基于改进生成对抗网络的非侵入式负荷预测样本不均衡的改善方法*
2022-04-28尹仕红张之涵谢智伟江敏丰郭兴林杨建明郑建勇
裘 星, 尹仕红, 张之涵, 谢智伟,江敏丰, 郭兴林, 杨建明, 郑建勇
(1.深圳供电局有限公司, 广东 深圳 440304;2.东南大学 电气工程学院, 江苏 南京 210096)
0 引 言
随着电网智能化发展的要求,以及响应国家能源发展“碳达峰,碳中和”的战略部署。非侵入式负荷识别在电网智能化发展和降低电能消耗,实现能源最大化利用方面有着重要的作用,利用非侵入式负荷识别技术能够预测居民用户在不同时刻的用电负荷,有利于电网系统上游发电节点做出预处理。在用电高峰时,根据负荷预测的结果制定分时电价引导居民错峰用电,以达到电网“削峰填谷”的效果。但是在非侵入式负荷预测的研究过程中发现,在对于居民用户的用电负荷的采集过程中,由于用户的生活方式决定了有些负荷属于常用负荷,有些负荷属于非常用负荷,所以对于常用负荷其采集到的样本数量较为丰富,而对于非常用负荷其样本数量自然相对较少[1-2]。这会导致在利用神经网络算法对其进行训练过程中出现过拟合和欠拟合的现象,对于负荷的识别效果产生不利影响。为了解决该问题,本文提出了一种基于改进辅助分类器的生成对抗网络(Auxiliary Classifier Generative Adversarial Networks,ACGAN)样本扩充模型,用于提高非常用负荷的样本数量以此改善非侵入式负荷识别样本质量[3]。
生成对抗网络(Generative Adversarial Networks,GAN)通过对比生成的图片与真实图片的相似性,不断优化生成器和判别器的质量,从而产生越来越接近真实样本的数据[4-5]。文献[6]基于一种改进的LMV-GCGAN模型,用于动漫头像生成,并且产生样本以外的头像。文献[7]通过将真实图片分解为RGB三通道,并通过GAN将三通道对比清晰图像进行噪点优化。文献[8]利用DCGAN对风机轴承故障样本进行扩充,解决样本不均衡问题,并运用扩充后的样本对轴承进行故障检测。在非侵入式负荷分解方面,文献[9]用卷积神经网络对居民用户的用电样本进行训练和预测,具有不错的识别效果。文献[10]对负荷的电压、电流等用电单数进行预处理生成V-I轨迹图形,并运用神经网络对负荷的V-I轨迹特征进行辨识,达到不错的识别效果。上述方法虽然能够利用现有的样本集对负荷进行训练和预测,但是对于样本数量较少的负荷识别效果仍然不佳,而且在利用原始ACGAN模型对样本数据进行扩充过程训练过程中,由于模型的损失函数的关系在迭代过程中容易发生梯度消失等问题,故需要花费大量的计算资源去调整模型参数来优化模型结构。
本文受到ACGAN能够对样本进行扩充的启发,在非侵入式负荷识别中,利用ACGAN模型对居民用户用电负荷中样本数量相对较少的样本集进行扩充,并运用卷积神经网络对扩充后的样本进行负荷的训练和分类。针对原始ACGAN模型在训练过程中容易出现梯度消失的问题,提出一种在模型判别器的损失函数中添加一类梯度惩罚函数,在模型的训练过程中更容易达到纳什均衡,生成的样本更接近真实样本数据。最后,利用非侵入式负荷识别的公共数据集PLAID对本文所提方法进行验证,证实了该方法的有效性[11-12]。
1 改进ACGAN算法
1.1 CGAN网络
GAN自提出以来得到广泛的应用以及对该神经网络的改进优化[13-14]。GAN属于无监督学习模型,模型主要由两个部分构成:生成器G和判别器D,两个模块的作用可理解为一种相互博弈的过程,其博弈过程的目标函数为
Ez~Pz[log2(1-D(G(z)))]
(1)
式中:V(D,G)——优化的目标函数;
x——真实数据(真实图片);
z——生成器生成的数据(图片);
Pdata——真实图片的分布函数;
Pz——生成图片的分布函数;
D(x)——真实图片的概率分布函数;
G(z)——生成图片的概率分布函数。
AGN的训练过程中,首先通过生成器G生成一组随机的噪声,然后判别器通过比较与真实数据之间的差异判断生成器当前所生成的是否为真实值。在优化迭代的过程中先固定判别器,通过生成器不断产生的生成数据与真实数据的差异来优化生成器,然后通过固定生成器来不断优化判别器,是一个优化迭代过程[15-17]。当生成器随机生成的一组数据通过判别器判定之后,与真实值的差异达到一定阈值可判定优化成功,在优化迭代的过程中生成器和判别器的损失函数分别为
式中:LG、LD——生成器的损失函数和判别器的损失函数。
尽管GAN不需要复杂的马尔可夫链,且能够产生比较贴近真实的样本数据,但是GAN的训练不稳定容易存在梯度消失等问题[18]。条件GAN(Conditional Generative Adversarial Networks,CGAN)作为一种GAN的变体,在GAN的基础上加了一个条件信息,从而实现条件生成模型,损失函数的目标函数为
Ez~Pz[log2(1-D(G(z|y)))]
(4)
由式(4)可见,CGAN是在生成器和判别器上分别增加了条件信息y,在生成器中采用类别标签和进行组合作为生成器的输入;在判别器中通用采用类别标签和图像数据进行组合作为判别器的输入。原始的GAN神经网络输入无监督学习,CGAN在GAN基础上加入条件信息后可视为有监督学习,能够改善GAN神经网络在训练过程中的不稳定性和梯度消失的问题[19-20]。
1.2 改进ACGAN网络
ACGAN的核心思想就是在原有的GAN模型的基础上添加了分类损失,其判别器的损失为
LD=LS+LC
(5)
真假判断损失和分类损失为
式中:LS、LC——真假判断损失和分类损失;
real|xreal——当为真实数据时C的值;
c|xfake——生成数据时C的值。
而生成器的损失函数为
LD=LC-LS
(8)
其真假判断损失和分类损失的计算式为
LS=E[logP(S=fake|xfake)]
(9)
LC=E[logP(C=c|xfake)]
(10)
为了解决原始ACGAN在训练过程中梯度容易消失的问题[21],本文引入了梯度惩罚的概念,在原始损失函数的基础上添加一个梯度惩罚公式。该梯度惩罚公式定义为
(11)


因此在原有ACGAN模型的损失函数基础上,改进后损失的ACGAN模型的损失函数为
在判别真假损失函数上,添加梯度惩罚函数之后,判别器和生成器在相互优化过程中梯度下降更快,更容易达到纳什均衡[22]。
2 模型的框架及训练
2.1 模型框架
使用ACGAN模型作为生成非侵入式负荷识别中不同负荷的样本,补充负荷中补偿用负荷的样本数量,以改善其样本不均衡问题。在非侵入式负荷识别过程中,通过智能装备(如智能电表)检测并获取居民用户用电负荷的相关数据,并对数据进行预处理、提取特征,然后运用神经网络深度学习等方法对特征负荷特征进行辨识,从而达到负荷辨识的效果。但是在实际的数据采集过程中,由于居民用户用电习惯的原因,存在常用负荷和非常用负荷之分,如冰箱、微波炉等为常用负荷,吹风机、烤箱等为非常用负荷。因此,在实际检测到的居民用电数据中存在数据样本不均衡问题,本文通过采用ACGAN对样本进行扩充,原始的GAN对于居民用户样本数据的扩充过程如图1所示。

图1 原始的GAN对于居民用户样本数据的扩充过程
CGAN中第一代生成器G1随机生成一组质量较差的图片,随之第一代判别器D1把生成的图片与真实图片进行比较后进行分类,可以将判别器视为二分类器,对于真实的图片输入为1,生成的图片输出为0,接着开始生成第二轮的图片,相较于第一轮生成器生成的图片更加接近于真实图片,直至迭代n次后生成器Gn生成的图片判别器Dn无法判别生成图片的真假。本文通过实际居民用电数据运用CGAN生成的样本数据,在训练过程中发现相同参数条件下训练过程不稳定,最终生成的样本数据较真实样本图片数据差距明显,即使增加Epoch次数改善效果依然不明显。因此,本文采用ACGAN模型并在ACGAN基础上进行一定改进,以适应居民用户用电负荷的样本数据。改进ACGAN模型如图2所示。

图2 改进ACGAN模型
该模型中生成器生成的图片由随机噪声Z和预分类器C产生一组随机数据,在生成器G中经过一系列逆卷积运算将一维的随机噪声生成二维的图片,逆卷积的过程也可成为采样过程,是提高样本精度的一种重要方法。其中生成器中卷积核的大小和卷积次数根据所需要生成样本的大小和样本像素要求决定。本文选取的PLAID样本数据集中生成的样本图片大小要求为226×226×3,经过总结,逆卷积运算输出图片大小的计算公式为Hout=(Hin-1)·stride-2·padding+kernel_size。本文设置4个卷积核,其中前3个卷积核的参数相同,stride为1,kernel为3,padding为1;最后一个卷积核大小根据样本大小(226×226×3)调整为stride为1,kernel为5,padding为1。本文所用的样本最终要转换成带有颜色空间的电压-电流轨迹的颜色空间图片,经过MATLAB自带的Pcolor颜色编码器处理的数据必须是0~1的数据,因此对于生成器生成的图片数据要进行归一化处理。本文对于ACGAN网络的训练采用Python语言Pytorch包中自带的归一化函数Sigmoid。判别器与生成器的网络结构呈现对称结构,其中卷积核大小stride、paddding等完全相同,判别器中图片大小必须保持与生成器中图片相同,不同在于生成器所使用的计激活函数为ReLU,而判别器使用的激活函数为LeakyReLU。
2.2 模型训练
在ACGAN模型结构的基础上,对模型进行训练,主要分为两个部分:生成器的训练和判别器的训练。在对生成器训练时,需要固定判别器的参数;在训练判别器时,需要固定生成器的参数。
(1)在训练判别器时,用Pytorch包中detach函数进行计算图截断,目的是为了在方向传播过程中不把梯度传递到生成器中,这是由于在训练判别器时要求生成器的所有结构和参数保持不变,因此过程中不需要生成器的梯度。
(2)在训练判别器时,需要进行两次反向传播,如果判别器判定图片为假时输出为0,判定为真时输出为1;或者将两次判别数据传递到bantch中。然后bantch对输入的数据分别做向前传播和向后传播。
在完成对模型的训练后,需要对结果进一步可视化处理。在数据可视化的过程中,对于初始输入的随机噪声数据都是固定的,在完成上述步骤后就完成一次迭代过程,通过尝试选取500次迭代以及生成器和判别器的学习率都为0.000 1,经过训练后产生的样本数据满足非侵入式负荷识别中电压-电流轨迹图的精度要求。
3 实验分析
3.1 样本分析
本文选取的数据集为非侵入式负荷识别公共数据集PLAID。该数据集记录了美国55个家庭居民用户用电数据,包含1 793组用电数据和11种不同电器。在对样本数据进行统计分析时发现,样本集中不同用电器的数量分布不均,对于进一步的负荷识别造成一定影响。样本种类及数量分布如图3所示。

图3 样本种类及数量分布
图3中,该11类负荷中平均样本数量为160,冰箱、加热器、吸尘器、洗衣机等电器的样本数量相对较少。在采用样本扩充之前,本文采用深度学习及神经网络对该模型进行训练和测试,对比不同神经网络在训练过程中的训练集和测试集的拟合情况,并将该拟合情况作为判定样本数据在采用神经网络训练时样本不均衡的判断依据。本文通过卷积神经网络(CNN)和改进性卷积神经网络(Alexnet)对该样本集进行训练和测试。样本集在神经网络中的训练过程如图4所示。

图4 样本集在神经网络中的训练过程
由图4可见,该样本集在训练过程中验证曲线与训练曲线之间的拟合情况较差。为了测试本文所提方法的有效性,接下来对该样本数量进行训练扩充,并对比原始ACGAN训练方法扩充的样本质量,证明该方法的有效性。本文仿真计算的硬件配置为Intel(R)Core(TM)i5-10210U CPU@1.60 GHz 2.11 GHz内存16 GB,软件采用Python公共平台Pycharm以及公共数据资源包Pytorch进行仿真分析。
3.2 样本扩充过程
本文参考文献[26]的方法对PLAID数据集进行负荷特征的构建,构建后样本负荷的V-I轨迹特征图如图5所示。
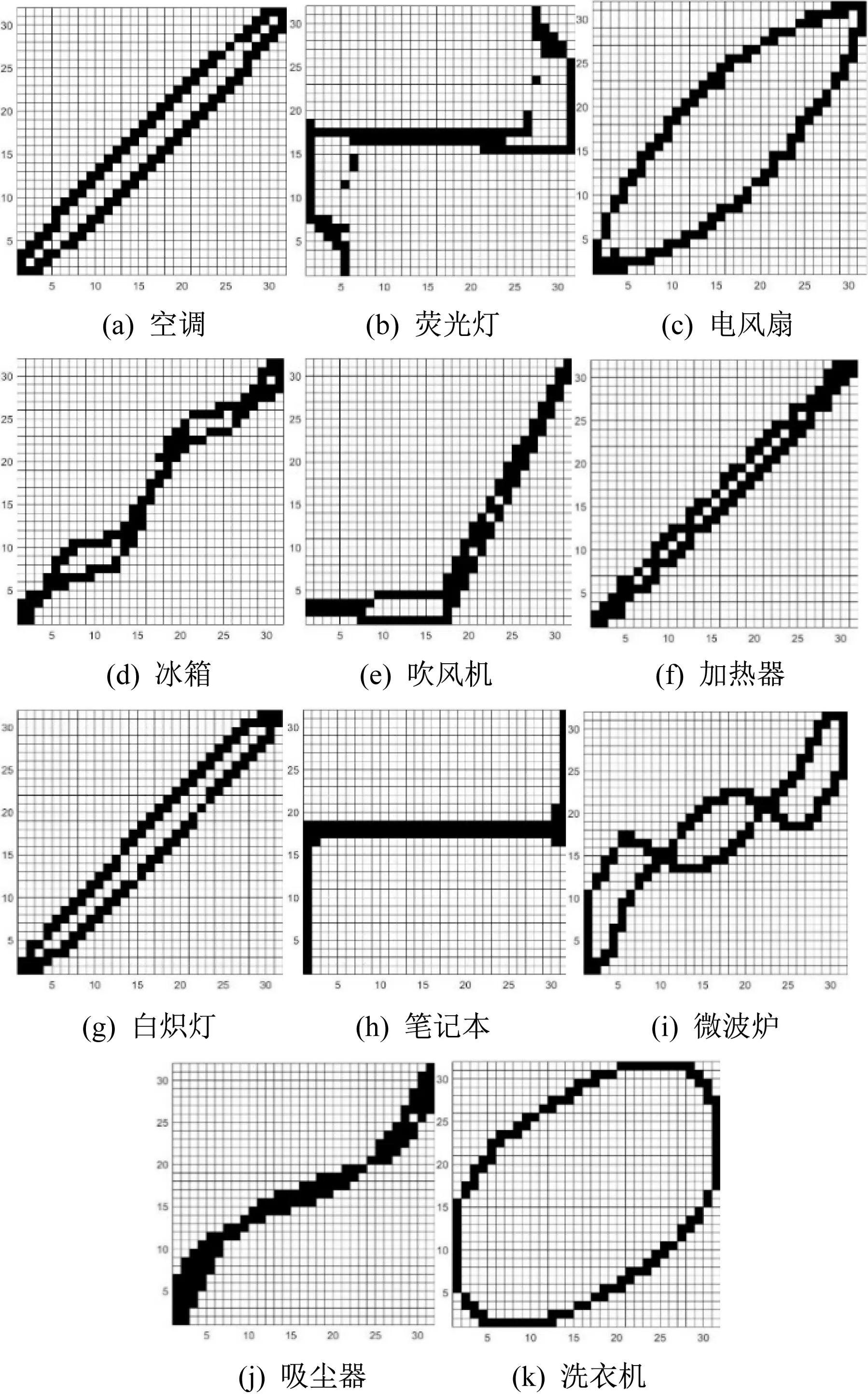
图5 构建后样本负荷的V-I轨迹特征图
为了将具有该V-I轨迹特征的样本图片数量进行扩充并验证本文所提方法的有效性,通过CGAN模型和改进ACGAN模型对样本进行训练。训练过程中两种模型的相关参数保持一致。训练模型相关参数如表1所示。

表1 训练模型相关参数
训练过程中,对两种模型的训练效果作对比。本文选取其中第1次噪声以及第100次迭代后和第200次迭代后生成器生成的图进行对比。CGAN样本训练过程如图6所示;改进ACGAN样本训练过程如图7所示。

图6 CGAN样本训练过程

图7 改进ACGAN样本训练过程
由生成的样本数据图片可见,生成器产生的初始噪声一致,但是在迭代运算过程中由于改进ACGAN网络添加了一个梯度惩罚过程,其梯度下降过程会更加显著,识别的准确率上升过程更加快速。ACGAN模型和改进ACGAN模型样本训练过程如图8所示。由图8可见判别器识别准确率的变化过程。

图8 ACGAN模型改进ACGAN模型样本训练过程
3.3 样本扩充后识别效果对比
运用上述方法将PLAID数据集的样本扩充完后,对扩充后的样本采用深度神经网络进行负荷的辨识,采用原始ACGAN网络生成的样本集和本文所提改进ACGAN网络生成的样本集进行比较分析。本文采用混淆矩阵对负荷辨识的结果进行评判,在混淆矩阵中定义:准确率ACC为分类正确的数量占总分类数量比值,即
(14)
式中:N——样本的总数量;
m——被神经网络分类正确的数量。
准确率P和召回率R的计算式分别为
(15)
(16)
式中:TP——被神经网络判断为正确的样本,而且实际上是正确样本的数量;
FP——被神经网络识别为正确的样本,但实际上是非正确样本的数量;
TN——被神经网络识别为非正确的样本,而且实际上是非正确样本的数量;
FN——被神经网络识别为非正确样本,但实际上是正确样本的数量[23-25]。
为了对识别的效果有更加客观评价,引入准确率和召回率的调和平均数Fscore,即
(17)
将ACGAN原始模型生成的样本和本文提供的改进ACGAN模型生成的样本,通过AlexNet神经网络进行训练和测试。原始ACGAN样本的辨识结果如图9所示;改进ACGAN样本的辨识结果如图10所示。

图9 原始ACGAN样本的辨识结果

图10 改进ACGAN样本的辨识结果
由图9和图10可见,改进后的ACGAN生成的样本在经过神经网络的辨识,其效果比原始ACGAN模型生成的样本的识别效果更好,对于样本数量较少负荷(冰箱、洗衣机、加热器、吸尘器)的改善效果尤甚。
4 结 语
本文针对非侵入式负荷识别中样本分布不均衡问题,提出了一种改进ACGAN模型对样本的数据进行扩充,该模型在原有CGAN和ACGAN的基础上对模型的损失函数作出改进,使用梯度惩罚来代替权值剪切,避免了在模型训练过程中容易出现的梯度消失等问题,并运用扩充后的样本进行特征的提取,然后进行负荷的识别,对比分析扩充样本之前和扩充样本后的识别效果,实验证明了本文所提方法的有效性。
