基于机器学习的心脏手术后急性肾损伤预测
2022-04-29范运龙邵佳康吴远斌朱思明何潇一李梁钢姜胜利
范运龙,邵佳康,吴远斌,宋 超,沈 铭,朱思明,何潇一,李梁钢,任 瞳,姜胜利
1 解放军医学院,北京 100853;2 河北医科大学第一医院 心血管内科,河北石家庄 050000;3 解放军总医院第一医学中心 心血管外科,北京 100853
急性肾损伤(acute kidney injury,AKI)是心脏手术后一种常见而严重的并发症,其文献报告的发生率为10%~30%[1]。值得一提的是,术后患者轻微的肾功能变化也与其晚期生存差异有关[2]。为了更好地管理心脏手术相关的急性肾损伤(cardiac surgery-associated acute kidney injury,CSA-AKI),既往研究通过传统的逻辑回归分析确定了几种风险评分,如克利夫兰评分和心脏手术后急性肾损伤评分[3]。然而,基于传统逻辑回归方法的风险模型受到其固有线性统计假设的限制,而潜在的非线性关联在分析过程中并未被考量[4]。此外,由于逻辑回归分析潜在的过拟合缺陷,在分析过程中只能纳入一小组输入变量。这导致一些可能对CSA-AKI有影响的围术期事件被排除在外,如术中输血和失血量。因此,需要探讨一种较传统的逻辑回归分析更有效的CAS-AKI预测模型。目前,机器学习被视为生物医学研究、个性化医学和计算机辅助诊断的有效手段,可用于诸多任务,包括风险分层、诊断分类和生存预测[5-8]。然而,许多医疗专业人员对于机器学习的概念并不是十分了解,尤其是在心脏外科学领域中将机器学习作为临床实践中的研究工具仍然处于空白阶段。因此,本研究试图基于机器学习技术,通过纳入术前和术中相关变量,分析其在AKI事件中的交互作用,从而构建出符合心脏手术患者特征的CSA-AKI风险预测模型。
资料与方法
1 资料 提取2017年1月1日- 2018年6月1日于解放军总医院第一医学中心心血管外科行心脏手术的638例患者的临床资料。纳入标准:1)年龄≥18岁;2)手术类型为瓣膜手术、冠状动脉旁路移植和大血管手术。排除标准:1)先天性心脏病矫正手术;2)数据丢失>10%;3)住院期间拒绝手术。
2 纳入分析的变量 收集患者的78个术前和术中变量来构建纳入分析的变量数据集。1)术前变量:人口学特征(性别、年龄、体质量指数、美国麻醉医师协会ASA分级、Mallampati气道分级、纽约心脏协会NYHA功能分级);病史(是否有90 d内心肌梗死史、是否血脂异常、是否糖尿病、是否高血压、是否既往心脏手术、是否肺动脉高压);术前用药(是否服用地高辛、是否服用倍他乐克、是否服用钙通道阻滞剂、是否服用阿司匹林、是否使用胰岛素、是否口服降糖药);实验室检查结果[红细胞计数、白细胞计数、血小板计数、中性粒细胞百分比、淋巴细胞百分比、红细胞比积测定、血红蛋白、活化部分凝血活酶时间(activated partial thromboplastin time,APTT)],国际标准化比值(international normalized ratio,INR),血浆纤维蛋白原,丙氨酸氨基转移酶(alanine aminotransferase,ALT),天冬氨酸氨基转移酶(aspartate aminotransferase,AST),总蛋白,白蛋白,总胆红素,直接胆红素,血糖,血清肌酐,尿素氮、钾、钠、氯。2)从体外循环记录和麻醉信息管理系统中提取术中变量:手术类型、手术时间、体外循环时间、失血量、输血量、尿量、晶体胶体输注量、术中血流动力学变量、术中是否使用血管活性药物、是否除颤、是否置入临时起搏器。此外,计算每名患者的欧洲心脏手术风险评分Ⅱ(Euro SCOREⅡ;http://www.euroscore.org/calc.html)和肌酐清除率。
肌酐清除率(mL/min)=(140-年龄)×重量(kg)×(0.85,如果是女性的话)/[72×血清肌酐(mg/dL)]。
3 终点事件 CSA-AKI是终点事件,其定义根据2012年改善全球肾病预后组织(Kidney Disease:Improving Global Outcomes,KDIGO)指南(https://kdigo.org/conferences/nomenclature):当术后7 d内血清肌酐水平大于术前水平1.5倍或术后48 h内血清肌酐较术前提高0.3 mg/dL时即可诊断为发生CSA-AKI事件。因KDIGO中关于AKI的尿量诊断标准在回顾性研究中的不准确性,因此未予考虑。
4 数据预处理 在数据分析之前进行了以下数据预处理:1)进行数据清洁以识别缺失值、异常值和重复项,缺失值采用平均值进行插补。2)特征选择和提取:在数据集中识别那些对预测模型构建最有用/最相关的特征(特征选择)或特征的组合(特征提取)。
5 模型的构建及验证 数据集由638例患者、78个变量构建而成。将整个数据集按8∶2的比例随机分成训练组和测试组。80%的训练数据集用于不同机器学习模型的构建。在建模过程中,使用网格搜索和5折交叉验证优化模型的超参数(为避免模型的过拟合现象,整个训练集随机分为5个迭代、5个相等尺寸的子集。在每次迭代时,1个子集用作测试数据,其余的4个子集用于进行训练)。此外,余下的20%测试集行进一步内部验证,以确定预测性能并识别最佳预测因子。采用支持向量机(support vector machine,SVM)、决策树(decision tree,DT)和随机森林(random foresst,RF)这3个机器学习算法来构建CSA-AKI事件的预测模型。使用ROC曲线中的AUC值、敏感度、特异性和准确率作为模型的预测效能评价指标。决策曲线分析(decision curve analysis,DCA)图用于展示模型的临床使用价值。此外,沙普利可加性特征解释方法(shapley additive explanation,SHAP)用于模型的可视化处理。
6 统计学分析 数据分析使用Python 3.6和Scikitlearn(https://scikit-learn.org)包进行。连续变量均呈非正态分布,以Md(IQR)表示,其比较采用Mann Whitney-U检验;分类变量以例数(百分比)表示,其比较采用χ2检验,P<0.05为差异有统计学意义。
结 果
1 患者特征 纳收的638例患者在术后7 d内,188例(29.5%)出现了CSA-AKI事件。相比非AKI组,AKI组年龄更大(P<0.001),Euro SCOREⅡ评分更高(P<0.001);AKI组合并症比例更高(P<0.05)。同时,AKI组患者失血量更多(P<0.001),术中尿量更少(P<0.001),手术时间更长(P<0.001),接受更多的治疗措施,如输注悬浮红细胞(P<0.001)、血小板(P<0.001);此外,AKI组患者血红蛋白和肌酐清除率更低,尿素氮更高(P<0.001)。见表1。
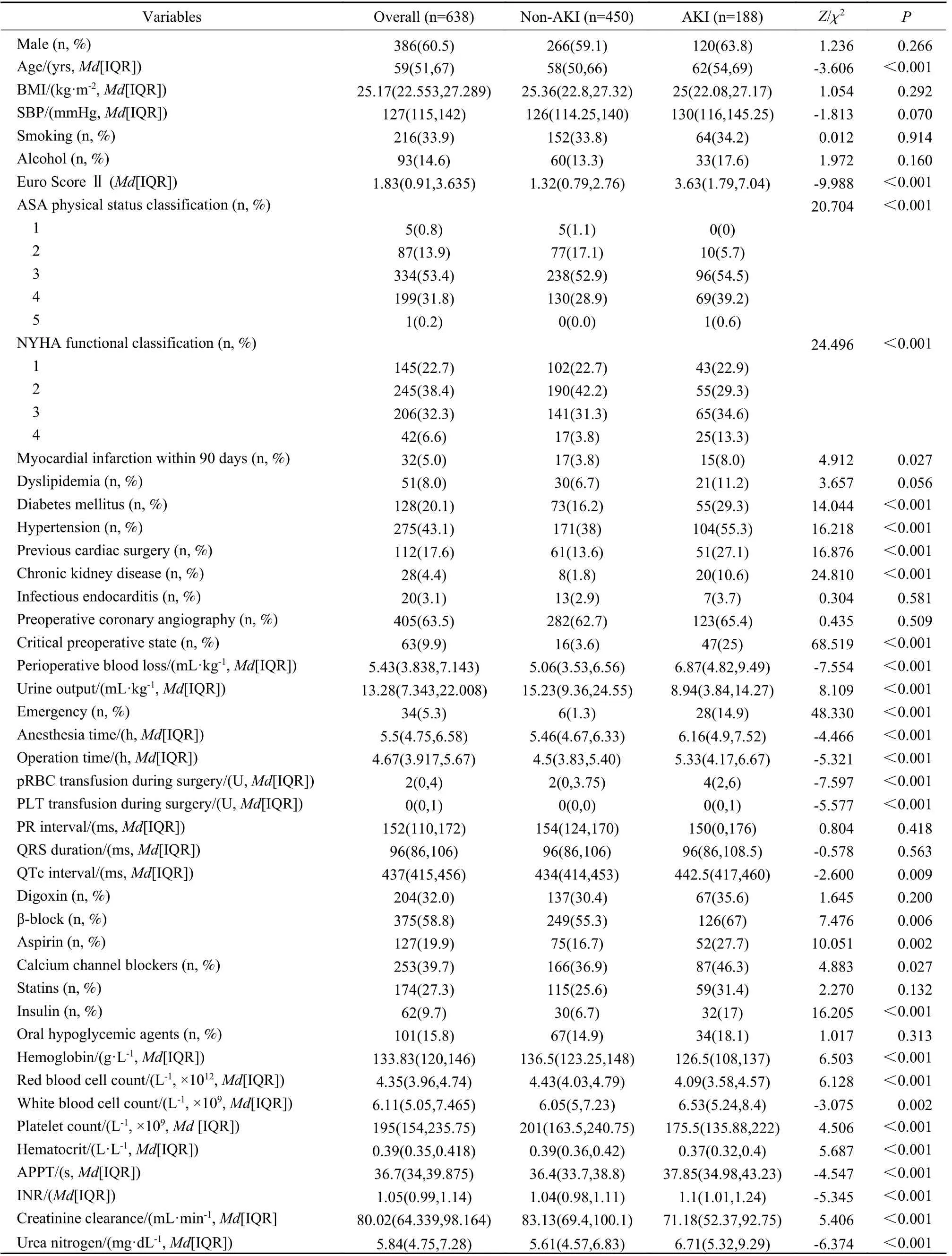
表1 患者一般特点和围术期变量Tab. 1 General characteristics and perioperative variables of the patients
2 模型效能 针对CSA-AKI风险预测所构建的3类机器学习模型中,RF模型在预测效能方面其受试者工作特征曲线的AUC数值为0.890(95%CI:0.762~1.000),敏感度为0.784,特异性为0.934,准确率为0.927,优于另外两个预测模型(图1、表2)。采用DCA曲线测试不同风险概率阈值下3个模型的临床适用性和净获益,结果表明,3个模型都有很高的临床净获益,其中RF模型表现最优(图2)。

表2 各个模型的预测性能Tab. 2 Predictive performance for each model
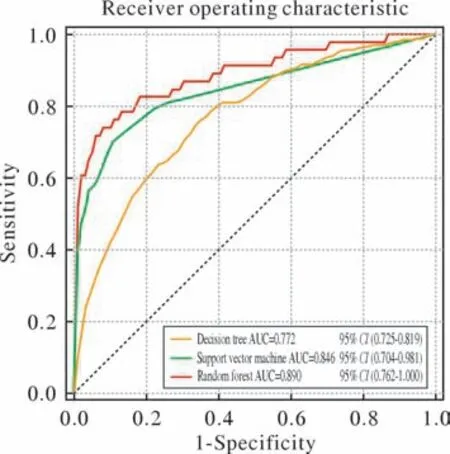
图1 随机森林、支持向量机和决策树预测模型的受试者工作特征曲线Fig.1 Receiver operating characteristic curves for predictive models of random forest, support vector machine and decision tree

图2 随机森林、支持向量机和决策树预测模型的决策曲线分析Fig.2 Decision curve analysis for predictive models of random forest, support vector machine and decision tree
3 预测CSA-AKI的主要危险因素 使用SHAP值来进行RF模型中特征贡献度分析和模型可解释性。图3展示了SHAP条形图中基于SHAP平均值从大到小排序前20名的特征及其对模型输出的平均影响幅度。结果表明,显著影响模型运行的10大变量依次是肌酐清除率、血红蛋白、手术时间、射血分数、术中尿量 、左房直径、手术权重、血清肌酐、术中失血量和体外循环时间。在这20个变量中,有6个变量(手术时间、术中尿量、手术权重、术中失血量、体外循环时间和术中使用血管活性药)为术中变量。图4显示了在RF模型中发生和未发生CSA-AKI事件在个体水平中的预测分析过程。在发生CSA-AKI事件患者中,起主要促进作用的是低肌酐清除率、低血红蛋白和高体质量指数,而起主要保护作用的是高射血分数。在未发生CSA-AKI事件患者中,起主要保护作用的是高血红蛋白值和高射血分数,而起主要促进作用的是高血清肌酐值。

图3 随机森林模型的前20变量矩阵图Fig.3 The top 20 variables matrix of the random forest model
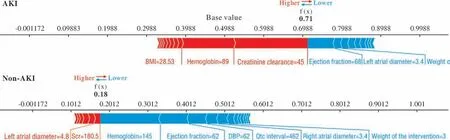
图4 SHAP在2例正确预测为AKI和非AKI患者中的特征重要性度量Fig.4 SHAP feature importance metrics for 2 patients that were correctly predicted as AKI and non-AKI
讨 论
在此回顾性队列研究中,我们使用78个术前和术中变量开发和验证了机器学习算法以预测CSA-AKI事件。由机器学习方法建立的模型可以基于所有患者的数据集来实现早期动态监测,节省了临床医生的时间[9]。人工智能(AI)与机器学习在临床医学的研究方面已获得诸多青睐,如用于评估患者术后结果[10]、预测低血压[11]和麻醉深度[12]。此外,机器学习也已应用于重症监护医学[13]、急诊医学[14]和神经医学[15]。随着电子健康记录在大数据领域的扩展,大量的电子健康记录数据和人工智能的交融促使机器学习在AKI临床研究中发挥着越来越重要的作用,且目前已成为AKI诊断和预测的有效工具[16]。
在一篇运用XGBoost机器学习算法构建的CSA-AKI风险模型报道中,模型的最佳AUC为0.78(95%CI:0.75~0.80)[17]。该研究表明,在心脏手术后预测AKI,机器学习模型的性能显著优于传统的逻辑回归模型(AUC=0.69,95%CI:0.66~0.72)。先前的风险评分模型的AUC通常仅为0.55,这可能是由于以往评分模型中纳入的变量集较少以及数据集中缺乏术中变量[17]。本研究中运用了3种机器学习算法,其中RF模型表现出模型预测的最佳性能,其敏感度为0.784,特异性为0.934,准确率为0.927,AUC为0.890(95%CI:0.762~1.000),DCA图中的结果也说明了模型具有较好的临床运用价值。此外,所构建的模型不仅基于术前变量,手术相关的变量也纳入分析,以此来确保模型更符合患者的实际情况。在SHAP变量重要性基质图中,前10个特征中一半是术中特征,这意味着术中条件对心脏手术后早期肾功能下降有重要影响。不同于先前强调了术前条件的预测模型,本研究证明了在CSA-AKI手术中反映患者急性生理反应的术中变量的价值。CSA-AKI的病理生理学可以解释为什么术中特征对AKI预测是如此至关重要。虽然AKI发病机制未完全阐明,但已知肾低灌注是由低流量、低压和血液稀释产生。此外,体外循环引起的快速核心体温降低,出血并发症和炎症反应在CSA-AKI发生发展中都发挥重要作用。
在本研究中,根据2012年KDIGO标准定义的CSA-AKI在术后7 d内的发生率为29.5%,其结果与先前报道一致[18]。CSA-AKI的发生与一系列风险因素有关,其发生发展不仅受到年龄、性别和合并症等人口统计特征的影响,还与手术类型、液体超滤体积、是否体外循环等围术期因素有关[19]。本研究不仅鉴定了与以前使用的风险评分模型相同的几种风险因素,如术前血红蛋白、肌酐清除率、手术时间、左心室射血分数、体质量指数和高血压[20-23],还鉴别了被传统评分模型忽视的重要风险因素,如术中尿液输出量、失血量、术中使用血管活性药、左心房直径和手术权重。鉴于此,机器学习开辟了新的生物标志物的可能性,这有利于理解疾病发病机制和指定新的干预路径。值得注意的是,一些众所周知的风险因素在本研究中的前20个特征中没有排名,如手术类型和成分血的输注。
肌酐清除率和血红蛋白被确定为CSA-AKI分类的最重要因素。血红蛋白水平与AKI之间的关系已被广泛研究,低水平的血红蛋白和贫血的存在成为AKI的独立危险因素[24]。既往的研究表明,血红蛋白与AKI呈负相关,即术前血红蛋白水平越低,越容易患AKI[25-26]。本研究中AKI组较非AKI组的血红蛋白水平更低也验证了这一结论。此外,既往报道肌酐水平较高的患者更易发生AKI[27]。此结论也与本研究结果一致。
本研究也有一定的局限性:1)研究分析仅使用单中心数据,病例相对较少。机器学习算法的性能可能因具有不同分布的患者特征和不同机构的较大数据集而不同。因此,需要外部验证以防止过度拟合。2)由于数据集的建立是由医师手动实现的,因此某些隐藏的变量关系可能由于医师认知的局限性而丢失。3)目前尚不清楚所构建的风险预测模型在临床实践中是否可以转化为患者的实际临床益处,因此尚需要前瞻性、多中心研究来评估。
综上所述,我们建立了心脏手术后预测AKI的机器学习方法,可用于手术后个体罹患AKI的风险预测。本研究结果显示术中变量对于AKI预测至关重要。随着研究的不断深入,基于机器学习的患者实时监测系统或将辅助临床医师提供有价值的临床决策支持,并减少CSA-AKI相关的死亡率和发生率。其不仅可以揭示预测因子之间的复杂关系,而且还评估术后患者CSA-AKI事件的发生风险。它将促进医生识别风险较高的患者,采取保护策略,从而改善患者的预后。
利益冲突声明:无。
