基于多源信息融合与HMM的剩余寿命预测
2022-05-07王康勃
黄 林, 龚 立, 姜 伟, 王康勃
(海军工程大学舰船综合试验训练基地, 湖北 武汉 430033)
0 引 言
在故障预测与健康监测(prognostics and health management,PHM)领域中,对设备性能退化的实时预测非常重要,是基于状态维修(condition-based maintenance,CBM)策略制定的重要依据。但是在大多数情况下,监控系统测量的数据无法跟踪系统每个组件的退化状态,因此CBM需要一个能够基于监测数据预测其系统性能退化状态的模型或者是一个可以量化的指标,例如系统健康指数(health index, HI)、剩余使用寿命(remaining useful life, RUL)等。
RUL是指设备失效前能够运行的次数或者时间。准确的RUL预测在实施CBM策略中起着关键作用,因为其可以为维修人员在系统故障之前提供足够的时间,使用者能够及时评估设备的健康状况,并针对设备状态规划和制定未来的维护保养计划。目前常采取的做法是,利用系统传感器采集大量的实时数据,将这些数据存储在历史数据集中,并通过建立基于数据驱动模型(data-driven model,DDM)来预测精确的组件衰减状态和RUL。
在关于PHM和CBM的文献中,基于物理模型、统计学理论和数据驱动等诸多方法被提出来解决RUL预测问题。近年来,由于机器学习方法能够在不了解设备退化机制的情况下,仅依靠历史数据对设备运行状态进行学习和预测,不需要过多的领域知识,因此受到了越来越多的关注,其中常用的方法包括支持向量机(support vector machine,SVM)、隐马尔可夫模型(hidden Markov model,HMM)、卡尔曼滤波、深度学习方法等。
HMM最早被应用于语音识别,是一个双重嵌入的随机过程,其一般随机过程是不可观测的(设备的状态是隐藏的),只能通过产生观测序列(即传感器信号)的另一组随机过程来观测,适用于动态过程时间序列信号分析和平稳随机信号的建模,在语音识别、手势识别、目标跟踪等许多应用领域都显示出其优越的性能。
HMM同样也被广泛应用于故障诊断和故障预测领域,故障预测是PHM核心课题之一,HMM可根据测量信号检测和识别系统健康状态,并对未来一段时间内的健康状态进行估计,从而实现系统RUL预测。Zhu等针对动态工业过程中的故障分类问题,提出了一种HMM驱动的鲁棒隐变量模型,将概率结构发展为一种分类器形式,以便在模型获取过程中融合各种类型的过程信息。Yiakopoulos等利用分段聚合近似和符号聚合近似时间序列数据挖掘表示方法,结合HMM应用于过程变量监控数据,并与过程缺陷相关联,从而捕捉隐藏在观测数据中的有意义的信息,识别特定异常情况。Galagedarage等采用HMM-贝叶斯网络混合系统,对田纳西-伊斯曼过程中的10个已识别故障进行预测和隔离,并成功地预测了所选的10个过程故障,并对其中的8个进行了准确隔离。Wang等提出了一种基于HMM的多模态过渡过程故障检测方法,以一种隐状态概率集成策略将局部监测结果以概率方式组合成两个全局指标,并采用贝叶斯信息准则进行模型评估,后采用负对数似然概率指标进行过渡过程故障检测。Du等以HMM建立润滑油降解的状态演化过程,利用最大化期望(expectation maximization,EM)算法估计HMM的未知参数,并以后验概率的形式通过条件可靠度函数和平均剩余寿命函数来进行预测。Soualhi等提出了两种基于HMM故障预测的概率方法,将故障预测不仅限于对RUL的估计,而且还扩展到对未来可能出现故障的风险的估计。Le等针对系统可能存在多个性能退化机制的情况,提出了一个多分支建模框架,通过CBM环境中的状态监测信息,证明了多分支HMM在RUL估计方面的性能。
上述文献证明了HMM在RUL预测应用中的有效性,并且与许多其他RUL预测方法相比,HMM的一个显著优点是具有比较强的可解释性。但是,标准HMM的最基础的假设是马尔可夫链,即系统下一时刻的状态仅由当前状态决定,不依赖于以往的任何状态,并以此计算所有变量的联合概率分布。这样将导致在利用建立好的HMM进行预测时,因为没有考虑预测对象的全寿命过程退化轨迹,HMM将产生较大的偏差,从而导致预测结果不够理想。
针对上述问题,提出了一种基于多源信息融合的HMM建模方法,首先定义经验信噪比(empirical signal to noise ratio, eSNR)选取主要信号,随后基于主成分分析(principal component analysis, PCA)方法将多维发动机监控数据进行信息融合,将监控数据从多维降至一维,通过对降维后的数据进行分析和比较,得到每台发动机的HI,再将测试数据集中的发动机性能HI与训练数据集遍历比较,通过相似性分析得到若干个与之最为接近的训练发动机HI,再将相应的发动机数据进行HMM建模,针对测试数据集中的每个发动机分别建立一个与之相对应的高斯混合隐马尔可夫模型(Gaussian mixture HMM, GM-HMM),再对其进行隐状态分析,通过EM算法,得到后验概率最大的模型后,采用维特比算法估计当前发动机的退化状态,再利用蒙特卡罗模拟,通过生成从当前健康状态到故障状态的路径,估计发动机的RUL。相比于直接利用所有的数据训练一个HMM,该方法在分析发动机退化轨迹的基础上,针对每一个测试发动机分别得到一个HMM,充分考虑了发动机的历史退化轨迹的影响,提高了模型的准确度。同时,为了避免可能出现的过拟合风险,相比于直接挑选一个最相似的退化轨迹,利用相似度原理分析选出了若干个最相似轨迹,再对其进行HMM建模。最后通过对NASA公开的航空发动机的案例进行研究,证明了所提预测方法的有效性。
1 基于eSNR和PCA的传感器信号融合方法
1.1 基于eSNR的传感器特征提取
特征提取是模式识别和机器学习的重要课题,数据中如果包含大量冗余变量或噪声信号,会对模型性能产生非常大的影响,导致模型过拟合或精度差等问题。在RUL预测的应用中,特征提取等价于选择合适的传感器信号,其目的是降低数据之间的冗余并尽量提高其相关性。常用的传感器选择方法包括观察传感器数据变化趋势、基于信息熵理论的传感器选择,上述方法简单直观,操作性强,但缺乏理论基础,基于主观判断的信号特征使预测结果不稳定。
为提取有用的传感器信号,并同时达到降噪的目的,本文提出了一种基于信噪比分析的传感器特征提取方法。首先对信号进行归一化处理,在此基础上分析各传感器数据的信噪比,再采用sigmoid函数将信噪比转化至0~1区间后,将归一化的传感器信号乘以对应的信噪比函数,对信号进行加权后,同时考虑传感器信号的变化趋势和不同信号之间的相关性,采用核PCA方法对数据进行降维,根据主成分方差占比提取信号作为最终的预测信号。
令{}为1维时间序列的原始传感器信号,{_}为经过PCA降维和数据平滑后的时间序列,定义eSNR为
eSNR ()=var{—})var{}
(1)
传感器信号的权重将根据其对应的eSNR而定,具体为

(2)

1.2 基于PCA数据降维与信息融合
PCA是一种数据压缩和特征提取的多变量统计分析技术,能够有效去除数据间的相关性,目的就是在保证数据损失尽可能小的前提下,经过线性变换舍弃小部分信息,以少数新的综合变量取代原始变量,因此要求主成分能够充分反映原始变量的信息,同时又互不相关,从而进行样本评价。
在许多情况下可以通过PCA来降低特征向量的维数,将系统众多的传感器信号转换为较少数量的主成分,同时PCA可以消除变量间的线性相关性,并通过融合多个变量来抑制噪声。传感器信号之间可能存在关联,且其相关性可能会破坏RUL预测模型,使预测结果产生偏差。PCA是一种将潜在相关变量转换为少量不相关变量的常用技术。
数据集=(,,…,,…,)包含个样本,每个样本为维变量,则的经验均值为
=(,,…,)
(3)
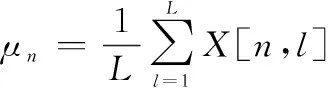
(4)
样本的协方差矩阵为

(5)
式中:为全为1的维向量。
对协方差矩阵进行特征向量分解,并选取前个特征向量,特征向量数的选择取决于希望保留的数据方差,例如80%,即有:

(6)
因此,可以对数据集进行降维处理,并保留系统80%方差:
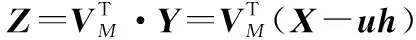
(7)
式中:=(,,…,)为由个特征向量组成的×矩阵,为×矩阵且每列为中对应列向量的一个主分量向量。
1.3 HI构建
本文对比了目前使用较为广泛的用于数据平滑从而构建系统HI的两种算法,分别是核岭回归(kernel ridge regression,KRR)和支持向量回归(support vector regre-ssion,SVR)模型。算法对经过eSNR特征选择和PCA降维后的多维系统监测数据进行拟合平滑处理,提取系统性能退化特征曲线,从而构建系统HI。
1.3.1 KRR
KRR是岭回归(ridge regression,RR)的扩展,而RR的本质是在线性回归的基础上增加L2正则化,RR的最小化代价函数为
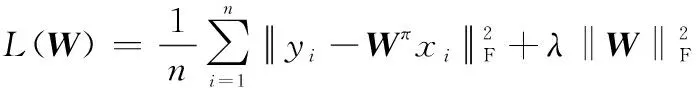
(8)
式中:为正则化参数;‖·‖表示F范数;∈×是变化矩阵;为第个样本;为第个样本的真实值。
即求解
arg min()=(+λ)
(9)
式中:∈×,∈×为训练数据特征向量矩阵和因变量矩阵;∈×为恒等矩阵。
通过核变换可以将此方法进行扩展,将数据映射到某一个核空间,使得数据在该核空间线性可分,从而能够处理非线性数据,则回归函数结果可表示为
()=(+λ)()
(10)
式中:为Gram矩阵,=(,) (=1,2,…,),为训练样本的数量。
本文使用高斯核函数:
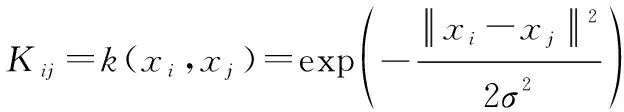
(11)
式中:为核函数宽度,通常采用交叉验证的方式选取合适的宽度参数。
132 SVR
SVR是SVM在分类应用方面的推广,SVR假设模型输出()与真实值之间最多有的误差,即仅当与之间的误差绝对值小于就算预测正确。于是,SVR问题写成:
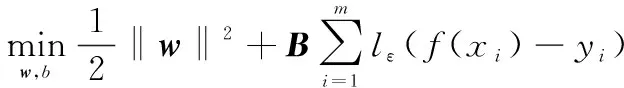
(12)
式中:为样本空间中超平面的法向量;为正则化常数;为的不敏感损失函数:

(13)
更多关于SVM的原理建议参看文献[21]。
1.3.3 对比分析
图1为两种方法对论文拟采用的数据集中某一训练样本进行拟合的情况,直接采用经过PCA降维后的散点作为系统HI不能很好地反应系统性能随使用时间增加而导致的性能退化情况,因此需要进行曲线拟合,提取系统退化特征,作为系统HI。图1分别为KRR和SVR对数据的平滑效果以及相应的误差变化趋势。可以看出,采用KRR提取的性能退化轨迹更加平滑,更能反应系统性能退化的真实状态,SVR曲线起伏波动较大,与实际情况有所差别,因此采用本文所提的KRR进行系统性能退化轨迹提取。
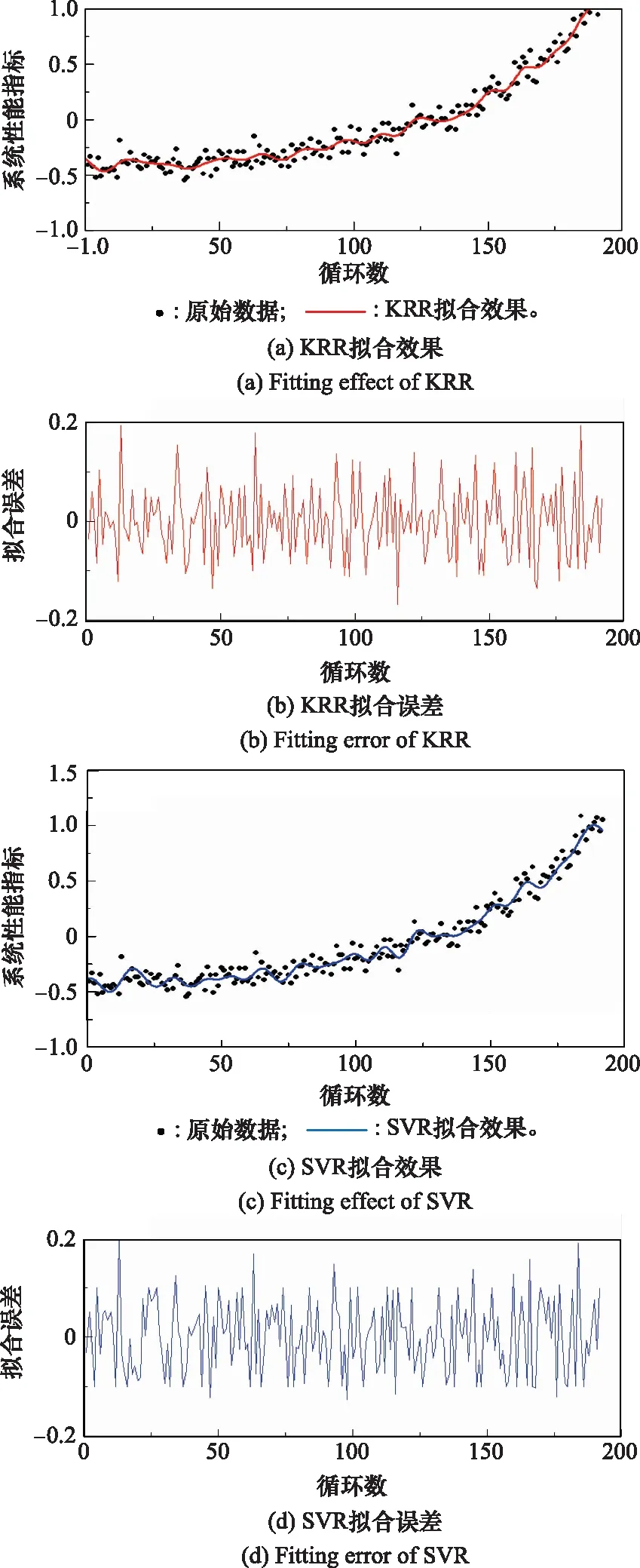
图1 KRR与SVR拟合效果对比Fig.1 Comparison of fitting effect between KRR and SVR
2 基于GM-HMM的RUL预测
2.1 GM-HMM基本原理
HMM是一种基于动态贝叶斯网(dynamic Bayesian network,DBN)的统计概率模型。HMM假定系统状态不可观测,并由有限个隐状态和一组观测变量构成,每个隐状态对应两种概率:状态转移概率和输出观测概率,且在任一时刻,观测变量的取值仅依赖于隐状态。在本文所关心的状态监测和故障诊断等领域的应用中,系统的健康状态(故障参数、RUL、HI等)即为HMM模型假定的隐状态。
HMM变量分两组:① 隐状态{,,…,},为模型在时刻的隐状态,假定马尔可夫隐状态空间={,,…,},其中为马尔可夫链隐状态数目,则显然有∈; ② 观测变量{,,…,},为时刻的观测值。若观测变量为离散值,并假定取值空间为={,,…,},则有∈。若HMM应用于RUL预测中,观测变量通常为系统一组可量化的监测变量,通常为连续型,因此取值空间可为无限维。一个标准的HMM可由以下3组参数确定。
(1) 模型在各状态之间的转移概率=[]×,其中
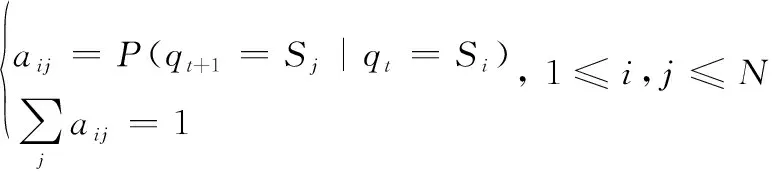
(14)
(2) 初始状态概率=[,,…,],其中
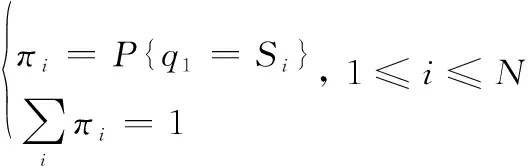
(15)
(3) 输出观测概率=[]×,其中
=(=|=), 1≤≤; 1≤≤
(16)
通过指定状态空间、观测空间和上述3组参数即可确定一个HMM,并可简化表示为
=(,,)
在RUL预测中,系统性能逐渐退化直至失效(RUL为0)的过程通常是不可逆的,因此左右连续型HMM(left-right continuous HMM)是描述退化过程的合适选择,其失效概率将随着时间推移而增加,状态转移概率矩阵形式如下:

(17)
另外,在实际应用中,由于观测变量往往是连续变化的,因此采用混合高斯函数拟合各个隐状态的对应输出分布,则式(16)可改写为
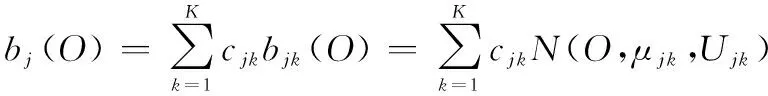
(18)
式中:为观测序列;为高斯元数目;为状态对应的权重;为第个高斯元函数。因此,GM-HMM可表示为
′=(,,,,)
(19)
并且有:
≥0, 1≤≤; 1≤≤
(20)
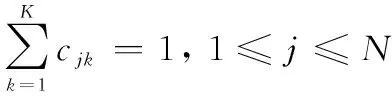
(21)
2.2 系统状态识别
HMM主要用于解决3个基本问题,分别是: ① 评估模型与观测序列之间的匹配程度; ② 根据观测序列推断出隐藏的模型状态; ③ 训练模型使其能更好地描述观测数据。本文主要利用GM-HMM解决后面两个问题。针对本文的实际需求,首先采用Baum-Welch算法,基于充足的训练样本数据,对GM-HMM模型参数进行训练,通过极大似然估计可得到观测序列下概率最大的模型,以该模型作为最终的模型,即上文中提到的问题③。得到HMM模型后,运用维特比算法,对测试数据进行分析处理,从而推断系统当前的健康状态,即HMM模型的隐状态,从而实现对设备当前健康状态的有效识别,对应上文提到的问题②,具体流程如图2所示。

图2 HMM健康状态预测流程Fig.2 Health status prediction based on HMM
2.3 基于蒙特卡罗模拟的RUL预测
通过训练数据对GM-HMM模型进行训练后,即可得到系统的转移矩阵,转移矩阵以概率的形式,描述了系统健康状态在每一个循环过程的演变信息,从而可以有效地对系统当前的健康状态进行预测,系统RUL预测流程如图3所示。

图3 RUL预测流程Fig.3 RUL prediction process
本文采用蒙特卡罗模拟,基于GM-HMM转移矩阵计算系统RUL,具体过程为: ① 基于训练后的GM-HMM模型,对当前测试样本进行次模拟,在这次模拟中,设备将逐步从健康状态演变至失效状态。根据GM-HMM转移概率生成0~1之间的均匀分布随机数,从而估计下一时刻系统健康状态; ② 将计算出的下一个状态视为当前状态,重复此过程直到达到系统失效状态; ③ 系统从健康状态运行至失效前的运行次数可作为RUL预测值,通过次模拟,可以得到个RUL预测值,直至完成所有样本模拟。根据蒙特卡罗模拟方法的思想,系统到达失效状态的平均步数可作为RUL预测值:
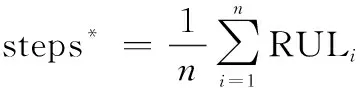
(22)
3 实验研究
为验证本文方法的有效性,采用美国国家航空航天局(National Aeronautics and Space Administration, NASA)公布的基于C-MAPSS的航空发动机性能退化仿真数据集,对基于GM-HMM和蒙特卡罗方法的RUL预测算法进行验证。
3.1 实验数据分析
图4为基于C-MAPSS构造的航空发动机结构简图,包含风扇、燃烧室、高低压压气机、透平、喷嘴等部件。
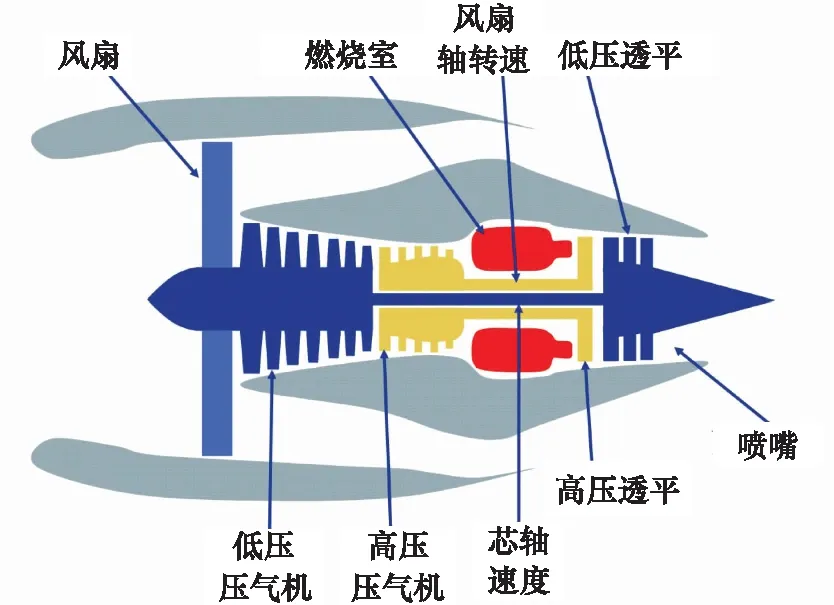
图4 C-MAPSS航空发动机简图Fig.4 C-MAPSS aeroengine diagram
NASA公布了5组数据集,每组数据集包含了上百台发动机单元,每台发动机初始为健康运行状态。在发动机运行过程中,随机注入不同的故障来模拟系统性能退化过程,每个发动机状态记录总共有24个变量,其中3个是操作设置,21个为监测值,包括工作循环数、工作环境参数、每个工作循环的监控数据等,如表1所示,监测数据加入了高斯白噪声干扰模拟实际传感器噪声影响,数据能够逼真地模拟真实系统,具有非常高的可信度。
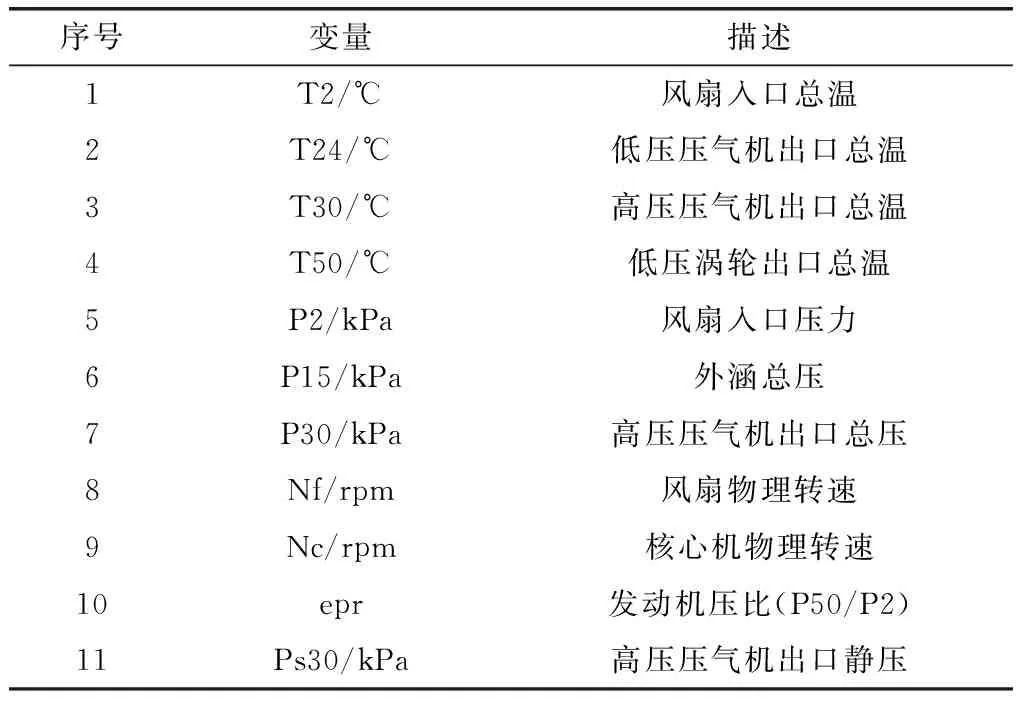
表1 发动机传感器数据描述
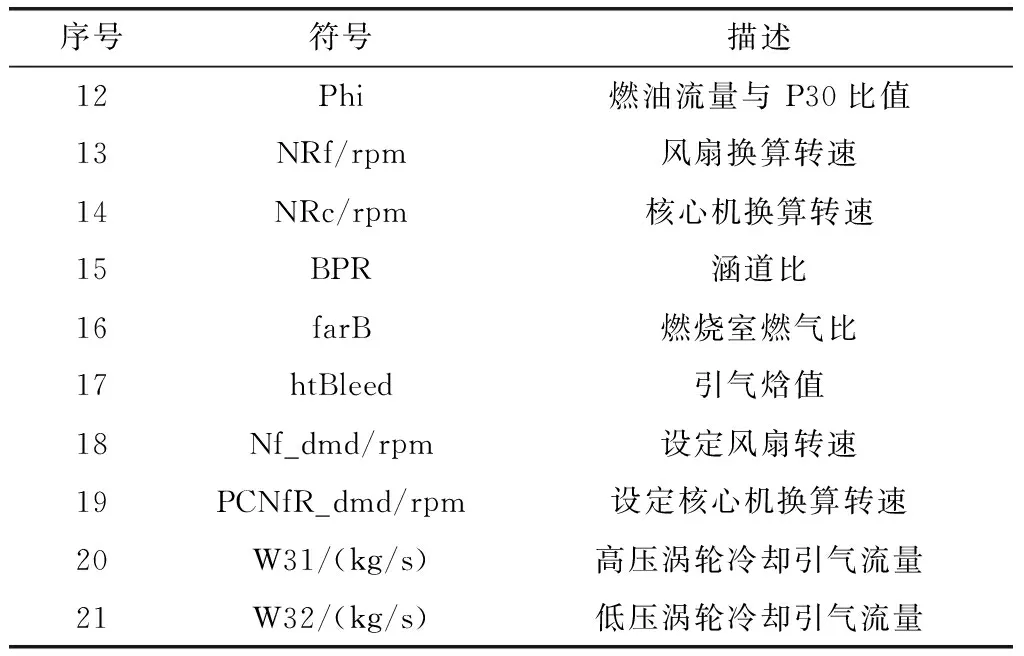
续表1
以NASA公布的5组数据集中的第一组为例进行方法验证。数据集FD001分为训练集和测试集,训练集即历史数据库样本,包含100组从正常运行状态至系统失效的全寿命数据,测试集即测试样本,包含样本发动机从完好状态运行至失效前一段时间的数据。
3.2 预测结果评价指标
常用的RUL预测结果评价指标有平均绝对误差、均方根误差、百分比误差、平均绝对百分比误差(mean absolute percentage error,MAPE)等,为方便比较和分析,本文采用MAPE作为评价指标之一,其计算式为
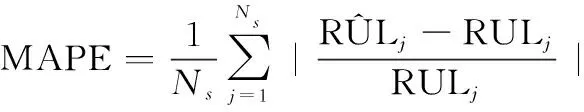
(23)
另一方面,在实际应用中,RUL预测值偏大比RUL预测值偏小造成的损害大,因此除了MAPE之外,还采用文献[25]提出的分段惩罚系数的方法,其表达式如下:
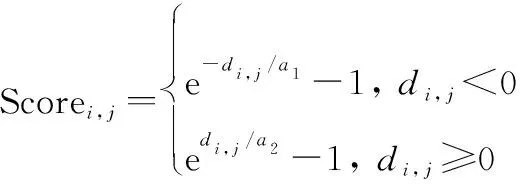
(24)
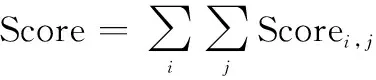
(25)

除此之外,还采用假阳性率(false positive rate, FPR)、假阴性率(false negative rate, FNR)和准确度来进行评价,其中
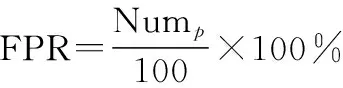
(26)
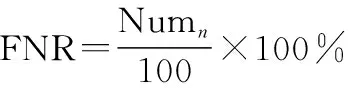
(27)
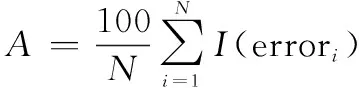
(28)
式中:Num为error<-10的个数;Num为error>13的个数。

3.3 发动机HI特征提取
首先对训练集中的发动机历史数据进行分析,通过观察数据分布可以看出,部分传感器信号为常值,不随发动机运行发生变化,例如、、、、、、,去除这些数据后,为降低数据之间的线性相关性,同时为达到降噪的目的,首先对传感器信号的趋势进行观察和分析,再基于eSNR和PCA进行降维处理,作为后续系统HI提取的数据来源。
图5为id为1的发动机的14个传感器信号在生命周期的变化趋势,需要注意的是,所有数据在分析之前已经进行了归一化处理,因此变化范围都在0~1之间。从图5中可以看出,航空发动机的14个传感器信号在生命周期内都具有单调性,可以被用来提取系统性能退化轨迹。
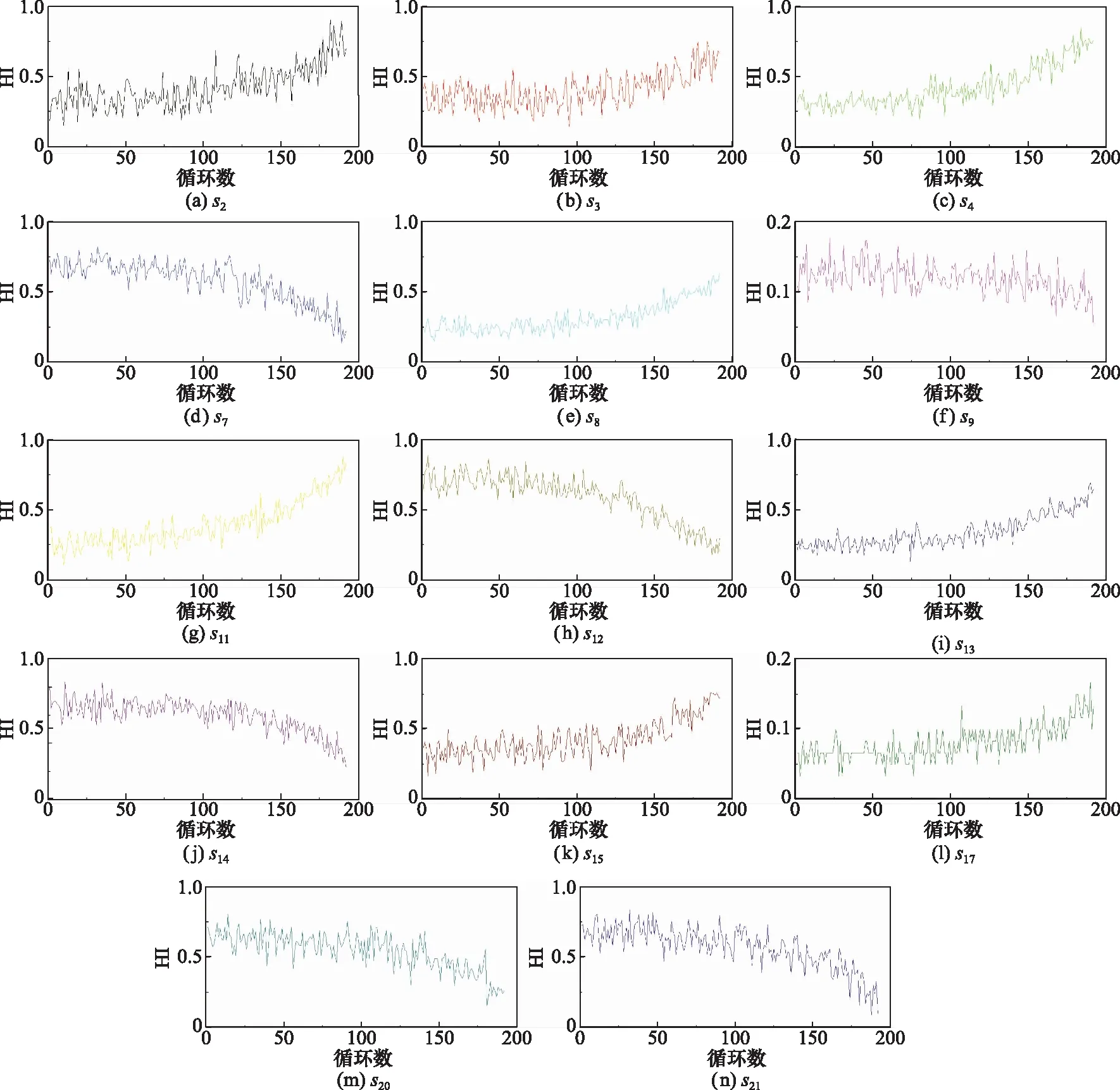
图5 样本发动机监控数据变化趋势Fig.5 Trend of sample engine monitoring data
为了降低数据维度以及数据之间的相关性,同时为了起到一定的数据降噪作用,对14维监控数据进行PCA降维处理。基于同样的训练参数,对测试集中的所有发动机监控数据做同样的处理,可以得到测试样本从正常运行状态到当前状态的性能退化曲线。图6(a)和图6(b)分别为样本库中100台发动机经过PCA降维和KRR处理后,基于eSNR进行特征提取得到的训练样本HI和经过降维和平滑处理后的状态。
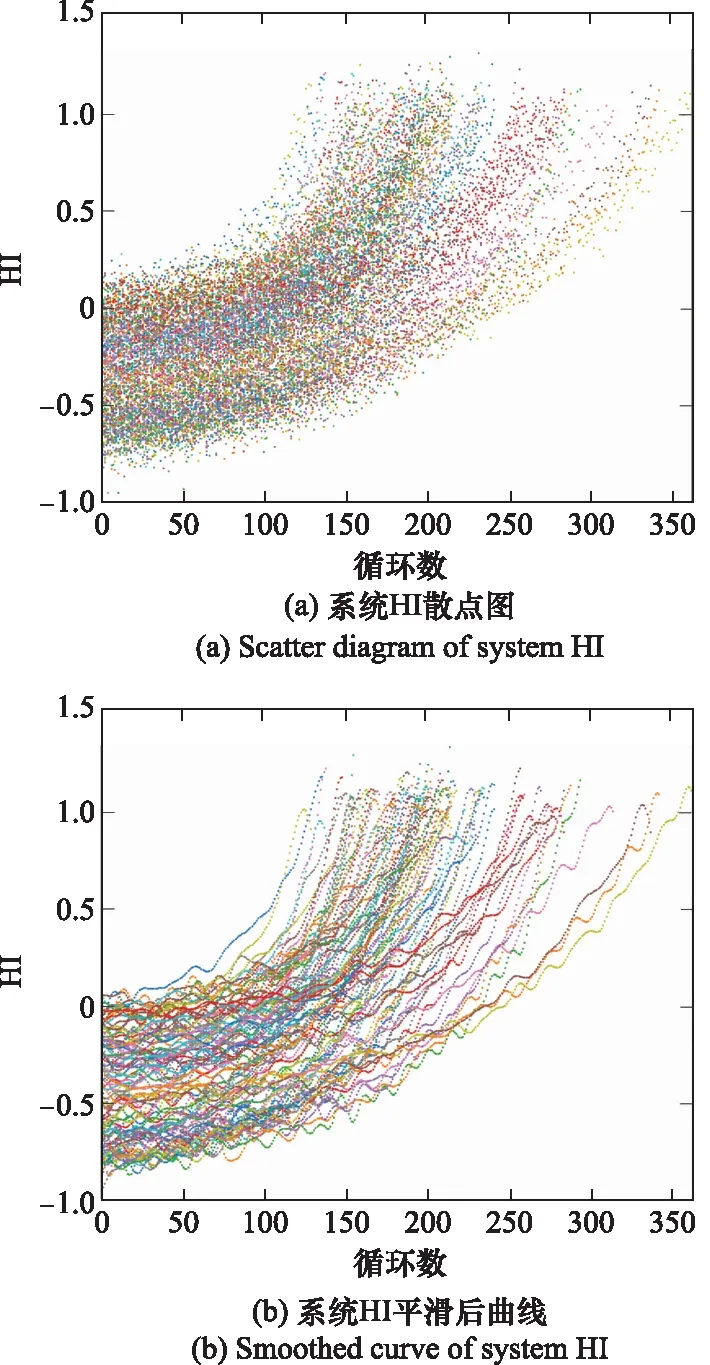
图6 系统HIFig.6 System HI
3.4 RUL预测结果分析
构建系统HI后,需要确定系统性能退化隐状态数目。部分文献直接通过经验确定隐状态数目,例如假设系统退化经历4个状态:正常状态、初步退化状态、严重退化状态和实效状态。直接通过经验确定HMM隐状态数目的方式包含部分不确定性,本文采用基于贝叶斯信息标准(Bayesian information criterion,BIC)的方法确定隐状态数目,并有:
BIC=·ln-2ln(|)
(29)
式中:为隐状态数目;为样本时间步长;(|)为观测概率。使得BIC最小的值为最佳隐状态数目。
图7为基于训练样本数据进行BIC分析的结果。显然,假设系统经历4个退化状态取得的效果最好。
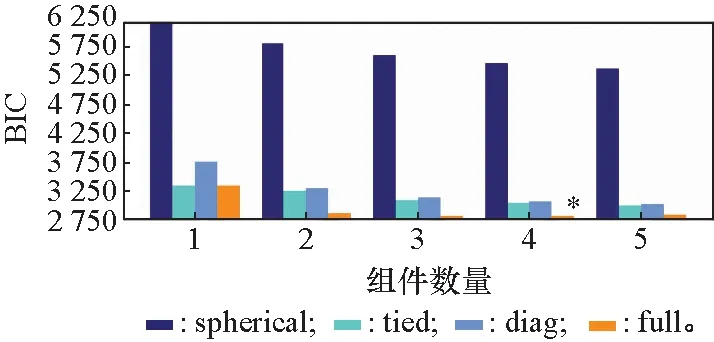
图7 BIC分析结果Fig.7 BIC analysis results
图8为基于4个退化状态建立的高斯混合模型,4个高斯混合模型(Gaussian mixture model, GMM)分别对应系统4个退化状态,从图8中可以看出GM-HMM可以较好地对系统退化状态进行模拟。
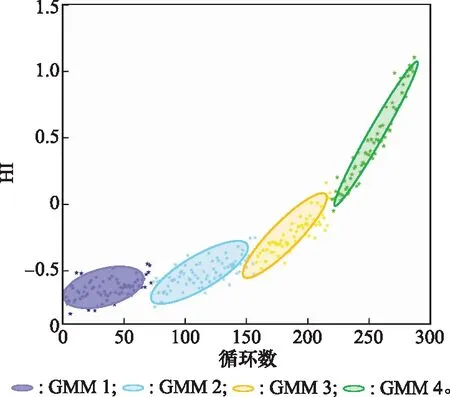
图8 4个组件对应的GMM模型Fig.8 GMM model of four components
基于提取的系统性能指数和GM-HMM模型,将训练样本数据输入模型中进行训练,并假定系统初始状态转移概率为

(30)
需要注意的一点是,将所有训练数据全部用于训练一个HMM并将该HMM模型应用于所有测试样本进行RUL预测,这种方式将会产生非常大的偏差。为了避免这种偏差,同时又尽可能地降低过拟合风险,本文提出并采用了一种“定制”策略,具体为:针对每一组测试数据,根据HI退化情况,基于最小欧式距离,从所有训练样本中选取5个性能最相近的发动机样本,以这些样本数据为每一组测试发动机训练一个HMM模型,即总共训练得到100个HMM。
以样本库中1号发动机HMM模型训练为例,经过训练后的状态转移概率为

(31)
图9为训练样本健康状态,即模型隐状态变化趋势。
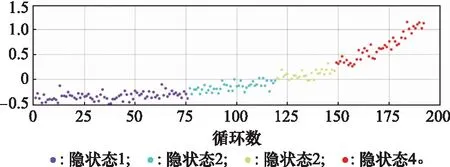
图9 系统隐状态变化趋势Fig.9 Change trend of system hidden state
将训练好的HMM模型对所有测试发动机数据进行RUL预测,计算相应评价指标,并将结果与多源信息融合、多层感知机、深度卷积网络、长短时记忆网络、DBN-HMM等文献方法的结果进行对比分析。表2为对比情况,从表2可以看出,本文所提方法在均方根误差(root mean square error, RMSE)、平均绝对误差(mean absolute error, MAE)等指标上比现有算法都有较大提高,并且相比于以上方法,在预测RUL的基础上能够更全面地监测系统退化过程,便于给出系统健康状态评估结果。

表2 试验结果对比分析
4 结 论
针对系统RUL估计的问题,提出多源信息融合与HMM的方法,采用PCA进行降维和降噪处理,并采用KRR对退化轨迹进行平滑处理并进一步降噪,在此基础上基于传感器信噪比构建系统HI,通过样本数据训练得到GM-HMM模型,推导系统性能退化状态,并进行RUL预测。最后,应用NASA公开的航空发动机数据对预测方法进行了验证,并与最新文献的结果进行了对比分析,验证了方法的可行性,预测结果较最新文献有了较大的提高,方法具有较高的实用性。
