考虑复杂随机来料的批量流作业调度
2022-04-29王铖恺
章 旸,王铖恺,刘 冉
(上海交通大学 机械与动力工程学院,上海 200240)
0 引言
柔性流水车间(Flexible Flow Shop, FFS)常见于半导体制造、钢铁制造、汽车制造等大量工业环境。作业调度是流水车间生产过程中的重要工作和经典问题,也是典型的NP-hard问题。合理的作业调度安排对于生产效率与资源利用均有很大的意义。对于可分批加工的生产任务,批量流方法可有效缩短最大加工完成时间。将每种工件的总加工批量划分为若干个子批,其中每个子批包含若干个单工件[1],通过对子批的单独调度,实现同种工件在多个工序中的并行加工,可缩短整个生产任务的完成时间。这类调度问题一般称为批量流调度问题。
批量流调度能够有效缩短生产任务的最大完成时间,但这种模式下的生产调度也更加困难。一般工件的分批越细,最大完成时间的缩短情况越明显,但过多的子批数会增加问题的规模和调度难度。同时,在实际生产中,每台机器在子批切换过程中需要进行换模,换模时间一般与加工顺序密切相关,这进一步加大了问题的复杂性。而且,随着生产环境的复杂化与不确定性的提高,生产过程的随机性也越发重要且必须被调度所考虑,例如工件的随机来料,工件在机器上的加工时间随机以及机器故障等。考虑随机性的车间调度问题已经非常复杂,考虑随机因素的批量流调度显然更加困难。
柔性流水车间内批量流调度问题(Flexible Job-shop Scheduling Problen with Lot Streaming, FJSP-LS)已经引起学界的重视和研究。LOW等[2]论述了车间调度中应用批量流方法的优势。对于FJSP-LS的求解,根据批量划分方式的不同,可分为均等子批、一致子批和可变子批[3]。目前,大多数柔性车间分批调度研究中,多采用一致子批的划分策略,白俊杰等[4]采用通过以最小化加工完成时间为目标对子批加工顺序进行分批与排序,指出在子批数量相同的情况下,柔性分批调度方法比均等分批调度方法可以更有效地缩短交货期。由于可变子批的复杂性,目前在该方面的研究较少,WANG等[5]提出一种三阶段方法来解决有换模时间的FJSP-LS,通过最小批量进行划分后以加工完成时间最小为目标确定调度方案,再优化批量,加工过程中子批批量可变。但为了缩短加工时间,往往需要更多的子批数据从而增加传输次数,生产成本变大。根据求解方法可将FJSP-LS分为精确算法与启发式算法两个研究方向。其中精确算法主要用来求解规模较小的批量流调度问题,MORTEZAEI等[6]通过建立混合整数规划模型实现了FJSP-LS的求解,并指出随着加工阶段的增多,批量流方法的效果更为显著,但是该模型对于所求解的问题规模要求较高,最多为两种工件,每种工件最多可分为3个子批;ALFIERI等[7]针对考虑换模时间的流水车间批量流调度问题提出一种动态规划算法,可在短时间内实现精确求解,但是该算法仅针对单种工件的两阶段加工生产线的分批调度,并不能应对多种类、多生产阶段的生产调度问题。近年来,为了应对越来越复杂的制造环境,以及对于大规模问题求解的要求,各种启发式算法被不断引入到批量流生产调度问题的研究中,VENTURA等[8]、TSENG等[9]分别采用遗传算法与粒子群算法进行求解,并且有大量学者通过对各启发式算法的改进实现了批量流问题的高效求解,如ALFIERI等[10]提出一种基于动态规划的精确与启发式相结合的算法来求解单种工件、两台机器的批量流调度问题;刘雪红等[11]针对柔性车间可变子批的特点建立了以最小化最大完成时间和最小化批次数目为优化目标的多目标柔性作业车间调度模型,并设计改进的候鸟算法进行求解,其中禁忌搜索(Tabu-Search, TS)是求解FJSP的经典算法[12-13],且与各启发式算法相比,TS能够在合理的时间内给出较好的调度方案。近年来,越来越多的学者将TS运用到FJSP-LS上,并获得了高质量的解。HAMED等[14]采用TS针对多种类工件的批量流调度问题进行求解,并设计了3种邻域搜索来加速算法的收敛,取得了良好的效果;SHAHVARI等[15]将TS与混合整数规划相结合,通过TS探索解空间,在加工路线确定后将混合整数规划问题转化为线性规划对目标解进行评估。
对于随机条件下的车间调度问题,现有的相关研究并不多,主要的研究方向为考虑工件加工时间随机、工件随机来料或设备故障的条件下最小化总加工完成时间。其中:WANG等[16]提出一种基于两阶段仿真的分布评估算法,用于在工件加工时间随机的情况下最小化流水车间的总加工时间;ZANDIEH等[17]针对工件随机来料,考虑机器故障的车间调度问题引入了变领域搜索算法(Variable Neighborhood Search, VNS);FU等[19]研究了工件加工时间服从正态分布,最小化最大完成时间与拖期的多目标优化问题,建立了混合整数规划模型,并开发了烟花算法来加速模型的求解。以上方法均仅考虑了工件的单独调度,并未考虑工件的分批问题,且不能应对复杂的随机环境。HAN等[18]对工件加工时间随机的批量流调度问题采用蒙特卡洛采样方法,将问题转化为确定的多目标优化问题,并提出一种多目标迁徙鸟优化算法进行求解,但是该问题并未考虑最小批量问题,即工件的子批批量可以为符合条件的任意整数,且不考虑批次切换过程中的换模时间。
Benders分解方法由BENDERS[20]首先提出,用于解决混合整数规划问题,近年来也越来越多被用于大规模或较为复杂的车间调度问题的求解。如HARJUNKOSKI等[21]提出一种求解钢铁行业大规模的复杂调度问题的分解算法;WALDHERR等[22]通过分解算法求解工件在加工过程中需要额外资源、有并行机器且考虑机器换模时间的复杂流水车间调度问题。Benders分解还可与SAA(sample average appropriation)方法结合,实现对随机问题的求解[23-24]。
虽然目前对批量流问题和随机车间调度问题均分别已有相关研究,但将两者结合起来的研究较少,且在考虑随机性时大多为针对某特定分布的研究,不能适应更为复杂的随机环境,并且目前还没有用Benders分解来求解随机环境下的FJSP-LS的相关文献。本文研究了复杂随机来料的可分批柔性生产线作业调度问题,基于SAA方法建立了混合整数规划模型,该模型适用于复杂随机环境,并考虑模型的难求解性以及Benders分解在求解难解的混合整数规划问题上的优越性,本文采用该方法来实现对复杂随机环境下柔性车间批量流调度问题的求解,同时设计禁忌搜索算法实现近似求解,可应对复杂随机环境以及大规模的批量流调度问题的求解,通过数值实验验证了方法的有效性。
1 问题描述与数学模型
1.1 问题描述
本文研究对象是由K台机器组成的生产线,其中机器位置固定且缓冲区容量无限,每台机器可进行一种或多种工艺的加工,但同一时间仅可加工一个工件,所有机器在系统时刻0处于空闲状态,不考虑机器故障。生产线需加工I种不同种类的工件,对于一个工件i∈I,其总加工任务量为di,di可被分为若干个子批,所有工件的来料时间不确定,服从某随机分布。工件来料后方可进行加工,在进入生产前即分为若干个批量不等的子批进入机器进行加工,子批在每台机器上加工时批量保持不变,每一子批加工前有与加工顺序相关的机器换模时间。子批批量规定为最小批量minS的整数倍,同时规定di为minS的整数倍,工件i最多可被分为ui个子批,ui=di/minS。所有子批按照加工顺序依次经过所有机器,只有在前一个子批全部加工完成并离开机器后,下一子批才可进入该机器并进行换模。工件i在机器k上的加工时间确定,为PTik,机器k上工件i到工件j上的换模时间STijk与i,j相关,不考虑工件在机器间的运输时间。
问题需确定每类工件应分为多少个子批、每个子批包含多少个最小批量以及所有子批的加工顺序,以最小化生产线在随机环境下的最大完成时间期望。
如图1所示:Cmax表示该调度方案的加工完成时间,J11表示工件1的第一个子批,J12表示工件1的第二子批,以此类推。其中:图1a~图1c为工件来料时间均为0时3种调度方式的加工完成时间比较,图1a为不分批,图1b与图1c分别为两种分批调度方案。由图1a与图1b、图1c的对比可见,对工件进行分批操作有利于缩短工件的加工完成时间;而对比图1b与图1c可见,不同的分批调度策略缩短加工时间的效果明显不同,分批1优于分批2。当工件来料时间发生变化时,如图1d与图1e所示,其中分批2的加工完成时间小于分批1。综合对比图1b、图1c与图1d、图1e,由不同的对比结果可知工件的来料时间对调度方案的效果有较大影响。在不同的来料时间背景下,最优的加工顺序与分批方案不同,最优的加工完成时间也不同,因此当来料时间不确定时,难以确定最优调度方案。

1.2 基于SAA的随机规划模型
在随机环境中,工件来料时间、子批在各机器上的加工完成时间与生产线最大完成时间都具有随机性质,很难直接建立数学模型求解。SAA方法根据工件来料时间的随机特性生成S个场景,目标是最小化这S个场景的最大完成时间均值。
建立本问题随机混合整数规划模型MIPSAA如下:
(1)优化变量
nij为整数变量,工件i的第j个子批的最小批量个数,可以为0;
Sij为整数变量,工件i的第j个子批的工件总数,可以为0;
zijgh为0-1变量,zijgh=1时,工件i的第j个子批和工件g的第h个子批均不为0,且工件i的第j个子批为工件g的第h个子批的前一个子批,否则zijgh=0;
Cs为连续变量,场景s的最大完成时间;
tijks为连续变量,场景s中工件i的第j个子批在机器k上的加工完成时间;
yij为0-1变量,nij>0时,yij=1;nij=0时,yij=0。
(2)随机变量
ATis为场景s中工件i的来料时间。
(3)其他变量
uij为辅助变量,用于顺序记录。
MIPSAA为:
(1)
s.t.
tijks≥tghks+SijPTik+STgik-(1-zghij)M,
0≤i≤I,1≤j≤ui,0≤g≤I,
1≤h≤ug,1≤k≤K,1≤s≤S,
(i,j)≠(g,h);
(2)
tijks≥tij(k-1)s+SijPTik+STgik-(1-zghij)M,
0≤i≤I,1≤j≤ui,0≤g≤I,1≤h≤ug,
1≤k≤K,1≤s≤S,(i,j)≠(g,h);
(3)
yij≤nij≤yijM,0≤i≤I,1≤j≤ui;
(4)
Sij=nij·minS,0≤i≤I,1≤j≤ui;
(5)
(6)
Cs≥tijKs,1≤i≤I,1≤j≤ui,1≤s≤S;
(7)
tij0s≥ATis,1≤i≤I,1≤j≤ui,1≤s≤S;
(8)
(9)
(10)
(11)
uj-ugh+M·zghij≤M-1,
0≤i≤I,1≤j≤ui,0≤g≤I,1≤h≤ug;
(12)
y01=1;
(13)
yij,zijgh∈{0,1},tijks≥0,Cs≥0,
intSij≥0,intnij≥0,uij≥0,
0≤i≤I,1≤j≤ui,0≤g≤I,
1≤h≤ug,0≤k≤K,1≤s≤S。
(14)
其中:目标函数(1)为最小化S个场景的最大完成时间均值;约束(2)表示同一机器上前后两个子批之间的约束;约束(3)表示同一子批在相邻两台机器上的加工约束,M为一个很大的正数,只有zijgh等于1时约束(2)、(3)才生效;约束(4)表示辅助变量yij与nij之间的关系;约束(5)表示每种工件每个子批包含Sij的工件数量为最小批量的整数倍;约束(6)表示同种工件的所有子批大小之和等于该种工件总批量;约束(7)表示最大完成时间不小于所有批次在最后一台机器上完工时间;约束(8)表示所有子批在该种工件来料后才可加工;约束(9)与约束(10)分别约束了每一个批次的紧前与紧后工件最多只有一批;约束(11)表示虚拟工件0为第一个子批;约束(12)保证了由变量zijgh决定的加工顺序是一条无闭环的完整的生产线;约束(13)表示虚拟工件0的第一个批次批量大于0;约束(14)表示各变量的取值范围。
2 求解算法
MIPSAA是一个非常难以求解的混合整数规划模型,车间调度问题(Job-shop Scheduling Problem, JSP)为经典的NP-hard问题[25],而本文研究的柔性车间调度还需考虑工件的分批以及工件的随机来料,进一步增加了问题的求解难度,显然也具有NP-hard的性质。即使对很小的问题算例,MIPSAA包含大量的约束和决策变量,例如对于3种工件,每种工件最多可分3批,场景数为75的小规模问题包含的约束多达14万条,变量6 000多个,直接通过CPLEX等求解工具无法在有限时间内求解。本文引入Benders分解方法并设计了两套算法来对该调度问题进行优化。首先简单介绍Benders分解算法,其核心思想是通过分离容易处理的变量与复杂变量,将原问题分解为子问题与主问题,对两类变量分别求解。模型MIP为:
mincTx+dTy。
(15)
s.t.
Ax+By≥b;
(16)
x≥0,y∈Y。
(17)

(18)

(19)
x≥0。
(20)
(21)
s.t.
ATu≤c;
(22)
u≥0。
(23)
遍历所有的y不现实,虽然MIP的可行域复杂,但在求解最优解的过程中,仅需要有限的cut(割平面)去逼近原问题。cut构造方法如下:

dTy+(b-By)Tup≤w。
(24)
式(24)称为optimalitycut。
(2)若DSP无界,记ur为DSP的一条极线,根据对偶理论,SP不可行,故增加限制减小使DSP无界的区域,等价于缩小了使SP不可行的区域,增加的cut为:
(b-By)Tup≤0。
(25)
式(25)称为feasibilitycut,与optimalitycut共同完成主问题的构造。MIP可重写为:
(26)
构造仅含整数变量的主问题(Master Problem, MP)如下:

allthefeasibilitycuts}。
(27)
主问题为由cut组成的整数规划,cut由DSP问题的极点与极线给出。Benders分解通过MP与DSP求解与迭代直至问题上下界相等,找到最优解。
2.1 基于Benders分解的精确算法
2.1.1 主问题与子问题构建

minCs。
(28)
s.t.
约束(7)~(8);
(29)
0≤i≤I,1≤j≤ui,0≤g≤I,
1≤h≤ug,1≤k≤K,(i,j)≠(g,h);
(30)
0≤i≤I,1≤j≤ui,0≤g≤I,1≤h≤ug,
1≤k≤K,(i,j)≠(g,h);
(31)
tijks≥0,Cs≥0,intSij≥0,0≤i≤I,
1≤j≤ui,0≤g≤I,1≤h≤ug,0≤k≤K。
(32)
SPSAA-s的对偶问题DSPSAA-s如下,其中:aijghks、bijghks、cijs和dijs为SPSAA-s的对偶变量;DSPSAA由S个DSPSAA-s构成。
(33)
s.t.
(34)
(35)
aij01ks≤0,1≤i≤I,1≤j≤ui,
1≤k≤K-1;
(36)
aij01Ks≤0,1≤i≤I,1≤j≤ui;
(37)
(38)
aijghks≥0,bijghks≥0,cijs≥0,dijs≥0,1≤i≤I,
1≤j≤ui,1≤g≤I,1≤h≤ug,1≤k≤K。
(39)
其中
(40)
主问题MPSAA如下,T为当前迭代次数。
minw。
(41)
s.t.
约束(4)~(6),(9)~(14);
(42)
其中
b0=nij·PTik+STgik-(1-zghij)·M。
(43)
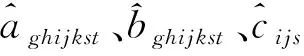
Benders分解求解MIPSAA的计算流程总结如下:
2.2.2 算法加速策略
尽管以上算法可对MIPSAA进行精确求解,但实际计算中算法在每一次迭代中仅添加一个cut效率过低,导致迭代次数过多,且伴随着算法的迭代,MPSAA越来越复杂,每次迭代时间随之增长。为了加速求解,设计了3种加速策略。
(1)预设optimalitycut策略
Benders分解的目的在于用有限的cut,去逼近原问题,为了加速求解,在算法开始前随机生成一定数量cut,并在步骤1首先将预设的cut添加进MPSAA中,是对整个Benders分解的一个良好预热。
(2)邻域搜索添加多个cut

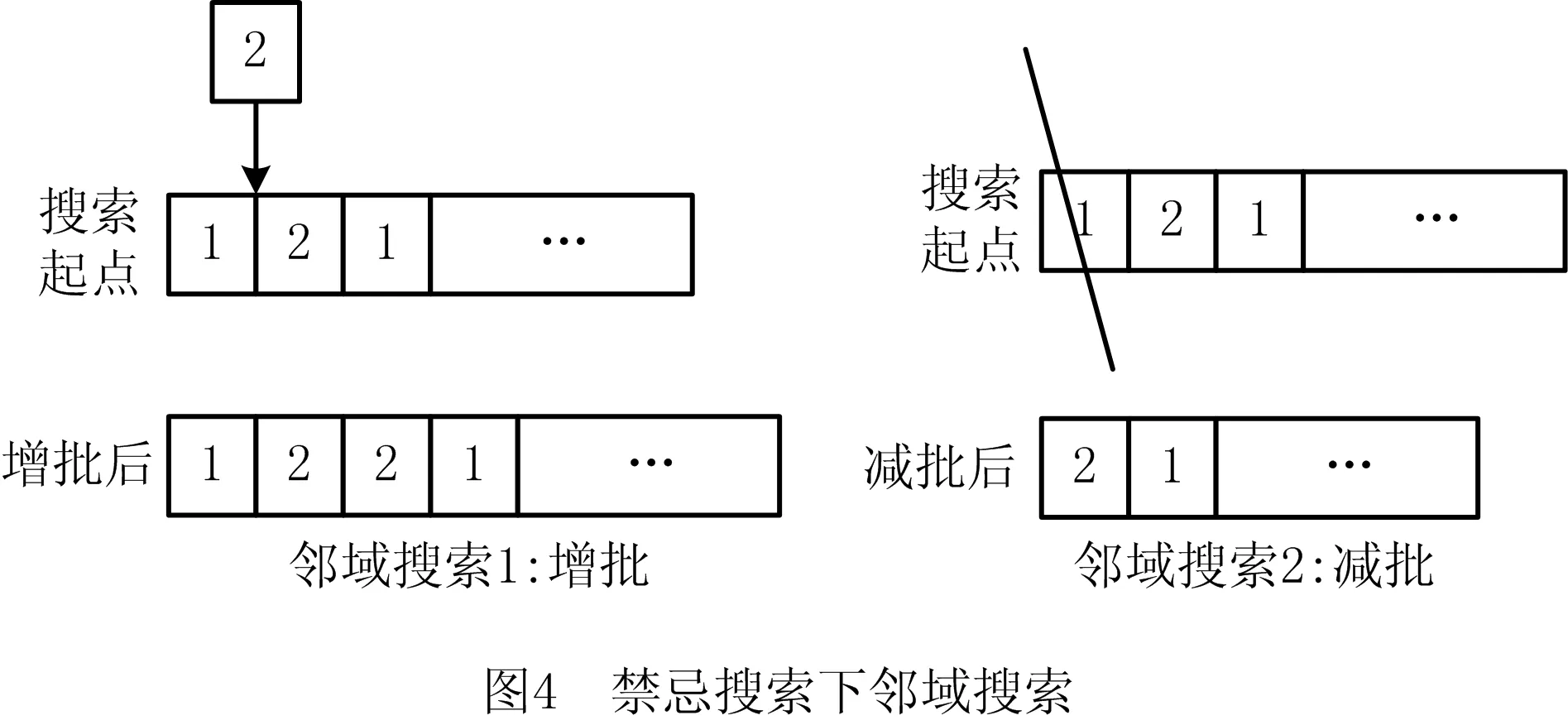
1)交换:从搜索起点的第一位开始交换Sc0相邻数对。
2)增批:在Sc0的每一位依次插入分批未达被分至最细的工件的一个子批,并随机选择该工件的另一子批将其批量减去一个最小子批。
3)减批:依次删除Sc0的每个子批,并将被删除的子批的批量随机加至该种工件的一个剩余子批上,当Sc0中仅包含一个子批的工件时,不可作删除处理。
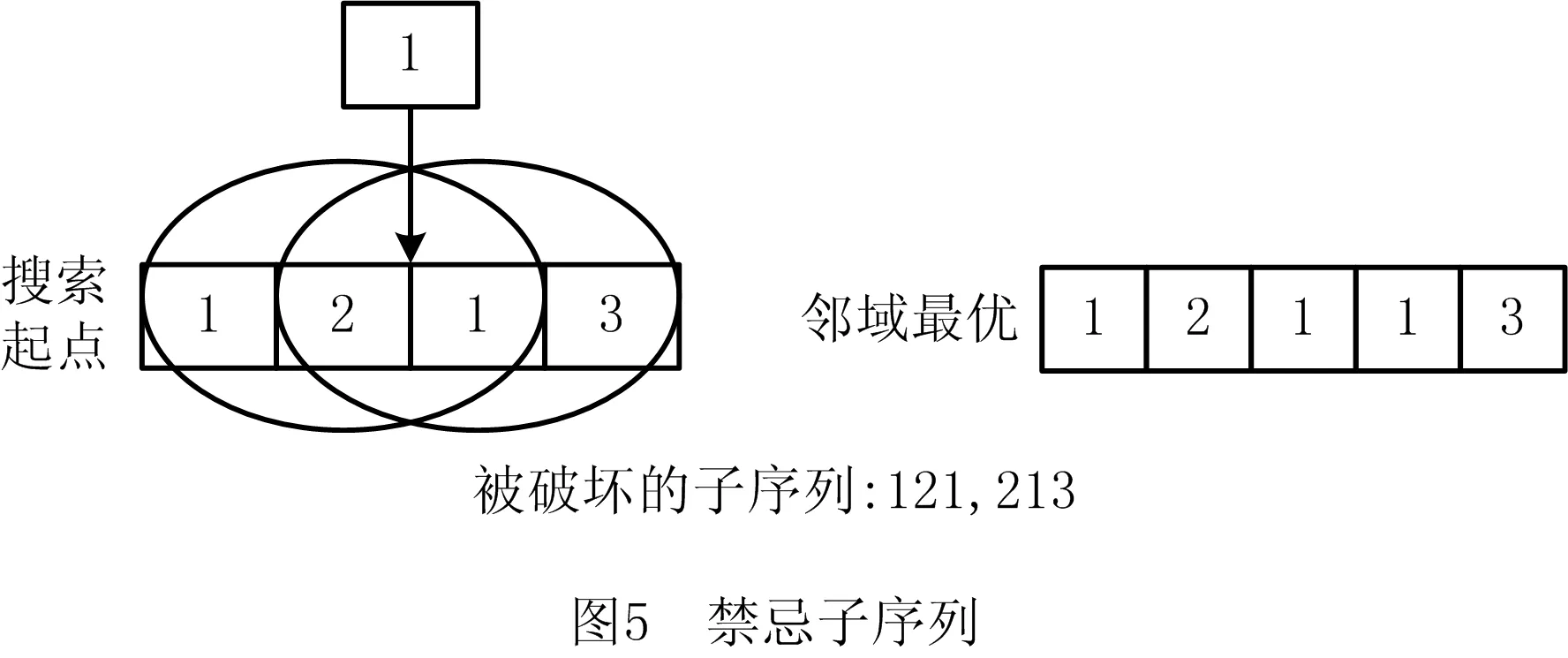
每一次邻域搜索可向主问题一次性添加若干cut,大大缩小可行域,但是频繁的搜索会使得约束过多,从而加重主问题求解的负担,故设计当上界在LS次迭代内未得到提升,则进行邻域搜索,引入计数参数count_ub记录上界重复次数,每次迭代结束后更新。

(3)有效不等式(Valid Inequalities, VIs)
(44)
(45)
(46)
(47)
以上均为MPSAA的可行解,却对应同一个Sc,为了避免重复解,可采用以下两组VIs。
(1)对于同种工件,优先对编号靠前的子批安排批量,约束如下:
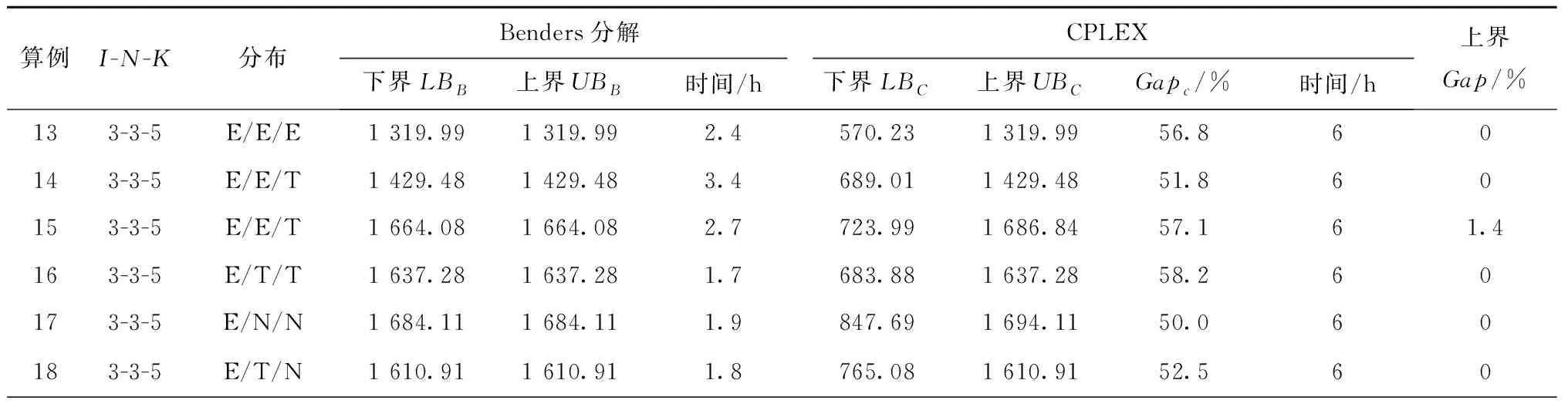
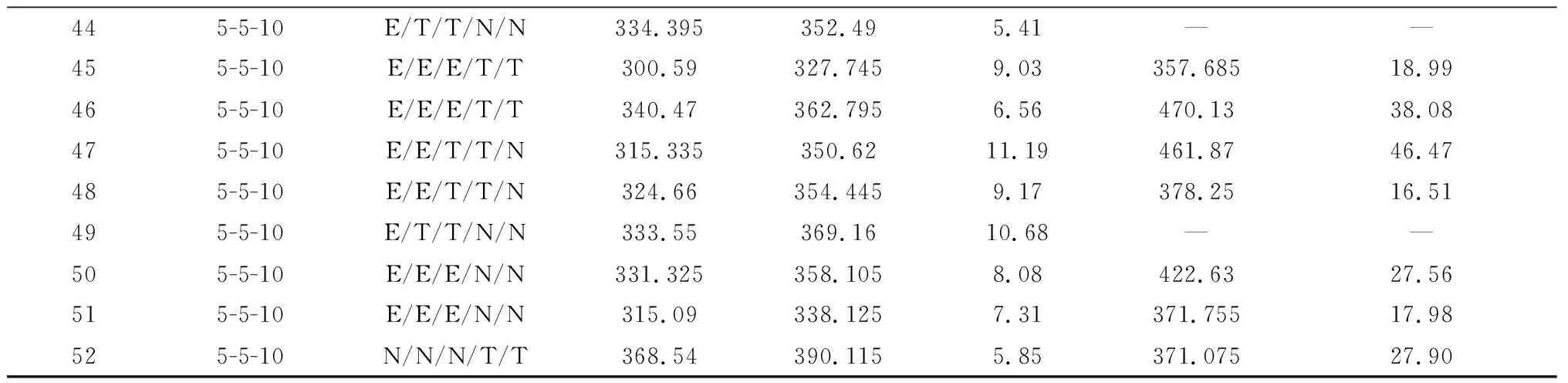
yij≥yih,1≤i≤I,1≤i (48) (2)同一种工件的不同批量在加工顺序的排列中依据该种工件的批次编号升序排列。 为了表达出每种工件在整个加工顺序中的排序,引入ind变量作为辅助变量。ind无范围约束,VIs如下: indij-indgh≥(zghij-1)·M+1,1≤i≤I, 1≤j≤di,1≤g≤I,1≤h≤dg; (49) indi,j+1≥indij+1,1≤i≤I,1≤j≤di。 (50) 添加约束(49)和约束(50)至MPSAA中。改进后的Benders分解流程图如图3所示。 上述精确算法难以在有限时间内求解大规模问题,本文在此基础上提出基于禁忌搜索的启发式算法,将问题分解为以下两个子问题: (1)确定每种工件分批数与分批后所有子批的加工顺序。 (2)加工顺序确定后每个子批的批量。 子问题(1)通过禁忌搜索算法对加工顺序进行优化,子问题(2)采用SAA与Benders分解法结合求解。 2.3.1 禁忌搜索算法 算法对加工顺序进行实数编码,数字表示工件种类,数字在序列中的位置表示顺序,数字在序列中出现的次数表示工件的子批个数,例如序列Sd={1 122}表示需加工两种工件,工件1与工件2均被分为2个子批,工件1的第一个子批首先加工,其次是工件1的第2个子批、工件2的第1个子批、工件2的第2个子批。如图4所示,每一次迭代从搜索起点Sd0出发对其进行邻域搜索并将下一次迭代的搜索起点更新为本次的邻域最优解,邻域搜索为增批与减批。 增批为选择编码中子批个数小于其子批上限的工件,在Sd0的所有相邻位中插入该工件的一个子批,增批可使工件的总子批数加1。减批为依次删除Sd0中工件编号在编码中出现次数大于1的工件的每一个子批,减批可使工件的总子批数减1。 为避免搜索重复解,建立禁忌列表(Tabu List, TL),将Sd0中被破坏的子序列存入TL内,舍弃被TL禁忌的邻域解,若一定迭代次数(禁忌步长)内邻域最优均未出现该子序列,则对其解禁,从TL中删除,如图5所示。本文的禁忌搜索算法通过邻域搜索对加工顺序进行优化,终止条件为计算时间。其中对加工顺序的评价,即Sd的解码为问题(2)的求解,并通过求解的加工完成时间对该加工顺序进行评价,算法终止时输出最优解。 禁忌搜索算法的基本过程如下: 步骤1初始化。迭代次数计数器iteration=0。随机生成Sd0并计算其最大完成时间Ma0。禁忌列表初始化为空,上界UB=Ma0,当前最优解Sdb=Sd0。 步骤2iteration=iteration+1,对Sd0进行邻域搜索并舍去被禁忌的解,得到邻域最优Sdlb及其最大完成时间Malb。 步骤3Sd0=Sdlb,UB=min{UB,Malb}。 步骤4更新禁忌列表TL。 步骤5检查计算时间是否满足终止条件,若满足,则迭代中止,输出Sdb;否则返回步骤2。 2.3.2 解码:基于SAA与Benders分解的子批量确定 对于每次禁忌搜索确定的工件全部子批的加工顺序,其对应子批批量无法直接得到,故基于SAA建立随机规划模型MIPTS,并采用Benders分解算法求解。 (1)输入变量 L为编码长度,子批编号l∈L; π为加工顺序,π(l)表示第l批工件的工件种类; ali为辅助变量,ali=1表示第l个子批工件种类为i,否则ali=0。 (2)待优化变量 nl为整数变量,第l个子批包含的最小子批数,大于0; tlks为连续变量,第s个场景下第l个子批在第k台机器上的加工完成时间。 (51) s.t.tlks-t(l-1)ks≥nl·minS·PTπ(l)k+STπ(l-1)π(l)k, 2≤l≤L,1≤k≤K,1 (52) tlks-tl(k-1)s≥nl·minS·PTπ(l)k+STπ(l-1)π(l)k, 1≤l≤L,1≤k≤K,1 (53) tl0s≥ATπ(l)s,1≤l≤L,1 (54) (55) tlks≥0,intnl>0,ali∈(0,1),1≤l≤L, 0≤i≤I,0≤k≤K,1≤s≤S。 (56) 目标函数(51)为最小化S个场景下,最后一个子批在最后一台机器上的完成时间均值。约束(52)表示同一台机器上相邻子批在该机器上的加工完成时间之间的关系;约束(53)表示同一子批在相邻两台机器上的加工完成时间之间的关系;约束(54)表示所有工件均在来料后才可开始加工;约束(55)是对各种工件各子批总量的约束;约束(56)是对所有变量取值范围的约束。 mintLKs。 (57) s.t. 约束(54); STπ(l-1)π(l)k,2≤l≤L,1≤k≤K; (58) STπ(l-1)π(l)k,1≤l≤L,1≤k≤K; (59) tl0s≥ATπ(l)s,1≤l≤L。 (60) SPTS-s的对偶问题DSPTS-s如下,其中λlks,γlks和δls分别为MIPTS-s的对偶变量。 (61) s.t. -γl1s+δls≤0,1≤l≤L; (62) λlk-λ(l+1)ks+γlks-γl(k+1)s≤0, 2≤l (63) λlKs-λ(l+1)Ks+γlKs≤0,2≤l (64) -λ2ks+γ1ks-γ1(k+1)s≤0,1≤k (65) -λ2Ks+γ1Ks≤0; (66) λLks+γLks-γL(k+1)s≤0,1≤k (67) λLKs+γLKs≤1; (68) λlks≥0,γlks≥0,δls≥0,1≤l≤L,1≤k≤K; (69) (70) minw。 (71) s.t. 约束(55); (72) nl>0,1≤l≤L。 (73) 其中:约束(72)由所有的optimalitycut组成;约束(73)为变量的取值约束。 计算流程可总结如下: 步骤2求解DSPTS,通过DSPSAA的目标值均值更新UB并构造cut更新MPTS。 本文算例规模用I-N-K表示,即需要在K台机器上加工I种工件,每种工件最多可分为N个子批。同一算例中不同种工件的来料时间服从不同的随机分布,分布表示如下:正态分布-N,指数分布-E,三角分布-T。最小批量minS=1。本章中,PTik采用来自TAILLARD[26]与MARIMUTHU等[27]的两组benchmark数据,分别记为数据集Tail和数据集Mari,同时根据实际制造中的调研信息,本文将不同种工件在不同机器上的换模时间设定为STijk=0.5×(PTik+PTjk)。全部算法采用C++编写算法程序,运行于3.10 GHz CPU和512 GB RAM的计算机,求解数学规划采用CPLEX求解软件。 场景数S过小会影响随机问题的求解精度,过大会使模型的求解难度大大提升,故在进行数值实验前需对S的选取进行灵敏度分析,结果如表1所示。其中算例1~算例7规模相同,工件1与工件2的来料时间服从指数分布,工件3的来料时间服从三角分布,PTik来自于算例Tail,所有算例的输入参数均相同,仅对场景数S做出区分。 表1 场景数的灵敏度分析 由表1可知,S的选取对于求解精度与计算时间均有较为明显的影响。由于用Benders分解算法求解MIPSAA的子问题时需求解S组对偶问题,随着场景数的增多,Benders分解的计算时间也随之增加,当S过大时,求解子问题会耗费大量时间,而调度方案在S大于75后已不再改变,且结果也基本稳定,故S过大不仅对求解精度提升不高,还会影响问题的求解速度。当场景数达到100时,需近4 h才能够完成求解,但是S过小时,由于场景数过少,则对于随机性的处理不够,解的稳定性不高,结果的波动较大,从灵敏度的分析结果来看,当场景数达到75时,算例对最优加工顺序与分批情况的求解结果已基本趋向收敛,可以确定S取75以上可满足实验需求。 为了验证随机性对求解结果的影响,通过实验对工件来料时间的随机性进行分析,其中算例8~12规模相同,PTik来自于算例Tail,场景数为75,工件1的来料时间服从指数分布,期望为200,工件2与工件3均服从正态分布,期望分别为200与150,算例8~13中3种工件的来料时间期望、加工时间、换模时间均相同,工件2与工件3的来料时间方差不同,各算例详细信息如表2所示。由表2可知,由于不同算例下工件来料时间期望相同,求解结果在一定范围内波动,但随着方差的增大,结果的波动逐渐增大,且各算例的最优加工顺序与最优分批情况有明显不同,来料时间的随机性对于工件的最优调度方案的求解有明显影响。 表2 来料时间随机性影响分析 为验证本文设计的SAA&BD算法的准确性与求解效率,进一步采用benchmark数据进行数值实验,并将结果与直接用CPLEX求解MIPSAA的解对比来进行SAA&BD算法效能的评估。以规模为3-3-5、3-3-8和3-3-10的20组数据作为算例13~32,其中算例13~22的加工时间数据来自于数据集Tail,算例23~32的加工时间数据来自于数据集Mari,SAA&BD算法预设cut数P=500,邻域搜索触发参数LS=20,场景数S=75,且不同算例下工件来料时间所服从的分布均不同,同一分布下不同算例的工件来料时间均值及方差不等,设置CPLEX计算时间为6 h,如表3所示为算例13~32的计算结果。其中GapC=(UBC-LBC)/UBC·100%,Gap=(UBC-UBB)/UBB·100%。 表3 小规模算例benchmark数值实验结果 续表3 由表3可知,在场景数等于75时,对于不同benchmark均能在3.5 h内完成求解,算法求解时间较为稳定。同时算例13~32的工件来料时间均服从不同的随机分布,Benders分解的求解时间并没有出现明显的差异性,稳定性较高,可以认为该算法足以应对复杂的随机环境。与CPLEX求解MIPSAA对比,即使是小规模算例,CPLEX也无法在6 h内达到收敛,且上下界差距较大,而采用Benders分解,虽与CPLEX的结果相近,但Benders分解在求解时间上优于CPLEX,且由于上下界相等,可以证明其得到的是最优解。进一步地,在各随机场景下Benders分解均能求得最优解且求解时间稳定,而CPLEX在6 h内求得的解上下界Gapc在5%~60%之间波动,稳定性较差,可见在随机环境中,Benders分解有较高的稳定性。 对于规模较大的问题,本文同样采用两组benchmark数据分别进行数值实验,为了验证算法的有效性,本文以收敛性为评价指标,将TS与遗传算法、CPLEX直接求解方法进行比较和分析。采用算例规模为5-5-10的20组数据作为本文算例33~52,其中算例33~42的加工时间数据来自于数据集Tail,算例43~52的加工时间数据来自于数据集Mari。由于工件种类较多,工件的随机来料情况更为复杂,取S=200。设置CPLEX计算时间为4 h,禁忌搜索与遗传算法终止条件为迭代1 h,如表4所示为算例33~52的计算结果。RTS、RGA与RCPLEX分别为TS、遗传算法(GA)以及CPLEX求得的最大完成时间,其中GAPGA与GAPCPLEX计算方式分别为(RGA-RTS)/RTS·100%、(RCPLEX-RTS)/RTS·100%。 表4 大规模算例benchmark数值实验结果 续表4 遗传算法的基本设计如下:首先随机生成50个个体组成初始种群,个体编码方式与TS一致,通过对编码解码求得每条染色体的适应度值。在每一轮迭代中,基于适应度采用轮盘赌方法对群体进行选择,对被选择的两个个体进行交叉,交叉方式为随机生成两个不同的基因位进行单点交换,交叉完成后对个体进行变异操作,随机选取5个基因位作变动。交叉概率为0.8,变异概率为0.1,一轮迭代后得到下一个种群,当计算时间达到1 h,输出进化过程中所得到的具有最优适应度个体作为最优解输出,终止计算。 由表4可知,与GA对比,同样的计算时间内,TS求得的最优解均明显优于GA,且GAPGA在4%~11%。如图6所示为算例33与53的收敛图(横坐标为迭代次数,纵坐标为当前最优解),TS求解1 h迭代次数约为100次。由图6可明显看出,TS在100次迭代内迅速收敛且已基本稳定,而GA在500次迭代内并不能快速找到一个优秀的解并达到收敛。 与CPLEX求解混合整数规划模型相比,TS在1 h内得到的最优解均优于GA与CPLEX在4 h内给出的最优上界,结果的GAP值可达10%以上,且在10%~60%之间波动较大。对于部分算例,如算例27中CPLEX上界与TS最优解的GAP大于57%,算例44与49中CPLEX在4 h内均未找到可行解,可见禁忌搜索算法无论求解时间还是求解效果都优于CPLEX。从TS自身的求解性能来看,算例33~42与算例43~52分别来自于两组不同的数据集,但均能够在100次迭代次数内达到收敛,具有一定的稳定性,且对于工件来料时间分布并不敏感,对于来料时间的随机性不再限定分布必须服从特定的分布,增加了本文研究所针对问题的适应性。 本文以工件来料时间随机且考虑机器换模时间的柔性流水车间的批量流调度问题为研究对象,基于SAA方法建立了混合整数规划模型,并设计了精确求解与启发式求解两套求解算法。针对小规模问题,采用Benders分解加速模型的求解,实现了小规模问题的精确求解。针对难以在有限时间内实现精确求解的大规模问题,设计了禁忌搜索算法。最终,本文通过数值实验对比所设计的算法与遗传算法以及CPLEX的求解结果,验证了模型的可行性,并证明了Benders分解在求解复杂混合整数规划模型时的有效性与禁忌搜索算法在求解大规模问题上的优势。下一步,将针对更为复杂的混合车间批量流随机调度问题进行研究。
2.3 启发式求解算法
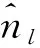
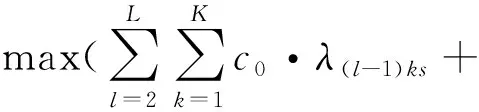
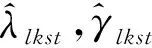


3 数值实验
3.1 随机性与灵敏度分析

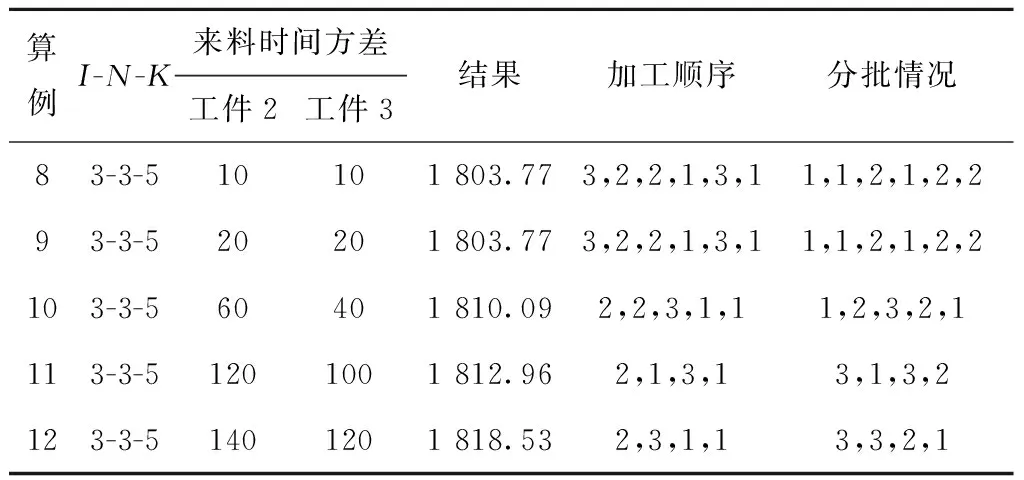
3.2 精确算法求解实验

3.3 启发式算法求解问题实验


4 结束语
