针对数据不平衡问题的分子生成模型
2022-04-26刘宏生
刘宏生,周 威,张 力
(1.辽宁大学 药学院,辽宁 沈阳110036;2.辽宁大学 信息学院,辽宁 沈阳110036; 3.辽宁大学 生命科学院,辽宁 沈阳110036)
0 引言
在目前的社会生存环境中,有大量毒性物质对人类生存发展产生很大的危害,这些毒性物质存在于人类生活的各个方面,以各种各样的方式对人类的生存产生影响.另一方面化合物的毒性预测对于药物研发来说也至关重要[1],化合物毒性和副作用等安全性因素成为了使药物研发失败的最主要原因.由于收集大量具有生物活性和毒性信息的化学物质是一项艰巨的任务,因此化合物数据中有标签的数据是严重不足的,而且这些有标签的数据存在类别不平衡现象[2],这将不利于模型的预测,为了解决化合物数据的类比不平衡问题,可以使用分子生成模型生成少数类化合物分子,进而扩充数据从而达到类别平衡.
近年来,无论是在理论上还是在实验证据上,深度生成神经网络已成为分子生成非常活跃的研究领域,为自动分子生成和优化开辟了新方向,到目前为止,模型通常基于SMILES和分子图形表示来创建具有所需特性的分子.Blaschke等[3]提出基于SMILES的生成对抗性自编码器(Adversarial Autoencoder,AAE)分子生成模型.Samanta等[4]提出了一种新的分子图变分自编码器,解码器能够提供生成分子的空间坐标,同时使用基于梯度的算法优化解码器并用来生成分子.Grechishnikova[5]提出了一种只依赖目标蛋白的氨基酸序列的分子生成模型,并将变压器神经网络体系结构应用于序列传导任务.Pereira等[6]提出的模型在强化训练过程中应用探索性策略,为生成的化合物增加了新颖性.
现有基于自编码器的生成模型与基于生成对抗网络的生成模型各有优缺点,自编码器可以很好地重构数据,而且编码器部分可以将高维的数据映射成低维的表征,起到良好的降维效果,但是生成的数据缺乏多样性.而对于辅助分类器的生成对抗网络(Auxiliary Classifier GAN,ACGAN)来说,虽然其具有良好的生成效果,并且能够在生成数据的同时使其带有标签信息,但是模型本身却存在过拟合和梯度消失的隐患.因此,为了能够达到生成指定类型的数据,从而进行数据扩充解决数据不平衡的目的,本研究结合2类模型的优点,提出了一种新型化合物分子的生成模型.
1 相关工作
1.1 自编码器
自编码器(Autoencoder,AE)是Rumelhart提出的一种深度学习中的前向神经网络[7],它可以使用无标签的数据训练来进行无监督的学习,从而获取更多的信息.自编码器由2个部分组成:一部分可以输入数据转换为隐藏层中低维表示,称之为编码器;另一部分将隐藏层中的低维表示映射成重构数据,称之为解码器.因此AE包括3层,其结构图如图1所示.对于输入数据和重构数据的接近程度,可以使用重构误差函数来进行衡量,从而尽可能地对输入数据进行复现,因此具有提取有效特征和降维的效果,就降维作用来说AE与主成分分析(PCA)相似,但是又有着更好的性能.

图1 AE模型结构
在AE架构图中,输入数据为X=(x1,x2,…,xm),其中x∈Rn,每个分量x都是一个n维的矢量,一共有m个数据.h=(h1,h2,…,hn)表示隐藏层向量,其中n表示隐藏层中单元的个数,应小于输入数据的数量m.输入层到隐藏层的编码过程可以通过式(1)表示:
h=s(Wxx+bx)
(1)
输出数据为y=(y1,y,…ym),隐藏层到输出层的解码阶段可以通过式(2)表示:
y=s(Wyh+bh)
(2)
公式中的Wx和Wy分别表示输入层到隐藏层以及隐藏层到输出层之间的连接权重矩阵,维度分别为n×m和m×s;bx和bh分别表示隐藏层和输出层中每个单元的偏置向量;各神经元一般选择sigmoid函数作为激活函数,其函数域的取值范围为0到1,公式中用s表示.
AE模型的训练其实就是寻找目标函数最优解的过程,在这一过程中权重及偏置向量得到了调节,进而能够最小化输入数据与输出数据之间的误差.
1.2 辅助分类器的生成对抗网络
ACGAN[8]是在生成对抗网络(GAN)的基础上改进得到的一种生成对抗网络模型,最早由Augustus等在2017年提出,ACGAN模型结构如图2所示.

图2 ACGAN模型结构
ACGAN与GAN在模型结构有所区别,原始的GAN模型中生成器的输入变量只有一个随机噪声z,而ACGAN模型中生成器的输入变量为2个,除了随机噪声z以外还加入了标签信息C,生成器通过使用2个变量可以生成类条件的假样本,用Xfake=G(c,z)来进行表示.ACGAN模型的判别器和GAN模型也有所区别,原始的GAN模型中的判别器只进行二分类判断真假,它的输出会被sigmoid激活函数映射到0,1之间,0代表假,1代表真,从而对数据的真假性进行判别,ACGAN模型中的判别器在此基础上增加了一个辅助分类器C,因此它的判别器还有另外一个输出,这个输出通过softmax分类器可以得到类别的后验概率,从而对类别进行预测.正因如此ACGAN模型中判别器的目标函数由2部分组成,即正确源的对数似然Ls和正确类别的对数似然Lc,两部分的公式分别如式(3)和式(4)所示:
Ls=E[lgP(S=real|Xreal)]+E[lgP(S=fake|Xfake)]
(3)
Lc=E[lgP(C=c|Xreal)]+E[lgP(C=c|Xfake)]
(4)
式(3)、(4)中的Ls是准确分类的真实样本和生成样本的损失,Lc是准确对样本类别进行分类的损失.在模型的训练过程中,判别器的目标是最大化Ls+Lc,生成器的目标是最大化Ls-Lc.
2 基于AE的改进ACGAN分子生成模型
2.1 AE-ACGAN模型结构
新提出的化合物分子生成模型主要包括2个部分,分别是AE和ACGAN,其中AE的主要功能包括2部分,编码器部分将高维度的化合物分子结构进行编码得到其低维的特征表示,而解码器部分则是对ACGAN生成的新化合物分子的潜在表示进行采样而后进行解码,最终得到新型的化合物分子结构.而ACGAN模块的功能则是利用AE提取的低维特征进行训练,从而生成新的化合物分子结构.此方法与以前的GAN方法之间的区别在于,生成器和判别器不使用简化分子输入行输入系统(SMILES)字符串作为输入,而是从训练SMILES字符串的AE中得出的n维向量作为输入[9].这使模型可以专注于优化采样,而不必担心SMILES语法问题.AE-ACGAN模型结构图如图3所示.
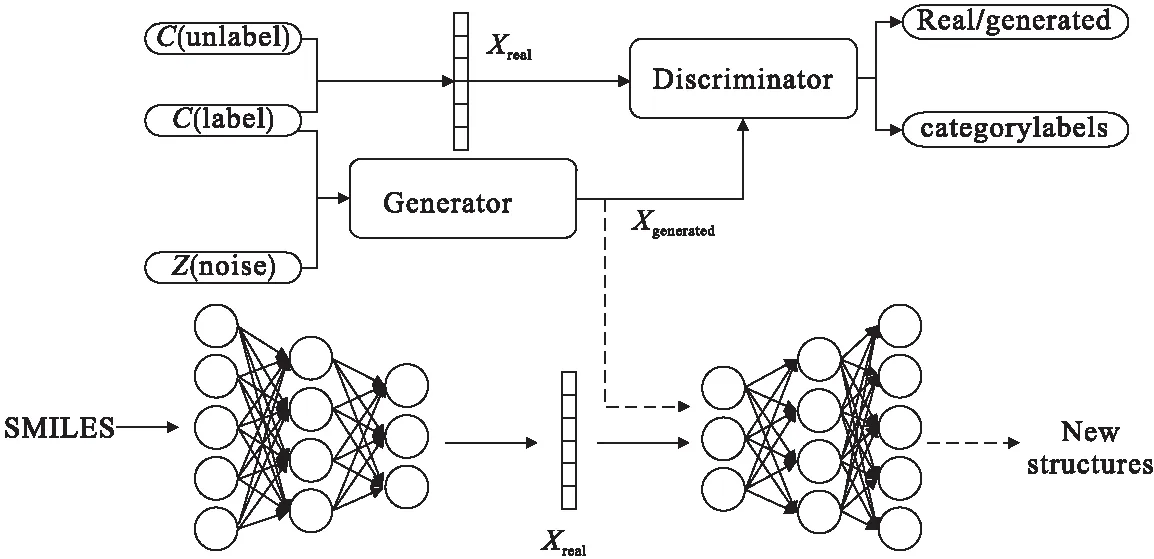
图3 AE-ACGAN模型结构
此方法先在一组化合物分子数据上对AE模型进行了预训练,通过AE的编码得到化合物分子的低维特征向量,然后通过解码器进行重构,通过重构误差不断地对自编码器的参数进行调整,最后得到最佳的低维特征表示h,然后,将其用作判别器的真实数据输入,一同放进判别器中的还有数据带有的分类信息,也就是数据本身的标签,同时将从均匀分布中采样的一组随机矢量作为伪数据和标签信息一同输入到生成器中.判别器中的辅助分类器可以更好地提高判别器的性能,这样判别器不仅能输出数据的真假信息,还能输出数据的类别.对于判别器的每5批训练,都会分配一批来训练生成器,以便判别器在向生成器提供更高梯度的同时保持领先地位.在ACGAN训练完成后,会对生成器进行多次采样,并将生成的潜在矢量输入解码器中,以获取新型的SMILES字符串.
2.2 AE设计
对于AE部分的构造和训练,最初,本文将one-hot编码的SMILES字符串通过每层512个长短期记忆网络(LSTM)单元的2层双向编码器输出,其中一半用于正向,一半用于反向,然后将2个方向的输出连接起来,并输入到512大小的前馈层,作为训练期间的正则化步骤,通过应用标准偏差为0.1的加性零中心高斯噪声来扰动所得向量.分子的潜在表示被馈送到前馈层,其输出被复制并以隐藏状态和单元状态插入到具有与编码器相同规格的4层单向LSTM解码器.最后1层的输出由具有softmax激活的前馈层处理,以返回对数据集中已知字符集的每个字符进行采样的概率.动量值为0.9的批量归一化应用于除高斯噪声层以外的每个隐藏层的输出.
本文对AE网络进行了100个epoch的训练,批处理大小为128,对于前50个epoch使用恒定的学习率10-3,随后以指数衰减,在最后1个epoch中达到10-6的值.解码器是使用teacher forcing训练机制进行训练,使用解码和训练SMILES之间的分类交叉熵的解码损失函数来训练模型,训练完AE后,将禁用噪声层,从而完成对ACGAN训练和采样集合的确定性编码和解码.
2.3 改进ACGAN
2.3.1 引入wasserstein距离
原始ACGAN真假判别目标函数存在一定的缺陷,即当判别器最优时,若真实和生成样本的2个分布没有交集,就会导致生成器梯度消失.而使用wasserstein距离衡量时即使2个分布没有重叠部分,它也可以反映二者的远近.因此本文选择使用wasserstein距离衡量分布距离,与原始ACGAN真假判别中的sigmod函数相比较,使用wasserstein距离衡量分布距离同样属于回归任务,所以将对sigmoid函数进行替换,这样一来在判别器对数据进行判别真假的功能上,使用wasserstein距离来对数据进行真假的判断,而在对数据进行标签分类上,与原始的ACGAN相同,依然使用softmax激活函数进行分类.
在原始的ACGAN上以wasserstein距离作为判别器的目标函数,虽然能够很好地解决在训练中存在的不稳定问题,那是因为样本在处于任何情形下,wasserstein距离都可以对样本之间的距离进行度量,这是Jenson′s Shannon(JS)散度所不具备的能力,因为JS散度的值是突变的,只有最大值和最小值2种情况,所以不能提供梯度信息.与JS散度相比wasserstein距离相对来说是平滑的,其中参数θ可以传递梯度信息,并且可以利用梯度下降法进行优化[10],正因如此生成器的参数才能得到更新从而拟合出真实分布.但wasserstein距离受Lipschitz连续条件的限制,即导函数不能超过Lipschitz的常数K,通过权重裁剪(weight clipping)将判别器的权重限制到某个范围,强制满足Lipschitz条件,这样容易产生2种不好的后果,即梯度消失或者梯度爆炸.正是由于这种方式过于粗暴,使得判别器的拟合能力受到了限制,从而对网络的表现产生一定的影响.为了对判别器的梯度进行限制,使它的值不超过K,在ACGAN判别器的损失函数上使用1种可替代的权重剪切方法——梯度惩罚(Gradient Penalty,GP)[11],以此来提高训练过程的稳定性,其本质是通过设置1个额外的损失项来实现梯度与常数K之间的联系,可以通过下面的公式(5)来对梯度惩罚项进行定义:
Relu([‖∇xD(x)‖p-K]2)
(5)
由于式(5)中K的取值对梯度下降的方向并不产生影响,因此可以将K的值设为1从而得到式(6):
(6)

(7)
另一部分是数据分类正确的概率Lc与原始ACGAN相同,依然是式(8):
Lc=Ec~Pdata[lgD(c)]+Ec~Pz[lg(1-D(G(c)))]
(8)
因此总的判别器能被训练的最大值为新的Ls与Lc之和,生成器能被训练的最大值为Lc与新的Ls之差.
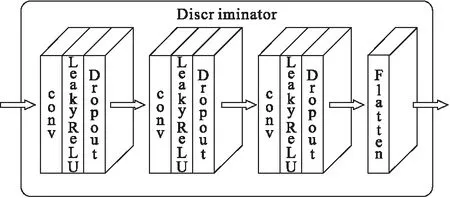
图4 判别器结构
此外本文在原始ACGAN的基础上对其判别器结构进行改动,原始的ACGAN的判别器中包含着批归一化(Batch Normalization)层[12],但是由于本文在原有的ACGAN上进行了改动,在判别器中引入了wasserstein距离对2个分布之间的距离进行衡量同时使用了梯度惩罚,所以判别器的模型结构较原始ACGAN发生相应的改变,其中不再使用批归一化层,这是因为每个batch中的每个样本都独立地施加了梯度惩罚.因此改进后ACGAN模型中的判别器网络基本与生成器网络一致,不同的是判别器中各层之间不再使用批归一化层,本文模型中的判别器结构如图4所示.对于ACGAN中优化器的选择也进行了相应的调整,不再用基于动量的优化算法Adam,选择使用RMSProp[13]进行替代,这一调整也可以对训练过程中产生的不稳定问题起到一定的改善作用.
2.3.2 利用无标签数据
由于原始的ACGAN模型属于深度学习中的有监督学习,因此只能使用有标签的数据作为输入,这样就使得大量的无标签化合物数据没有得到很好的利用,与此同时小样本的数据对于GAN来说不太友好,因此GAN需要足够的数据来训练网络以达到收敛,作为GAN的一种衍生模型,ACGAN一般情况下也需要大量的数据样本,但是对于化合物数据而言,并没有足够的有标签样本供ACGAN训练,因此就要想办法使得ACGAN可以不单单只使用有标签的数据进行训练,也可以将大量的无标签的化合物数据样本作为输入.

图5 改进ACGAN模型结构
为了能更好地利用大量的无标签化合物数据,本文同样使用其作为ACGAN模型的输入.通过前面对ACGAN的介绍以及改进可以知道,ACGAN模型中判别器的目标函数由2部分组成,即正确源的对数似然Ls和正确类别的对数似然Lc,在将无标签的数据加入到ACGAN模型的输入时,现在ACGAN的输入数据就包括了2部分,有标签的化合物数据和无标签的化合物数据.有标签的化合物数据跟之前完全使用有标签的数据作为输入时没有区别,判别器对这部分样本的损失函数仍然是由2部分组成,一部分是对数据的真实性进行判断得到损失函数Ls,其表达式同式(7),另一部分是对数据的类别进行判断得到的损失函数Lc,其表达式同式(8),对于生成器通过输入随机的噪声以及添加的标签信息生成的伪数据来说,判别器的损失函数依然是这2部分.对于无标签的真实化合物数据,当其作为ACGAN模型的输入时,判别器的损失函数就发生了改变,无标签的化合物数据不包含类别信息,所以判别器不能使用这些数据进行类别判断,但是这些数据依然是真实的数据,因此判别器只使用这些数据和生成器生成的数据进行判断,来训练判别器鉴别真假的能力,这样一来判别器的损失函数就只包含一部分也就是只对数据的真实性进行判断得到损失函数Ls,3种不同数据的损失函数构成了整个网络的损失函数.输入数据的改变使得模型的结构图也发生了改变,利用无标签数据的ACGAN模型结构如图5所示.
通过与原始ACGAN模型的对比可以发现,改进后模型的输入数据除了有标签的数据之外还包括无标签的数据,当无标签的数据输入到判别器中的时候,判别器中的wasserstein距离可以对数据进行真假的判断,由于不包含标签信息所以无法对其进行分类,但是无标签的数据仍然是真实数据,仍然可以训练判别器的鉴别能力.
3 实验分析
3.1 数据处理
分子必须以字符序列表示,例如“SMILES”字符串.SMILES经常被用作生成型AE模型的输入,并且事实证明可以利用其生成新的化合物分子,对SMILES字符串应用seq2seq模型以提取数据驱动的分子描述符[14].尽管原则上,1个规范的SMILES字符串足以对分子进行明确的描述,但实际上,不同的规范化算法产生不同的规范表示.在这项研究中,本文使用了RDKit.
由于神经网络只能处理数字数据,因此需要对SMILES字符串进行一些初始预处理.“one-hot”编码是1种将分类变量转换为二进制值(“1”和“0”)的数组,每个二进制值中都严格带有单个“1”.在这种情况下,每个SMILES字符串都可以表示为二进制值的矩阵,其中每一行对应于有效符号字典中的1个项目,每一列对应于SMILES字符串中的1个字符,并且在它们的对应位置为“1”,相交表示它们之间的对应关系.
3.2 评价指标及结果分析
本文通过以下标准对新生成的化合物分子进行评价.
1)有效性:有效SMILES的比例,即有效SMILES的数量除以生成的SMILES的总数.
2)独特性:唯一SMILES的比例,即唯一SMILES的数量除以有效SMILES的总数.
3)新颖性:用于转移学习的数据集中不存在的生成分子的比例,即新颖(未重复数据删除)SMILES的数量除以有效SMILES的数量.
为了验证本文所提出的分子生成模型的效果,本文与常用的几种生成模型进行比较,并使用生成分子的评价标准进行评估,如图6所示,通过与现有的一些模型在有效性方面的对比,可以发现本文所提出的AE-ACGAN模型生成的分子具有较高的有效性,并且相较于现有的模型有了一定的提高,同时这也表明生成的序列符合化合物分子的规则.
生成的化合物分子的独特性和新颖性如图7所示,本文所提出的化合物分子生成模型在独特性和新颖性上也有所提升,这是由于模型中的ACGAN有着更好的生成效果,使得所生成化合物分子的多样性更强,从而进一步说明了所生成化合物分子的质量比较高,能够用来很好地扩充原始数据.
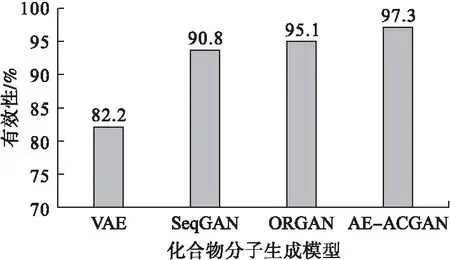
图6 有效性对比

图7 独特性与新颖性对比

图8 无毒与有毒化合物不同比率的ACC
本文提出的新型分子生成模型,生成了与原始数据具有相同特点的新分子,按照标签的要求生成了指定类型的有毒化合物分子,新生成的有毒化合物分子可以用于增强原始的类别不平衡数据集,然后再使用化合物毒性预测模型进行训练.新的训练集样本包括原始数据和新生成的有毒化合物分子,通过添加不同数量的有毒化合物分子改变原始数据中有毒化合物分子和无毒化合物分子类别之间的比率,然后进行预测,通过准确率可以发现增强后的类别平衡数据对于模型有着更好的训练效果.
通过图8可以看出,随着数据集中无毒化合物与有毒化合物的比率越来越接近于1∶1,测试集的准确率得到了明显的提升,这说明在数据不平衡的条件下化合物毒性预测模型的预测效果受到了一定的限制,当数据集中无毒化合物分子与有毒化合物分子的类别达到平衡时,预测模型能够达到比较好的预测效果,说明通过少数类数据进行数据扩充对解决数据不平衡问题起到了良好的效果,这样也证明了本文提出的新型的化合物分子生成模型有着很好的生成效果,所生成的新型的化合物分子能够起到很好的数据扩充作用.
4 结论
本文通过结合AE和改进后的ACGAN,提出了一种新的分子生成的模型AE-ACGAN.结果表明,该模型生成的化合物分子相对于训练集而言,绝大部分采样化合物是新颖的而且质量比较高,通过将新生成的有毒化合物分子增加到原始数据集中,使原来类别不平衡的数据变得平衡,从而使得分类模型的预测准确率有了进一步的提升,证明新提出的分子生成模型能够生成指定的少数类化合物分子,对原始的化合物数据进行扩充,从而改善数据类别不平衡问题.
