基于时空特征融合的语音情感识别
2022-04-25郑传锟张自力刘军平胡新荣何儒汉
彭 涛,郑传锟,张自力,刘军平,胡新荣,何儒汉
(1.纺织服装智能化湖北省工程研究中心 湖北 武汉 430200; 2.湖北省服装信息化工程技术研究中心 湖北 武汉 430200; 3.武汉纺织大学 计算机与人工智能学院 湖北 武汉 430200)
0 引言
语音是人机交互的主要方式之一,语音系统要实现与人类的自然交流,就必须能有效地处理潜在的情感信息[1]。因此,在开发语音系统(语音识别、说话人识别、语种识别和语音合成)的同时,应利用语音情感知识,将语音情感识别嵌入到现有的语音系统中,使其更加自然、有效。语音情感识别是一项具有挑战性的任务,主要有以下三个原因:1) 人类情感是抽象的,这使得情感难以区分;2) 人类情感只能在说话过程的某些特定时刻被察觉;3) 带有情感标签的语音数据样本通常是有限的[2]。
近年来,依赖于海量的训练数据与强大的大数据处理系统,使得深度学习在复杂的高维数据处理领域取得了突破性的进展。随着深度神经网络的引入,语音情感识别的性能有了显著提升。在语音情感识别领域中,代表性的深度学习方法有:卷积神经网络(convolutional neural network,CNN);循环神经网络(recurrent neural network, RNN)以及深度置信网络(deep belief network, DBN)等。越来越多的研究人员尝试将深度学习运用到语音情感识别中,以提高语音情感识别系统的性能。王杰等[3]将神经预测器引入隐马尔科夫模型计算状态观察概率,同时又利用状态累计概率输入径向基神经网络分类,避免特征向量时间规整的麻烦。Xu等[4]提出了使用多尺度区域注意来处理不同粒度的情感特征,并且通过实验证明其识别率高于传统的语音情感识别方法。Atmaja等[5]将低水平特征作为双向长短期记忆神经网络(bi-directional long-short term memory neural network,BLSTM)的输入,证明了BLSTM 网络和注意力机制可以学习与情绪相关的帧级声学特征,同时证明了帧级特征作为输入优于段级特征。彭玉青等[6]针对深度学习模型在对小样本进行训练时会出现过拟合现象,提出随机退出优化方法和随机下降连接优化方法,缓解过拟合现象。Li等[7]提出了一种基于一维卷积网络的语音情感识别模型,将Mels频谱图和Log-Mels频谱图作为互补特征输入模型,实验证明该方法在语音情感识别领域有效。Zhang等[8]提出深度卷积网络的方法,通过微调图像数据集训练的CNN网络获得特征后进行分类。沈克琳等[9]利用CNN模型计算篇章中所含英文单词的平均情感极性作为篇章情感、倾向的量化分值。Aldeneh等[10]证明了卷积神经网络可以直接应用于时域低级声学特征来识别情绪显著区域。
1 面向SER的3D-DACRNN模型
虽然深度神经网络在语音情感识别领域中取得了很大的成功,但是由于受人们说话方式、说话内容和所处环境的影响,直接特征不足以表达说话人的情感。因此,受到梅尔频率倒谱系数在语音情感识别(speech emotion recognition,SER)领域中使用一阶差分(delta)和二阶差分(delta-delta)积极效果的启发,通过计算频谱图的一阶差分和二阶差分反映情感的变化过程,保留有效的情感信息,同时减少了情感无关因素的影响,并且将原始话语生成的三维对数频谱图作为CNN输入,此输入类似于RGB图像,也适用于迁移学习。目前的研究大多是基于具有公信力的数据集[11],训练样本和测试样本来自同一个语料库,与实际应用场景不符,并且海量语音数据的情感标注也是一项具有挑战性的任务[12],因此可以使用在ImageNet数据集上预先训练的AlexNet网络来提取语音数据的情感特征[2],利用迁移学习来解决跨语料库识别和语音数据难以获取的难题。此外,大多数语音情感数据集的情感标签是在一段语音上标注的,而一段语音通常包含许多类似沉默等与情感无关的信息,在大多数情况下情感仅与少量内容相关,所以为SER选择与情感相关的时频区域尤为重要[13],因此提出将迁移学习、卷积循环神经网络(convolutional recurrent neural network,CRNN)和注意力机制相结合来进行语音情感识别, 以提升语音情感识别任务的准确性和鲁棒性。
提出的基于迁移学习的注意力卷积神经网络(dilated-attention CRNN,D-ACRNN)结构如图1所示,模型包括6个部分:1) 从语音信号提取3D-LogMels频谱图(静态,一阶差分和二阶差分)作为模型的输入;2) 用卷积神经网络(CNN)提取3D-LogMels频谱图局部不变的空间特征;3) 双向长短期记忆神经网络(BLSTM)用于提取包含上、下文信息的时间特征,并将空间特征和时间特征融合为时空特征;4) 注意力层用来自动关注情感有关部分;5) 时间金字塔(DTPM)用于将帧级特征融合为话语级特征;6) 将话语级特征输入到支持向量机(support vector machine, SVM)中进行分类。

图1 基于迁移学习的3D-Dilated-ACRNN网络结构Figure 1 3D-Dilated-ACRNN network structure based on transfer learning
1.1 3D-LogMels频谱图的生成
近年来,Abdel-Hamid等[14]使用对数梅尔频谱图作为CNN输入。但是,对数梅尔频谱图是直接特征,无法体现情感变化的过程,考虑到3D-LogMels频谱图中的一阶差分和二阶差分能反映情绪变化的过程,因此提出使用3D-LogMels频谱图作为D-ACRNN的输入。

mi=log(pi),
(1)
(2)
(3)
在计算了具有一阶差分和二阶差分的3D-LogMels频谱图之后,可以将获得的3D特征X∈Rt×f×c作为CNN的输入,其中:t表示时间(帧)长度;f表示梅尔滤波器组的数量;c表示特征通道数。在此任务中,AlexNet网络要求输入高宽比为1∶1,目前研究者已经证明在语音情感识别中,重叠长度应大于250 ms,并且梅尔滤波器组的数量f设置为64时效果最好[8],因此将f设置为64,t和f一样设置为64。将给定的语音信号分成汉明窗大小为25 ms,偏移为10 ms的短帧,t为64时,语言信号重叠长度为10 ms×63+25 ms=655 ms,是建议的250 ms的2.6倍,因此可以为情感识别提供足够的线索。c的值设置为3,分别代表静态、一阶差分和二阶差分。
1.2 基于迁移学习的Dilated-ACRNN网络
目前许多研究者在使用迁移学习时忽略了语音数据的时序信息和空间信息,因此提出了基于迁移学习的Dilated-ACRNN网络。首先,将3D-LogMels频谱图输入CNN提取帧级空间特征;然后,使用BLSTM提取包含上、下文信息的时间特征,并将空间特征和时间特征融合为时空特征,同时注意力机制会使模型专注于频谱图的特定时频区域。
1.2.1语音信号空间特征提取 对于给定的3D-LogMels频谱图,使用CNN提取频谱图的空间特征。CNN部分由五个卷积层、一个膨胀卷积层、三个池化层和三个全连接层构成,具体结构如图2所示。

图2 Dilated-ACRNN网络中CNN部分具体实现Figure 2 The specific implementation of the CNN part in the Dilated-ACRNN network
卷积层名称含义为Conv层数 [卷积核尺寸]-步长-卷积核个数,最大池化层名称定义为Maxpool[内核尺寸]-步长。为了简化图2,将归一化层和Dropout层省略。可以看出,该结构与AlexNet网络的结构相似。AlexNet网络在大型ImageNet数据集上进行训练,并利用图像识别任务和语音情感识别任务的相似性,将图像领域学习到的模型应用到语音情感识别领域中[15],解决了跨语料库识别和带有情感标签的语音数据难获取等难题。因此直接从AlexNet网络中复制模型的初始参数,微调三个全连接层,使模型适用于语音情感识别任务。但是AlexNet网络中的参数是从图像数据集中训练得到的,虽然语音频谱图和图像数据有相似性,但也有不同之处,图像数据集训练的参数并不能完全表现语音数据的空间信息。因此添加膨胀卷积层来提取频谱图的空间特征,膨胀卷积未使用池化增大感受野,不会丢失信息[16],有利于提高语音情感识别任务模型的准确率。
1.2.2语音信号时空特征提取 长短期记忆(long-short term memory,LSTM)神经网络属于RNN的变种。依赖于其独特的机制,LSTM 能处理间隔距离长的文本特征信息,在自然语言处理和语音情感识别中有着广泛的应用。双向长短期记忆神经网络(BLSTM)结合了长短期记忆网络和双向循环神经网络的优点,能够学习语音数据的时间上下、文信息[17]。
AlexNet网络是在大型ImageNet数据集上进行的训练,主要用于图像分类任务,此类任务大多仅包含空间信息,不需要时序信息,这也是图像分类任务与语音情感识别任务的区别。因此在AlexNet网络的基础上加入BLSTM网络来提取时序信息,将CNN部分获取的空间特征输入BLSTM中,以获得此帧语音的时序信息,并将空间特征和时间特征融合为时空特征。具体结构如图3所示,将CNN网络输出的4 096个序列输入BLSTM层中,其中BLSTM层具有4 096个细胞,正、反两个方向各2 048个,因此通过LSTM层可以获得一系列4 096维的高级特征表示。

图3 时空特征融合模型Figure 3 Spatiotemporal feature fusion model
1.2.3注意力模型 作为对BLSTM的附加处理,引用了注意力模型。在语音情感识别任务中,一段语音中并非所有的时频单位都对整个话语的情感状态同样重要,因此引入注意力机制来提取对整个话语情感重要的元素。具体实现方式为
ei=uTtanh(Wai+b),
(4)

(5)
(6)
用公式(4)通过多层感知器(MLP),以tanh作为非线性激活函数来获得输入序列ai的新表示ei。公式(5)将注意力得分ei通过Softmax函数规整为0~1之间的注意力权值αi。公式(6)利用获得的注意力权值αi对输入的L帧特征中的特征向量ai加权,最终得到加权后的特征表示c。
2 实验
2.1 数据集
EMODB数据集是由柏林工业大学录制的德语情感语音库[18],由10位演员(5男5女)对10个语句(5长5短)进行7种情感(中性/nertral、生气/anger、害怕/fear、高兴/joy、悲伤/sadness、厌恶/disgust、无聊/boredom)的模拟得到,共包含800句语料,经过听辨测试后保留男性情感语句233句,女性情感语句302句,共535句。其中语句内容包含日常生活用语的5个短句和5个长句,具有较高情感自由度,不包含某一特定情感倾向。数据集采用16 kHz采样,16 bit量化,并以WAV格式保存文件。
eNTERFACE05是一个公开的英文视听数据集[19]。包含生气、厌恶、害怕、高兴、悲伤和惊奇6种情感。eNTERFACE05数据集共计包含1 166个视频,其中 264个女性录音(23%)和902个男性录音(77%)。采用无压缩立体声16位格式,音频采样率为48 kHz。
交互式情绪二元运动捕捉(IEMOCAP)数据库是一个动作、多模式和多峰值的数据库[20],由南加州大学的Sail实验室收集。它包含大约12 h的视听数据,包括视频、语音、面部运动捕捉、文本转录。IEMOCAP数据库由多个注释员注释成类别标签,如愤怒、快乐、悲伤、中立,以及维度标签,如Arousal和Valence等。详细的动作捕捉信息、激发真实情感的互动设置,以及数据库的大小,使该语料库成为现有数据库的重要补充。
2.2 实验设置
由于数据集中仅包含有限数量的样本,并且语音数据有瞬时不变的特点,因此在实验中将话语划分为一定数量的重叠片段。根据文献[21]中建议,在语音情感识别中重叠长度应大于250 ms。因此,将重叠长度设置为64帧,大约为655 ms。对于EMODB数据集,从535个语音片段增加到11 842个。对于eNTERFACE数据集,从1 293个语音片段增加到26 587个。由于IEMOCAP数据集中数据分布不均匀,一些情感的数据量太少,因此实验中仅采用标签为happy,anger,neutral和sad的四种数据。通过上述重叠的方法,将2 280个语音片段增加到31 934个。实验设置最小批量为30,随机梯度下降的动量为0.5,学习率为0.000 1,迭代次数为300。
实验中同时采用加权平均召回率(WAR)和未加权平均召回率(UAR)作为度量标准。加权精度为测试集所有发音的整体精度,未加权精度为所有类别准确度的平均值。
实验采用留一法交叉验证(leave-one-out cross-validation),将数据集分为n个部分,其中一部分作为验证集,其余部分作为训练集。这种方法得出的结果与训练整个测试集的期望值最为接近。
2.3 实验对比基线
将与以下几个基准进行比较。
1) 深度卷积神经网络(deep convolutional neural network,DCNN):使用5层CNN网络来提取帧级空间特征,然后使用判别时间金字塔匹配,将帧级特征组合成段级特征,并将其输入SVM中以进行分类。
2) 卷积循环全局神经网络(convolutional recurrent global neural network,CRGNN):提取频谱图特征后,使用全局最大池化策略来选择最显著的特征。
3) 1-D D-ACRNN:使用与3-D D-ACRNN网络相同的网络模型,但是输入的不是3D-LogMels频谱图,而是一维静态的LogMels频谱图,将其称为“1-D D-ACRNN”。
4) CRNN:使用CRNN提取频谱图的特征,不使用图像数据的参数,用以研究迁移学习在语音情感识别任务中的作用。
2.4 实验结果分析
使用不同网络层数的消融实验结果如表1所示,可以观察到在EMODB数据集上,一层膨胀卷积和一层BLSTM达到最佳性能(黑体数据性能最佳),结果表明深度学习中不是网络层数越多效果越好,主要取决于训练数据的类型和大小。
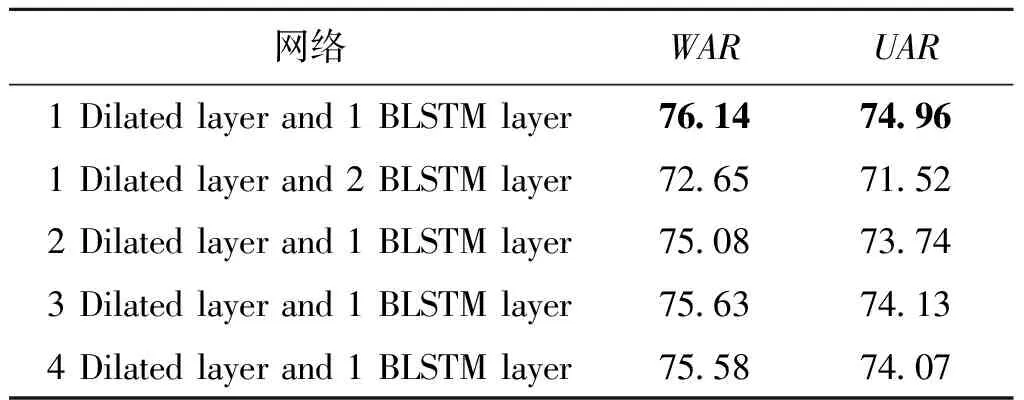
表1 不同网络层数在EMODB数据集上的WAR和UARTable 1 WAR and UAR of different network layers on EMODB data set 单位:%
表2展示了不同模型对比实验的结果,主要从UAR和WAR两方面对比(黑体数据表示性能最佳)。首先,在EMODB和IEMOCAP数据集上与CRGNN方法进行比较,在WAR上分别提升了2.7%和7.38%。结果表明了Dilated-ACRNN的有效性。然后,在EMODB和eNTERFACE两个数据集上与DCNN方法进行比较,通过实验结果可以看到3D-DACRNN优于DCNN,并且在两个数据集上的WAR分别提升了2.82%和2.47%;UAR分别提升了4.66%和3.32%,证明了添加时空信息对于语音情感识别任务的有效性。接下来,研究了将3D-LogMels频谱图作为输入的有效性,将3D-LogMels频谱图作为输入的3D-DACRNN,在三个数据集上的WAR和UAR都略高于与将静态频谱图作为输入的1D-DACRNN,这表明计算LogMels频谱图的一阶差分和二阶差分可以保留有效的情感信息,提升语音情感识别的准确性。最后,在EMODB和eNTERFACE两个数据集上与CRNN方法进行比较,通过实验可以看到DACRNN优于CRNN,并且在两个数据集上的WAR分别提升了4.14%和7.77%,证明迁移学习能够提高语音情感识别任务的准确性。

表2 不同方法在EMODB、eNTERFACE、IMOCAP数据集上的WAR和UARTable 2 WAR and UAR of different methods on EMODB、eNTERFACE、IMOCAP data sets
然后使用混淆矩阵进一步分析3D-D-ACRNN的性能。图4~6分别为EMODB,eNTERFACE,IEMOCAP数据集的混淆矩阵。如图4所示,在EMODB数据集中,boredom、sadness、neutral都获得了较高的识别率,而happiness和disgust识别率较低,其中20%的fear被归类为happiness,20.75%的boredom被归类为disgust。如图5所示,在eNTERFACE数据集中,anger的识别率较高,而disgust识别率较低,其中18.18%的fear被归类为disgust。造成以上误识别的原因是以上几种情感在情感空间的坐标太接近,因此需要使用能提取更加细致特征的特征提取模型。如图6所示,在IEMOCAP数据集中,anger、sad获得了较高的识别率,而happy识别率较低,其中42%的neutral被归类为happy,在IEMOCAP数据集造成happy识别率较低的原因可能是在IEMOCAP数据集中happy样本的数量较少,可以利用重叠等手段增加数据集中处于临界值的样本数量。

图4 EMODB数据集的混淆矩阵Figure 4 Confusion matrix of EMODB dataset

图5 eNTERFACE数据集的混淆矩阵Figure 5 Confusion matrix of eNTERFACE dataset

图6 IEMOCAP数据集的混淆矩阵Figure 6 Confusion matrix of IEMOCAP dataset
3 结论
在本文中,为SER提出了一种基于迁移学习的三维注意力卷积循环神经网络(3D-D-ACRNN)。首先从语音信号中提取3D-LogMels(静态,一阶差分和二阶差分)作为CNN输入;其次,使用迁移学习的方法解决数据量不足的缺点;然后,使用膨胀卷积和BLSTM分别提取语音数据的空间特征和包含上、下文信息的时间特征,并将空间特征和时间特征融合为时空特征;最后,将注意力层用于关注语音情感相关的部分。在EMO-DB,eNTERFACE、IEMOCAP三个数据集上进行的实验表明,提出的方法具有一定的优越性。
