基于LDA和BiGRU的文本分类
2022-05-09冼广铭王鲁栋曾碧卿梅灏洋
冼广铭,王鲁栋,曾碧卿,梅灏洋,陶 睿
(华南师范大学 软件学院,广东 佛山 528225)
0 引 言
文本分类是指从原始文本数据中提取特征,并根据这些特征预测文本数据的类别。在过去的几年里,人们提出了大量的文本分类模型,从机器学习到深度学习。分类算法可以说是机器学习领域中人们研究的最多的一个部分,有很多成熟的算法,比如KNN[]和支持向量机[2]等。随着神经网络的兴起,各种深度学习算法也应用在文本分类中[3-6]。
文献[7]针对短文本的长度短,特征稀疏的问题,提出了一种基于局部语义特征与上下文关系融合中文短文本分类算法。文献[8]尽可能多地蕴含文本语义和语法信息,同时降低向量空间维度,提出了一种结合词向量化与GRU的文本分类算法。文献[9]结合Word2vec,改进型TF-IDF和卷积神经网络三者的CTMWT文本分类模型,相比于传统的机器学习算法具有更好的分类效果。文献[10]在LDA主题模型的基础上,利用神经网络拟合单词-主题概率分布,解决了较难权衡分类准确率与计算复杂度间的关系的问题。文献[11]基于Word2vec模型对短文本进行词嵌入扩展解决了稀疏性,并将词向量转换成了概率语义分布来测量语义关联性。文献[12]利用双向GRU提取文本特征,采用贝叶斯分类器分类,改进了单向GRU对后文依赖性不足的缺点。文献[13]改进了TF-IDF计算方法,在新闻数据集上兼顾了新闻标题和正文,效果有较大的提高。文献[14]通过词嵌入法并融合LDA主题模型扩展评论信息的特征表示方法来解决短文本数据稀疏,特征不明显等问题。
通过以上方法的分析,该文提出基于LDA和BiGRU的文本分类模型。相比于传统单一的神经网络,创新在于LDA和TF-IDF特征加权的Word2vec词向量融合,使用双向GRU捕捉文本上下文信息特征,最后经过softmax进行分类。
1 相关工作
1.1 LDA文本表示
LDA主题模型由Blei等[15]提出,是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,它包含了词、主题和文档的三层结构。文档到主题和主题到词都是多项式分布,如图1所示。

图1 LDA主题模型
图1各个字符多代表的含义为:M表示文本个数,V表示词个数,K表示主题个数,W表示词。Z表示词的主题分配,α表示文档集合中隐含主题间的相对强弱,β表示所有隐含主题自身的概率分布,其中θ表示文本主题的概率分布,φ表示特定主题下特征词的概率分布。
构建LDA模型需要对模型参数的估计,使用Gibbs抽样,基于Gibbs抽样的参数推理方法实现简单且容易理解。因此,LDA模型抽取算法主要是用Gibbs抽样算法。最后经过抽样算法得到主题-词分布矩阵φ和文本-主题分布矩阵θ,公式如下所示:
(1)
(2)
式中,φk,t表示主题k中词项t的概率;θm,k表示文本m中主题k的概率。
词向量矩阵生成后,采用基于最大概率主题下的填充方式,来解决文本特征不足的问题。
1.2 Word2vec文本表示
文本是由每个单词构成的,在深度学习中,是用词向量表示词的,通常也被认为是词的特征向量。而谈起词向量,one-hot是最简单的词向量,用一个很长的向量来表示一个词,向量的长度为词典的大小,向量的分量只有一个1,其他位置为0。但是用独热编码表示会有一些缺点:(1)随着维数的增加,计算量会呈指数级增长,尤其是用在深度学习网络;(2)存在“词汇鸿沟”现象,不能很好地表示词与词之间的相似性。2013年提出的Word2vec[16]很好地解决了独热编码存在的问题。
Word2vec通过embedding层将one-hot编码转化成低维度的连续值,即稠密向量,而且将其中具有相近意思的词映射到向量空间中相近的位置,解决了独热编码的词汇鸿沟和维度灾难的问题。Word2vec有CBOW和Skip-Gram两种模型。CBOW是在已知上下文预测当前词,而Skip-Gram相反,根据当前词预测上下文的词。该文采用Skip-Gram模型。
1.3 TF-IDF算法
TF-IDF是一种统计算法,是用来评估一个字词在其文件的重要程度。它的重要程度与其出现在文件中的次数成正比,但与它出现在语料库中的频率成反比。TF-IDF算法常用在搜索引擎、关键词提取、文本相似性和文本摘要等方面。
其中,TF(term frequency)是词频,代表关键字出现在文本中的频率。这个数字通常被归一化。
TFw的公式如下:
(3)
其中有一些没意义的词,比如“啊”“的”之类的,对于判断文章的关键词没有什么用处,称它们为停止词,在度量相关性时不会考虑这些词的频率。
IDF(inverse document frequency)是逆文本频率,包含关键词w的文档越少,就说明关键词w具有的区别能力越好。对于关键词w,求它的IDF,总的文章数量除以包含w关键词的文章数量,取对数。
IDFw的公式如下:
(4)
(分母加1是为了避免分母为0的情况)
因此,对于任意关键词的TF-IDF就是:
TF-IDF=TF*IDF
(5)
2 模型框架
该文提出的模型框架一共由三部分组成,第一部分是数据集的预处理,包括分词、去除停止词等一些步骤;第二部分是Word2vec训练词向量经过TF-IDF进行加权和LDA模型进行向量拼接;第三部分是将第二部分得到的向量输入到BiGRU中,提取更深层次的特征,最后输入到softmax进行分类。总体框架如图2所示。

图2 模型框架
2.1 向量融合
首先用Word2vec中的skip-gram模型进行词向量的训练,虽然词向量生成选择了Word2vec,但是无法反映出词语对文本的重要性,因此选择了TF-IDF对词语进行加权,通过使用该算法很好地反映出哪些词语对文本比较重要,使得后续分类工作效果更好。
把经过Word2vec训练的词向量和所对应的词的TF-IDF权重进行相乘得到新的词向量,词向量数乘公式如下:
D'=word2vec(w) × tfidf
(6)
其中,D'是词语w进行TF-IDF加权后的词向量,word2vec(w)为词汇w的Word2vec词向量。将每个词D'与LDA模型主题的主题-词分布矩阵相匹配,用最大主题的前r个词作为该词的扩展,得到D'',模型如下:
D''={w1,(c1,c2,…,cr),…,wn,(c1,c2,…,cr)}
(7)
D''为D'的基于LDA的扩展模型,wn为第n个词,(c1,c2,…,cr)为wn词的r个扩展。
得到Word2vec经过TF-IDF加权的词向量D'和经过LDA最大概率的扩展D'',把这两个向量进行拼接,如下所示:
D={D';D''}
(8)
其中,“;”表示向量的顺序拼接操作。得到融合的向量D后,接下来就是输入到双向GRU中,提取文本深层次的特征。
2.2 BiGRU相关神经网络
循环神经网络能很好地处理文本数据变长并且有序的输入序列,能将前面提取到的有用信息编码到状态变量中,而且循环神经网络的变体GRU加入了门控机制很好地解决了梯度消失的问题。
2.2.1 GRU
GRU(gated recurrent unit)网络是RNN的一种变体,它简化了结构,只需3组参数,运算时间和收敛速度与RNN相比都有较大的提升。其结构如图3所示。

图3 GRU模型
根据GRU神经网络的结构,得到以下前向传播的重要公式:

(9)
(10)
rt=σ(Wr· [ht-1,xt])
(11)
zt=σ(Wz· [ht-1,xt])
(12)
yt=σ(Wo·ht)
(13)
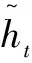
虽然单向的GRU能提取文本的长距离特征,但是只从一个方面提取的特征还不够充分。因此要利用BiGRU从前向和后向提取文本长距离特征,充分考虑到上下文文本信息特征。
2.2.2 BiGRU
BiGRU[17]是由两个反方向的单向GRU组成,单向GRU和传统的单向循环神经网络一样只能关联历史数据,不能充分学习上下文。单向循环神经网络及变体只能根据前面的时序信息预测下个时刻的输出。BiGRU的输出是由两个反方向的GRU状态共同决定,在每一个时刻t,输入会同时提供给两个反向的GRU。
得到Word2vec和LDA向量融合的文本矩阵后,输入到BiGRU中,获得更深层次的文本特征,最后进行softmax归一化处理,根据所输出的概率判断所属类别。
3 实 验
3.1 实验环境
该文所使用的实验环境为win10 64位,i5-8300H处理器,内存为16 G,固态硬盘256 G。
3.2 数据集来源及处理
使用的数据集是天池比赛新闻文本分类数据集和爬虫爬取的新闻文本数据集,其中天池比赛赛题数据按照字符级别进行匿名处理,整合划分出14个候选类分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐的文本数据。其中包括训练集20万条,测试集10万条。根据统计结果分析,该数据集类别分布存在较为不均匀的情况,科技新闻最多,星座新闻最少,做以下处理,去掉数量最少的房产、时尚、彩票和星座四个类别的新闻。
3.3 实验参数设置及对比模型
对于主题个数的选取,如果设置主题数过大,LDA主题模型计算复杂度会比较大,而且容易产生过拟合,因此根据文献[18]设置其他参数,超参数α默认值为0.5,β默认值为0.1。根据以往经验,词向量维度设置100效果最佳,词向量维度大于100时,随着维度增加模型的效果并未显著变化。对于BiGRU隐藏层节点数,隐藏层节点数过小的话,模型缺少学习和信息处理的能力,如果节点数过多的话,会使模型结构变得复杂,增加训练的时间。为了防止过拟合,模型在输出前使用了dropout函数,参数设置为0.5,使用Adam优化器,相比于其他优化算法,Adam集合了AdaGrad和RMSProp两个算法的优点,计算高效,内存使用少。最后输出层使用softmax函数,连接到10维的向量,根据离散概率分布输出预测类别。
设置了三个对比模型,用来验证提出模型的有效性。实验分别用GRU、BiGRU、CNN作为对比模型。
3.4 实验评价标准
为了验证提出模型的有效性,使用准确率、精确率、召回率和F1值综合评分作为衡量指标。对于精确率P,定义为预测为正类的结果中,正确个数占的比例,又称查准率。召回率R定义为实际为正类的样本中,正确判断为正类占的比例,又称查全率。F1值是由精确率和召回率计算得来的,是精确率和召回率的调和平均值。表1为混淆矩阵,准确率由预测准确的TN和FN的和与总预测相比得到的,召回率、F1值计算公式如下:
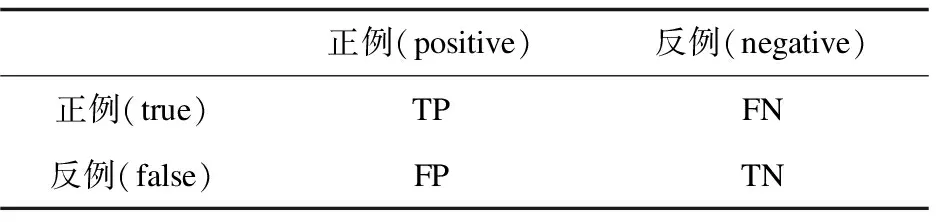
表1 混淆矩阵
(14)
(15)
(16)
(17)
3.5 实验结果与分析
(1)主题个数的选取。
采用LDA主题模型对分类文本向量进行扩展,充分结合有关信息,来解决提取文本特征信息不足的问题,因此设定主题数为[0,60],把LDA扩展特征输入到分类器中。选了3个较常用的分类器,分别是Bayes、SVM和KNN,采用F1值作为评价指标。实验结果如图4所示。
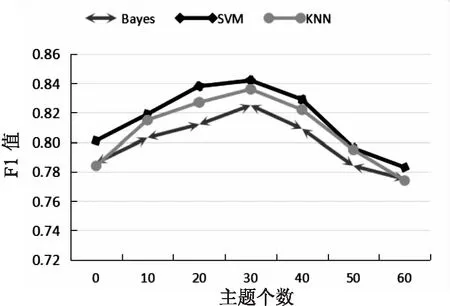
图4 主题个数选取结果
由图4可知,当主题数设定为30时,分类效果最好,当主题的个数小于30时,效果并没有显著变化,当主题数大于30时效果显著下降。因为随着主题数的增加,容易产生过拟合,而且计算复杂度也会随着主题数的增大而增加。由此以下实验中LDA主题数确定为30。
(2)隐含层节点数目的选择。
双向循环神经网络的隐含层节点数目影响分类效果,如果隐含层节点的数量过少,使得模型无法充分发挥学习上下文信息的能力,网络也无法处理复杂的问题;选用过多,虽然可以减小网络的系统误差[19]但是会增加网络训练的时间,也容易使网络训练过度导致过拟合。因此,确定双向循环神经网络隐含层合理的节点数目以便后续实验进行。在满足精度要求的前提下取尽可能紧凑的结构,即取尽可能少的隐层节点数。该实验节点初始数目设置为60,间隔大小为20。实验结果如图5所示。
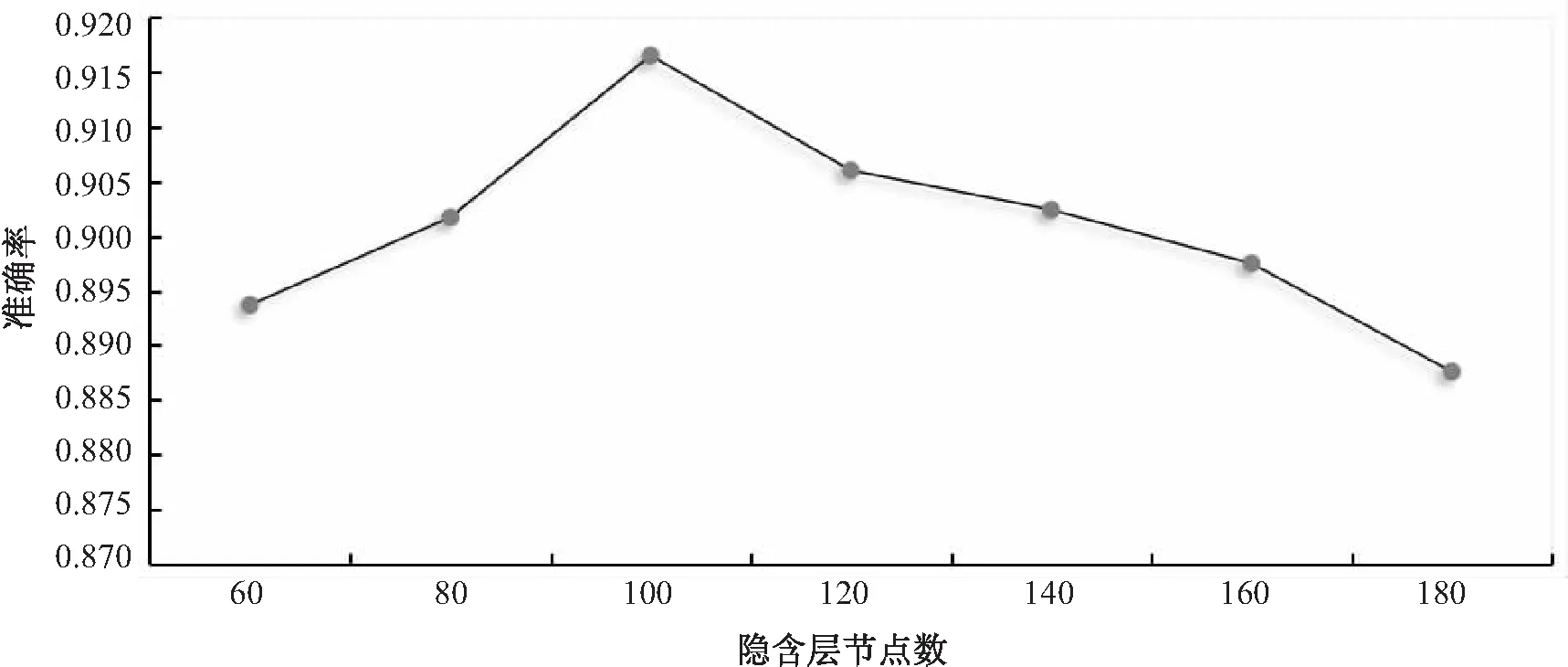
图5 隐含层节点数效果
由图5可知,当节点数为100时,模型的准确率最好,由此可知隐含层节点数已达到最合理的数目;当节点数大于100时,随着节点数增加准确率而下降。说明节点数过多,会导致网络训练过度模型效果变差,因此,后续实验中的模型隐含层选的节点数选择100。
(3)对比实验。
经过第一个实验确定主题数和第二个实验确定隐含层节点数目后,为了验证该模型的有效性,在新闻数据集上所得的实验效果如表2所示,采用准确率、精确率、召回率和F1值作为评价指标。
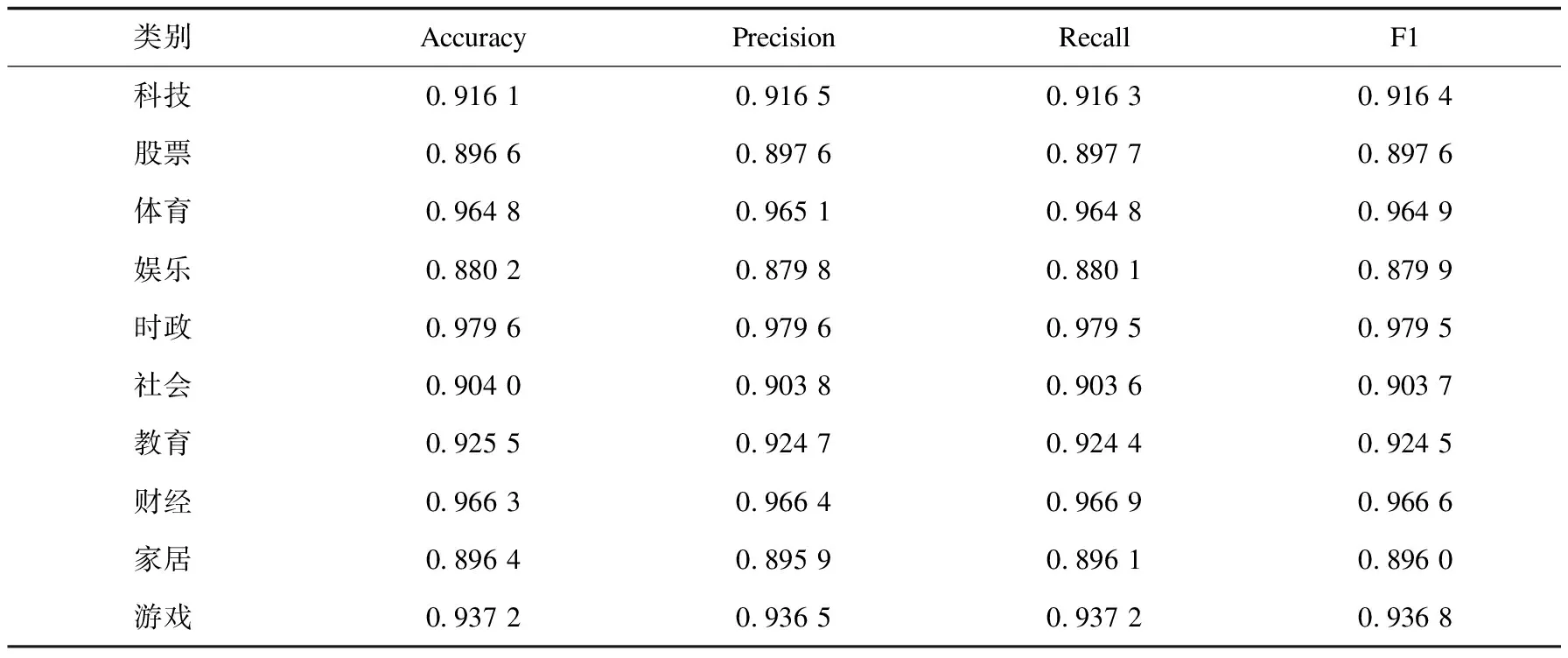
表2 文中方法效果
从表2可以看出,文中方法在时政和财经上分类效果最好。
为了更好地证明文中方法的有效性,采用各个新闻类别的Precision、Recall和F1值的平均值作为评价指标,各个分类方法总体效果如表3所示。
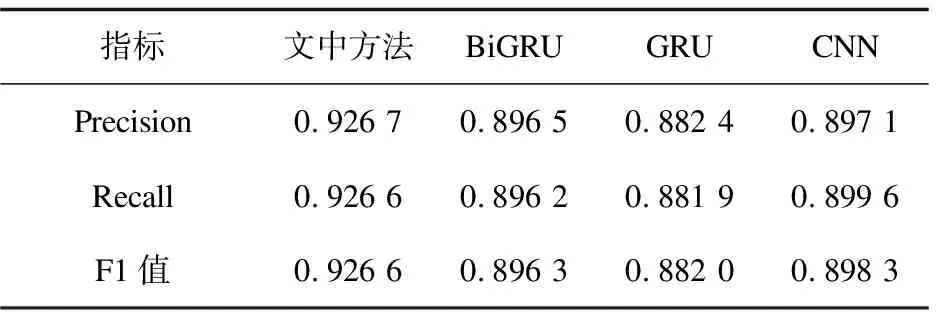
表3 各个分类方法整体效果
从表中易得出文中方法在F1值上比优于BiGRU模型,验证了扩展主题特征的有效性,丰富了主题信息;BiGRU模型比GRU模型表现稍好,是由于双向循环神经网络不同于单向循环神经网络,该网络考虑从两个相反的方向提取文本的深层次文本信息,而且文中方法提出的模型在F1值上也比GRU模型高了4个百分点。综上,文中方法引入了LDA主题模型来扩展特征信息,使用双向循环神经网络是有效的。
(4)数据量大小对实验结果的影响。
图6为数据量大小对F1值的影响。横坐标为每个新闻分类的数据量,纵坐标为F1值。由图可知,随着数据量从1 000增加到2 500,四种算法的效果有较明显的提升,这是由于数据量少不能充分学习特征,数据量多能充分学习特征。四种算法中,当数据量从1 000到1 300时,其他与RNN相关的神经网络明显比CNN斜率大,验证了RNN神经网络的变体GRU具有收敛速度快的特点。当数据量约为2 400时,各算法效果到达均衡状态。由图6可知,文中方法能在数据量较少的情况下,相比于其他算法获得不错的实验效果,验证了该方法的有效性。
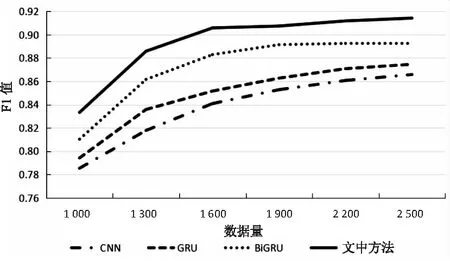
图6 数据量效果
4 结束语
提出一种基于LDA主题模型和BiGRU的文本方法。该方法首先使用Word2vec训练词向量,然后经过TF-IDF加权,对词向量特征进行增强,且经过LDA主题模型扩展的特征进行向量融合来扩展特征信息,再经过双向GRU从前后两个反方向提取文本的深层次信息,最后经过softmax函数进行分类。该模型在新闻分类数据集上进行了实验,与其他现有的方法相比,在各项评价指标上都取得了不错的效果。
由于提取特征为单一的神经网络,所以下一步考虑使用CNN作为辅助模型提取局部特征多个神经网络模型融合的方法来提高分类效果;对于词向量训练的方式,预训练模型BERT[20]在多项NLP任务已经取得了不错的效果,下一步会考虑使用预训练模型提高分类效果。
