基于DBSCAN_GAN_XGBoost的网络入侵检测方法
2022-04-29汪祖民王冬昊邹启杰
汪祖民,王冬昊,梁 霞,邹启杰,秦 静,高 兵
(1.大连大学 信息工程学院,辽宁 大连 116622;2.大连大学 软件工程学院,辽宁 大连 116622;3.辽宁轻工职业学院 信息工程系,辽宁 大连 116100)
0 引言
物联网的普及使更多的新用户、新设备不断地连入网络[1]。由于保护个人信息的需要,对网络安全的需求也在快速增长。因此,网络入侵的防御与检测已经成为网络安全管理系统中的重要组成部分[2]。随着机器学习与深度学习技术的不断成熟,二者在网络入侵检测中更加重要。然而,在网络流量中通常存在着严重的数据不平衡问题[3],即异常数据流量远小于正常数据流量,同时各类别所占的数据比例分布不均匀[4],这就使得分类器的学习性能和准确率显著下降。
为解决网络入侵检测中数据不平衡问题,众多学者对其进行了深入研究,主要通过数据生成和特征处理2种方式来提升网络入侵检测的检测精度。在数据生成方面,王磊等[5]将K-means算法与加权随机森林结合,引入欧式距离作为欠采样时分配样本个数的权重依据,算法在面对不平衡数据时具有较好的稳定性。高忠石等[6]提出了一种基于PCA-LSTM(principal components analysis long short term memory)的入侵检测方法,该方法着重提高了小样本数据集的检测精度,但在面对大量样本的检测时性能较差。张仁杰等[7]通过聚类法对数据集进行划分,使用变分自编码器对划分出的边界样本进行扩充,比原始样本检测精度提高了20.9百分点。王垚等[8]提出了一种新的过采样方法,通过计算实例硬度,准确识别难以正确分类的样本。通过聚类算法结合实例硬度识别安全区域,并依据统计学最优分配原理进行过采样,从而有效提高了分类器的分类性能。
在特征处理方面,李小剑等[9]将堆叠稀疏自编码网络和加权极限学习(weighted extreme learning machine,WELM)进行融合,再以WELM作为集成算法(AdaBoost)的基础分类器来解决高维海量数据的类别分布不均衡问题,准确率达到93.83%。冯英引等[10]提出了一种类别重组技术结合FocalLoss损失函数的处理方法,对原始网络入侵流量分类,该方法提高了入侵检测中的稀有类样本的准确率。王荣杰等[11]从数据集划分算法和集成规则2个角度入手提出一种新的集成分类算法,有效提高了分类精度,但稳定性较低。徐雪丽等[12]将卷积神经网络(convolutional neural networks,CNN)和支持向量机(support vector machine,SVM)结合,极大地提高了学习速度和泛化性能,但对于海量不平衡数据的检测速度较慢。徐伟等[13]提出了一种先采用人工蜂群(ABC)算法进行特征提取,再通过XGBoost算法对特征进行分类和评价的方法,该方法能够准确地对不同攻击类型进行分类,但同样在面对海量高维不平衡数据时,检测精度略有下降。梁杰等[14]使用独热编码将数据集中的网络流量数据进行编码降维后再通过卷积神经网络进行特征学习,准确率达到99%以上,但在对攻击类别的样本识别上表现较差。
在上述研究中,模型普遍在二分类表现突出,而在面对海量不平衡数据和稀有类攻击样本时表现欠佳。因此,本文通过深度学习和机器学习结合的方式,提出一种基于DBSCAN_GAN_XGBoost的网络入侵检测模型来解决现有问题。在扩充稀有攻击类样本时,着重扩充特征不明显的离群样本,以保证分类器可以充分学习离群样本,提高分类模型在面对不平衡数据时的检测精度。
1 基于DBSCAN_GAN_XGBoost的入侵检测方法
本文针对入侵检测数据集中样本数据不平衡、无法使分类器充分训练而导致的检测精度不高的问题,提出了一种基于DBSCAN_GAN_XGBoost的入侵检测模型,如图1所示,具体步骤如下。
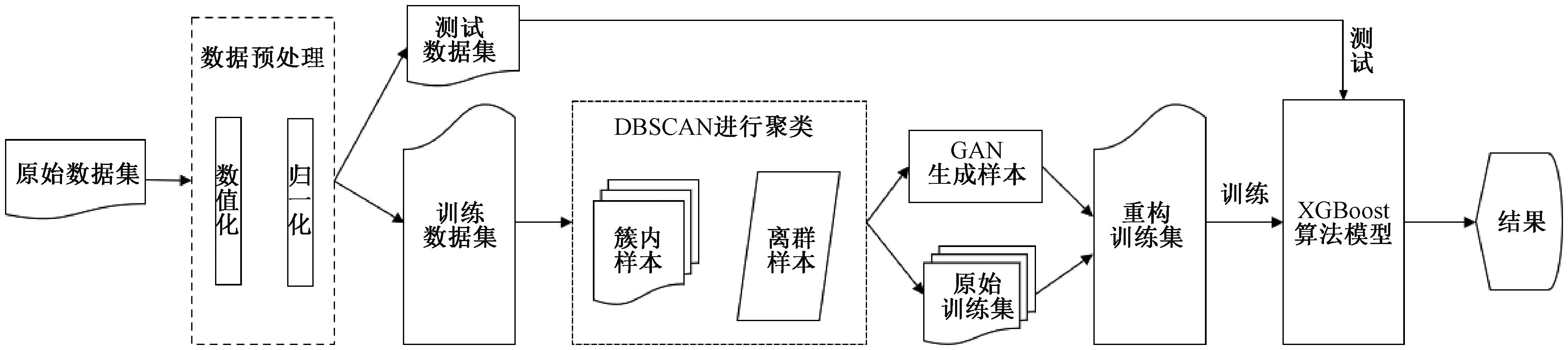
图1 DBSCAN_GAN_XGBoost模型
步骤1数据预处理。将数据集中的数据进行数值化、归一化处理,再将处理后的数据集按7∶3的比例进行数据划分,提取出训练集中的稀有类攻击样本。
步骤2DBSCAN噪声样本提取。采用DBSCAN对提取出的稀有类攻击样本分别聚类,划分成离群样本和簇内样本,分别提取游离在簇外的噪声样本和簇内样本。
步骤 3GAN样本生成。采用生成对抗网络对各稀有类数据样本中的簇内样本和噪声样本进行数据扩充,使其在数据集中比例均衡,并保证其样本内部的多样性。
步骤4XGBoost集成分类器样本检测。将GAN生成后的数据样本与原始训练集合并成为新的训练数据集,训练得到最优分类模型,并采用测试集完成对网络异常流量的检测。
1.1 数据预处理
(1)对字符型特征数值化。首先将UNSW-NB15数据集中的字符型特征与标签转换为数值型。训练集和测试集中proto、service、state字符型数据表示为数值型。以service为例,该属性共包括13个变量,用1~13依次表示13个变量。类别标签Normal、Backdoor、Analysis等转化为数值表示:Normal表示为1,Backdoor表示为2,Analysis表示为3,以此类推。
(2)归一化处理。由于各个特征属性之间的数值相差较大,故对所有特征进行数值归一化处理。采用min-max方法将数据集中不同特征的取值转换到[-1,1]中,不改变其原始信息。转换表达式为
(1)
1.2 DBSCAN样本提取
网络入侵检测中对稀有攻击类型样本进行样本扩充时,通常直接对提取出的稀有类数据进行过采样。该方法只平衡了不同类别样本数量差异,忽略了样本内部的不同,即同一种攻击类型数据也会有不同的攻击特征,如果将数据集中稀有攻击类数据提取后直接送入生成模型中进行训练,那么训练后依然会有分布在原始样本边缘的噪声样本,且噪声样本的数量较小,无法使分类器得到充分学习,进而影响分类器的泛化能力和多数类样本分类的准确率。本文在对稀有攻击类样本进行样本扩充前,先将稀有攻击类样本进行聚类,分离出簇内样本和噪声样本。相较于其他聚类算法,基于密度聚类的DBSCAN算法能够有效处理任意形状的聚类,通过将簇定义为密度相连点的最大集合,在样本内将具有高密度的区域划分为簇,有效分离出样本内的不同簇与噪声样本。
传统的DBSCAN[15]算法使用欧式距离来计算两点间的距离是否小于设置的邻域值,但在面对实际的入侵检测问题时,数据集内的各个特征重要性不同,从而导致各特征维度对簇结构的作用程度不同。因此,本文在计算欧式距离时引入每个特征维度的权重,使邻域内的密度点可以有效避免噪声维度对聚类精度的影响。加权的欧式距离为
(2)
模型首先使用XGBoost算法对样本的特征权重进行计算,赋予每个特征维度一个权重值。接着随机选取样本A,计算样本A到训练集中其他样本点的加权欧式距离,根据邻域大小和最小样本数检索样本A的所有密度可达点。如果样本A是一个核心点,此过程就产生一个关于样本A的簇;如果样本A是一个边界点并且样本A没有密度可达点,将访问下一个样本。每个簇由样本相关性高的样本聚集在一起,使用DBSCAN对分离出的稀有攻击类样本进行聚类,通过调整核心点周围邻近区域的半径和邻近区域内最少包含样本数,使样本划分为离群样本和簇内样本。
1.3 GAN稀有类样本扩充
数据集中的稀有攻击类样本在经过DBSCAN算法处理后,获得样本间相关性高的簇内样本和容易与其他攻击类型产生混淆的噪声样本。接着使用生成模型对其进行样本扩充。
目前,在数据生成阶段主流的生成模型为变分自编码器(variational auto-encoders,VAE)和生成对抗网络(GAN),然而变分自编码器生成的样本要尽可能与原样本相似,并不能生成多样化的样本。在实际的入侵检测问题中,如果生成的样本与原样本相同,那么就会因同一攻击类型样本单一、缺乏多样性造成分类器的学习不充分,容易产生过拟合。与VAE非黑即白的判别方式不同,GAN通过生成器和判别器的共同进步,使得生成的样本具有多样性,并且GAN的生成效果要优于VAE,所以本文采用生成对抗网络对聚类后的样本进行样本扩充。
生成对抗网络是Goodfellow等[16]基于零和博弈理论,通过生成模型和判别模型交互博弈而提出的一种新的生成模型,如图2所示。
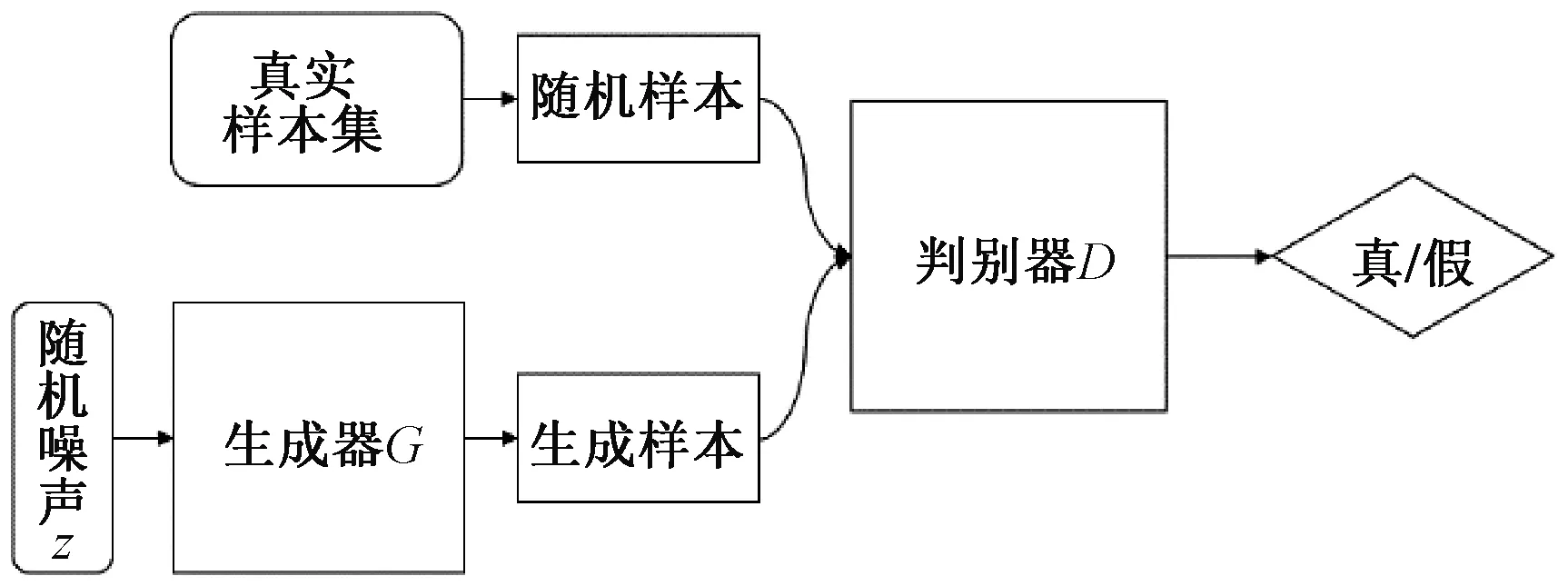
图2 生成对抗网络
在训练过程中,生成器不断提升伪造数据欺骗判别器,而判别器努力学习区分真假数据的能力。二者不断迭代优化,最后达到动态均衡。生成器最终完成数据扩充并生成仿真样本,整个模型的目标函数为
min maxV(D,G)=Ex~Pm[ln(D(X))]+
Ez~Pz[ln(1-D(G(z)))]。
(3)
式中:D(x)为判别器辨别从训练集中抽取的簇内样本为真的概率;1-D(G(z))为判别器辨别由生成模型生成的簇内样本为伪造样本的概率;x~Pm为x取自训练数据中簇内样本的分布;z~Pz为z取自生成模型G生成簇内样本的数据分布;V(D,G)为损失函数,优化D(X)时就让V(D,G)最大,优化G(X)就让V(D,G)最小,最终求出最优解的生成模型。
1.4 XGBoost分类器
XGBoost[17]在梯度提升的基础上改善了目标函数的计算方式以提高模型精确度,同时在训练数据前,预先对数据进行排序并保存,以便在之后的迭代中重复使用,降低了模型的计算量,可以较好地解决网络入侵检测在面对海量高维度数据时的检测精度和速度问题。XGBoost的目标函数Obj为
(4)
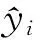
(5)
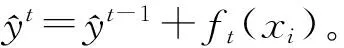
(6)
然后,再利用ft=0处的泰勒二阶展开式找到使ft最小化的目标函数,去除常数项并优化损失函数项,即
(7)
式中:gi为一阶导数;hi为二阶导数。
(8)
(9)
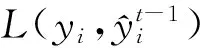
(10)
此时目标函数为关于叶子节点分数wj的一元二次函数,求最优解并将其代入到目标函数中,如式(11)所示:
(11)
2 实验与分析
2.1 实验数据
本文使用UNSW-NB15数据集[18]对模型进行验证。该数据集是真实的网络正常行为和网络流量攻击的混合体,能够较全面地反映当前网络流量的多样性和现代低足迹攻击。数据集中包含了大量低使用率的入侵攻击和深度网络流量信息。该数据集共有257 673个样本,包含正常数据Normal和9种攻击类型:Fuzzers、Analysis、Backdoor、DoS、Exploit、Generic、Reconnaissance、Shellcode和Worms。每1条数据都是由47维特征、多分类标识符、二分类标识符组成。数据集分为训练集(175 341个样本)和测试集(82 332个样本),各类数据分布见表1。
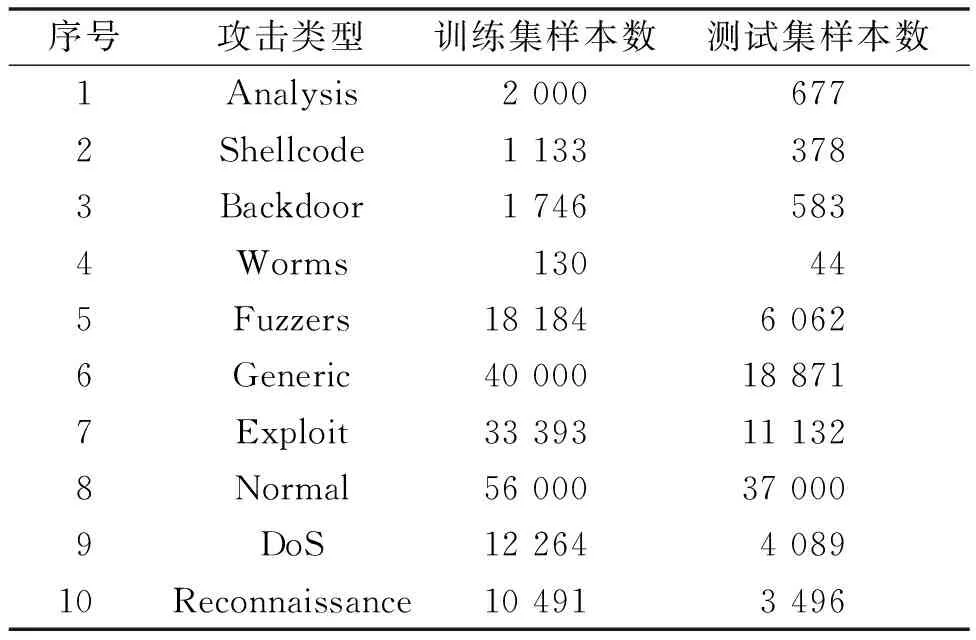
表1 UNSW-NB15数据集各类数据分布
2.2 实验参数设置
基于密度的聚类算法将样本中的高密度区域划分为簇,每个簇看作是样本空间中被噪声分隔开的稠密区域,从而解决了挖掘数据时对簇的形状要求单一的问题。DBSCAN算法通过对eps和minPts的设置可以发现任意形状的簇类。eps表示每个核心点的邻域中样本间的最大距离,如果样本间的最大距离小于或等于eps,那么将样本划分为同一类别,eps越大产生的簇就越大,包含的样本点就越多。minPts表示一个邻域半径内最少样本的数量,minPts越低,算法则会建立更多的簇与噪声样本。在一定程度上,minPts数越大产生的簇就越健壮。为了确保样本间的相似性,避免同类样本生成过多子簇,本文经过实验对比不同参数的轮廓系数,得出稀有攻击类样本的eps、minPts参数设置如表2所示。
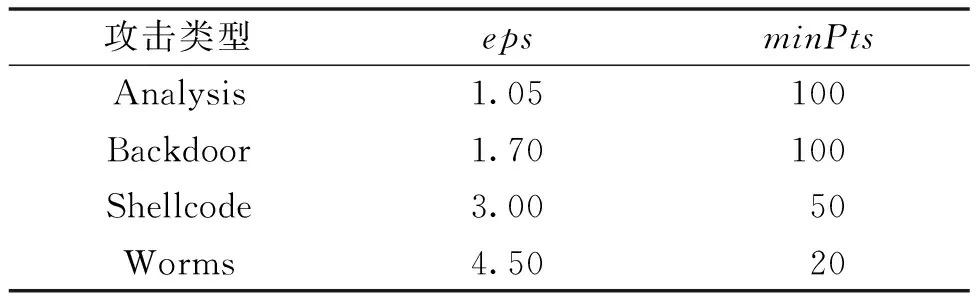
表2 各稀有攻击类eps、minPts参数设置
实验对DBSCAN算法分离后的少量攻击类样本使用GAN进行训练。以Analysis样本为例,Analysis攻击类型被划分为2个子簇和1份噪声样本,其数量分别为1 436、564、100。按照比例使用GAN算法生成新的样本并分别设置时期为100、批大小为40、学习率为0.000 2,生成新样本,其损失曲线分别如图3、4所示。由图3、4可知,当训练次数到达1 000左右,生成器和判别器模型开始收敛。
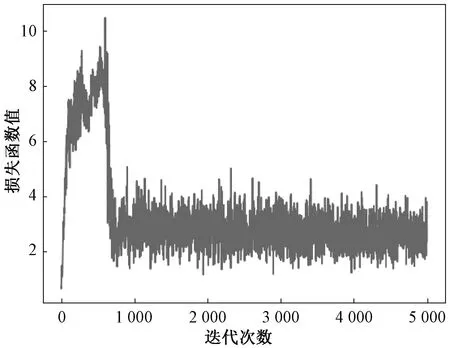
图3 生成器损失曲线
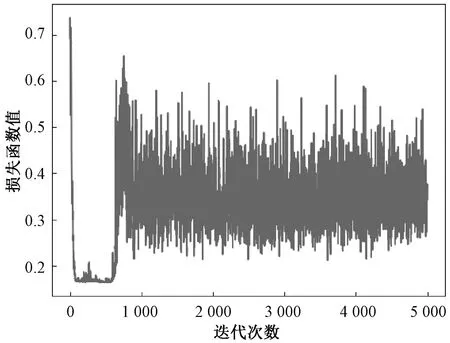
图4 判别器损失曲线
通过GAN算法将UNSW-NB15数据集中稀有攻击类型数据分别扩充到10 000,对比数据生成前后各个类别的数据量。如表3所示,采用GAN算法进行数据扩充后,数据集中的各类别样本比例更为均衡。
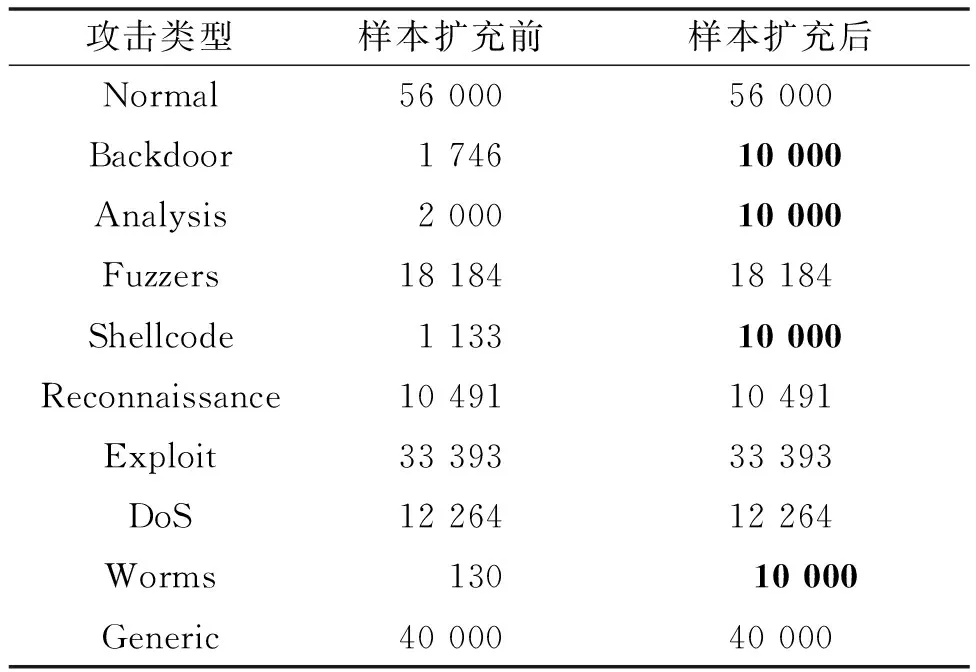
表3 样本扩充前后各类型数据量对比
使用样本扩充后的数据集对XGBoost算法进行多次实验,调优XGBoost参数。损失函数设置为Softmax,目的是把回归结果映射成最终的多标签分类。eta为每个迭代产生的模型的权重;max_depth为每棵树的最大深度,其值越大,模型的学习越具体,越容易过拟合。XGBoost的参数设置如表4所示。
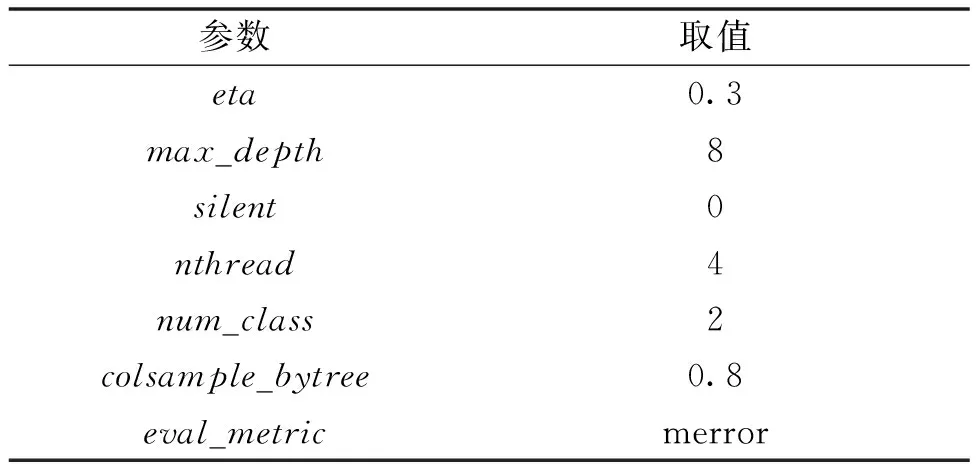
表4 XGBoost参数设置
2.3 实验结果及分析
分别使用原始训练集和重构后的训练集对XGBoost模型进行训练,并在测试集进行测试。如图5所示,模型的准确率和精确率分别为98.76%和96.50%,比样本扩充前分别提高了15.63百分点和19.60百分点。图6、7分别为模型对于稀有攻击类型数据在扩充前后的召回率和精确率对比。实验结果表明,对稀有攻击类型样本扩充后模型的召回率和精确率有显著提高。这是因为本文在对样本扩充时,着重扩充了特征不明显的离群样本,让分类器能充分学习此类样本,使模型能够更好地识别出稀有攻击类型数据的类别并且提高了稀有攻击类型数据的判别精度。
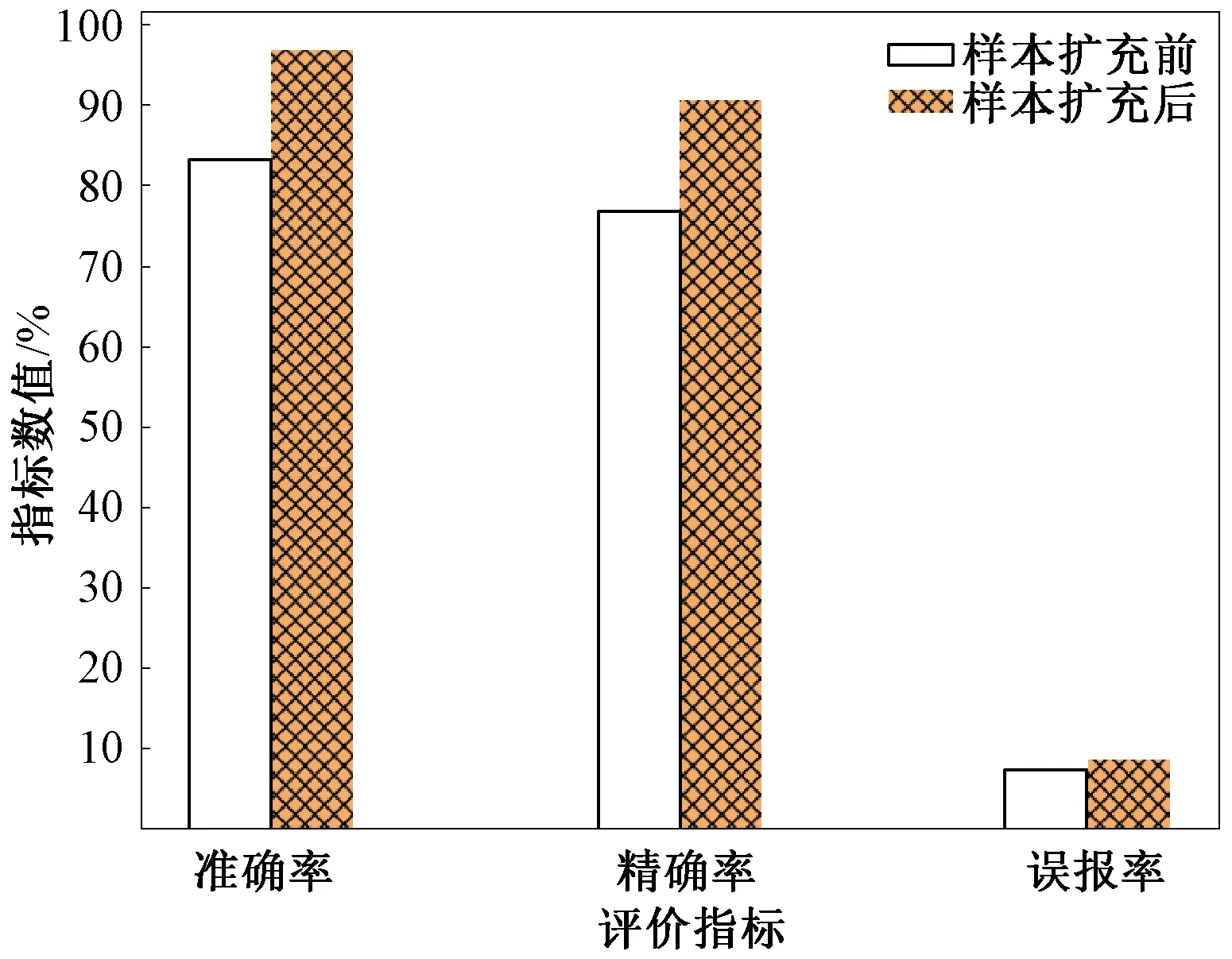
图5 稀有攻击类样本扩充前后评价指标对比
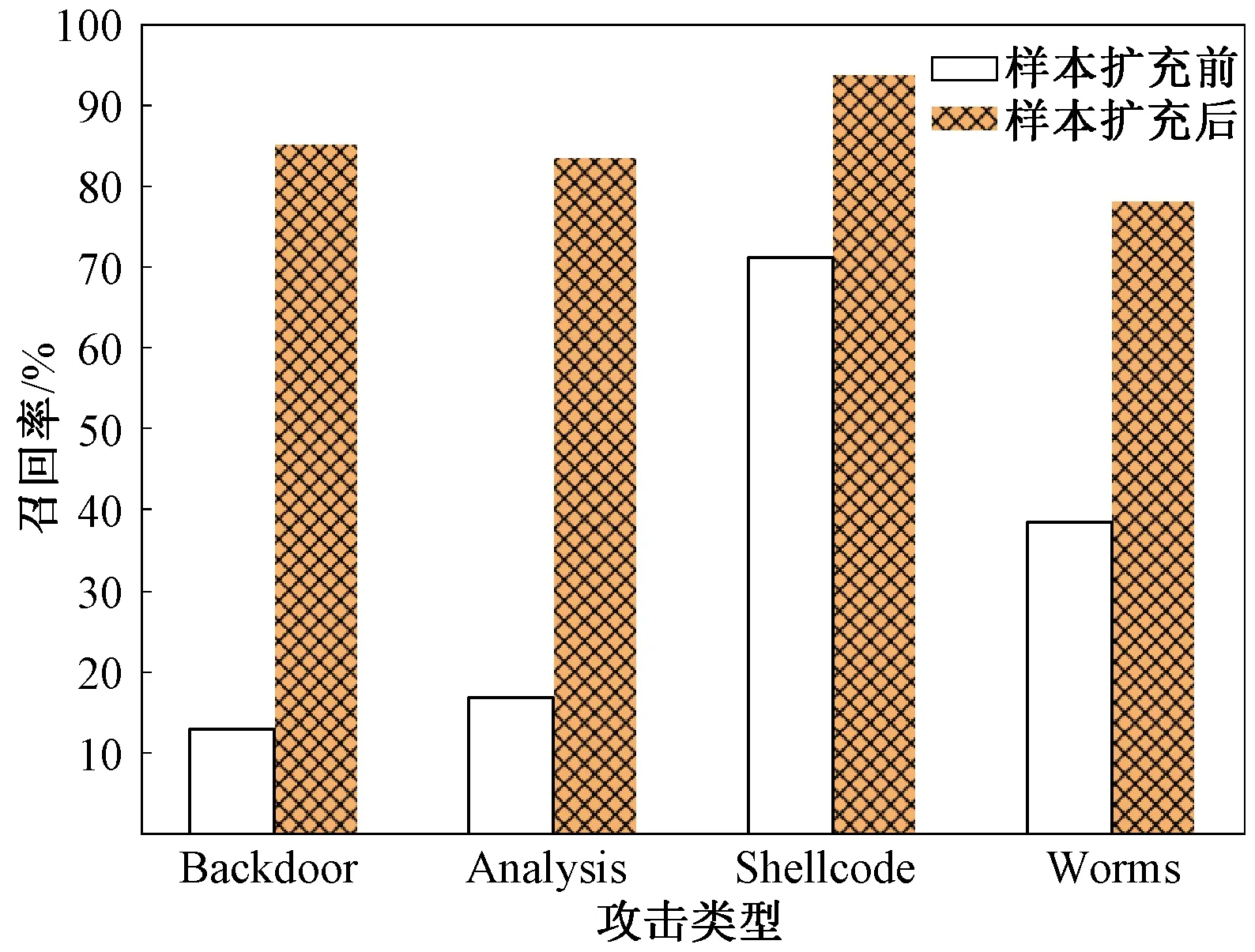
图6 稀有攻击类样本扩充前后召回率对比
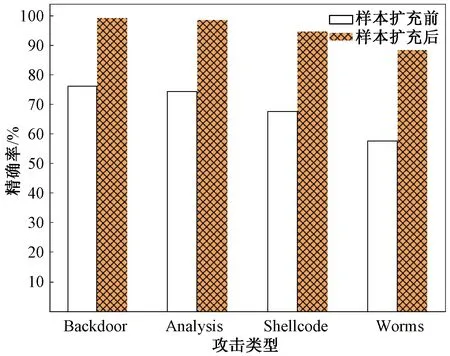
图7 稀有攻击类样本扩充前后精确率对比
如表5所示,样本扩充后,稀有攻击类型Backdoor、Analysis、Shellcode和Worms的召回率均提升显著。攻击类型Backdoor、Analysis在数据生成前的召回率都普遍较低,这是因为数据数量占比低,数据得不到充分学习,从而导致其行为难以检测,召回率低。分别对稀有攻击类的数据样本和噪声样本进行扩充,提高稀有攻击类别的占比,使稀有攻击类样本能够充分被分类器学习,提高其召回率。
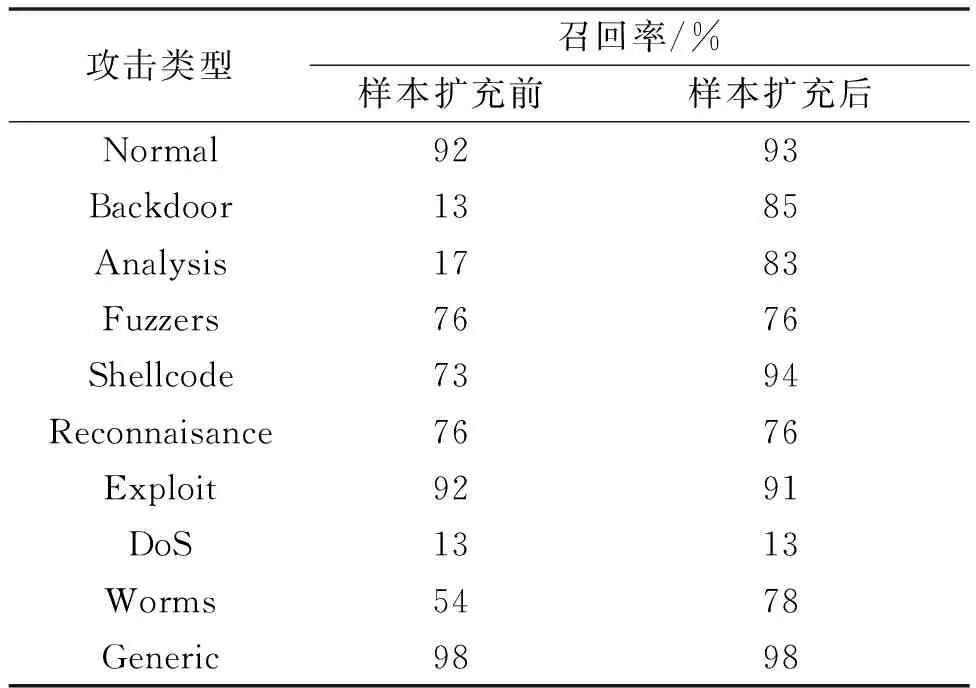
表5 样本扩充前后各类型召回率对比
本文方法与其他方法的检测率对比如表6所示。文献[14]利用CNN(convolutional neural network)对独热编码处理后的原始网络包进行提取,对部分大样本攻击类型检测精度达90%以上,但在面对小样本攻击类型时检测精度大幅下降。
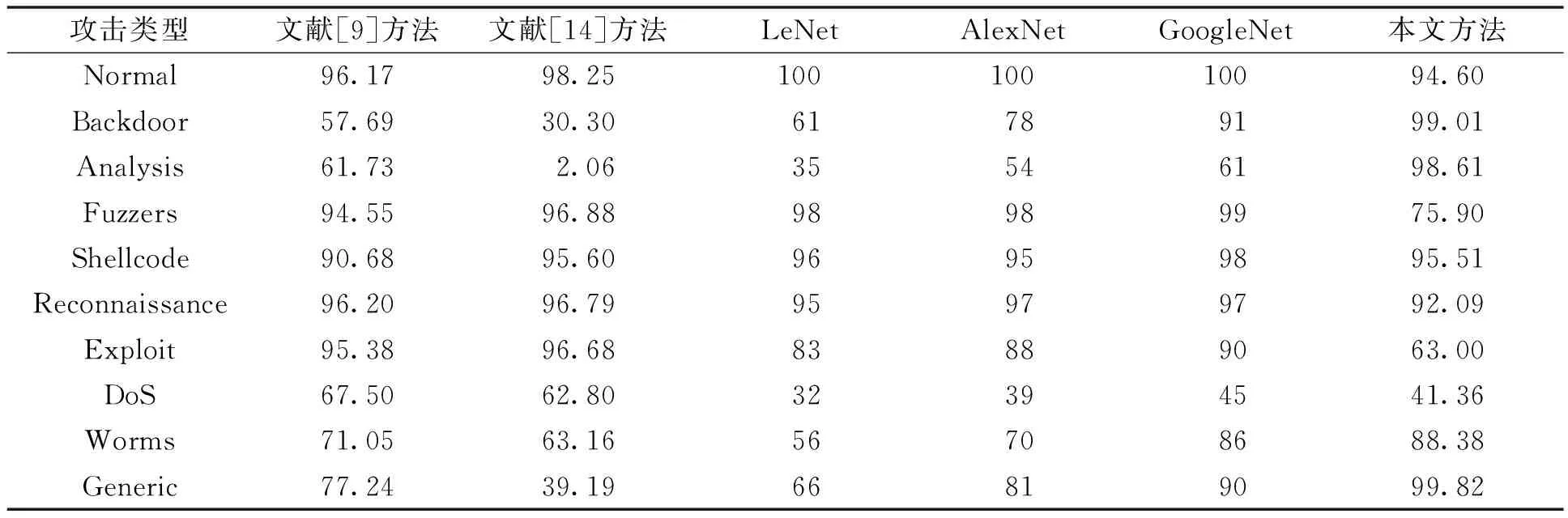
表6 不同类别数据检测率对比
通过实验结果分析可知,本文通过提升Backdoor、Analysis、Shellcode、Worms稀有攻击类型数据占比,将稀有攻击类型数据的检测率分别提高至99.01%、95.61%、95.51%和88.38%,证明本研究方法在网络流量的检测上对稀有攻击类型有较好的检测精度,特别是在Backdoor和Analysis上有较大幅度的提升。同时,文献[6]在多样本类别的检测率上均有所提高,这是因为文献[6]在特征维度重构时,丢弃了会影响模型特征学习和泛化能力的只含有IP头部信息的数据包以及空数据包内容,从而避免了数据集在训练过程中形成的特征干扰,提高了检测精度。此外,本文算法在Generic类别上有了较大提升,这是由于Generic与部分Exploit的攻击特性接近,且在文献[9-10,14]中Generic与Exploit数量相差较大,提升树在创建时学习不充分,导致较多的特征重要性较高的特征值被误判为Exploit攻击。
为了进一步验证DBSCAN_GAN_XGBoost算法的性能,将其与传统的机器学习和深度学习算法进行比较,结果如表7所示。由表7可知,经典机器学习算法DT(decision tree)、LR(logistic regression)检测效果均不理想;深度学习算法LSTM(long short term memory)和DBN(deep belief networks)的检测效果均优于DT和LR。相比于其他算法,本文的DBSCAN_GAN_XGBoost算法在准确率上平均提高了8.24百分点,误报率低于LSTM算法。综上所述,本文算法在入侵检测中表现较好。
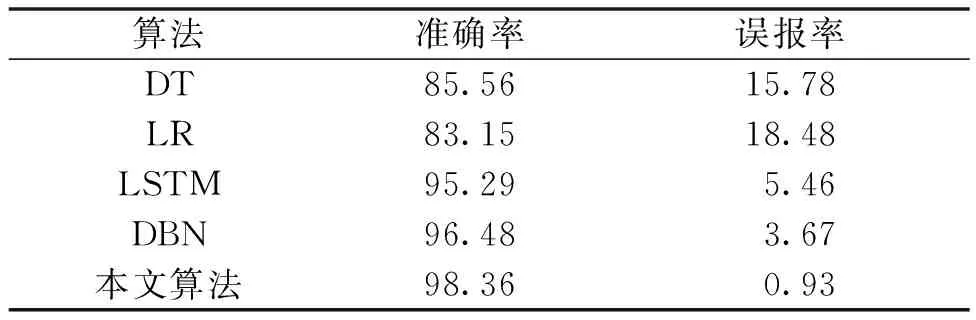
表7 算法的检测效果
3 结论
为了使网络入侵检测能更精准地辨别稀有类攻击类型,本文提出了一种基于DBSCAN_GAN_XGBoost的入侵检测模型。首先,模型将数据集中稀有类攻击样本通过加权密度聚类,分离出簇内样本和离群样本。然后,使用GAN算法对分离出的样本进行重采样,以确保生成的样本满足类别比例平衡的同时保证样本内部的多样性。最后,将重采样后攻击类别平衡的数据集输入到XGBoost分类器中进行训练和测试,并使用攻击类别更多且样本量丰富的UNSW-NB15数据集来评估模型的有效性。实验结果表明,本文模型在保证了多数类样本检测精度的前提下,对稀有类攻击类型的检测准确率和召回率提升显著。下一步考虑在此基础上使用多维优化的方法对入侵检测数据中数据量较多的攻击类型进行数据抽样,提升多数类样本攻击类型检测率,并在多个数据集上进行实验,从而更全面地验证所提算法的效果。
