结合特征选择的SAE-LSTM入侵检测模型
2022-05-08王文涛汤婕王嘉鑫
王文涛,汤婕,王嘉鑫
(中南民族大学 计算机科学学院&湖北省制造企业智能管理工程技术研究中心,武汉 430074)
信息时代下,网络与信息安全的可靠性愈发的得到大家的重视,入侵检测系统(Intrusion Detection System,IDS)被公认为是防火墙后的第二道网络安全闸门,在网络信息安全领域发挥着重要的作用.IDS根据输入数据的来源可分为:基于主机的入侵检测系统(Host Intrusion Detection System,HIDS)和基于网络的入侵检测系统(Net Intrusion Detection System,NIDS)[1],以下将主要讨论NIDS的入侵检测.
现阶段NIDS分为两种:误用检测(Misuse detection)系统和异常检测(Anomaly detection)系统[2].误用检测系统是基于已知特征和模式的知识来检测攻击,这些特征和模式可以统称为signature[3].但随着网络传播速度不断提高,数据维度急剧增加,传统入侵检测系统无法及时提取有用属性并做出检测判决,造成了误警率高、检测率低的问题[4].
将机器学习应用到NIDS已成为近年来网络安全领域的研究热点.余等[5]研究了融合粒子群算法和支持向量机的网络入侵检测技术.前者通过采用粒子群优化算法确定惩罚参数C和核宽度参数,排除特征集噪声干扰,优化了支持向量机迭代过程.任等[6]利用K近邻离群点检测算法,先将大量数据集分离出小规模且高质量的训练集,再通过多层次的随机森林分类器,实验发现该方法可以有效检测Probe攻击.
现实的网络流量数据存在大量冗余特征,对冗余特征进行分析通常会占用大量内存和计算资源[7].因此,对网络数据进行特征提取是构建有效模型的关键.此外,张等[8]研究发现对大量的特征训练会导致分类算法对训练样本产生过拟合,难以泛化到新样本.近年来,深度学习(Deep Learning,DL)的出现为解决机器学习的局限性提供了新的思路.
目前深度学习在NIDS分类算法主要包括5种:深度神经网络(Deep Neural Networks,DNN)、卷积神经网络(Convolutional Neural Networks,CNN)、循环神经网络(Recurrent Neural Network,RNN)、深度信念网络(Deep Belief Network,DBN)和自编码器(Autoencoder,AE)[9].之前的大部分工作都忽略了时间维度对检测性能的影响.针对该问题本研究在深度学习模型上选取稀疏自动编码器(Sparse Autoencoder,SAE)、长短时记忆网络(Long Short-Term Memory,LSTM)来构建入侵检测系统分类器.具体研究工作如下:
(1)基于UNSW-NB15数据集的包特性聚成4类特征:时间特征、内容特征、基本特征、额外生成特征.其次运用特征工程的思想,对特征进行排序:簇间按照随机森林重要性排序,簇内特征计算与分类信息的相关性并设定相关性阈值.在排序后的特征簇内依次选出大于阈值的重要特征,剩余特征则按照先簇间重要性、后簇内相关性的规则排序,最终得到全部特征排序,并选出表现较优的前13个特征.
(2)设计基于SAE-LSTM的异常流量检测模型,运用稀疏自动编码器(SAE)重构数据,将重构后的数据输入LSTM神经网络分类器进行分类.
1 相关工作
从20世纪90年代末起,入侵检测技术的研究取得了飞速的发展,特别是在构建智能化方面取得了飞速的进步[10].入侵检测研究重点是对入侵行为进行判断,本质上是一个分类问题,然而网络数据中大量冗余及不相关网络特征会严重干扰IDS的分类过程.
1.1 入侵检测系统的特征选择
早期研究发现,不同类型的攻击和正常行为都与数据集的各个特征属性存在一定程度的关联性.因此寻找到最小的特征子集不仅能简化运算,还能提升检测率[11].由于IDS所需处理的数据量极大,系统中的冗余及无关特征会造成计算复杂度高、资源开销大的问题.因此,特征选择已成为入侵检测系统的重要部分.2010年,钱[12]提出可从两方面讨论IDS特征选取:相关性尺度及重要性度量尺度.前者是讨论特征与分类标签间的相关性度量,筛选出相关性高的特征;后者是将入侵检测看作分类系统,依据不同特征对目标分类的贡献度来打分.学者在重要性度量方面有诸多研究:BREIMAN[13]提出通过随机森林(Random Forest,RF)的置换特征重要性计算特征的重要性得分.陈[14]在CIC-IDS2017数据集上运用随机森林进行特征选择选取前30个特征进行机器学习.2020年,何[15]提出结合RF与特征递归消除的混合特征选择方法.
不仅在入侵检测领域,RF在医学[16]、信息学[17]等方面也有广泛运用.但RF问题在于:适用于低维的数据集特征选择,当特征规模较大时,计算效率会大大降低,通常需引入前向或者后向算法来消除特征.
1.2 入侵检测系统的RNN深度学习研究
网络攻击在一段时间内是连续的,t+1时刻的数据特征和t时刻可能具有一定的相关性.RNN目前能够很好地处理与时间相关的序列数据,但它在时间序列数据过长时,会出现梯度消失和梯度爆炸的问题[18].
2017年,WANG[19]等发现当正常流量数据包含异常攻击流量数据时,会产生较高的重构误差,导致较高的漏警率和误警率.为了解决这一问题,他提出了一种多层的长短期记忆网络(Long Short Time Memory,LSTM),用于从上下文中学习网络数据的表示.同时使用LSTM的编码器及解码器的功能来重构数据.
YIESI等[20]利用简单的自动编码器和SVM分类器对入侵检测系统的流量数据进行自动特征提取.研究者使用不同的激活函数和损失函数分别在KDD-99、NSL-KDD数据集上实验,结果表明,激活函数为ReLU以及损失函数为交叉熵损失函数取得比其他函数更高的检测精度.
入侵检测技术已成为检测网络域中各种恶意活动的重要机制.基于前文的研究,提出一种结合聚类思想的随机森林特征选择以及SAE-LSTM分类器的入侵检测模型.首先,对UNSW-NB15数据集按照数据包特性进行聚类,聚成基本特征、内容特征、时间特征、额外生成特征4大簇.保持其他簇不变逐一对同一特征簇的特征进行随机森林置换,通过置换前后预测误差大小来衡量特征簇间重要性.在簇内,通过计算簇内特征与分类信息的相关性进一步得到簇内特征排序.在UNSW-NB15数据集上做特征选择,取出前13个特征.在分类器上,采用融合稀疏自动编码器(Sparse Autoencoder,SAE)作数据重构的LSTM分类器.该模型可在一定程度提高IDS的检测准确率,同时降低误报率和漏警率.
2 基于特征选择的SAE-LSTM入侵检测模型
为提高NIDS的检测性能,提出了一种基于特征选择的LSTM深度学习方法,方法的实验框架如图1所示.主要包括三个阶段.
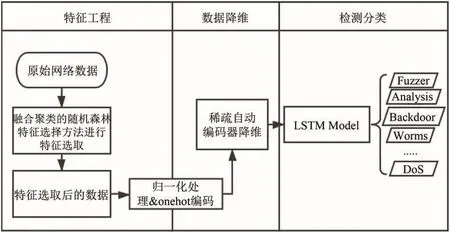
图1 基于特征工程的SAE-LSTM入侵检测模型Fig.1 SAE-LSTM intrusion detection model based on Feature Engineering
特征工程:原始网络数据集经过转换数值型数据后,输入特征选择模块,选取最优的特征集合,提高攻击检测效率.
数据降维:经特征选取后的数据集再进行清除脏数据、归一化、字符串类型one-hot编码等处理,再通过SAE进行编码、解码操作,重构数据集合,实现数据降维.
检测分类:攻击检测模型采用的是LSTM分类器.
2.1 融合聚类思想的随机森林置换重要性特征选择
随机森林在用作特征选择时分为两类:基于基尼(Gini)指数和基于置换重要性(Permutation Importance,PI).基尼系数的选择标准为依据每个子节点达到最高的纯度,即落在子节点中的所有观察都属于同一个分类,此时基尼系数最小,纯度最高,不确定度最小.随机森林置换重要性是基于“置换检验”的思想由BREIMAN针对随机森林引入的[13],其核心是对特征重要性进行检测,通过计算改变单个特征数值后模型对测试集数据的预测结果误差.如果模型的误差提升幅度较大,那么该特征就是“重要的”.如果误差不变或变化很小,则称该特征为“不重要”.
置换重要性的步骤可简述为:
1.划分训练数据集(Xtrain,Ytrain)来训练模型.
2.对训练数据集进行预测(Xtrain,Y_hat),计算准确度得分.
3.计算每个特征的置换重要性:
(1)置换训练数据集中的第i个特征的值,保持其它特征不变.生成置换后的训练数据集(Xtrain_permuted).
(2)用第2步训练好的模型以及Xtrain_permuted数据集进行预测(Y_hat_permuted)计算对应的准确度得分(score_permuted).
置换重要性的缺点在于适用低维度(特征数小于20)的数据,随着数据特征增加,采用单个特征重要性度量的方式会导致算法运行占据空间大,时间长,效率低[21].针对此问题,提出引入聚类后多特征一齐置换的随机森林特征选择方法.
表1中列出选用的UNSW-NB15数据集所有统计特征及其特征描述.根据数据包属性将特征类型聚为4类[22]:基本特征、内容特征、时间特征、额外生成特征.

表1 UNSW-NB15数据集的特征类型分布情况Tab.1 Distribution of feature types in UNSW-NB15 dataset
特征选择的流程如算法Cluster-RF所示.针对初始数据按照包属性聚类后,每个簇进行随机置换后的准确度得分除以簇内特征个数即为该簇的准确度得分.按照得分大小给簇排序,簇内特征按照与分类信息的皮尔森相关性进行排序.选出每个簇内与分类标签相关性大于0.3[23]的特征(即有相关性的特征),并按照簇重要性先排序在前.实验结果显示皮尔森相关性大于0.3的特征数量为10.而相关性小于0.3的特征则按照先簇间置换重要性、后簇内相关性依次排序.最终输出特征排序结果.
基于聚类的随机森林置换重要性算法Cluster-RF流程:
输入:原始特征集合U
输出:特征排序列表List
N为原始特征个数
{}→feature_selected,{}→feature_surplus
foriin range(N):
if特征与分类标签相关性>相关性阈值
feature_selected←特征i;
if特征与分类标签相关性<相关性阈值
feature_surplus←特征i;
将剩余特征集合feature_surplus按照特征性质聚类成簇Ck←Cluster k={1,2,,d};
对簇进行随机森林置换重要性排序得簇重要性排序Rank(Ck);
对剩余特征集合feature_surplus中的特征按照先簇间重要性、后簇内相关性大小为原则进行重新排序赋予新集合feature_surplus_sorted←feature_surplus;
输出最终特征排序List[1:N]←feature_selected+feature_surplus_sorted
End.
2.2 稀疏自动编码器
稀疏自动编码器(SAE)具有三层结构,包括输入层、隐藏层和输出层.自动编码器可分为编码器和解码器.编码器通常用于数据压缩和特征提取.由于减少了隐藏层神经元的数量,编码将同一类型的数据映射到特定的神经元上,达到降维的效果.而将提取的数据转化为输入数据的形状的过程称为解码.编码可以很好地实现从高维数据空间到低维数据空间的非线性转换.将网络数据集原始特征作为输入向量x输入公式(1)进行编码:

其中W∈Rp×q为编码层的权重矩阵,b∈Rp代表偏置向量.而σ是激活函数的表示.然后将构造特征通过如下公式进行解码.W'代表着解码层的权重矩阵,b'代表解码层的偏置向量.

对稀疏自动编码器进行训练,优化稀疏自动编码器中的四项参数,即两个权重矩阵W与W'与两个偏置向量b与b'.此时,将已得到的重新构造的特征与原始特征相比较,将它们之间的差值称之为重构误差,公式如下:
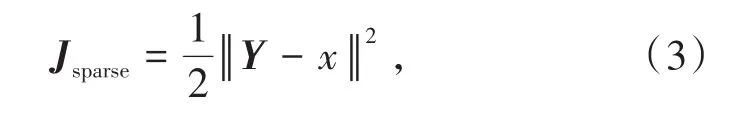
为了解决神经网络中可能会出现的过拟合现象,稀疏自动编码器在损失函数中加入权重惩罚项,可以将公式(3)合理地替换为:
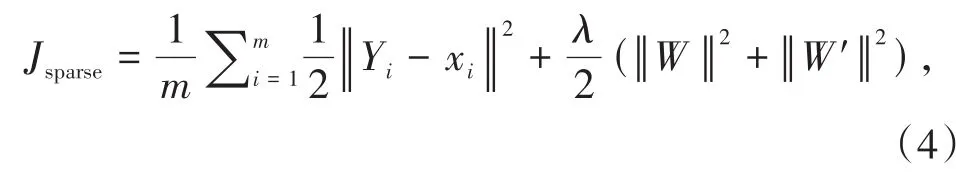
其中m为特征数量,λ为权重惩罚系数.
编码可以很好地实现从高维数据到低维数据空间的非线性转换.稀疏自动编码器利用反向传播算法使得输出尽可能等于输入,并且隐藏层必须满足一定的稀疏性,即隐藏层不能携带太多信息.所以隐藏层对输入进行了压缩,并在输出层中解压缩.整个过程会丢失信息,但训练能够使丢失的信息尽可能减少.为了保证隐藏层的稀疏性,自动编码器的代价方程加入了一个KL离散度作为惩罚项.KL离散度是衡量某个隐层节点的平均激活输出和提出的设定的稀疏度ρ之间的相似性,公式为:

实验中的稀疏自动编码器结构如图2所示:

图2 稀疏自动编码器结构Fig.2 The structure of sparse automatic encoder
2.3 RNN变种-LSTM分类模型
RNN模型面临的挑战是梯度消失.为解决这个问题,HOCHREITER和SCHMIDHUBER[18]利用3个门控单元来改进RNN模型,提出了LSTM模型.门控机制的工作原理是通过存储历史记忆,从而利用不同时间的信息计算出隐藏单元在时间步骤t的激活值ht[16].LSTM单元的结构如图3所示.获得神经单元的更新激活的过程如下.
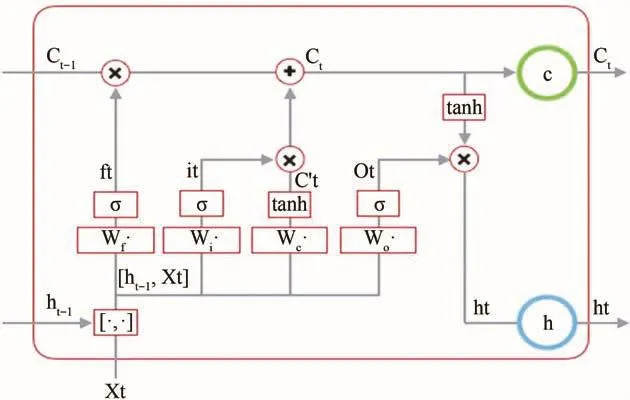
图3 LSTM模型结构Fig.3 LSTM model structure
其中LSTM网络中各个端输出的公式集合为:
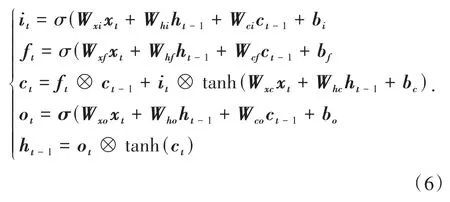
实验中网络数据集的每个时间戳经稀疏自编码器重构后得到32维数据,再输入到LSTM模型中.其中每一行即一个样本,代表一个时序状态,时序长度为1.研究采用的LSTM神经网络模型的隐层神经元结构参考了现有的LSTM模型,另外采用试值法,测试隐层节点数对异常检测模型的影响,最终试验确定每层隐藏神经元个数为32,层数为一层.
3 实验及分析
入侵检测实验在编译环境为Python 3.6.4、操作系统为Ubuntu 18.04且配备NVIDIA GeForce RTX 2070显卡的计算机上进行.
3.1 评价指标介绍
对于模型分类后的结果,实验采用的评价指标为:准确率(Accuracy)、误警率(FAR)、漏警率(MAR)和检测时间,计算公式如下.其中,TP(True Positive)表示将攻击流量预测为攻击流量的样本数.TN(True Negative)为将正常流量预测为正常流量的样本数.FP(False Positive)为将正常流量预测为攻击流量的样本数.FN(False Negative)为将攻击流量预测为正常流量的样本数.准确率表示模型判断正确的数据数量占总数据的百分比,即:
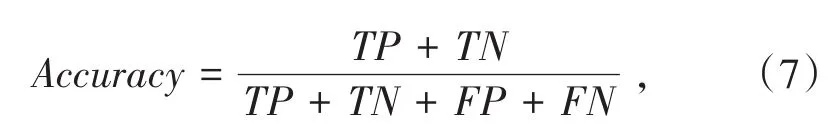
误警率表示正常流量被模型判断为攻击流量的数量占样本中被检测为攻击流量的百分比即:
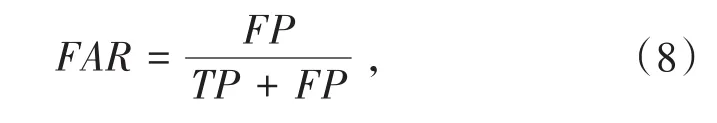
漏警率表示攻击流量被模型判断为正常流量的结果占样本实际攻击流量数据的百分比即:
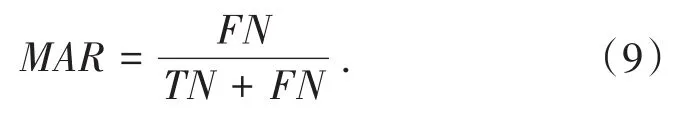
3.2 基准数据集介绍
UNSW_NB15入侵检测数据集相比于传统的KDD99和NSLKDD数据集更适合研究人员用于入侵检测技术的研究[22].它是结合真实世界攻击与目前几种典型攻击于一体的数据集,由澳大利亚网络安全中心(ACCS)创建.该数据集原始特征为49个、具有9种攻击类型,分别是Fuzzers,Analysis,Backdoors,DoS,Exploits,Generic,Reconnaissance,Shellcode和Worms.该数据集的训练集数量为175341条,测试集为82332条.
AWID数据集作为wifi数据集于2016年公开,其中包含从真实网络世界收集的正常与攻击入侵数据.该数据集中的每一条都有155个属性,每个属性特征都可解释.根据分类类别区分不同,可以分为AWID-CLS和AWID-ATK数据集.CLS数据集主要分为4类即正常、Flooding、Impersonation、和Injection.AWID-ATK数据集则是根据前面所述4类里更加细化的17个目标类别.对于这一数据集,考虑到它为高维数据集,研究中用于辅助验证特征选择方法的有效性.
3.3 特征选择结果
研究运用特征工程的思想探寻对检测精度贡献度高的特征集合.采取策略为先将数据集聚类成簇、再以簇为单位进行簇间重要性排序,簇内特征又根据与分类标签的皮尔森相关性进行排序.先取出簇内相关性大于0.3的特征[23]共10个,按簇重要性大小排序.上一步操作后再将剩余特征按照先簇间重要性大小、后簇内相关性大小进行排序,最终输出特征重要性排序.
特征排序后,为了确定最佳特征集合数量,按照排序从前8个开始选取.如图4所示.当选取特征数量为13时,UNSW-NB15数据集在提出的SAE-LSTM模型以及逻辑回归分类器中分别达到了99.1%、90.5%的准确率.
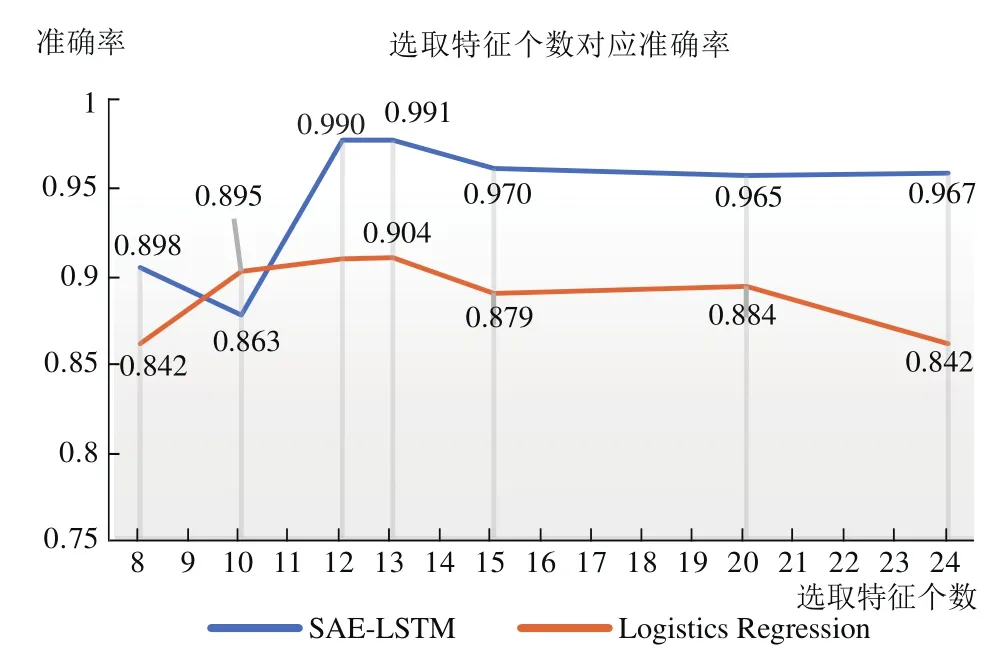
图4 测试集上选择特征个数与分类器准确率关系Fig.4 Relationship between the number of selected features and classifier accuracy on the test set
研究同时也将UNSW-NB15数据集中的8种攻击流量分别混合正常流量数据做特征选择试验.表2展示了特征选择前后各种攻击流量类型在逻辑回归分类器的准确率表现.结果表明:所提出的特征选择方法在Backdoors攻击上可以达到95.2%的检测准确率.

表2 各种攻击下选取的最优特征子集Tab.2 Optimal subset of features selected under various attacks
此外,特征选择的方法还在wi-fi数据集AWID上进行实验.该数据集包含155维特征,其中有非数值化特征”wlan.ra”、”wlan.da”等,且缺失值较多.研究在删除缺失值大于80%的特征属性后剩余96维,进一步进行特征选取,最终得到28维特征.
表3展示了两数据集特征选取前后在SAELSTM模型的准确率差异.AWID数据集准确率高达98.33%,较选择前提升14.57%.同时在高维数据集下,所提出的特征选择方法可以削减原随机森林方法的时间开销.

表3 有线及无线数据集上特征选择的表现Tab.3 Performance of feature selection on wired and wireless data sets
图5、图6展示了所选取的13维特征与四元组特征[24]即(源IP地址,目的IP地址,源端口号,目的端口号)的Renyi熵在所提出SAE-LSTM模型上作预测误报率、漏警率实验对比.
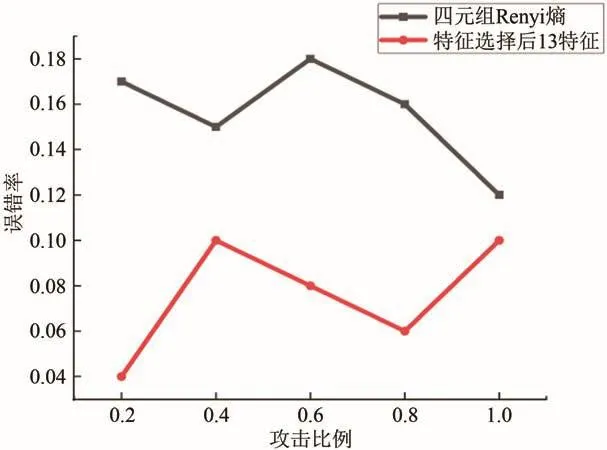
图5 四元组Renyi熵特征与选取特征误警率对比Fig.5 Comparison of quadratic Renyi entropy features and selected features false alarm rate
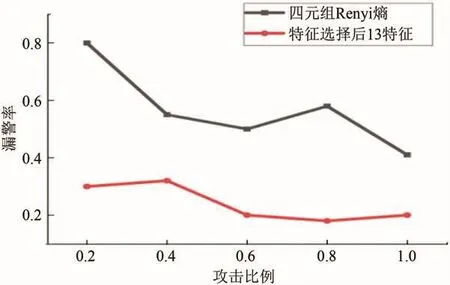
图6 四元组Renyi熵特征与选取特征漏警率对比Fig.6 Comparison of quadratic Renyi entropy features and selected features missed alarm rate
实验结果证明:当攻击比例为0.2时,四元组Renyi熵特征检测误报率到达0.17,而特征选取后的误报率仅为0.04;攻击比例为0.8时,特征选取后的13个特征集合在SAE-LSTM分类器误报率仅为0.18,较四元组Renyi熵特征集合下降4%.各项指标均表明,特征选取后的特征集合可有效提升检测性能.
3.4 预处理
由于本实验为二分类实验,实验中会除去attack_cat攻击种类字段.数据预处理过程将训练集和测试集中的符号特征protocol,service,state以one-hot编码转化为数值表示.
归一化处理:不同的特征属性字段之间的量纲会有所差异,为了消除这类差异给分类器的准确率造成影响.特此做归一化,一方面消除不同的特征属性字段之间的量纲的差异,另一方面使得数据的量纲更具有可比较性.

3.5 模型结果以及分析
实验使用Python进行编码,Keras框架构建神经元网络.在数据预处理阶段,除去有重复项的src_ip、dst_ip,src_port、dst_port四个特征.随后通过特征选择从45维特征选取13维特征.模型训练包含两个阶段:第一阶段是训练SAE重构网络数据.根据理论分析和查阅前人工作经验[25]表明隐藏层数、单位数和稀疏常数是影响SAE性能的主要因素.实验采用枚举法选取参数训练不同的SAE,确定ρ=0.04的SAE[128,32,32]达到了最好的性能,因此选择其作为SAE的参数.经测试,最终选取两层隐含层的SAE结构[26,29].第二阶段,将编码后的数据作为LSTM分类模型输入.
图7(a)、图7(b)显示SAE-LSTM模型随时间戳步长增加,训练集与测试集精度变化情况.对训练数据集,随着时间戳步长的增加,精度的提高不太明显.在测试数据集上,分类精度随着时间戳步长增加提升较明显,并且在时间戳步长为8时,检测准确率最高.
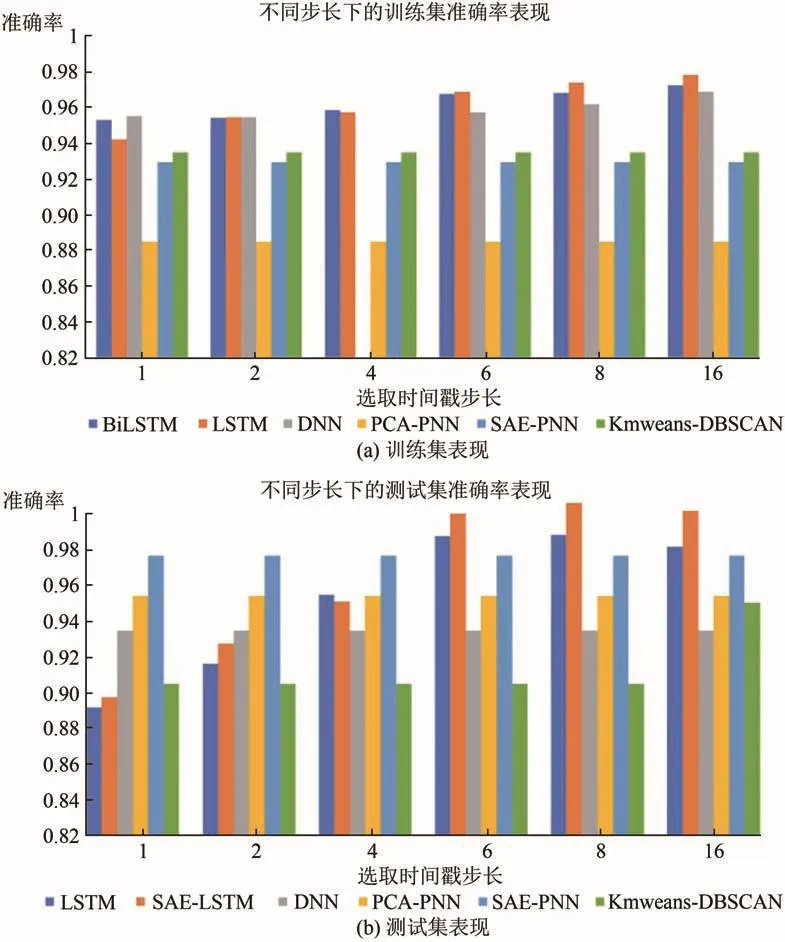
图7 不同时间步长的LSTM模型与其他模型准确率对比Fig.7 Accuracy of LSTM models with different fetch steps vs.other models
表4所示,对比同样采用UNSW-NB15数据集的相关论文模型,结合特征选择的SAE-LSTM入侵检测模型的检测率达99.1%、误报率为4.18%、漏报率为2.1%,具有更高的检测率、更低的误报率和漏报率.
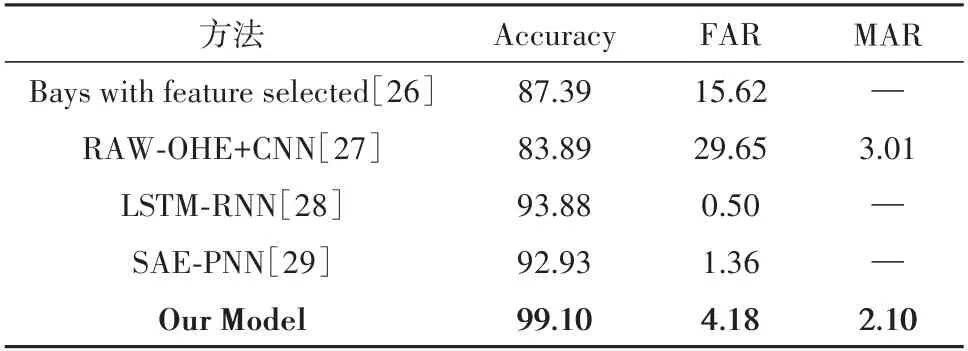
表4 实验模型与其他文献模型结果对比 %Tab.4 Comparison of the results of this model with other models in the literature %
4 结语
为削减特征冗余对入侵检测的干扰,提高入侵检测系统的准确率及泛化能力,提出一种入侵检测的有效框架,包括特征选择与检测分类两大块.首先,采用融合聚类思想的随机森林特征打分机制,在UNSW-NB15网络数据集上选取出贡献最大的前13个特征,并在155维数据集AWID上进行试验以证明特征选择方法的有效性.
特征选取后的数据,经由稀疏自动编码器提取低维的数理特征,最后将编码器的输出数据作为LSTM输入,并将时间戳步长作为研究的重要参数.实验结果表明,时间戳步长为8时,实验模型具有最佳检测精度.准确度达到98%以上,同时FAR低于4.18%.在未来的研究中,将着重于通过引入注意力机制来提高训练数据的性能.
