LIF技术与ELM算法的电力变压器故障诊断研究
2022-05-05闫鹏程张超银孙全胜尚松行尹妮妮张孝飞
闫鹏程, 张超银, 孙全胜, 尚松行, 尹妮妮, 张孝飞
1. 安徽理工大学, 深部煤矿采动响应与灾害防控国家重点实验室, 安徽 淮南 232001
2. 安徽理工大学电气与信息工程学院, 安徽 淮南 232001
引 言
自20世纪70年代以来, 我国的经济迅速地发展, 电力工业也相应地大规模壮大, 导致电力变压器的使用日益增多[1-2]。 根据国家电力联合会的相关统计, 2021年1月—2月份, 全社会用电量为12 588亿kW时, 同比增长22.2%, 全国工业用电量比制造业用电量增加1 846亿kW时。 发电机组保持绿色发展, 核能、 风能、 水能等能源的发电量均有提升, 其中燃气发电机组容量超过一亿千瓦, 装机容量的增加, 对电网中的关键设备要求更高[3-4]。 煤炭发电是电力生产的主要能源, 煤矿中的电力变压器更是在电能传输中起关键作用。 因此, 定期对煤矿变压器检测维护显得十分重要。 电力变压器常见的故障为电性故障、 局部受潮以及热性故障。 电性故障主要表现为短路故障, 比如单相对地短路、 两相对地短路、 三相之间的短路, 出口处短路最为常见。 局部受潮表现为套管部位密封不严谨, 储油柜内有积水等, 电力变压器油中掺杂水分会影响其绝缘特性[5-8]。 异常电流过热会导致电力变压器出现热性故障, 比如涡流、 环流等因素, 都会引起电流的瞬间增加, 引起电力变压器出现故障[9-10]。
目前对电力变压器油检测的方法大多是气相色谱法, 这种方法操作比较复杂, 不适合在线检测, 不能快速地检查出故障原因[11-14]。 本文提出激光诱导荧光光谱技术结合ELM算法识别出电力变压器故障类型。 首先, 通过激光打入未知油样, 得到荧光光谱, 再通过MSC、 SNV预处理算法进行噪声处理, 采用KPCA与PCA算法对得到的光谱数据进行降维, 再经过ELM算法识别出电力变压器的故障类型。
1 实验部分
1.1 材料
实验样本是从黄山市和宿州市的国家电网收集的电力变压器油样, 分别为热性故障油、 电性故障油、 局部受潮油以及原油, 故障油均为单状态下的油样。 每种油样分别采集50个, 共200个, 存放在密闭无光的容器中。
1.2 荧光光谱的采集
采用的仪器为美国Ocean optics公司生产的激光诱导荧光光谱仪, 型号为USB2000+, 光谱仪探头为可浸入式, 型号为FPB-405-V3。 整个油样的光谱采集流程如图1所示。
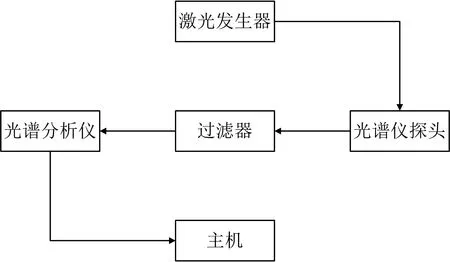
图1 油样的光谱采集流程图
为了防止其他光线的干扰, 整个实验均在暗室中进行。 由激光发生器发射出波长为405 nm的激光, 经过光纤传输, 到达微型光谱仪探头, 探头把激光直接输出到被测油样中, 而后接收被测油样受激发而产生的荧光, 经过过滤器, 筛选出所需要的光谱波段, 再由光纤传输到光谱仪进行光电信号转换等, 最后经数据线传送到主机。 主机上由OceanView软件显示荧光光谱, 波长范围370~1 050 nm, 积分时间100 ms, 多次扫描平均为3, 滑动平均宽度为1。
1.3 光谱预处理
由于在光谱获取的过程中, 难免会有一些不确定因素影响光谱图的质量。 第一, 一些干扰噪声掺杂在生成的光谱图像中, 会增大光谱数据的错误概率。 第二, 由于数据量大, 数据的品质不统一。 为了提高高品质的数据, 以便得到更高质量的结果, 因此, 我们需要对获得的光谱数据采用两种预处理方法, 分别为多元散射校正法(MSC)、 标准矢量归一化法(SNV)。
光谱预处理目前常用的一种方法是多元散射校正算法, 降低散射的影响, 增加光谱数据的准确性。 由于难以获取理想光谱数据, 因此, 假设所有光谱数据的平均值为“理想光谱”。 其次, 将采集的油样光谱与理想光谱进行一元线性回归, 得到每个油样的基线平移量和偏移量。 最后, 校正每个油样的光谱。
(1)
(2)
(3)
标准矢量归一化算法的主要作用是削减光程变化、 表面散射等因素的影响。 SNV算法是对光谱阵的行运算的, 处理的对象为某一条光谱。 SNV归一化的公式
(4)
k=1, 2, …,m;i=1, 2, …,n

两种预处理算法所生成的图像和原始图像进行对比, 如图2所示, 波段在370~550和900~1 050 nm基本趋于一致,主要不同集中在550~900 nm, 四种波的波峰也主要集中在此, 可以看出有四类不同的波形, 分别代表四种不同的油样。
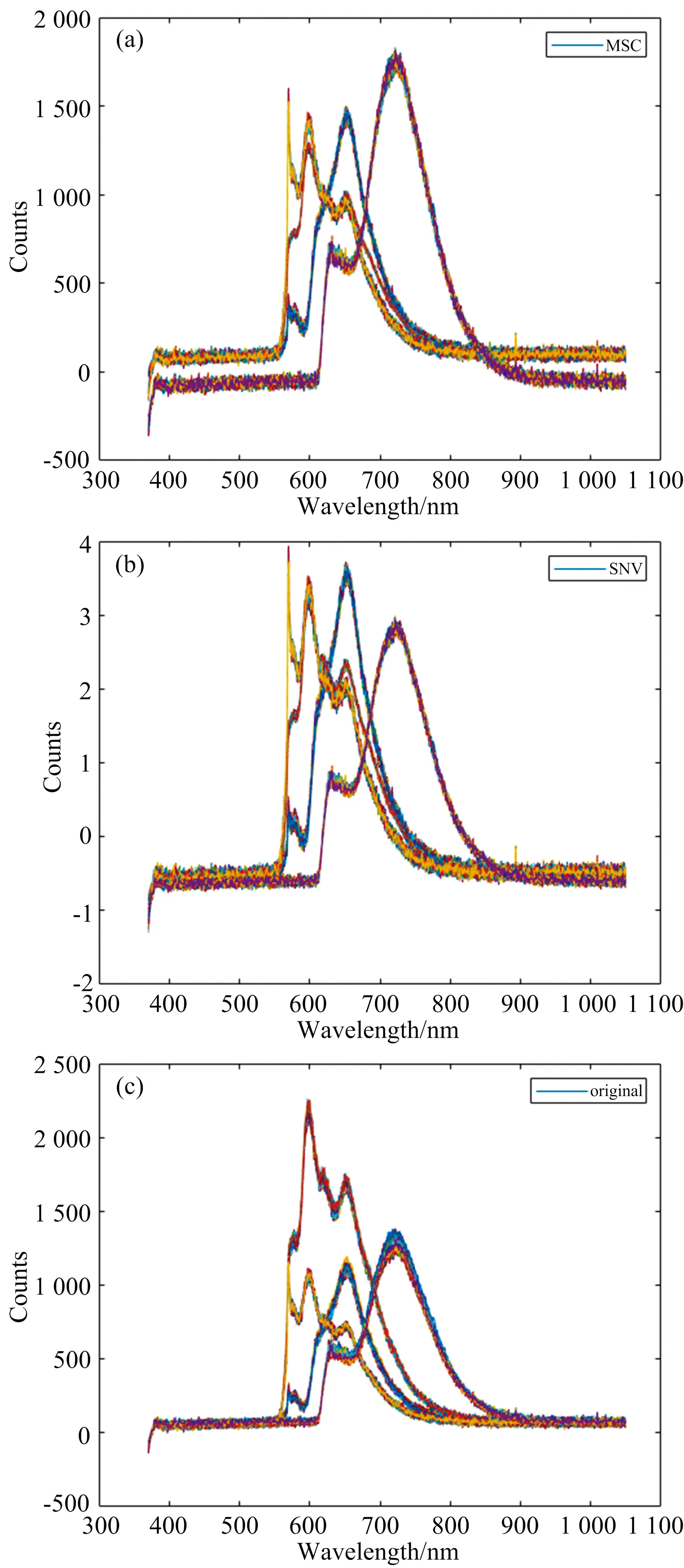
图2 两种预处理及原始图像
1.4 PCA和KPCA降维
每个样本生成的光谱数据为2 048个, 一共200个样本, 由于数据维度过大, 会造成模型的复杂性, 因此, 采用PCA与KPCA算法降低数据的维度, 减少整个模型的训练时间。
主成分分析(PCA)是把原来的变量映射到新的变量空间, 在新的变量空间可以用若干个变量替代原来的变量, 并尽可能保留原变量的数据内容, 新变量之间相互正交, 消除原变量的共线性问题。
核主成分分析(KPCA)是通过核函数把原始数据映射到高维空间, 再利用更高的维度空间进行线性降维。
对预处理后的数据和原始数据进行降维, 如图3和图4所示, 当主成分数为1时, 只有MSC-PCA和MSC-KPCA的累计贡献度达到85%以上, 其他模型的累计贡献度均低于此值。 随着主成分数的增加, 累计贡献度也随之上升, 因此, 选择主成分数为5, MSC-PCA累计贡献度为95.68%, Original-PCA与SNV-PCA累计贡献度分别为61.74%和78.58%, MSC-KPCA累计贡献度达到最高, 为99.00%, Original-KPCA与SNV-KPCA均低于MSC-KPCA的累计贡献度, 分别为63.84%和84.72%。 结合数据可以看出, MSC预处理后的数据经两种方式降维效果最好, 累计贡献度最高。 同时, 经预处理比未经预处理得到的降维数据更佳。

图3 PCA累积贡献率
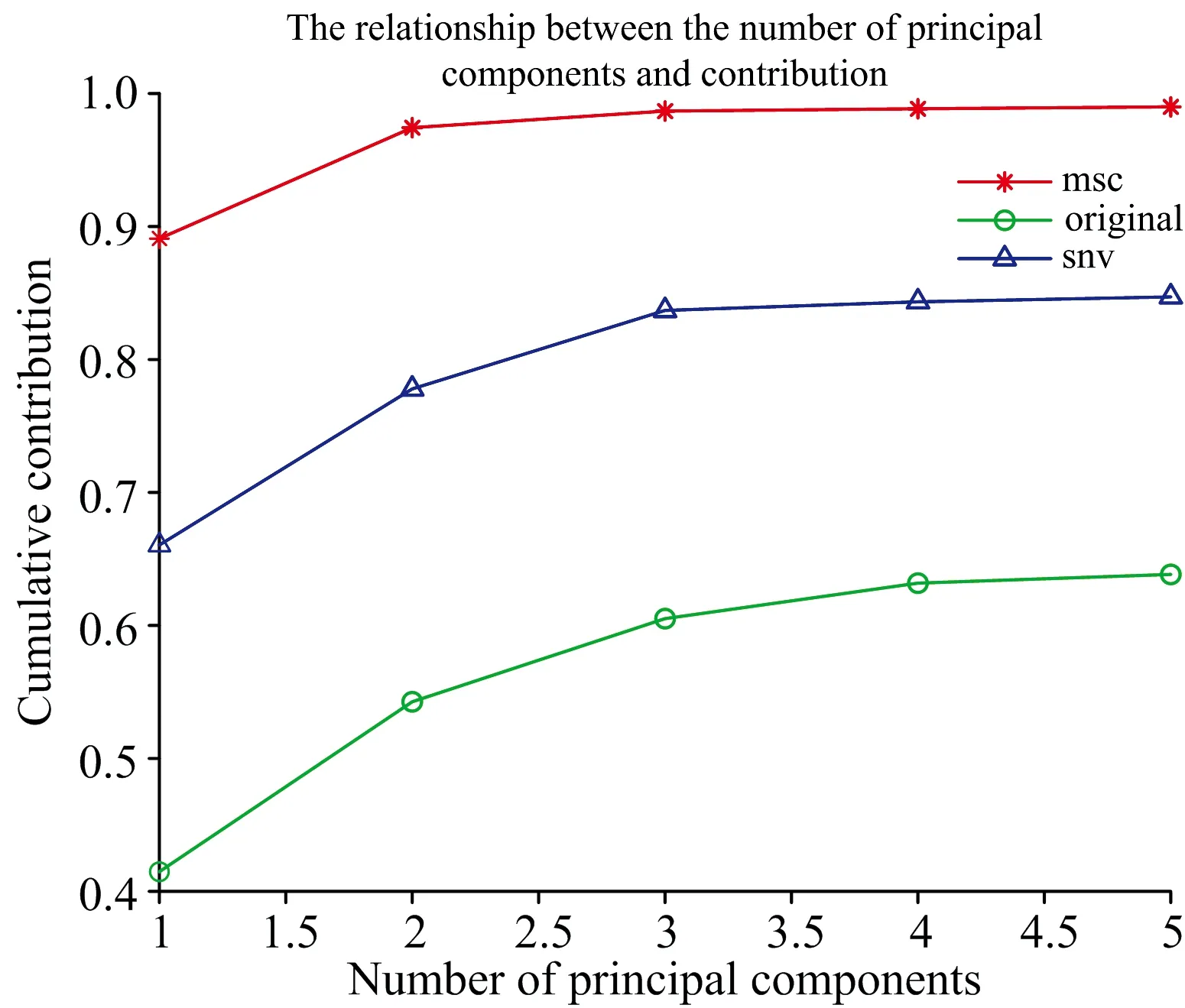
图4 KPCA累积贡献率
2 结果与讨论
极限学习机(ELM)是一种前馈神经网络算法, 该算法包含输入层、 隐含层、 输出层。 在创建网络时, 输入层和隐含层的连接权值以及隐含层神经元的阈值均为随机设定, 且设定以后不再调整。 隐含层和输出层之间的连接权值β可通过求以下方程组的最小二乘解获取

(5)
其解为
(6)
式(6)中,H+为隐含层输出矩阵H的Moore-Penrose广义逆。
2.1 ELM的预测模型的基本步骤
(1)导入PCA与KPCA降维后的数据。
(2)训练集/测试集的产生。 本实验采用四种油样, 每类油样分别贴入标签1, 2, 3和4, 即标签1对应热性故障油, 标签2对应电性故障油, 标签3对应局部受潮油, 标签4对应原油。 每一种油样中, 随机选取40个作为训练集, 10个为测试集, 共160个训练集, 40个测试集。
(3)数据归一化, 把不同范围的数据映射到指定的区间, 减小数据差异较大对模型性能的影响, 提高预测模型的收敛速度, 缩短训练时间。
(4)ELM创建/训练。 用elmtrain()函数创建并训练ELM, 设置隐含层神经元个数以及激活函数类型, 参数TYPE设置为0。
(5)ELM仿真测试。 训练完成后, 用elmpredict()函数对测试集进行仿真测试。 设置TF和TYPE, 并与训练函数参数保持一致。
(6)绘图与性能评价。 直观反映结果, 并作出合理判断。
2.2 结果与性能评价
由于测试集与训练集是随机产生, 因此每次结果都会不同, 某次运行的ELM预测模型拟合, 结果如图5所示。 预测结果最好的是MSC-KPCA-ELM模型, 预测值与真实值基本一致。 表现效果最差的是未经预处理的Original-PCA-ELM, 预测值在真实值周边波动。 直观的看, 经MSC、 SNV预处理的模型比未经预处理的模型预测更为准确。

图5 ELM测试集输出模型预测结果对比
各预测模型的性能指标如表1所示, MSC-KPCA-ELM模型最佳, 平均相对误差MRE为0.96%, 均方根误差RMSE为0.027 1, 均接近于0。 SNV-KPCA-ELM模型的平均相对误差MRE为1.74%, 均方根误差RMSE为0.036, Original-KPCA-ELM模型平均相对误差MRE为2.41%, 均方根误差RMSE为0.063 2。 可以看出, 同为KPCA降维的模型, 经MSC预处理的效果要好。 MSC-PCA-ELM模型的平均相对误差MRE为1.18%, 均方根误差RMSE为0.033 9, 对比后发现, 同为MSC预处理, KPCA-ELM模型比PCA-ELM模型效果更佳。 效果最差的模型是Original-PCA-ELM,平均相对误差比最佳的模型高2.54%, 均方根误差RMSE高0.045 9。

表1 ELM测试集输出模型性能指标对比
MSC预处理后的KPCA-ELM模型运行时间为0.5 s, PCA-ELM模型运行时间为3.296 9 s, 其中KPCA降维的时间为0.437 5 s, PCA降维的时间为3.234 4 s, 可以看出, 由KPCA降维比PCA更快, 同一状态下的效果会更好。
相对误差能够反映预测值偏离真实值的实际大小, 如图6所示为ELM测试集输出结果的相对误差曲线, 误差幅度变化较大主要集中在标签1所对应的油样, 标签2, 3和4基本趋于平稳。 MSC-KPCA模型的相对误差波动最小, 为0.12%~3.68%, 验证出预测结果更为准确。 误差幅度变化最大的为Original-PCA模型, 最高值为18.74%, 较MSC-PCA模型高出了12.02%, 可以看出, 此模型预测结果相对不佳。
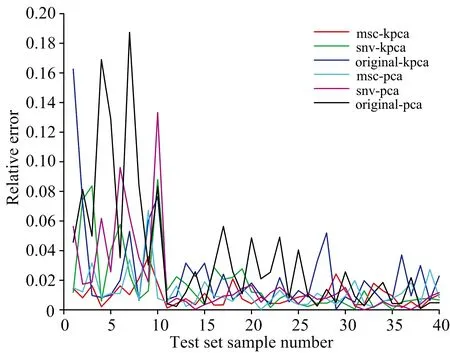
图6 预测值与真实值的相对误差曲线
3 结 论
实验对三种电力变压器故障油以及原油利用激光诱导荧光光谱分析技术进行数据分析, 采用MSC、 SNV两种预处理方式, 结果发现, MSC预处理后的数据经KPCA降维, 其主成分贡献率达到最高, 而未经预处理的数据经两种降维算法达到的效果均较差。 实验可见, 经KPCA降维的模型运行时间小于PCA, 验证出使用LIF技术获取电力变压器油荧光光谱, 结合MSC-KPCA模型经ELM拟合性能最佳, 对检测电力变压器故障类型具有一定的可靠性。
