scale fusion)[20]。在单尺度多模态融合的基础上,通过在不同网络层采用全局平均池化操作拓展到多尺度情形。
·基于ResNet-34的多尺度多模态融合(Stronger backbone)[20]。在多尺度多模态融合的基础上,将主干网由ResNet-18替换为结构更复杂的ResNet-34。
·基于图像块的特征学习方法(FaceBagNet)[16]。它是一种多输入CNN网络,采用图像块作为输入,并通过模态特征随机擦除(MFE)操作来防止过度拟合。
·基于局部和深度图像的人脸反欺骗方法(Patch and Depth)[12]。采用图像块和深度图作为输入,通过CNN来提取两者特征并结合。
·静态和动态图像融合的多模态的人脸反欺骗(PSMM-Net)[21]。将SD-Net网络拓展到多模态版本,并提出了一种部分共享的融合方法来学习不同模态间的互补信息。
2.3 实现细节
该文将原始的全脸图像大小调整112×112,并使用随机旋转、翻转、裁剪和颜色失真进行数据增强。同时从原始图像中随机选取不同大小图像块,即16×16、32×32、48×48、64×64和全部图像。如表2所示,经过多次实验证明,当图像块尺寸为48×48时,实验效果最好,因此最终选择48×48的图像块进行实验。实验采用随机梯度下降(SGD)算法对模型进行25个周期的训练,初始学习率为0.1,经过15个和20个周期后,学习率下降10倍,批处理大小为64。
损失函数:损失函数采用的是softmax loss,其表达式为:
其中,Wj为网络最后一个全连接层的权重W的第j列;b为偏置项;C为类的数目;xi为第i个样本的特征;yi为xi对应的类标签。
2.4 实验结果
2.4.1 不同多模态融合方法比较
不同多模态融合方法的比较结果如表1所示。
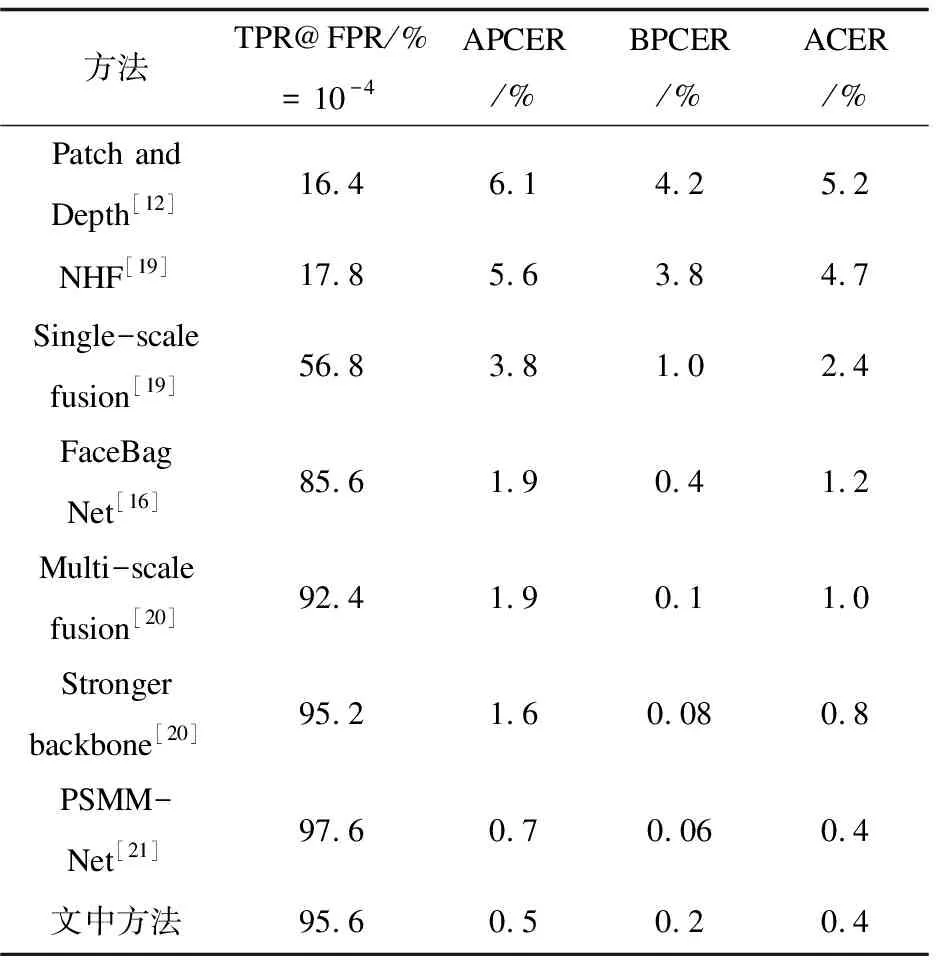
表1 不同多模态融合方法比较
可以看出,文中方法相对于现有的多模态人脸反欺骗方法性能更佳。相对于方法[16],文中方法在平均分类错误率(ACER)上降低了0.8%,在假正率(FPR)为10-4的情况下真正率(TPR)提升了10%。相对于方法[20],文中方法在平均分类错误率(ACER)上仍然降低了0.4%,在假正率(FPR)为10-4的情况下真正率(TPR)也提升了0.4%。与网络结构更复杂方法[21]相比,文中方法在平均分类错误率(ACER)上也取得了相同结果,在攻击呈现分类错误率(APCER)上降低了0.2%,且提出的多模态融合模型网络结构更简单。
2.4.2 消融实验
为了研究多模态共享分支模块(Multi-modal Shared branch Network)和多模态通道注意力融合模块(Multi-modal Squeeze and Excitation Fusion)的有效性,采用48×48大小的图像块进行了一系列的消融实验。其中“MMSN& MSEF”表示同时去掉多模态共享分支模块和多模态通道注意力融合块,“MSEF”表示去掉多模态通道注意力融合块,“MMSN”表示去掉多模态共享分支模块。
如表2所示,仅采用多模态共享分支模块相对于两模块均去掉的原始模型在平均分类错误率(ACER)上降低了0.4%,在假正率(FPR)为10-4的情况下真正率(TPR)提升了17%。仅采用多模态通道注意力融合模块相对于原始模型在平均分类错误率(ACER)上降低了0.5%,在假正率(FPR)为10-4的情况下真正率(TPR)提升了18%。两个模块结合实现了最好结果,在平均分类错误率(ACER)上降低了0.9%,在假正率(FPR)为10-4的情况下真正率(TPR)提升了21%。实验结果充分证明了多模态通道注意力融合模块和多模态共享分支模块的有效性。
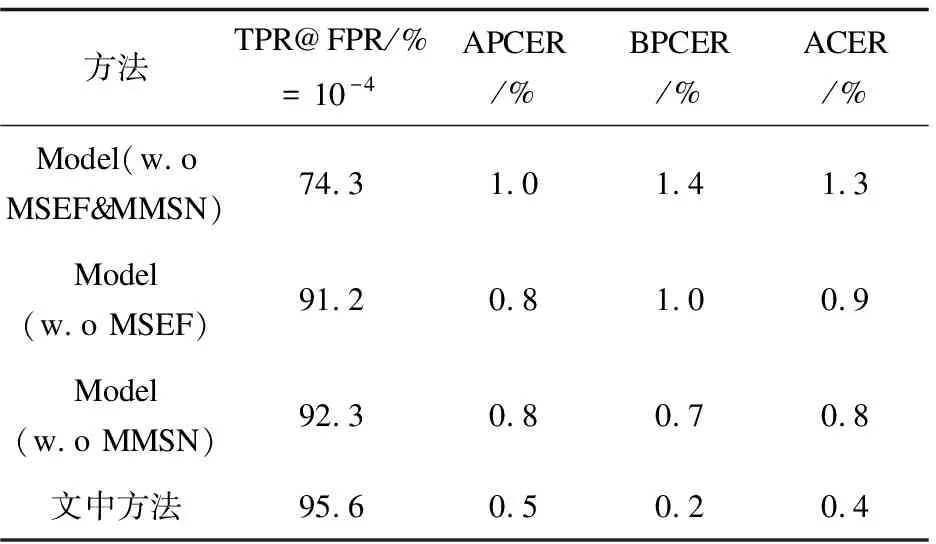
表2 消融实验结果
2.4.3 不同融合方法实验结果比较
为了研究提出的多模态通道注意力融合方法对模型的影响,将模型中的融合方法进行替换,进行对比实验。结果如表3所示,提出的多模态通道注意力融合方法取得了最好的实验结果,相对于通道注意力融合方法,在平均分类错误率(ACER)上降低了0.4%,在假正率(FPR)为10-4的情况下真正率(TPR)提升了3.1%。
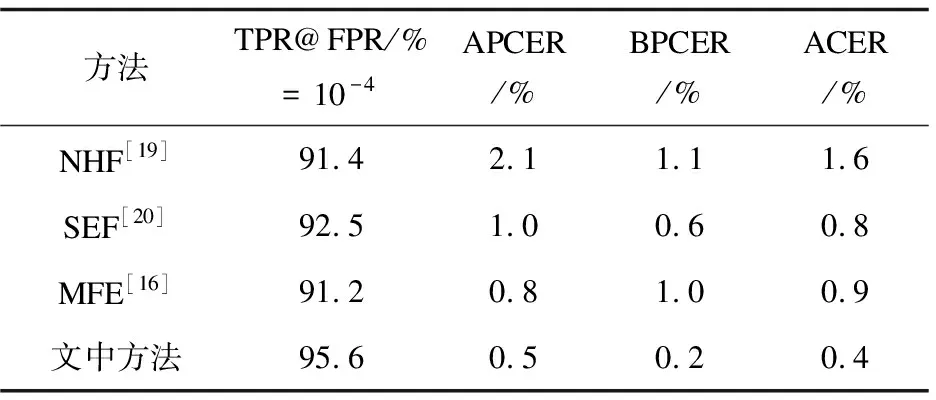
表3 不同融合方法实验结果
2.4.4 不同特征提取方法实验结果比较
为了研究提出的多模态共享分支模块对模型的影响,将模型中的特征提取网络进行替换,进行对比实验。结果如表4所示,采用文中提出的多模态共享分支模块得到了最好结果,相对于多尺度特征提取方法,在平均分类错误率(ACER)上降低了0.3%,在假正率(FPR)为10-4的情况下真正率(TPR)提升了2.4%。同时,多模态共享分支模块中的通道注意力网络(SEN)也起到了至关重要的作用,相比于去除了通道注意力网络的多模态共享分支模块,在平均分类错误率(ACER)上降低了0.1%,在假正率(FPR)为10-4的情况下真正率(TPR)提升了13%。
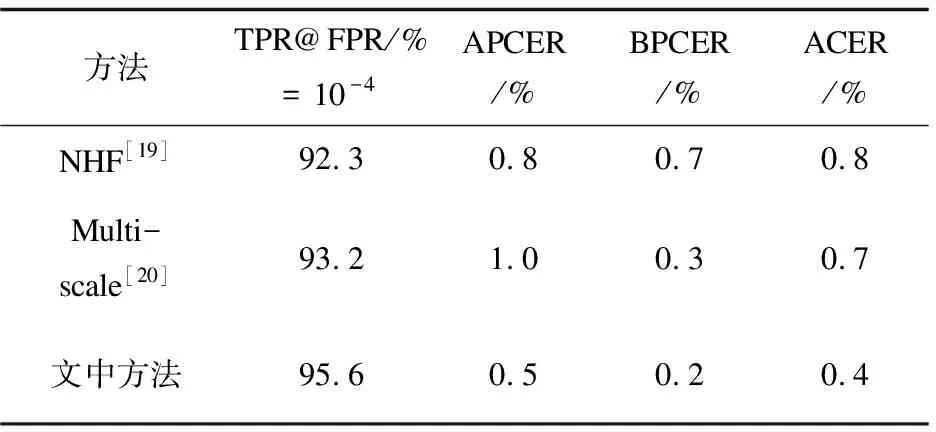
表4 不同特征提取方法实验结果

续表4
2.4.5 不同图像块大小实验结果比较
为了研究不同图像块大小对模型的影响,采用了不同大小的图像块进行实验,即16×16、32×32、48×48、64×64和全部图像。如表5所示,当图像块大小为48×48时实验效果最佳,相对于采用整体图像而言在平均分类错误率(ACER)上降低了2.4%,在假正率(FPR)为10-4的情况下真正率(TPR)提升了37%。
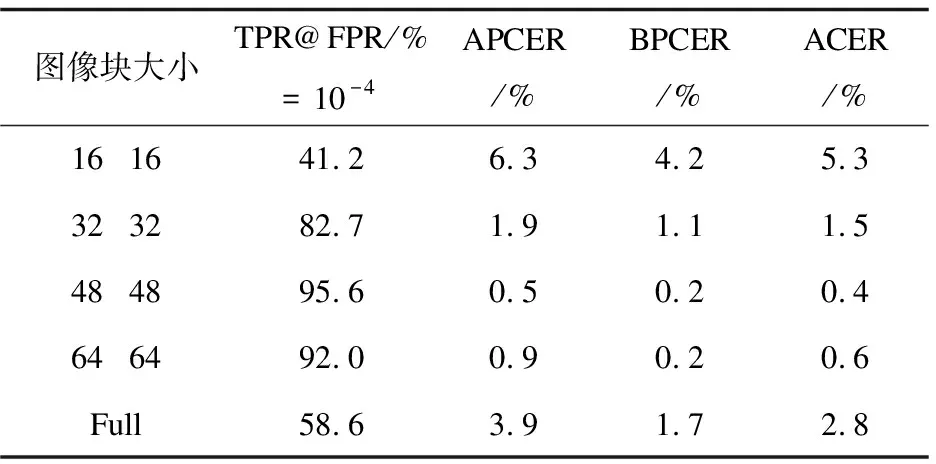
表5 不同图像块大小实验结果
2.4.6 不同模态组合实验结果比较
不同模态组合实验结果如表6所示。可以看到,仅有RGB和红外(IR)模态组合时平均分类错误率(ACER)为1.8%,在假正率(FPR)为10-4的情况下真正率(TPR)为66.1%。而Depth深度和RGB模态组合时在平均分类错误率(ACER)上达到了1.4%,在假正率(FPR)为10-4的情况下真正率(TPR)达到了68.1%。但深度和红外模态组合结果最好,平均分类错误率(ACER)为1.8%。融合三种模态时实现了最佳结果,平均分类错误率(ACER)降低到了0.4%,在假正率(FPR)为10-4的情况下的真正率(TPR)提升到了95.6%。这有效说明了多模态融合的必要性。

表6 不同模态组合实验结果
3 结束语
该文提出了一种多模态融合的人脸反欺骗模型。先通过多模态共享分支网络实现不同模态间信息的交互,然后利用多模态通道注意力融合网络融合不同模态的特征。实验结果表明,与现有方法相比,该方法实现了更好的性能,尤其是平均分类错误率(ACER)指标达到了0.4%。另外,提出的多模态共享分支网络和多模态通道注意力融合网络结构简单,可以应用到其他基于卷积神经网络的多模态人脸反欺骗模型,具有较好的通用性。
