面向用户需求的空天地一体化车载网络任务分配策略
2022-05-07谭诗翰金凤林顿聪颖
谭诗翰, 金凤林, 顿聪颖
(陆军工程大学指挥控制工程学院, 江苏 南京 210007)
0 引 言
随着汽车技术的发展,人们对汽车的期望不再仅仅是更舒适、更环保、更有趣,对汽车信息化、智能化服务的需求正在不断增强。车载网络能够实现车辆、其他终端和公共网络之间的信息交换,可以在交通管理、车辆移动数据服务和自动驾驶等方面发挥关键作用,是未来汽车发展的重要方向之一。第三代合作伙伴计划(the 3rd generation partnership project,3GPP)一直在寻求支持长期演进(long-term evolution,LTE)和5G蜂窝网络的车载网络服务。由电信和汽车行业联合成立的5G汽车协会(the 5G automotive association,5GAA)也在致力于推动车载网络技术的开发、测试和部署。
然而,当前车载网络系统仍然存在一些重大问题。一是随着城市的快速发展,车载网络用户量激增,网络拥塞问题愈发严重;二是,用户对车载网络服务的需求趋于多样化,单一的网络服务难以满足用户需求;三是在一些偏远地区用户难以获得可靠的网络服务。
传统地面网络对网络系统性能的提升能力有限:一方面,由于地面无线接入网频谱资源有限,过密的基站部署将导致更多的网络资源竞争和网络间相互干扰;另一方面,地面网络本身有限的覆盖范围,无法满足覆盖区域边缘以及偏远地区用户的需求。
空天地一体化车载网络(space-air-ground integrated vehicular networks,SAGVN)利用现代信息网络技术将空间、空中和地面网络部分连接起来,具有覆盖范围大、吞吐量高和恢复能力强等固有优势,有望解决上述车载网络发展过程中遇到的瓶颈问题。
近些年来,大量的研究涌入SAGVN。其中,文献[11]介绍了一种可以用于SAGVN的实验仿真平台。文献[8]提出了一种基于软件定义的SAGVN架构。文献[12]在此基础上,提出了一个基于人工智能(artificial intelligence, AI)的SAGVN管理和控制架构。文献[13]也在文献[8]的基础上,提出了一种基于AI的SAGVN资源分配方式。文献[14]将虚拟网络功能(virtual network functions,VNFs)和业务功能链(service function chaining, SFC)融入SAGVN架构,用于增强SAGVN管理性能。此外,SAGVN建设在工业界也在快速推进,包括GIG、TSAT和O3b在内的多个项目已经开始了SAGVN相关的研究和实验。
但是,针对SAGVN的网络管理仍然存在以下几个难点:
(1) 地面、空中和空间网络在带宽、网络覆盖面积、时延和网络费用等差异巨大,需要统筹考虑,使不同网络发挥各自优势,互补短板。
(2) 车载用户需求向着多元化发展,对网络进行管理需要针对不同需求用户提供不同服务。
(3) 网络状态更为复杂,对网络管理的计算难度增加。
基于以上分析,本文提出了面向用户需求的SAGVN任务分配策略,通过为SAGVN内不同网络合理分配不同的网络任务,提升网络对用户的服务质量(quality of ser-vice,QoS),主要做了以下工作:
(1) 构建车载用户需求和用户满意度描述框架。相同的网络服务对于不同需求的用户,对网络QoS的体验可能截然不同,想要为用户合理分配网络,准确地描述用户需求就显得尤为重要。本文基于多准则效用理论,结合信号强度、网络费用、时延和带宽多种影响因素建立适当的效用函数,获得用户对不同影响因素的需求,然后利用层次分析法(analytic hierarchy process,AHP)获得各影响因素权重,权重的大小反映了用户对不同网络性能的偏好。根据用户当前接入网络的网络性能、用户满意度影响因素和影响因素权重,获得用户对当前网络服务的满意度。例如,通过车载网络将图片、视频和车辆信息快速上传到数据中心,用户希望获得高带宽的网络传输服务,所以用户对网络带宽需求较高,网络带宽具有更大的权重;当发生交通事故时,实时地向智能交通平台报告事故地点有助于挽救生命,避免交通拥堵,此时用户倾向于高时延高可靠度的网络服务,当前网络服务的时延以及可靠度对用户满意度影响较大。
(2) 提出整体用户满意度最大的网络任务分配策略。对于不同用户,SAGVN所能提供的网络服务也不同。本文将SAGVN任务分配过程抽象为半马尔可夫决策过程(semi Markov decision process,SMDP),通过控制不同网络为不同的用户提供服务,使长期整体用户满意度最大。利用价值迭代算法获得最优网络任务分配策略。考虑实际操作中网络状态复杂多变,利用Q-learning算法与网络进行交互学习,获得近似最优的网络任务分配策略。本文中最优网络任务分配策略具体来讲就是通过有计划性的安排,减少一些位于地面网络密集区域的用户对卫星网络资源的占用,为一些偏远地区用户预留卫星网络资源;将一些对网络带宽需求不高的用户带宽减少,从而为未来需要更高网络带宽的用户预留网络资源等方法,实现长期整体用户满意度最大。
本文的主要贡献有:
(1) 基于多种影响因素构建效用函数,并给出了这些效用函数详细证明。利用AHP,获得各影响因素权重。通过影响因素效用函数和权重来描述用户的网络需求和偏好。根据当前网络对用户服务影响因素效用函数值加权乘积,将网络对用户的QoS抽象为用户对网络服务的满意度。
(2) 基于对用户需求和满意度的描述,提出了一种面向用户需求的网络任务分配策略。将对不同网络的任务分配过程抽象为SMDP,利用价值迭代算法,获得最优的网络任务分配策略,并利用Q-learning算法获得近似最优策略。
(3) 在网络资源充足和网络拥塞两种网络环境下进行仿真实验。仿真结果表明,相较于传统网络任务分配策略,本文所提策略在网络资源充足环境下,整体用户满意度上升超过30%;在网络拥塞环境下,对用户服务请求的拒绝率下降超过40%。在网络拥塞环境下,对网络服务分配策略中用户满意度的影响因素进行分析,仿真结果表明,所提方法可以有效降低网络对网络服务需求迫切用户服务请求的拒绝率。
1 场景描述
1.1 系统架构
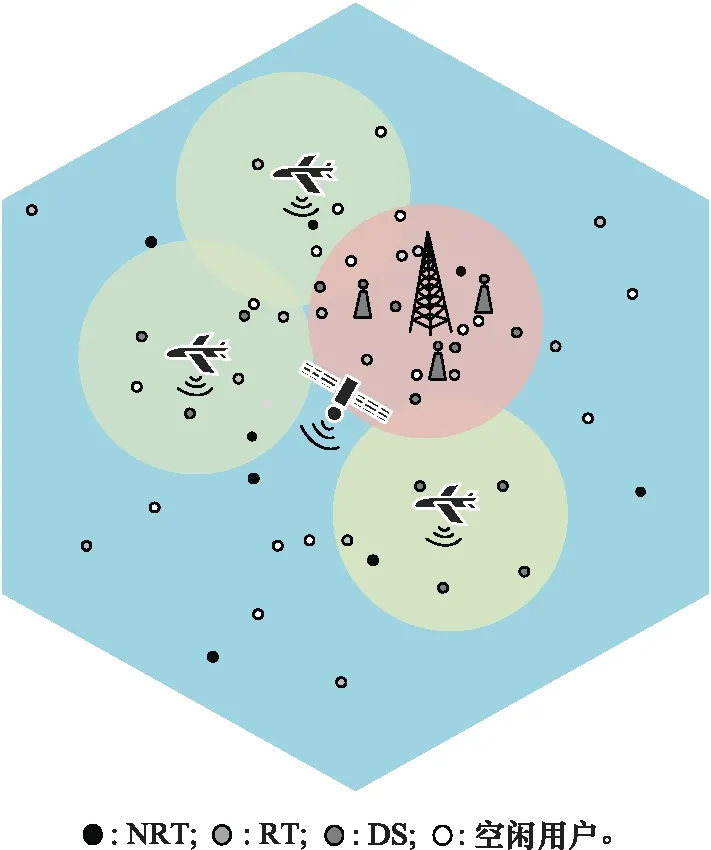
本文主要讨论局部区域内SAGVN的任务分配策略。由卫星划分一定范围的网络区域,将区域内的网络作为一个整体,对区域内的网络分配网络任务。如图1所示,SAGVN由3层组成:基础设施层、控制层和管理层。基础设施层包括空间段、空中段和地面段内所有的无线通信节点,比如低轨卫星(low earth orbit,LEO)、无人机(unmanned aerial vehicle,UAV)、地面基站等。控制层由不同网络的网络控制器组成,比如软件定义网络(software defined network,SDN)控制器,网络控制器通过南向接口(southbound interfaces,SBIs)控制各自的底层物理资源,比如卫星波束转向、UAV运动控制、网络资源分配等。管理层包括后台数据中心,功能是协调不同网络动作。控制层通过北向接口(northbound interfaces,NBIs)实现网络管理,如移动管理、网络监督、网络任务分配等功能。不同网段的网络控制器由上层管理层通过东西接口进行协调。

图1 SAGVN模型Fig.1 SAGVN model
本文基于网络管理层功能,根据由基础设施层和控制层收集上传的用户信息和网络状态信息数据,制定网络任务分配策略。网络管理层根据网络任务分配策略,通过各网段控制器控制无线通信节点对不同用户的网络服务请求做出响应,使用户接入不同的无线通信节点,实现对不同网络的任务分配。
1.2 场景模型
根据上文所述,设区域内SAGVN用户集合为,用户∈,设区域内用户总量为,设∈{0,1},=1表示网络正在对用户服务,=0表示用户未接入网络,用户所接入网络的信号强度、费用、时延和带宽分别表示为、、和。
设区域内基础设施层通信节点的集合为,通信节点∈,通信节点总数为,通信节点的总功率、总带宽和最大用户量为、和,通信节点剩余带宽、剩余功率和剩余用户量为、和,覆盖用户的通信节点的集合表示为,通信节点服务覆盖范围内用户的集合表示为,设, ∈{0,1},, =1表示用户接入网络(∈),, =0表示用户未接入网络。
2 用户需求和满意度描述
对用户需求和满意度的描述是一个复杂的过程,需要多种模块协调进行。如图2所示,用户网络需求和满意度描述框架包括数据采集、网络筛选、拟合值生成和满意度计算等模块。首先,数据采集模块收集并提供用户需求描述所需的所有参数,包括用户配置、流量需求、QoS需求和运营商网络配置。在此框架中,车载终端收集和上传用户需求相关参数。基于这些参数,可以计算出信号强度、时延和网络费用等影响因素指标。网络筛选模块选择满足给定约束条件的网络,建立不同用户的可用网络集合。拟合值生成模块使用AHP为每个指标生成文献[20]中讨论的期望权重。最后,根据当前网络服务性能,获得用户对网络服务的满意度。

图2 用户需求和满意度描述框架Fig.2 User requirements and satisfaction description framework
2.1 AHP
利用AHP为每个影响因素分配适当的权重,利用权重来表征用户偏好。AHP如算法1所示。

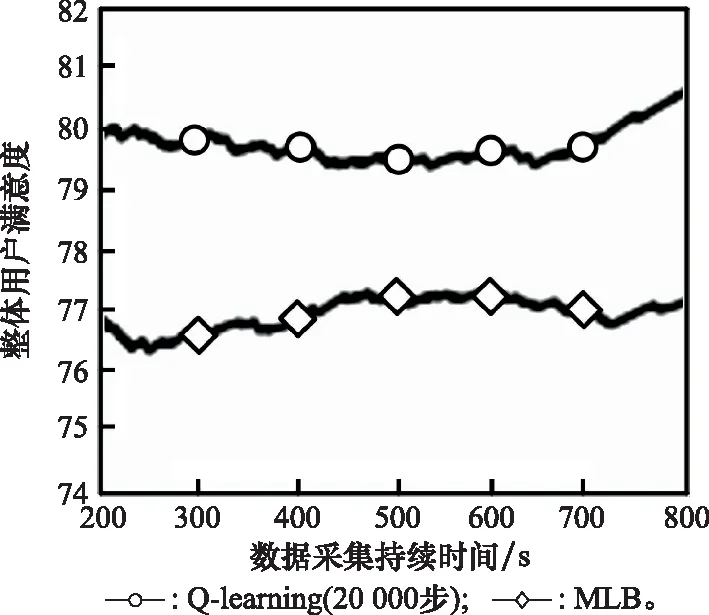
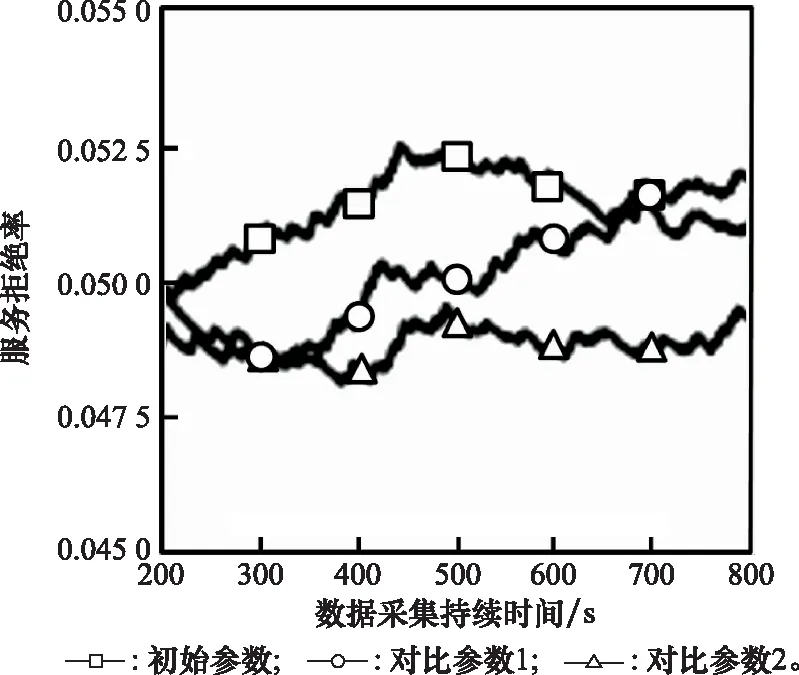
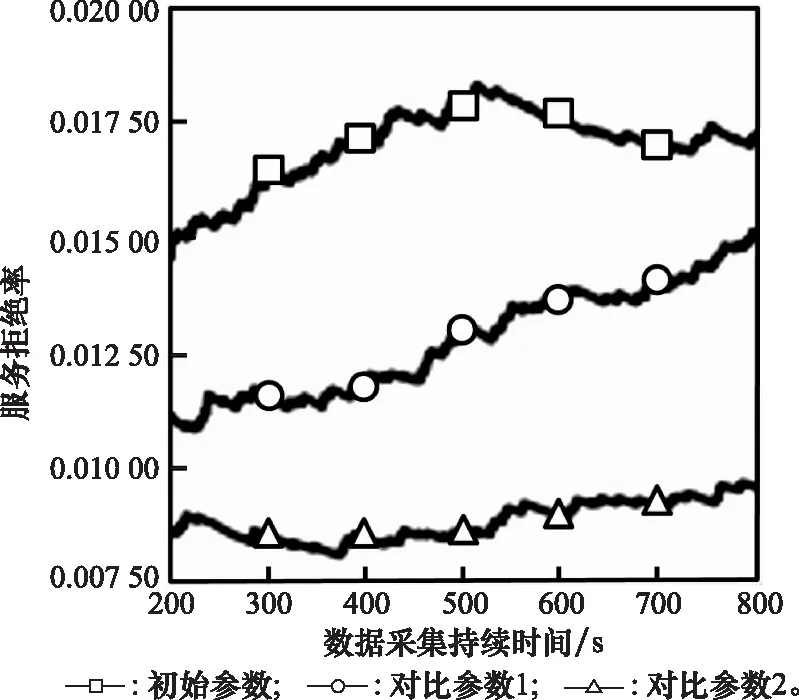
算法 1 AHP输入 用户需求:最大和最小带宽bmax和bmin,最大网络费用cmax,最大网络时延τmax,最大和最小信号强度需求smax和smin;输出 用户i对于不同影响因素权重:网络费用权重αic、信号强度权重αis、网络时延权重αiτ、带宽权重αib;过程1. 根据用户需求,构建层次结构L=l1,l2,…,lm,令k=1;2. 循环1:构建决策矩阵;3. 循环2:计算层次k权重;4. 获得网络费用权重αi,kc、信号强度权重αi,ks、网络时延权重αi,kτ、带宽权重αi,kb;5. 判断层次k权重是否一致,如果不是,返回循环1;6. 如果k 根据效用理论,效用函数要满足二次可微性、单调性和凹凸性,本文采用了文献[21]中效用函数设计方案,为每个影响因素设计了效用函数。 221 信号强度效用函数 一般情况下,当接收到的信号强度低于某一阈值时,可以认为不能保证网络正常运行。在这种情况下,信号强度的效用值为0。此外,用户所接收的信号强度具有上限。 设用户信号强度效用函数如下: (1) (2) 以下给出其他的二次可微性、单调性和凹凸性证明。 证明二次可微性,只需证明式(1)中的第2个和第3个方程是可微的。由式(1)可得 (3) 所以: (4) 因此,式(1)中的效用函数是二次可微的。同时,容易发现式(1)也是单调的、凹凸的。 证毕 式(1)的现实意义是信号强度越高,效用函数值越大,网络信号强度越好。说明所定义的效用函数()可以有效地用于网络任务分配。 222 网络费用效用函数 对于用户来说,网络费用是一个更直观的度量。不同网络的费用可以相互直接比较。本文用线性函数表示网络费用的效用函数。因此,用户的网络费用效用函数可以表示为 (5) 式(5)的现实意义是网络费用越小,效用函数值越大,网络越好。这说明所定义的效用函数()可以有效地用于网络任务分配。 223 网络时延效用函数 一般来说,网络时延应该有一个最大值。在设计效用函数时,网络时延越大,对应的效用值越低。因此,定义用户的网络时延的效用函数为 (6) (7) 网络时延效用函数与信号强度效用函数相似,都是二次可微的、单调的和凹凸的。由于篇幅限制,没有给出详细的证明过程。式(6)的现实意义是时延越小,效用函数()值越大,网络越好。这说明所定义的效用函数()可以有效地用于网络任务分配。 224 网络带宽效用函数 当网络带宽低于用户流量的最低需求时,将导致用户服务请求丢失。当网络带宽大于用户流量最大需求时,用户的满意度不会进一步提高。因此,用户的网络带宽效用函数定义如下: (8) (9) 用户满意度是用户对网络QoS体验的抽象,满意度越高,用户体验越好。 将网络对用户的服务性能参数代入用户效应函数中,信号强度可由用户终端确定,其他指标需通过网络信息采集获得。将效用函数值加权相乘,获得用户对网络服务的满意度。用户对网络服务的满意度表示为 (10) 区域内整体用户满意度表示为 (11) 本文考虑有限的单一网络服务区域网络任务分配。假设同一网络任务在任务结束前不主动切换网络,如果用户移动到了网络服务范围外,用户结束已经完成的任务部分,重新申请网络服务。为了简化模型,假设一个用户同一时刻最多只有一个网络任务。则问题描述为 (12) (13) (14) (15) (16) (17) 其中,式(12)~式(14)表示网络通信节点功率、总带宽和最大用户量的约束;式(15)表示单个用户同一时刻最多只能接入一个网络;式(16)表示单个用户同一时刻最多有一个网络任务;式(17)为用户对可接入网络服务性能约束。 马尔可夫决策过程(Markov decision process,MDP)通过探索和优化,估计不同状态下采取不同的动作所能带来的长期收益,由此可以根据当前状态选择最优的动作,从而获得长期最优的动作策略。SMDP在MDP的基础上,拓展到在无限时间内的可数时刻上选择最优动作。本文中,SAGVN状态是不断变化的,单个时刻内网络整体用户满意度最大,无法保证长时间整体用户满意度最大,所以采取SMDP的方法来获得长期整体用户满意度最大的网络任务分配策略。 尽管本文中决策时刻发生在[0,+∞)上任意时刻,但实际上只有在有新的用户请求网络服务和网络任务结束时刻需要进行网络任务分配的决策。由于网络状态取决于网络任务分配策略,所以网络状态变化是一个马氏过程。基于以上分析,可以将网络服务分配抽象为SMDP,从而获得在不同的网络状态下,对于不同需求的用户网络服务请求分配不同网络所能获得的整体用户满意度长期收益,并选择收益最大的网络为用户提供服务。 本节首先定义网络状态、行动、状态转移概率和奖励函数,然后介绍价值迭代算法。 3.2.1 网络状态空间 定义网络状态: =(,,…,,|,,…,∈) (18) 式中:,,…,表示SAGVN内无线通信节点的状态;用来描述最近一个服务数据。表示通信节点的状态量,由通信节点剩余带宽、剩余功率和剩余用户量组成: =(,,|∈) (19) 定义集合描述网络系统所有可能状态: (20) 用描述网络系统中网络任务结束时所有可能的状态,其中表示为,由结束任务所接入的通信节点和占用的通信节点功率和带宽组成: ={(,,…,,)}∈ (21) 假设通信节点结束对用户的服务,则表示为 =(,,|∈) (22) 用描述有新的用户服务请求时所有可能的状态,其中表示为,由用户的服务需求描述和用户可接入通信节点组成: ={(,,…,,)} (23) (24) 注意,这里没有讨论用户对网络最小带宽、最小信号强度、最大时延和最大网络费用的约束,但实际操作中,当用户满意度=0时,网络拒绝对用户提供服务。 显然,,包含了网络系统中所有可能状态,即:=∪。 322 决策时刻与行动集 (25) 当=0时表示网络拒绝用户的服务请求。本文中,网络可以通过主动拒绝现有的用户服务请求,为未来可能的服务请求预留网络资源。 323 状态转移概率 由上文所述,网络系统状态之间的转换是马氏过程,所以转移概率可以直接利用马氏过程的状态转移速率得到。本文中,状态转移速率分为下面几种情况: 对于状态∈,只可能发生两种转移,任务结束′∈和一个服务请求到来′∈,其转移速率为 (26) 式中:, 表示网络内用户服务结束的概率;表示区域内用户服务请求概率。 对于状态∈,假设将用户′接入通信节点′,即=′,其转移速率为 (27) 对于状态∈,假设网络拒绝用户服务请求,即=0,其转移速率为 (28) 状态动态性可以等价地用嵌入式链的状态转移概率(′|,)来表示: (′|,)=(′|,)·(,) (29) 式中:(,)表示每个状态的期望逗留时间。 324 网络奖励 为制定优化目标,设(,)表示当采取行动时,状态下所获得的永久奖励,它是以单位时间为基础定义的。本文中,用(,)表示状态下采取动作后网络的整体用户满意度,将(,)表示为 (,)=(,)+(,) (30) 惩罚项(,)反映拒绝用户服务请求所带来的长期惩罚,表示为 (,)=-·(′|,=0,∈) (31) 式中:是网络在拒绝用户服务请求的单位时间成本,即拒绝服务惩罚参数。 325 离散化时间 本文利用价值迭代算法来解决SMDP问题,以确定网络在每个状态下所采取的最优动作。因此,需要一个单值化阶段,将连续时间马氏链转换为离散马氏链。 首先,将时间离散为持续时间的区间,为恒定值,且小于任意状态下的期望逗留时间: 0<<(,),∀∈ (32) 然后,对转移概率进行如下修改: (33) (34) 326 价值迭代算法 定义网络任务分配策略(,)是状态到动作的映射,表示状态要采取的动作。当策略被采用时, ()=,,,…,,… (35) (36) 利用价值迭代算法获得最优策略,具体如算法2所示。 算法 2 价值迭代算法输入 折现因子,任意网络状态量x,迭代精度参数δ;输出 最优网络任务分配策略π*;过程1. 初始化V(x);2. 循环1:最优网络任务分配策略π*;3. 初始化前后两个策略最大优化差值:Δ=0;4. 循环2:计算每个状态x∈X的最大预期长期折现回报:V(x)←maxa∑x'p(x'|x,a)[R-(x,a)+V(x')]根据当前状态下前后两个策略差值ν',更新Δ:Δ=max(ν',Δ);5. 如果Δ>δ,返回循环1;6. 输出一个确定的π≈π*,使得:π(x)=arg maxa∑x'p(x'|x,a)[R-(x,a),V(x')]7. 结束。 虽然SMDP可以得到理论最优策略,但是在实际操作过程中用户的服务结束概率和服务请求概率很难获得,网络系统状态转移概率难以确定。此外,利用价值迭代算法计算SMDP最优策略也存在计算复杂度高的问题,很难应用于实际操作中。Q-learning算法可以通过不断与网络交互学习,递归获得近似最优策略,是解决MDP实际操作困难问题的常用方法。Q-learning算法虽然最初用于求解MDP,但稍加修改即可应用于SMDP。 3.3.1 算法描述 定义状态-动作对(,())的价值函数(,())。(,())表示网络状态,使用策略的期望长期折现奖励。目标是找到一个策略,使每个状态的值最大化: (37) 式中:表示学习率(0<<1),决定学习到的值会多大程度上覆盖旧的值;(,Δ)表示相对于单个时间区间,用户在持续时间Δ内的累计奖励值: (38) 式中:是Δ与单位时间的整数比值。 332 探索与开发 在决策过程中,网络会随机或基于以前学习的值进行决策。为获得高回报,网络可能更倾向于它过去尝试过并发现有效的行为,即开发模式。然而,为发现最为有效的动作,网络需要尝试之前没有选择过的动作,即探索模式。Q-learning算法是一种在线迭代学习的算法,探索和开发同时进行。网络必须探索各种各样的行动,并逐步趋向于最为有效的行动。并且,为获得可靠的值,需要进行充分的探索。 本文采取一种-贪婪的探索-开发策略。在决策过程中,网络以概率()进行探索,并以概率1-()利用存储的值,选择值最大的动作。为提高长期的网络性能,探索永远不会停止,而是会随着时间的推移而减少。定义(,)为状态-动作对(,)到当前时间的访问次数。()为 (39) 为使(,)收敛到最优值,将设为 (40) 具体如算法3所示。 算法 3 Q-learning算法输入 网络系统当前状态x;输出 网络动作a;过程1. 初始化Q(x,a),状态参数对出现次数c(x,a)=0;2. 循环:对每个时间区间更新Q(x,a);3. 计算ε(x);如果是探索模式,随机选择动作a;如果是开发模式,选择动作a:Q(x,a)>Q(x,a'), ∀a∈A(w)4. 更新c(x,a)=c(x,a)+1;5. 更新Q(x,a):Q(x,a)←Q(x,a)+ρ(R(x,Δt)+κmaxa(Q(x',a')-Q(x,a)))6. 结束。 本文使用python和ns2平台搭建了一个系统级网络仿真环境。实验环境布置LTE基站、虚拟UAV节点和虚拟卫星节点作为无线通信节点,为每一个通信节点设置网络覆盖区域、网络资源量和接入用户上限。假设不同网络使用专用频段,不存在信道资源竞争。网络资源由不同网段根据自身配置自主分配给接入用户。 为简化实验,根据SAGVN用户特性,假设车载网络中存在3种用户网络服务需求,分别为非实时服务(non-real time, NRT)、实时服务(real time, RT)和时延敏感服务(delay sensibility, DS)。其中,NRT由传统的数据流生成,比如车内用户进行邮件下载、网上冲浪等,对带宽需求较高;RT由视频流或语言流生成,比如道路实时监控或者车内通话等,对带宽和时延要求较高;DS是由汽车自动驾驶,事故应急响应等需要低时延的应用生成。网络系统内类用户(∈{NRT,RT,DS})服务请求速率服从参数为的泊松分布,服务时长服从参数为的指数分布。实验拓扑详如图3所示,参数设置如表1和表2所示。 图3 实验拓扑Fig.3 Experimental topology 表1 用户参数 表2 SAGVN参数 在网络相对稳定后,选取随机时间作为初始时刻,间隔固定时长=0.12 s收集网络数据。为了验证本文算法的有效性,将其与文献[29]所提出的基于自适应阈值移动负载均衡(mobility load balancing, MLB)策略对比。区分网络资源充足和网络拥塞两种网络环境,主要从整体用户满意度和服务拒绝率两个方面指标来讨论不同服务分配策略性能。 其中,类服务拒绝率计算公式如下: (41) 网络系统对用户服务请求的拒绝率反映了网络系统拥塞程度,计算公式如下: (42) 式中:为类服务被网络拒绝的次数;为网络持续时间。 4.2.1 网络资源充足环境 图4给出网络资源充足环境下不同服务分配策略的整体用户满意度。从图4可以看出,SMDP可以得到最优的网络系统整体用户满意度。将每一时间区间作为一个时步,Q-learning算法进行20 000步(持续时间=2 400 s),整体用户满意度接近于SMDP,同时相较于自适应MLB策略,整体用户满意度提升了超过30%。 不同于MLB策略,基于学习的方法可以通过增加学习周期,不断趋近于最优解。从图4可以看出,Q-learning算法进行5 000步(持续时间=600 s)相较于2 000步(=2 400 s),由于学习不充分,整体用户满意度下降超过20%。 图4 网络资源充足环境中整体用户满意度对比Fig.4 Comparison of overall user satisfaction in the environment of adequate network resources 4.2.2 网络拥塞环境 随着网络拥塞程度的上升,网络系统对用户服务请求的拒绝率对网络整体用户满意度的影响不断增加,本文对网络拥塞环境做单独讨论。图5和图6分别给出了网络拥塞环境下Q-learning算法和自适应MLB策略网络系统整体用户满意度和服务拒绝率。 图5 网络拥塞环境下不同服务分配策略整体用户满意度对比Fig.5 Comparison of overall user satisfaction with different service allocation strategies in the environment of network congestion 图6 网络拥塞环境中网络服务拒绝率对比Fig.6 Comparison of network service rejection rate in the environment of network congestion 从图5可以看出,在网络拥塞环境下,Q-learning算法相较于自适应MLB策略整体用户满意度上升大约5%。从图6可以看出,使用Q-learning算法,网络系统对用户服务拒绝率相较于使用自适应MLB策略下降超过40%。 考虑到实际操作中,不同服务对网络需求的迫切程度不一样,简单设置不同类别服务的拒绝惩罚参数,无法有效反映不同用户实际需求。比如车辆自动驾驶,即使在网络拥塞的环境下,也需要实时将车辆信息上传到数据中心处理,所以网络需要优先保障此类服务请求。随着车载网络用户量不断增加,网络拥塞将是一个难以避免的问题,对一些对网络服务需求迫切的信息优先保障其网络服务具有很强的现实意义。在本文实验环境中,假设存在网络任务对网络服务需求相较于其他类别任务更为迫切,因而网络拒绝这个服务对用户整体满意度的影响更大,拒绝服务惩罚参数应该设置更高。 图7给出了基于Q-learning算法不同拒绝服务惩罚参数设置(见表3)的网络服务拒绝率,图8给出了对应参数设置下,对网络需求迫切服务的拒绝率。可以看出,通过合理调整拒绝服务惩罚参数,可以在网络系统整体服务拒绝率基本不变的情况下,使网络需求迫切服务拒绝率有明显下降。 图7 不同服务惩罚参数网络服务请求的拒绝率Fig.7 Rejection rate of service requests by networks with different service penalty parameters 表3 拒绝服务惩罚参数βl 图8 不同服务惩罚参数设置下需求迫切网络服务请求的拒绝率Fig.8 Rejection rate of urgent service requests with different service penalty parameters 通过调整拒绝服务惩罚参数来降低网络对相应服务请求的拒绝率,既可以有目的性地降低对网络服务需求迫切用户服务请求的拒绝率,又可以充分利用网络资源,能够有效解决当前由于网络数据量激增而导致的网络拥塞问题。下一步,如何调整拒绝服务惩罚参数以实现网络对用户服务请求拒绝率的有效控制,以及如何设定可以充分满足用户需求的最优拒绝服务惩罚参数将会是研究的重点。 本文主要针对网络中用户整体满意度最大的网络任务分配策略进行研究。基于多种影响因素,构建了用户需求和满意度描述框架。基于用户需求和用户满意度,提出了基于SMDP的网络任务分配策略,通过仿真实验验证了所提策略的优势。但是,现实情况往往比想象中更为复杂,仍有一些问题有待进一步研究: (1) SAGVN的可拓展性。针对随机接入的无线通信节点和车载用户,需要构建更为高效的网络管理框架,更快将其纳入网络管理系统。 (2) SAGVN网络的能量消耗。能量消耗是制约SAGVN发展的重要问题,需要有效的能量管理策略。 (3) 网络分片。结合网络功能虚拟化技术对网络分片,为特定用户提供定制服务。2.2 效用函数
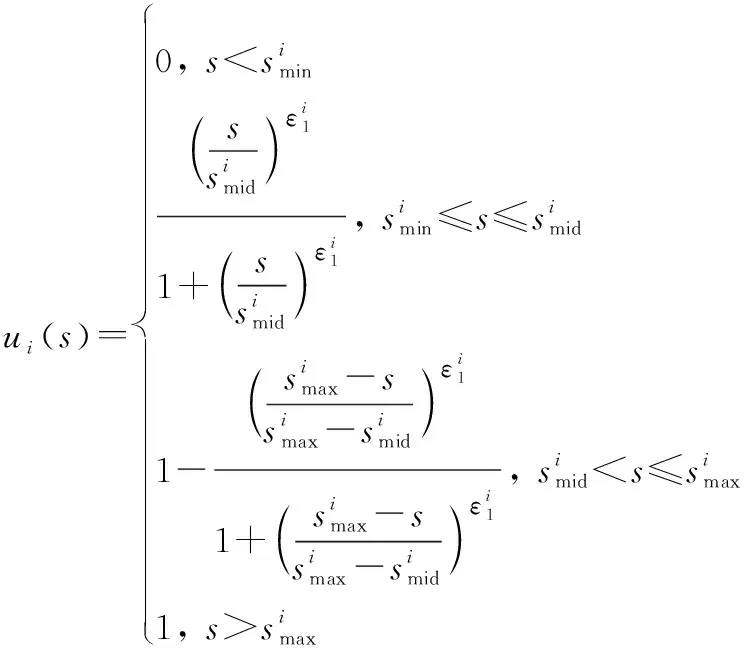
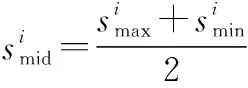
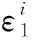
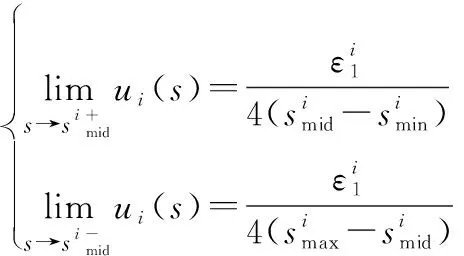
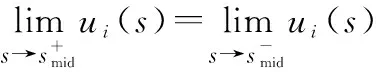
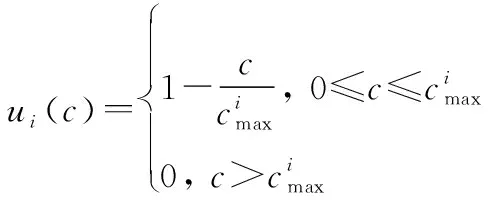
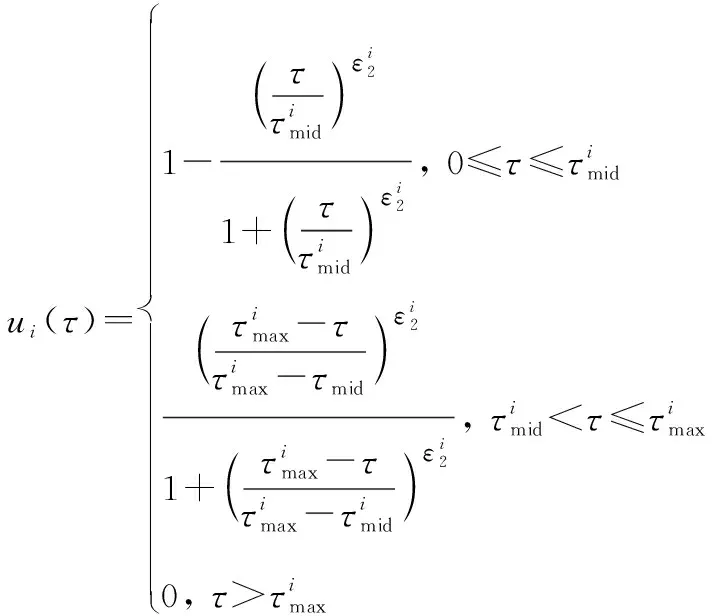
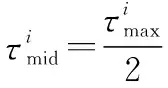




2.3 用户满意度
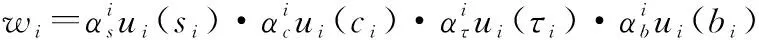

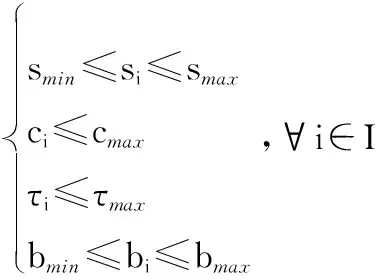
3 网络任务分配策略
3.1 问题描述
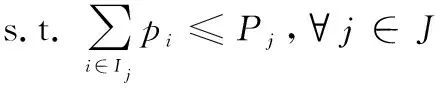

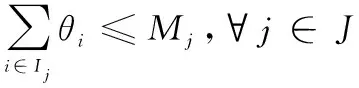

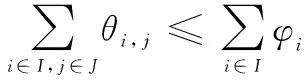
3.2 SMDP
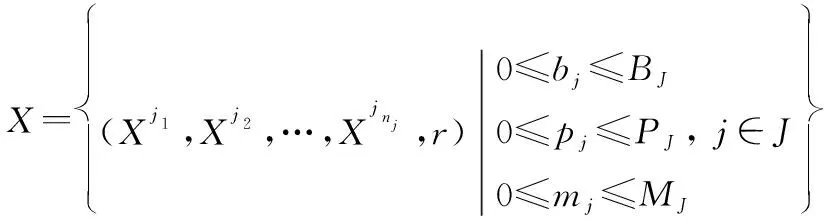
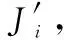
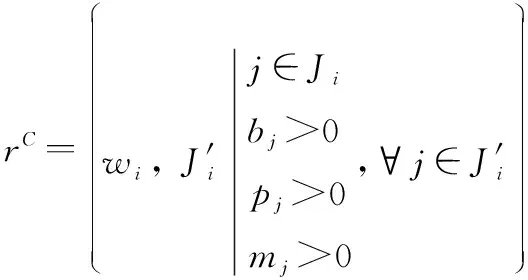
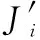
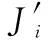
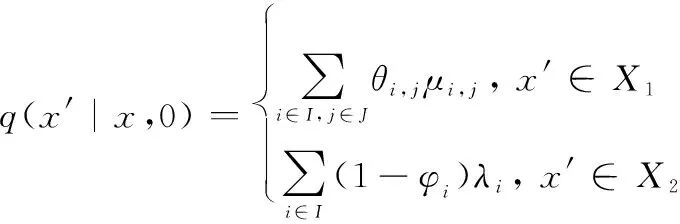
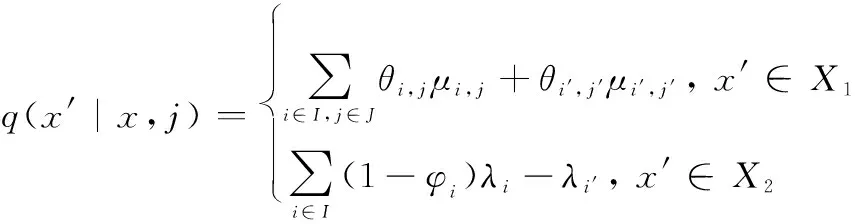
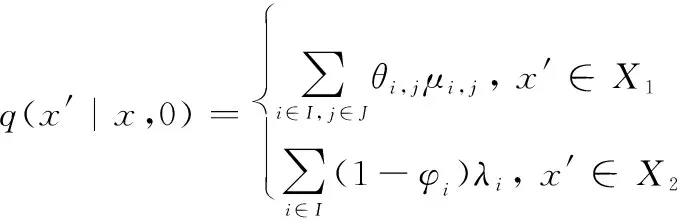
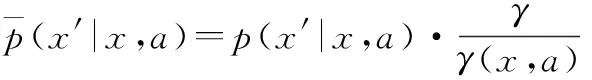



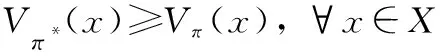

3.3 Q-learning算法
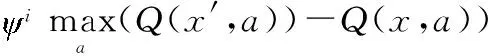
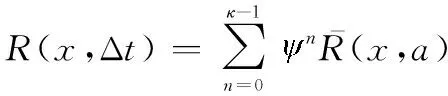
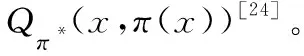
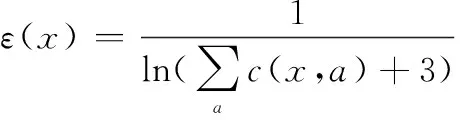
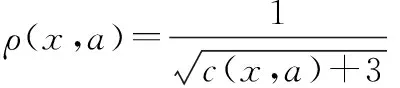

4 仿真实验
4.1 仿真环境


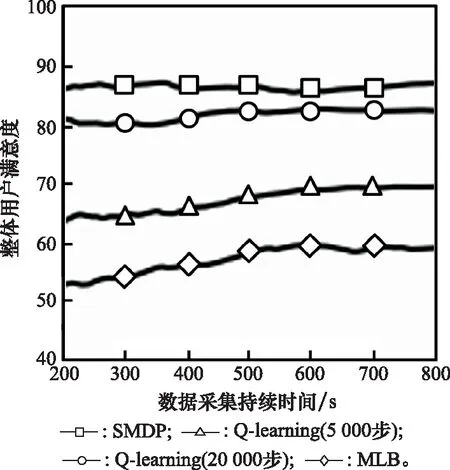
4.2 实验结果分析




5 结束语
