基于正则化元学习的小样本图像分类算法
2022-05-06甘宏
甘 宏
(广州南方学院,510970,广州)
0 引言
近年来,将深度学习技术用于视觉识别任务取得了相当大的进展[1-5]。然而,有监督的深度学习模型需要大量的标记样本和迭代步骤来训练模型的参数,这严重限制了深度学习技术对新出现或罕见类别的适用性,同时收集并标记大量的样本需要耗费大量的人力物力。相比之下,人类却擅长通过少量甚至几个样本来识别物体,而深度学习技术难以用于每类仅有一个或几个样本的学习。受人类具备小样本学习能力的启发,使得小样本学习问题引起了广泛的关注。
现有的小样本学习方法大致可以分成3类:度量学习、元学习以及基于数据增强方法。度量学习方法利用辅助数据集学习得到一个度量空间,使得在该度量空间中同一类样本的特征向量彼此间的距离较近,而不同类样本的特征向量距离则较远,从而实现小样本学习。文献[6]将卷积孪生网络用于单样本图像识别,通过有监督的方式训练孪生网络,然后重用网络所提取的特征向量进行单样本学习。文献[7]提出了匹配网络,该算法的核心是episode-based的训练策略,其基本思想是训练和测试是要在同样条件下进行,即在训练的时候让网络模型只看每一类的少量样本,使得训练和测试的过程保持一致。原型网络的基本思想是每个类都存在一个原型表达,该类的原型是支撑集在利用度量空间中特征向量的均值作为类表示[8]。F Sung等[9]提出了关系网络求解小样本学习问题,该模型2个模块:嵌入模块和关系模块。嵌入式模块用于提取数据样本的特征表示,而关系模块用于估计2个特征表示之间的距离。D DAS等[10]添加了一个预训练阶段,利用所有基类的分类任务预训练模型获得参数的初始化。Li等[11]在分类损失函数中添加一个与任务相关的附加边际损失,以更好地区分不同类别的样本,从而提高分类性能。Zhou等[12]利用贪婪算法选择与支持集样本的相似基类,使得度量模型能对新的小样本任务有较强的适应性。元学习方法通过对多个任务的学习,以使元模型(meta-learner)能够对新的任务做出快速而准确的学习,该方法包含了2个关键问题:训练得到最优初始化参数和学习有效的参数更新规则。FINN等[13]提出了MAML(Model-Agnostic Meta-Learning)的元学习方法,基本思想是训练一组初始化参数,通过在初始参数的基础上进行一或多步的梯度调整,来达到仅用少量数据就能快速适应新任务的目的。K Wang等[14]给出了结合概率推理和元学习的识别模型,以阻止元模型训练过程中偏向某些具体任务,从而提高元模型对新任务的泛化能力。Meta-SGD算法[15]对MAML算法进一步优化,不仅对初始参数进行了学习,而且对元模型的更新方向和学习速率进行学习。文献[16]提出了一阶元学习算法,该算法采用一阶导数近似表示二阶导数,使得元参数更新过程中不需要像MAML算法一样计算二阶导数,从而提高元模型的训练效率。数据增强方法通过扩充样本来提高小样本学习的性能。然而,数据生成模型在仅有少数几个训练数据时,往往表现不佳。
本文提出算法属于元学习方法的范畴。针对现有元学习方法对部分训练任务存在有偏的不足,本文提出基于正则化元学习算法。通过在元学习的目标函数中添加正则化项,阻止元学习的初始模型偏向现有某些训练任务,提高元模型对新任务的泛化能力,从而提高小样本图像分类的性能。
1 小样本图像分类问题
小样本分类的目标是找到参数θ,小样本分类目标是学习得到参数θ使得分类器fθ在询问集中的期望值最大
(1)

2 正则化元学习算法
为了减小元训练过程中产生有偏,提高元学习模型的泛化能力。本节提出了正则化元学习算法(Regularized Meta Learning,REML)。通过在元目标函数添加正则化约束项,使得模型对训练任务无偏。针对小样本图像分类问题,MAML算法的元目标函数为:
(2)

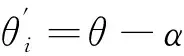
(3)
其中LTi(fθ)采用交叉熵损失函数,表示为:

(4)
因此,MAML算法的元目标函数可以表示为:
(5)
为尽量减小参数θ对训练任务有偏,提高元模型的泛化能力。本文引入交叉熵的约束条件,作为原目标函数的正则化项,使得参数θ对训练任务是无偏的。交叉熵表示为:

(6)
以交叉熵作为正则化项,则元目标函数表示为

(7)
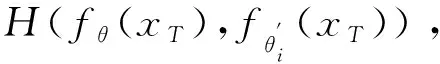
(8)
元目标函数梯度更新表示为

(9)
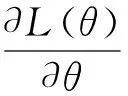
(10)
求导涉及到二维求导问题,大大增加了算法的计算量。针对以上不足,利用一阶导数近似二阶导数得到
(11)
则元参数更新模型(9)可以简化为
(12)
3 算法步骤
本节将给出算法的详细步骤,详见算法1。
算法1:正则化元学习算法。
1)While not done do;
2)抽取几个任务Ti构成任务块Tbat;
3)for allTiinTbatdo;
4)从Ti中每类选取K个样本记做D;
5)利用LTi(fθ)和D计算∇θL(fθ);
7)从Ti抽取Dval用于元参数学习;
8)End for;
9)利用Dval和元学习目标函数L(θ)学习元模型参数θ,
10)End while。
输出:元模型参数θ。
4 实验结果与分析
本节通过在miniImageNet、CUB-200和CIFAR-100这3个典型数据集上进行的小样本分类实验,来充分验证本文算法性能,并与MAML、Reptile、Relation Networks和Prototypical Networks等先进算法比较。实验1比较了不同算法在MiniImageNet数据集中的性能,并给出了参数λ对本文算法的影响;实验2比较了不同算法在数据集CUB-200上的算法性能;实验3给出了在数据集CIFAR-100上不同算法的性能比较。
为方便与其他算法进行比较,在后续的实验中本文算法采用了与文献[8-9,13,16]相同的网络结构。网络结构由4个模块组成,每个模块包含1个3×3×64的卷积层和1个2×2的池化层,每个卷积层均采用归一化处理。
4.1 MiniImageNet数据集
MiniImageNet数据集包含100个类,其中每个类包含600个样本。采用与其他算法相同的拆分,其中64个类用于训练,16个类进行验证,20个类用于测试。分别进行了5-way 1-shot和5-way 5-shot小样本图像分类实验,表1给出不同算法的分类精度比较。
由表1可以看出,本文算法由于提高了模型对新任务的泛化能力,从而使分类精度得到了一定的提升。
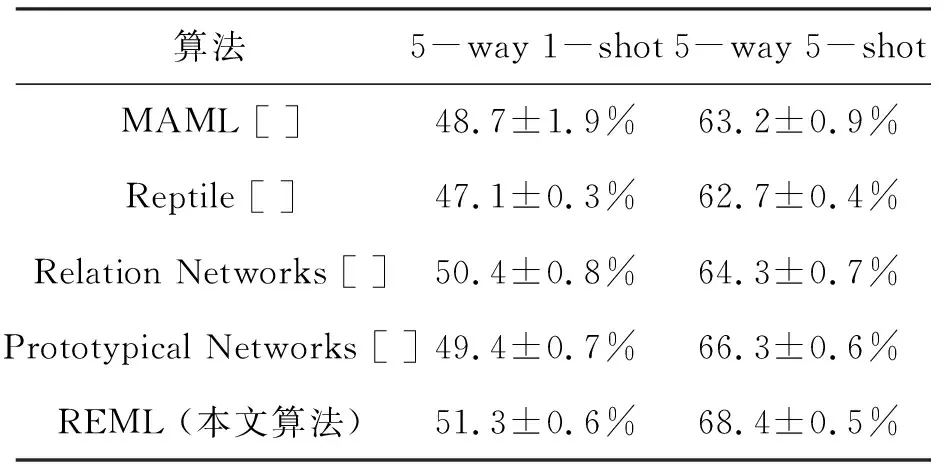
表1 不同算法在数据集miniImagenet中分类精度的比较
4.2 CUB-200数据集
CUB-200数据集[14]包括了200种细分的类。参照文献[15]中的划分,随机选取100个类用于元训练,50个类用于验证,50个类进行测试,并将每幅图像的尺寸大小调整为84×84。分别进行了5-way 1-shot和5-way 5-shot小样本图像分类实验,表2比较了4种算法的分类精度。
由表2可以看出,本文算法相对于MAML算法的分类精度能有将近4%的提升。
4.3 CIFAR-100数据集
CIFAR-100数据集包括了100个类,每个类包含600张尺寸为32×32的图形。随机选取64个类进行元训练,16个类用于验证,20个类用于小样本分类性能测试。与其他实验类似,分别进行了5-way 1-shot和5-way 5-shot小样本图像分类实验,表3比较了不同算法的分类精度。由表3可以看出,本文算法相对于MAML算法精度有3%左右的精度提高。

表2 不同算法在数据集CUB-200中分类精度的比较
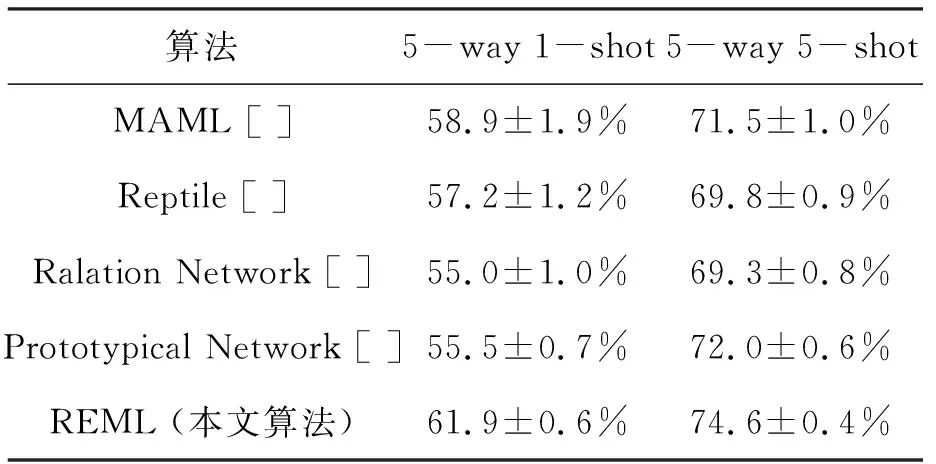
表3 不同算法在数据集CIFAR-100中的分类精度比较
4.4 平衡参数λ对算法性能的影响
本小节通过对以上3个数据库的5-way 5-shot小样本图像分类实验,分析平衡参数λ对算法性能的影响。图1给出了本文算法(REML)在不同参数值时的分类精度。由图1可以看出,当参数λ取值接近0时,算法识别精度与MAML算法接近;当参数λ取0.2~0.3之间时能获得较高的识别精度;当参数λ大于0.3之后,随着参数的增加算法性能逐步下降。

图1 平衡参数λ不同时的算法分类精度
5 结论
针对小样本学习问题,本文提出了正则化元学习算法(REML)用于求解小样本图像分类问题。该算法以交叉熵作为正则化项,以阻止元模型参数偏向某些具体任务,从而提高元模型的泛化能力,即提高元模型对新任务的适应能力。此外,采用一阶导数近似二阶导数减小元学习模型训练所需计算量。在miniImageNet、CUB-200和CIFAR-100这3个数据集上进行的实验表明,本文算法的分类性能优于现有的同类算法,并表明平衡参数选择在0.2~0.3之间时能获得较高的识别精度。
