基于新能源汽车充电数据的全国充电桩研究模型
2022-05-08郑陈亮王兴月谢燕芳
郑陈亮,张 亮,程 登,王兴月,谢燕芳
(上汽通用五菱汽车股份有限公司广西汽车新四化重点实验室,广西 柳州 545007)
引言
新能源汽车近年来展现出良好的发展事态。充电桩作为新能源汽车必不可少的需求,充电桩的基础设施建设也备受关注。在充电桩的基础设施建设无法匹配新能源汽车的增长速度的背景下,许多厂商纷纷投资建设了自家开发的充电桩,用户只需要下载对应商家开发的App,即可找到该商家投放在附近的充电桩。一定程度上解决了新能源汽车“充电难”问题,但也衍生出了用户寻找充电桩问题,如需要下载多个商家的App,如何判断并找出最近的充电桩点等问题。有些商家提供了信息整合服务,通过购买前几家充电商家的充电桩信息做整合开放给用户使用,这一做法从一定程度解决了App 数目多的问题,但也存在一些问题,一是整合成本高,二是后期迭代无法把控。因此,新能源汽车用户和充电基础设施之间存在的“信息鸿沟”,厂商间没有开发一个统一的充电应用App,使得“充电难”和充电设施资源浪费的情况依旧存在。
目前国内外关于新能源汽车充电桩桩点的选址已有了不少研究。黄丹慧[1]以重庆市出租车为例,提出了一种多层次的充电桩选址优化模型,孙文静[2]借助I-DBSCAN 算法和ED-DBSCAN 算法探讨挖掘了有规律出行的城市私家车的出行信息。李永攀[3]等人对比分析了深圳各个城区新能源汽车充电次数,并得出新能源用户更集中分布在经济发达且教育程度普遍更高的地区。万众[4]等人对广东省的高速公路服务区的新能源汽车充电设施布局进行了深层分析,发现存在充电需求偏低的服务区。Erotokritos Xydas 针对英国的新能源汽车充电需求特征进行了分析[5],Stuart Speidel 等人对澳大利亚西部新能源汽车的充电模式进行了分析研究[6]。纵观国内外学者研究,新能源汽车的充电桩分布及合理布局是当前新能源汽车售后研究的热点问题之一,同时以往学者的研究更局部在某个地区,并未推行至全国,尚未提出一种可用于分析全国新能源汽车充电桩的研究模型。
为了能够有效改善全国新能源汽车用户“充电难”问题,本文依据新能源汽车用户海量的充电数据,应用数据挖掘技术分析挖掘用户的充电位置,建立相关的聚类模型,研究出充电桩位置及数量,从而完善充电桩数据,为全面完备的充电APP 应用场景开发提供参考依据。
1 研究方法与数据说明
1.1 研究方法
充电桩点的预测分析本质上属于聚类问题,即根据用户的充电位置信息进行聚类判别。有较多聚类的方法,大体上可以分为划分方法、层次方法、基于密度的方法、基于网格的方法和基于模型的聚类方法。
DBSCAN(Density-based Spatial Culstering of Application with Noise)算法是一种由Ester Martin 等人[7]提出的基于密度的空间聚类算法。该算法的中心思想是:对于某一聚类中的每个对象,在给定半径(Eps)的邻域内数据对象个数必须大于某个给定值,换言之,领域密度必须超过某一个阈值(MinPts)。DBSCAN 算法因其收敛速度较快,同时能够处理任意形状的聚类,被广泛应用于空间数据聚类中。本文将采用DBSCAN 算法进行分析,DBSCAN 算法详细介绍可参考文献[8]和[9]。
1.2 数据说明
本次研究使用某整车企业1 230 台新能源汽车最近3 个月的车辆充电数据,主要包含充电时间、充电经纬度、充电时长等数据字段。数据由车载传感器采集,并由T-BOX 终端遵照GB/T 32960-2016《电动汽车远程服务与管理系统技术规范》,通过移动网络以一定的周期将数据实时传输至企业的大数据平台。
海量的原始数据中存在着大量不完整的数据,直接使用原始数据将会导致挖掘结果存在偏差,因此数据预处理尤为重要。本次数据预处理包括剔除异常数据、剔除轨迹漂移点及数据经纬度转换等。由于数据库下载的经纬度数据参考的是WGS-84 坐标系,是GPS 全球卫星定位系统使用的坐标系,但高德地图使用的是由WGS-84 加密生成的GCJ-02 坐标系,若要将识别出位置,必须要对经纬度数据进行转换成高德API 可调用的坐标系。
2 实证分析
2.1 充电桩点判断
基于DBSCAN 聚类的实现过程,首先需要设定关键参数Eps 和MinPts。从聚类数据样本集X 中任意选取一点p,若该点的条件符合核心对象的判定,那么从该点密度可达的所有数据点成为一个聚类,而不属于任何簇的数据点则被标记为噪声点。表1 中展示出不同Eps 和MinPts 组合时,聚成的簇数。当Eps=0.001,MinPts=4 时,簇数为3 335;当Eps=0.002,MinPts=4 时,簇数为3 248;当Eps=0.001,MinPts=5时,簇数为3 770;当Eps=0.002,MinPts=5 时,簇数为3 665。使用“平均变化程度”作为分析指标。在实验中涉及两个参数,Eps 和MinPts,根据控制变量法,固定住其中一个参数,用簇数变动率与参数变动率之比的绝对值作为该参数对簇数影响程度的衡量指标,称之为“平均变化程度”。根据视参数为增加还是减少,在计算时有两种算法,如在比较表1 中1 号与2 号实验时,参数MinPts 均为4,关于参数Eps 的平均变化程度为=0.054,分别称为参数增加时的平均变化程度和参数减小时的平均变化程度。
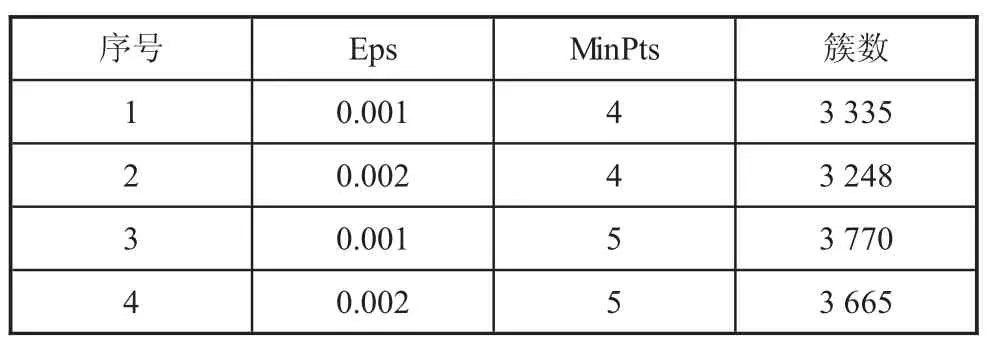
表1 DBSCAN 算法参数选择
在Eps 值相同时,MinPts 值大的对应簇数越大,变化幅度可达400 簇左右;在MinPts 值相同时,Eps值大的对应簇数越小,变化幅度可达100 簇左右。结合表2 的计算结果,调整MinPts 参数所带来的平均变化程度明显大于调整Eps 参数所带来的平均变化程度。可以认为最终分类簇数受到MinPts 参数的影响更大,需要根据实际的分类数目需求合理选择MinPts 参数,然后再调整Eps 参数。根据实际情况,本实验选择MinPts=4,Eps=0.001 作为DBSCAB 算法中的关键参数。由此可见,通过1 230 台车三个月的充电数据,可以识别出3 335 的充电桩点。
为了具体了解充电桩点的位置信息,借助高德开放平台,将其可视化,如图1 所示,图中圆圈未标有“P”字样表示用户的实际充电数据,圆圈中标有“P”字样代表该簇充电桩的中心位置。为了验证算法的准确性,借助高德地图现有的充电桩分布,见图2。通过对比分析可以发现,借助DBSCAN 聚类算法识别出的充电桩位置较为准确,且充电桩的分布更为丰富。
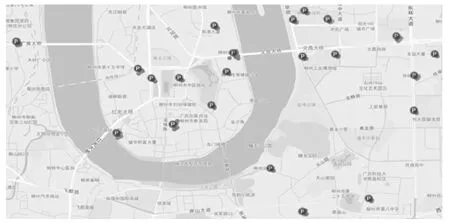
图1 充电桩位置分布图
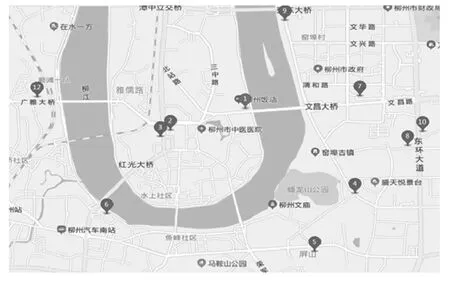
图2 高德地图充电桩位置分布
2.2 充电桩数判断
本节将依据上文的算法模型识别出的充电桩位置,判断各个充电桩的数量。假定每个位置充电桩的数量至少为一个,共收集了N 天的充电数据,将每一天(0∶00—24∶00)划分为K 个等间距的时间片段,一个充电桩在第n(0<n<N+1)天中第k(0<k<K+1)个时间段有nk 条充电记录。第k 个时间段的最高充电记录为ak=max{nk,0<n<N+1},它是以第k 时间段数据进行推断的充电桩数量估计值,然后求每个时间段推断出的估计值中的最大值M=max{ak,0<k<K+1},该值体现了该位置充电桩数目的经验下限,即该位置的充电桩数目从经验数据上进行推断的结果是:不少于M 个。由于M 是通过实际数据算出的,也体现了该位置真实使用的充电桩数目,因此也称M 为“活跃充电桩数量”,简称“充电桩数量”。
充电桩数量的估计值与划分的片段数目K 有关,根据目前市面上电动车的平均充电时间实际值,本文确定的K=24,即每个片段有1h,得到各个站点的充电桩数量估计值如表2。

表2 各站点充电桩数量 个
由表2 充电桩的数量可知,有10 个充电站点的充电桩数量为2 个,其余站点充电桩数量均为1 个。目前所能够识别的充电桩的数量较少,可能原因是样本量较小。
3 结论
本文基于DBSCAN 聚类设计了一种新能源用户的充电桩位置研究模型。本文根据新能源用户充电数据,能够准确的聚类判别出全国充电桩的位置,并判断出充电桩的数量,在一定程度上有效地改善了识别充电桩位置的难题,完善了充电桩数据,为App 应用场景开发提供了参考价值。
