基于迁移学习和集成学习的医疗文本分类
2022-05-09郑承宇徐权峰
郑承宇,王 新,王 婷,徐权峰
(云南民族大学 数学与计算机科学学院,云南 昆明 650500)
0 引 言
挖掘隐藏在医疗文本中的丰富语义信息是文本挖掘领域的重要任务之一。医疗文本具有复杂的专业术语等现象,常见的文本分类模型在处理医疗文本时常常面临文本语义稀疏、知识利用不足等问题。传统的主流机器学习算法如ML-KNN[1]、ML-DT[2]、Rank-SVM[3]在处理数据稀疏、维度过高的大规模数据集时,效果并不理想。近年来,基于大数据驱动的深度学习算法如CNN、RNN以及其他混合神经网络模型取得了快速发展,在情感分析[4]、信息检索[5]、问答系统[6]等领域得到了广泛应用。基于深度学习算法的文本分类模型为了取得优异的性能,需要大量的时间和精力去采集目标领域的大型数据集和进行模型的参数训练过程,且易造成巨大的计算资源耗费。为了解决这一问题,该文引入文本迁移学习方法,将在通用领域表现较好的预训练语言模型,通过模型微调技术,迁移到特定目标医学领域数据集上进行文本迁移学习,并微调网络结构,针对医疗文本语义稀疏、维度过高的特点,采用混合神经网络进行集成训练,解决传统文本分类算法对医疗文本语义理解不足的问题。
1 相关研究
2013年,Mikolov等[7]提出Word2Vec词向量表征模型,推动了深度学习算法在自然语言处理领域中的发展。随后,基于卷积神经网络(convolutional neural network,CNN)、循环神经网络(recurrent neural network,RNN)和长短期记忆网络(long-short term memory network,LSTM)的文本分类模型被广泛应用到句子分类、多模态分析和语义关联等自然语言处理任务中[8-9]。在医疗文本多标签分类领域,Chen等[10]提出一种卷积神经网络与循环神经网络在多标签文本分类中的集成应用模型CNN-RNN,同时捕获医疗文本词汇信息和上下文语义信息。Ibrahim[11]等提出一种用于多标签生物医疗文本分类的混合神经网络模型,分别利用CNN和LSTM模块提取医疗文本最具区分度的特征和上下文信息特征,然后进行特征融合。上述算法结合CNN、RNN和LSTM提取文本特征的优点,有效提升了深度学习算法对医疗文本的分类效果。
Word2Vec词向量表征打破了文本相似词汇不同表达的隔阂,训练完成的词向量表达包含不同文本的词意信息,但面临文本词向量表示无法根据具体语境进行动态调整的问题,从而造成文本语义信息损失。基于此,越来越多的研究者开始采用递进式网络结构进行堆叠式搭建,提取文本特征时充分利用单一网络优势。2018年,Du等[12]提出一种基于嵌入式语言学习模型(embeddings from language models,ELMO)的深层神经网络学习框架,结合具体语境对文本向量表达进行动态调整,并利用双向长短期记忆网络(bidirectional long-short term memory network,Bi-LSTM)和Attention注意力机制捕获文本上下文的语义关联,用于生物医学文本的多标签分类,取得了不错的效果。ELMO词向量表征模型可以有效学习文本上下文语义信息进行动态词向量表征[13],但仍面临着梯度消失以及无法并行化等问题。
针对上述问题,2018年,Devlin等[14]提出一种基于双向Transformer结构表示的文本预训练语言模型(bidirectional encoder representations from transformers,BERT),利用Transformer 结构中的encoder部分代替传统的LSTM模块,在文本向量表示方面展示出了强大的算法性能。BERT模型作为一种高效的文本向量表示方法,其有效性依赖于大量的模型参数训练,需要耗费大量的时间和资源成本。2020年,Lan等[15]提出了一种轻量化网络结构ALBERT(A Lite BERT),通过采用几种优化策略获得一种轻量化网络模型,在多项自然语言处理任务数据集上超越了BERT模型。基于上述研究,该文提出一种基于迁移学习和集成学习的医疗文本分类算法,从通用领域表现较好的ALBERT预训练语言模型中,通过模型微调技术实现医疗文本的语义增强,然后设计Bi-LSTM-CNN混合神经网络模块进行集成训练,提取医疗文本蕴涵的丰富语义特征,实现医疗文本的深层语义信息抽取。
2 迁移和集成框架
2.1 ALBERT迁移学习框架
ALBERT预训练语言模型在通用领域的中文文本向量表示方面展现出了优越的算法性能,通过采用多层双向的Transformer结构[16]设计,对大量中文语料库进行训练,得到融合词汇本身和上下文语义信息的动态向量表示,在一定程度上解决了同义词、多义词等现象对文本语义的影响,其模型结构如图1所示。分析ALBERT预训练语言模型的网络结构,通过迁移学习和模型微调技术,将其应用到特定的目标领域,结合医疗领域文本数据集进行训练,可以实现医疗文本的语义增强。
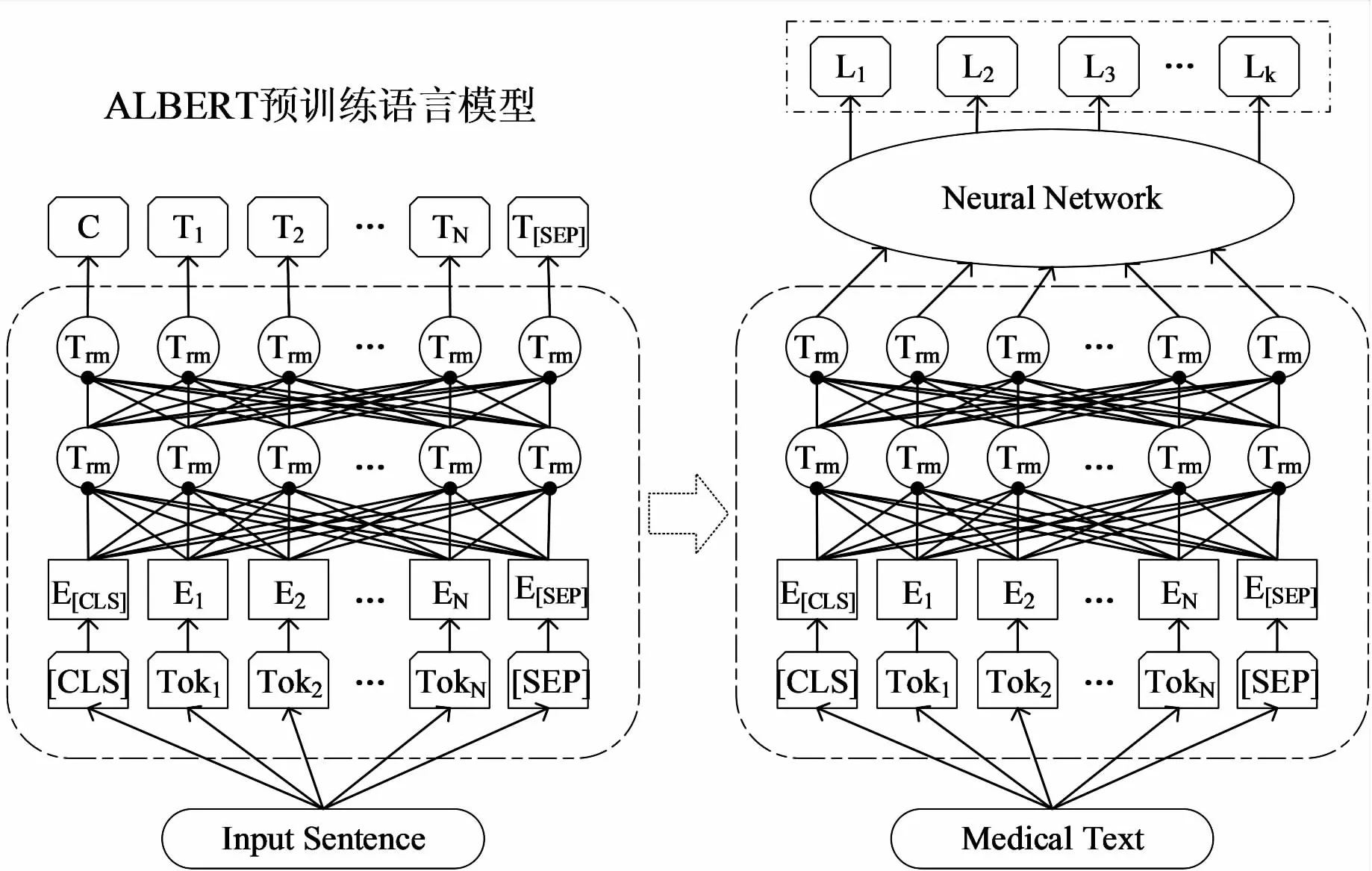
图1 ALBERT模型迁移学习框架
文本领域的迁移学习主要是调整预训练语言模型的第一层网络结构,将在通用领域性能表现较好的预训练网络模型迁移到特定医学领域数据集上进行训练。ALBERT模型在句子层面按照字符级别进行文本向量输入,基于迁移学习和模型微调技术,使得该模型在特定领域也具有较好的算法性能,在实际应用中具有重要的应用价值。
ALBERT模型采用多层双向Transformer结构设计,多头自注意力机制[17]是其中最重要的组成部分,可以计算文中每个词与该句子中所有词的相互关系,并通过这种相互关系调整每个词在句子中的权重从而获得新的表达,其计算原理如下:
MultiHead(Q,K,V)=Concat(head1,head2,…,
headh)Wo
(1)

(2)
(3)
(4)

2.2 Bi-LSTM-CNN集成学习框架
基于ALBERT预训练语言模型的文本迁移学习方法,根据不同任务需要可将最后一层Transformer结构的输出向量输入到下游任务的深层神经网络中进行训练。医疗文本作为一种复杂的序列信息,具有语义稀疏、维度过高的特点,Bi-LSTM模型采用双向的序列结构设计,可以更深入地抽取文本序列的全局结构信息,实现序列信息的复杂关系建模。随后,采用CNN卷积神经网络模块对Bi-LSTM模块获取的文本语义信息特征进行进一步地抽取,可以获取得到维度更低的深层语义表达,模型结构如图2所示。

图2 Bi-LSTM-CNN集成学习框架
Bi-LSTM模型考虑了文本的词序信息和语义信息,对带有上下文依赖关系的文本具有很好的建模能力,可适用于各种特定任务的模型构建,是目前常用的文本语义编码模型。Bi-LSTM-CNN集成学习框架基于RCNN[18]混合神经网络模型框架进行搭建,在双向长短期记忆网络后面连接一个卷积层和最大池化层,构成Bi-LSTM-CNN集成网络模块,解决了RNN循环神经网络梯度消失或梯度爆炸的问题,且充分考虑当前字符所在上下文的语义信息,从而学习文本的全局结构信息。
Bi-LSTM包含与LSTM相同的遗忘门、输入门和输出门三个细胞状态,这三个门协同工作,进行信息的筛选、更新与输出,各细胞状态的更新如下:
f=σ(W(f)xt+U(f)ht-1+b(f))
(5)
i=σ(W(i)xt+U(i)ht-1+b(i))
(6)
u=tanh(W(u)xt+U(u)ht-1+b(u))
(7)
ct=i⊙u+f⊙ct-1
(8)
o=σ(W(o)xt+U(o)ht-1+b(o))
(9)
ht=o⊙tanh(ct)
(10)
其中,xt表示当前输入单元状态,i,o,f,u分别表示当前输入门、输出门、遗忘门和候选细胞生成,ct,ht表示细胞状态更新和隐藏状态输出,σ(·)表示激活函数,W表示权重矩阵,b表示偏置项。
3 TLCM文本分类模型
3.1 TLCM模型
针对医疗文本语义稀疏、维度过高的特点,该文引入ALBERT预训练语言模型进行迁移学习,采用多层双向Transfomer编码器进行医疗文本的动态的词向量表征。在此基础上,利用Bi-LSTM双向长短期记忆网络和CNN卷积神经网络搭建Bi-LSTM-CNN集成学习模块,实现文本特征的深层语义信息提取。输出层采用二交叉熵损失和sigmiod激活函数进行文本的多标签分类训练,提出一种基于迁移学习和集成学习的医疗文本多标签分类算法(Trans-LSTM-CNN-Multi,TLCM),算法流程如图3所示。

图3 TLCM模型框架
TLCM医疗文本分类模型采用Bi-LSTM双向长短期记忆网络学习文本序列的上下文依赖关系,即全局结构信息特征,然后利用CNN卷积神经网络对Bi-LSTM模块获取的文本全局结构信息特征进一步地进行高维特征向量表达,实现更深层次的文本语义抽取,且在一定程度上可以解决医疗文本语义信息表达维度过高、知识利用不足的问题。
3.2 算法流程
基于迁移学习和集成学习的多标签医疗文本分类算法流程如下:
算法1:基于TLCM模型的医疗文本多标签分类算法。
输出:各训练参数确定的TLCA文本多标签分类网络。
(1)Wo={wk=1/N|k=1,2,…,N} //初始化N个样本的权值
(2) repeat //迭代轮次,重复训练

(4) forkin range(N)
(5)wk={w1,w2,…,wn} //读取文本数据wk
(6)Tk=embedding(wk) //文本序列化
(7)foroin range(O) //遍历第o层Trans

(9)end for
(10)forpin range(P) //遍历第p层Bi-LSTM


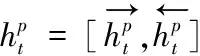
(14)end for
(15)forqin range(Q) //遍历第q层卷积模块

(17)end for
(18)μ=MaxPooling(υq) //最大值池化
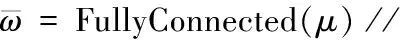
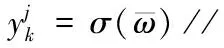
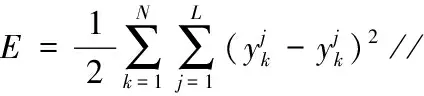
(22)end for
(23) 根据E计算各参数的梯度
(24) 更新k个样本的权值Wo
(25) end for
(26) until 训练误差E收敛到一个较小的值
(27) end
4 实验结果及分析
4.1 实验数据
实验使用的语料库来源于中华医学会提供的5 000条公共医疗中文健康问句数据,每一条中文健康提问数据已被标注为多个医学类别,且具有0个至6个不确定的标签数量,属于典型的多标签分类任务数据集。根据实验需求,将数据集按照4∶1的比例划分为训练集与验证集。该数据集的样本标签分布统计如表1和表2所示。

表1 样本标签个数分布

表2 样本类别分布
4.2 评价指标
实验采用Micro-F1衡量算法的整体性能,对于文本分类多标签分类任务,每条文本文档具有0个或多个标签,每个标签具有“0”或“1”两个类别,Micro-F1是测试不平衡数据集的重要指标。
(11)
(12)
(13)
Micro-F1同时考虑了所有标签整体精确率(Precision)和召回率(Recall),是两者的调和平均值。其中,Precision表示预测结果为正例的样本里面预测正确的样本所占的比例,Recall表示实际结果为正例的样本里面预测正确的样本所占的比例。
4.3 参数设置
该文提出一种基于迁移学习和集成学习的医疗文本分类算法,模型参数主要包括ALBERT、Bi-LSTM、CNN三个模块的参数,依次调整各个网络模块参数的数值,可以得到模型的最优超参数。在实验过程中,迁移学习采用Google发布的中文版预训练语言模型,Bi-LSTM-CNN集成框架采用ALBERT模型进行词嵌入表示。模型训练相关参数详细展示如表3所示。

表3 模型参数设置
4.4 实验结果
为了验证所提TLCM模型的分类效果,该文做了4组对比实验,其中2组基于Word2Vec词向量表示,另外2组基于ALBERT预训练语言模型,分别集成Bi-LSTM和CNN模型进行对比实验,每组实验采用相同的测试集和验证集。为了比较模型性能的差异,对照组实验的Bi-LSTM和CNN模块涉及参数与该文保持一致。实验采用Precision、Recall和Micro-F1值作为算法性能评价指标,实验结果如图4和图5所示。
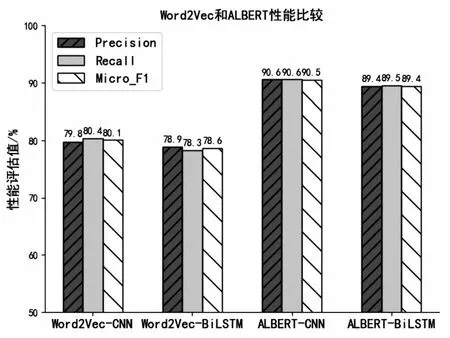
图4 基于Word2Vec和ALBERT的算法性能对比
图5展示了各模型的分类结果。实验结果表明,单独引入Bi-LSTM和CNN模块进行集成训练的ALBERT模型,Micro-F1值分别为89.4%和90.5%,该文所提基于迁移学习和集成学习的文本分类模型在上述数据集上,Precision、Recall表现出了优良的算法性能,三项评测指标分别达到了91.7%,91.8%和91.8%,说明Bi-LSTM-CNN集成模块充分结合两者的优点,表现出了优良的算法性能。此外,如图4所示,基于传统Word2Vec词向量表示的文本分类模型在上述数据集中,模型预测Micro-F1值分别为80.1%,78.6%,显著低于ALBERT预训练语言模型,这是因为ALBERT预训练语言模型可以结合具体语境对文本向量表达进行动态调整,进一步验证了迁移学习在医疗文本分类领域应用的可行性。此外,实验采用中文健康问句语料库,数据规模较小,标签分布严重不均衡,一定程度上影响了模型的分类效果,增加伪数据、多模态数据等,调整模型相关超参数可进一步提升该算法的多标签分类性能。
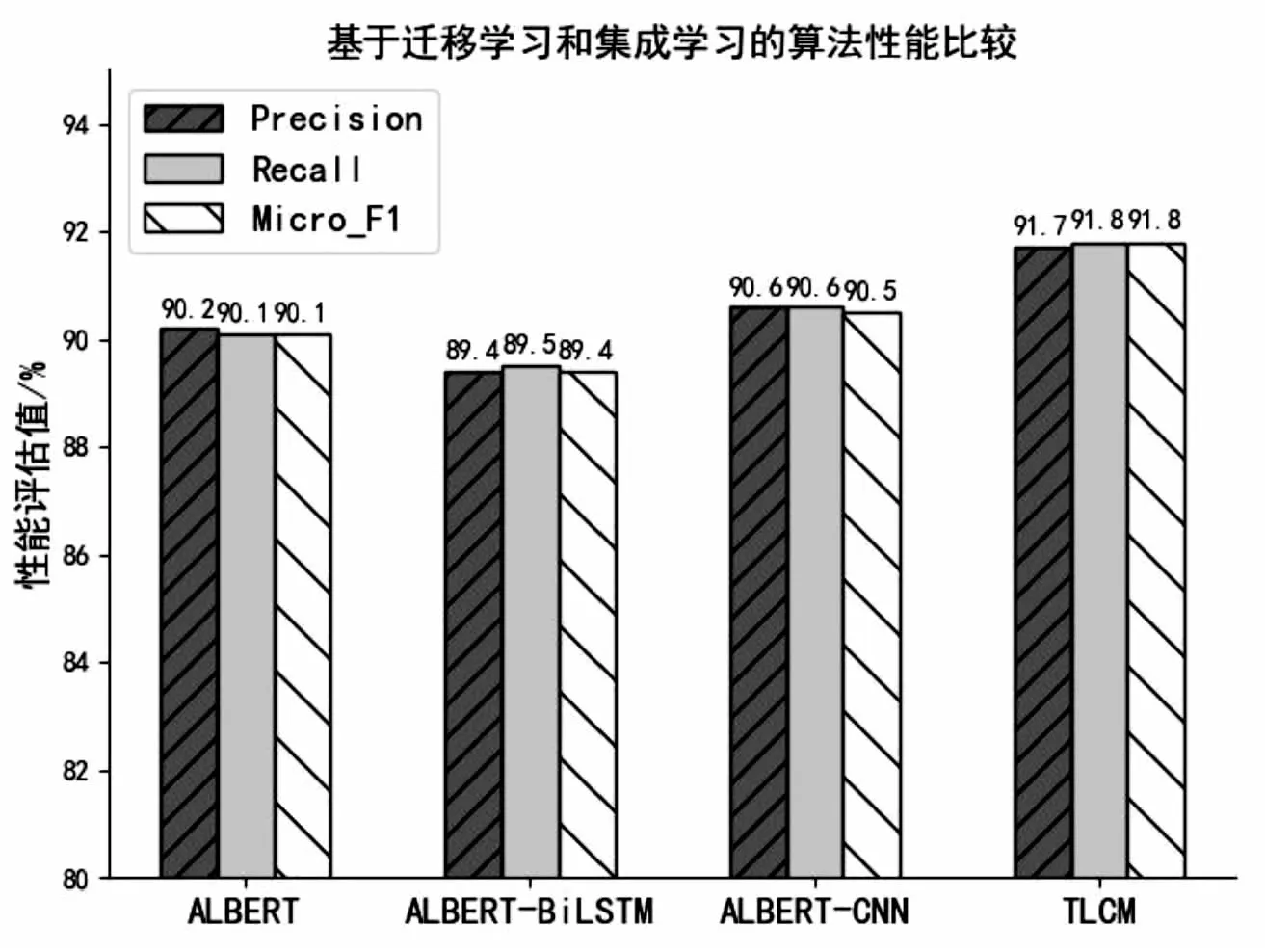
图5 基于迁移学习和集成学习的算法性能
5 结束语
针对医疗文本语义稀疏、维度过高的问题,提出了一种基于迁移学习和集成学习的医疗文本分类算法,迁移学习ALBERT预训练语言学习模型,通过模型微调技术,实现对目标领域医疗文本的动态词向量表征。在此基础上,构建Bi-LSTM-CNN集成学习模块,采用Bi-LSTM双向长短期记忆网络学习文本序列的上下文依赖关系,然后利用CNN卷积神经网络对Bi-LSTM模块获取的文本全局结构信息特征进一步地进行高维特征向量表达,实现更深层次的文本语义抽取。在一定程度上解决了医疗文本语义信息表达维度过高、知识利用不足的问题。实验结果表明,该模型在各项评测指标中均具有良好的表现,基于迁移学习和集成学习的文本分类方法,在小规模医疗文本数据集上表现出了优越的算法性能。在下一步的工作中,扩展模型到多层级和包含隶属关系的医疗文本多标签分类任务中,探讨基于标签序列的文本分类方法,进一步提高模型分类准确率。
