基于CNN与BiGRU融合神经网络的入侵检测模型
2022-04-29张安琳张启坤黄道颖刘江豪李建春陈孝文
张安琳,张启坤,黄道颖,刘江豪,李建春,陈孝文
(1.郑州轻工业大学 工程训练中心,河南 郑州 450001;2.郑州轻工业大学 计算机与通信工程学院,河南 郑州 450001)
0 引言
入侵检测系统(intrusion detection system,IDS)中常见的深度学习方法[1-3]主要有多层感知器(multilayer perceptron, MLP)、卷积神经网络(convolutional neural networks, CNN)[4]、循环神经网络(recurrent neural network, RNN)、自编码器(autoencoder, AE)等。其中,循环神经网络又包含长短期记忆网络(long shortterm memory, LSTM)和门控循环单元(gated recurrent unit, GRU)2种变体。
Roy等[5]将MLP应用于入侵检测,并与支持向量机进行对比,精度有明显的提升,但在特征数量较多、维度较高的环境中,仅MLP通常难以得到良好的训练效果。Wang等[6]将处理过的流量数据转换成像素,利用CNN将流量数据以图片的形式进行输入和训练,得到较高的二分类准确率(100%)和多分类准确率(99.17%)。Naseer等[7]使用CNN、RNN和AE等不同神经网络架构来构建分类模型,实验结果表明,CNN和LSTM在入侵检测的分类中能够表现出良好的效果。Kim等[8]使用LSTM构建检测系统,在KDD-Cup99数据集上取得了96.93%的准确率,但误报率达到了10.04%。Putchala[9]提出在物联网领域使用GRU进行入侵检测研究,但实验仅在KDD-Cup99数据集上进行,未实现应用于物联网相关数据的设想。王伟[10]结合CNN和LSTM对流量数据进行学习,在CNN提取流量数据空间特征的基础上再使用LSTM提取数据的时序特征,得到了较高的精度并保持较低的误报率,但该方法在CNN特征提取时可能会损失部分数据信息的时间特性。研究表明,这些基于深度学习的入侵检测系统在处理大数据时性能更好[11],但仍存在一些问题。
(1)数据集过时。以往的入侵检测研究大多基于KDD-Cup99和NSL-KDD数据集,距今已有近20年历史,不能很好地反映当下网络状况。
(2)数据样本不平衡。分类研究通常更注重提升模型总体的评价指标,如准确率、精确率等,忽视了对少数类样本的分类问题。但在真实的网络环境中,这些少数类攻击会比多数类攻击产生更大的破坏和影响。然而,目前基于KDD-Cup99等数据集的研究通常都直接使用官方提供的训练和测试样本,较少有研究工作涉及入侵检测问题下的数据不平衡问题以及相关的解决方案[12]。
(3)特征学习不全面。以往的研究大多基于单种神经网络:CNN可以学习数据中的空间特征,精确地提取局部特征,但是学习不到时序特征;RNN可以对数据中的时序特征进行提取,分析信息的长期依赖关系,但是不能有效提取空间特征[13],且RNN只能学习数据单一方向的时序特征,没有充分考虑到流量数据前后信息对当前状态的共同影响。
1 基于CNN与BiGRU融合神经网络入侵检测模型
为了解决入侵检测研究中出现的上述问题,本文提出一种基于CNN与BiGRU(bidirectional gated recurrent unit)[14]融合神经网络入侵检测模型,结构如图1所示。本文模型主要由数据预处理模块和融合神经网络模块两部分组成,其特点有:
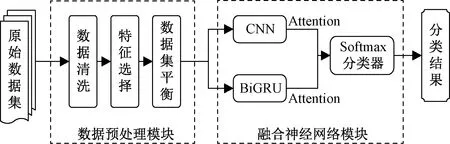
图1 基于CNN与BiGRU融合神经网络入侵检测模型
(1)使用2018年最新的入侵检测数据集CSE-CIC-IDS2018进行模型的训练和测试[15],该数据集包含最新的网络攻击,且满足现实世界攻击的所有标准[16]。
(2)对数据集进行清洗,并通过基于平均不纯度减少(mean decrease impurity,MDI)的特征选择算法进行特征优化降维,降低了计算机的资源消耗,提高了整体的计算效率。
(3)使用SMOTE-Tomek算法对数据集进行了数据层面的平衡处理,避免了使用一般过采样方法产生的过拟合、样本“入侵”以及模糊边界等问题。
(4)将一维数据转化为二维矩阵,使用CNN进行二维卷积,充分提取数据的空间特征;使用双向门控循环单元(BiGRU)进行数据时序特征的双向提取,充分学习数据的时间特征。
(5)引入注意力机制(attention mechanism, AM)进行特征加权,提高模型的整体性能。
1.1 数据预处理模块
数据预处理部分主要包括原始数据集的清洗、特征选择、数据集平衡等操作。数据集的清洗采用的是常规方法,限于篇幅,不再介绍。
1.1.1 特征选择
(1)无用特征删除。入侵检测系统应该根据流量信息的行为特征进行分类,避免偏向于特定标识所附带的信息,因此需要将涉及特定网络标识的特征删除;通过分析数据,将同一特征下数值相同的特征列删除。
(2)特征重要性。特征重要性用来评估数据特征对入侵检测系统分类的影响程度,用其Gini重要性来衡量,通过计算特征重要性评分VIM可以筛选出数据的重要特征,从而进行特征优化。
假设有m个特征X1,X2,...,Xm,要计算出每个特征Xj的Gini指数评分VIMj,即第j个特征在随机森林所有决策树中节点分裂“不纯度”的平均改变量,Gini指数用GI表示:
(1)
式中:K表示有K个特征样本类别;pmk表示节点m(将特征m逐个对节点计算Gini值变化量)中类别k所占的比例。
特征Xj在节点m的重要性,即节点m分枝前后的Gini指数变化量为
VIMjm=GIm-GIl-GIr。
(2)
式中:GIl和GIr分别为节点m左、右分支的新节点的Gini指数。
如果特征Xj在决策树i中出现的节点在集合M中,则第i棵树中特征Xj的重要性为
(3)
在有n棵树的随机森林中,特征Xj的重要性为
(4)
将特征重要性进行归一化处理,得到特征重要性评分:
(5)
所有特征的特征重要性评分之和为1,其特征重要性评分代表了该特征对数据分类的贡献大小。
1.1.2 数据集平衡
(1)SMOTE(synthetic minority over-sampling technique)算法。SMOTE算法是数据层面应用最广泛的过采样算法[17]。SMOTE算法有效解决了随机过采样方法产生的过拟合问题,SMOTE算法为解决数据不平衡问题提供了新的思路,但存在一定的局限性:SMOTE算法中根样本与辅助样本的选择决定了新样本的合成,然而在合成少数类样本时,忽视了多数类样本的分布情况。若根样本与辅助样本均处于少数类所在区域,则合成的新样本是符合要求的。但在实际运算中,如果根样本与辅助样本中有一个是噪声样本,那么合成的新样本将极有可能出现在多数类样本区域,出现合成的少数类样本入侵多数类样本空间的问题。此外,若SMOTE算法选定位于类边界的少数类样本合成新样本,且其k近邻样本也处于类的边界,那么经插值合成的少数类样本也同样会出现在两类的重叠区域,从而模糊两类的边界。
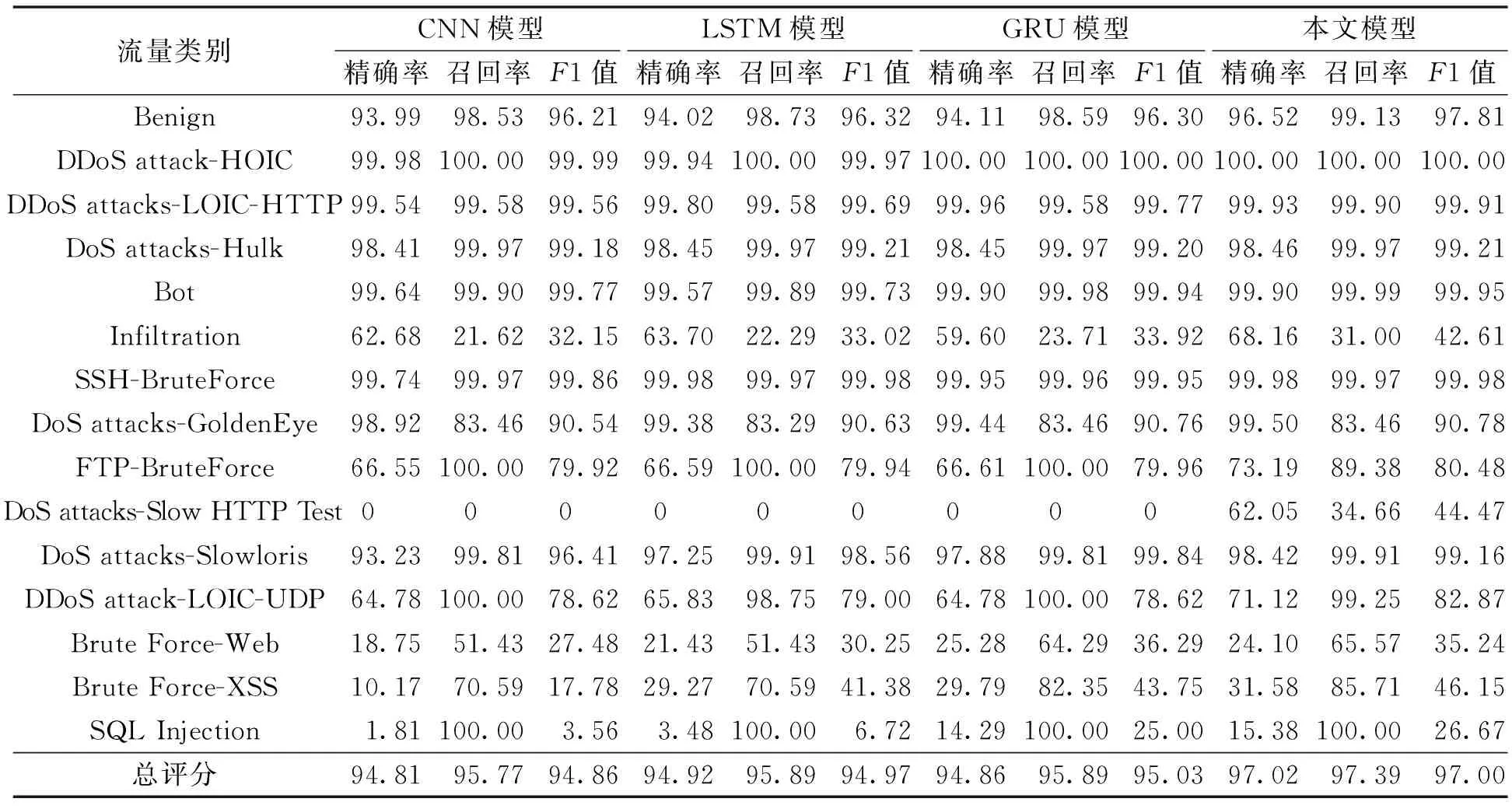
(2)Tomek Links算法。Tomek Links算法是一种数据欠采样算法[18],其基本原理:给定一些样本对(xi,xj),其中xi∈Smax,xj∈Smin,xi和xj的距离记为d(xi,xj)。若不存在任一样本xk使得d(xi,xk) 为解决SMOTE算法导致的样本入侵问题以及模糊边界问题,将Tomek Links算法和SMOTE算法相结合,称之为SMOTE-Tomek算法,来解决数据的不平衡问题。首先使用SMOTE算法对原始数据进行过采样操作来合成少数类样本,然后使用Tomek Links算法对经过SMOTE算法处理的数据进行清洗,移除数据集中存在的Tomek Links对,从而过滤掉两类之间的噪声数据和重叠样本。 融合神经网络模块主要由CNN、BiGRU、注意力机制以及分类器构成。在入侵检测的数据分析及特征提取中,既需要分析空间层面的特征联系,也应该考虑到时间层面上特征之间的变化规律。融合神经网络可以提取局部平行特征,同时能够分析各特征点前、后信息对该特征点的影响。CNN在图像处理上表现出更加优异的性能,因此,为了充分学习流量数据的空间特征,在使用CNN进行学习之前,将一维流量数据转化为二维矩阵进行输入,以便CNN将流量数据当作图像进行卷积处理。使用BiGRU代替普通的GRU,以一维文本数据格式进行特征提取,充分获取流量数据的双向时间特征。CNN和BiGRU在本模型中的实现见图2中对应部分,限于篇幅,本文不再展开介绍。 注意力机制[19]是对输入信息的加权求和,根据信息的重要程度确定权重。通过注意力机制可以充分挖掘数据的特征信息,提高分类的准确率[20]。本文CNN和BiGRU中分别添加相应的注意力机制进行特征加权,以提高模型的整体性能。注意力机制的运算过程:使用tanh函数对经过神经网络处理的隐藏状态序列ht进行非线性变换,得到ht的隐式表示ut。对ut进行加权处理,得到注意力权值αt。依据注意力权值对序列的隐含向量进行加权,得到最终流量的新特征向量v。 ut=tanh(Wtht+bt); (6) (7) (8) 式中:Wt、uw均为权重矩阵;bt为偏置量。 在CNN和BiGRU中分别引入注意力机制赋予特征权重,随后将两神经网络提取的特征信息进行融合,通过全连接网络进行处理,并通过Softmax分类器输出分类结果。本文构建的融合神经网络模型结构如图2所示。 图2 本文融合神经网络模型 这样一来,在入侵检测的特征提取中,既考虑了空间层面的特征联系,也考虑了时间层面上特征之间的变化规律。该融合神经网络利用CNN提取局部平行特征,同时利用BiGRU获取流量数据的双向时间特征,对长距离时间关联依赖特征进行特征提取,从而分析各特征点前、后信息对该特征点的影响。由于CNN与LSTM为并联处理关系,而非串联处理关系[10],这样就避免了文献[10]方法在最初的CNN特征提取时可能会损失部分数据信息时间特性的问题,并且可以得到较高的精度和较低的误报率,与文献[10]结果一致,从而较好地解决了单一神经网络特征学习不全面的问题。 实验采用的微型机处理器为Intel Core i5,内存为16.0 GB,显卡为GeForce GTX 1650,操作系统为Windows 10,编程语言为Python 3.5.4,框架为Keras 2.4.3,后端采用Tensorflow-GPU 2.2.0,实验利用CUDA(compute unified device architecture)进行GPU加速,加快模型训练。 2.2.1 数据集的数据清洗 CSE-CIC-IDS2018入侵检测数据集共有83个数据特征字段(又称为标签)和1个类别标签,共计84个标签。由正常流量(标签为Benign)和14种攻击流量构成,包含7种攻击场景。经过数据清洗的数据集流量类别分布如表1所示。 表1 数据集流量类别分布 2.2.2 特征选择 CSE-CIC-IDS2018入侵检测数据集中每个数据包括84个特征字段[15]。在实际入侵检测系统运用中,数据集中包含冗余特征,使用时会增加计算工作量、降低检测速度、影响入侵检测的泛化性。入侵检测系统应该根据网络流量的行为特征进行分类,不应偏向于IP地址等具有特定网络标识的信息,因此预处理过程中删掉了Flow ID、Src IP、Src Port、Dst IP、Timestamp这5个涉及特定网络标识的特征字段;信息相同的数据字段不会对分类提供有效信息,因此删掉了Bwd PSH Flags、Fwd URG Flags、Bwd URG Flags、CWE Flag Count、Fwd Byts/b Avg、Fwd Pkts/b Avg、Fwd Blk Rate Avg、Bwd Byts/b Avg、Bwd Pkts/b Avg、Bwd Blk Rate Avg这10个数据值全为0的特征字段,数据集剩余68个特征字段。依据前述特征重要性评分公式(5),计算得到剩余68个特征字段的特征重要性评分。为了构建8×8的卷积神经网络数据矩阵,再按照特征重要性评分大小对特征字段进行排序,将特征重要性最低的Fwd PSH Flags、FIN Flag Cnt、SYN Flag Cnt、Active Mean这4个特征字段删除,数据集剩余64个特征字段。 考虑到计算机性能限制,本次实验从正常流量中随机抽取2×106条流量作为正常流量的总样本,攻击类流量样本不变。经过其他处理的数据集数据按照8∶1∶1的比例拆分为训练集、验证集和测试集。 在多分类中,使用随机采样对训练集中部分多数类样本进行下采样操作,同时使用SMOTE-Tomek算法对部分少数类样本进行合成和清洗,完成训练集的数据平衡。 为了对模型的性能进行充分评估,实验采用准确率、精确率、召回率以及F1值作为模型评价指标。 对于多分类问题,对某种流量类别进行分类评估时,将该流量类别视为正样本,其余流量类别均视为负样本。 模型超参数的选取会直接影响模型的效果。本文模型采用Nadam优化算法代替Adam加强对学习率的约束[21],使用F1值评价指标作为模型超参数优化指标,得到实验最佳超参数设置:BiGRU隐藏层节点数为64;卷积核大小为3×3;丢弃率为0.5;批大小为256;迭代次数为100;学习率为0.002。其中,学习率为动态变化的,初始值为0.002,当参数状态越来越逼近全局最优点时,学习率按一定比例降低。 为了验证SMOTE-Tomek算法对数据平衡的有效性,将经过SMOTE-Tomek算法处理和未经过SMOTE-Tomek算法处理的数据集在本文模型上进行对比检测,得到数据集平衡前后各类别识别准确率如图3所示。 图3 数据集平衡前后各流量类别识别准确率 经SMOTE-Tomek算法处理的数据集较未经过处理的数据集在少数类的识别精度上提升明显。经SMOTE-Tomek算法处理,DoS attacks-Slow HTTP Test识别准确率从0提升至34.66%,SQL Injection识别准确率从0提升至100%,DDoS attack-LOIC-UDP、Brute Force-Web和Brute Force-XSS分别提升了5.22百分点、6.55百分点和35.71百分点,FTP-BruteForce识别准确率降低了10.62百分点。通过分析混淆矩阵发现,FTP-BruteForce和DoS attacks-Slow HTTP Test极易发生混淆,平衡处理前,系统将DoS attacks-Slow HTTP Test全部误判为FTP-BruteForce,经过平衡处理后,虽然FTP-BruteForce识别准确率有所下降,但可以更好地将两类区分。 实验结果证明了SMOTE-Tomek数据集平衡算法对于提升模型检测效果的有效性。 选取经典的单一深度学习模型与本文模型进行性能比较,对比实验为多分类方式。 实验中,使用CNN、LSTM和GRU单一模型与本文模型进行对比。所有模型均使用经过SMOTE-Tomek算法处理过的训练集对模型进行训练,分别比较这几种模型对各类别流量分类的性能,以精确率、召回率和F1值为评价指标。多分类结果如表2所示。 表2 CNN、LSTM、GRU模型与本文模型的多分类性能对比 由表2可知,本文模型应用于多分类问题时的总体性能良好,除FTP-BruteForce外,模型各类别分类评分均高于CNN、LSTM和GRU模型。因FTP-BruteForce和DoS attacks-Slow HTTP Test极易发生混淆,故DoS attacks-Slow HTTP Test召回率得到明显提升后,FTP-BruteForce召回率有所下降,但本文模型中FTP-BruteForce分类取得了更高的精确率和F1值。Infiltration类分类性能较其他几种神经网络模型提升明显,召回率较CNN模型提升了9.38百分点。 本文模型总的分类精确率、召回率以及F1值均高于其他几种单一神经网络模型,其中各攻击流量类别的总评精确率比LSTM模型提升了2.10百分点;总评召回率比LSTM模型提升了1.50百分点;总评F1值比GRU模型提升了1.97百分点。 综上实验结果,之所以取得较好的性能,是由于本文模型利用CNN对局部平行特征进行特征提取,避免特征丢失,能够提取深层次信息;同时,利用BiGRU对长距离时间关联依赖特征进行特征提取,充分考虑到数据集平衡前后信息对当前的影响,有效降低检测误报率,较好地解决了单一神经网络特征学习不全面的问题。 针对当前深度学习入侵检测中存在的数据集不平衡及特征信息学习不全面等问题,提出了一种基于CNN与BiGRU融合神经网络入侵检测模型。通过SMOTE-Tomek算法完成对数据集的平衡处理,使用基于平均不纯度减少的特征重要性算法实现特征选择,将CNN和BiGRU模型进行特征融合并引入注意力机制进行特征提取,从而提高模型的总体检测性能。实验结果表明,SMOTE-Tomek算法能够有效对数据进行平衡,加强了各检测模型对少数类样本的学习。同时,通过与经典单一深度学习模型的对比实验表明,该模型能够在更全面地提取数据特征的同时,还能在各项评价指标中获得更好的效果。1.2 融合神经网络模块
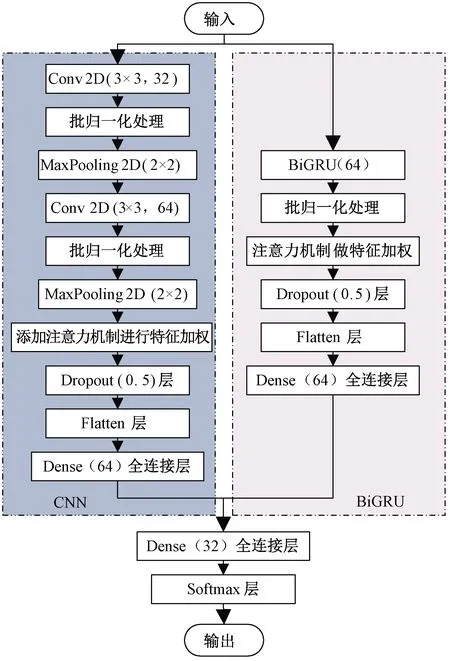
2 实验部分
2.1 实验环境
2.2 数据集预处理
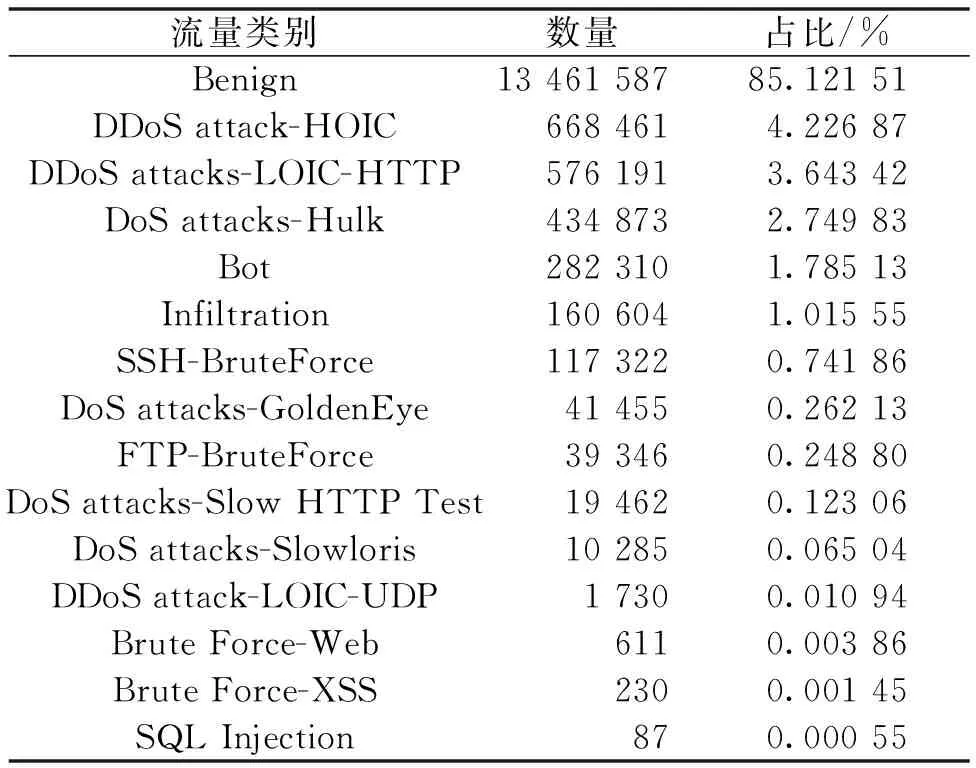
2.3 数据集拆分与平衡
2.4 评价指标
2.5 超参数设置
3 结果分析
3.1 SMOTE-Tomek数据平衡算法的有效性
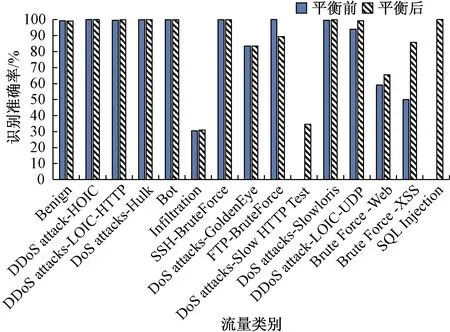
3.2 融合神经网络模型性能分析
4 结论
